提升 Hive Query 执行效率 - Hive LLAP
从 Hive 刚推出到现在,得益于社区对它的不断贡献,使得 Hive执行 query 效率显著提升。其中比较有代表性的功能如 Tez (将多个 job整合为一个DAG job)以及 CBO(Cost-based-optimization)。
Hive 在 2.0 版本以后推出了一个新特性名为 LLAP(Live Long And Process),它可以显著提高 hive query的效率。
LLAP提供了一种混合模型,它包含一个长驻进程,用于直接与DataNode 进行IO交互,并紧密地集成在基于DAG的框架中。Caching,pre-fetching,部分query的执行,以及 access control被移动到此进程执行。
大部分Small/short queries被此进程直接处理。而如果是大型任务(如在reduce阶段中的大型shuffle) 则仍被标准的yarn containers 处理。此外,LLAP 还提供了更精细的访问控制。
类似于 DataNode 进程,LLAP 进程也可被其他应用访问,特别是在以文件为中心(file-centric)的关系型数据处理(如 join,多表查询)中。下图展示了 带有LLAP 的执行引擎的一个例子:

可以看到,Tez AM 仍作为 Application Master,处理整个任务调度。Query在初始阶段即被送往 LLAP。在Reduce阶段中,大型的 shuffles 操作在不同的 containers 中执行。多个 queries 与 applications 可以并行地访问 LLAP。
为了满足 caching 以及 JIT 优化,以及减少大部分的启动消耗(startup costs),LLAP 会在每个从节点上启动一个常驻进程。这个进程用于处理 I/O,caching,以及query中部分片段的执行。
LLAP 与集群中执行引擎共同工作,以保留 Hive 原有的性能(如可扩展性能)。LLAP 并不会替代已存在的执行引擎,而是增强它的功能。这里需要注意的几点是:
1. 这些进程是可选的。没有他们,Hive也可以正常工作
2. LLAP 并不是一个执行引擎(如MR or Tez)。一个query 的整个执行过程仍由原有的执行引擎调度与监控。LLAP级别的支持暂时仅对 Tez 可用
3. 取决于query,一个LLAP进程可以提供query的部分结果,或是转交给外部的Hive Task
4. 资源管理仍由 YARN 负责。在YARN container 分配资源后,执行引擎可以决定哪些资源可以被分配给LLAP,或者它可以启动 Apache Tez processors 在一个独立的 YARN container中。
搭建 Hive LLAP
下面介绍一下搭建 LLAP 的流程
1. 安装 Apache Slider
由于Hive LLAP 基于 Apache Slider,所以需要先在主节点上安装 Apache Slider。
Github地址地址:https://github.com/apache/incubator-retired-slider/tree/branches/branch-0.92
下载后使用 maven 编译:mvn clean site:site site:stage package -DskipTests
完成后解压 apache-slider-0.92.0-incubating/slider-assembly/target/slider-0.92.0-incubating-all.tar.gz
文件目录如下:

编辑 conf/slider-env,加入 JAVA_HOME 以及 HADOOP_CONF_DIR 环境变量:

编辑 conf/slider-client.xml,指定集群 zookeeper 地址:
<property>
<name>hadoop.registry.zk.quorum</name>
<value>xxxxxx:2181</value>
</property>
将 bin/ 目录加入 PATH 环境变量,执行 slider 命令,验证是否安装成功:

2.LLAP 配置
hive-site.xml 中添加以下参数:
<property>
<name>hive.zookeeper.quorum</name>
<value>xxxxx:2181</value>
</property>
<property>
<name>hive.execution.mode</name>
<value>llap</value>
</property>
<property>
<name>hive.llap.execution.mode</name>
<value>all</value>
</property>
<property>
<name>hive.llap.daemon.service.hosts</name>
<value>@llap_demo</value>
</property>
<property>
<name>tez.runtime.io.sort.mb</name>
<value>150</value>
</property>
使用以下命令生成 llap 环境包:
hive --service llap --name llap_demo\
--instances 2\
--cache 512m\
--executors 4\
--iothreads 4\
--size 4096m\
--xmx 2048m\
--loglevel INFO\
--args "-XX:+UseG1GC -XX:+ResizeTLAB -XX:+UseNUMA -XX:-ResizePLAB -XX:MaxGCPauseMillis=200"\
--javaHome $JAVA_HOME
--instances指定多少个从节点
--cache 指定每个节点的cache大小
--executors 指定节点executors 数量
--iothread 指定每个实例的 io 线程数
--size 指定每个节点的container内存大小
--xmx 指定container JVM 堆大小
--log-lever 指定日志等级
在执行过程中,需要用到 hbase 相关 jar 包,若报错与此相关,则添加相应依赖到 hive lib,如:
sudo cp -r /usr/lib/hbase/* /usr/lib/hive/lib
执行完成后会生成一个命名为 llap-slider-(%Date) 格式的文件夹,如 llap-slider-19Mar2019,运行文件夹内 run.sh,即可启动 LLAP 常驻进程,如 yarn 界面下:

此时会在从节点上均启动一个 container,一般会启动失败,报错为缺少依赖jar 包。在从节点上启动 container 时,相关 jar 依赖位于 llap-slider-19Mar2019 文件下的 llap-slider-19Mar2019.zip 解压后的 files 下:

若需要添加 jar 包,则需先解压 llap-19Mar2019.tar.gz,然后将 jar 包加入此文件夹,最后再打包还原成原目录结构,例如:
cd llap-slider-19Mar2019
unzip llap-19Mar2019.zip -d unzipped
cd unzipped
cd package
cd files
tar -xvzf llap-19Mar2019.tar.gz
rm -rf llap-19Mar2019.tar.gz
tar -cvzf llap-19Mar2019.tar.gz *
// 添加 jar 包
sudo cp /usr/lib/hadoop/*.jar .
...
rm -rf bin conf config.json lib
cd /home/hadoop/llap-slider-19Mar2019
rm -rf llap-19Mar2019.zip
cd unzipped
zip -r llap-19Mar2019.zip *
cp llap-19Mar2019.zip ../
cd ..
rm -rf unzipped/
启动成功后,可以在 application master 界面理看到:
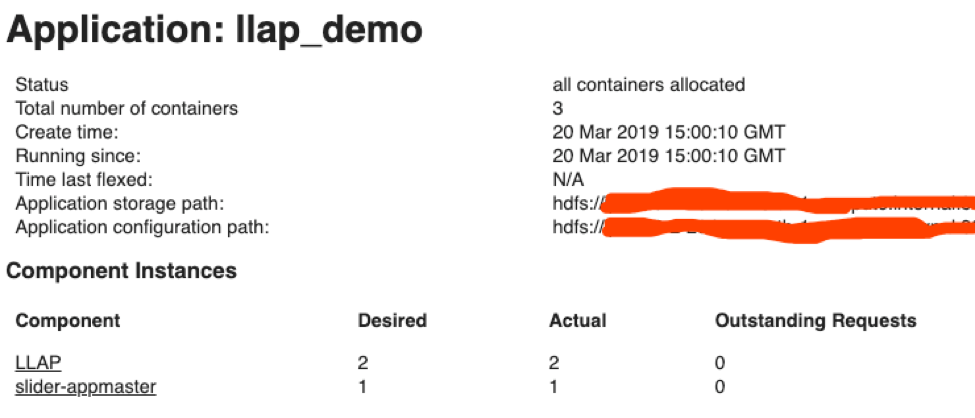
测试
在 LLAP 成功启动后,下面对 Hive query 效率进行测试。这里我们使用 hortonworks 提供的 hive-testbench。
Github地址为:https://github.com/hortonworks/hive-testbench
下载并编译生成环境后,生成 30 G数据:
./tpcds-setup.sh 30
在 hive shell 中,设置 llap 模式为 none:
hive> set hive.llap.execution.mode=node;
执行提供的示例 sql 语句:

可以看到此任务跑了 131 秒。开启 llap 模式,再次运行:
hive> set hive.llap.execution.mode=all;

可以看到执行仅耗费 50 秒,前文提到 LLAP 会使用cache优化query,所以若是再次执行同一query,会比之前运行更快:

LLAP 可以显著提升 Hive query 执行效率。但由于 LLAP 为常驻进程,会持续占用 yarn 可用资源。若集群并不单独作为 hive 数仓,而是用于各类应用(Spark、Hive 等),则是否在集群使用仍需权衡。
提升 Hive Query 执行效率 - Hive LLAP的更多相关文章
- MySQL 5.7 优化SQL提升100倍执行效率的深度思考(GO)
系统环境:微软云Linux DS12系列.Centos6.5 .MySQL 5.7.10.生产环境,step1,step2是案例,精彩的剖析部分在step3,step4. 1.慢sql语句大概需要13 ...
- 【原创】大数据基础之Hive(1)Hive SQL执行过程之代码流程
hive 2.1 hive执行sql有两种方式: 执行hive命令,又细分为hive -e,hive -f,hive交互式: 执行beeline命令,beeline会连接远程thrift server ...
- 【原创】大叔经验分享(1)在yarn上查看hive完整执行sql
hive执行sql提交到yarn上的任务名字是被处理过的,通常只能显示sql的前边一段和最后几个字符,这样就会带来一些问题: 1)相近时间提交了几个相近的sql,相互之间无法区分: 2)一个任务有问题 ...
- 在Hive中执行DDL之类的SQL语句时遇到的一个问题
在Hive中执行DDL之类的SQL语句时遇到的一个问题 作者:天齐 遇到的问题如下: hive> create table ehr_base(id string); FAILED: Execut ...
- Hive查看执行日志
HIVE-如何查看执行日志 HIVE既然是运行在hadoop上,最后又被翻译为MapReduce程序,通过yarn来执行.所以我们如果想解决HIVE中出现的错误,需要分成几个过程 HIVE自身翻译成为 ...
- Hive Query生命周期 —— 钩子(Hook)函数篇
无论你通过哪种方式连接Hive(如Hive Cli.HiveServer2),一个HQL语句都要经过Driver的解析和执行,主要涉及HQL解析.编译.优化器处理.执行器执行四个方面. 以Hive目前 ...
- hive高阶1--sql和hive语句执行顺序、explain查看执行计划、group by生成MR
hive语句执行顺序 msyql语句执行顺序 代码写的顺序: select ... from... where.... group by... having... order by.. 或者 from ...
- 【原创】大叔问题定位分享(22)hive同时执行多个insert overwrite table只有1个可以执行
hive 2.1 一 问题 最近有一个场景,要向一个表的多个分区写数据,为了缩短执行时间,采用并发的方式,多个sql同时执行,分别写不同的分区,同时开启动态分区: set hive.exec.dyna ...
- hive -e执行出现「cannot recognize input near '<EOF>' in select clause」问题
问题现象 写了一个简单的shell脚本调用hive执行组装的sql,在执行时总是报cannot recognize input near '<EOF>' in select clause错 ...
随机推荐
- php 图片添加文字,水印
因为工作需求,用到这个,网上找了很多,也没有找到好的方式,最后找到这种感觉比较简单的方式,记录下来,以备后用. $im = imagecreatefrompng("img/yyk_bg. ...
- python 之路 day5 - 常用模块
模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configparser has ...
- 如何查看视图的sql语句
select text from syscomments s1 join sysobjects s2 on s1.id=s2.id where name='视图名称'前提条件是视图没有被加密,有权限
- Vfox数据库导出EXCEL,含有备注型子段
1. 选择菜单“数据”-> “自其他来源”->“来自 Microsoft Query ”. 2. 在出来的“选择数据源” 里面双击第一个选项“<新数据源>”会出来一个“创建新数 ...
- Linux高效数据统计命令wc
wc(world count)是一个统计文件字词,字节,行数的命令,它可以帮我们非常方便的统计以上信息. 主要参数 常见参数如下: -c 统计字节数. -l 统计行数. -m 统计字符数.这个标志不能 ...
- java数组集合元素的查找
java数组和集合的元素查找类似,下面以集合为例. 数组集合元素查找分为两类: 基本查找: 二分折半查找: 基本查找: 两种方式都是for循环来判断,一种通过索引值来判断,一种通过数组索引判断. 索引 ...
- vue - 列表显示(列互相影响,全选控制,更新数据)
要实现的效果为:全选,且列A列B互相影响,列B勾选则列A一定勾选,列A取消勾选,则相应列B取消勾选 数组 vue中列表渲染有些不是相应式的 var list=[ { a:'aaaa', b:'ddd' ...
- Hadoop-Impala学习笔记之SQL参考
参考:Apache Impala Guide--Impala SQL Language Reference. Impala使用和Hive一样的元数据存储,Impala可以访问使用原生Impala CR ...
- JSP页面静态包含和动态包含的区别与联系
---恢复内容开始--- JSP页面静态包含和动态包含的区别与联系: 1.<%@ include file=" " %> 是指令元素,<jsp:include p ...
- 剑指offer(66)机器人的运动范围
题目描述 地上有一个m行和n列的方格.一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于k的格子. 例如,当k为18时,机器人能 ...