numpy鸢尾花
import numpy
from sklearn.datasets import load_iris
#从sklearn包自带的数据集中读出鸢尾花数据集data
iris_data = load_iris()
# 查看data类型,包含哪些数据
print("数据类型: ", type(iris_data))
print("包含数据: ", iris_data.keys()) # 看包含哪些数据
iris_feature = data.feature_names,data.data
#鸢尾花特征:
print(iris_feature)
#iris_feature数据类型
print(type(iris_feature))
iris_target = data.target
#鸢尾花数据类别:
print(iris_target)
#iris_target数据类型:
print(type(iris_target))

sepal_len = np.array(list(len[0] for len in data.data))
#取出所有花的花萼长度(cm)的数据
print(sepal_len)

# 6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
petal_len = numpy.array(list(len[2] for len in iris_data['data'])) # 取花瓣长
petal_len.resize(5, 30)
petal_wid = numpy.array(list(wid[3] for wid in iris_data['data'])) # 取花瓣宽
petal_wid.resize((5, 30))
petal_len_wid = numpy.array(dict(length=petal_len, width=petal_wid)) # 形成新数组
print("花瓣长宽: ", petal_len_wid)

# 取出某朵花的四个特征及其类别
print("某朵花数据: ", iris_data['data'][0], iris_data['target'][0])
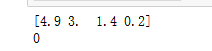
iris_one = []
iris_two = []
iris_three = [] for i in range(0,150):
if data.target[i] == 0:
Data = data.data[i].tolist()
Data.append('setose')
iris_one.append(Data)
elif data.target[i] ==1:
Data = data.data[i].tolist()
Data.append('color')
iris_two.append(Data)
else:
Data = data.data[i].tolist()
Data.append('flower')
iris_three.append(Data)

# 生成新的数组,每个元素包含四个特征+类别
iris_result = numpy.array([iris_setosa, iris_versicolor, iris_virginica]) print("分类结果", iris_result)

numpy鸢尾花的更多相关文章
- 机器学习——logistic回归,鸢尾花数据集预测,数据可视化
0.鸢尾花数据集 鸢尾花数据集作为入门经典数据集.Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理.Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集.数据集包含150个数 ...
- numpy数据集练习
#1. 安装scipy,numpy,sklearn包 import numpy as np #2. 从sklearn包自带的数据集中读出鸢尾花数据集data from sklearn.datasets ...
- 第十三次作业——回归模型与房价预测&第十一次作业——sklearn中朴素贝叶斯模型及其应用&第七次作业——numpy统计分布显示
第十三次作业——回归模型与房价预测 1. 导入boston房价数据集 2. 一元线性回归模型,建立一个变量与房价之间的预测模型,并图形化显示. 3. 多元线性回归模型,建立13个变量与房价之间的预测模 ...
- 第七次作业——numpy统计分布显示
用np.random.normal()产生一个正态分布的随机数组,并显示出来. np.random.randn()产生一个正态分布的随机数组,并显示出来. 显示鸢尾花花瓣长度的正态分布图,曲线图,散点 ...
- 第六次作业———numpy数据集练习
1. 安装scipy,numpy,sklearn包 2. 从sklearn包自带的数据集中读出鸢尾花数据集data 3.查看data类型,包含哪些数据 4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及 ...
- numpy统计分布显示
#导包 import numpy as np #导入鸢尾花数据 from sklearn.datasets import load_iris data = load_iris() pental_len ...
- pytorch解决鸢尾花分类
半年前用numpy写了个鸢尾花分类200行..每一步计算都是手写的 python构建bp神经网络_鸢尾花分类 现在用pytorch简单写一遍,pytorch语法解释请看上一篇pytorch搭建简单网 ...
- numpy数据集练习 ----------sklearn类
# 1. 安装scipy,numpy,sklearn包 import numpy from sklearn.datasets import load_iris # 2. 从sklearn包自带的数据集 ...
- Python实现鸢尾花数据集分类问题——使用LogisticRegression分类器
. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法. 概率p与因变量往 ...
随机推荐
- flask 第三章 特殊装饰器 CBV Flask-Session WTForms
1.flask中的特殊装饰器 前面我们讲过的装饰器函数中,用来登录验证,这次我们来介绍几个flask中的特殊装饰器 1). @app.before_request 具体的用途是: 在请求进入视图函数之 ...
- 阿里云已买到域名价格统计js代码
var sum = 0; $('.table-hover tr.ng-scope').each(function(){ sum = sum + parseInt($(this).children()[ ...
- 聚类--K均值算法
import numpy as np from sklearn.datasets import load_iris iris = load_iris() x = iris.data[:,1] y = ...
- Ubuntu16.04下安装OpenCV3.2.0
1.安装官方给的opencv依赖包 $ sudo apt-get install build-essential $ sudo apt-get install cmake git libgtk2.0- ...
- ansible-play中关于标签tages,handler,notify的使用
--- - hosts: webser remote_user: root tasks: - name: install httpd package yum: name=httpd tages: in ...
- C语言作业(心理魔术)
#include "stdafx.h" #include "stdio.h" #include "stdlib.h" #include &q ...
- shell练习题2
需求如下: 写一个shell脚本,检查指定的shell脚本是否有语法错误,若有错误,首先显示错误信息,然后提示用户输入q或Q退出脚本, 输入其他内容则直接用vim打开该shell脚本. 参考解答如下 ...
- tensorFlow入门实践(三)实现lenet5(代码结构优化)
这两周我学习了北京大学曹建老师的TensorFlow笔记课程,认为老师讲的很不错的,很适合于想要在短期内上手完成一个相关项目的同学,课程在b站和MOOC平台都可以找到. 在卷积神经网络一节,课程以le ...
- 20165214 2018-2019-2 《网络对抗技术》Exp4 恶意代码分析 Week6
<网络对抗技术>Exp3 免杀原理与实践 Week5 一.实验目标与内容 1.实践目标 1.1是监控你自己系统的运行状态,看有没有可疑的程序在运行. 1.2是分析一个恶意软件,就分析Exp ...
- django学习系列——python和php对比
python 和 php 我都是使用过,这里不想做一个非常理性的分析,只是根据自己的经验谈一下感想. 在web开发方面,无疑 php 更甚一筹. 从某种角度来说,php 就是专门为 web 定制的语言 ...