Hanlp等七种优秀的开源中文分词库推荐
Hanlp等七种优秀的开源中文分词库推荐
中文分词是中文文本处理的基础步骤,也是中文人机自然语言交互的基础模块。由于中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词。
纵观整个开源领域,陆陆续续做中文分词的也有不少,不过目前仍在维护的且质量较高的并不多。下面整理了一些个人认为比较优秀的中文分词库,以供大家参考使用。
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
HanLP提供下列功能:
l 中文分词
l HMM-Bigram(速度与精度最佳平衡;一百兆内存)
l 最短路分词、N-最短路分词
l 由字构词(侧重精度,可识别新词;适合NLP任务)
l 感知机分词、CRF分词
l 词典分词(侧重速度,每秒数千万字符;省内存)
l 极速词典分词
l 所有分词器都支持:
l 索引全切分模式
l 用户自定义词典
l 兼容繁体中文
l 训练用户自己的领域模型
l 词性标注
l HMM词性标注(速度快)
l 感知机词性标注、CRF词性标注(精度高)
l 命名实体识别
l 基于HMM角色标注的命名实体识别 (速度快)
l 中国人名识别、音译人名识别、日本人名识别、地名识别、实体机构名识别
l 基于线性模型的命名实体识别(精度高)
l 感知机命名实体识别、CRF命名实体识别
l 关键词提取
l TextRank关键词提取
l 自动摘要
l TextRank自动摘要
l 短语提取
l 基于互信息和左右信息熵的短语提取
l 拼音转换
l 多音字、声母、韵母、声调
l 简繁转换
l 简繁分歧词(简体、繁体、臺灣正體、香港繁體)
l 文本推荐
l 语义推荐、拼音推荐、字词推荐
l 依存句法分析
l 基于神经网络的高性能依存句法分析器
l MaxEnt依存句法分析
l 文本分类
l 情感分析
l word2vec
l 词向量训练、加载、词语相似度计算、语义运算、查询、KMeans聚类
l 文档语义相似度计算
l 语料库工具
l 默认模型训练自小型语料库,鼓励用户自行训练。所有模块提供训练接口,语料可参考OpenCorpus。
在提供丰富功能的同时,HanLP内部模块坚持低耦合、模型坚持惰性加载、服务坚持静态提供、词典坚持明文发布,使用非常方便,同时自带一些语料处理工具,帮助用户训练自己的模型。
“结巴”中文分词,做最好的 Python 中文分词组件。
特性
l 支持三种分词模式:
l 精确模式,试图将句子最精确地切开,适合文本分析;
l 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
l 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
l 支持繁体分词
l 支持自定义词典
算法
l 基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
l 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
l 对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
代码示例

Jcseg 是基于 mmseg 算法的一个轻量级中文分词器,同时集成了关键字提取,关键短语提取,关键句子提取和文章自动摘要等功能,并且提供了一个基于 Jetty 的 web 服务器,方便各大语言直接 http 调用,同时提供了最新版本的 lucene, solr, elasticsearch 的分词接口!Jcseg 自带了一个 jcseg.properties 文件用于快速配置而得到适合不同场合的分词应用,例如:最大匹配词长,是否开启中文人名识别,是否追加拼音,是否追加同义词等!
核心功能:
l 中文分词:mmseg 算法 + Jcseg 独创的优化算法,四种切分模式。
l 关键字提取:基于 textRank 算法。
l 关键短语提取:基于 textRank 算法。
l 关键句子提取:基于 textRank 算法。
l 文章自动摘要:基于 BM25+textRank 算法。
l 自动词性标注:基于词库+(统计歧义去除计划),目前效果不是很理想,对词性标注结果要求较高的应用不建议使用。
l 命名实体标注:基于词库+(统计歧义去除计划),电子邮件,网址,大陆手机号码,地名,人名,货币,datetime 时间,长度,面积,距离单位等。
l Restful api:嵌入 jetty 提供了一个绝对高性能的 server 模块,包含全部功能的http接口,标准化 json 输出格式,方便各种语言客户端直接调用。
中文分词模式:
六种切分模式
(1).简易模式:FMM 算法,适合速度要求场合。
(2).复杂模式:MMSEG 四种过滤算法,具有较高的歧义去除,分词准确率达到了 98.41%。
(3).检测模式:只返回词库中已有的词条,很适合某些应用场合。
(4).检索模式:细粒度切分,专为检索而生,除了中文处理外(不具备中文的人名,数字识别等智能功能)其他与复杂模式一致(英文,组合词等)。
(5).分隔符模式:按照给定的字符切分词条,默认是空格,特定场合的应用。
(6).NLP 模式:继承自复杂模式,更改了数字,单位等词条的组合方式,增加电子邮件,大陆手机号码,网址,人名,地名,货币等以及无限种自定义实体的识别与返回。
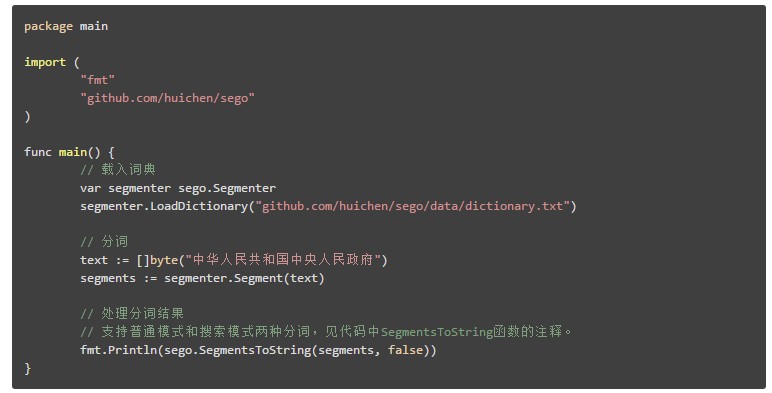
sego 是一个 Go 中文分词库,词典用双数组 trie(Double-Array Trie)实现, 分词器算法为基于词频的最短路径加动态规划。
支持普通和搜索引擎两种分词模式,支持用户词典、词性标注,可运行 JSON RPC 服务。
分词速度单线程 9MB/s,goroutines 并发 42MB/s(8核 Macbook Pro)。
示例代码:
中文处理工具包
特点
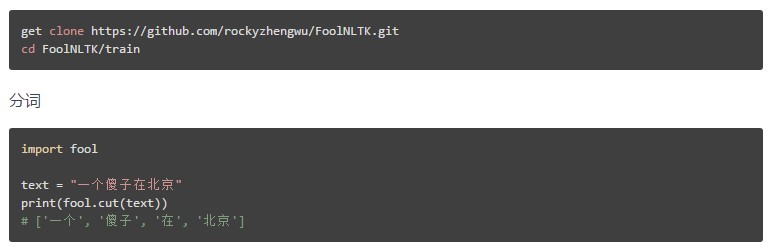
l 可能不是最快的开源中文分词,但很可能是最准的开源中文分词
l 基于 BiLSTM 模型训练而成
l 包含分词,词性标注,实体识别, 都有比较高的准确率
l 用户自定义词典
l 可训练自己的模型
l 批量处理
定制自己的模型
6、Ansj 中文分词 —— 基于 n-Gram+CRF+HMM 的中文分词的 Java 实现
Ansj 中文分词是一个基于 n-Gram+CRF+HMM 的中文分词的 java 实现。分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上。目前实现了中文分词、中文姓名识别、用户自定义词典、关键字提取、自动摘要、关键字标记等功能,可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目。
下面是一个简单的分词效果,仅做参考:

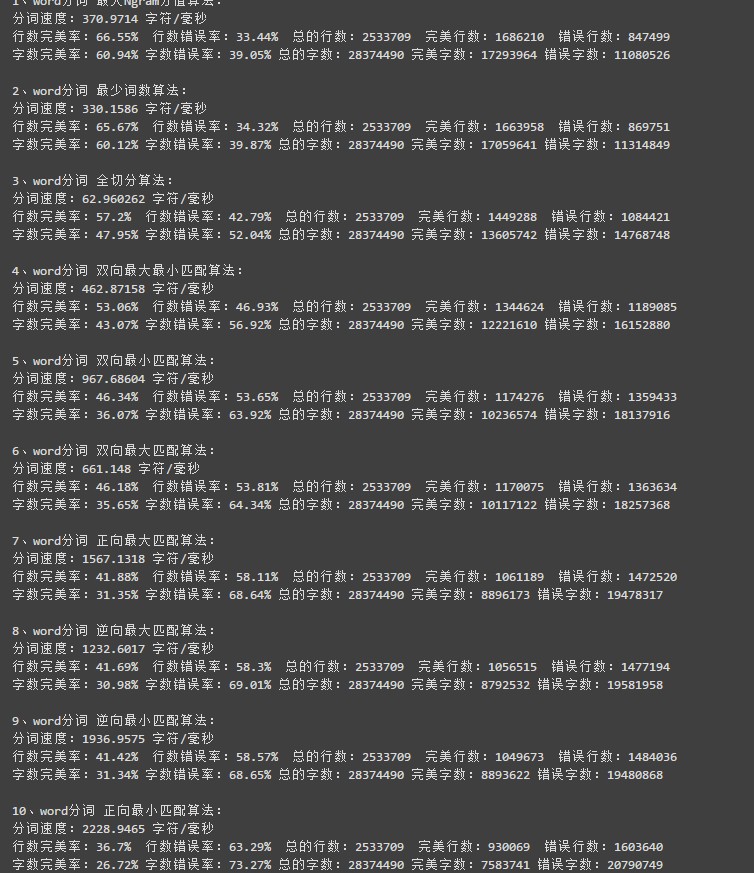
word 分词是一个 Java 实现的分布式的中文分词组件,提供了多种基于词典的分词算法,并利用 ngram 模型来消除歧义。能准确识别英文、数字,以及日期、时间等数量词,能识别人名、地名、组织机构名等未登录词。能通过自定义配置文件来改变组件行为,能自定义用户词库、自动检测词库变化、支持大规模分布式环境,能灵活指定多种分词算法,能使用refine功能灵活控制分词结果,还能使用词频统计、词性标注、同义标注、反义标注、拼音标注等功能。提供了10种分词算法,还提供了10种文本相似度算法,同时还无缝和 Lucene、Solr、ElasticSearch、Luke 集成。注意:word1.3 需要 JDK1.8 。
分词算法效果评估:
转载自编辑部的故事的个人空间
Hanlp等七种优秀的开源中文分词库推荐的更多相关文章
- 开源中文分词工具探析(七):LTP
LTP是哈工大开源的一套中文语言处理系统,涵盖了基本功能:分词.词性标注.命名实体识别.依存句法分析.语义角色标注.语义依存分析等. [开源中文分词工具探析]系列: 开源中文分词工具探析(一):ICT ...
- GitHub 优秀Android 开源项目
阅读目录 1.Xabber客户端 2.oschina客户端 3.手机安全管家 4.星座连萌 5.玲闹铃 6.魔乐盒 7.PWP日历 8.Apollo音乐播放器 9.夏普名片识别 10.高仿人人网 11 ...
- 11大Java开源中文分词器的使用方法和分词效果对比,当前几个主要的Lucene中文分词器的比较
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- 11大Java开源中文分词器的使用方法和分词效果对比
本文的目标有两个: 1.学会使用11大Java开源中文分词器 2.对比分析11大Java开源中文分词器的分词效果 本文给出了11大Java开源中文分词的使用方法以及分词结果对比代码,至于效果哪个好,那 ...
- JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的 开源 Java EE快速开发平台
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓 ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- 开源中文分词工具探析(四):THULAC
THULAC是一款相当不错的中文分词工具,准确率高.分词速度蛮快的:并且在工程上做了很多优化,比如:用DAT存储训练特征(压缩训练模型),加入了标点符号的特征(提高分词准确率)等. 1. 前言 THU ...
- 开源中文分词工具探析(五):FNLP
FNLP是由Fudan NLP实验室的邱锡鹏老师开源的一套Java写就的中文NLP工具包,提供诸如分词.词性标注.文本分类.依存句法分析等功能. [开源中文分词工具探析]系列: 中文分词工具探析(一) ...
- 开源中文分词工具探析(五):Stanford CoreNLP
CoreNLP是由斯坦福大学开源的一套Java NLP工具,提供诸如:词性标注(part-of-speech (POS) tagger).命名实体识别(named entity recognizer ...
随机推荐
- REST easy with kbmMW #16 – Multiple servers using HTTP.sys transport
前文写过使用HTTP.sys转输层(TkbmMWHTTPSysServerTransport),实现一个kbmMW应用服务器. 如果在一台服务器上,同时运行多个,基于TkbmMWHTTPSysServ ...
- Java学习笔记31(IO:Properties类)
Properties类,表示一个持久的j集,可以存在流中,或者从流中加载 是Hashtable的子类 map集合的方法都能用 用途之一:在开发项目中,我们最后交给客户的是一个编译过的class文件,客 ...
- 解决IDEA16闪退的问题
问题描述:在编辑等使用过程中,IDEA有时会突然闪退,一脸懵逼...... 原因: 1.内存分配不够 修改home/bin/目录下面的配置文件: idea.exe.vmoptions idea64.e ...
- jdk安装和环境配置
public class test{ public static void main(String[] args){ System.out.println("hello world" ...
- mysql 数据查询全讲
数据查询 涉及到DQL(Data Query Language)是sql语句的一类 本文全面介绍了mysql下 select 语句的各种查询方式:普通查询,模糊查询,查询排序,分页查询,聚合函数查询 ...
- Win2003可用序列号(标准版与企业版)
通用性好的win2003序列号: (推荐先用这个里面的)FJ8DH-TQPYG-9KFHQ-88CB2-Y7V3Y GRD4P-FTQQF-JCDM8-4P6JK-PFG7M JD7JX-KCDTH- ...
- YII2.0使用ActiveForm表单(转)
Controller控制器层代码 <?php namespace frontend\controllers; use frontend\models\UserForm; class UserCo ...
- 【CSP】字符与int
[转自https://yq.aliyun.com/articles/19153] WIKIOI-1146 ISBN号码 光仔december 2014-03-01 16:20:00 浏览479 评 ...
- Linux 针对nginx日志文件做ip防刷限制
针对nginx日志做ip访问限制 1.cat /var/log/server/nginx/access.log| awk -F '?' '/optionid/{print $1}'|awk '{pri ...
- nginx高并发下配置参数
今天下午,测试组同事模拟800个用户同时发起请求,nginx开始报错, "Too Many Open Files" 我们使用的是Dell R430服务器,2个物理CPU,每个CP ...