SigXplorer设置延时及Local_Global
通过SigXplorer设置绝对延时和相对延时及对Local-Global的理解
一、基本理解
(感觉可能有偏差)
在于博士的教程第44和45讲中,分别对绝对延时和相对延时进行了设置,通过SigXplorer。
1、当前对绝对延时和相对延时的理解为:(用length来衡量的话)
绝对延时:绝对走线长度,为走线限定一个大体范围;(delta(min,max)<800mil,2cm)
相对延时:一组走线之间的偏差,即走线的等长设置。(tolerance<400mil,常规DDR)
2、设置绝对延时时,不存在local和global之分,实际系统已将其定义为global,即针对一组线的全局绝对延时。
3、设置相对延时时有local和global之分。(参见教程第45讲)
Local:平面内
Global:纵向,不同平面内(参见进阶部分,将Global理解为全局的:包含横向和纵向,应该更准确)
在设置同一XNet内T型连接2个分支之间互相等长时,用Local含义为:
同一XNet内T型连接的2个分支之间互相等长(横向),相同拓扑结构的同一个XNet内(其它XNet)T型线的2个分支也要等长(不然变成设置单根线了,还要拓扑干什么!)。不表示不同XNet中具有相同拓扑结构的支线之间的纵向等长。话句话说,Local表式每个XNet内的平面等长。
需要设置不同XNet、具有相同拓扑结构支线之间的纵向等长,用Global。
画图如下:
举个例子吧:
A有2把尺子:A1(1#),A2(2#);
B有2把尺子:B1(1#),B2(2#);
C有2把尺子:C1(1#),C2(2#)。
Local:(约束名要相同,参见博士的第45讲),需要满足:
A的2把尺子要满足长度关系:A1=A2
B的2把尺子要满足长度关系:B1=B2
C的2把尺子要满足长度关系:C1=C2
…
不需要满足:A1=B1=C1=…,A2=B2=C2=…
此即平面等长
用Global:
需要满足(只有一个拓扑约束时):
A1=B1=C1=…(设置1号尺子纵向等长时)
A2=B2=C2=…(设置2号尺子纵向等长时)
而不需要满足:
A1=A2,B1=B2,…
此即纵向等长。
注:若设置了2条Global等长,并用同一个名字(rule name) ,即在同一个match group中,分别设置1号等长和2号等长,则需要满足的等式增加为:
A1=B1=C1=…(设置1号尺子纵向等长时)
A2=B2=C2=…(设置2号尺子纵向等长时)
A1=A2,B1=B2,C1=C2…(同一个match group内的全局等长)
上面3个组式子又可以等效为:A1=B1=C1= A2=B2=C2=。。。;即所有走线均要等长。
========================
二、理解进阶
(这次感觉应该差不多了)
实际上SigXplorer中的topology constraints是一个非常灵活的约束设置工具。
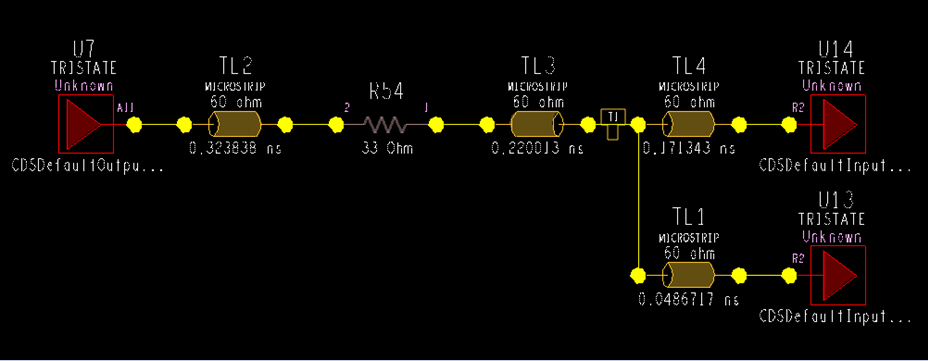
图1 拓扑结构图
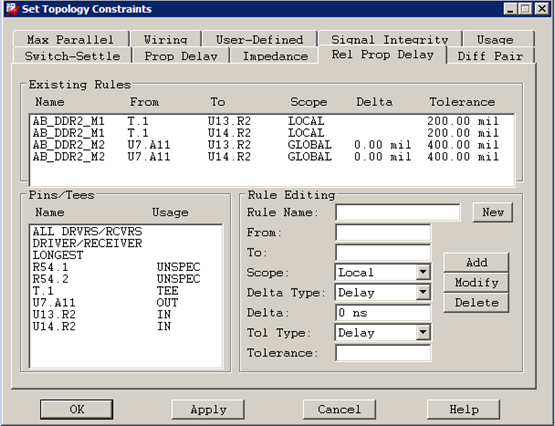
2 设置的相对延时
注解:
AB_DDR2_M1:图中设置了T型点到U13、U14(两片同样的三星16位DDR2 SDRAM拼成32位)的相对延时:同一个XNet内,T型点到U13和T型点到U14,这两条分支线尽量相等,此时信号干扰最小,图2中设置tolerance为200mil。因为是同一个XNet内的等长,故此处用Local。(不需要本XNet内T型点到U13与其它XNet 的T型点到U13等长)。
AB_DDR2_M2:同时,总体上还要保证3512芯片的引脚出来,经T型点分开之后,到DDR2芯片引脚的走线距离相等。3512芯片引出的地址线经过T型点分支成为2簇,簇内和簇间都要相等。这通过AB_DDR2_M2约束来实现(AB_DDR2_M2实际在CM中为match group),不同的拓扑(线路)要进行相对延时比对必须添加为一个match group,故在此match group中存在2项(分别对应不同的路由)
Global的含义为:不同XNet之间均要进行线长的相对延时控制。
设置完成后:

图3 Match group:AB_DDR2_M1
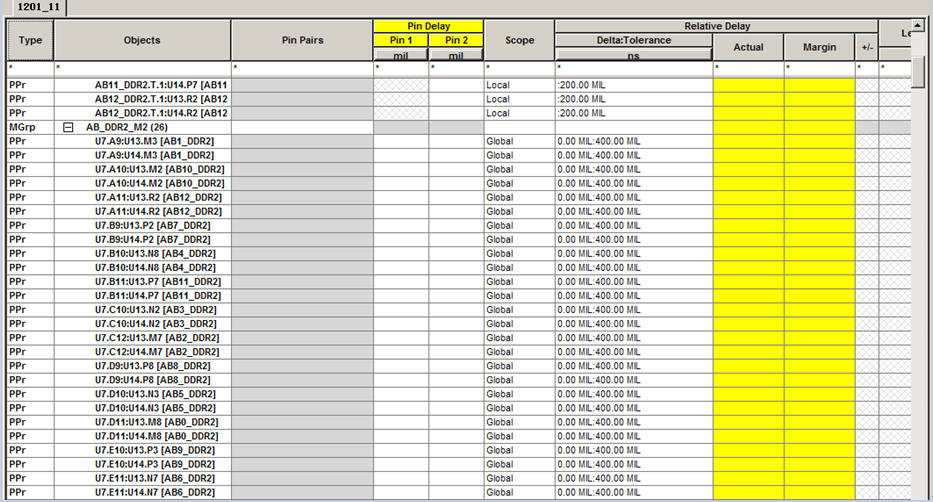
图4 Match group:AB_DDR2_M2
通过上面的设置可以总结如下几点:(主要是对Local和Global的理解)
1、 图2中的rule name在CM中对应match group
所以,需要有多少种拓扑支路参与相对延时控制,就需要在同一个rule name中添加多少个拓扑支路;前述的AB_DDR2_M1、AB_DDR2_M2均有2个支路;
2、 Local和Global:
Local代表同网络内进行相对比对(相对延时控制),实际上,SigXplorer提取的拓扑结构也是在一个网络内的(包含XNet),举例来说,图3中设定为Local的相对延时设置,只会在同一个XNet中进行比对,如只会分别在AB0_DDR2内,分别在AB1_DDR2内、等等中进行比对。不会拿AB0_DDR2和AB1_DDR2中拓扑相同的走线相比对。即前面所说的在一个NET内的横向比对。
Global:全局比对,即:将AB0_DDR2和AB1_DDR2中拓扑相同的走线相比对(纵向)。若在一个约束(如AB_DDR2_M1)中设置了不止1条拓扑支线,则同一网络内,不同支线之间的走线长度也要比对(此时完成的实际是local功能)。
因此:可以说Local是Global的特例。
AB_DDR2_M1和AB_DDR2_M2均有2项,分别各自对应2个不同拓扑支线。
AB_DDR2_M1中对2条拓扑支线进行了设置,表明这2条支线是一定要进行互相比对的(因为已经被加到一个rule name中了,也即被加到一个match group中了),接下来需要选择比对的方式,是仅仅同个网络内的横向比对(Local),还是去全局比对(同一网络内横向,不同网络间纵向)(修正一下:说Global是全局应该更加贴切,因为Global不仅可以指纵向还包括横向)。举例来说,图4中AB_DDR2_M2内所有的走线长度均会互相比对,不管是同一个NET(横向)还是不同NET(纵向)。
2点疑问:
1)既然Global既包括纵向(网络间)又包括横向(同一网络内),为什么还需要Local(只能在同一网络内)?
² 因为并不是在所有NET(或者是XNet)内的走线长度都需要与其它NET进行匹配。对很多T型分支线,只需要保证在同一个NET内的2条分支尽量等长即可。
2)既然设置为Local的相对延时比对方法只限定为同一NET内?就是一个NET内不同拓扑支线的走线长度互相比较,为什么设置相对延时时可以将tolerance设置得不一样?
² 即使是同一个网络,当分支较多时,可能需要比对的不止2条支线,例如
A支线,tolerance:500mil
B支线,tolerance:200mil
C支线,tolerance:500mil
这样,A与B、C与B之间tolerance均只能按照200mil走线,但是A和C之间可以按照500mil的tolerance走线。
SigXplorer设置延时及Local_Global的更多相关文章
- 关于利用ajax时,设置访问延时的方法
在实际开发中应使用后端的延时方法,一般为sleep,可以设置延时几秒后返回给前端请求的数据 众所周知,在js中,并不存在例如C++或者JAVA.PHP中的sleep延时方法, 目前仅有的所谓延时方法S ...
- [ios]新手笔记-。-UIPickerView 关于伪造循环效果和延时滚动效果
查找了网上资料,循环效果绝大部分都是增加行数来制造循环的错觉,延时滚动就是利用NSTimer间隔出发滚动事件来制造滚动效果. 代码: #import <UIKit/UIKit.h>#imp ...
- linux 模拟延时和丢包
这是 RHCA 中的一个 BDP 的测试,这也是公司很常用的一种延时和丢包的模拟,现在分享给大家. 我们做的应用软件,还有测试 TCP/UDP 对比,测试 BDP 对 TCP/IP 的影响时,我们都 ...
- iOS 四种延时的方法
- (void)initBlock{ //延时的方法 //1:GCD延时 此方式在能够在參数中选择运行的线程. 是一种非堵塞的运行方式,没有找到取消运行的方法. double ...
- RocketMQ源码 — 九、 RocketMQ延时消息
上一节消息重试里面提到了重试的消息可以被延时消费,其实除此之外,用户发送的消息也可以指定延时时间(更准确的说是延时等级),然后在指定延时时间之后投递消息,然后被consumer消费.阿里云的ons还支 ...
- UI设计篇·入门篇·简单动画的实现,为布局设置动画,用XML布置布局动画
不仅仅控件可以设置动画,一个布局也可以设置动画, 当给一个布局设置了动画的时候,这个布局里所包含的控件都会依赖执行这些动画. 为布局设置动画的实现步骤: 1.新建一个动画,设置需要实现的形式 2.新建 ...
- 性能测试四十六:Linux 从网卡模拟延时和丢包的实现
Linux 中模拟延时和丢包的实现 使用ifconfig命令查看网卡 Linux 中使用 tc 进行流量管理.具体命令的使用参考 tc 的 man 手册,这里简单记录一下使用 tc 模拟延时和丢包的命 ...
- RabbitMQ学习之延时队列
原帖参考:http://www.cnblogs.com/telwanggs/p/7124687.html?utm_source=itdadao&utm_medium=referral http ...
- java实现rabbitMQ延时队列详解以及spring-rabbit整合教程
在实际的业务中我们会遇见生产者产生的消息,不立即消费,而是延时一段时间在消费.RabbitMQ本身没有直接支持延迟队列功能,但是我们可以根据其特性Per-Queue Message TTL和 Dead ...
随机推荐
- BZOJ2005: [Noi2010]能量采集(欧拉函数)
Description 栋栋有一块长方形的地,他在地上种了一种能量植物,这种植物可以采集太阳光的能量.在这些植物采集能量后, 栋栋再使用一个能量汇集机器把这些植物采集到的能量汇集到一起. 栋栋的植物种 ...
- 网络流最大流——dinic算法
前言 网络流问题是一个很深奥的问题,对应也有许多很优秀的算法.但是本文只会讲述dinic算法 最近写了好多网络流的题目,想想看还是写一篇来总结一下网络流和dinic算法以免以后自己忘了... 网络流问 ...
- 10、初识constexpr和常量表达式
常量表达式:是指值不会改变并且在编译过程就能得到计算结果的表达式.显然字面值属于常量表达式,用于表达式初始化的const对象也是常量表达式. 1.判断一个变量是不是常量表达式 一个对象(表达式)是不是 ...
- Interger对象不要用==进行比较
为了更好的空间和时间性能,Integer会缓存频繁使用的数值,数值范围为-128到127,在此范围内直接返回缓存值. IntegerCache.low 是-128,IntegerCache.high是
- MyBatis mapper文件中使用常量
MyBatis mapper文件中使用常量 Java 开发中会经常写一些静态常量和静态方法,但是我们在写sql语句的时候会经常用到判断是否等于 //静态类 public class CommonCod ...
- python 队列、栈
队列 常规队列 双端队列 优先级队列 栈
- matplotlib调整子图大小
因为子图太多而导致每个子图很小,很密,如何调整
- 优先队列-UVA10603
#include<cstdio> #include<cstring> #include<queue> using namespace std; typedef st ...
- PAT (Basic Level) Practice (中文)1023 组个最小数 (20 分) (排序)
给定数字 0-9 各若干个.你可以以任意顺序排列这些数字,但必须全部使用.目标是使得最后得到的数尽可能小(注意 0 不能做首位).例如:给定两个 0,两个 1,三个 5,一个 8,我们得到的最小的数就 ...
- spark-sklearn TypeError: 'JavaPackage' object is not callable
from sklearn import svm, datasets from spark_sklearn import GridSearchCV from pyspark import SparkCo ...