tomcat原理详解
tomcat的启动是通过Bootstrap类的main方法(tomcat6开始也可以直接通过Catlina的main启动)
Bootstrap的启动
Bootstrap的main方法先new了一个自己的对象(Bootstrap),然后用该对象主要执行了四个方法:
init();
setAwait(true);
load(args);
start();
init():初始化了ClassLoader(类加载器,没它的话后面就没法加载其他类了),然后用ClassLoader创建了Catlina实例。
setAwait(true),load(args),start();这三个方法实际上都是通过反射调用的Catlina实例中所对应的这三个方法。
Catlina的启动
首先Catlina中的setAwait(true)方法:
这个方法设置的值(true或false),是留给后面用的。当通过后面的start()方法启动完服务器后,会检查这个值为true还是false,如果为true,调用Catlina的await()方法,tomcat继续开着。如果为false,则调用Catlina的stop()方法,关闭tomcat。
然后是Catlina中的load(args)方法:
Catalina将利用Digest解析server.xml(server的配置文件,server是最顶层容器),并根据server的配置文件创建server实例。
然后调用server实例的init()方法,进行server的初始化。
Server初始化时,又会调用其内部的Service的init方法(server只有一个,但service有多个)。
大体流程如下图:
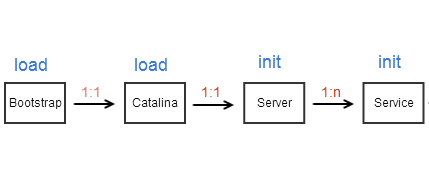
然后是Catlina中的start()方法:
Catlina的start()方法主要调用了server的start()方法来启动服务器,然后server的start()方法再调用多个service的start()方法。
大体流程如下图:
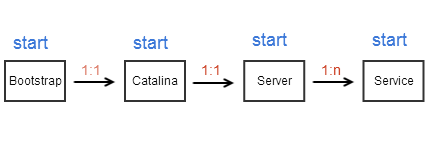
Server的启动
由上面Catlina的启动我们知道了,
Catlina中的load(args)方法使得Server进行了初始化,
Catlina中的start()方法使得Server也调用了start方法。
Server是一个接口,它的默认实现类是StandardServer,所以上面和之后我们操作的Server实际上是操作的StandardServer。
StandardServer继承自LifecycleMBeanBase,而LifecycleMBeanBase又继承自LifecycelBean。
根据之前的分析我们知道,StandardServer主要要调用两个方法:init()和start()。
而这两个方法都不在StandardServer中,实际上都在StandardServer的父类LifecycelBean中。而LifecycelBean中的这两个方法,实际上由“回头”调用了StandardServer中的initInternal()和startInternal()方法。
也就是StandardServer调用了init()实际上是调用了自己的initInternal()方法。
StandardServer调用了start()实际上是调用了自己的startInternal()方法。
initInternal()方法和startInternal()方法“分别循环调用了每一个service的init()方法和start()方法”。
除以上方法外,Standard还有addService()方法用来添加service,和remove()方法用来删除service。
另外Standard还拥有await()方法,用法在上面Catlina的启动中讲了。
Service的启动
一个Serve中可以有多个service,Service也是接口,Service接口的默认实现类是StandardService,所以上面和后面讨论的service实际上是在操作StandardService。
StandardService也继承于LifecycleMBeanBase,而LifecycleMBeanBase继承于LifecycelBean,LifecycelBean中存在init()和start()方法。
所以Server循环调用每个StandardService的init()和start()方法,其实是调用的StandardService的父类LifecycelBean中的init()和start()方法,然后init()和start()方法在“回头调用”StandardService中的initInternal()方法和startInternal()方法
也就是说Server循环调用每个StandardService的init()和start()方法,最后执行的是每个Service的initInternal()方法和startInternal()方法。
每一个service都是一个对外提供服务的组件,每一个Service中都包含:一个Container+多个Connector,所以service中的方法,都是用来操作这两种类的。
initInternal()方法:
下面是initInternal源码:
protected void initInternal() throws LifecycleException {
super.initInternal();
if(this.container != null) {
this.container.init();
}
Executor[] arr$ = this.findExecutors();
int arr$1 = arr$.length;
int len$;
for(len$ = 0; len$ < arr$1; ++len$) {
Executor i$ = arr$[len$];
if(i$ instanceof JmxEnabled) {
((JmxEnabled)i$).setDomain(this.getDomain());
}
i$.init();
}
this.mapperListener.init();
Object var11 = this.connectorsLock;
synchronized(this.connectorsLock) {
Connector[] var12 = this.connectors;
len$ = var12.length;
for(int var13 = 0; var13 < len$; ++var13) {
Connector connector = var12[var13];
try {
connector.init();
} catch (Exception var9) {
String message = sm.getString("standardService.connector.initFailed", new Object[]{connector});
log.error(message, var9);
if(Boolean.getBoolean("org.apache.catalina.startup.EXIT_ON_INIT_FAILURE")) {
throw new LifecycleException(message);
}
}
}
}
}
首先,调用Container的init()方法,
再调用mapperListener的init()方法(mapperListener是用来监听container的变化的),
再调用“多个”excutor的init()方法(excutor是用来在connector中管理线程池的),
再调用Connctor的init()方法。
startInternal()方法:
与上同理,也是分别调用四种类的start()方法。
总结一下,Server和Service的关系大致如下图(需要说明的是,下图中每个类或接口中所包含的方法我并没有全写出来,只写了与流程相关的几个):
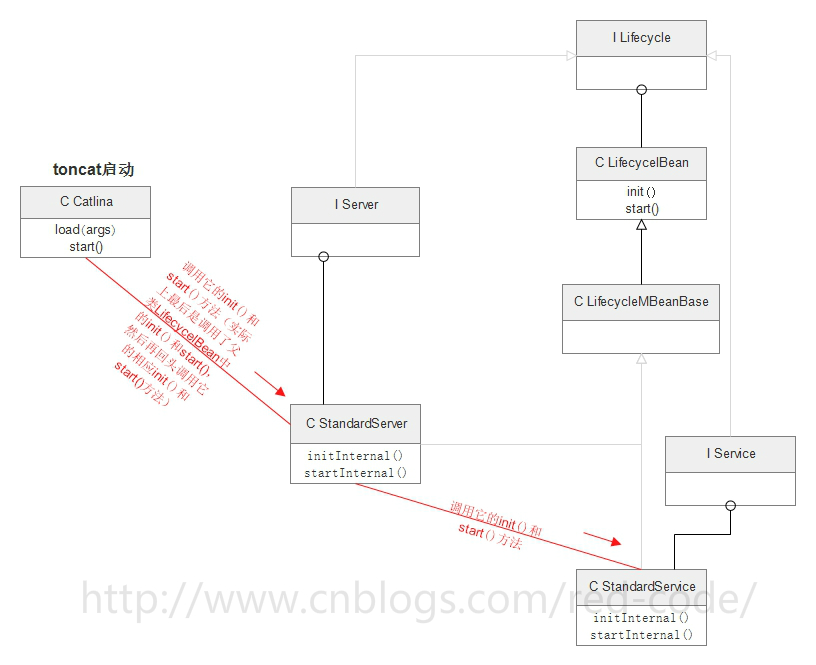
Lifecycle接口
将到这里应该提一下Lifecycle接口,该接口的默认实现就是LifecycleBean类。
通过上面提到Server和Service子类我们发现他们都继承了LifecycleBean类,并调用了该类的init()和start()方法。
实际上凡是拥有“生命周期”的组件都实现了Lifecycle接口,Lifecycle接口的作用就是进行“生命周期的规定”。
该接口主要做了以下四件事:
一、定义了13个String常量,这些常量被用于定义“LifecycleEvent事件”的type属性中 。这样设计的好处是,只需要发送一种类型事件LifecycleEvent,而根据里面type属性的值的不同,来判定是什么事件。(否则13种事件就得定义13中事件类)。
二、定义了三个管理监听的方法,分别用来添加、查找、删除LifecycleListener类型的监听器。
三、定义了四个生命周期方法:init()、start()、stop()、destroy(),用于执行生命周期各个阶段的操作。
四、定义了用来获取当前状态的两个方法。
LifecycleBase实现类
lifecycleBase是Lifecycle接口的默认实现类,所有拥有生命周期的组件都直接或间接的继承自lifecycleBase类,lifecycleBase为lifecycle接口中的各个方法提供了默认实现。
三个管理监听的方法:
这三个方法分别是addLifecycleListener(添加监听器)、findLifecycleListeners(查找监听器)、removeLifecycleListener(删除监听器)。
监听器的管理专门使用了一个“LifecycleSupport类”来完成。
这三个方法都调用了LifecycleSupport中的同名方法。
LifecycleSupport中通过一个数组来保存现有个监听器。
另外LifecycleSupport中还定义了处理LifecycleEvent时间的方法。
四个生命周期方法:
主要就是init()和start()方法,在调用方法之前会先判断当前状态与要调用的方法是否匹配,如果不匹配则会执行相应的方法使其匹配(如在低啊用init之前先调用了start,这是就会先执行init)。
之后会调用相应的模板方法(initInternal()和startInternal())让子类具体执行init和start。
我们先看一下init()方法的源码:
public final synchronized void init() throws LifecycleException {
if(!this.state.equals(LifecycleState.NEW)) {
this.invalidTransition("before_init");
}
this.setStateInternal(LifecycleState.INITIALIZING, (Object)null, false);
try {
this.initInternal();
} catch (Throwable var2) {
ExceptionUtils.handleThrowable(var2);
this.setStateInternal(LifecycleState.FAILED, (Object)null, false);
throw new LifecycleException(sm.getString("lifecycleBase.initFail", new Object[]{this.toString()}), var2);
}
this.setStateInternal(LifecycleState.INITIALIZED, (Object)null, false);
}
可以看出,init()方法先将当前状态设置成了INITIALIZING,然后执行的是具体实现类的initInternal()方法。
再看看start()的源码:
public final synchronized void start() throws LifecycleException {
if(!LifecycleState.STARTING_PREP.equals(this.state) && !LifecycleState.STARTING.equals(this.state) && !LifecycleState.STARTED.equals(this.state)) {
if(this.state.equals(LifecycleState.NEW)) {
this.init();
} else if(this.state.equals(LifecycleState.FAILED)) {
this.stop();
} else if(!this.state.equals(LifecycleState.INITIALIZED) && !this.state.equals(LifecycleState.STOPPED)) {
this.invalidTransition("before_start");
}
this.setStateInternal(LifecycleState.STARTING_PREP, (Object)null, false);
try {
this.startInternal();
} catch (Throwable var2) {
ExceptionUtils.handleThrowable(var2);
this.setStateInternal(LifecycleState.FAILED, (Object)null, false);
throw new LifecycleException(sm.getString("lifecycleBase.startFail", new Object[]{this.toString()}), var2);
}
if(this.state.equals(LifecycleState.FAILED)) {
this.stop();
} else if(!this.state.equals(LifecycleState.STARTING)) {
this.invalidTransition("after_start");
} else {
this.setStateInternal(LifecycleState.STARTED, (Object)null, false);
}
} else {
if(log.isDebugEnabled()) {
LifecycleException t = new LifecycleException();
log.debug(sm.getString("lifecycleBase.alreadyStarted", new Object[]{this.toString()}), t);
} else if(log.isInfoEnabled()) {
log.info(sm.getString("lifecycleBase.alreadyStarted", new Object[]{this.toString()}));
}
}
}
由此可看到start方法判断了当前状态,如果状态正确执行的起始是子类的startInternal()方法
两个获取当前状态的方法:
在生命周期的相应方法中已经设置了state属性,这两个方法就是返回该属性。
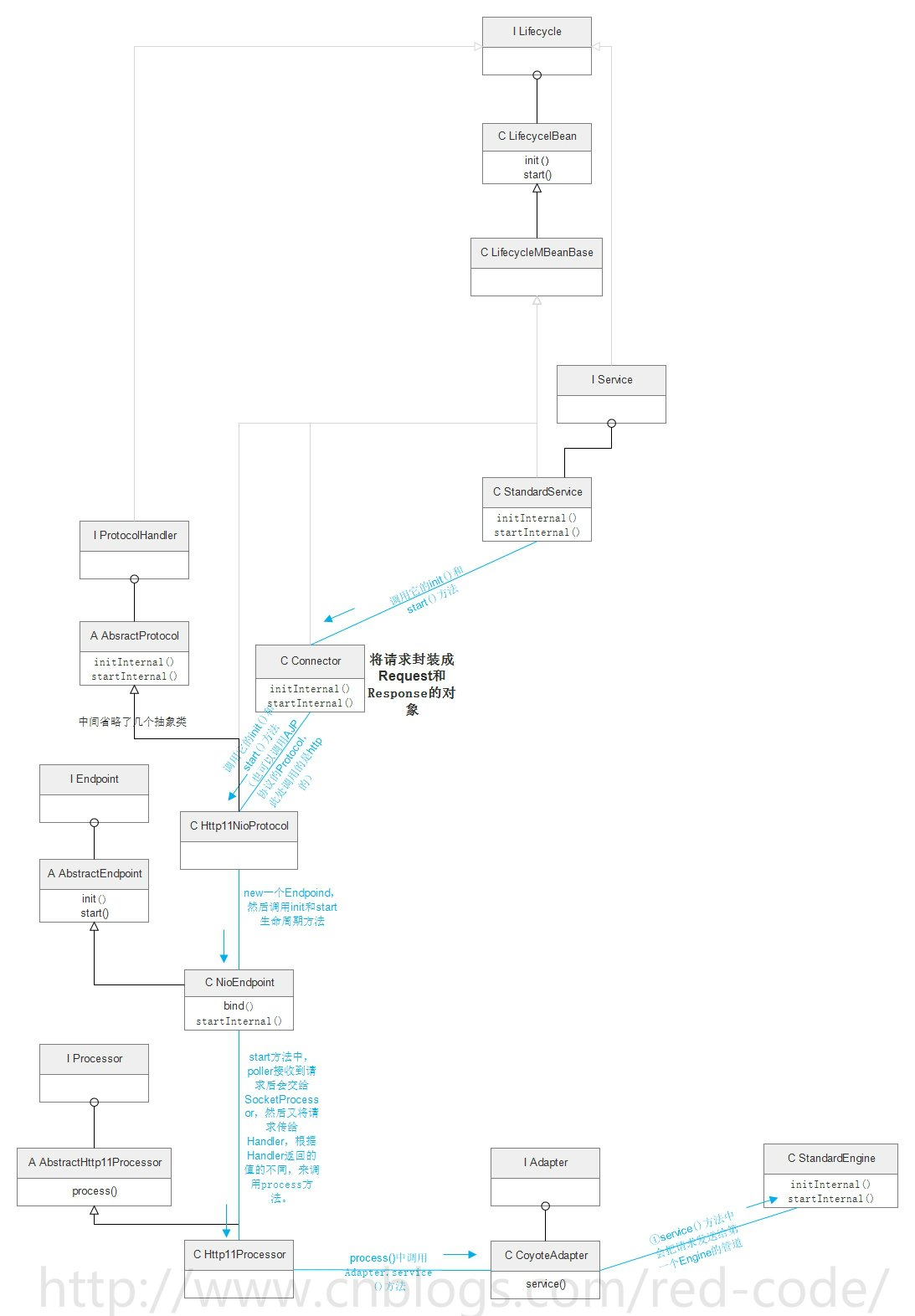
Connector
Connector的主要任务是负责处理浏览器发送过来的请求,并创建一个Request和Response的对象用于和浏览器交换数据,然后产生一个线程用于处理请求,Connector会把Request和Response对象传递给该线程,该线程的具体的处理过程是Container容器的事了。Container就是Servlet的容器,Container处理完后会吧结果返回给Connector,最后Connector使用socket将处理结果返回给客户端,整个请求处理完毕。
Connector的底层是使用socket进行连接,Request和Response时按照http协议(协议可选)来封装,所以Connector同时实现了TCP/IP和HTTP协议。
很明显Connector应该可以有多个,因为一次请求对应一个Connector,统一时间可能有多个请求。
Connector可以处理不同协议类型的请求,默认处理的是HTTP1.1协议。
Connector中使用ProtocolHandler来具体处理请求,不同的ProtocolHandler代表不同协议的请求类型。
ProtocolHandler中又包含三个重要的组件:
Endpoint,用于处理底层socket网络连接。
Processor,用于将socket接收到的socket封装成request。
Adapter,用于将requst交给Container进行处理。
具体执行顺序如下
一、之前讲过了,Catlina会调用load方法,根据server.xml配置文件创建Server对象,之后Server由调用init()创建service,service再调用Connector的init方法创建并初始化。
所以Connector是在Catlina会调用load方法时创建的。
二、Conntctor首先执行的是初始化init,Conntctor的初始化主要是用来初始化ProtocolHandler。
所以Conntctor执行init后:
1、先创建一个Adapter,并设置到ProtocolHandler中(这个Adapter后面要用,也就是上面所提到的用于将requst交给Container进行处理。)
2、调用ProtocolHandler的init方法,让它进行初始化。
3、调用mapperListener的init方法初始化(mapperListener作用是用来监听容器,容器发生变化会被通知)
三、刚刚上面提到了ProtocolHandler的init方法被调用了,我们在看看ProtocolHandler初始化都做了什么。
整个ProtocolHandler结构如下图:
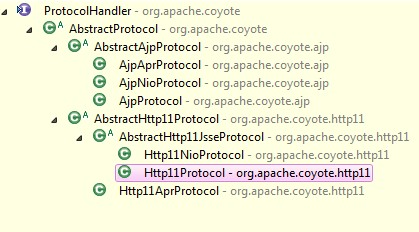
ProtocolHandler的初始化方法被实现于“AbstractProtocol抽象类”中。
该抽象类有两种子抽象类:AbstractAjpProtocol和AbstractHttp11Protocol,分别对应了两种不同的请求协议。
所以最终我们初始化的步骤其实是在AbstractHttp11Protocol抽象类中执行(当协议为HTTP时)。
配置文件server.xml中可以指明需要创建的ProtocolHandler类型,默认是处理HTTP1.1协议的ProtocolHandler,之后我们真正创建的就是AbstractHttp11Protocol抽象类的某一个子类(如Http11NioProtocol)
AbstractHttp11Protocol抽象类的初始化主要是调用了Endpoint的init初始化。
四、endpoint的init方法在抽象父类AbstractEndpoint中,是个模板方法,实际上调用的是子类NioEndpoint里面的bind()方法。
这里的bind()方法主要作用是,检查Acceptor和poller的线程数量是否正确(必须大于等于1)。
提一下Acceptor和poller这两个类,Acceptor的作用是控制与tomcat建立连接的数量,但Acceptor只负责建立连接。socket内容的读写是通过Poller来实现的。
此时Connector的init初始化就完成了。
五、Connector的init方法执行完后,会被调用执行startInternal方法。
同理,此方法会调用protocolHandler.start()方法。
然后protocolHandler的start又会调用endpoint.start()方法。
endpoint的start方法在抽象父类AbstractEndpoint中,是个模板方法,实际上调用的是子类NioEndpoint里面的startInternal()方法。
该方法主要做了:
1、初始化一些属性
2、根据之前定义的Acceptor和poller的线程数量,来启动相应数量的Acceptor和poller。
其中poller会将请求交给SocketProcessor,而SocketProcessor的职责就是把具体的请求处理过程委派给Handler,handler会执行Processor接口里的process()方法,进行“对request的解析,包括请求头、请求行和请求体”。
而这个process()方法是在抽象父类AbstractHttp11Processor里实现的,
process()方法会先从socket里读取http请求数据,并解析请求头,构造Request对象和Response对象。
六、process()方法最后会调用Adapter的service()方法。
Adapter接口只有一个实现类CoyoteAdapter。
service()完成“请求行和请求体的解析”,并把解析出来的信息封装到Request对象和Response对象中,之后service()便将封装了Request以及Response对象的Socket传给Container容器了。
传输的代码是:
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
即:先从Connector中获取service,然后从service中获取Container。接着再获取管道,再获取管道的第一个值Value,最后调用invoke()方法执行请求。
七、调用mapperListener的start方法。,该方法注册了已初始化的组件(在上面讲的Connector的init时初始化的mapperListener),然后为这些组件添加监听器,最后添加容器之间的映射关系。
此时Connector的startIntenal就完成了。
至此整个Connector启动完毕,大致的流程图如下(需要说明的是,下图中每个类或接口中所包含的方法我并没有全写出来,只写了与流程相关的几个,并且多处地方的子类选择不是唯一的,我画的该流程是基于获取HTTP1.1协议的请求):
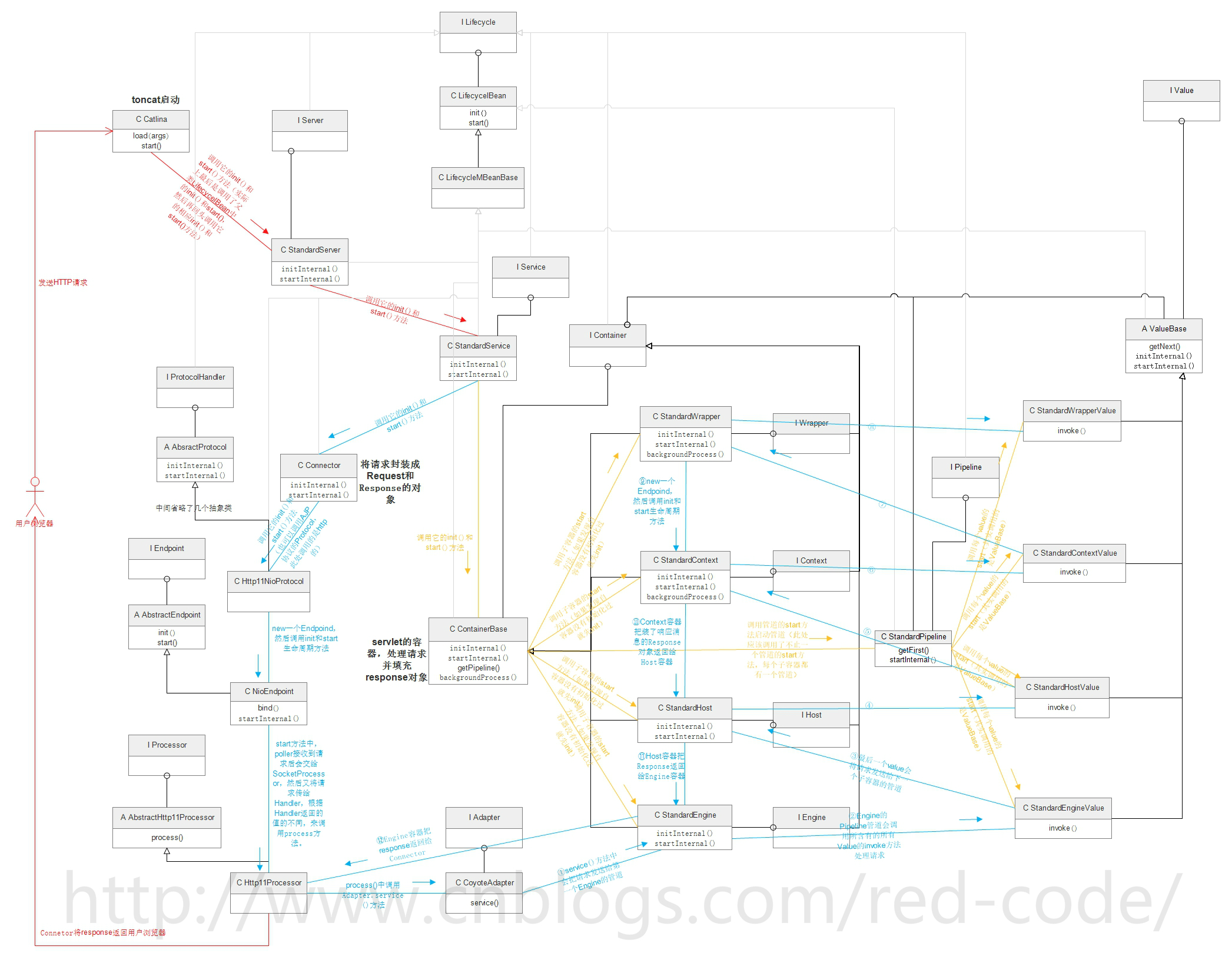
Container
Container容器是子容器的父接口,所有的子容器都继承该接口。
Container容器还继承Lifecycle接口,这样就拥有了完整的生命周期,他的子容器也就拥有了完整的生命周期。
Container接口的实现子类为ContainerBase,
其下的四个子容器接口为:Engine、Host、Context、Wrapper。他们之间是逐层包含的,每个service只能有一个Engine,一个Engine能够含有多个Host,每个Host可以含有多个Context,每个Context能够含有多个Wrapper。
四个子容器接口也有各自的子实现类,这些实现类继承自ContainerBase。
4中子容器的作用:
1、Engine:接收Connector传来的request和response,选择可用的Host来处理当前请求管理Host)。
2、Host:代表一个虚拟主机,也是一个站点。外面以www.demo.com/test这个url为例,www.demo.com这个域名就代表一个Host,该域名对应的就是webapps目录所代表的站点。
3、Context:代表一个应用,还是以www.demo.com/test这个url为例,通过域名可以直接访问到ROOT根目录里面的应用就是主应用。webapps/test目录可以通过www.demo.com/test访问到,这个test就又是一个子应用。于是这就是两个Context(每一个应用对应一个Context)。
所以www.demo.com下的应用都属于该Host站点。而其他的域名又是其他Host站点。
4、Wrapper:每一个Wrapper封装一个servlet。
这里需要特殊说明的是Container的四个子容器的生命周期:
1、虽然四个子容器的共同父类ContainerBase定义了initInternal()和startInternal()方法,但子容器还是可以根据自身情况再添加内容。
2、ContainerBase的init()方法是service初始化的时候调用的。但四个子容器的init方法“并不是”在ContainerBase的init()方法中被循环调用。而是在执行start()方法时,通过状态判定来调用的init()(如果没初始化就初始化)。
3、Context和Wrapper是“动态添加的”,在站点目录下每放置一个war包,就会动态添加一个Context,在web.xml里每配置一个servlet,就可以动态添加一个Wrapper。所以子容器的start方法不仅仅在“tomcat启动的时候会被调用”,当"父容器ContainerBase添加某个子容器时",也会调用该子容器的start()方法。
Container的执行流程为两条:
初始化
第一条流程为:Service执行init()调用Container的init()方法(注意,此时Container并不会调用子容器的init()方法),然后Service执行start()时调用Container的start,Container的start再循环调用每一个子容器的start()方法。然后再调用管道的“生命周期管理”(管道不需要初始化,所以在init()中不会调用)。第一条流程的流程图示如下:

Container的init()和start()方法执行内容如下:
一、Container的启动是通过init()和start()完成的。之前分析过这两个方法都会通过service来调用。
init()和start存在于LifecycelBean中,实际上最后调用的是ContainerBase中的initInternal()和startInternal()方法。
ContainerBase的initInternal方法主要是初始化了ThreadPoolExecutor类(startStopExecutor属性),用于管理启动和关闭的线程。
ThreadPoolExecutor继承自Executor用于管理线程,这里就不过多介绍了。
代码如下:
protected void initInternal() throws LifecycleException {
LinkedBlockingQueue startStopQueue = new LinkedBlockingQueue();
this.startStopExecutor = new ThreadPoolExecutor(this.getStartStopThreadsInternal(), this.getStartStopThreadsInternal(), 10L, TimeUnit.SECONDS, startStopQueue, new ContainerBase.StartStopThreadFactory(this.getName() + "-startStop-"));
this.startStopExecutor.allowCoreThreadTimeOut(true);
super.initInternal();
}
二、ContainerBase执行完initInternal后,会由于service的start的调用,执行ContainerBase的startInternal()方法。
代码如下:
protected synchronized void startInternal() throws LifecycleException {
this.logger = null;
this.getLogger();
//如果有Cluster和Realm,则调用他们的start方法。
Cluster cluster = this.getClusterInternal();
if(cluster != null && cluster instanceof Lifecycle) {
((Lifecycle)cluster).start();
}
Realm realm = this.getRealmInternal();
if(realm != null && realm instanceof Lifecycle) {
((Lifecycle)realm).start();
}
Container[] children = this.findChildren();
ArrayList results = new ArrayList();
//使用startStopExecutor调用新线程来启动每一个子容器
for(int fail = 0; fail < children.length; ++fail) {
results.add(this.startStopExecutor.submit(new ContainerBase.StartChild(children[fail])));
}
boolean var10 = false;
Iterator i$ = results.iterator();
while(i$.hasNext()) {
Future result = (Future)i$.next();
try {
result.get();
} catch (Exception var9) {
log.error(sm.getString("containerBase.threadedStartFailed"), var9);
var10 = true;
}
}
if(var10) {
throw new LifecycleException(sm.getString("containerBase.threadedStartFailed"));
} else {
//调用管道的启动方法
if(this.pipeline instanceof Lifecycle) {
((Lifecycle)this.pipeline).start();
}
//设置生命周期状态为STARTING状态。
this.setState(LifecycleState.STARTING);
//调用threadStart方法启动后台线程
this.threadStart();
}
}
startInternal()方法主要做了5件事:
1、如果有Cluster和Realm,则调用他们的start方法。
Cluster用于配置集群,在server.xml中可配置,它的作用是同步session。
Realm是tomcat的安全域,可以用来管理资源的访问权限。
2、使用startStopExecutor调用新线程来启动每一个子容器(即调用他们的start()方法),具体启动过程是通过一个for循环对每个子容器启动一个线程(这样可以多个线程同时启动,效率高),并将返回的Future保存到一个List中,然后遍历每个Future并调用其get方法。(下面详细说)
3、调用管道中Value的start方法来启动管道。(下面详细说)
4、设置生命周期状态为STARTING状态。
5、调用threadStart方法启动后台线程,该线程是一个while循环,定期调用backgroundProcess方法做一些事情,间隔时间可通过属性设置,单位是秒,如果小于0就不启动后台线程了。
backgroundProcess()方法在ContainerBase、StandardContext、StandardWrapper中都有实现。
ContainerBase中的backgroundProcess():调用了Cluster、Realm和管道的backgroundProcess()方法。
StandardContext中的backgroundProcess():调用ContainerBase中的backgroundProcess(),还对Session过期和资源变化进行了处理。
StandardWrapper中的backgroundProcess():调用ContainerBase中的backgroundProcess(),还会对jsp生成的servlet定期进行检查。
至此Container的启动就完成了,接下来我们详细的说一下上面的四个子容器的启动,和管道的启动。
先来看看使用startStopExecutor调用新线程来启动每一个子容器(即调用他们的start()方法)时,每一个子容器都干了些啥。
由于每一个子容器的接口都继承自Container接口,而Container接口又继承自Lifecycle接口,所以每一个子容器都有完整的生命周期(都拥有start和init方法),所以调用各个子容器的start方法实际上就是调用他们各自实现类的startInternal()方法。
StandardEngine
protected void initInternal() throws LifecycleException {
this.getRealm();
super.initInternal();
}
由源码可看出init方法调用了getRealm(),作用是如果没有配置Realm,则使用默认的NullPealm。然后调用了父类ContainerBase中的initInternal方法。
protected synchronized void startInternal() throws LifecycleException {
if(log.isInfoEnabled()) {
log.info("Starting Servlet Engine: " + ServerInfo.getServerInfo());
}
super.startInternal();
}
由源码可看出:startInternal()只是调用了父类的startInternal()方法。
StandardHost
Host的默认实现类StandardHost没有重写initInternal方法,所以初始化时调用的是父类的相应方法。
startInternal代码如下:
protected synchronized void startInternal() throws LifecycleException {
String errorValve = this.getErrorReportValveClass();
if(errorValve != null && !errorValve.equals("")) {
try {
boolean t = false;
Valve[] valves = this.getPipeline().getValves();
Valve[] valve = valves;
int len$ = valves.length;
for(int i$ = 0; i$ < len$; ++i$) {
Valve valve1 = valve[i$];
if(errorValve.equals(valve1.getClass().getName())) {
t = true;
break;
}
}
if(!t) {
Valve var9 = (Valve)Class.forName(errorValve).newInstance();
this.getPipeline().addValve(var9);
}
} catch (Throwable var8) {
ExceptionUtils.handleThrowable(var8);
log.error(sm.getString("standardHost.invalidErrorReportValveClass", new Object[]{errorValve}), var8);
}
}
super.startInternal();
}
由此看到此方法就是查看管道中是否有ErrorReportValve,如果没有就将他添加进去。判断的方法就是遍历管道里面的所有value,然后通过每个value的名字进行判断。
StandardContext
在startInternal中通过一个var25的boolean来判断是否进行下一步的处理,起始位true,当中途遇到问题后改为false,后面某些处理就不做了。
if(var25 && !this.listenerStart()) {
log.error(sm.getString("standardContext.listenerFail"));
var25 = false;
}
此处触发Listener(Listener定义在web.xml中)。
if(var25 && !this.filterStart()) {
log.error(sm.getString("standardContext.filterFail"));
var25 = false;
}
此处触发web.xml中配置的filter过滤器。
if(var25 && !this.loadOnStartup(this.findChildren())) {
log.error(sm.getString("standardContext.servletFail"));
var25 = false;
}
此处初始化了所有Servlet,即调用在web.xml中配置了load-on-startup的servlet的init方法初始化(load-on-startup的作用是标记容器是否在启动时加载此servlet)。
StandardWrapper
StandardWrapper没有重写initInternal方法,其startInternal()源码如下:
protected synchronized void startInternal() throws LifecycleException {
Notification notification;
if(this.getObjectName() != null) {
notification = new Notification("j2ee.state.starting", this.getObjectName(), (long)(this.sequenceNumber++));
this.broadcaster.sendNotification(notification);
}
super.startInternal();
this.setAvailable(0L);
if(this.getObjectName() != null) {
notification = new Notification("j2ee.state.running", this.getObjectName(), (long)(this.sequenceNumber++));
this.broadcaster.sendNotification(notification);
}
}
主要就做了三件事:
1、用broadcaster发送通知,只要用于JMX,
2、调用父类的startInternal方法
3、调用setAvailable方法,作用是设置Wrapper包含的所有servlet的有效的起始时间。
下面谈论管道的startInternal方法:
管道
由源码可知管道是在ContainerBase中启动的,而四个子容器都继承了ContainerBase,所以四个自容器都有属于自己的管道。
而每一个管道里装的都是“Value”类型,Value是接口,Value的实现类用于进行各种各样的具体处理操作。
所谓管道就是指多个处理者(value)对某一个请求“依次”进行处理,请求交给第一个value处理完后,再交给第二个value处理·····,每一条管道的“最后一个Value”都会有点特殊,该Value会将请求发送给下一个管道,然后下一个管道拿到请求后,继续交给该管道内的第一个value处理·····
举例,如:
请求到达Engine后,实际上是传给了Engine的管道(因为Engine继承了Container,所以他拥有StandardPipeline类型的管道),然后管道中有一个Value first属性,该属性是一个链式结构,存放在管道中first里面的Value是该管道的第一个value,而该value内部存在指针,指向他的下一个value。
管道就能依靠头value来遍历该管道内的每一个value,让他们依次处理请求。
而Engine管道的最后一个value为StandardEngineValue类,该value会将请求发送给Host的管道。
总结一下,每一个子容器都有它的StandardPipeline管道,每一条管道中装有多个value,value中的 invoke方法用来进行具体的处理请求,每个管道中的最后一个value会将请求传给下一个子容器的管道。(感觉自己有点啰嗦了。。。 (`・ω・´))
回到管道的生命周期讲解,
在ContainerBase中调用管道的启动方法(该语句存在于startInternal中):
if(this.pipeline instanceof Lifecycle) {
((Lifecycle)this.pipeline).start();
}
Pipeline的实现类为StandardPipeline类。该类中相应的源码为:
protected synchronized void startInternal() throws LifecycleException {
Valve current = this.first;
if(current == null) {
current = this.basic;
}
for(; current != null; current = current.getNext()) {
if(current instanceof Lifecycle) {
((Lifecycle)current).start();
}
}
this.setState(LifecycleState.STARTING);
}
首先调用了first属性赋值给了current,first属性里存储的是“第一个value”,并将它赋值到了当前value上。
之后做了一个判断,判断当前value是否为空,为空就将当前value设置为“最后一个value”。
之后从当前value(即:第一个value)开始调用start方法,每调用完一个,就将当前value的下一个value赋值到当前value上。即:循环调用该管道内所有value的start方法。
我们再来看一下value的start方法。
value继承于生命周期接口,所以调用start就是调用其子类的startInternal()方法。
所有的子value都继承于ValueBase类,而startInternal方法就是定义在ValueBase类里,源码如下:
protected synchronized void startInternal() throws LifecycleException {
this.setState(LifecycleState.STARTING);
}
可以看出ValueBase中的startInternal方法只做了一件事,就是将当前状态设置为STARTING。
至此,第一条流程就完成了。
传值
第二条流程为:Connector的Adapter将request和response传给Container的管道,从Engine的管道一路处理到Wrapper的管道,Wrapper再将response一路返回给Engine,然后Engine将response返回给Connector,Connector再返回给用户浏览器。
需要提前说明的是,四个自容器的管道中,每个管道都有多个value用来依次处理请求,但我在这主要分析“每个子容器管道的最后一个value”,分别是:StandardEngineValue、StandardHostValue、StandardContextValue、StandardWrapperValue。
StandardEngineValue
final class StandardEngineValve extends ValveBase {
private static final StringManager sm = StringManager.getManager("org.apache.catalina.core");
public StandardEngineValve() {
super(true);
}
public final void invoke(Request request, Response response) throws IOException, ServletException {
Host host = request.getHost();
if(host == null) {
response.sendError(400, sm.getString("standardEngine.noHost", new Object[]{request.getServerName()}));
} else {
if(request.isAsyncSupported()) {
request.setAsyncSupported(host.getPipeline().isAsyncSupported());
}
host.getPipeline().getFirst().invoke(request, response);
}
}
public final void event(Request request, Response response, CometEvent event) throws IOException, ServletException {
request.getHost().getPipeline().getFirst().event(request, response, event);
}
}
这里的invoke方法主要就做了一件事:
根据请求找到所对应的站点(Host),然后找到host的管道,调用其头部value的invoke方法,并把request和response传给他。
StandardHostValue
其invoke源码为:
public final void invoke(Request request, Response response) throws IOException, ServletException {
Context context = request.getContext();
if(context == null) {
response.sendError(500, sm.getString("standardHost.noContext"));
} else {
if(request.isAsyncSupported()) {
request.setAsyncSupported(context.getPipeline().isAsyncSupported());
}
boolean asyncAtStart = request.isAsync();
boolean asyncDispatching = request.isAsyncDispatching();
try {
context.bind(Globals.IS_SECURITY_ENABLED, MY_CLASSLOADER);
if(!asyncAtStart && !context.fireRequestInitEvent(request)) {
return;
}
try {
if(asyncAtStart && !asyncDispatching) {
if(!response.isErrorReportRequired()) {
throw new IllegalStateException(sm.getString("standardHost.asyncStateError"));
}
} else {
context.getPipeline().getFirst().invoke(request, response);
}
} catch (Throwable var10) {
ExceptionUtils.handleThrowable(var10);
if(response.isErrorReportRequired()) {
this.container.getLogger().error("Exception Processing " + request.getRequestURI(), var10);
} else {
request.setAttribute("javax.servlet.error.exception", var10);
this.throwable(request, response, var10);
}
}
response.setSuspended(false);
Throwable t = (Throwable)request.getAttribute("javax.servlet.error.exception");
if(!context.getState().isAvailable()) {
return;
}
if(response.isErrorReportRequired()) {
if(t != null) {
this.throwable(request, response, t);
} else {
this.status(request, response);
}
}
if(!request.isAsync() && (!asyncAtStart || !response.isErrorReportRequired())) {
context.fireRequestDestroyEvent(request);
}
} finally {
if(ACCESS_SESSION) {
request.getSession(false);
}
context.unbind(Globals.IS_SECURITY_ENABLED, MY_CLASSLOADER);
}
}
}
Host的用处再上上面已经讲过了,一个host代表一个站点(也叫一个虚拟主机),
其处理过程可以总结如下:
1、先根据request请求,选择一个context容器。如果不为空,则继续处理。
2、调用Context容器的bind()方法。此方法获取一条线程,然后让该线程处理Context。
3、获取context的管道,再调用管道中头value的invoke方法,将request和response传入其中。
StandardContextValue
其invoke源码如下:
public final void invoke(Request request, Response response) throws IOException, ServletException {
MessageBytes requestPathMB = request.getRequestPathMB();
if(!requestPathMB.startsWithIgnoreCase("/META-INF/", 0) && !requestPathMB.equalsIgnoreCase("/META-INF") && !requestPathMB.startsWithIgnoreCase("/WEB-INF/", 0) && !requestPathMB.equalsIgnoreCase("/WEB-INF")) {
Wrapper wrapper = request.getWrapper();
if(wrapper != null && !wrapper.isUnavailable()) {
try {
response.sendAcknowledgement();
} catch (IOException var6) {
this.container.getLogger().error(sm.getString("standardContextValve.acknowledgeException"), var6);
request.setAttribute("javax.servlet.error.exception", var6);
response.sendError(500);
return;
}
if(request.isAsyncSupported()) {
request.setAsyncSupported(wrapper.getPipeline().isAsyncSupported());
}
wrapper.getPipeline().getFirst().invoke(request, response);
} else {
response.sendError(404);
}
} else {
response.sendError(404);
}
}
其处理过程可以总结如下:
1、先获取request的请求路径,该路径不能直接访问WEB-INF或者META-INF目录下的资源。
2、再根据request,选择合适的Wrapper。
3、再在response中设置一个sendAcknowledgement(在TCP/IP协议中,如果接收方成功的接收到数据,那么会回复一个ACK数据。)
4、获取Wrapper的管道,再调用管道中头value的invoke方法,将request和response传入其中。
StandardWrapperValue
每个Wrapper都封装着一个servlet,所以Wrapper和servlet有着很深的联系。
StandardWrapper里会加载他代表的servlet并创建实例(即调用它的init方法),但不会调用servlet的service方法。
StandardWrapperValue会调用sertvlet的service方法。
其具体执行顺序如下,
1、分配一个Servlet实例,因为StandardWrapper负责加载servlet,所以也是从Wrapper中获取servlet。
try {
if(!unavailable) {
servlet = wrapper.allocate();
}
} catch (UnavailableException var38) {
this.container.getLogger().error(sm.getString("standardWrapper.allocateException", new Object[]{wrapper.getName()}), var38);
long requestPathMB = wrapper.getAvailable();
if(requestPathMB > 0L && requestPathMB < 9223372036854775807L) {
response.setDateHeader("Retry-After", requestPathMB);
response.sendError(503, sm.getString("standardWrapper.isUnavailable", new Object[]{wrapper.getName()}));
} else if(requestPathMB == 9223372036854775807L) {
response.sendError(404, sm.getString("standardWrapper.notFound", new Object[]{wrapper.getName()}));
}
} catch (ServletException var39) {
this.container.getLogger().error(sm.getString("standardWrapper.allocateException", new Object[]{wrapper.getName()}), StandardWrapper.getRootCause(var39));
throwable = var39;
this.exception(request, response, var39);
} catch (Throwable var40) {
ExceptionUtils.handleThrowable(var40);
this.container.getLogger().error(sm.getString("standardWrapper.allocateException", new Object[]{wrapper.getName()}), var40);
throwable = var40;
this.exception(request, response, var40);
servlet = null;
}
2、执行Servlet相关的所有过滤器:
ApplicationFilterChain filterChain = ApplicationFilterFactory.createFilterChain(request, wrapper, servlet);
try {
if(servlet != null && filterChain != null) {
if(context.getSwallowOutput()) {
boolean var29 = false;
try {
var29 = true;
SystemLogHandler.startCapture();
if(request.isAsyncDispatching()) {
((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch();
var29 = false;
} else if(comet1) {
filterChain.doFilterEvent(request.getEvent());
var29 = false;
} else {
filterChain.doFilter(request.getRequest(), response.getResponse());
var29 = false;
}
} finally {
if(var29) {
String time = SystemLogHandler.stopCapture();
if(time != null && time.length() > 0) {
context.getLogger().info(time);
}
}
}
String t2 = SystemLogHandler.stopCapture();
if(t2 != null && t2.length() > 0) {
context.getLogger().info(t2);
}
} else if(request.isAsyncDispatching()) {
((AsyncContextImpl)request.getAsyncContext()).doInternalDispatch();
} else if(comet1) {
filterChain.doFilterEvent(request.getEvent());
} else {
filterChain.doFilter(request.getRequest(), response.getResponse());
}
}
}
ApplicationFilterChain可以看做是一个“过滤器链”,StandardWrapperValve中的invoke会先创建该类的实例,然后调用它的doFilter方法,即从该链中的第一个过滤器开始调用。如果执行到了最后一个过滤器,就开始调用Servlet的service方法。
3、关闭过滤器链
if(filterChain != null) {
if(request.isComet()) {
filterChain.reuse();
} else {
filterChain.release();
}
}
4、通知Wrapper,重新委派处理完毕的servlet。
try {
if(servlet != null) {
wrapper.deallocate(servlet);
}
} catch (Throwable var31) {
ExceptionUtils.handleThrowable(var31);
this.container.getLogger().error(sm.getString("standardWrapper.deallocateException", new Object[]{wrapper.getName()}), var31);
if(throwable == null) {
throwable = var31;
this.exception(request, response, var31);
}
}
至此Container第二条流程也完成了。
总结出来,简易流程图如下:
tomcat原理详解的更多相关文章
- TOMCAT原理详解及请求过程(转载)
转自https://www.cnblogs.com/hggen/p/6264475.html TOMCAT原理详解及请求过程 Tomcat: Tomcat是一个JSP/Servlet容器.其作为Ser ...
- TOMCAT原理详解及请求过程
Tomcat: Tomcat是一个JSP/Servlet容器.其作为Servlet容器,有三种工作模式:独立的Servlet容器.进程内的Servlet容器和进程外的Servlet容器. Tomcat ...
- Tomcat学习(二)------Tomcat原理详解及请求过程
Tomcat: Tomcat是一个JSP/Servlet容器.其作为Servlet容器,有三种工作模式:独立的Servlet容器.进程内的Servlet容器和进程外的Servlet容器. Tomcat ...
- Tomcat启动过程原理详解 -- 非常的报错:涉及了2个web.xml等文件的加载流程
Tomcat启动过程原理详解 发表于: Tomcat, Web Server, 旧文存档 | 作者: 谋万世全局者 标签: Tomcat,原理,启动过程,详解 基于Java的Web 应用程序是 ser ...
- sso单点登录原理详解
sso单点登录原理详解 01 单系统登录机制 1.http无状态协议 web应用采用browser/server架构,http作为通信协议.http是无状态协议,浏览器的每一次请求,服务 ...
- I2C 基础原理详解
今天来学习下I2C通信~ I2C(Inter-Intergrated Circuit)指的是 IC(Intergrated Circuit)之间的(Inter) 通信方式.如上图所以有很多的周边设备都 ...
- tomcat配置文件详解
Tomcat系列之服务器的安装与配置以及各组件详解 tomcat 配置文件详解
- Zigbee组网原理详解
Zigbee组网原理详解 来源:互联网 作者:佚名2015年08月13日 15:57 [导读] 组建一个完整的zigbee网状网络包括两个步骤:网络初始化.节点加入网络.其中节点加入网络又包括两个 ...
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
随机推荐
- 网格视图GridView的使用
网格视图GridView的排列方式与矩阵类似,当屏幕上有很多元素(文字.图片或其他元素)需要按矩阵格式进行显示时,就可以使用GridView控件来实现. 本文将以一个具体的实例来说明如何使用GridV ...
- win10 java环境变量
https://jingyan.baidu.com/article/fd8044fa2c22f15031137a2a.html
- Jenkins与Gitlab集成
一.安装jenkinshttps://mirrors.tuna.tsinghua.edu.cn/jenkins/redhat/ #清华yum源 yum -y install java-1.8. ...
- Cron 表达式详解(已整理、很清晰)
Cron表达式是一个字符串,字符串分为6或7个域,每一个域代表一个含义,Cron有如下两种语法格式: Seconds Minutes Hours DayofMonth Month DayofWeek ...
- spring boot 2.0(一)权威发布spring boot2.0
Spring Boot2.0.0.RELEASE正式发布,在发布Spring Boot2.0的时候还出现一个小插曲,将Spring Boot2.0同步到Maven仓库的时候出现了错误,然后Spring ...
- rancher2.x添加node的坑。
启动rancher server后,添加一台新节点为k8s的节点.设置如下 ps:worker:k8s的agent端 control:k8s的第二个master etcd:第二个etcd 坑1:节点上 ...
- 解决validaform先验证后 ajax提交
$(".myfroms").Validform({//form class btnSubmit:".submitLayer", 绑定提交按钮 tiptype:4 ...
- jq判断网页是在什么浏览器打开的
有的时候项目中有需要用户扫描二维码进行页面识别跳转操作的,(类似当前需要先判断是否为手机默认浏览器打开,尤其是微信打开会影响APP包的下载-微信内置的一个拦截,这对Android来说影响有点大),因此 ...
- js向一个数组中插入元素的几个方法-性能比较
向一个数组中插入元素是平时很常见的一件事情.你可以使用push在数组尾部插入元素,可以用unshift在数组头部插入元素,也可以用splice在数组中间插入元素. 但是这些已知的方法,并不意味着没有更 ...
- [转载]Python使用@property装饰器--getter和setter方法变成属性
原贴:为什么Python不需要getter和setter getter 和 setter在java中被广泛使用.一个好的java编程准则为:将所有属性设置为私有的,同时为属性写getter和sette ...