tf一些函数
1.
tf.reduce_mean(a) : 求平均值
2.
tf.truncated_normal([3,2],stddev=0.1) : 从正态分布中输出随机值,标准差为0,1,构造矩阵为3*2的
3.
tf.argmax(vector, 1):返回的是vector中的最大值的索引号,如果vector是一个向量,那就返回一个值,如果是一个矩阵,那就返回一个向量,这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号。
A = [[1,3,4,5,6]]
B = [[1,3,4], [2,4,1]]
with tf.Session() as sess:
print(sess.run(tf.argmax(A, 1)))
print(sess.run(tf.argmax(B, 1)))
输出:
[4]
[2 1]
4.
tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果是相等的那就返回True,反正返回False,返回的值的矩阵维度和A是一样的
A = [[1,3,4,5,6]]
B = [[1,3,4,3,2]]
with tf.Session() as sess:
print(sess.run(tf.equal(A, B)))
输出:
[[ True True True False False]]
5.
tf.cast()
强制转换类型
使用案例:
import tensorflow as tf
x = tf.constant([1.8, 2.2], dtype=tf.float32)
r = tf.cast(x, tf.int32)
sess = tf.Session()
print(sess.run(r)) # [1, 2], dtype=tf.int32
6.
mnist.train.next_batch(100):拿出100个样本来
7.
Dropout就是在不同的训练过程中随机扔掉一部分神经元。
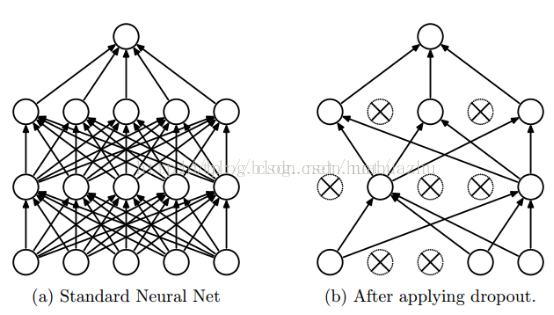
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
上面方法中常用的是前两个参数:
第一个参数x:指输入
第二个参数keep_prob: 设置神经元被选中的概率
8.
transpose函数
import tensorflow as tf
#x = tf.constant([[1, 2 ,3],[4, 5, 6]])
x = [[[1,2,3,4],[5,6,7,8],[9,10,11,12]],[[21,22,23,24],[25,26,27,28],[29,30,31,32]]]
#a=tf.constant(x)
a=tf.transpose(x, [0, 1, 2]) # 正常情况下,0,1,2
b=tf.transpose(x, [0, 2, 1]) # 将1和2的位置换了一下,原来是2*(3*4),后面的2个3和4换了一下以后,现在是2*(4*3)
c=tf.transpose(x, [1, 0, 2]) # 所有矩阵的第一行拼成一个矩阵,第二行。。。。。
with tf.Session() as sess:
print ('---------------')
print (sess.run(a))
print ('---------------')
print (sess.run(b))
print ('---------------')
print (sess.run(c))
print ('---------------')
输出:
---------------
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[21 22 23 24]
[25 26 27 28]
[29 30 31 32]]]
---------------
[[[ 1 5 9]
[ 2 6 10]
[ 3 7 11]
[ 4 8 12]]
[[21 25 29]
[22 26 30]
[23 27 31]
[24 28 32]]]
---------------
[[[ 1 2 3 4]
[21 22 23 24]]
[[ 5 6 7 8]
[25 26 27 28]]
[[ 9 10 11 12]
[29 30 31 32]]]
---------------------
9.
tf.split
a=[[1,2,3,4,5,6],[7,8,9,10,11,12]]
s=tf.split(a,2,0) # 2是切割的数量,0是维度,对a的第0个维度切割成2份(矩阵中,第0个维度即行,第1个维度即列,如果是1维数组,只有一个维度0),这里是对行进行切割,切割完后就是1行1行的了,然后他说是2份,那就独立成份
print(tf.Session().run(s))
a=[1,2,3,4,5,6]
s=tf.split(a,3,0) # 因为是1维数组,默认是0,因为要切成3份,所以结果是[array([1, 2]), array([3, 4]), array([5, 6])]
print(tf.Session().run(s))
10.
tf.nn.embedding_lookup
a = [[0.1, 0.2, 0.3], [1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3]]
a = np.asarray(a)
print(a)
idx1 = tf.Variable([0, 2, 3, 1], tf.int32)
idx2 = tf.Variable([[0, 2, 3, 1], [4, 0, 2, 2]], tf.int32)
out1 = tf.nn.embedding_lookup(a, idx1) # 取a的第0个序号,第2个序号,第3个序号,第1个序号对应的行
out2 = tf.nn.embedding_lookup(a, idx2) # 总共取了2个矩阵,每行取法一样
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print(sess.run(out1))
print(out1)
print('==================')
print(sess.run(out2))
print(out2)
11.
tf.nn.bias_add
a=tf.constant([[1,1],[2,2],[3,3]],dtype=tf.float32)
b=tf.constant([1,-1],dtype=tf.float32)
with tf.Session() as sess:
print(sess.run(a))
print(sess.run(b))
print('bias_add:')
print(sess.run(tf.nn.bias_add(a, b))) # 将后一项加到前一项
12.
tf.one_hot
classes = 4
labels = tf.constant([0,0,2])
output = tf.one_hot(labels,classes)
# 后面表示输出的尺寸,前面的labels,如果是0,则表示1 0 0 0 0 ...,
# 如果是1,则表示:0 1 0 0 0 0....(即one-hot编码)
# 这个例子中,输出的长为4,
sess = tf.Session()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
output = sess.run(output)
print(output)
out:
[[1. 0. 0. 0.]
[1. 0. 0. 0.]
[0. 0. 1. 0.]]
13.
>>>a = np.array([[1,2,3],[4,5,6]])
>>>np.reshape(a,(3,-1)) # -1表示不知道该填什么值的时候让它自己计算出来
array([[1, 2],
[3, 4],
[5, 6]])
>>> np.reshape(a,(1,-1))
array([[1, 2, 3, 4, 5, 6]])
>>> np.reshape(a,(6,-1))
array([[1],
[2],
[3],
[4],
[5],
[6]])
>>> np.reshape(a,(-1,1))
array([[1],
[2],
[3],
[4],
[5],
[6]])
14.
tf.expand_dims(input, axis=None, name=None, dim=None)
在第axis位置增加一个维度,比如:
# 't' is a tensor of shape [2]
shape(expand_dims(t, 0)) ==> [1, 2]
shape(expand_dims(t, 1)) ==> [2, 1]
shape(expand_dims(t, -1)) ==> [2, 1]
# 't2' is a tensor of shape [2, 3, 5]
shape(expand_dims(t2, 0)) ==> [1, 2, 3, 5]
shape(expand_dims(t2, 2)) ==> [2, 3, 1, 5]
shape(expand_dims(t2, 3)) ==> [2, 3, 5, 1]15.
tf.concat
# a的第0个维度有2个元素:[1,2,3],[4,5,6],a的第1个维度有3个元素
a=[[[1,2,3],[4,5,6]]] # 维度:123
b=[[[7,8,9],[10,11,12]]] # 维度:123
# a的维度是1*2*3,b的维度是1*2*3,在第0个维度拼接的结果是:(1+1)*2*3 = 2*2*3
print(tf.concat([a,b],axis=0).shape)
print(tf.concat([a,b],axis=1).shape)
print(tf.concat([a,b],axis=2).shape)
print(tf.concat([a,b],axis=-1).shape)
16.
tf.device()
在tensorflow中,我们可以使用 tf.device() 指定模型运行的具体设备,可以指定运行在GPU还是CUP上,以及哪块GPU上。
例如:使用 tf.device('/gpu:1') 指定Session在第二块GPU上运行:
tf一些函数的更多相关文章
- tensorflow 笔记14:tf.expand_dims和tf.squeeze函数
tf.expand_dims和tf.squeeze函数 一.tf.expand_dims() Function tf.expand_dims(input, axis=None, name=None, ...
- TensorFlow随机值:tf.random_normal函数
tf.random_normal 函数 random_normal( shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=No ...
- tf.transpose函数的用法讲解
tf.transpose函数中文意思是转置,对于低维度的转置问题,很简单,不想讨论,直接转置就好(大家看下面文档,一看就懂). tf.transpose(a, perm=None, name='tra ...
- tensorflow中 tf.reduce_mean函数
tf.reduce_mean 函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值. reduce_mean(input_ ...
- tf.transpose函数解析
tf.transpose函数解析 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.transpose(a, perm = None, name = 'transpose') 解释 将a进 ...
- tf.slice函数解析
tf.slice函数解析 觉得有用的话,欢迎一起讨论相互学习~Follow Me tf.slice(input_, begin, size, name = None) 解释 : 这个函数的作用是从输入 ...
- tf.random_normal()函数
tf.random_normal()函数用于从服从指定正太分布的数值中取出指定个数的值. tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf. ...
- Tensorflow函数——tf.placeholder()函数
tf.placeholder()函数 Tensorflow中的palceholder,中文翻译为占位符,什么意思呢? 在Tensoflow2.0以前,还是静态图的设计思想,整个设计理念是计算流图,在编 ...
- tf.Session()函数的参数应用(tensorflow中使用tf.ConfigProto()配置Session运行参数&&GPU设备指定)
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/dcrmg/article/details ...
- 【tensorflow基础】tensorflow中 tf.reduce_mean函数
参考 1. tensorflow中 tf.reduce_mean函数: 完
随机推荐
- Docker学习笔记之编写 Docker Compose 项目
0x00 概述 通过阅读之前的小节,相信大家对 Docker 在开发中的应用已经有了一定的了解.作为一款实用的软件,我们必须回归到实践中来,这样才能更好地理解 Docker 的实用逻辑和背后的原理.在 ...
- Mysql报错java.sql.SQLException:null,message from server:"Host '27,45,38,132' is not allowed to connect
Mysql报错java.sql.SQLException:null,message from server:"Host '27,45,38,132' is not allowed to co ...
- oracle 11g AUTO_SAMPLE_SIZE动态采用工作机制
Note that if you're interested in learning about Oracle Database 12c, there's an updated version of ...
- host元素的属性autoDeploy和reloadable的区别
web.xml文件的修改会触发AutoDeploy,受host节的autoDeploy配置值的影响. class类文件修改会触发Reload操作,受reloadable配置值的影响. 而autoDep ...
- BeautifulSoup 模块详解
BeautifulSoup 模块详解 BeautifulSoup是一个模块,该模块用于接收一个HTML或XML字符串,然后将其进行格式化,之后遍可以使用他提供的方法进行快速查找指定元素,从而使得在HT ...
- ZVAL——PHP源码分析
基于 PHP 5.6.20 ZVAL——php变量实现的基础 _zval_struct 结构体的定义位于 Zend/zend.h 322 行 typedef union _zvalue_value { ...
- XXX银行项目部署
XXX银行项目部署 一.下载项目代码 1.使用git工具下载代码 代码路径:推荐代码下载到桌面 git clone http://sunyard_姓名拼音@bitbucket.devops.hfdev ...
- linux判断文件大小
第一条code ll -s | tail -n +2 | awk '$1 >= 10 {print $1,$10 "容量大于10"} $1 <= 9 {print $1 ...
- 跟阿铭学Linux习题答案
第一章:走进Linux 1.简述它的发展历史,列举几种代表性的发行版 Linux之前是Unix,由于Unix收费昂贵,so,Richard Stallman 发起了开发自由软件的运动,并成立了自由软件 ...
- Codeforces 700B Connecting Universities - 贪心
Treeland is a country in which there are n towns connected by n - 1 two-way road such that it's poss ...