Java并发容器和框架
ConcurrentHashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率近100%。因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,会死循环的获取Entry。
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable(){
public void run(){
for(int i = 0; i < 1000; i++){
new Thread(new Runnable(){
public void run(){
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
t.start();
t.join();
HashTable使用synchronized保证线程安全,但在线程竞争激烈的情况下HashTable的效率低下。当一个线程访问HashTable的同步方法时,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态访问。HashTable在多个线程访问的时需要竞争同一把锁,因此效率低下。ConcurrencyHashMap采用锁分段技术。先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个数据的时候,其他段的数据也能被其他线程访问。
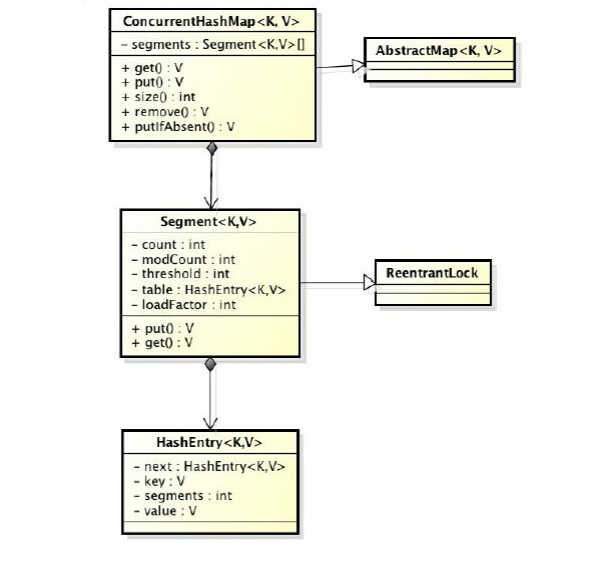
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrencyHashMap中扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HasnEntry数组里的元素,党对HashEntry数组的数据进行修改时,必须先获取与它对应的Segment的锁。
ConcurrentHashMap的初始化方法是通过initialCapacity,loadFactor和concurrencyLevel等几个参数来初始化segment数组,段偏移量segmentShifr,段掩码segmentMask和每个segment里的HashEntry数组来实现的。
if(concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
while(ssize < concurrencyLevel){
++sshift;
ssize <<= 1;
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
segments数组的长度ssize是通过concurrencyLevel计算得出的。为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方(power-of-two size),所以必须计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。concurrencyLevel的最大值是65535,这意味着segments数组的长度最大为65536,对应的二进制是16位。
segmentShift和segmentMask需要在定位segment时的散列算法里使用。sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移动4次,所以sshift为4。segmentShift用于定位参与散列运算的位数,segmentShift等于32(ConcurrentHashMao的hash*(输出的最大数是32位)减sshift,即2。segmentMask是散列运算的掩码,等于ssize减1,即15。掩码的二进制各个位的值都是1.因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1。
初始化每个segment
输入参数intialCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过这两个参数来初始化数组中的每个segment。
if(initialCapacity > MAXIMUM_CAPACITY){
initialCapacity = MAXIMUM_CAPACITY;
}
int c = initialCapacity / ssize;
if(c * ssize < initialCapacity)
++c;
int cap = 1; //segment中的HashEntry数组的长度
while(cap < c)
cap <<= 1;
for(int i = 0; i < this.segments.length; ++i)
this.segments[i] = new Segment<K, V>(cap, loadFactor); //segment的容量threshold=(int)cap*loadFactor。默认情况下,initialCapacity是16,loadFactor是0.75,cap为1,threshod为0
定位Segment
ConcurrentHashMap会使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再散列。再进行散列的目的是减少散列冲突,使元素能够均匀地分布在不同的Segment上,从而提高容器的存取效率、
private static int has(int h){
h += (h << 15) ^ 0xffffcd7d;
h ^= (h >>> 10);
h += (h << 3);
h ^= (h >>> 6);
h += (h << 2) + (h << 14);
return h ^ (h >>> 16);
}
ConcurrentHashMao通过散列算法定位segment。默认情况下,segmentShift为28,segmentMask为15,在散列后的数最大是32位的二进制数据,向右无符号移动28位(让高4位参加到散列运算中),
final Segment<K, V> segmentFor(int hash){
return [segments(hash >>> segmentShift) & segmentMask];
}
ConcurrentHashMap的操作
get():先经过一次散列,然后在使用这个散列值通过算咧运算定位到Segment,再通过散列算法定位到元素。get整个过程都不需要加锁,除非读到的值是空才会加锁重读。get方法里将要使用的共享变量都定义成了volatile类型。因为Java内存模型的happen before原则,对volatile字段的写入操作会优先于读操作,即使两个线程同时修改和获取volatile变量,get操作也可以拿到最新值。定位HashEntry和定位的Segment的散列算法虽然都是与数组的长度减去1再相"与",定位Segment使用的是元素的hashcode通过再散列后得到的值的高位,而定位HashEntry直接使用过的是散列后的值。
public V get(Object key){
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
}
put():put需要对共享变量进行写入操作,所以在操作共享变量是必须加锁。put先定位到Segment,然后在Segment里面进行插入操作。插入操作经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二部定位添加元素的位置,然后将其放在HashEntry数组里面。
是否需要扩容:在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),若超过阈值,则对数组进行扩容。Segment的扩容判断比HashMap更恰当,若HashMap在插入元素后判断元素已经达到容量后再进行扩容,之后若没有新元素插入,则HashMap就进行了无效的扩容
如何扩容:在扩容时,先创建一个容量是原来容量二倍的数组,然后将原数组里的元素进行再散列后插入到新的数组中,ConcurrentHashMap只会对某个segment进行扩容。
size():统计整个ConcurrentHashMap里元素的大小。ConcuurentHashMap先尝试2次通过不锁住Segment的方式来统计各个Segment大小。若统计过程中容器的count发生了变化(使用modCount变量,在put,remove和clean方法元素操作前将变量modCount加1,在统计size前后比较modCount是否发生变化),则再采用加锁的方式来统计所有Segment的大小。
实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队出队同一把锁)或两个锁(入队和出队用不同的锁)等方式起来实现。非阻塞的实现方式则可以使用循环CAS的方式来实现
ConcurrentLinkedQueue
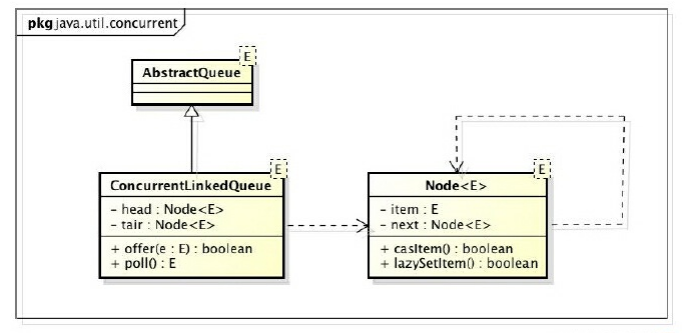
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列。它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free“算法来实现。ConcurrentLinkedQueue由head节点和tail节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成,该节点与节点之间就是通过next关联起来,从而组成一张链表结构的队列。默认情况下head节点存储的元素为空,tail节点等于head节点。
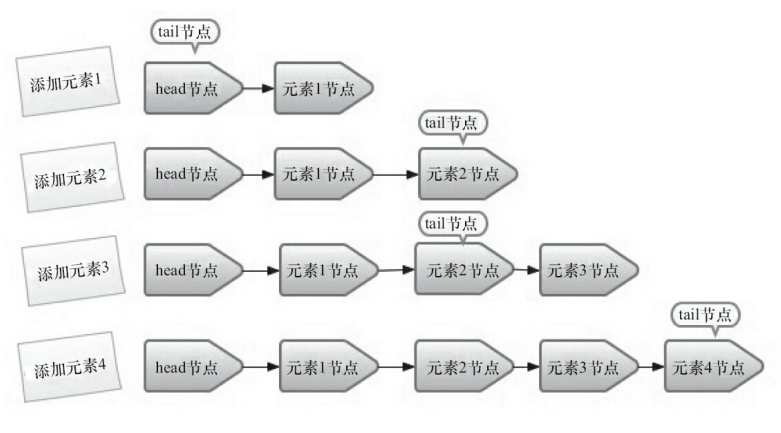
入队列
入队列就是将入队节点添加到队列的尾部。入队主要做两件事:第一是将入队节点设置成当前队列尾节点的下一个节点;第二是更新tail节点,若tail节点的next节点不为空,则将入队节点设置成tail节点,若tail节点的next节点为空,则将入队节点设置城tail的next节点,所以tail节点不总是尾节点。
public boolean offer(E e){
if(e == null)
throw new NullPointerException();
Node<E> n = new Node<E>(e);
retry:
// 入队不成功反复入队
for(;;){
Node<E> t = tail;
Node<E> p = t;
for(int hops = 0; ; hops++){
// 获取p的下一个节点
Node<E> next = succ(p);
if(next != null){
if(hops > HOPS && t != tail)
continue retry;
p = next;
}else if(p.casNext(null, n)){
//若tail节点有大于等于1个next节点,则将入队节点设置成tail节点。
if(hops >= HOPS)
casTail(t, n);
return true; //永远返回true,不要通过返回值判断入队是否成功
}else{
p = succ(p);
}
}
}
}
定位尾节点
tail节点并非总是尾节点。尾节点可能是tail节点,也可能是tail节点的next节点。
final Node<E> succ(Node<E> p){
Node<E> next = p.getNext();
return (p==next) head : next;
}
设置入队节点为尾节点
p.casNext(null, n)方法将入队节点设置为当前队尾节点的next节点,若p是null则表示p是当前队列的尾节点,若不为null,则表示有其他线程更新了尾节点,需要重新获取当前队列的尾节点
HOPS
doug lea使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将tail节点更新为尾节点,而是当tail节点和尾节点的距离大于等于常量HOPS的值时才更新tail节点,tail和尾节点的距离越长,使用CAS更新tail节点的次数就会越少,但每次入队时定位尾节点的时间久越长
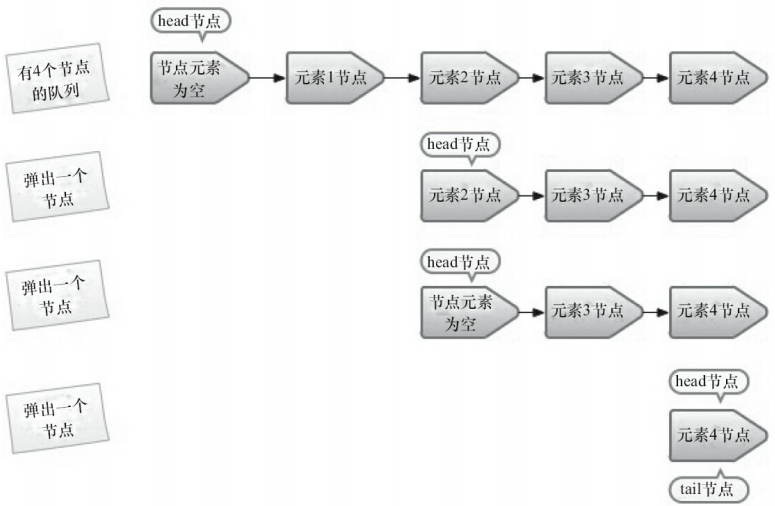
出队列
出队列就是从队列里返回一个节点元素,并清空该节点对元素的引用。当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。当head节点没有元素时,出队操作才会更新head节点。
public E poll(){
Node<E> h = head;
Node<E> p = h;
for(int hops = 0; ; hops++){
// 获取p节点元素
E item = p.getItem();
// 若p节点的元素不为空,使用CAS设置p几点引用的元素为null,成功则返回p
if(item != null && p.casItem(item, null)){
if(hops >= HOPS){
Node<E> q = p.getNext();
updateHead(h, (q != null) q : p);
}
return item;
}
//若头节点的元素为空或头节点发生了变化,则头节点已被另一个线程改了,此时选取p的下一个节点
Node<E> next = succ(p);
// 若p的下一个节点也空,则说明队列已空
if(next == null){
updateHead(h, p);
break;
}
// 若一个元素不为空,则将头节点的下一个节点设置成头节点
p = next;
}
return null;
}
阻塞队列
阻塞队列是一个支持两个附件操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
支持阻塞的插入方法:当队列满时,队列会阻塞插入元素的线程,直到队列不满时
支持阻塞的移除方法:在队列为空时,获取元素的线程会等待队列变为非空
阻塞队列常用于生产者进而消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素,消费者用来获取元素的容器。
插入和移除操作的4种处理方式
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
| 插入方法 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除方法 | remove() | poll() | take() | poll(time, unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
抛出异常:当队列满时,若再往队列里插入元素,会抛出IllegalStateException("Queuefull")异常。当队列空时,从队列里获取元素会抛出NoSuchElementException异常。
返回特殊值:当往队列插入元素时,会返回元素是否插入成功,成功返回true。若移除方法,则是从队列里取出一个元素,否则返回null。
一直阻塞:当阻塞队列满时,若生产者线程往队列里put元素,队列会一直阻塞生产者线程,直到队列可用或响应中断退出。当队列空时,若消费者线程从队列里take元素,队列会阻塞住消费者线程,直到队列不为空。
超时退出:当阻塞队列满时,若生产者线程往队列里插入元素,队列会阻塞生产者线程一段时间。若超过指定时间,生产者线程就会退出。
JDK提供7个阻塞队列
ArrayBlockingQueue:由数组结构组成的有界阻塞队列
LinkedBlockingQueue:由链表结构组成的有界阻塞队列
PriorityBlockingQueue:支持优先级排序的无界阻塞队列
DelayQueue:使用优先级队列实现的无界阻塞队列
SychronousQueue:不存储元素的阻塞队列
LinkedTransferQueue:链表结构组成的无界阻塞队列
LinkedBlockingDeque:由链表结构组成的双向阻塞队列
公平访问队列是指阻塞的线程,可以按照阻塞的先后顺序访问队列,即先阻塞线程先访问队列。非公平性是对等待的线程是非公平的,当队列可用时,阻塞的线程都可以争夺访问队列的资格,有可能县阻塞的线程最后才访问队列。
ArrayBlockingQueue
ArrayBlockingQueue按照先进先出的原则对元素进行排序。默认情况下不保证线程公平的访问队列
public ArrayBlockingQueue(int capacity, boolean fair){
if(capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
LinkedBlockingQueue
LinkeBlockingQueue的默认的和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序。
PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排序。也可以自定义类实现compareTo()方法来指定元素排序规则,或初始化PriorityBlockingQueue时指定构造参数Comparator来对元素进行排序。不能保证同优先级元素的顺序。
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从对了了中提取元素。
应用场景如下:
缓存系统的设计:可以使用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了
定时任务调度:使用DelayQueue保存当前将会执行的任务和执行时间,一旦从DelayQueue中获取到到任务就开始执行。
实现Delayed接口:
在创建对象时,初始化基本数据。使用time记录当前对象延迟到什么时候可以使用,使用sequenceNumber来标识元素在队列中的先后顺序。
private static final AtomicLong sequencer = new AtomicLong(0);
ScheduledFutureTask(Runnable r, V result, long ns, long period){
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
实现getDelay方法。该方法返回当前元素还需要延时多长时间,单位是纳秒。
public void getDelay(TimeUnit unit){
return unit.convert(time - now(), TimeUnit.NANOSECONDS);
}
实现compareTo方法来指定元素的顺序。
public int compareTo(Delayed other){
if(other == this)
return 0;
if(other instanceof ScheduledFutureTask){
ScheduledFutureTask<> x = (ScheduledFutureTask<>) other;
long diff = time - x.time;
if(diff < 0)
return -1;
else if(diff > 0)
return 1;
else if(sequenceNumber < x.sequenceNumber)
return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) 0 : ((d < 0) -1 : 1);
}
延时阻塞队列的实现
当消费者从队列里获取元素时,若元素没有达到延时时间,就阻塞当前线程
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if(delay <= 0)
return q.poll();
else if(leader != null) // leader是一个等待获取队列头部元素的线程。若leader不等于空,表示已经有线程在等待获取队列的头元素
available.await();
else{
Thread thisThread = Thread.currentThread();
leader = thisThread;
try{
available.awaitNanos(delay);
}finally{
if(leader == thisThread)
leader = null;
}
}
SynchronousQueue
SynchronousQueue的每一个put操作必须等待一个take操作,否则不能继续添加元素。它支持公平访问队列。默认情况下线程采用非公平性策略访问队列
public SynchronousQueue(boolean fair){
transferer = fair ? new TransferQueue() : new TransferStack();
}
SynchronousQueue负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素。
LinkedTransferQueue
transfer():当前有消费者正在等待接收元素(消费者使用take()或带有时间限制的poll()),transfer方法可以把生产者传入的元素立刻transfer给消费者。若没有消费者在等待接收元素,transfer方法将元素存放在队列的tail节点,并等待该元素被消费者消费了才返回。
Node pre = tryAppend(s, haveData); //将当前节点作为tail节点
return awaitMatch(s, pred, e, (how == TIMED), nanos); //让CPU自旋等待消费者消费元素
tryTransfer():用来试探生产者传入的元素是否能直接传给消费者。若没有消费者接受元素,则返回false。tryTransfer方法无论消费者是否接受都立刻返回,而transfer方法必须等到消费者消费后才返回。tryTransfer(E e, long timeout, TimeUnit unit)方法试图把生产者传入的元素直接传给消费者,若没有消费者消费该元素则等待指定的时间再返回,若超时还没消费元素,则返回false,若在超时时间内消费了元素,则返回true。
LinkedBlockingDeque
LinkedBlockingDeque是由链表组成的双向阻塞队列。双向队列指的是可以从队列的两端插入和移除元素。双向队列因为多了一个操作对了的入口,在多线程同时入队时,减少了一半的竞争。相对于其他阻塞队列,LinkedBlockingDeque多了addFirst,addList,offerFirst,offerLast,peekFirst和peekLast等方法。
阻塞队列的实现原理
使用通知模式的实现
通知模式就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个对了中的元素后,会通知生产者当前队列可用。
private final Condition notFull;
private finla Condition notEmpty;
public ArrayBlockingQueue(int capacity, boolean fair){
notEmpty = lock.newCondition();
notFull = lock.newCondition();
} public void put(E e) throws InterruptedException{
checkNotFull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try{
while(count == items.length)
notFull.await();
insert(e);
}finally{
lock.unlock();
}
} public E take() throws InterruptedException(){
final ReentrantLock lock = this.lock;
lock.lokcInterruptibly();
try{
while(count == 0)
notEmpty.await();
return extract();
}finally{
lock.unlock();
}
} private void insert(E x){
items[putIndex] = x;
putIndex = inc(putIndex);
++count;
notEmpty.signal();
}
当往队列里插入一个元素时,若对了不可用,那么阻塞生产者主要通过LockSupport.park(this)来实现
pubilc final void await() throws InterruptedException{
if(Thread.interrupted())
throw new InterruptedException();
Node node = addConditionWaiter();
int savedState = fullRelease(node);
int interruptMode = 0;
while(!isOnSyncQueue(node)){
LockSupport.park(this);
if((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
if(acquireQueued(node, savedState) && interrutMode != THROW_IE)
interruptMode = REINTERRUPT;
if(node.nextWaiter != null)
unlinkCancelledWaiters();
if(interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
public static void park(Object blocker){
Thread t = Thread.currentThread();
setBlocker(t, blocker);
unsafe.park(false, 0L);
setBlocker(t, null);
}
park会阻塞当前线程,只有一下4种情况中的一种发生时,该方法才会返回:
与park对应的unpark执行或已经执行时。“已经执行”是指unpark先执行,然后在执行park的情况
线程被中断时
等待完time参数指定的毫秒数时
异常现象发生时
JVM在linux下实现park的方式是使用系统方法pthread_cond_wait。pthread_cond_wait是一个多线程的条件变量函数。这个方法接受两个参数:一个共享变量_cond,一个互斥量_mutex,unpark是使用pthread_cond_signal实现的。
Fork/Join
Fork/Join是一个把大人物分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
工作窃取(work-stealing)算法
工作窃取算法是指某个线程从其他队列里窃取任务来执行。
当把一个当任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并未每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。有的线程会先干完自己的任务,此时其他线程对应的队列里还有任务等待处理。于是该线程就去其他线程的队列里窃取一个任务来做。此时他们会访问同一个队列,为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从队列的头部拿任务执行,窃取任务的线程从双端队列的尾部任务执行。
优点:充分利用线程进行并行计算,减少了线程间的竞争
缺点:在双端队列里只有一个任务时会存在竞争,并且该算法会消耗了更多的系统资源。
设计
分割任务:需要一个fork类来把大任务分割成子任务,需要不停地分割直到分割出的子任务足够小。
执行任务并合并结果:分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据
Fork/Join使用两个类来完成上述设计:
ForkJoinTask:需要使用ForkJoin框架,必须先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承ForkJoinTask,只需要继承它的子类,Fork/Join只提供了两个子类:
RecursiveAction:用于没有返回结果的任务
RecursiveTask:用于有返回结果的任务
ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他线程的队列的尾部获取一个任务。
public class CountTask extends RecursiveTask<Integer>{
private static final int THRESHOLD = 2;
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
boolean canCompute = (end - start) <= THRESHOLD;
if(canCompute){
for(int i = start; i <= end; i++)
sum += i;
}else{
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
leftTask.fork(); // 每个子任务调用fork方法时又会进入compute方法,看当前子任务是否有必要分割成子任务,若不需要则执行当前任务,否则继续分割。
rightTask.fork();
int leftResult = leftTask.join();
int rightResult = rightTask.join();
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(1, 4);
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (Exception e) {
}
}
}
ForkJoinTask在执行的时候可能会抛出异常,但是没办法在主线程中捕获异常。ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已被取消。并且可以通过ForkJoinTask的getException方法获取异常。getException方法返回Throwable对象,若任务被取消了则返回CancellationException。若任务没有完成或被抛出,则返回null。
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
ForkJoinTask的fork方法实现原理
当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步地执行这个任务,然后立即返回结果。
public final ForkJoinTask<V> fork(){
((ForkJoinWorkerThread) Thread.currentThread()).pushTask(this);
return this;
}
push方法把当前任务存放在ForkJoinTask数组队列里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行。
final void pushTask(ForkJoinTask<> t){
ForkJoinTask<>[] q;
int s, m;
if((q = queue) != null){
long u = (((s = queueTop) & (m = q.length -1)) << ASHIFT) + ABASE;
UNSAFE.putOrderedObject(q, u, t);
queueTop = s + 1;
if((s -= queueBase) <= 2)
pool.signalWork();
else if(s == m)
growQueue();
}
}
ForkJoinTask的join方法实现原理
Join方法的主要作用是阻塞当前线程并等待获取结果。
public final V join(){
jf(doJoin() != NORMAL)
return reportResult();
else
return getRawResult();
}
private V reportResult(){
int s;
Throwable ex;
if((s = status) == CANCELLED)
throw new CancellationException();
if(s == EXCEPTIONAL && (ex = getThrowableException()) != null)
UNSAFE.throwException(ex);
return getRawResult();
}
调用doJoin()方法得到当前任务的状态来判断返回什么结果。任务状态由4种:已完成(NORMAL),被取消(CANCELLED),信号(SIGNAL)和出现异常(EXCEPTIONAL)。
若任务状态是已完成,则直接返回任务结果
若任务状态是被取消,则直接抛出CancellationException
若任务状态是抛出异常,则直接抛出对应的异常
private int doJoin(){
Thread t;
ForkJoinWorkerThread w;
int s;
boolean completed;
if((t = Thread.currentThread()) instanceof ForkJoinWorkerThread){
if((s = status) < 0) //查看状态,若任务完成,则直接返回任务状态
return s; if((w = (ForkJoinWorkerThread)t).unpushTask(this)){
try{
completed = exec();
}catch(Throwable ex){
return setExceptionalCompletion(rex);
}
if(completed)
return setCompletion(NORMAL);
}
return w.joinTask(this);
}else
return externalAwaitDone();
}
Java并发容器和框架的更多相关文章
- 《Java并发编程的艺术》第6/7/8章 Java并发容器与框架/13个原子操作/并发工具类
第6章 Java并发容器和框架 6.1 ConcurrentHashMap(线程安全的HashMap.锁分段技术) 6.1.1 为什么要使用ConcurrentHashMap 在并发编程中使用Has ...
- JAVA并发编程的艺术 Java并发容器和框架
ConcurrentHashMap ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成. 一个ConcurrentHashMap里包含一个Segment数组, ...
- 第六章 Java并发容器和框架
ConcurrentHashMap的实现原理与使用 ConcurrentHashMap是线程安全且高效的hashmap.本节让我们一起研究一下该容器是如何在保证线程安全的同时又能保证高效的操作. 为什 ...
- Java 并发编程——Executor框架和线程池原理
Eexecutor作为灵活且强大的异步执行框架,其支持多种不同类型的任务执行策略,提供了一种标准的方法将任务的提交过程和执行过程解耦开发,基于生产者-消费者模式,其提交任务的线程相当于生产者,执行任务 ...
- Java 并发编程——Executor框架和线程池原理
Java 并发编程系列文章 Java 并发基础——线程安全性 Java 并发编程——Callable+Future+FutureTask java 并发编程——Thread 源码重新学习 java并发 ...
- (转)java并发编程--Executor框架
本文转自https://www.cnblogs.com/MOBIN/p/5436482.html java并发编程--Executor框架 只要用到线程,就可以使用executor.,在开发中如果需要 ...
- 【Java 并发】Executor框架机制与线程池配置使用
[Java 并发]Executor框架机制与线程池配置使用 一,Executor框架Executor框架便是Java 5中引入的,其内部使用了线程池机制,在java.util.cocurrent 包下 ...
- java 并发容器一之BoundedConcurrentHashMap(基于JDK1.8)
最近开始学习java并发容器,以补充自己在并发方面的知识,从源码上进行.如有不正确之处,还请各位大神批评指正. 前言: 本人个人理解,看一个类的源码要先从构造器入手,然后再看方法.下面看Bounded ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
随机推荐
- 创建属性Attribute
XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(xmlPath); var root = xmlDoc.DocumentElement;//取到 ...
- Oracle 11.2.0.4下载地址
Linux x86: https://updates.oracle.com/Orion/Services/download/p13390677_112040_LINUX_1of7.zip?aru=16 ...
- noip2017奶酪
题目描述 现有一块大奶酪,它的高度为 h,它的长度和宽度我们可以认为是无限大的,奶酪 中间有许多 半径相同 的球形空洞.我们可以在这块奶酪中建立空间坐标系,在坐标系中, 奶酪的下表面为z=0,奶酪的上 ...
- Python3组播通信编程实现教程(发送者+接收者)
一.说明 1.1 标准组播解释 通信分为单播.多播(即组播).广播三种方式 单播指发送者发送之后,IP数据包被路由器发往目的IP指定的唯一一台设备的通信形式,比如你现在与web服务器通信就是单播形式 ...
- Python3+BaiduAI识别高颜值妹子图片
一.在百度云平台创建应用 为什么要到百度云平台创建应用,首先来说是为了获取获取access_token时需要的API Key和Secret Key 至于为什么需要API Key和Secret Key才 ...
- OGG文件获取创建日期
转载:http://blog.sina.com.cn/s/blog_b0ed98070102v1tr.html 搜索关键字: OGG文件的数据结构以及读取其注释信息的代码 实例说明: "DA ...
- 逆袭之旅DAY10.东软实训.
- svn服务器搭建及使用(二)
上一篇介绍了VisualSVN Server和TortoiseSVN的下载,安装,汉化.这篇介绍一下如何使用VisualSVN Server建立版本库,以及TortoiseSVN的使用. 首先打开Vi ...
- Cracking The Coding Interview 9.3
//Given a sorted array of n integers that has been rotated an unknown number of times, give an O(log ...
- Linux学习 : 移植qt 5.6.3 及 tslib 1.4
(一) 移植 qt5.6.3 一.qt简介: Qt是一个1991年由Qt Company开发的跨平台C++图形用户界面应用程序开发框架.它既可以开发GUI程序,也可用于开发非GUI程序,比如控制台工具 ...