java 环境的安装、设置免密登陆、进行hadoop安装、关闭防火墙
1、去这个网站下载对应的版本:
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我这边下载的是:jdk-8u181-linux-x64.tar.gz
wget -c http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz
然后解压:
tar -zxvf jdk-8u181-linux-x64.tar.gz
修改配制文件:
vim ~/.bashrc 在最后加入:
export JAVA_HOME=/usr/local/src/jdk1.8.0_181
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
或是把这个加入到
/etc/profile 里面
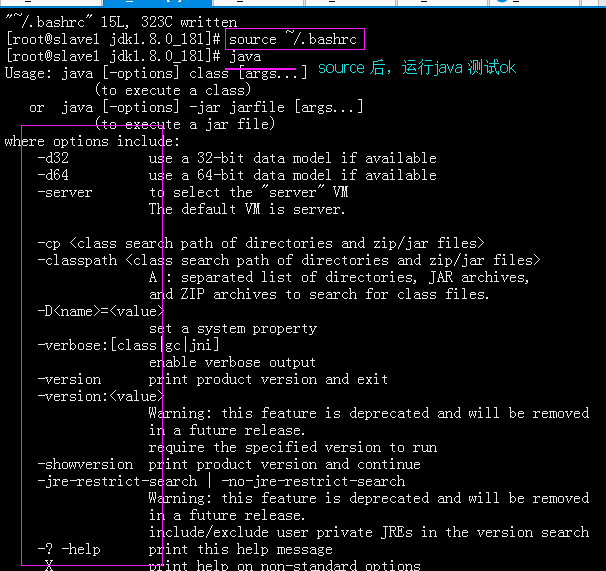
然后,再source ~/.bashrc 或 source /etc/profile
运行就可以查看: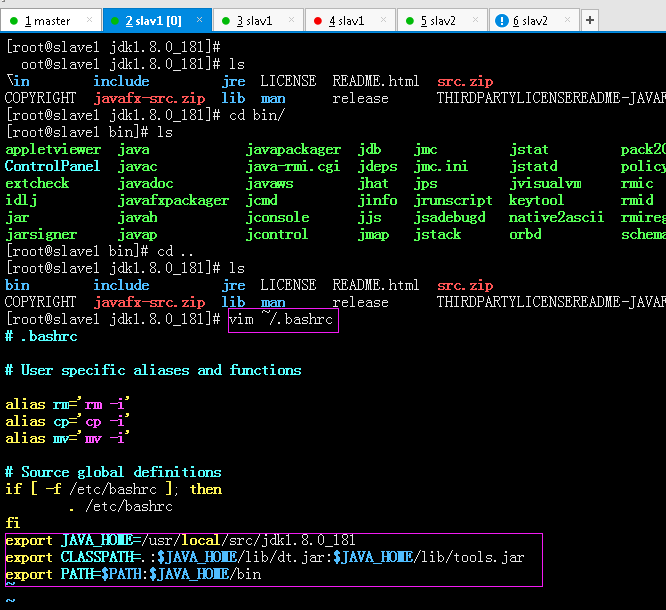
auto_jdk.sh
#!/bin/bash
cd /usr/local/src/
a=`ls |grep jdk*.tar.gz`
tar -xvf $a
b=`ls |grep jdk1*`
cat >> ~/.bashrc << "eof"
export JAVA_HOME=/usr/local/src/$b
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
eof
source ~/.bashrc
2、设置免密登陆:
开启网络ID
[root@localhost /]# vim /etc/sysconfig/network
# Created by anaconda
NETWORKING=yes
HOSTNAME=master
[root@localhost /]# cat >> /etc/hosts << "eof" (在三台机器上都这样子配制)
> 192.168.10.7 master
>192.168.10.8 slave1
> 192.168.10.9 slave2
> eof
[root@localhost /]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.7 master
192.168.10.8 slave1
192.168.10.9 slave2
[root@localhost /]#
密钥生成:ssh-keygen -t rsa -P ''
touch authorized_keys
chmod 600 authorized_keys
cat id_rsa.pub > authorized_keys
用同样的方式,在slave1和slave2上都生成密钥(ssh-keygen -t rsa -P '')
然后,把id_rsa.pub都复制到master上去:
scp id_rsa.pub 192.168.10.7:/root/.ssh/id_rsa.pub1 (在slave1上执行)
scp id_rsa.pub 192.168.10.7:/root/.ssh/id_rsa.pub2 (在slave2上执行)
然后,在maser上执行:
cat id_rsa.pub1 >> authorized_keys
cat id_rsa.pub2 >> authorized_keys
scp authorized_keys root@slave1:/root/.ssh
scp authorized_keys root@slave2:/root/.ssh
最后,再进行测试。
3、进行hadoop安装
这个网站,有目前相关的版本:http://apache.fayea.com/hadoop/common/
wget -c http://apache.fayea.com/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz
解压:tar -xvf hadoop-2.6.5.tar.gz
修改hadoop-env.sh,yarn-env.sh中的JAVA_HOME的路径,都在最前面加一个:export JAVA_HOME=/usr/local/src/jdk1.8.0_181
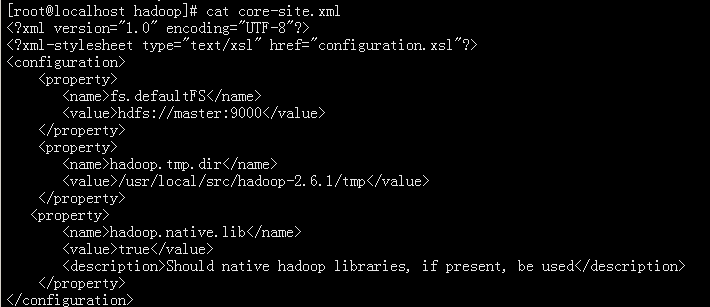
vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.10.7:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.1/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<value>true</value>
<description>Should native hadoop libraries, if present, be used</description>
</property>
</configuration>
vim hdfs-site.xml
cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.datanode.ipc.address</name>
<value>0.0.0.0:50020</value>
</property>
<property>
<name>dfs.datanode.http.address</name>
<value>0.0.0.0:50075</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>

mv mapred-site.xml.templat mapred-site.xml
vim mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

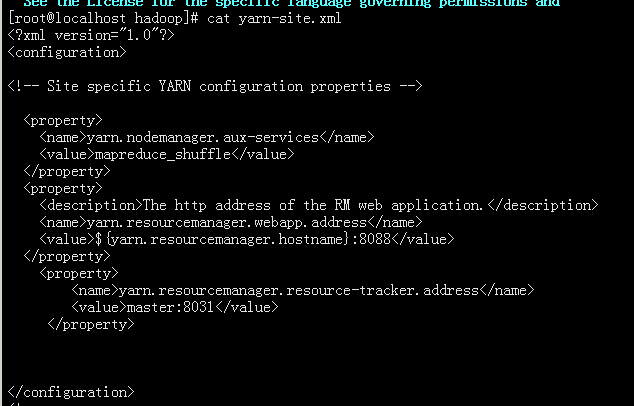
vim yarn-site.xml
[root@localhost hadoop]# cat yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
</configuration>
vim slaves
slave1
slave2

4、关闭三台机器的防火墙
systemctl stop firewalld
systemctl disable firewalld.service
iptables -F
systemctl status firewalld
格式化name
/usr/local/src/hadoop-2.6.1/bin/hdfs namenode -format
启动hdfs和yarn
$HADOOP_HOME/sbin/start-dfs.sh
启动完成后,输入jps查看进程,如果看到以下二个进程:
5161 SecondaryNameNode
4989 NameNode
表示master节点基本ok了
再输入$HADOOP_HOME/sbin/start-yarn.sh ,完成后,再输入jps查看进程
2361 SecondaryNameNode
7320 ResourceManager
4989 NameNode
通过web页面查看hdfs和mapreduce
http://master:50090/
http://master:8088/
查看状态
另外也可以通过 bin/hdfs dfsadmin -report 查看hdfs的状态报告
java 环境的安装、设置免密登陆、进行hadoop安装、关闭防火墙的更多相关文章
- Mysql 5 忘记root密码,设置免密登陆
1.修改my.cnf配置文件 vi /etc/my.cnf #允许免密认证登陆 skip-grant-tables = true 2.重启Mysql数据库并登陆数据库修改root用户密码 system ...
- Linux设置免密登陆
生成秘钥 ssh-keygen -t rsa -C "XX@qq.com",然后一路回车就行 生成之后会在用户的根目录生成一个 ".ssh"的文件夹 进入&qu ...
- linux高频操作: host,用户管理,免密登陆,管道,文件权限,脚本,防火墙,查找
1. 修改hosts和hostname 2. 用户管理 3. 免秘登陆 4. 文件末尾添加 >> 5. 设置可执行文件 6. 任何地方调用 7. Centos6 永久关闭防火墙 8. Ce ...
- xshell 远程登陆CentOS7 免密登陆
首先说一下大体的思路: 1. 以密码登陆CentOS系统 2. 配置ssh 3. xshell 生成秘钥 4. 进行免密登陆 软件.设备: xshell(下载地址(免费版),也可以自行百度下载) Ce ...
- Hadoop完全分布式环境搭建(二)——基于Ubuntu16.04设置免密登录
在Windows里,使用虚拟机软件Vmware WorkStation搭建三台机器,操作系统Ubuntu16.04,下面是IP和机器名称. [实验目标]:在这三台机器之间实现免密登录 1.从主节点可以 ...
- ssh免密登陆及时间设置
1.ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa // 在自己主机生成私钥和公钥 2.scp id_rsa.pub centos@s201:/home/centos ...
- Linux免密登陆设置了免密登陆为啥还需要输入密码
一.设置了免密码登陆但是还是需要输入密码: 权限保证:1.authorized-keys 的权限为 600 2.home.账户所在的目录如hadoop..ssh这三个文件的权限都必须设置为700,缺少 ...
- linux 下的ssh免密登陆设置
一,原理 说明: A为linux服务器a B为linux服务器b 每台linux都有ssh的服务端和客户端,linux下的ssh命令就是一个客户端 我们常用ssh协议来进行登陆或者是文件的拷贝,都需要 ...
- ssh的免密登陆
想必大家都有使用ssh登陆的过程了,那么,怎么设置ssh免密登陆呢?下面有一些我的总结: 环境:服务器主.从 主服务器:192.168.1.1 从服务器:192.168.1.2 实现主服务器ssh登录 ...
随机推荐
- iis 支持 .netcore 环境
1,安装 dotnet-win-x64 https://dotnet.github.io/2,安装 DotNetCore.1.0.4_1.1.1-WindowsHosting.exe https:/ ...
- 活代码LINQ——07
来源说明:https://blog.csdn.net/sha574810590/article/details/40738069 在LINQ中,数据源和查询结果实际上都是IEnumerable< ...
- 最小生成树 HDU1301 (kuskal & prim)
Kruskal:1.边排序,2.按边从小到大连接森林至树 3.并查集 #include <stdio.h> #include <stdlib.h> #include < ...
- ava、Python和PHP三者的区别
Java.Python和PHP三者的区别 2017年07月15日 22:09:21 书生_AABB 阅读数:18994 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blo ...
- MySQL【文本处理函数】的使用方法
文本处理函数 名称 调用示例 示例结果 描述 LEFT LEFT('abc123', 3) abc 返回从左边取指定长度的子串 RIGHT RIGHT('abc123', 3) 123 返回从右边取指 ...
- shiro三连斩之第三斩,整合 springboot
shiro爱springboot中使用 ,还有thymeleaf前端框架.主要是如何配置 pom.xml配置依赖 <?xml version="1.0" encoding=& ...
- dapper.simplecurd
[Table("Users")]//真实表名 publicclass User { [Key] publicint UserId { get; set; } [Column(&qu ...
- Flutter错误集合
一.Waiting for another flutter command to release the startup lock... 运行flutter命令 flutter upgrade 运行 ...
- Struts2配合layui多文件上传--下载
先说上传: 前台上传文件的js代码: var demoListView = $('#demoList') ,uploadListIns = upload.render({ elem: '#testLi ...
- Bootstrap 总结
Bootstrap 首先要引入下面三个文件 <!-- 新 Bootstrap 核心 CSS 文件 --> <link href="https://cdn.bootcs ...