python3 语法小结
(1) 关键字
# -*- coding: utf-8 -*-
#!/usr/bin/python3 """
1、关键字(保留字)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif',
'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or',
'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
"""
import keyword
print(keyword.kwlist) """2、注释"""
#单行注释
""" 多行注释"""
'''多行注释'''
(2)数据类型,此处重点字符串常用方法
# -*- coding: utf-8 -*-
#!/usr/bin/python3
#1、数字类型
"""
数字有四种类型:整数、布尔型、浮点数和复数。
int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
bool (布尔), 如 True。
float (浮点数), 如 1.23、3E-2
complex (复数), 如 1 + 2j、 1.1 + 2.2j
"""
#2、字符串 参考:https://www.cnblogs.com/fyknight/p/7895894.html
def strFuc():
a = "hello"
b = a *3
print(a) #python2 print不要括号
print(b)
print(a,b)
#不换行
print(a,end=",")
print(b,end=",")
"""
hello
hellohellohello
hello hellohellohello
hello,hellohellohello,
"""
s = "hello stupid"
#---------<常用方法>-----------
#index 返回元素下标
index = s.index("u")
print(index) # #find
leftIndex = s.find("stu")
print(leftIndex) # #count 得到字符串元素的个数
count = s.count("l")
print(count) # #strip 类似java trim(),移除左右两边空格
print(" add ".strip()) #split 分隔符,返回列表
s = "hello,stupid"
lis = s.split(",")
print(lis)
print(isinstance(lis, list)) # 列表 #replace 替换
s = "hello,stupid"
rep = s.replace("stupid", "笨蛋")
print(rep) # hello,笨蛋 #join 序列中的元素以指定的字符拼接生成一个新的字符串,并返回这个字符串
tup = ("Hello,my ", "beautiful", " girl") #tup = ["Hello,my ","beautiful"," girl"]
str = "".join(tup)
print(str) # Hello,my beautiful girl #format
# 按默认顺序对字符串进行格式化
s = "I am dark {},I'm {} years old!"
s1 = s.format('knight', '')
print(s1) # I am dark knight,I'm 28 years old! #按位置对字符串进行格式化
s = "I am dark {1},I'm {0} years old!"
s1 = s.format('', 'knight')
print(s1) #I am dark knight,I'm 28 years old! # endoce()和decode()
# 以utf-8的方式进行编码并解码
s = '暗黑骑士'
s1 = s.encode('utf-8')
print(s1) # 得到以"utf-8"编码后的二进制数
s2 = s1.decode('utf-8')
print(s2) # 用decode解码,以什么编码就要以什么解码,否则乱码
"""
b'\xe6\x9a\x97\xe9\xbb\x91\xe9\xaa\x91\xe5\xa3\xab'
暗黑骑士
"""
# startswith(suffix,start,end)和endswith(suffix,start,end)
s = 'dark knight'
s1 = s.startswith('dark')
print(s1) # True
# 判断字符串是否以指定字符串开头,并指定范围
s = 'dark knight'
s1 = s.startswith('k', 5)
print(s1) # True #upper() 和lower()
# title() 将字符串中的所有单词的首字母替换成大写字母
s = "i am hero"
print(s.title()) # I Am Hero
# swapcase() 将字符串的大小写字母进行转换,并返回转换后的字符串
print(s.swapcase()) # I AM HERO
#capitalize() 返回一个将字符串首字母大写、字符串中的其它字母变为小写的字符串
s = 'dARk kNigHt'
s1 = s.capitalize()
print(s1) #Dark knight #center(len,sginl) 返回一个居中对齐的字符串,并使用指定长度的填充符号,不指定填充符号默认使用空格作为填充符号
s = 'dark knight'
s1 = s.center(30)
print('开始->', s1, '<-结束') #开始-> dark knight <-结束
print('开始->', s.center(30,"*"), '<-结束') #开始-> *********dark knight********** <-结束 #zfill() 按指定长度在字符串的左侧填充"0"补齐,并返回这个补齐“0”后的字符串
s = "hej"
print(s.zfill(15)) #000000000000hej
#isdigit() 判断字符串是否只由数字组成,并返回一个布尔值
#isalpha() 判断字符串是否只由字母组成
#isalnum() 判断字符串是否只由字母或数字组成
#isupper() 判断字符串中所有的字母是否为大写。并返回一个布尔值
#islower() 判断字符串中所有的字母是否为小写。并返回一个布尔值
#isspace() 判断字符串是否只由空白字符组成,并返回一个布尔值
(3)python 导入:

commonModule.py
# -*- coding: utf-8 -*-
#!/usr/bin/python3
def isGreater(x,y):
'''
x是否大于
:param x:
:param y:
:return:yTrue or False
'''
return x > y
moduleTest.py
# -*- coding: utf-8 -*-
#!/usr/bin/python3
import com.grammar.commonModule as commonModule
if __name__ == "__main__":
a = commonModule.isGreater(3,2)
print(a)
此处需要指定工程为sourceFolder。具体有下两种:
1、pycharm:file>setting>

2、找到工程python37.iml文件
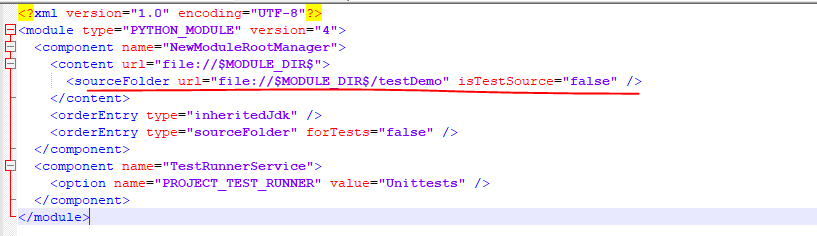
(4)数据类型(列表、元组、字典、集合)
列表:
# -*- coding: utf-8 -*-
#!/usr/bin/python3 def listFuc():
lis = [2,3,"hello"] #列表的数据项不需要具有相同的类型
print(lis)
#len(list) 列表元素个数
#max(list) 返回列表元素最大值 注意:元素相同类型,否则报错
#min(list) 返回列表元素最小值
#list(seq) 将元组转换为列表
#----列表方法
#list.append(obj) 在列表末尾添加新的对象
#list.count(obj) 统计某个元素在列表中出现的次数
#list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表
#list.index(obj) 从列表中找出某个值第一个匹配项的索引位置
#list.insert(index, obj) 将对象插入列表
list1 = ['Google', 'Runoob', 'Taobao']
list1.insert(1, 'Baidu')
print('列表插入元素后为 : ', list1) #列表插入元素后为 : ['Google', 'Baidu', 'Runoob', 'Taobao']
#list.pop([index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
#list.remove(obj) 移除列表中某个值的第一个匹配项
#list.reverse() 反向列表中元素
#list.sort(key=None, reverse=False) 对原列表进行排序,其中key是按照某种规则排序
vowels = ['e', 'a', 'u', 'o', 'i']
vowels.sort(reverse=True) ## 降序
print('降序输出:', vowels) # 降序输出: ['u', 'o', 'i', 'e', 'a']
random = [(2, 2), (3, 4), (4, 1), (1, 3)]
# 以元组第二元素有小到达排序
random.sort(key=lambda x: x[1]) # [(4, 1), (2, 2), (1, 3), (3, 4)]
print(random)
#list.clear() 清空列表
#list.copy() 复制列表 #遍历列表(1)
lis = [2,3,4,5,1,7]
for i in lis:
print(i,end=",")
else:
print("结束") #遍历列表(2)
for i in range(len(lis)):
print("序号:%s 值:%s"%(i,lis[i])) # 遍历列表(3)
for i, val in enumerate(lis):
print("序号:%s 值:%s" % (i, val)) """
序号:0 值:2
序号:1 值:3
序号:2 值:4
序号:3 值:5
序号:4 值:1
序号:5 值:7
"""
#添加元素
list = [2, 3, 4, 5, 1, 7]
# list[6] =8 #IndexError
list.append(8) # ok
print(list) #删除数据
delList = [2,3,4,5,1,7]
#del delList[6] #IndexError 注意:不要超出范围
del delList[5]
print(delList)#[2, 3, 4, 5, 1] #序列
seqList = [2,3,4,5,1,7]
print(seqList[0:2]) #[2, 3]
print(seqList[1:]) # [3, 4, 5, 1, 7]
print(seqList[0:len(seqList)]) #[2, 3, 4, 5, 1, 7]
元组:
# -*- coding: utf-8 -*-
#!/usr/bin/python3
import collections
def tupleFuc():
tup1 = (50)
tup2 = (50,)
print(type(tup1)) # <class 'int'>
print(type(tup2)) # <class 'tuple'> # 访问元组
tup1 = ('Google', 'Runoob', 1997, 2000)
tup2 = (1, 2, 3, 4, 5, 6, 7)
print("tup1[0]: ", tup1[0]) # tup1[0]: Google
print("tup2[1:5]: ", tup2[1:5]) # tup2[1:5]: (2, 3, 4, 5) # 元组中的元素值是不允许直接修改的
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
# 以下修改元组元素操作是非法的。
# tup1[0] = 100
# 但可以对元组进行连接组合
tup3 = tup1 + tup2;
print(tup3) # (12, 34.56, 'abc', 'xyz') #通过间接方法修改元组
#方法1:
tuple1 = (1, 2, 4, 5)
tuple2 = tuple1[:2] + (3,) + tuple1[2:]
print(tuple2) #(1, 2, 3, 4, 5)
#方法2:
t1=(1,2,3,4)
list = list(t1)
list[1] = 9
t2= tuple(list)
print(t2) #(1, 9, 3, 4) tup = ('Google', 'Runoob', 1997, 2000)
print(tup)
del tup;
print("删除后的元组 tup : ")
print(tup) #NameError: name 'tup' is not defined # ---元组运算符
# len() 计算元素个数
print(len((1, 2, 3))) #
# 元组连接
a = (1, 2, 3) + (4, 5, 6, 7)
print(a) # (1, 2, 3, 4, 5, 6, 7)
# 复制
print(("Hi") * 3) # HiHiHi 相当于字符串复制
print(("Hi",) * 3) # ('Hi', 'Hi', 'Hi')
# 元素是否存在
print(3 in (1, 4, 3)) # True
#迭代
for i in (1, 2, 3, 4): print(i) #内置函数
#len(tuple) 计算元组元素个数
#max(tuple) 返回元组中元素最大值 元素类型一致
#min(tuple) 返回元组中元素最小值
#tuple(list) 将列表转换为元组 与list(tuple) 相反
list1 = ['Google', 'Taobao', 'Runoob', 'Baidu']
l = tuple(list1)
print(l) ##('Google', 'Taobao', 'Runoob', 'Baidu') s = "Hello,%s,%s" % ("jack", "Tom")
print(s) #Hello,jack,Tom #遍历 range(start,end,step)
t1 = (1, 2, 3, 4)
for i in range(0, 9, 2):
print(i)
"""
0
2
4
6
8
"""
def namedtupleFuc():
#Python元组的升级版本 -- namedtuple(具名元组)
# 两种方法来给 namedtuple 定义方法名
# User = collections.namedtuple('User', ['name', 'age', 'id'])
User = collections.namedtuple('User', 'name age id')
user = User('tester', '', '')
print(user) #User(name='tester', age='22', id='464643123')
print(user.name,user.age,user.id) #tester 22 464643123
字典:
# -*- coding: utf-8 -*-
#!/usr/bin/python3
def dictFuc():
dict = {'Alice': '', 'Beth': '', 'Cecil': ''}
# 访问指定元素
print(dict["Beth"]) #
# print(dict.Beth) #AttributeError
print(dict.get("Beth")) # # 修改字典
dict["Alice"] = ""
print(dict) # {'Alice': '1234', 'Beth': '9102', 'Cecil': '3258'} #删除字典元素和字典
delDict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} del delDict['Name'] # 删除键 'Name'
print(delDict) # {'Age': 7, 'Class': 'First'}
delDict.clear() # 清空字典
print(delDict) # {}
del delDict # 删除字典
print(delDict) # NameError: name 'delDict' is not defined #注意:1、不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住
# 2、键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行 #内置函数
#len(dict) 计算字典元素个数,即键的总数
#str(dict) 输出字典,以可打印的字符串表
strDict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print(str(strDict)) # {'Name': 'Runoob', 'Age': 7, 'Class': 'First'} #内置方法
#dict.clear() 删除字典内所有元素
# dict.copy() 返回一个字典的浅复制
# dict.fromkeys() 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值
attribute = ("name", "age", "gender")
userDict = dict.fromkeys(attribute)
print(userDict) # {'name': None, 'age': None, 'gender': None}
userDict = dict.fromkeys(attribute, 10)
print(userDict) # {'name': 10, 'age': 10, 'gender': 10}
# dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值
# key in dict 如果键在字典dict里返回true,否则返回false
# dict.items() 以列表返回可遍历的(键, 值) 元组数组
itemDict = {'Name': 'Runoob', 'Age': 7}
print(itemDict.items()) #Value : dict_items([('Name', 'Runoob'), ('Age', 7)])
print(type(itemDict.items())) #<class 'dict_items'>
print(list(itemDict.items())) # [('Name', 'Runoob'), ('Age', 7)] 注意: 需要转换
#print(itemDict.items()[0]) #TypeError: 'dict_items' object does not support indexing
for k,v in itemDict.items():
print(k,v)
"""
Name Runoob
Age 7
"""
# dict.keys() 返回一个迭代器,可以使用 list() 来转换为列表
# dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
# dict.update(dict2)
updict = {'Name': 'Runoob', 'Age': 7}
updict2 = {'Age': 'female'}
updict.update(updict2)
# 注意:如果键值有重复,则 dict2 的内容更新替换到 dict 中
print("更新字典 dict : ", updict) # 更新字典 dict : {'Name': 'Runoob', 'Age': 'female'}
#按照key给字典排序
sdict = {200: 'a', 20: 'b', 610: 'c'}
d1 = {}
for k in sorted(sdict.keys()):
d = {k: sdict[k]}
d1.update(d)
print(d1) # {20: 'b', 200: 'a', 610: 'c'}
# dict.values() 返回一个迭代器,可以使用 list() 来转换为列表
# dict. pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
# dict. popitem() 随机返回并删除字典中的一对键和值(一般删除末尾对)。
集合:
# -*- coding: utf-8 -*-
#!/usr/bin/python3
def setFuc():
# 空集合
s = set() # { },因为 { } 是用来创建一个空字典
#初始化
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
s1 = set({'apple', 'orange', 'apple', 'pear', 'orange', 'banana'})
# 一个无序的不重复元素序列
print(s1) #{'banana', 'pear', 'orange', 'apple'}
ar = set('abracadabra') #不推荐
print(ar) #{'c', 'r', 'a', 'b', 'd'} #集合间的运算
a = set('abracadabra')
b = set('alacazam')
#集合a中包含而集合b中不包含的元素
print(a-b) #{'d', 'b', 'r'}
#集合a或b中包含的所有元素 =>并集
print(a|b) #{'r', 'm', 'a', 'z', 'd', 'c', 'b', 'l'}
# 集合a和b中都包含了的元素 =>交集
print(a & b ) #{'a', 'c'}
#不同时包含于a和b的元素 =>并集 - 交集
print(a ^ b ) #{'l', 'z', 'r', 'd', 'b', 'm'}
c=(a|b)-(a & b)
print(c) #{'d', 'z', 'r', 'm', 'l', 'b'} # 添加元素
addS = set({'apple', 'orange', 'apple', 'pear', 'orange', 'banana'})
addS.add('pix')
print(addS) # {'orange', 'banana', 'pear', 'apple', 'pix'}
addS.add({1, 3}) #TypeError: unhashable type: 'set' add() 不能是列表、元组或字典
#update() 参数可以是列表,元组,字典等
print(addS.update({1, 3})) # {1, 'apple', 3, 'pear', 'orange', 'banana'} #移除元素
remS = set({'apple', 'orange', 'apple', 'pear', 'orange', 'banana'})
remS.remove('apple')
print(remS) # {'banana', 'orange', 'pear'}
remS.remove('adg')
print(remS) # 元素不存在,KeyError: 'adg'
#discard() 元素不存在,不会发生错误
remS.discard('adg')
print(remS) # {'orange','banana', 'pear'}
#pop()
thisset = set(("Google", "Runoob", "Taobao", "Facebook"))
x = thisset.pop()
print(x) # Runoob 每次结果不一样
print(thisset) # {'Facebook', 'Google', 'Taobao'}
#注意:如果元素是列表或元组,从左删除
listSet = set([3, 2, 1, 5, 4, 7, 8])
print(listSet) # {1, 2, 3, 4, 5, 7, 8}
listSet.pop()
print(listSet) # {2, 3, 4, 5, 7, 8} tupleSet = set((3, 2, 1, 5, 4, 7, 8))
print(tupleSet) # {1, 2, 3, 4, 5, 7, 8}
tupleSet.pop()
print(tupleSet) # {2, 3, 4, 5, 7, 8} #len(s) 集合元素个数
lset = set(("Google", "Runoob", "Taobao"))
print(len(lset)) # #clear()清空集合
clrset = set(("Google", "Runoob", "Taobao"))
clrset.clear()
print(clrset) # set() #判断元素是否在集合中存在 x in s
inset = set(("Google", "Runoob", "Taobao"))
print("Google" in inset) # True if __name__ == "__main__":
listSet = set([3,2,1,5,4,7,8])
print(listSet) #{1, 2, 3, 4, 5, 7, 8}
listSet.pop()
print(listSet)#{2, 3, 4, 5, 7, 8}
(5)条件、循环
条件
# -*- coding: utf-8 -*-
#!/usr/bin/python3
def conditionFuc1():
var1 = 100
if var1: #True 或 非0数字 或非""字符串
print("1 - if 表达式条件为 true")
print(var1)
else:
print("...") var2 = 0
if var2:
print("2 - if 表达式条件为 true")
print(var2)
print("Good bye!")
"""
1 - if 表达式条件为 true
100
Good bye!
""" if __name__ == "__main__":
var1 = 100
if var1:
print("1 - if 表达式条件为 true")
print(var1)
else:
print("...") var2 = 0
if var2:
print("2 - if 表达式条件为 true")
print(var2)
print("Good bye!")
"""
1 - if 表达式条件为 true
100
Good bye!
"""
循环
# -*- coding: utf-8 -*-
#!/usr/bin/python3
def whileFuc():
n = 100
sum = 0
counter = 1
while counter <= n:
sum = sum + counter
counter += 1
else:
print("counter > n,counter=%s"%counter) #最后一次打印:counter > n,counter=101
print("1 到 %d 之和为: %d" % (n, sum)) ##1 到 100 之和为: 5050 def forFuc():
sites = ["Baidu", "Google", "Runoob", "Taobao"]
for site in sites:
if site == "Runoob":
print("Runoob!")
break
print("循环数据 " + site)
else:
print("没有循环数据!")
print("完成循环!") """
循环数据 Baidu
循环数据 Google
Runoob!
完成循环!
"""
def rangeFuc():
#range(start,end,step)
for i in range(0, 10, 3):
print(i) """
0
3
6
9
"""
#break和 continue 与java相同
#pass 表示空语句,什么都不做
if __name__ == "__main__":
rangeFuc()
(6)迭代器与生成器
未完待续。。。
python3 语法小结的更多相关文章
- python2 与 python3 语法区别
python2 与 python3 语法区别 概述# 原稿地址:使用 2to3 将代码移植到 Python 3 几乎所有的Python 2程序都需要一些修改才能正常地运行在Python 3的环境下.为 ...
- python从入门到大神---3、浮光掠影python3语法
python从入门到大神---3.浮光掠影python3语法 一.总结 一句话总结: 语法不必一次记全部,效率太差,用哪部分内容,就把那部分内容全部记下来 1.python3中单引号和双引号的区别是什 ...
- python2.+进化至python3.+ 语法变动差异(不定期更新)
1.输出 python2.+ 输出: print "" python3.+ 输出: print ("") 2.打开文件 python2.+ 打开文件: file ...
- Python3语法详解
一.下载安装 1.1Python下载 Python官网:https://www.python.org/ 1.2Python安装 1.2.1 Linux 平台安装 以下为在Unix & Linu ...
- IT兄弟连 HTML5教程 HTML5的基本语法 小结及习题
小结 一个完整的HTML文件由标题.段落.列表.表格.文本,即嵌入的各种对象所组成,这些逻辑上统一的对象称为元素.HTML文档主体结构分为两部分,一部分是定义文档类型,另一部分则是定义文档主体的结构框 ...
- pyhton2 python3 语法区别
几乎所有的Python 2程序都需要一些修改才能正常地运行在Python 3的环境下.为了简化这个转换过程,Python 3自带了一个叫做2to3的实用脚本(Utility Script),这个脚本会 ...
- XML语法小结
语法结构主要要求: (1)有且仅有一个根元素. 根元素也称文档元素,整个 XML 文档的其他元素都包含在根元素中,并通过嵌套形成树 型结构.除了根元素外,其他元素都是子元素. (2)每个元素必须有开始 ...
- Markdown基础语法小结
一.前言 Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式. --摘自百度百科 没想到一向不太靠谱的百度百科这次竟有了如此精辟的解释. ...
- python的语法小结
break 与continue的区别: 1.break是直接中断全部循环 2.continue则是在只不执行此次所循环的东西,其它循环依旧执行,比方说只是跳过第4次循环,第5次循环照常进行. \n 表 ...
随机推荐
- kali linux 64bit 2019.1a下启动bbqsql:No module named coros
kali linux 64bit 2019.1a下bbqsql启动失败,错误: File "/usr/local/lib/python2.7/dist-packages/bbqsql/lib ...
- Codeforces Round #427 (Div. 2) Problem D Palindromic characteristics (Codeforces 835D) - 记忆化搜索
Palindromic characteristics of string s with length |s| is a sequence of |s| integers, where k-th nu ...
- Jbarcode 条形码生成工具
一.准备jar包 https://sourceforge.net/projects/jbcode/?source=typ_redirect 二.编写工具类 package com.example.de ...
- Java TreeSet的定制排序
注:只贴出实现类 package Test3; import java.util.Comparator;import java.util.TreeSet; public class Test { pu ...
- vim改善生活的几个插件
vim改善生活的几个插件 http://www.cnblogs.com/lovesaber/archive/2012/01/06/2315343.html
- P3178 [HAOI2015]树上操作
P3178 [HAOI2015]树上操作 思路 板子嘛,其实我感觉树剖没啥脑子 就是debug 代码 #include <bits/stdc++.h> #define int long l ...
- POJ 1873 The Fortified Forest(凸包)题解
题意:二维平面有一堆点,每个点有价值v和删掉这个点能得到的长度l,问你删掉最少的价值能把剩余点围起来,价值一样求删掉的点最少 思路:n<=15,那么直接遍历2^15,判断每种情况.这里要优化一下 ...
- Why there is two completely different version of Reverse for List and IEnumerable?
https://stackoverflow.com/questions/12390971/why-there-is-two-completely-different-version-of-revers ...
- Torch 两个矩形框重叠面积的计算 (IoU between tow bounding box)
Torch 两个矩形框重叠面积的计算 (IoU between tow bounding box) function DecideOberlap(BBox_x1, BBox_y1, BBox_x2, ...
- [蓝桥] 算法训练 K好数
时间限制:1.0s 内存限制:256.0MB 问题描述 如果一个自然数N的K进制表示中任意的相邻的两位都不是相邻的数字,那么我们就说这个数是K好数.求L位K进制数中K好数的数目.例如K = 4,L = ...