论文阅读笔记(四)【TIP2017】:Video-Based Pedestrian Re-Identification by Adaptive Spatio-Temporal Appearance Model
Introduction
(1)背景知识:
① 人脸识别是具有高可靠性的生物识别技术,但在低解析度(resolution)和姿态变化下效果很差.
② 步态(gait)是全身行为的生物识别特征,大部分步态识别方法是基于轮廓而不受外貌影响,但在复杂的背景和遮挡下轮廓难以提取.
(2)问题场景:
假设行人在不同的相机中不更换衣服,结合人体外貌特征和步态特征进行识别.
难点:行人重识别受到姿态、视角、光照、遮挡的影响,空间对齐(spatial alignment)通过处理不同部位的样貌来解决该问题. 然而人体部位在不同阶段也有变化,如游泳时手臂样貌会变化,且会遮挡躯干等.
(3)本文工作:
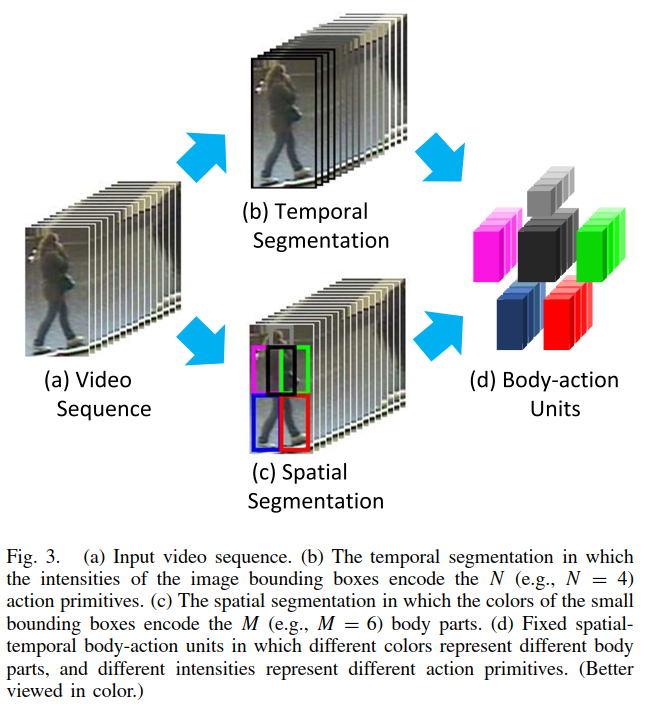
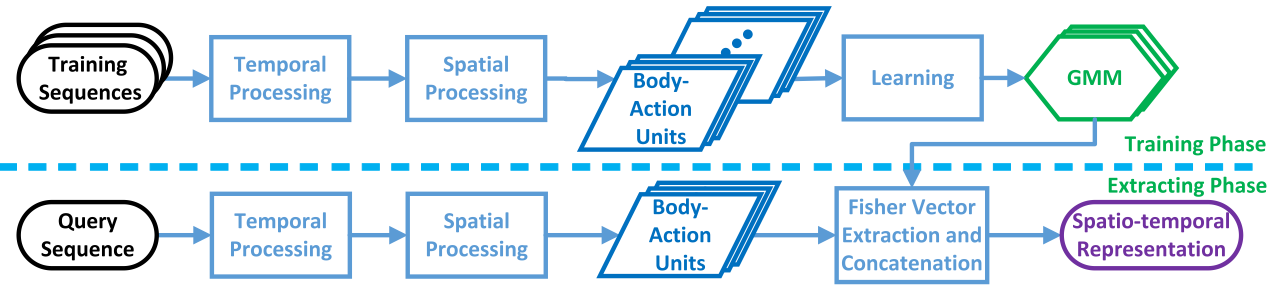
提出了一个时空表示方法,对人体部位空间布局和动作原语(action primitive)的时间序列进行编码(关注的重点在于“行走”,忽略了其余动作),具体来说:
对于一个视频序列,裁剪成若干步行周期. 在时间上,将步行周期分割成不同的动作阶段;在空间上,将不同的身体部位按姿态划分. 由此得到众多的视频标记点(video blobs),每一个标记点对应一个动作原语,也称为人体动作单元(body-action unit).
从body-action units中提取出Fisher vectors(一种广义的Bag-of-Words类型的特征),由此构建出特征向量对行人的样貌进行表示.
(什么是BoW特征?【传送门】)
Proposed Method

(1)时空人体动作模型(Spatio-Temporal Body-Action Model)
① 提取步行周期:
对于一个视频 Q = (I1, I2, ..., It),每一帧 I 的运动能量强度计算为:
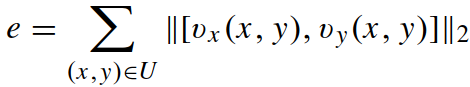
由于通常行人的下半身运动最突出和连续,U 是图片的下半部分的像素集,vx 和 vy 是水平和竖直方向上的 optic flow. (什么是optic flow?)
流动能量分布(Flow Energy Profile, FEP):E = (e1, e2, ..., et).
当 E 最大时,对应两腿重合的情况;当 E 最小时,对应两腿分开最远的情况.
但是没有规格化的 FEP 噪声比较大,需要通过离散傅里叶变化进行规格化,如上图的(b).
(离散傅里叶变化如何工作?)
每一个步行周期包含2段正弦曲线,即每条腿走一步是一段曲线.
将一个步行周期截取成更小的段(segments),对应不同的动作原语,S = (s1, s2, ..., sN).
② 确定Body-Action Unit:
将人体分为6部分:P = (p1, p2, ..., pM),pi 是某一帧上的一个区域,其中 M 设置为6.
结合在①中得出的步行周期的动作原语,得到规格为 M*N 的Body-Action Units,即人体的6个部位在步行的4个阶段不同的动作,定义如下:
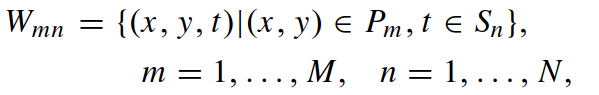
③ 自适应人体动作单元(adaptive Body-Action Units):
由于步行的动态性,识别的人体部位可能不准确,比如两只腿可能会重叠,如下图:

解决方法:对模板进行改进,分为两种:基于插值函数(interpolation function)和基于越阶函数(step function),调整后的结果如下图:
个人理解:前者的模板框是连续变换的,后者是离散变换的.

效果如下图:interpolation function 是逐渐变化,而 step function 的变化形式单一.

(2)Fisher vector的学习与提取:
特征构成:

其中 x~, y~, t~ 表示在这个unit中的像素点相对坐标,I(x,y,t) 为像素强度,由于图片有3个通道,因此 I 和它的偏导均为3维,每个像素点的特征总维数为 D = 3 + 7*3 = 24.
利用训练集得出 W,并提取出相应的特征,训练出GMM(高斯混合模型).
什么是高斯混合模型?【传送门】
训练得到的模型构成: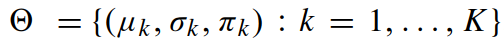 ,K设置为32.
,K设置为32.
μk、σk、πk 分别表示均值、协方差、高斯成分的先验概率(prior probability).
高斯成分(Gaussian component):
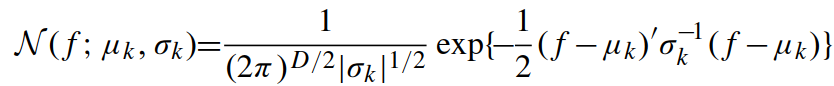
计算第 i 个像素特征描述的第 k 个高斯成分的后验概率为:
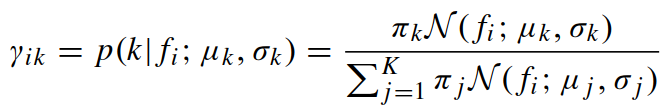
Fisher vector由wk、uk、vk 构成(其中 w 为标量,u 和 v 是向量),即 Θ(W) = [w1, u1, v1, ..., wK, uK, vK],计算如下:
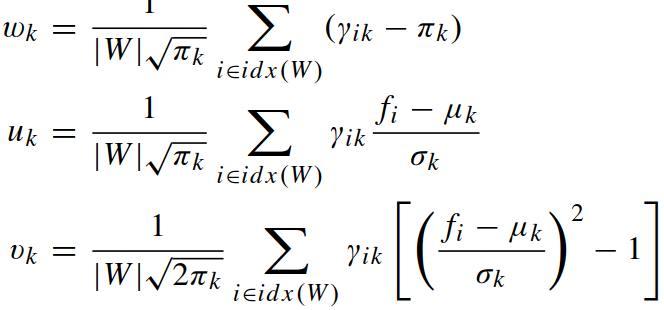
一段视频含有若干步行周期,对于任意一个周期,划分为 N 个动作原语,M 个人体动作部位,使用的GMM由 K 个高斯成分构成,每帧每部位的每个高斯成分有 2D+1 个特征构成,由此得出Fisher vector的维度是:(2D+1)KMN.
(w、u、v三个量的意义是什么?)
(3)结合监督学习:
结合样貌表征和监督距离矩阵,如KISSME.
KISSME简介:
查询集中的行人 x,有 nx 个特征 xi(i = 1, ..., nx);
视频库中的行人 y,有 ny 个特征 yj(j = 1, ..., ny).
特征的差记为 dij = xi - yj.
d 的行人内(intrapersonal)协方差矩阵为 ΣI, 行人间(extrapersonal)协方差矩阵 ΣE.
两个向量之比的对数为: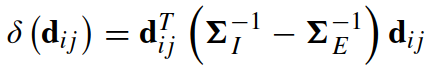
实验中的两个协方差矩阵可以估算为:
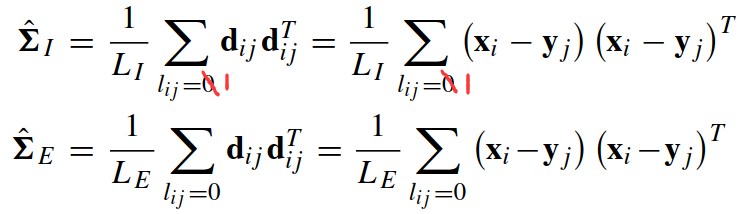
其中 lij = 1表示 xi 和 xj 属于同一个人,lij = 0表示 xi 和 xj 不属于同一个人. LI 和 LE 分别是相同特征对和不同特征对的数量.(感觉上面公式出错了,1写成了0)
KISSME度量矩阵 ψ 为: ,使得满足如下条件(第二个距离公式比第一个效果更好):
,使得满足如下条件(第二个距离公式比第一个效果更好):
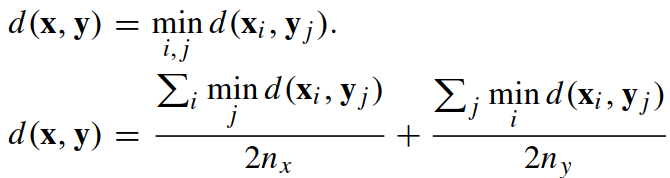
其中: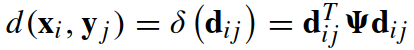
(KISSME怎么理解?)
(4)方法概览:
Experiments
(1)数据集和实验设置:
① 数据集:iLIDS-VID、PRID2011、SDU-VID(新引入)
iLIDS-VID、PRID2011的介绍在【前文】中介绍过;
SDU-VID数据集包含了300个行人的600个图像序列,每个序列包含16-346帧,平均130帧.
【数据集链接】
② 实验设置:
M = 6
N = 4
K = 32
由于不同的视频序列含有不同数量的步行周期,每一个周期提取出特征后,选用距离最近的来表示.(这段话没有理解作者确切的意思,暂且这么理解)
实验使用了24维和12维特征,24维是上文中 f 所提特征,12维是删去了颜色和二阶导数的特征.
(2)实验结果:
(实验结果的分析看得不是很明白,略过)
论文阅读笔记(四)【TIP2017】:Video-Based Pedestrian Re-Identification by Adaptive Spatio-Temporal Appearance Model的更多相关文章
- 论文阅读笔记四:CTPN: Detecting Text in Natural Image with Connectionist Text Proposal Network(ECCV2016)
前面曾提到过CTPN,这里就学习一下,首先还是老套路,从论文学起吧.这里给出英文原文论文网址供大家阅读:https://arxiv.org/abs/1609.03605. CTPN,以前一直认为缩写一 ...
- 论文阅读笔记四十九:ScratchDet: Training Single-Shot Object Detectors from Scratch(CVPR2019)
论文原址:https://arxiv.org/abs/1810.08425 github:https://github.com/KimSoybean/ScratchDet 摘要 当前较为流行的检测算法 ...
- 论文阅读笔记四十八:Bounding Box Regression with Uncertainty for Accurate Object Detection(CVPR2019)
论文原址:https://arxiv.org/pdf/1809.08545.pdf github:https://github.com/yihui-he/KL-Loss 摘要 大规模的目标检测数据集在 ...
- 论文阅读笔记四十六:Feature Selective Anchor-Free Module for Single-Shot Object Detection(CVPR2019)
论文原址:https://arxiv.org/abs/1903.00621 摘要 本文提出了基于无anchor机制的特征选择模块,是一个简单高效的单阶段组件,其可以结合特征金字塔嵌入到单阶段检测器中. ...
- 论文阅读笔记四十四:RetinaNet:Focal Loss for Dense Object Detection(ICCV2017)
论文原址:https://arxiv.org/abs/1708.02002 github代码:https://github.com/fizyr/keras-retinanet 摘要 目前,具有较高准确 ...
- 论文阅读笔记四十三:DeeperLab: Single-Shot Image Parser(CVPR2019)
论文原址:https://arxiv.org/abs/1902.05093 github:https://github.com/lingtengqiu/Deeperlab-pytorch 摘要 本文提 ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- 论文阅读笔记四十五:Region Proposal by Guided Anchoring(CVPR2019)
论文原址:https://arxiv.org/abs/1901.03278 github:code will be available 摘要 区域anchor是现阶段目标检测方法的重要基石.大多数好的 ...
- 论文阅读笔记四十二:Going deeper with convolutions (Inception V1 CVPR2014 )
论文原址:https://arxiv.org/pdf/1409.4842.pdf 代码连接:https://github.com/titu1994/Inception-v4(包含v1,v2,v4) ...
- 论文阅读笔记四十一:Very Deep Convolutional Networks For Large-Scale Image Recongnition(VGG ICLR2015)
论文原址:https://arxiv.org/abs/1409.1556 代码原址:https://github.com/machrisaa/tensorflow-vgg 摘要 本文主要分析卷积网络的 ...
随机推荐
- android编译/反编译常用工具及项目依赖关系
项目依赖关系 apktool:依赖smali/baksmali,XML部分 AXMLPrinter2 JEB:dx 工具依赖 AOSP , 反编译dex 依赖 apktool dex2jar:依赖 A ...
- docker安装mysql/redis
1.安装mysql容器 #搜索mysql镜像 docker search mysql #拉取mysql镜像 docker pull docker.io/mysql #创建mysql容器,MYSQL_R ...
- Leetcode 与树(TreeNode )相关的题解测试工具函数总结
最近在剑指Offer上刷了一些题目,发现涉及到数据结构类的题目,如果想在本地IDE进行测试,除了完成题目要求的算法外,还需要写一些辅助函数,比如树的创建,遍历等,由于这些函数平时用到的地方比较多,并且 ...
- python中class的定义及使用
#类(Class): 用来描述具有相同的属性和方法的对象的集合.它定义了该集合中每个对象所共有的属性和方法. #对象:它是类的实例化. #方法:类中定义的函数. #类(Class) 由3个部分构成: ...
- SQL语法学习记录——JOIN
学习内容参考来源:www.runoob.com JOIN准备 --为了方便练习,在数据库中创建演示数据: create database TEST; use TEST ; ---------- go ...
- maven的核心概念——聚合
第十六章聚合 16.1 为什么要使用聚合 将多个工程拆分为模块后,需要手动逐个安装到仓库后依赖才能够生效.修改源码后也需要逐个手动进行clean操作.而使用了聚合之后就可以批量进行Maven工程的安装 ...
- javascript 基础整理
js编码标准 参考 数据类型 注意事项
- android中常用的布局管理器
Android中的几种常用的布局,主要介绍内容有: View视图 RelativeLayout 相对布局管理器 LinearLayout 线性布局管理器 FrameLayout ...
- Xamarin.Forms弹出对话框插件
微信公众号:Dotnet9,网站:Dotnet9,问题或建议,请网站留言: 如果您觉得Dotnet9对您有帮助,欢迎赞赏. Xamarin.Forms弹出对话框插件 内容目录 实现效果 业务场景 编码 ...
- c#枚举转字典或表格
using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; usin ...