GoldenGate实时投递数据到大数据平台(3)- Apache Flume
Apache Flume
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合,最后存储到一个中心化数据存储系统中,方便进行数据分析。事实上flume也可以收集其他信息,不仅限于日志。包括端口数据、JMS、命令行等输出数据。
架构
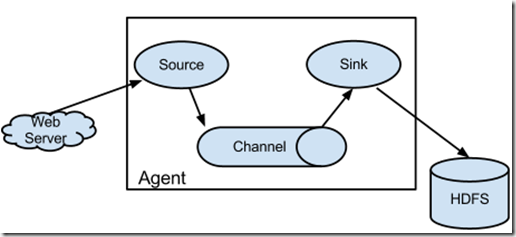
Flume主要的组件包括source(数据源),数据中间存储(channel),sink数据目标存储。
可实现多种拓扑架构,如级联数据传输。
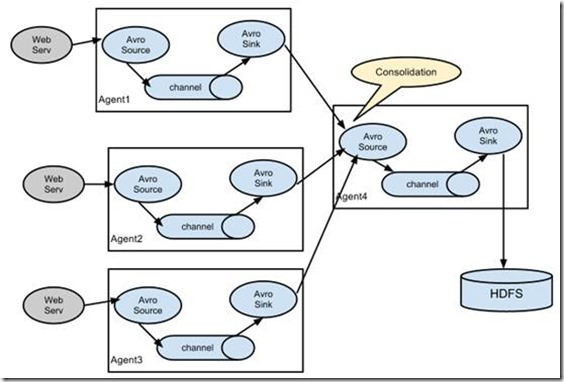
可以多对一做数据集中
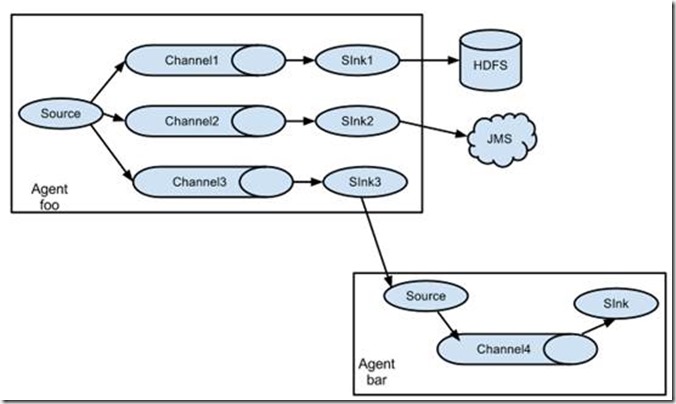
也可以一对多做数据分发
Flume支持的组件
Source
Channel

sink
安装及简单测试
从flume.apache.org下载安装包之后,解压到/u02/flume1.8
编辑一个示例文件 conf/a1.conf,内容如下
| # Name the components on this agent
a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
以上配置监听44444端口的netcat source。
启动代理
bin/flume-ng agent --conf conf --conf-file conf/a1.conf --name a1 -Dflume.root.logger=INFO,console
输出日志如下
| info: Including Hive libraries found via () for Hive access
+ exec /u01/jdk1.8.0_111/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/u02/flume1.8/conf:/u02/flume1.8/lib/*:/lib/*' -Djava.library.path= org.apache.flume.node.Application --conf-file conf/a1.conf --name a1 2018-01-02 09:11:28,634 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:62)] Configuration provider starting 2018-01-02 09:11:28,640 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:134)] Reloading configuration file:conf/a1.conf ............................ 2018-01-02 09:11:28,814 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:166)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444] |
可以看到监听的IP和端口已经正常启动。
在另一个终端上执行telnet,输入相关的文字。
$telnet localhost 44444
| Trying 127.0.0.1...
Connected to localhost. Escape character is '^]'. hello OK that's ok OK quit OK ^] telnet> quit Connection closed. |
可以看到flume agent窗口输出的日志包含有刚才输入的文字,flume agent可以正常运行。
| 2018-01-02 09:12:07,928 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
2018-01-02 09:12:16,932 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 74 68 61 74 27 73 20 6F 6B 0D that's ok. } 2018-01-02 09:12:20,935 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{} body: 71 75 69 74 0D quit. } |
OGG与flume集成的架构

GoldenGate在源端捕获关系型数据库的增量数据,OGG通过网络将数据传输到flume配置的节点,在此节点上配置flume agent,并启动一个监听端口,然后OGG Java adapter解析增量数据,实时将数据写入到Flume agent的source端口中,最后由flume通过channel, sink将数据传输到下一个目标存储节点。
采用GoldenGate与flume的集成,可以实现RDBMS的增量数据,实时写入到flume支持的任意目标类型节点。
针对OGG的投递,只需要在a1.conf中添加一段接收avro的监听配置即可,如下:
|
a1.sources = r1 r2 a1.sources.r2.channels = c1 a1.sources.r2.type = avro a1.sources.r2.bind = 192.168.89.132 a1.sources.r2.port = 41414 |
重新启动flume agent,可以看到输出日志中包含了AVRO相关的日志信息:
| 2018-01-02 09:39:21,785 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:119)] Monitored counter group for type: SOURCE, name: r2: Successfully registered new MBean.
2018-01-02 09:39:21,786 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:95)] Component type: SOURCE, name: r2 started 2018-01-02 09:39:21,788 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.source.AvroSource.start(AvroSource.java:260)] Avro source r2 started. |
OGG配置
解压goldengate for bigdata 12.3到/u01/ogg4bd_12.3目录。
设置环境变量
export LD_LIBRARY_PATH=/u01/jdk1.8.0_111/jre/lib/amd64/server
拷贝Adapter-Examples/big-data/flume中的所有文件到dirprm/目录下。
修改flume.props文件中flume对应的lib路径。
修改custom-flume-rpc.properties中flume监听avro的主机和端口。
flume.props文件内容如下:
[oracle@ol73 dirprm]$ more flume.props
| gg.handlerlist = flumehandler
gg.handler.flumehandler.type=flume gg.handler.flumehandler.RpcClientPropertiesFile=custom-flume-rpc.properties gg.handler.flumehandler.format=avro_op gg.handler.flumehandler.mode=tx #gg.handler.flumehandler.maxGroupSize=100, 1Mb #gg.handler.flumehandler.minGroupSize=50, 500 Kb gg.handler.flumehandler.EventMapsTo=tx gg.handler.flumehandler.PropagateSchema=true gg.handler.flumehandler.includeTokens=false gg.handler.flumehandler.format.WrapMessageInGenericAvroMessage=true goldengate.userexit.timestamp=utc goldengate.userexit.writers=javawriter javawriter.stats.display=TRUE javawriter.stats.full=TRUE gg.log=log4j gg.log.level=INFO gg.report.time=30sec #Sample gg.classpath for Apache Flume gg.classpath=dirprm/:/u02/flume1.8/lib/*: javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar |
以上文件内容从示例文件中直接拷贝即可,唯一要修改的是gg.classpath。
custom-flume-rpc.properties内容如下
[oracle@ol73 dirprm]$ more custom-flume-rpc.properties
|
client.type=default hosts=h1 hosts.h1=192.168.89.132:41414 batch-size=100 connect-timeout=20000 request-timeout=20000 |
唯一要修改的是flume监听的主机IP和端口,如果有多个flume组成的集群,可以设置多个host。
最后,是ogg投递的进程参数rflume.prm
[oracle@ol73 dirprm]$ more rflume.prm
| REPLICAT rflume
-- Trail file for this example is located in "AdapterExamples/trail" directory -- Command to add REPLICAT -- add replicat rflume, exttrail AdapterExamples/trail/tr TARGETDB LIBFILE libggjava.so SET property=dirprm/flume.props REPORTCOUNT EVERY 1 MINUTES, RATE GROUPTRANSOPS 10000 MAP QASOURCE.*, TARGET QASOURCE.*; |
OGG投递测试及验证
进入ggsci,添加进程,使用自带的示例数据
GGSCI> add replicat rflume, exttrail AdapterExamples/trail/tr
启动投递进程
GGSCI (ol73) 5> start rflume
Sending START request to MANAGER ...
REPLICAT RFLUME starting
查看进程状态,发现已经投递完成
GGSCI (ol73) 6> info rflume
| REPLICAT RFLUME Last Started 2018-01-02 09:41 Status RUNNING
Checkpoint Lag 00:00:00 (updated 00:00:00 ago) Process ID 66856 Log Read Checkpoint File /u01/ogg4bd_12.3/AdapterExamples/trail/tr000000000 2015-11-06 02:45:39.000000 RBA 5660 |
检查投递的数据
GGSCI (ol73) 7> stats rflume, total
| Sending STATS request to REPLICAT RFLUME ...
Start of Statistics at 2018-01-02 09:41:51. Replicating from QASOURCE.TCUSTMER to QASOURCE.TCUSTMER: *** Total statistics since 2018-01-02 09:41:45 *** Total inserts 5.00 Total updates 1.00 Total deletes 0.00 Total discards 0.00 Total operations 6.00 Replicating from QASOURCE.TCUSTORD to QASOURCE.TCUSTORD: *** Total statistics since 2018-01-02 09:41:45 *** Total inserts 5.00 Total updates 3.00 Total deletes 2.00 Total discards 0.00 Total operations 10.00 End of Statistics. |
在flume agent的日志上可以看到
|
2018-01-02 09:41:45,296 (New I/O server boss #5) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x41866afa, /192.168.89.132:17935 => /192.168.89.132:41414] OPEN 2018-01-02 09:41:45,299 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x41866afa, /192.168.89.132:17935 => /192.168.89.132:41414] BOUND: /192.168.89.132:41414 2018-01-02 09:41:45,300 (New I/O worker #1) [INFO - org.apache.avro.ipc.NettyServer$NettyServerAvroHandler.handleUpstream(NettyServer.java:171)] [id: 0x41866afa, /192.168.89.132:17935 => /192.168.89.132:41414] CONNECTED: /192.168.89.132:17935 2018-01-02 09:41:45,700 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{SCHEMA_EVENT=TRUE, SCHEMA_NAME=QASOURCE, TABLE_NAME=TCUSTMER, GENERIC_WRAPPER=false, SCHEMA_FINGERPRINT=-1783711649} body: 7B 0A 20 20 22 74 79 70 65 22 20 3A 20 22 72 65 {. "type" : "re } 2018-01-02 09:41:45,701 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{SCHEMA_EVENT=TRUE, SCHEMA_NAME=QASOURCE, TABLE_NAME=TCUSTMER, GENERIC_WRAPPER=true, SCHEMA_FINGERPRINT=1472787928} body: 7B 0A 20 20 22 74 79 70 65 22 20 3A 20 22 72 65 {. "type" : "re } 2018-01-02 09:41:45,701 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{SCHEMA_EVENT=TRUE, SCHEMA_NAME=QASOURCE, TABLE_NAME=TCUSTORD, GENERIC_WRAPPER=false, SCHEMA_FINGERPRINT=495754722} body: 7B 0A 20 20 22 74 79 70 65 22 20 3A 20 22 72 65 {. "type" : "re } 2018-01-02 09:41:45,701 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{OP_COUNT=4, GG_TRANID=00000000000000001956} body: 22 51 41 53 4F 55 52 43 45 2E 54 43 55 53 54 4D "QASOURCE.TCUSTM } 2018-01-02 09:41:45,748 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:95)] Event: { headers:{OP_COUNT=12, GG_TRANID=00000000000000003286} body: 22 51 41 53 4F 55 52 43 45 2E 54 43 55 53 54 4D "QASOURCE.TCUSTM } |
可以看到,在flume输出的日志中,已经有对应的表及源端DB操作等数据,console输出信息中,flume-ng针对logger是只显示16个字节的,剩下的都被sink截了。
如果有需求,也可以使用flume sink将数据输出到HDFS、HIVE, kafka等目标端,从而实现RDBMS数据与其它半结构化数据的实时整合。
GoldenGate实时投递数据到大数据平台(3)- Apache Flume的更多相关文章
- GoldenGate实时投递数据到大数据平台(2)- Cassandra
简介 GoldenGate是一款可以实时投递数据到大数据平台的软件,针对apache cassandra,经过简单配置,即可实现从关系型数据将增量数据实时投递到Cassandra,以下介绍配置过程. ...
- GoldenGate实时投递数据到大数据平台(5) - Kafka
Oracle GoldenGate是Oracle公司的实时数据复制软件,支持关系型数据库和多种大数据平台.从GoldenGate 12.2开始,GoldenGate支持直接投递数据到Kafka等平台, ...
- 大数据学习---大数据的学习【all】
大数据介绍 什么是大数据以及有什么特点 大数据:是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合. 大数据是一种方法论:“一切都被记录,一切都被数字化,从数据中寻找需求,寻找知 ...
- 转 开启“大数据”时代--大数据挑战与NoSQL数据库技术 iteye
一直觉得“大数据”这个名词离我很近,却又很遥远.最近不管是微博上,还是各种技术博客.论坛,碎碎念大数据概念的不胜枚举. 在我的理解里,从概念理解上来讲,大数据的目的在于更好的数据分析,否则如此大数据的 ...
- GoldenGate实时投递数据到大数据平台(6)– HDFS
GoldenGate可以实时将RDBMS的数据投递到HDFS中,在前面的文章中,已经配置过投递到kafka, mongodb等数据平台,本文通过OGG for bigdata的介质中自带的示例演示实时 ...
- GoldenGate实时投递数据到大数据平台(7)– Apache Hbase
Apache Hbase安装及运行 安装hbase1.4,确保在这之前hadoop是正常运行的.设置相应的环境变量, export HADOOP_HOME=/u01/hadoop export HBA ...
- GoldenGate实时投递数据到大数据平台(4)- ElasticSearch 2.x
ES 2.x ES 2.x安装 下载elasticSearch 2.4.5, https://www.elastic.co/downloads/elasticsearch 解压下载后的压缩包,启动ES ...
- GoldenGate实时投递数据到大数据平台(1)-MongoDB
mongodb安装 安装 linux下可使用apt-get install mongodb-server 或 yum install mongodb-server 进行安装. 也可以在windows上 ...
- [转载] 使用 Twitter Storm 处理实时的大数据
转载自http://www.ibm.com/developerworks/cn/opensource/os-twitterstorm/ 流式处理大数据简介 Storm 是一个开源的.大数据处理系统,与 ...
随机推荐
- Object类(API文档)
java.lang Class Object java.lang.Object public class Object Class Object is the root of the class hi ...
- 多态使用时,父类多态时需要使用子类特有对象。需要判断 就使用instanceof
instanceof:通常在向下转型前用于健壮性的判断,判断是符合哪一个子类对象 package Polymorphic; public class TestPolymorphic { public ...
- 常量,变量,a++,++a,+=等
常量:数据在程序里面进行运算时不能发生改变的数据,成为常量.变量:可变动的数据.变量的定义: 数据类型 变量名 = 初始值.基本数据类型:整数型:byte 1字节 ...
- javaBean转为json
一个测试用例 javabean转json @Test @Rollback(false) public void policyQueryTest() throws Exception { // 查询数据 ...
- Marathon自动扩缩容(marathon-lb-autoscale)
我们在服务里面创建如下的应用(以下是创建完复制过来的json): { "id": "/nginxtest", "cmd": null, &q ...
- Java中输出正则表达式匹配到的内容
import java.util.regex.Matcher; import java.util.regex.Pattern; public class A { public static void ...
- 项目发布脚本-nodejs
#!/bin/bash export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin clear printf &q ...
- Hybrid设计--核心交互
普通网页中跳转使用a标签,这里我们要对跳转进行更多的干预,所以将全站的跳转收口到框架层,用forward去实现.拒绝用a和window.location.如果我想对所有跳转做一个处理,开动画或者对跳转 ...
- Python Shell 中敲击方向键显示「^[[C^[[D],问题解决
碰到问题后,在网上搜索. 有帖子建议:yum install -y ncurses-devel,我这个2.7.13版本的在Linux下不行.估计是解决python3.x的方案. 尝试网上建议的,装了 ...
- gcc dynamic load library
Linux下一般都是直接在编译生成时挂接上链接库,运行时,把链接库放到系统环境里就可以了 但是windows出现带来了动态链接的概念,也就兴起了非windows世界的插件的概念的范潮 对应于windo ...