[No0000100]正则表达式匹配解析过程分析(正则表达式匹配原理)&regexbuddy使用&正则优化
常见正则表达式引擎
引擎决定了正则表达式匹配方法及内部搜索过程,了解它至关重要的。目前主要流行引擎有:DFA,NFA两种引擎。
|
引擎 |
区别点 |
|
DFA |
DFA引擎它们不要求回溯(并因此它们永远不测试相同的字符两次),所以匹配速度快!DFA引擎还可以匹配最长的可能的字符串。 不过DFA引擎只包含有限的状态,所以它不能匹配具有反向引用的模式,还不可以捕获子表达式。 代表性有:awk,egrep,flex,lex,MySQL,Procmail |
|
NFA 非确定型有穷自动机 又分为传统NFA,Posix NFA |
传统的NFA引擎运行所谓的“贪婪的”匹配回溯算法(longest-leftmost), 以指定顺序测试正则表达式的所有可能的扩展并接受第一个匹配项。 传统的NFA回溯可以访问完全相同的状态多次,在最坏情况下,它的执行速度可能非常慢,但它支持子匹配。 代表性有:GNU Emacs,Java,ergp,less,more,.NET语言 ,PCRE 一般高级语言都采用该模式。 |
DFA以字符串字符为主,逐个在正则表达式匹配查找,而NFA以正则表达式为主,在字符串中逐一查找。尽管速度慢,但是对操作者来说更简单,因此应用更广泛!下面所有以NFA引擎举例说明,解析过程!
解析引擎眼中的字符串组成
对于字符串“DEF”而言,包括D、E、F三个字符和 0、1、2、3 四个数字位置(零宽空间):0D1E2F3,对于正则表达式而言所有源字符串,都有字符和位置。正则表达式会从0号位置(可以匹配^),逐个去匹配的。
占有字符和零宽度
正则表达式匹配过程中,如果子表达式匹配到的是字符内容,而非位置,并被保存到最终的匹配结果中,那么就认为这个子表达式是占有字符的(IsMatch开始为true);如果子表达式匹配的仅仅是位置,或者匹配的内容并不保存到最终的匹配结果中,那么就认为这个子表达式是零宽度的(IsMatch不为true)。占有字符是互斥的,零宽度是非互斥的。也就是一个字符,同一时间只能由一个子表达式匹配,而一个位置,却可以同时由多个零宽度的子表达式匹配。常见零宽字符有:^,(?=)等
正则表达式匹配过程详解实例
我们掌握了上面几个概念,我们接下来分析下几个常见的解析过程。结合使用软件regexBuddy来分析。
regexbuddy正则表达式测试工具使用方法(图文)
1、安装完regexbuddy
该工具支持多种程序语言正则表达式,如:perl,pcre,javascript,python,ruby,c#,java等等,还能自动生成程序代码,并且内部带有大量的常用正则表达式。
2、一般切换到side by side:
3、匹配过程
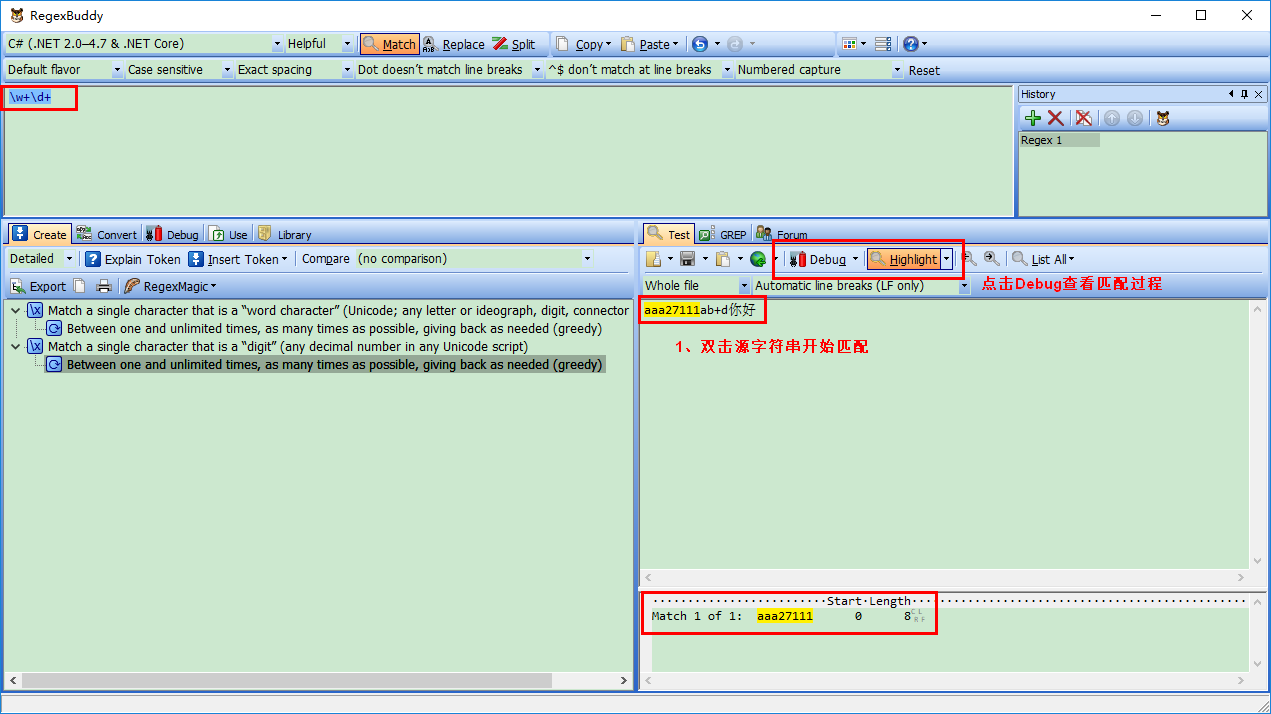
匹配完,点击“Test”里面Debug(Here),自动切换到Debug界面:
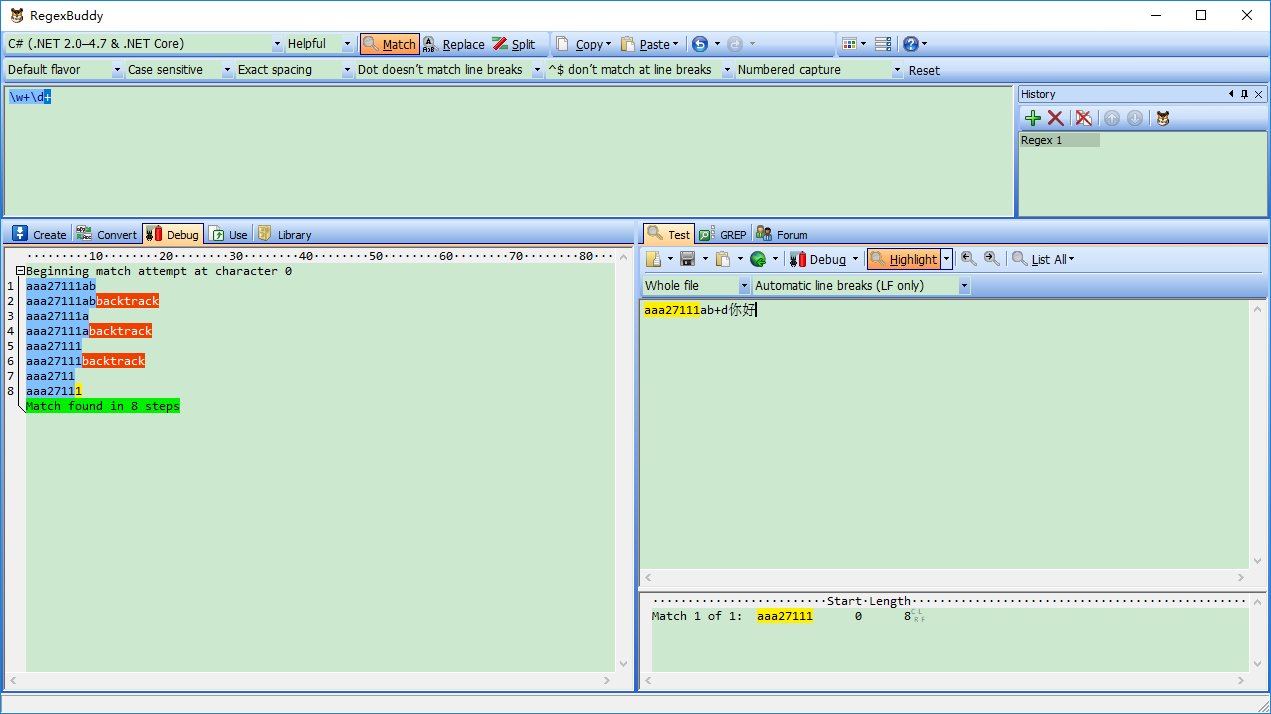
匹配过程:\w+一下子贪婪匹配aaa27111ab,然后\d+没有匹配字符串了。开始回逆了,逐个字符减少,直到发现最后一个字符“1”与\d+匹配为止。最终匹配到字符串是:“aaa27111”
从上面一个匹配看,这个简单一个匹配,搜索了8次,进行了不断查找。如果我们已经准确知道自己要匹配什么样字符,我们可以对源正则表达式修改下,减少匹配次数。就达到优化正则表达式目的,提高匹配效率!
如果我们知道源字符串只是a-z字符,进行修改发现,只要用2次搜索就匹配到所需字符。
为什么需要性能测试工具
我们都知道,正则表达式使用进行搜索查找,没有字符串直接查找快!而且性能是几何倍数下降。那么,为什么正则表达式速度会比字符串搜索慢呢。我们来看看,正则表达式查找字符串的匹配过程吧。正则表达式由一些元字符,普通字符,量词字符组合成。默认情况下,这些量词元字符(*,+,?)都是贪婪模式,会最大长度匹配字符串。我们知道,正则表达式往往搜索路径会有多个,我们看看,下面匹配过程。就知道,主要影响正则表达式执行性能有哪些了。
正则表达式匹配过程如:\d+abc,元字符是:”12345bdc”,查找会从左向右进行,\d+,贪婪模式,一下子匹配到12345,然后bdc与\d+不能匹配,”abc”中,”a”字符,开始匹配”bdc”,发现匹配失败。正则表达式开始回溯匹配(贪婪模式量词开始逐一减少匹配字符长度),\d+只匹配”1234”,”5bdc”与”abc”匹配,任然失败。\d+继续减少匹配长度为:”123”,”45bdc”与”abc”匹配,任然失败。继续回退,直到\d+匹配”1”,用”2345bdc”与”bdc”匹配,任然失败。整个匹配就失败了。
从上面过程中,我们发现,每次回溯,要重新操作匹配因此匹配搜索次数,直接影响正则表达式的性能。做正则表达式性能优化,一般就是优化查询的次数。这个是我们分析过程,如果有个工具能够实实在在看到每一步匹配过程,对于我们优化正则表达式将带来太多方便了。这里介绍工具是:regexbuddy软件,它就是一个实实在在看到匹配过程工具。
Demo1: 源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:“DEF”
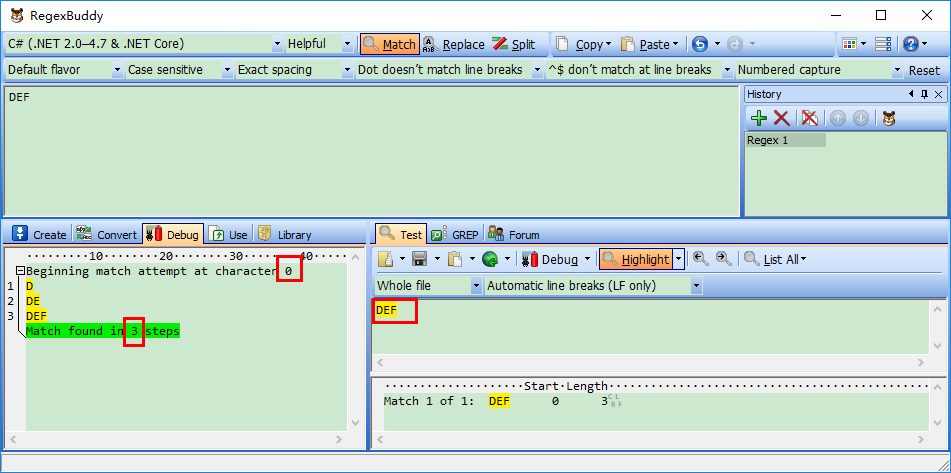
过程可以理解为:首先由正则表达式字符 “D” 取得控制权,从位置0开始匹配,由 “D” 来匹配“D”,匹配成功,控制权交给字符 “E” ;由于“D”已被 “D” 匹配,所以 “E” 从位置1开始尝试匹配,由“E” 来匹配“E”,匹配成功,控制权交给 “F”;由“F”来匹配“F”,匹配成功。
Demo2:源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:/D\w+F/

过程可以理解为:首先由正则表达式字符 /D/ 取得控制权,从位置0开始匹配,由 /D/ 来匹配“D”,匹配成功,控制权交给字符 /\w+/ ;由于“D”已被 /D/ 匹配,所以 /\w+/ 从位置1开始尝试匹配,\w+贪婪模式,会记录一个备选状态,默认会匹配最长字符,直接匹配到EF,并且匹配成功,当前位置3了。并且把控制权交给 /F/ ;由 /F/ 匹配失败,\w+匹配会回溯一位,当前位置变成2。并把控制权交个/F/,由/F/匹配字符F成功。因此\w+这里匹配E字符,匹配完成!
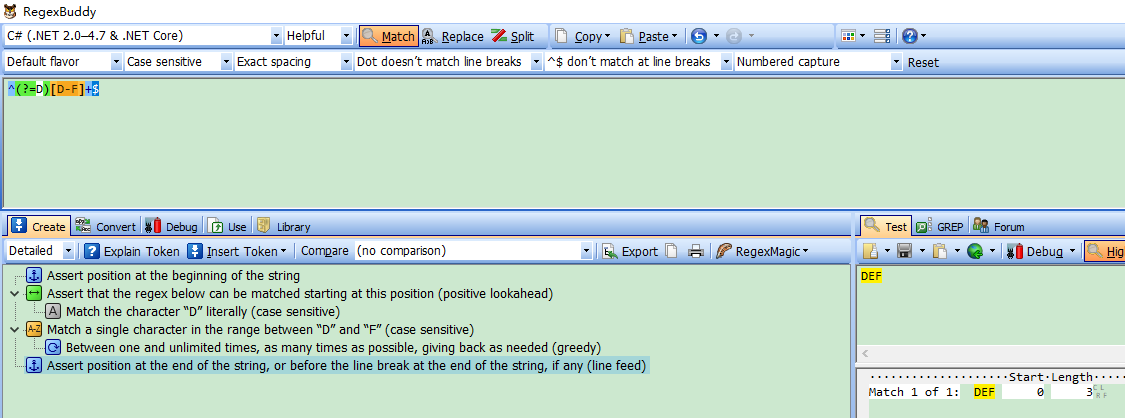
Demo3:源字符DEF,对应标记是:0D1E2F3,匹配正则表达式是:/^(?=D)[D-F]+$/
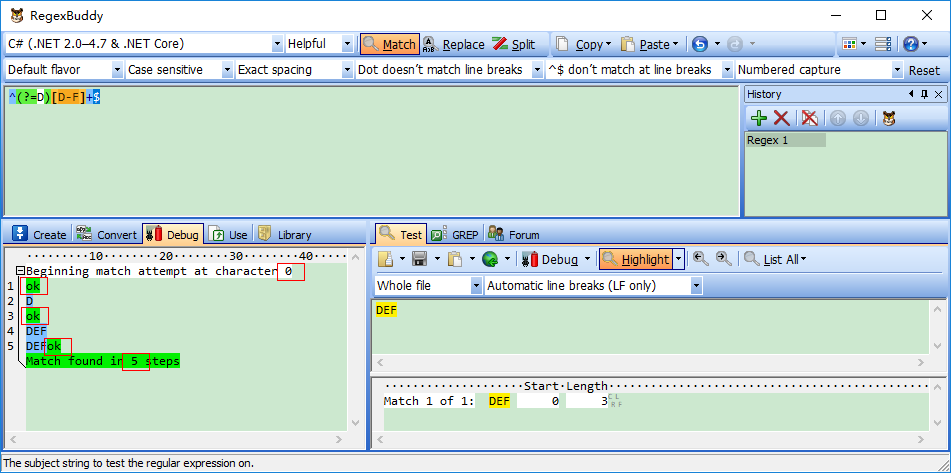
过程可以理解为:元字符 /^/ 和 /$/ 匹配的只是位置,顺序环视(匹配完开头,从左往右依次匹配) /(?=D)/ (匹配当前位置,右边是否有字符“D”字符出现)只进行匹配,并不占有字符,也不将匹配的内容保存到最终的匹配结果,所以都是零宽度的。 首先由元字符 /^/ 取得控制权,从位置0开始匹配, /^/ 匹配的就是开始位置“位置0”,匹配成功,控制权交给顺序环视 /(?=D)/;/(?=D])/ 要求它所在位置右侧必须是字母”D”才能匹配成功,零宽度的子表达式之间是不互斥的,即同一个位置可以同时由多个零宽度子表达式匹配,所以它也是从位置0尝试进行匹配,位置0的右侧是字符“D”,符合要求,匹配成功,控制权交给 /[D-F]+/ ;因为 /(?=D)/ 只进行匹配,并不将匹配到的内容保存到最后结果,并且 /(?=D)/ 匹配成功的位置是位置0,所以 /[D-F]+/ 也是从位置0开始尝试匹配的, /[D-F]+/ 首先尝试匹配“D”,匹配成功,继续尝试匹配,直到匹配完”EF”,这时已经匹配到位置3,位置3的右侧已没有字符,这时会把控制权交给 /$/,元字符 /$/ 从位置3开始尝试匹配,它匹配的是结束位置,也就是“位置3”,匹配成功。此时正则表达式匹配完成,报告匹配成功。匹配结果为“DEF”,开始位置为0,结束位置为3。其中 /^/ 匹配位置0, /(?=D)/ 匹配位置0, /[D-F]+/ 匹配字符串“DEF”, /$/ 匹配位置3。
匹配详解
- 用“(\$)”匹配“$1.30”
匹配结果:
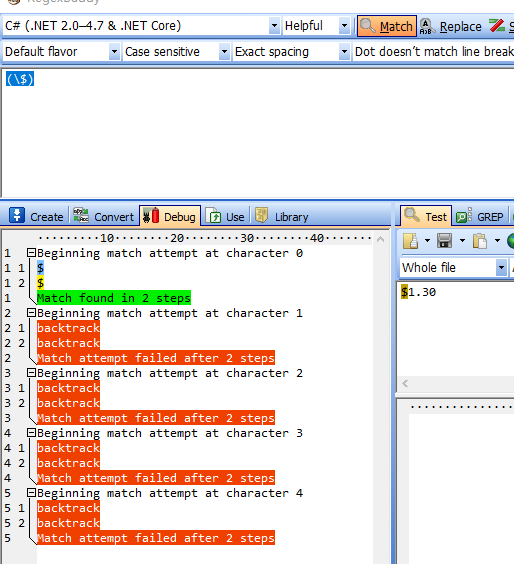
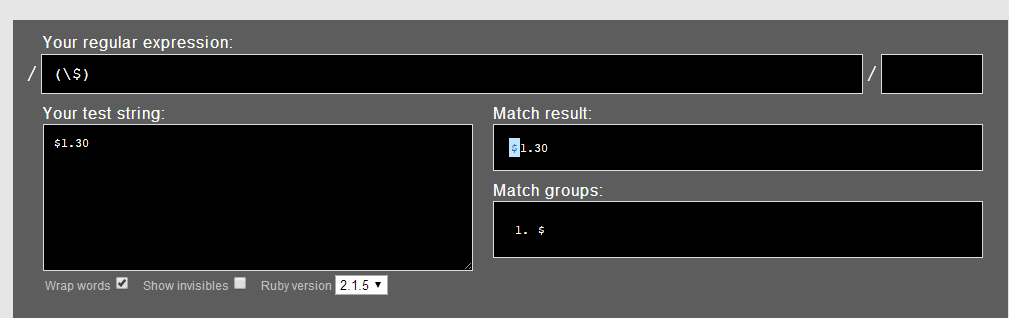
1.1.尝试从“ $ 1 . 3 0 ”的第一个“零宽空间”开始匹配“(\$)”: “ $ 1 . 3 0 ”匹配到,IsMatch=true。
1.2. 尝试从“ $ 1 . 3 0 ”的第二个“零宽空间”开始匹配“(\$)”:“1 . 3 0 ”依次均不匹配。
2. 用“(\$*)”匹配“$1.30”
匹配结果:
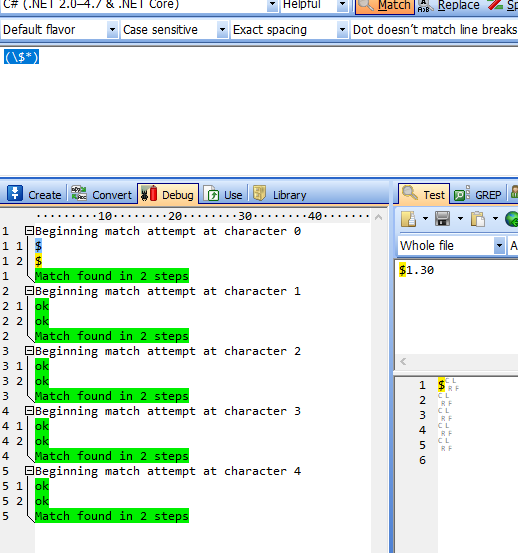

2.1.尝试从“ $ 1 . 3 0 ”的第一个“零宽位”开始匹配“(\$*)”: “ $ 1 . 3 0 ”匹配。(\$*是尽可能多的匹配$,此处匹配了1次$)
2.2尝试从“ $ 1 . 3 0 ”的第二个“零宽位”开始匹配“(\$*)”:由于1符合\$*(\$*是尽可能多的匹配$,此处匹配了0次$),所以“ 1”中的零宽空间被捕获,但1未被捕获。
2.3尝试从“ $ 1 . 3 0 ”的第三个“零宽位”开始匹配“(\$*)”:由于.符合\$*(\$*是尽可能多的匹配$,此处匹配了0次$),所以“ .”中的零宽空间被捕获,但.未被捕获。
2.4尝试从“ $ 1 . 3 0 ”的第四个“零宽位”开始匹配“(\$*)”:由于3符合\$*(\$*是尽可能多的匹配$,此处匹配了0次$),所以“ 3”中的零宽空间被捕获,但3未被捕获。
2.5尝试从“ $ 1 . 3 0 ”的第五个“零宽位”开始匹配“(\$*)”:由于0符合\$*(\$*是尽可能多的匹配$,此处匹配了0次$),所以“ 0”中的零宽空间被捕获,但0未被捕获。
2.6尝试从“ $ 1 . 3 0 ”的第六个“零宽位”开始匹配“(\$*)”:由于$(结尾)符合\$*(\$*是尽可能多的匹配$,此处匹配了0次$),所以“ $”(结尾)中的零宽空间被捕获,但结尾未被捕获。
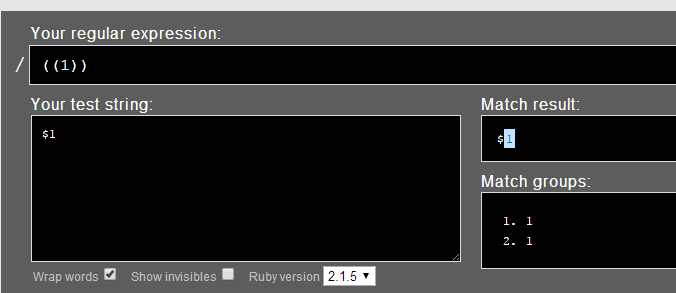
3. 用“((1))”匹配“$1”
匹配结果:

[No0000100]正则表达式匹配解析过程分析(正则表达式匹配原理)&regexbuddy使用&正则优化的更多相关文章
- Django url配置 正则表达式详解 分组命名匹配 命名URL 别名 和URL反向解析 命名空间模式
Django基础二之URL路由系统 本节目录 一 URL配置 二 正则表达式详解 三 分组命名匹配 四 命名URL(别名)和URL反向解析 五 命名空间模式 一 URL配置 Django 1.11版本 ...
- javascript 正则表达式之分组与前瞻匹配详解
本文主要讲解javascript 的正则表达式中的分组匹配与前瞻匹配的,需要对正则的有基本认识,本人一直对两种匹配模棱不清.所以在这里总结一下,如有不对,还望大神指点. 1.分组匹配: 1.1捕获性分 ...
- 正确匹配URL的正则表达式
网上流传着多种匹配URL的正则表达式版本,但我经过试验,最好用的还是从stackoverflow上查到的: (https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_| ...
- java 正则匹配空格字符串 正则表达式截取字符串
java 正则匹配空格字符串 正则表达式截取字符串 需求:从一堆sql中取出某些特定字符串: 比如配置的sql语句为:"company_code = @cc and project_id = ...
- Delphi 正则表达式语法(6): 贪婪匹配与非贪婪匹配
Delphi 正则表达式语法(6): 贪婪匹配与非贪婪匹配 //贪婪匹配 var reg: TPerlRegEx; begin reg := TPerlRegEx.Create(nil); ...
- java中匹配中文的正则表达式
java中要匹配中文的正则表达式可以有两种写法:一是使用unicode中文码:二是直接使用汉字字符: 例: (1)String str = "晴"; String regexStr ...
- js进阶正则表达式10-分组-多行匹配-正则对象的属性(小括号作用:分组,将小括号里面的东西看成一个整体,因为量词只对前一个字符有效)(多行匹配:m)(属性使用:reg.global)
js进阶正则表达式10-分组-多行匹配-正则对象的属性(小括号作用:分组,将小括号里面的东西看成一个整体,因为量词只对前一个字符有效)(多行匹配:m)(属性使用:reg.global) 一.总结 1. ...
- 廖雪峰Java9正则表达式-2正则表达式进阶-5非贪婪匹配
1.贪婪匹配 问题:给定一个字符串表示的数字,判断该数字末尾0的个数? "123000": 3个0 "10100": 2个0 "1001": ...
- VIM 用正则表达式,非贪婪匹配,匹配竖杠,竖线, 匹配中文,中文正则,倒数第二列, 匹配任意一个字符 :
VIM 用正则表达式 批量替换文本,多行删除,复制,移动 在VIM中 用正则表达式 批量替换文本,多行删除,复制,移动 :n1,n2 m n3 移动n1-n2行(包括n1,n2)到n3行之下: ...
随机推荐
- 【C#】C#对电子邮件的收发操作
目录结构: contents structure [+] 简介 发送邮件 读取邮件 1.简介 邮件传输常用的协议有,SMTP.POP3.IMAP4.他们都属于TCP/IP协议,默认状态下分别通过TCP ...
- JProfiler进行Java运行时内存分析
原文地址:https://www.cnblogs.com/onmyway20xx/p/3963735.html 在最近的工作中,通过JProfiler解决了一个内存泄漏的问题,现将检测的步骤和一些分析 ...
- awk的些许小技巧
一句话kill掉名为navimain进程的shell脚本(利用awk的列操作能力) `ps|grep navimain | awk 'NR==1 {print $1}'`
- Effective Java 第三版——44. 优先使用标准的函数式接口
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- 空间谱专题02:波束形成(Beamforming)
作者:桂. 时间:2017-08-22 10:56:45 链接:http://www.cnblogs.com/xingshansi/p/7410846.html 前言 本文主要记录常见的波束形成问题 ...
- Kubernetes1.2如何使用iptables
转:http://blog.csdn.net/horsefoot/article/details/51249161 本次分析的kubernetes版本号:v1.2.1-beta.0. Kubernet ...
- [转]设备唯一标识方法(Unique Identifier):如何在Windows系统上获取设备的唯一标识
原文地址:http://www.vonwei.com/post/UniqueDeviceIDforWindows.html 唯一的标识一个设备是一个基本功能,可以拥有很多应用场景,比如软件授权(如何保 ...
- DataTable转成List集合
项目开发中,经常会获取到DataTable对象,如何把它转化成一个List对象呢?前几天就碰到这个问题,网上搜索整理了一个万能类,用了泛型和反射的知识.共享如下: public class Model ...
- elasticsearch中 refresh 和flush区别【转】
elasticsearch中有两个比较重要的操作:refresh 和 flush refresh操作 当我们向ES发送请求的时候,我们发现es貌似可以在我们发请求的同时进行搜索.而这个实时建索引并可以 ...
- js数组相关知识集合
一.js数组快速排序 <script type="text/javascript"> var arr = [1, 2, 3, 54, 22, 1, 2, 3]; fun ...