SQL入门(1): 创建/查询/更新/连接/视图/SSMS简介
本文介绍SQL的基本查询语句
(1) select... from
* 表示全部, 选择的东西还可以进行简单的运算, 可以列别名
select * from student; -sage from student; -- plsql development 中列名就是2018-sage -sage birth, lower(sdept) from student;-- lower(sdept) 最后没有列名!
如何选出表中的前两行?
;
消除重复行 -> distinct
select distinct sno from cs; --选课的学生学号
between.. and...; in ; like;
null ; not null;
and ; or
;-- 选出不及格的学生学号
;
select sname from student where sdept in ('cs','MA');
select * from student where sname like '徐%'; --姓徐的人
select * from student where sname like '徐_'; -- 姓徐的人,且名字只有两个字
select * from student where sname not like '_平'; -- 名字第二个字不是平的学生
select cname from course where cname like 'DB\_design' escape'\'; -- 转义字符,需要加escape
select distinct sno from sc where grade <60;-- 选出不及格的学生学号-- 选出没成绩或者不及格的学生学号
;
order by 按照某种顺序排布 desc 降序, 默认是升序asc
order by grade desc;
聚集函数: count(), max ,min ,avg,sum ( distinct | all)
select count(*) from student; --学生人数 select count(distinct sno) from sc ;-- 修课总人数 --学号是201213的学生修读的总学分 " and sc.cno=course.cno;
group by 对输出进行分组
select cno,count(sno) from sc group by cno ;-- 各个课程号以及对应的选课人数 select sno from sc group by sno having count(*)>=3;-- 修了三门课以上的学生学号--平均成绩90以上的学生学号与成绩 select sno, avg(grade) from sc group by sno having avg(grade)>=90;--以下错误!! where 中不能用聚集函数 group by sno ;
--按系区分男女 统计各系的学生人数,按人数降序排 select sdept, ssex, count(sno) from student group by sdept, ssex order by count(sno) desc
注意: 上述group by 要把sdept,ssex都写进去!, 不只写一个!!!, 很重要
两门课以上不及格的学生学号与平均成绩
;
注意: 结果中的每一条信息的sno是 不同的!
上述方法是有歧义的, avg(score)是不及格课的成绩的平均还是所有课的成绩平均??
上述表示不及格课的成绩的平均!! 如果想要得到所有课的平均 , 如何修改?
select sno, avg(score) from sc where sno in ( ) group by sno; -- 选出两门课以上不及格的学生学号, 因此avg(score)是所有课的平均
连接查询, 等值连接 =
(1)查询每一个学生以及他的修课情况
select student.* , sc.* from student, sc where student.sno=sc.sno;
这会出现很多冗余信息, 如何去掉冗余? select 中一项一项列出来..
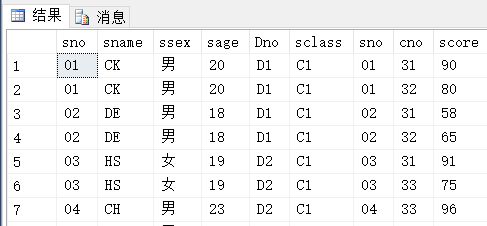
(2) 修2号课程且grade>=90的学生的学号和姓名
';
自身连接 需要用到 别名
(3) 得到每一门课程的先修课, 以(a,b) 形式呈现, 表示a的先修课是b
select c1.cname, c2.cname from course c1,course c2 where c1.cpno=c2.cno;
(4)查询每个学生的学号 姓名 修课名称以及成绩
select student.sno, sname, cname, grade from student, course,sc where student.sco=sc.sno and course.cno=sc.cno;
嵌套查询
(5) 查询与'A' 同系的学生的姓名 学号 系别
select sname, sno ,sdept from student where sdept in ( select sdept from student where sname='A'); -- 也可以用自身连接 select s1.sname ,s1.sno, s1.sdept from student s1, student s2 where s1.sdept=s2.sdept and s2.sname='A';
(6)找每个学生超过他们所修课程的平均分的课程号和学生的学号
select sno, cno from sc x where grade>(select avg(y.grade) from sc y where y.sno=x.sno );
(7)查询修读了名称为"AA"课的学生的姓名与学号
select sname, sno from student where sno in (select sno from sc where cno in ( selecet cno from course where cname='AA'));
>any 大于子查询中的某个值
>all 大于所有值
(8) 非cs系的学生中比cs系的所有学生年龄都小的学生姓名与年龄
select sname, sage from student where sdept <>'CS' and sage < all ( select sage from student where sdept='CS');
集合查询: union, intersect, except(差集)或者minus
(9) 查询cs 系学生以及年龄<19岁的学生
select * from student where sdept='CS' union ;
注意: union 合并会自动去除重复, union all 不会除重!
(10) 没学过01号课的学生的学号
'; -- 错误, 这把学过01又学过02的人也算进去了
select distinct sno from sc except
('); -- 正解!
表的数据更新 insert into, update, delete from;
1.插入数据 insert into 表名(属性) values (数据)
insert into student(sno, sname, ssex, sdept, sage) );
insert into student(sno, sname, ssex,sdept) ', 'chensan','male','cs'); -- sage 默认是null
插入子查询结果 (实现批量insert)
), avg_age smallint); --创立一个新表 insert into dept_age( sdept, avg_age) select sdept, avg(sage) from student group by sdept;
修改数据 update 表名 set(列名)=表达式 where 条件
(11) 将cs系学生年龄改为20
where sdept='cs';
将cs系学生年龄+1
where sdept='cs';
将cs系学生的成绩改为0;
where sno in (select sno from student where sdept='cs');
(12)上调所有学生001号课程的成绩10%
';
删除数据 delete from 表名 where 条件, 表还是在的!
'; -- 删除一个tuple delete from sc ; --删除所有选课记录
(13) 删除四门课不及格的学生
delete from student where sno in ( );
补充:
已知五张表的数据如下:
student(sno,sname,ssex, sage,dno,sclass) , dno 表示系号
dept(dno,dname,dean) , dean表示系主任的名字
course(cno,cname,chours,credit,tno) chours学时, credit学分, tno 任课教师编号
teacher(tno,tname,dno,salary)
sc(sno,cno,score)
(1) 创建数据库 名叫 SCT (SQL server 的操作, 在SSMS中)
create datebase sct;
create table 表名(列名 数据类型);
常见数据类型有: char(n); varchar(n) , real, float , date (2001-01-01), time(23:10:10), int
numeric(p,q) 表示p位整数与q位小数.
[primary| unique| not null ], primary 表示一个表只能有一个主键,
unique表示 可以有多个候选键, not null 表示这一列不能为空.
) ),ssex ), sage ),sclass ));
用现成的表创建与该表结构一样的新表!
-- 创建表tbl2, 它的表结构与tbl1一样 ; -- 复制表, 把数据也复制过去了 create table tab2 as select * from tbl1 where True;
如何查看已经创建的表的结构?字段? 在plsql development 中, 打开一个命令窗口, 输入 desc table_name 得到:

向表中追加元素, 如果顺序对的上, 可以
insert into student ,'d03','class1');
注意: 上述创建表 之前增加语句 use sct; 表示在这个数据库中(ssms 中,SQL server 中要用,这个软件会在最后简单介绍)
设置某些的列的默认值, 这样在之后insert中没有数据就不会显示Null, 而是显示默认值
) ),ssex ), sage ),sclass ) default '1班');
也可以用函数作为默认值:-->把系统时间作为默认值
) ),ssex ), sage ),sclass ),begin_date date default sysdate);
默认值可以保证该列的非空约束!! 很有用
修改默认值的约束
) default '2班';--添加默认值约束 ) default null; --删除默认值约束 alter table student modify sclass default '3班';-- 修改
查询实例:
) and dno='d01';
(1)既学过01 又学过02课的学生学号
'; -- 出错,where 的条件永远达不到 --修改为 ' -- 自身连接 ';
(2)修过31号课程且大于80分的学生学号并且按照成绩由高到低排序
order by grade desc;
(3)工资不同的任意两名教师
select T1.name as teacher1, T2.name as teacher2 from teacher T1, teacher T2 where T1.salary>T2.salary;
改进: 有差额的任意两位教师的工资差(t1,t2,diff(salary)) 形式展现
select T1.name as teacher1 , T2.name as teacher2 , T1.salary - T2.salary from teacher T1, teacher T2 where T1.salary>T2.salary;
(4)修的的01课程分数比02课程高的学生学号
' and s1.grade>s2.grade;
(5)重点: 未上chensan 老师的课的学生姓名
select sname from student s, sc,teacher t , course c where t.tname<>'chensan' and s.sno=sc.sno and sc.cno=c.cno and t.tno=c.tno; -- 出错,条件中上过chensan的课 , 但是也修过其他老师的课的学生也被筛选出来了 --修正: 运用 not in 双重否定 select sname from student where sno not in (select sno from sc,teacher t , course c where t.tname='chensan' and sc.cno=c.cno and t.tno=c.tno ) ; -- 先选出修过chensan 老师课的学生学号
(6)将xy 同学31号课程成绩重新设置为班级该课程的平均分
嵌套查询,找到与xy 同班的同学,修了同一门课的同学
update sc set score= ( select avg(sc2.score) from sc sc1,sc sc2, student s1,student s2 where s.sname='xy' and s1.class=s2.class -- 同班 ' --同课 and s1.sno=sc1.sno and s2.sno=sc2.sno)-- 多表连接 where sc.sno=student.sno and student.sname='xy';
修正表 alter / drop
alter table 表名 add 增加新列
alter table 表名 drop 删除约束 删除列
alter table 表名 modify 修改列定义
) ,tel );--在student 表中增加2列,addr,tel ); -- 修改sname 的数据类型 alter table student drop unique(sname); -- 删除姓名为唯一值的约束 alter table student drop deptno; --删除系号这一列! -- 一个alter中可以实现多步 ) ); --更改sname字段数据结构,并增加一个字段remark drop table student;-- 撤销学生表 drop datebase sct; -- 删除整个sct数据库 use sct; -- 使用当前数据库 close sct; -- 关闭数据库
(7) 找出'31'号课成绩不是最高的学生学号
' and score< some
(');
相关子查询:
(1) 修过31号课程的学生姓名
' and sno=s.sno);
这里没有 sno=s.sno 也可以.查询结果一样的.
(2) 所有课都不及格的学生的姓名
> all (select score from sc where s.sno=sno);
这里没有 sno=s.sno 不行,子查询中 必须要说明是哪个学生的成绩.
(3)zs 同学成绩最低的课程号
select cno from sc, student s where sc.sno=s.sno and s.sname='zs' and score<= all(select score from sc where sc.sno=s.sno);
in 等价于 = some
但是not in 与 <> some 不等价, not in 与<> all 等价
难点: exists 运用! 判别是否为空.
(1) 修过'xxy' 老师的课的学生姓名, 用三个链接表达式
select distinct sname from student s, teacher t, sc, course c where t.tname='xxy' and c.tno=t.tno and s.sno=sc.sno and c.cno=sc.cno;
--使用exists
select distinct sname from student where exists (select * from sc,course c,teacher t where t.name='xxy' and t.tno=c.tno and c.cno=sc.cno and sc.sno=student.sno);
( 2) 修过'001 号老师所有的课的学生姓名
转化为 不存在001号老师 的一门课这位学生没有修过
select sname from student where not exists -- 不存在这样的学生
(' and not exists -- 001号教师的课
( select * from sc where sc.sno=student.sno and c.cno=sc.cno)); --学生没学过
(3)没修过'xxy'老师上过的任何一门课的学生姓名
即: xxy的所有课这个学生都没有上过
select sname from student where not exists ( select * from teacher t, course c ,sc where t.tname='xxy' and t.tno=c.tno and sc.sno=student.sno and sc.cno=c.cno);
(4) 学过001号学生学过的所有课的学生学号-->不存在001号学生的一门课 这位学生没有学过
select sno from sc x where not exists
(' and not exists (select * from sc where sno=x.sno and cno=y.cno);
(5) SPJ (sno,pno,jno,qty) 内部参数分别表示 供应号,零件号,工程号,数量
用了s1 号供应商的全部零件的工程号--? 不存在s1 号供应的零件 该工程没有用
select distinct jno from spj x where not exists (select * from spi y where y.sno='s1' and not exists (select * from spj where jno=x.jno and pno=y.pno));
注意点: 聚集函数除了count(*) 之外其他都不计null
内连接, 外连接
inner join
left outer join 左外连接 left join
right outer join 右外连接 right join
full outer join 全外连接
连接条件 natural, on, using (col1,col2,...colN )
A left outer join B 表示 A的任何元组 t都会在结果中, B 中若有满足连接条件的元组s ,则与t 相连, 否则t 与空值元组相连
例: 所有教师的任课情况并按照教师号 排序 (没有上课的教师也在其中)
select teacher.tno ,tname,cname from teacher inner join course on teacher.tno=course.tno order by teacher.tno asc; -- 没有课的教师没有算进去! 要用外连接 select teacher.tno, tname, cname from teacher left outer join course on teacher.tno=course.tno order by teacher.tno asc;
连接的详细介绍
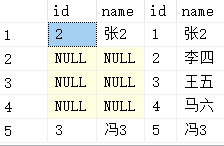
)); )); ,'赵1'); ,,'冯3'); ,,'凌5'); ,,'李四'); ,,'马六'); ,'冯3');
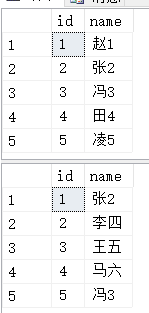
join 实例:
select * from a full outer join b on a.name=b.name;-- 名字一样就匹配在一起 8条 select * from a inner join b on a.name=b.name; -- 2条 select * from a left outer join b on a.name=b.name; -- 5条 select * from a right outer join b on a.name=b.name; -- 5条
(1) A inner join B 产生的结果A和B的交集

(2)A full outer join B 是两者的并集, 如果没有匹配就显示null
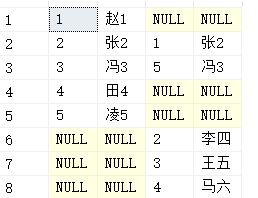
(3) A left outer join B, A中所有保留, B中元组不在A 中的则过滤掉
在Oracle 中外连接用(+) ,加号显示在哪个表, 哪个表的数据不全.
注意: 在where 后面写+, 写+ 这个方法少用!
-- 返回table2表中的所有记录,返回table1表中所有满足条件的记录 SELECT table1.column, table2.column FROM table1, table2 WHERE table1.column(+) = table2.column; -- 右外连接 --返回table1表中的所有记录,返回table2表中所有满足条件的记录 SELECT table1.column, table2.column FROM table1, table2 WHERE table1.column= table2.column(+); -- 左外连接
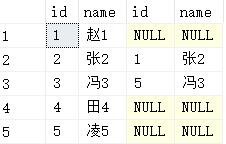
(4) A right outer join B, B表的所有保留
(5) A cross join B, 实现笛卡尔乘积, 很少用这个! 共有25个元组
(6) 自然连接 NATURAL JOIN
自然连接 将表中具有相同名称的列自动进行记录匹配。
--已知有两张表 --emp(ename, sal, dno) 姓名 工资, 部门编号 --dept(dno,dname) 部门编号 部门名字 select e.ename, e.sal, d.dname from dept d natural join emp e;
select * from a natural join b; ?? 报错?
视图介绍 view
视图是一个虚表, 视图建立在已有表的基本上,视图赖以建立的这些表称之为基表;
视图是从一个或多个基本表中导出的表, 只存放视图的定义,但是不存放对应数据, 它不过是一个查询结果, 当基表的数据变化, view 也会随之变化.
视图分为简单视图、复杂视图、连接视图、只读视图:
1、简单视图只从单表里获取数据;不包含函数和数据组。
2、复杂视图从多表获取数据;包含函数和数据组。
3、连接视图是指基于多个表建立的视图,使用连接视图能够简化连接查询。
4、只读视图只允许使用select语句,不允许其他DML语句的操作。
1.定义视图
create or replace view 视图名[列名..] as 子查询 [with check option]
create view cs_student as select sno,sname,sage from student where sdept='cs';
上述replace 很重要, 可以避免重名!!
如果视图的属性名缺省, 则默认为子查询结果中的属性名,
with check option 指明当对视图进行 insert,update,delete 时, (增改删)
要检查进行insert\update\delete 的元组是否满足视图中子查询 定义的条件.
简单几个例子: emp 表示员工的表, dept 表示部门表
emp(empno,ename,job,deptno)
dept(deptno,dname)
--连接视图 CREATE VIEW dept_emp_view AS SELECT d.deptno, d.dname, e.empno, e.ename, e.job ;

--只读视图 SQL> CREATE VIEW emp_view3 AS with read only;
示例:
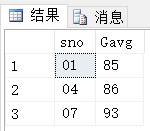
--建立cs 系修了01号课程的学生的视图, 视图中的列名可以修改 create view cs1(ssno, ssname , sscore) as '; --建立cs 系修了01号课程且成绩>90的学生的视图, 在cs1的基础上建立! ; -- 带表达式的视图 -sage from student; --将学号与平均成绩定义成一个视图, 这是一个复杂视图 create view S_G(sno,Gavg) as select sno, avg(score) from sc group by sno;
with check option 运用:
create view dept_emp_view2 as
with check option constraint ck_view;
select * from dept_emp_view2;
--结果
DEPTNO DNAME EMPNO ENAME JOB
ACCOUNTING CLARK MANAGER
ACCOUNTING KING PRESIDENT
ACCOUNTING MILLER CLERK
;
--出现错误: 修改和添加数据时deptno 的值必须为10。
实例:
--将所有女生定义成一个视图 create view female(sno,name,sex,age,dept) as select * from student where ssex='female'; -- 用* 不好, 若之后对基本表student 修改字段, 则该视图的字段会出错,select 还是一个一个列举出来比较保险
2. 更改与删除视图
更改视图: CREATE OR REPLACE VIEW 子句修改视图
CREATE OR REPLACE VIEW emp_view AS SELECT * FROM emp WHERE job = 'SALESMAN';
删除视图: drop view 视图名[ cascade]
cascade表示可以将这个view导出的其他视图一块删除
3.查询视图
cs_student (sno,sname,sage)已知
-- 在cs_student 视图中查询年龄20岁以下的学生学号与年龄 ; --查询修了001号课程的cs系的学生的姓名与学号 ' ;
以下为一个重要注意点!
--在视图S_G基础上找到平均分90以上的学生学号与平均分 ; --出错! 这就相当于where avg(score) >90 , where后不能跟着聚集函数 -- 对视图的查询 转为对基本表的查询一定要有意义. -- 正确的做法如下 ; -- 或者下面也行 select * from (select sno,avg(score) from sc group by sno) as S_G(sno,Gavg) -- 作为临时表 ;
4.更新视图
例:
-- 将cs_student 中学号是201323的学生姓名改为xyy '; -- 在cs_student中新增一条记录 ); -- 删除'yyy' 姓名的学生 delete from cs_student where sname='yyy';
对视图的更新是比较复杂的, 对视图的更新最终需要反映到基本表上去, 然而有时候视图的映射是不可逆的
比如上述S_G(sno,Gavg)
'; --这里对S_G的更新无法转换为对基本表sc的更新, -- 这解释也很简单, 修改平均成绩, 无法反映到这个学生的每一门的成绩!!
-- 创建一个视图
create view classstud(sname, sclass) as
select sname, sclass from student;
insert into classstud values ('zfda','class01'); --出错, 这条记录是插不进去的!!
-- classstud 没有主键sno, sno 是基本表student 的主键, 因此无法更新!
如何判别一个视图是否可以更新?
一般视图中用了聚集函数,unique, distinct, group by,由单表构成但是没有主键的都不能更新

................................
...最后: 简单介绍下微软公司的SQL server , 在SMSS中( SQL server management studio )这个软件中
首先介绍它的快捷键: ctrl+k 再按ctrl+c表示注释, ctrl+k 再按ctrl+u表示取消注释, F5执行

其他没啥好好说的, 无非就是在
create datebase sct;
create table student;
之后写查询语句需要 写 use sct;
SQL server 一般管理中型数据库, 在很多大公司业务中不常用, 之后的文章, 语法都是默认是按照Oracle来的, 对应的编译器是PL/SQL development.
SQL入门(1): 创建/查询/更新/连接/视图/SSMS简介的更多相关文章
- javax.transaction.xa.XAException: java.sql.SQLException: 无法创建 XA 控制连接。(SQL 2000,SQL2005,SQL2008)
javax.transaction.xa.XAException: java.sql.SQLException:无法创建 XA 控制连接.错误: 未能找到存储过程'master..xp_sqljdbc ...
- SQL入门学习3-数据更新
4-1 数据的插入(INSERT语句的使用方法) 使用INSERT语句可以向表中插入数据(行).原则上,INSERT语句背刺执行一行数据插入. CREATE TABLE 和INSERT 语句,都可以设 ...
- javax.transaction.xa.XAException: java.sql.SQLException: 无法创建 XA 控制连接。错误: 未能找到存储过程 'master..xp_sqljdbc_xa_init'
配置JTA SQL Server XADataSource参考:https://msdn.microsoft.com/zh-cn/library/aa342335.aspx 使用 JDBC 驱动程序 ...
- sql 多表联合查询更新
sqlserver: update A a set a.i = b.k from B b where a.key = b.key oracle : update A a set a.i = (sele ...
- 关系数据库SQL之高级数据查询:去重复、组合查询、连接查询、虚拟表
前言 接上一篇关系数据库SQL之基本数据查询:子查询.分组查询.模糊查询,主要是关系型数据库基本数据查询.包括子查询.分组查询.聚合函数查询.模糊查询,本文是介绍一下关系型数据库几种高级数据查询SQL ...
- SQL入门经典(六) 之视图
视图实际上就是一个存储查询,重点是可以混合和匹配来自基本表(或其他视图)的数据,从而创建在很多方面象另一个普通表那样的起的作用.可以创建一个简单的查询,仅仅从一个表(另一个视图)选择几列或几行,而忽略 ...
- ORACLE 通过连接查询更新 update select
注意: 关键的地方是where 语句的加入. 在11G中, 如果不加11G , 或造成除匹配的行数更新为相应的值之后, 其余的会变成负数. 所以,执行前需要测试, 普通办法就是: 先查看需要更新的 ...
- 数据库系统学习(七)-SQL语言之复杂查询与视图
第七讲 SQL语言之复杂查询与视图 基本内容 子查询 IN与NOT IN谓词子查询 判断某一表达式的值是否在子查询的结构中 非相关子查询 相关子查询 theta some /theta all谓词子查 ...
- 《mysql必知必会》笔记3(插入、更新、删除、创建删除更新表、视图)
十九:插入数据 1:insert语句用来将行插入数据表中,可以插入完整的行.行的一部分.插入多行.插入某些查询的结果. 2:不指定列名,可以这样插入: insert into customers va ...
随机推荐
- mybatis 使用缓存策略
mybatis中默认开启缓存 1.mybatis中,默认是开启缓存的,缓存的是一个statement对象. 不同情况下是否会使用缓存 同一个SqlSession对象,重复调用同一个id的<sel ...
- Openvpn搭建详解
说明:公司新购进一批阿里云ESC服务器,计划只有一台有公网IP,其他都通过内网连接.那么问题来了,平时维护时,如果要通过远程工具连接其他服务器就需要先登录公网服务器(A),然后跳转到其内网其他机器上, ...
- vue路由嵌套,vue動態路由
https://www.cnblogs.com/null11/p/7486735.html https://www.cnblogs.com/goloving/p/9271501.html https: ...
- VMware Workstation 12 Pro安装CentOs图文教程(超级详细)
本文记录了VMware Workstation 12 Pro安装CentOs的整个过程,具体如下: VMware Workstation 12: CENTOS 6.4 : 创建虚拟机 1.首先安装好V ...
- python抓取NBA现役球员基本信息数据并进行分析
链接:http://china.nba.com/playerindex/ 所需获取JSON数据页面链接:http://china.nba.com/static/data/league/playerli ...
- Web App架构
Web App 架构分为两种:一种是工程架构,一种是项目架构. 工程架构则主要有以下几个方面的内容: 1, 解放生产力,我们希望在开发项目的过程中把全部目光都放到书写业务代码上,不需要去考虑一些重复性 ...
- ElasticSsarch汇总
用途: 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索: 实时分析的分布式搜索引擎: 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据. 点击查看安装.基本增删改查操作REST ...
- 清北澡堂 Day2 下午 一些比较重要的数论知识整理
1.欧拉定理 设x1,x2,.....,xk,k=φ(n)为1~n中k个与n互质的数 结论一:axi与axj不同余 结论二:gcd(axi,n)=1 结论三:x1,x2,...,xk和ax1,ax2, ...
- Linux squid代理
代理的作用: 共享网络 : 加快访问速度,节约通信带宽 : 防止内部主机受到攻击 : 限制用户访问,完善网络管理: 标准代理: 首先要在内部主机指定代理服务器的IP和port,然后通过代理服务器访问外 ...
- Linux-服务器创建swap交换分区
服务器 swap 交换分区制作 作用:‘提升‘ 内存的容量,防止OOM(Out Of Memory) 查看当前的交换分区 # cat /proc/swaps # free -m # swapon -s ...