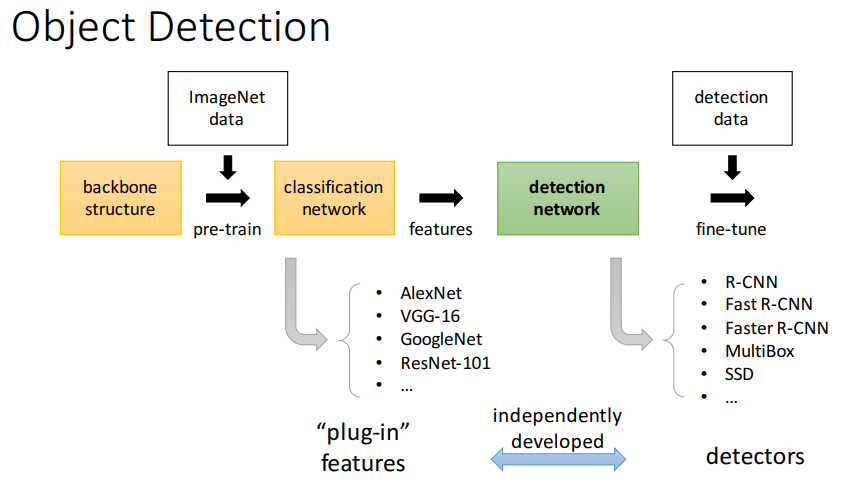
[Localization] R-CNN series for Localization and Detection
CS231n Winter 2016: Lecture 8 : Localization and Detection
CS231n Winter 2017: Lecture 11: Detection and Segmentation
https://zhuanlan.zhihu.com/qianxiaosi
本篇整理得比较杂,毕竟这一块小知识点较多,故,这里只是笔记收集,暂且不能称之为笔记整理。
以下三篇博文读来甚好,推荐:
概念的理解很重要,读下文,推荐:
CNN架构基础:
From: Lecture 9 | CNN Architectures

"小姑娘,很可爱"
Link: http://image-net.org/explore
![]()
Link: http://cocodataset.org/#home

几种常见网络结构:

Ref: The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
这张图的表述比较清晰:http://icml.cc/2016/tutorials/icml2016_tutorial_deep_residual_networks_kaiminghe.pdf
Ref: [Localization] Localization and Detection
但在此有必要单独对该网络做些了解,开始进入正题。
好喜欢的一堂课,充分体现了“实践出真知”。

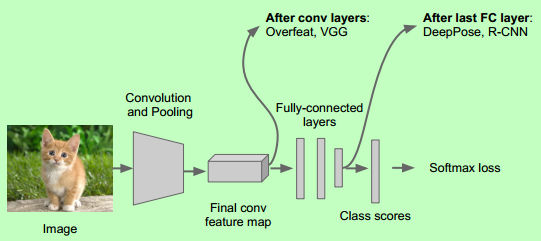
Classification + Localization
Idea #1: Localization as Regression
Step 1: Train (or download) a classification model (AlexNet, VGG, GoogLeNet).
Step 2: Attach new fully-connected “regression head” to the network.

Step 3: Train the regression head only with SGD and L2 loss.
Step 4: At test time use both heads.
这算是两个“终端”,那么分叉点设置在哪里?常见的是两个地方,如下:
以上这个就算是一个用于“识别” + “定位”的基本框架。
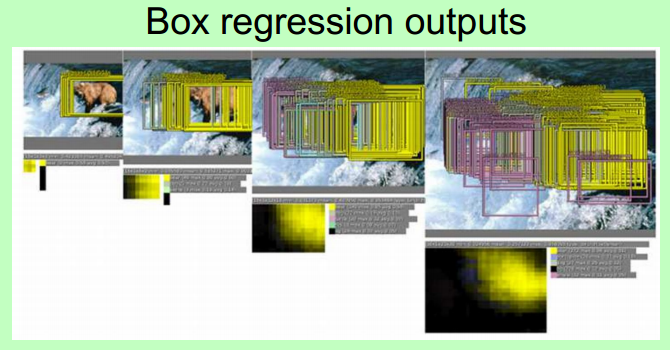
Idea #2: Sliding Window
这个图,基本能体现该idea的思想。
Efficient Sliding Window: Overfeat 【可以了解下相关的Model arch】
Winner of ILSVRC 2013 localization challenge
Sermanet et al, “Integrated Recognition, Localization and Detection using Convolutional Networks”, ICLR 2014
理解:Efficient sliding window by converting fullyconnected layers into convolutions. 全连接转变为(看作是)卷积

基本原理:
1x1 denotes 1x1x4096
下面是另一个不同尺寸大小的图片,可见计算量与上一个14x14相当(只是多了黄色区域的计算),但只有全连接情况下用时的1/4。

VGG基本上只是用了比Overfeat更深的网络。
ResNet用了一个RPN(Region Proposal Network)的定位方式。

Object Detection
思路:用分类来代替回归,但窗口大小的确定等问题比较麻烦。
行人检测
Histogram of Oriented Gradients 方向梯度直方图
对应的深度模型是:Deformable Parts Model (DPM)
可以只检测感兴趣的(出现可能性大的)区域
Region Proposal: Selective Search
从像素出发,把具有相似颜色和纹理的相邻像素进行合并 --> 块状区域。

R-CNN
整合上述方法
已有“检测方法 + cnn分类器” --> R-CNN (2014) 【基于区域的CNN分类方法】
目标识别基本知识:【指标:mAP and IoU】
Ref: https://zhuanlan.zhihu.com/p/21533724
ResNet也放进来,是因为有效的特征对于目标检测领域是极为重要的。
在目标检测中,以下几个指标非常重要:(a)识别精度;(b)识别效率;(c)定位准确性。
一、识别精度
说起识别精度,不得不提目标检测中衡量检测精度的指标mAP(mean average precision)。简单来讲就是在多个类别的检测中,每一个类别都可以根据recall和precision绘制一条曲线,那么AP就是该曲线下的面积,而mAP是多个类别AP的平均值,这个值介于0到1之间,且越大越好。具有代表性的工作是ResNet、ION和HyperNet。
ResNet:何凯明的代表作之一,获得了今年的best paper。文章不是针对目标检测来做的,但其解决了一个最根本的问题:更有力的特征。
检测时基于Faster R-CNN的目标检测框架,使用ResNet替换VGG16网络可以取得更好的检测结果。【毕竟是多人投票机制】
二、识别效率
YOLO:这是今年的oral。这个工作在识别效率方面的优势很明显,可以做到每秒钟45帧图像,处理视频是完全没有问题的。
YOLO最大贡献是提出了一种全新的检测框架——直接利用CNN的全局特征预测每个位置可能的目标,相比于R-CNN系列的region proposal+CNN 这种两阶段的处理办法可以大大提高检测速度。
今年新出来的SSD[11]方法虽然在识别率上边有了很大的提升,但YOLO的先驱作用是显而易见的。【看来前者比后者是质的提升,出来了YOLO2】
三、准确性
在目标检测的评价体系中,有一个参数叫做IoU,简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率。
在Pascal VOC中,这个值为0.5。而2014年以来出现的MS COCO竞赛规则把这个IoU变成了0.5-1.0之间的综合评价值,也就是说,定位越准确,其得分越高,这也侧面反映了目标检测在评价指标方面的不断进步。
目标分类嫁接目标识别:
Ref: https://www.zhihu.com/question/35887527
如果都用一句话来描述:
* RCNN 解决的是,“为什么不用CNN做classification呢?”
(但是这个方法相当于过一遍network出bounding box,再过另一个出label,原文写的很不“elegant”
* Fast-RCNN 解决的是,“为什么不一起输出bounding box和label呢?”
(但是这个时候用selective search generate regional proposal的时间实在太长了
* Faster-RCNN 解决的是,“为什么还要用selective search呢?”
于是就达到了real-time。开山之作确实是开山之作,但是也是顺应了“Deep learning 搞一切vision”这一潮流吧。
传统的detection主流方法是DPM(Deformable parts models), 在VOC2007上能到43%的mAP,虽然DPM和CNN看起来差别很大,但RBG大神说“Deformable Part Models are Convolutional Neural Networks”(http://arxiv.org/abs/1409.5403)。
CNN流行之后,Szegedy做过将detection问题作为回归问题的尝试(Deep Neural Networks for Object Detection),但是效果差强人意,在VOC2007上mAP只有30.5%。
既然回归方法效果不好,而CNN在分类问题上效果很好,那么为什么不把detection问题转化为分类问题呢?
- RBG的RCNN使用region proposal(具体用的是Selective Search Koen van de Sande: Segmentation as Selective Search for Object Recognition)来得到有可能得到是object的若干(大概10^3量级)图像局部区域,
- 然后把这些区域分别输入到CNN中,得到区域的feature,
- 再在feature上加上分类器,判断feature对应的区域是属于具体某类object还是背景。
当然,RBG还用了区域对应的feature做了针对boundingbox的回归,用来修正预测的boundingbox的位置。RCNN在VOC2007上的mAP是58%左右。
RCNN存在着重复计算的问题(proposal的region有几千个,多数都是互相重叠,重叠部分会被多次重复提取feature),于是RBG借鉴Kaiming He的SPP-net的思路单枪匹马搞出了Fast-RCNN,跟RCNN最大区别就是Fast-RCNN将proposal的region映射到CNN的最后一层conv layer的feature map上,这样一张图片只需要提取一次feature,大大提高了速度,也由于流程的整合以及其他原因,在VOC2007上的mAP也提高到了68%。
探索是无止境的。Fast-RCNN的速度瓶颈在Region proposal上,于是RBG和Kaiming He一帮人将Region proposal也交给CNN来做,提出了Faster-RCNN。Fater-RCNN中的region proposal netwrok实质是一个Fast-RCNN,这个Fast-RCNN输入的region proposal的是固定的(把一张图片划分成n*n个区域,每个区域给出9个不同ratio和scale的proposal),输出的是对输入的固定proposal是属于背景还是前景的判断和对齐位置的修正(regression)。Region proposal network的输出再输入第二个Fast-RCNN做更精细的分类和Boundingbox的位置修正。Fater-RCNN速度更快了,而且用VGG net作为feature extractor时在VOC2007上mAP能到73%。
个人觉得制约RCNN框架内的方法精度提升的瓶颈是将dectection问题转化成了对图片局部区域的分类问题后,不能充分利用图片局部object在整个图片中的context信息。可能RBG也意识到了这一点,所以他最新的一篇文章YOLO(http://arxiv.org/abs/1506.02640)又回到了regression的方法下,这个方法效果很好,在VOC2007上mAP能到63.4%,而且速度非常快,能达到对视频的实时处理(油管视频:https://www.youtube.com/channel/UC7ev3hNVkx4DzZ3LO19oebg),虽然不如Fast-RCNN,但是比传统的实时方法精度提升了太多,而且我觉得还有提升空间。
学习路径:R-CNN--> Fast R-CNN --> Faster R-CNN --> YOLO --> mobileNet with SSD
- 基于region proposal的RCNN系列:RCNN、Fast RCNN、Faster RCNN,
- 基于区域划分的YOLO、SSD,
- 基于强化学习的AttentionNet等,
- 还有最新的Mask RCNN
开始RCNN - 目标检测(2)RCNN
RCNN另辟蹊径,既然我们无法使用卷积特征滑窗,那我们通过区域建议方法产生一系列的区域,然后直接使用CNN去分类这些区域是目标还是背景不就可以吗?
当然这样做也会面临很多的问题,不过这个思路正是RCNN的核心。因此RCNN全称为Regions with CNN features。
R-CNN Arch.

R-CNN Training
Step 1: Train (or download) a classification model for ImageNet (AlexNet)
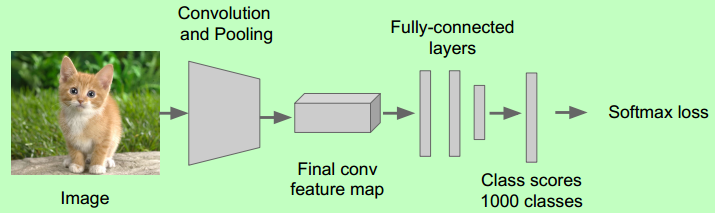
Step 2: Fine-tune model for detection
- Instead of 1000 ImageNet classes, want 20 object classes + background 【自定义识别自己需要的20个新目标】
- Throw away final fully-connected layer, reinitialize from scratch
- Keep training model using positive / negative regions from detection images

Step 3: Extract features
- Extract region proposals for all images 【产生目标区域候选:直接使用Selective Search,选择2K个置信度最高的区域候选】
- For each region: warp to CNN input size, run forward through CNN, save pool5 features to disk
- Have a big hard drive: features are ~200GB for PASCAL dataset!
贪婪非极大值抑制
由于有多达2K个区域候选,我们如何筛选得到最后的区域呢?
R-CNN使用贪婪非极大值抑制的方法,假设ABCDEF五个区域候选,
- 首先根据概率从大到小排列。假设为FABCDE。
- 然后从最大的F开始,计算F与ABCDE是否IoU是否超过某个阈值,如果超过则将ABC舍弃。
- 然后再从D开始,直到集合为空。
而这个阈值是筛选得到的,通过这种处理之后一般只会剩下几个区域候选了。
CNN目标特征提取
RCNN使用ImageNet的有标签数据进行有监督的预训练,然后再在本数据集上微调最后一层全连接层。直到现在,这种方法已经成为CNN初始化的标准化方法。
但是训练CNN的样本量还是不能少的,因此RCNN将正样本定义的很宽松,为了尽可能获取最多的正样本,RCNN将IOU>0.5(IoU 指重叠程度,计算公式为:A∩B/A∪B)的样本都称为正样本。
每次迭代:批大小为128,其中正样本个数为32,负样本为96。其实这种设置是偏向于正样本的,因为正样本的数量实在是太少了。
由于CNN需要固定大小的输入,因此对于每一个区域候选,首先将其防缩至227*227,然后通过CNN提取特征。
选择哪一层作为特征提取层呢?RCNN进行了宽泛的实验,最终选择的fc层。如下图所示。

Step 4: Train one binary SVM per class to classify region features
目标种类分类器
Ref: https://www.zhihu.com/question/54117650

在通过CNN提取区域候选的特征后,R-CNN对于每个种类训练SVM用以分类这些特征具体属于哪个种类。
但是这里面的样本确定和CNN中的样本也是不一样的,因为CNN需要大量的样本去驱动特征提取,因此正样本的阈值比较低。
而SVM适合小样本的分类,通过反复的实验,RCNN的SVM训练将ground truth样本作为正样本,而IOU>0.3的样本作为负样本,这样也是SVM困难样本挖掘的方法。
Step 5 (bbox regression): For each class, train a linear regression model to map from cached features to offsets to GT boxes to make up for “slightly wrong” proposals
BoundingBox回归
为了进一步提高定位的准确率,R-CNN在贪婪非极大值抑制后进行BoundingBox回归,进一步微调BoundingBox的位置。
不同于DPM的BoundingBox回归,RCNN是在Pool5层进行的回归。而BoundingBox是类别相关的,也就是不同类的BoundingBox回归的参数是不同的。
Fast R-CNN
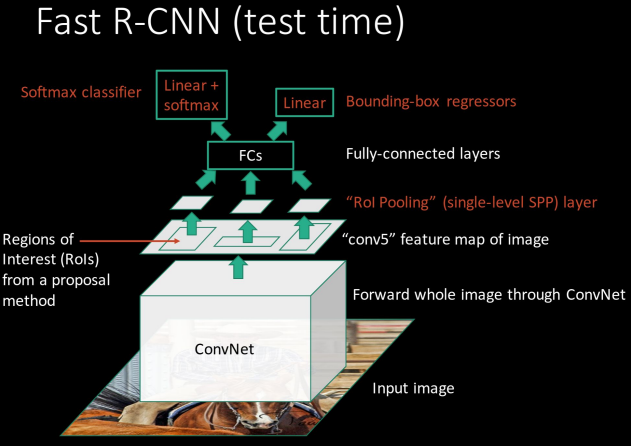
Ref: 【目标检测】Faster RCNN算法详解【值得一读】
Background
Fast RCNN方法解决了RCNN方法三个问题:
问题一:测试时速度慢
RCNN一张图像内候选框之间大量重叠,提取特征操作冗余。
本文将整张图像归一化后直接送入深度网络。在邻接时,才加入候选框信息,在末尾的少数几层处理每个候选框。
问题二:训练时速度慢
原因同上。
在训练时,本文先将一张图像送入网络,紧接着送入从这幅图像上提取出的候选区域。这些候选区域的前几层特征不需要再重复计算。
问题三:训练所需空间大
RCNN中独立的分类器和回归器需要大量特征作为训练样本。
本文把类别判断和位置精调统一用深度网络实现,不再需要额外存储。
以下按次序介绍三个问题对应的解决方法。
学习SPPNet有进一步理解有帮助:
- https://wenku.baidu.com/view/c797106cff4733687e21af45b307e87101f6f8fd.html
- https://zhuanlan.zhihu.com/p/27485018
无论是RCNN还是SPPNet,其训练都是多阶段的。
- 首先通过ImageNet预训练网络模型,
- 然后通过检测数据集微调模型提取每个区域候选的特征,
- 之后通过SVM分类每个区域候选的种类,
- 最后通过区域回归,精细化每个区域的具体位置。
为了避免多阶段训练,同时在单阶段训练中提升识别准确率,Fast RCNN提出了多任务目标函数,将SVM分类以及区域回归的部分纳入了卷积神经网络中。
- Selective search
selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。
既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。
最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个,不然总是产生那么多你也用不完不是吗?好了这就是整篇文章的思路了,那我们一点点去看。
然后通过颜色、纹理等打分。
但是还是需要重复为每个region proposal提取特征啊,能不能我们直接根据region proposal定位到它在卷积层特征的位置,然后直接对于这部分特征处理呢?
如何从一个region proposal 映射到feature map的位置?
SPPNet通过角点尽量将图像像素映射到feature map感受野的中央,假设每一层的padding都是p/2,p为卷积核大小。
对于feature map的一个像素(x',y'),其实际感受野为:(Sx‘,Sy’),其中S为之前所有层步伐的乘积。
然后对于region proposal的位置,我们获取左上右下两个点对应的feature map的位置,然后取特征就好了。
左上角映射为:
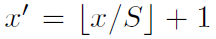
右下角映射为:
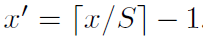
当然,如果padding大小不一致,那么就需要计算相应的偏移值啦。
进入正题
网络结构
Ref: http://blog.csdn.net/shenxiaolu1984/article/details/51036677
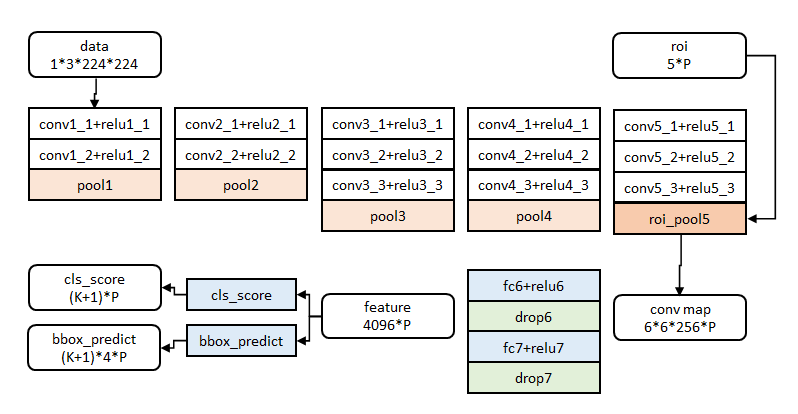

类似于RCNN,Fast RCNN思路:
- 首先通过Selective Search产生一系列的区域候选,
- 然后通过通过CNN提取每个区域候选的特征,
- 之后训练分类网络以及区域回归网络。
对比SPPNet,我们可以看出Fast RCNN的区别所在,首先是将SPP换成了ROI Poling。
ROI Poling可以看作是空间金字塔池化的简化版本,它通过将区域候选对应的卷积层特征还分为H*W个块,然后在每个块上进行最大池化就好了。
每个块的划分也简单粗暴,直接使用卷积特征尺寸除块的数目就可以了。空间金字塔池化的特征是多尺寸的,而ROI Pooling是单一尺度的。而对于H*W的设定也是参照网络Pooling层的,例如对于VGG-19,网络全连接层输入是7*7*512,因此对应于我们的H,W就分别设置为(7,7)就可以了。
另外一点不同在于网络的输出端,无论是SPPNet还是RCNN,CNN网络都是仅用于特征提取,因此输出端只有网络类别的概率。而Fast RCNN的网络输出是包含区域回归的。
- 网络初始化
网络初始化当然还是经典的方法啦,首先更改网络的结构,将最后一层池化层替换为ROI Pooling层,然后设置ROI Pooling层的参数,也就是使得H,W匹配全连接层的输入要求。
然后将网络的输出改为两个子网络,一个用以分类一个用于回归。
最后更改网络的输入,网络的输入是图片集合以及ROI的集合。
- 为什么SPPNet的误差不能够反向传播到池化层之前的卷积等层?
主要原因是SPPNet在训练时每个批次的样本是来自于不同的图像,而空间金字塔池化的感受野又特别的大,一般是整幅图片,因此无论是前向传播还是反向传播误差都要经过一整副图片,效率特别慢,也无法进行权重更新。
而本文使用的方法是对于同一批次的图片,尽量选用来自同一幅图片的不同区域。比如每个批大小为128,其中64副来自同一幅图片。这样做的好处是相比于SPPNet,我们的训练速度大约能提高64倍。
为什么以前这些网络都不这样干呢?如果做过深度学习的调参就能知道,如果一个批次里的图片都来自同一个类,网络的收敛速度会很慢。
- 而作者发现,他们这样干,收敛速度也很快。我觉得一方面原因是因为BatchSize挺大的,本文将BatchSize设置为128。
- 另一方面,同一幅图片的不同区域候选很可能来在不同的类别,比如网络示意图中的图片,包含了马、人、帽子等等。
- 多任务损失函数
Fast RCNN将分类与回归做到了一个网络里面,因此损失函数必定是多任务的:
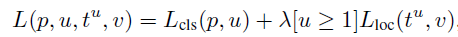
其中分类任务还是我们常用的对数损失,的定义方式与RCNN中一致,为中心区域坐标,以及区域宽度及高度。但是使用的损失函数不同,Fast RCNN使用的损失函数为鲁棒性的L1损失函数,而非RCNN中试用的L2损失函数,而且训练的过程也简单很多,需要注意的每个区域候选对于每个类都有区域回归训练。
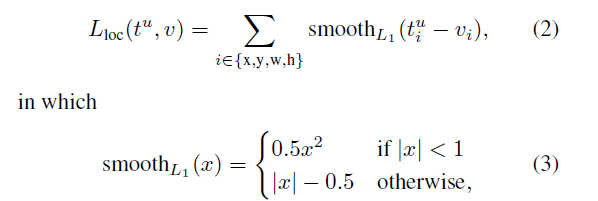
- Mini-Batch 采样
Mini-Batch的设置基本上与SPPNet是一致的,不同的在于128副图片中,仅来自于两幅图片。其中25%的样本为正样本,也就是IOU大于0.5的,其他样本为负样本,同样使用了困难负样本挖掘的方法,也就是负样本的IOU区间为[0.1,0.5),负样本的u=0,函数为艾弗森指示函数,意思是如果是背景的话我们就不进行区域回归了。在训练的时候,每个区域候选都有一个正确的标签以及正确的位置作为监督信息。
- ROI Pooling的反向传播
不同于SPPNet,我们的ROI Pooling是可以反向传播的,让我们考虑下正常的Pooling层是如何反向传播的,以Max Pooling为例,根据链式法则,对于最大位置的神经元偏导数为1,对于其他神经元偏导数为0。ROI Pooling 不用于常规Pooling,因为很多的区域建议的感受野可能是相同的或者是重叠的,因此在一个Batch_Size内,我们需要对于这些重叠的神经元偏导数进行求和,然后反向传播回去就好啦。
- 多尺度训练
这一点和SPPNet都是相同的,主要是对图片进行放缩,使得短边在一个区间内,然后对于每一个ROI,找到使其对应的原始图像面积接近224*224个像素的尺寸。
- 哪些层是需要学习的?(因为之前有预训练)

由于我们使用了更深的网络VGG16,因此作者觉得仅仅是微调最后的全连接层是不够的,因此尝试去微调其他的网络层,并进行了对比试验。
发现,卷积层2_1之前一般是通用任务相关的,不需要再去学习了,而学习卷积层2_1之后的其他网络层显得至关重要,将识别准确率从61.4提高到了67.2。
- SVM与SoftMax的比较
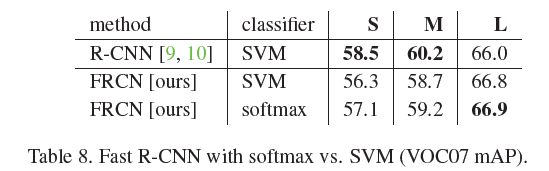
此前在RCNN中,我们了解到了不能够使用CNN中的样本定义方式去训练SVM,是因为两个分类器对于样本的需求是不同的。因此直接使用Fast RCNN的训练样本去训练SVM也是不公平的,
因此作者通过R-CNN中SVM的训练方式和参数设计对比SVM和SoftMax的结果,发现softMax结果优于SVM 0.1-0.8,也就是说将分类及回归放到一个网络中去做,并没有影响到网络的精度。
- 识别结果对比
首先是速度上的优势,相比于SPPNet,Fast RCNN训练速度快3倍,测试速度快10倍,精度更高。相比于RCNN,Fast RCNN训练速度快9倍,测试速度快213倍。
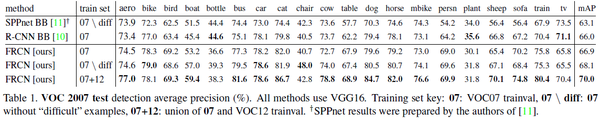
在速度提高的同时,精度也是不俗的表现哦,可以看到Fast RCNN在VOC 2007库上取得了68.1的MAP,相比于SPPNet的66.0提高2.1%。
- 存在的不足
现在的Fast RCNN模型已经接近完美了,识别检测全部放到了卷积神经网络的框架里面,速度也是相当的快。美中不足的是,区域建议网络还是Selective Search,网络其他部分都能在GPU中运行,而这部分需要在CPU中运行,有点拖后腿啊。接下来的Faster RCNN已经弥补了这个问题。
Faster R-CNN
直到最终版本Faster RCNN可以说是近乎完美的目标检测模型,网络优美,速度快。
github地址:rbgirshick/py-faster-rcnn
论文地址:Towards Real-Time Object Detection with Region Proposal Networks
RCNN:目标检测(2)-RCNN - 知乎专栏
Fast RCNN:目标检测(4)-Fast R-CNN - 知乎专栏
摘要
Fast R-CNN提到如果去除区域建议算法的话,网络能够接近实时,而selective search方法进行区域建议的时间一般在秒级。产生差异的原因在于卷积神经网络部分运行在GPU上,而selective search运行在CPU上,所以效率自然是不可同日而语。
一种可以想到的解决策略是将selective search通过GPU实现一遍,但是这种实现方式忽略了接下来的检测网络可以与区域建议方法共享计算的问题。
因此Faster RCNN从提高区域建议的速度出发提出了region proposal network 用以通过GPU实现快速的区域建议。通过共享卷积,RPN在测试时的速度约为10ms,相比于selective search的秒级简直可以忽略不计。
- Faster RCNN整体结构为RPN网络产生区域建议,
- 然后直接传递给Fast RCNN。
当然重点就是这个RPN网络咯,我们看看RPN如何产生区域候选。下图是Faster RCNN的整体网络结构:

对于一幅图片的处理流程为:图片-->卷积特征提取-->RPN产生proposals-->Fast RCNN分类proposals。
区域建议的产生
在目标检测领域,区域建议与后续的检测往往是分开进行的,而对于区域建议算法一般分为两类:
- 基于超像素合并的(selective search、CPMC、MCG等),
- 基于滑窗算法的,也就是我们在selective search一文中提到的穷举法。
自从卷积网络出现后,滑窗也自然高级了一点,比如说可以在卷积特征层上滑窗,由于卷积特征层一般很小,所以得到的滑窗数目也少很多。但是产生的滑窗准确度也就差了很多,毕竟感受野也相应大了很多。
Faster RCNN的做法是,既然区域建议的精度不够,给每一个region再来个回归得到更加精细化的位置就是咯。
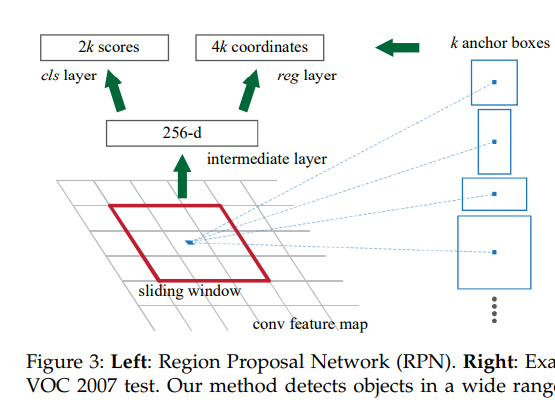
RPN对于feature map的每个位置进行滑窗,通过不同尺度以及不同比例的K个anchor产生K个256维的向量,然后分类每一个region是否包含目标以及通过回归得到目标的具体位置。
- 这里使用的滑窗大小为
,感觉很小,但是其相对于原图片的感受野约为200左右个像素。
- anchor box的作用是产生不同比例及尺度的region proposal,通过将anchor中心点与滑窗中心点对齐,然后以一定的比例及大小裁剪滑窗。比如裁剪一个512*512的大小,比例为1:2的滑窗实现就是对于滑窗中心点向外扩充像素使得对应原图包含的像素点个数为512*512,比例为1:2。然后对于这一块进行卷积提取固定维度的特征。
- RPN是一个全卷积神经网络的结构,也就是将全连接层通过卷积层去替换(我将在下一篇文章里面写FCN)。因此可以接受任意大小的输入,同时输出所有的anchors对应的特征。实验细节部分会详细说这一点。
- 由于采用的是滑窗的方式,因此全连接层(上图获得256-d向量的位置)是共享权重的,每个滑窗的权重都是相同的。其实现方式是通过
- 这里使用的滑窗大小为
多尺度样本的产生
由于目标检测的目标尺度可能相差很大,因此我们需要尽可能产生不同尺寸的region proposals,常见的有两种方法,加上本文的一共三种方法:
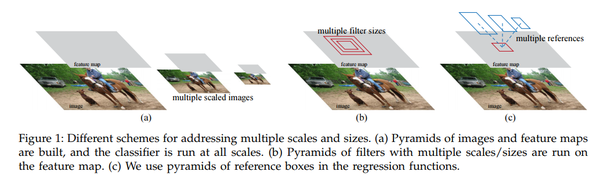
- 图像金字塔:通过将图像放缩到不同的尺寸,然后提取特征去做。有点类似于RCNN中的实现方式,显然这样需要为每一个尺寸重复提取卷积特征,成本很高。
- 卷积特征金字塔:先对于图像提取卷积特征,然后将卷积特征放缩到不同的尺寸。类似于SPP的实现方式。在SPP中我们也看到,这里面的图像也需要放缩到几种尺寸,产生多尺度结果。
- anchor金字塔:通过不同尺度的anchor在卷积特征上滑窗相当于是anchor金字塔,不需要图像有多个尺寸,仅需要有多个尺寸的anchor就好了。文章使用了3种尺度以及3种比例。
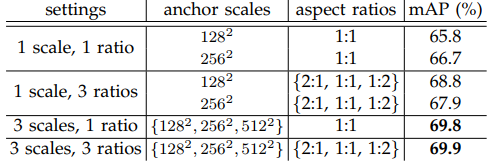
感觉区域大小很重要,3尺寸的1比例与3比例相差很小,因为比例准不准没关系,后面还有回归层去微调呢,但是如果尺寸不够那回归层就无能为力了。
损失函数的设计
RPN包含两个网络分支,分类层以及回归层。
- 分类层给出一个二分类label,也就是这个region是否包含目标,
- 回归层产生目标的位置。
其中与任意ground-truth box的IOU大于0.7即认为是包含目标的,而对于任意ground-truth box的IOU都小于0.3则认为是负样本。对于回归采用的与Fast RCNN一致。
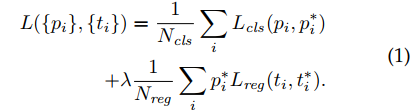
通过Ncls,Nreg,权衡分类以及回归的重要性程度。这里面一切都与Fast RCNN类似,那我们就只用看不同的地方就好了。
- 分类损失一个是二分类,一个是类别相关的分类。
- 回归损失一个是非类别相关的,Fast RCNN是类别相关的。
- Fast RCNN ROI pooling后面跟着两个FC然后再到相应的分类或是回归,RPN则是一个全卷积的过程,包括对于后续的向量全连接操作都是通过
卷积实现的。而且无论回归还是分类从256-d向量到后面都只有一个卷积层。
- 9个anchor的参数不共享,但是每个滑窗位置的参数是共享的。
RPN的训练过程
- RPN可以通过BP算法端到端训练,为了防止类似样本向负样本倾斜,我们在每一个批次中采样256个anchors,然后这些anchors中正负样本比例为1:1。
- RPN与Fast RCNN权重共享训练
文章使用的四步交替训练的方法:
- 通过预训练模型初始化RPN网络,然后训练RPN。
- 通过预训练模型初始化Fast RCNN,并使用RPN产生的proposal训练RPN。
- 通过Fast RCNN初始化RPN中与其共有的网络层,然后固定这些层训练其他层。
- 固定Fast RCNN中的共有层,通过RPN训练Fast RCNN。
实验细节
文章对于图像的预处理是放缩使得短边为600个像素,以VGG为例,经过四次的池化操作,每个卷积层像素的感受野对应于原图为16个像素。对于1000*600的图片,其卷积特征层尺寸为60*40,所以anchors数量为60*40*9,而去除在边缘的不完整的anchors,最后能得到6000个anchors,而这些anchors的特征是同时计算出来的。比如针对一个图像尺寸128*128,其对应于卷积层特征尺寸为9*9,然后对于所有的9*9小块进行卷积得到的feature map就是所有的anchor对应的特征。RPN产生的region proposal重叠较多,通过NMS去除重叠后大约剩余2K个proposal,在测试时仅选用前300个proposal,效果也是相当的好。
- 不同尺度的anchors对应的真实的proposal大小
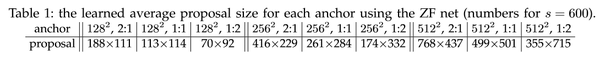
可以看到,我们的尺寸和比例还是起到了作用的,相应尺寸和比例的proposal也基本符合要求的。
- proposal个数

可以看到300个proposal其实并没有降低识别准确率,而且NMS对结果也没啥影响,所以测试时取前300个proposal,这样可以大幅提高速度。
- 分阶段权重共享的优点
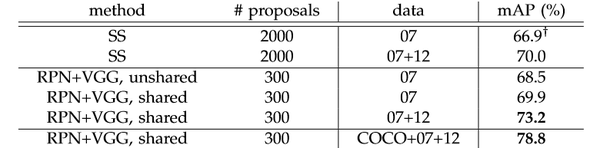
权重共享大约能够提升个1.5个百分点,还是很有效果的。同时我们也看到数据集扩充对于识别结果影响最大,通过COCO+07+12训练然后再07上测试能够达到78.8%,提高10个点。
- 时间性能

通过ZF基本可以实现实时的,所以文章标题也是朝着实时目标检测迈进嘛~
总结
至此,可以说RCNN目标检测系列已经是相当的完美了,无论是结果还是效率都可以商用了。但是网络的通用性不太好,在最新的网络比如Inception、ResNet系列直接套用Faster RCNN是不合适的,如何使用这些新的网络呢?接下来我们将研究FCN、RFCN这两个方法。
【没怎么看透,还需要时日】
其他链接:
Code:
R-CNN
(Cafffe + MATLAB): https://github.com/rbgirshick/rcnn
Probably don’t use this; too slow
Fast R-CNN
(Caffe + MATLAB): https://github.com/rbgirshick/fast-rcnn
Faster R-CNN
(Caffe + MATLAB): https://github.com/ShaoqingRen/faster_rcnn
(Caffe + Python): https://github.com/rbgirshick/py-faster-rcnn
YOLO
http://pjreddie.com/darknet/yolo/
[Localization] R-CNN series for Localization and Detection的更多相关文章
- 【CV】CVPR2015_A Discriminative CNN Video Representation for Event Detection
A Discriminative CNN Video Representation for Event Detection Note here: it's a learning note on the ...
- PP: Time series clustering via community detection in Networks
Improvement can be done in fulture:1. the algorithm of constructing network from distance matrix. 2. ...
- 论文笔记之:Active Object Localization with Deep Reinforcement Learning
Active Object Localization with Deep Reinforcement Learning ICCV 2015 最近Deep Reinforcement Learning算 ...
- iOS Programming Localization 本地化
iOS Programming Localization 本地化 Internationalization is making sure your native cultural informatio ...
- ### Paper about Event Detection
Paper about Event Detection. #@author: gr #@date: 2014-03-15 #@email: forgerui@gmail.com 看一些相关的论文. 1 ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- object detection[NMS]
非极大抑制,是在对象检测中用的较为频繁的方法,当在一个对象区域,框出了很多框,那么如下图: 上图来自这里 目的就是为了在这些框中找到最适合的那个框.有以下几种方式: 1 nms 2 soft-nms ...
- Image Processing and Analysis_8_Edge Detection:Edge and line oriented contour detection State of the art ——2011
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- 【翻译】Awesome R资源大全中文版来了,全球最火的R工具包一网打尽,超过300+工具,还在等什么?
0.前言 虽然很早就知道R被微软收购,也很早知道R在统计分析处理方面很强大,开始一直没有行动过...直到 直到12月初在微软技术大会,看到我软的工程师演示R的使用,我就震惊了,然后最近在网上到处了解和 ...
随机推荐
- 淘宝bug bug bug
手机淘宝(苹果版)出现了一个挺耀眼的bug...... 待评价有九个,如图 点进去评价6个之后,还有三个 再出来,待评价还是有九个. 重新打开,下拉刷新都不能改变
- iOS11适配
链接: 你可能需要为你的 APP 适配 iOS 11 iOS11新特性,如何适配iOS11 App界面适配iOS11(包括iPhoneX的奇葩尺寸) iOS 11 安全区域适配总结 iOS 11 sa ...
- Linux设置和查看环境变量的方法 详解
1. 显示环境变量HOME $ echo $HOME /home/redbooks 2. 设置一个新的环境变量hello $ export HELLO="Hello!" $ ech ...
- android:提升 ListView 的运行效率
之所以说 ListView 这个控件很难用,就是因为它有很多的细节可以优化,其中运行效率 就是很重要的一点.目前我们 ListView 的运行效率是很低的,因为在 FruitAdapter 的 get ...
- CAP:Alantany 谈 CAP
引用Alantany的话:“CAP理论提出就是针对分布式数据库环境的,所以,P这个属性是必须具备的.P就是在分布式环境中,由于网络的问题可能导致某个节点和其它节点失去联系,这时候就形成了P(parti ...
- 修正 Mui 下拉上拉刷新功能
下拉增加动态时间计算功能: 上拉增加状态文字提示功能(当然也支持时间计算功能,只是我们暂时用不到):
- android中Textview 和图片同时显示时,文字省略号显示,图片自动靠到右边
很纠结的一个标题,实在是不知道怎么去描述这个现象. 上图片吧,先看看需求是什么样的. 1.需求: 视频与票的图标跟在标题后面显示,当标题过长时icon显示到省略号…后(textview省略号显示, ...
- C#去除HTML标签
public static string ReplaceHtmlTag(string html, int length = 0) { string strText = System.Text.Regu ...
- MUI class="mui-switch" 开关 默认为选中
<label >日期条件: </label> <div id="is_select_time" class="mui-switch mui- ...
- SNF快速开发平台3.0之BS页面展示和九大优点-部分页面显示效果-Asp.net+MVC4.0+WebAPI+EasyUI+Knockout
一)经过多年的实践不断优化.精心维护.运行稳定.功能完善: 能经得起不同实施策略下客户的折腾,能满足各种情况下客户的复杂需求. 二)编码实现简单易懂.符合设计模式等理念: 上手快,见效快.方便维护,能 ...