redis之 3.0集群安装
1. 集群
即使有了主从复制,每个数据库都要保存整个集群中的所有数据,容易形成木桶效应。
使用Jedis实现了分片集群,是由客户端控制哪些key数据保存到哪个数据库中,如果在水平扩容时就必须手动进行数据迁移,而且需要将整个集群停止服务,这样做非常不好的。
Redis3.0版本的一大特性就是集群(Cluster),接下来我们一起学习集群。
1.0. 架构

(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot(插槽)上,cluster 负责维护node<->slot<->value
1.1. 解压安装包
[root@mysql5 local]# pwd
/usr/local
[root@mysql5 redis]# tar -zxvf redis-3.0.2.tar.gz
[root@mysql5 redis]# ln -s redis-3.0.2 redis
[root@mysql5 redis]# pwd
/usr/local/redis
[root@mysql5 redis]# make
[root@mysql5 redis]# make install PREFIX=/usr/local/redis
# 创建六个实例目录
[root@mysql5 redis]# mkdir /usr/local/redis7001
[root@mysql5 redis]# mkdir /usr/local/redis7002
[root@mysql5 redis]# mkdir /usr/local/redis7003
[root@mysql5 redis]# mkdir /usr/local/redis7004
[root@mysql5 redis]# mkdir /usr/local/redis7005
[root@mysql5 redis]# mkdir /usr/local/redis7006
# 拷贝软件到相应的实例
[root@mysql5 redis]# pwd
/usr/local/redis
[root@mysql5 redis]# cp -rf * /usr/local/redis7001
[root@mysql5 redis]# cp -rf * /usr/local/redis7002
[root@mysql5 redis]# cp -rf * /usr/local/redis7003
[root@mysql5 redis]# cp -rf * /usr/local/redis7004
[root@mysql5 redis]# cp -rf * /usr/local/redis7005
[root@mysql5 redis]# cp -rf * /usr/local/redis7006
1.2. 修改配置文件
1、 设置不同的端口,7001、7002、7003、7004、7005、7006
2、 开启集群,cluster-enabled yes
3、 指定集群的配置文件,cluster-config-file "nodes-xxxx.conf"
4、打开redis后台执行, daemonize yes
5、启动集群
1.3. 创建集群
1.3.1. 安装ruby环境
因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
yum -y install zlib ruby rubygems
gem install redis
手动安装:
rz上传redis-3.2.1.gem
gem install -l redis-3.2.1.gem
1.3.2. 创建集群
首先,进入redis的安装包路径下:
cd /usr/local/src/redis/redis-3.0.1/src/
执行命令:
./redis-trib.rb create --replicas 1 10.100.25.44:7001 10.100.25.44:7002 10.100.25.44:7003 10.100.25.44:7004 10.100.25.44:7005 10.100.25.44:7006
--replicas 0:指定了从数据的数量为0 ,如果指定为1的话,每个集群节点会有一个副本
注意:这里不能使用127.0.0.1,否则在Jedis客户端使用时无法连接到!
redis-trib用法:
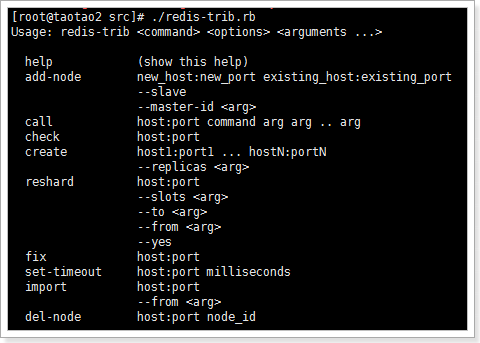
1.3.3. 集群检测
[root@mysql5 redis7001]# redis-cli -p 7001
127.0.0.1:7001> cluster nodes
dbec41c5a8406c18810a9962ed68068fbcf9aaac 10.100.25.44:7005 slave d277e9e7267b8e6f7da2e72b0d4070868c51bfe3 0 1538674374274 5 connected
d42782bf3eaf1e130d0d694533f3e1bea7e3ef2c 10.100.25.44:7003 master - 0 1538674373770 3 connected 10923-16383
9a0ab8d1772787bde727b0e78b1b8db242f60d2b 10.100.25.44:7004 slave 1e0d1bea4f1f95ca2d673bbbe342afa2646e942b 0 1538674376293 4 connected
17d51731c87847ed5dd6d78146f68a899e0028ab 10.100.25.44:7006 slave d42782bf3eaf1e130d0d694533f3e1bea7e3ef2c 0 1538674371251 6 connected
d277e9e7267b8e6f7da2e72b0d4070868c51bfe3 10.100.25.44:7002 master - 0 1538674375284 2 connected 5461-10922
1e0d1bea4f1f95ca2d673bbbe342afa2646e942b 10.100.25.44:7001 myself,master - 0 0 1 connected 0-5460
redis之 3.0集群安装的更多相关文章
- hadoop 2.2.0集群安装详细步骤(简单配置,无HA)
安装环境操作系统:CentOS 6.5 i586(32位)java环境:JDK 1.7.0.51hadoop版本:社区版本2.2.0,hadoop-2.2.0.tar.gz 安装准备设置集群的host ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- hadoop 2.2.0集群安装
相关阅读: hbase 0.98.1集群安装 本文将基于hadoop 2.2.0解说其在linux集群上的安装方法,并对一些重要的设置项进行解释,本文原文链接:http://blog.csdn.net ...
- ElasticSearch 5.0.0 集群安装部署文档
1. 搭建环境 3台物理机 操作系统 centos7 es1 192.168.31.141 4g内存 2核 es2 192.168.31.142 4g内存 2核 es3 ...
- CentOS下Storm 1.0.0集群安装具体解释
本文环境例如以下: 操作系统:CentOS 6 32位 ZooKeeper版本号:3.4.8 Storm版本号:1.0.0 JDK版本号:1.8.0_77 32位 python版本号:2.6.6 集群 ...
- Linux基于Hadoop2.8.0集群安装配置Hive2.1.1及基础操作
前言 安装Apache Hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可,安装前需保证Hadoop已启(动文中用到了hadoop的hdfs命 ...
- redis3.0.0 集群安装详细步骤
Redis集群部署文档(centos6系统) Redis集群部署文档(centos6系统) (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对 ...
- hadoop2.20.0集群安装教程
一.安装的需要软件及集群描述 1.软件: Vmware9.0:虚拟机 Hadoop2.2.0:Apache官网原版稳定版本 JDK1.7.0_07:Oracle官网版本 Ubuntu12.04LTS: ...
- 最新版spark1.1.0集群安装配置
和分布式文件系统和NoSQL数据库相比而言,spark集群的安装配置还算是比较简单的: 很多教程提到要安装java和scala,但我发现spark最新版本是包含scala的,JRE采用linux内嵌的 ...
随机推荐
- SharePoint Framework 构建你的第一个web部件(二)
博客地址:http://blog.csdn.net/FoxDave 本篇接上一讲,介绍一下web部件项目中的代码. 下面首先列举一下项目中的一些关键文件. Web部件类 HelloWorldWebPa ...
- codeforce949A(顺带vector详细使用介绍)
A. Zebras time limit per test1 second memory limit per test512 megabytes inputstandard input outputs ...
- Oracle中从控制文件读取的视图
Oracle中有一些数据字典视图需从控制文件中读取信息,如下所示.用户在数据库打开之前就可以访问这些视图,因为这些视图的内容存储在控制文件中. v$archived_log:归档日志信息,如大小,SC ...
- nginx防DOS攻击
将 timeout 设低来防止 DOS 攻击 client_body_timeout 10; client_header_timeout 10; keepalive_timeout 5 5; send ...
- 7-log4j2之自定义Appender
一.添加Maven依赖 <dependencies> <dependency> <groupId>org.apache.logging.log4j</grou ...
- FMX取得屏分辨率
procedure Tfrm_Main.FormCreate(Sender: TObject); var ScreenSvc: IFMXScreenService; Size: TPointF; be ...
- Spring+Hessian+Maven+客户端调用实例
Hessian是一个采用二进制格式传输的服务框架,相对传统soap web service,更轻量,更快速.官网地址:http://hessian.caucho.com/ 先上个效果图,在客户端界面通 ...
- 2017ICPC北京赛区网络赛 Minimum(数学+线段树)
描述 You are given a list of integers a0, a1, …, a2^k-1. You need to support two types of queries: 1. ...
- Scrum_Sprint
1.计划会议过程 经过一天的讨论研究,我们对该项目进行了需求分析,确定了这周所要实现的各个功能 并做好了任务看板,并将项目的各个功能分成一个个任务,进行了初步的分工 2.backlog BACKLOG ...
- jupyter notebook远程服务器终端连接
如下图