RabbitMQ可靠性投递及高可用集群
可靠性投递:
首先需要明确,效率与可靠性是无法兼得的,如果要保证每一个环节都成功,势必会对消息的收发效率造成影响。如果是一些业务实时一致性要求不是特别高的场合,可以牺牲一些可靠性来换取效率。
要保证消息的可靠性投递,首先需要从以下几方面来确保,其次考虑其他的原因:

1、确保消息发送到RabbitMQ服务器(发送)。
可能因为网络或者Broker的问题导致①失败,而生产者是无法知道消息是否正确发送到Broker的。有两种解决方案,第一种是Transaction(事务)模式,第二种Confirm(确认)模式。
在通过channel.txSelect方法开启事务之后,我们便可以发布消息给RabbitMQ了,如果事务提交成功,则消息一定到达了RabbitMQ中,如果在事务提交执行之前由于RabbitMQ异常崩溃或者其他原因抛出异常,这个时候我们便可以将其捕获,进而通过执行channel.txRollback方法来实现事务回滚。使用事务机制的话会“吸干”RabbitMQ的性能,一般不建议使用。
try {
channel.txSelect();
// 发送消息
// String exchange, String routingKey, BasicProperties props, byte[] body
channel.basicPublish("", QUEUE_NAME, null, (msg).getBytes());
// int i =1/0;
channel.txCommit();
System.out.println("消息发送成功");
} catch (Exception e) {
channel.txRollback();
System.out.println("消息已经回滚");
}
生产者通过调用channel.confirmSelect方法(即Confirm.Select命令)将信道设置为confirm模式。一旦消息被投递到所有匹配的队列之后,RabbitMQ就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这就使得生产者知晓消息已经正确到达了目的地了。Confirm.Select命令 下分为三种模式分别如下:
普通确认模式:
// 开启发送方确认模式
channel.confirmSelect();
channel.basicPublish("", QUEUE_NAME, null, msg.getBytes());
// 普通Confirm,发送一条,确认一条
if (channel.waitForConfirms()) {
System.out.println("消息发送成功" );
}
批量确认模式:
try {
channel.confirmSelect();
for (int i = 0; i < 5; i++) {
// 发送消息
// String exchange, String routingKey, BasicProperties props, byte[] body
channel.basicPublish("", QUEUE_NAME, null, (msg +"-"+ i).getBytes());
}
// 批量确认结果,ACK如果是Multiple=True,代表ACK里面的Delivery-Tag之前的消息都被确认了
// 比如5条消息可能只收到1个ACK,也可能收到2个(抓包才看得到)
// 直到所有信息都发布,只要有一个未被Broker确认就会IOException
channel.waitForConfirmsOrDie();
System.out.println("消息发送完毕,批量确认成功");
} catch (Exception e) {
// 发生异常,可能需要对所有消息进行重发
e.printStackTrace();
}
异步监听确认模式:
// 用来维护未确认消息的deliveryTag
final SortedSet<Long> confirmSet = Collections.synchronizedSortedSet(new TreeSet<Long>()); // 这里不会打印所有响应的ACK;ACK可能有多个,有可能一次确认多条,也有可能一次确认一条
// 异步监听确认和未确认的消息
// 如果要重复运行,先停掉之前的生产者,清空队列
channel.addConfirmListener(new ConfirmListener() {
public void handleNack(long deliveryTag, boolean multiple) throws IOException {
System.out.println("Broker未确认消息,标识:" + deliveryTag);
if (multiple) {
// headSet表示后面参数之前的所有元素,全部删除
confirmSet.headSet(deliveryTag + 1L).clear();
} else {
confirmSet.remove(deliveryTag);
}
// 这里添加重发的方法
}
public void handleAck(long deliveryTag, boolean multiple) throws IOException {
// 如果true表示批量执行了deliveryTag这个值以前(小于deliveryTag的)的所有消息,如果为false的话表示单条确认
System.out.println(String.format("Broker已确认消息,标识:%d,多个消息:%b", deliveryTag, multiple));
System.out.println("multiple:"+multiple);
if (multiple) {
System.out.println("deliveryTag:"+deliveryTag);
// headSet表示后面参数之前的所有元素,全部删除
confirmSet.headSet(deliveryTag + 1L).clear();
} else {
// 只移除一个元素
confirmSet.remove(deliveryTag);
}
System.out.println("未确认的消息:"+confirmSet);
}
}); // 开启发送方确认模式
channel.confirmSelect();
for (int i = 0; i < 10; i++) {
long nextSeqNo = channel.getNextPublishSeqNo();
// 发送消息
// String exchange, String routingKey, BasicProperties props, byte[] body
channel.basicPublish("", QUEUE_NAME, null, (msg +"-"+ i).getBytes());
confirmSet.add(nextSeqNo);
}
System.out.println("所有消息:"+confirmSet); // 这里注释掉的原因是如果先关闭了,可能收不到后面的ACK
//channel.close();
//conn.close();
2、确保消息路由到正确的队列(交换机路由)。
可能因为路由关键字错误,或者队列不存在,或者队列名称错误导致②失败。可以使用 mandatory=true 配合ReturnListener,可以实现消息无法路由的时候返回给生产者。另一种方式就是使用备份交换机(alternate-exchange),无法路由的消息会发送到这个交换机上。
//1.采用ReturnListener
channel.addReturnListener(new ReturnListener() {
public void handleReturn(int replyCode,
String replyText,
String exchange,
String routingKey,
AMQP.BasicProperties properties,
byte[] body)
throws IOException {
System.out.println("=========监听器收到了无法路由,被返回的消息============");
System.out.println("replyText:"+replyText);
System.out.println("exchange:"+exchange);
System.out.println("routingKey:"+routingKey);
System.out.println("message:"+new String(body));
}
}); AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder().deliveryMode(2).
contentEncoding("UTF-8").build();
// 2.在声明交换机的时候指定备份交换机
//Map<String,Object> arguments = new HashMap<String,Object>();
//arguments.put("alternate-exchange","ALTERNATE_EXCHANGE");
//channel.exchangeDeclare("TEST_EXCHANGE","topic", false, false, false, arguments); // 发送到了默认的交换机上,由于没有任何队列使用这个关键字跟交换机绑定,所以会被退回
// 第三个参数是设置的mandatory,如果mandatory是false,消息也会被直接丢弃
channel.basicPublish("","wuzztest",true, properties,"只为更好的你".getBytes());
运行上诉例子,由于设置了ReturnListener,可以看到Broker通知了我们消息路由失败。
3、确保消息在队列正确地存储(存储)。
可能因为系统宕机、重启、关闭等等情况导致存储在队列的消息丢失,即③出现问题。
1、队列持久化,声明队列的时候第二个参数指定为true。
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
2、交换机持久化,声明交换机的时候第三个参数设置为true。
channel.exchangeDeclare(EXCHANGE_NAME,"direct",true, false, null);
3、消息持久化,发送消息的时候设置deliveryMode(2)。
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.deliveryMode(2) // 2代表持久化,其他代表瞬态
.build();
channel.basicPublish("", QUEUE_NAME, properties, msg.getBytes());
4、集群,镜像队列。
4、确保消息从队列正确地投递到消费者(消费)。
如果消费者收到消息后未来得及处理即发生异常,或者处理过程中发生异常,会导致④失败。为了保证消息从队列可靠地达到消费者,RabbitMQ提供了消息确认机制(messageacknowledgement)。消费者在订阅队列时,可以指定autoAck参数,当autoAck等于false时,RabbitMQ会等待消费者显式地回复确认信号后才从队列中移去消息。
如果消息消费失败,也可以调用Basic.Reject或者Basic.Nack来拒绝当前消息而不是确认。如果requeue参数设置为true,可以把这条消息重新存入队列,以便发给下一个消费者(当然,只有一个消费者的时候,这种方式可能会出现无限循环重复消费的情况,可以投递到新的队列中,或者只打印异常日志)。
// 创建消费者,并接收消息
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,
byte[] body) throws IOException {
String msg = new String(body, "UTF-8");
System.out.println("Received message : '" + msg + "'"); if (msg.contains("拒收")){
// 拒绝消息
// requeue:是否重新入队列,true:是;false:直接丢弃,相当于告诉队列可以直接删除掉
// TODO 如果只有这一个消费者,requeue 为true 的时候会造成消息重复消费
channel.basicReject(envelope.getDeliveryTag(), false);
} else if (msg.contains("异常")){
// 批量拒绝
// requeue:是否重新入队列
// TODO 如果只有这一个消费者,requeue 为true 的时候会造成消息重复消费
channel.basicNack(envelope.getDeliveryTag(), true, false);
} else {
// 手工应答
// 如果不应答,队列中的消息会一直存在,重新连接的时候会重复消费
channel.basicAck(envelope.getDeliveryTag(), true);
}
}
}; // 开始获取消息,注意这里开启了手工应答
// String queue, boolean autoAck, Consumer callback
channel.basicConsume(QUEUE_NAME, false, consumer);
在自动确认的情况下,消息是在Broker发送给消费者之后就从队列删除。否则在调用basicACK方法的时候删除。
5、其他
消费者回调:
消费者处理消息以后,可以再发送一条消息给生产者,或者调用生产者的API,告知消息处理完毕。参考:二代支付中异步通信的回执,多次交互。某提单APP,发送碎屏保消息后,消费者必须回调API。
补偿机制:
对于一定时间没有得到响应的消息,可以设置一个定时重发的机制,但要控制次数,比如最多重发3次,否则会造成消息堆积。
参考:ATM存款未得到应答时发送5次确认;ATM取款未得到应答时,发送5次冲正。根据业务表状态做一个重发。
消息幂等性:
服务端是没有这种控制的,只能在消费端控制。消息重复可能会有两个原因:
1、生产者的问题,环节①重复发送消息,比如在开启了Confirm模式但未收到确认。
2、环节④出了问题,由于消费者未发送ACK或者其他原因,消息重复投递。
对于重复发送的消息,可以对每一条消息生成一个唯一的业务ID,通过日志或者建表来做重复控制。
消息的顺序性:
消息的顺序性指的是消费者消费的顺序跟生产者产生消息的顺序是一致的。在RabbitMQ中,一个队列有多个消费者时,由于不同的消费者消费消息的速度是不一样的,顺序无法保证。
高可用集群方案:
rabbitmq集群是通过erlang的分布式特性进行rabbitmq集群,各个rabbitmq的服务为相应的节点,每个节点都提供给客户端连接,进行消息的发送与接收。rabbitmq各节点之间通信使用域名,所以集群成员中所有主机名都要可解析。
1.修改 hosts文件:vim /etc/hosts , 三台都这样子配置
192.168.254.137 rabbit1
192.168.254.138 rabbit2
192.168.254.139 rabbit3
2.修改 rabbitMQ的HOME配置,vim rabbitmq-env.conf ,138.139两台分别为rabbit@rabbit2,rabbit@rabbit3:
#192.168.254.137
NODENAME=rabbit@rabbit1
HOME=/mysoft/rabbitmq_server-3.6.12/var/lib/rabbitmq/
3.rabbitmq集群的节点间是使用cookie来确认通信的,所以集群中的每个节点都必须有相同的erlang.cookie每个rabbitmq启动时,erlang会自动创建一个cookie文件,为了使每个节点的cookie保持一致,可以先让其中一个节点来创建,然后将这个文件拷贝到其他节点的相应位置。我这边让137节点去生成,通过以下命令拷贝到其他两个节点:
scp .erlang.cookie root@192.168.254.138:/mysoft/rabbitmq_server-3.6.12/var/lib/rabbitmq/
4.分别启动3台节点服务。然后将 rabbit@rabbit2,rabbit@rabbit3 两台节点加入rabbit@rabbit1:
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit1
rabbitmqctl start_app
如果出现以下信息,把各个节点对应的数据目录直接干掉重启,当然生产上不会这么干:
Error: {inconsistent_cluster,"Node rabbit@rabbit1 thinks it's clustered with node rabbit@rabbit2, but rabbit@rabbit2 disagrees"}
5.成功后会看到如下状态:

节点状态分为 磁盘节点跟内存节点,改变节点状态:
rabbitmqctl stop_app
rabbitmqctl reset // 会移除节点
rabbitmqctl join_cluster rabbit@rabbit1
rabbitmqctl change_cluster_node_type ram
rabbitmqctl start_app
成功如下:

1)每个节点会保存交换器、队列、绑定等数据
2)消费者可以通过连接任何节点来定位到需要的队列获取数据
3)默认情况下,队列的完整信息(含内容)不会在集群下所有的节点中保存,而是只存在于一个节点中
4)当保存队列完整信息的节点崩溃,消费者不能从集群中获得这个队列的消息,生产者不能推送消息到队列中
5)为了保证集群的高可用,可以在创建队列时声明为镜像队列,即所有节点都保存队列的完整信息,其中有一个主队列,其他都是从队列,当主队列所在的节点崩溃,集群在从队列中选举出一个队列成为主队列
查看集群状态:rabbitmqctl cluster_status。
普通集群是无法实现队列及队列里面数据的复制,所以引入了镜像队列。
镜像队列:
镜像队列的配置可以通过管理端页面,也可以使用命令,命令如下:
rabbitmqctl set_policy [-p vhostpath] {name} {pattern} {definition} [priority] #ha-mode:all、exactly、nodes
比如 rabbitmqctl set_policy -p hostname test "^" '{"ha-mode":"all"}',这行命令在vhost名称为hostname创建了一个策略,策略名称为test,策略模式为 all 即复制到所有节点,包含新增节点,策略正则表达式为 “^” 表示所有匹配所有队列名称。通过控制台如下图:
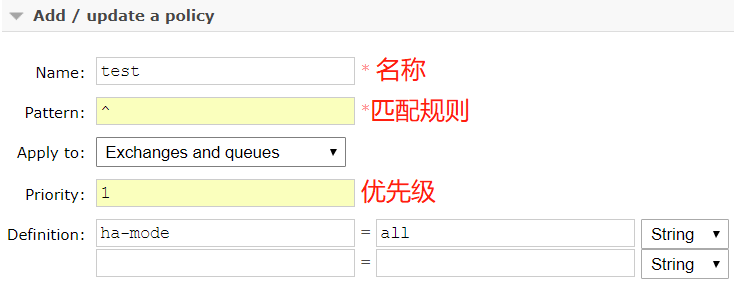
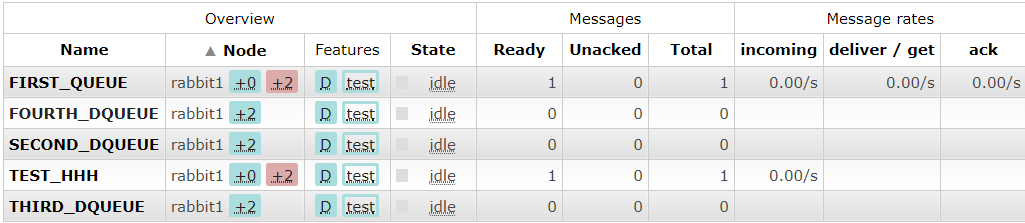
匹配成功后查看队列会出现以下情况,会发现Node列会出现 +2,说明集群还有两个节点和本节点是镜像同步模式:
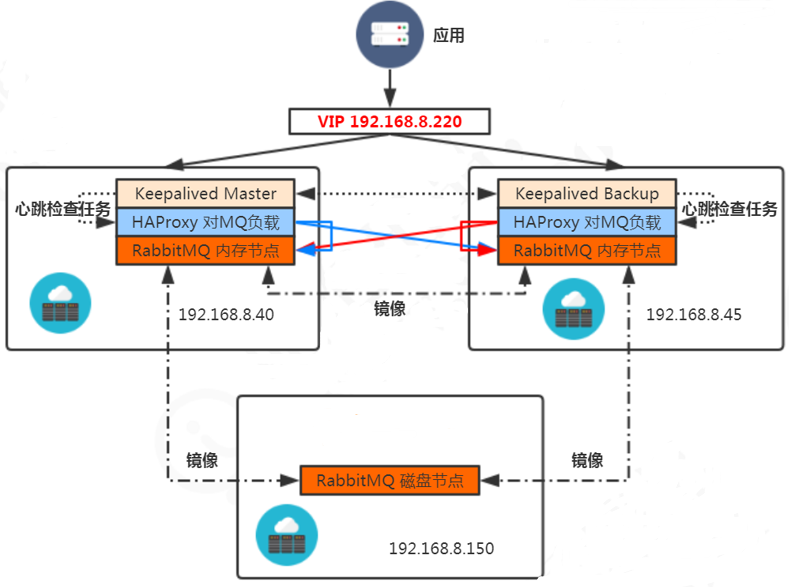
可以通过配置镜像队列的方式去实现数据的同步,然后可以通过HAproxy负载+Keepalived实现集群的高可用。具体配置可以参考 https://www.cnblogs.com/wuzhenzhao/p/10195423.html 。架构如下:
网络分区:
为什么会出现分区?因为RabbitMQ对网络延迟非常敏感,为了保证数据一致性和性能,在出现网络故障时,集群节点会出现分区。
当一个RabbitMQ集群发生网络分区时,这个集群会分成两个或者多个分区,它们各自为政,互相都认为对方分区的节点已经down,包括queues,bindings,exchanges这些信息的创建和销毁都处于
自身分区内,与其它分区无关。如果原集群中配置了镜像队列,而这个镜像队列又牵涉到两个或者多个网络分区中的节点时,每一个网络分区中都会出现一个master节点,如果分区节点个数充足,也
会出现新的slave节点,对于各个网络分区,彼此的队列都是相互独立的,当然也会有一些其他未知的、怪异的事情发生。当网络恢复时,网络分区的状态还是会保持,除非采取一些措施去解决他。
为了从网络分区中恢复,首先需要挑选一个信任的分区,这个分区才有决定Mnesia内容的权限,发生在其他分区的改变将不被记录到Mnesia中而直接丢弃。手动恢复网络分区有两种思路:
1. 停止其他分区中的节点,然后重新启动这些节点。最后重启信任分区中的节点,以去除告警。
2. 关闭整个集群的节点,然后再启动每一个节点,这里需确保你启动的第一个节点在你所信任的分区之中。
停止/启动节点有两种操作方式:
1. rabbimqctl stop/ rabbitmq-server -detached
2. rabbitmqctl stop_app/ rabbitmqctl start_app
自动处理网络分区:
RabbitMQ提供了4种处理网络分区的方式,在rabbitmq.config中配置cluster_partition_handling参数即可,分别为:
1. ignore (默认是ignore)
2. pause_minority (少数派中的节点在分区发生时会自动关闭,当分区结束时又会启动)
3. pause_if_all_down(RabbitMQ会自动关闭不能和list中节点通信的节点)
4. autoheal(当认为发生网络分区时,RabbitMQ会自动决定一个获胜的(winning)分区,然后重启不在这个分区中的节点以恢复网络分区。)
广域网的同步方案:federation插件 ,shovel插件。
常见问题:
1、消息队列的作用与使用场景?
异步:批量数据异步处理。削峰:高负载任务负载均衡(秒杀)。解耦:串行任务并行化。广播:基于发布订阅实现一对多通信。
2、多个消费者监听一个生产者时,消息如何分发?
采用Round-Robin(轮询,可以通过设置channel.basicQos(2) 来设置 PrefetchSize的值实现Fair dispatch(公平分发),。当超过2条消息没提交,队列则不会给该消费者发送消息。
3、无法被路由的消息,去了哪里?
默认情况下这种消息会被丢弃,当然我们可以通过设置来实现消息重发,或者指定备用交换机来转发死信队列。上文中确保路由到制定队列中已写明。
4、消息在什么时候会变成Dead Letter(死信)?
1.消息被消费者拒绝,并且requeue,重新入队被设置成false:channel.basicReject(envelope.getDeliveryTag(), false);
2.消息过期。队列设置了过期时间或者指定消息设置了过期时间,可以在定义的时候设置死信交换机,以做后期处理
3.队列达到最大长度(先入队的消息会被发送到DLX)
5、RabbitMQ如何实现延迟队列?
使用rabbitmq-delayed-message-exchange插件,或者通过死信队列的机制。使用TTL(过期时间)结合DLX(死信)的方式来实现消息的延迟投递。
6、如何保证消息的可靠性投递?
见上文。一共分为4步,保证消息发送(Prodecer),消息转发(Exchange),消息存储(Queue),消息消费(Consumer)等方面去保证。
7、如何在服务端和消费端做限流?
服务端限流通过磁盘空间与内存空间去控制,默认是1G跟40%的时候,这两个阈值都可以通过rabbit.config去配置
消费端的限流可以通过来设置 PrefetchSize的值实现,调用channel.basicQos(2)。
8、如何保证消息的顺序性?
正常情况下有多个生产者生产消息与多个消费者同时消费消息,消息的顺序性是无法保证的,在一个队列只有一个消费者的情况,才能实现顺序性。或者使用全局ID去处理保证顺序性。
9、RabbitMQ的集群模式及节点类型?
普通模式,镜像模式。节点类型分为磁盘节点(DISC)与内存节点(RAM)。
RabbitMQ可靠性投递及高可用集群的更多相关文章
- RabbitMQ和Kafka的高可用集群原理
前言 小伙伴们,通过前边文章的阅读,相信大家已经对RocketMQ的基本原理有了一个比较深入的了解,那么大家对当前比较常用的RabbitMQ和Kafka是不是也有兴趣了解一些呢,了解的多一些也不是坏事 ...
- rabbitmq+haproxy+keepalived实现高可用集群搭建
项目需要搭建rabbitmq的高可用集群,最近在学习搭建过程,在这里记录下可以跟大家一起互相交流(这里只是记录了学习之后自己的搭建过程,许多原理的东西没有细说). 搭建环境 CentOS7 64位 R ...
- RabbitMQ学习系列(六): RabbitMQ 高可用集群
前面讲过一些RabbitMQ的安装和用法,也说了说RabbitMQ在一般的业务场景下如何使用.不知道的可以看我前面的博客,http://www.cnblogs.com/zhangweizhong/ca ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- Redis总结(五)缓存雪崩和缓存穿透等问题 Web API系列(三)统一异常处理 C#总结(一)AutoResetEvent的使用介绍(用AutoResetEvent实现同步) C#总结(二)事件Event 介绍总结 C#总结(三)DataGridView增加全选列 Web API系列(二)接口安全和参数校验 RabbitMQ学习系列(六): RabbitMQ 高可用集群
Redis总结(五)缓存雪崩和缓存穿透等问题 前面讲过一些redis 缓存的使用和数据持久化.感兴趣的朋友可以看看之前的文章,http://www.cnblogs.com/zhangweizhon ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- rabbitmq+ keepalived+haproxy高可用集群详细命令
公司要用rabbitmq研究了两周,特把 rabbitmq 高可用的研究成果备下 后续会更新封装的类库 安装erlang wget http://www.gelou.me/yum/erlang-18. ...
- 搭建 RabbitMQ Server 高可用集群
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
- 搭建 RabbitMQ Server 高可用集群【转】
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
随机推荐
- 原生Ajax XMLHttpRequest对象
一.Ajax请求 - 现在常见的前后端分离项目中,一般都是服务器返回静态页面后浏览器加载完页面,运行script中的js代码,通过ajax向后端api发送异步请求获取数据,然后调用回调函数,将数据添加 ...
- mysql之优化(2)
1.选取最适用的字段属性MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可 ...
- golang运算与循环等
一.golang运算符 1.算术运算符 + 相加- 相减* 相乘/ 相除% 求余++ 自增-- 自减 2.关系运算符 == 等于!= 不等于> 大于< 小于>= 大于等于<= ...
- Ajax提交表单初接触
<!doctype html> <html class="no-js"> <head> <meta charset="utf-8 ...
- MyBatis基础:MyBatis调用存储过程(6)
1. 存储过程准备 CREATE PROCEDURE sp_task ( IN userId INT ) BEGIN SELECT * FROM task WHERE user_id = userId ...
- 基于HA机制的Nginx配置实现
Keepalived是一个基于VRRP协议来实现服务高可用方案.下载地址:http://www.keepalived.org/ keepalived-1.2.24.tar.gz VRRP协议:虚拟路由 ...
- Civil 3D .NET二次开发第11章代码升级至2018版注意事项
原来涉及2017的,均需要改为2018 原来的21改为22 代码中AeccXUiLand.AeccApplication.11.0"改为AeccXUiLand.AeccApplication ...
- class09
class09 四川菜很辣. Sichuan cuisine is very spicy. 那个汤是凉的. That soup is cold. 这茶很烫. This tea is very hot. ...
- (转)史上最全 40 道 Dubbo 面试题及答案,看完碾压面试官!
背景:因为自己的简历写了dubbo,面试时候经常被问到.实际自己对dubbo的认识只停留在使用阶段,所以有必要好好补充下基础的理论知识. https://zhuanlan.zhihu.com/p/45 ...
- 一.Django 学习 —— 环境搭建
Ⅰ.前言 Django是一个开放源代码的Web应用框架,由Python写成.采用了MVC的框架模式,即模型M,视图V和控制器C. 我们先搭建一个Django项目运行的环境. 需要准备的有: 1- Py ...