MapReduce的工作原理
MapReduce简介
MapReduce有哪些角色?各自的作用是什么?
MapReduce程序执行流程
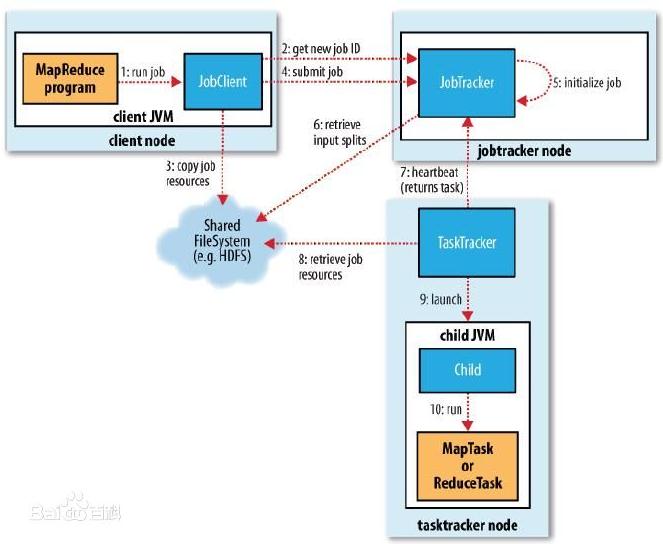
MapReduce工作原理
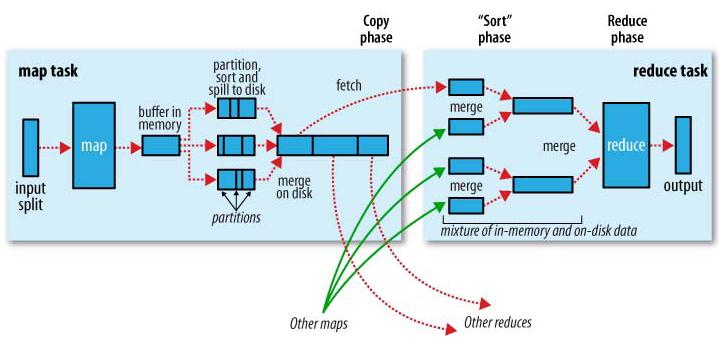
reduce task
MapReduce中Shuffle过程


MapReduce编程主要组件
针对MapReduce的缺点,YARN解决了什么?
MapReduce的工作原理的更多相关文章
- Hadoop 4、Hadoop MapReduce的工作原理
一.MapReduce的概念 MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框就是mapreduce,两者缺一不可,也就是 ...
- Hadoop基础-MapReduce的工作原理第二弹
Hadoop基础-MapReduce的工作原理第二弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Split(切片) 1>.MapReduce处理的单位(切片) 想必 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- MapReduce 1工作原理图文详解
MapReduce工作原理图文详解 一 MapReduce程序执行流程 程序执行流程图如下: 流程分析:1.在客户端启动一个作业.2.向JobTracker请求一个Job ID.3.将运行作业所需要的 ...
- 【hadoop】细读MapReduce的工作原理
前言:中秋节有事外加休息了一天,今天晚上重新拾起Hadoop,但感觉自己有点烦躁,不知后续怎么选择学习Hadoop的方法. 干脆打开电脑,决定: 1.先将Hadoop的MapReduce和Yarn基本 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
随机推荐
- Mvc Swagger报错的解决办法。
报错信息:Not supported by Swagger 2.0: Multiple operations with path ‘xxxx.aspx’ and method 'POST' 解决办法出 ...
- zimbra6同域名与同hostname与同系统异机恢复
系统:redhat5.4_64 安装DNS:[root@test6 ~]# yum install bind -y[root@test6 ~]# yum install bind-chroot -y[ ...
- AES加密解密算法
class Aes { /** * AES加密 * @param $data * @param $secret_key * @return string */ public static functi ...
- 一篇文章搞懂Android组件化
网上组件化的文章很多,我本人学习组建化的过程也借鉴了网上先辈们的文章.但大多数文章都从底层的细枝末节开始讲述,由下而上给人一种这门技术“博大精深”望而生畏的感觉.而我写这篇文章的初衷就是由上而下,希望 ...
- Eclipse:An error has occurred. See error log for more details. java.lang.NullPointerException
问题描述 在使用 Eclipse Clean 项目时报错:An error has occurred. See error log for more details. java.lang.Null ...
- pip安装mysql-python报错:Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-install-enRreC/mysql-python/
公司业务开发,用python开发网站;需要使用模块MySQLdb. 我直接pip install MySQLdb,当然不成功了,模块名字因该是mysql-python pip install mysq ...
- ELK搭建<一>:搭建ES集群
1.首先进入官网下载ES,如果下载最新之前的版本 点击past releases就行了. 2.解压后进入config修改配置文件elasticsearch.yml #集群名称 cluster.name ...
- swoole框架基本总结
框架-Swoole扩展-Swoole文档中心 http://wiki.swoole.com/wiki/page/p-framework.html swoole有两个部分. 一个是PHP扩展,用C开发的 ...
- 检查linux版本命令
lsb_release -a cat /etc/issue cat /proc/version uname -a cat /etc/redhat-release
- android调试工具 adb命令学习
查看Android版本号 adb shell getprop ro.build.version.release getprop ro.build.version.release 5.1 查看Andro ...