Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
在上一章(Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立)
我们提到,在输出流DFSOutputStream创建后,DataStreamer也随之创建,并且被启动
下文主要是围绕DataStreamer进行讲解
DataStreamer是一个守护线程类,继承关系如下。
观察DataStreamer的run方法,没有意外的,我们可以发现他和普通的做法一样,用一个死循环维持线程执行,直到客户端关闭
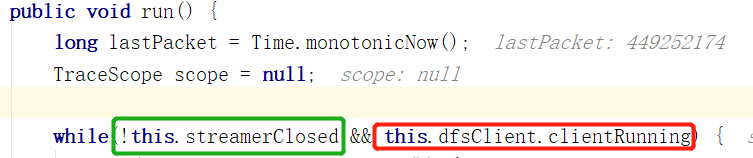
并且通过一个streamerClosed的布尔变量作为开关,控制守护线程的开启与关闭。
这个变量被volatile修饰,根据Happens-Before原则推测,其他线程通过打开或关闭这个开关,来控制DataStreamer的运作。

DataStreamer,从名字上已经能猜到,是一个控制数据传输的类
DataStreamer简要的生命周期与主要职责:
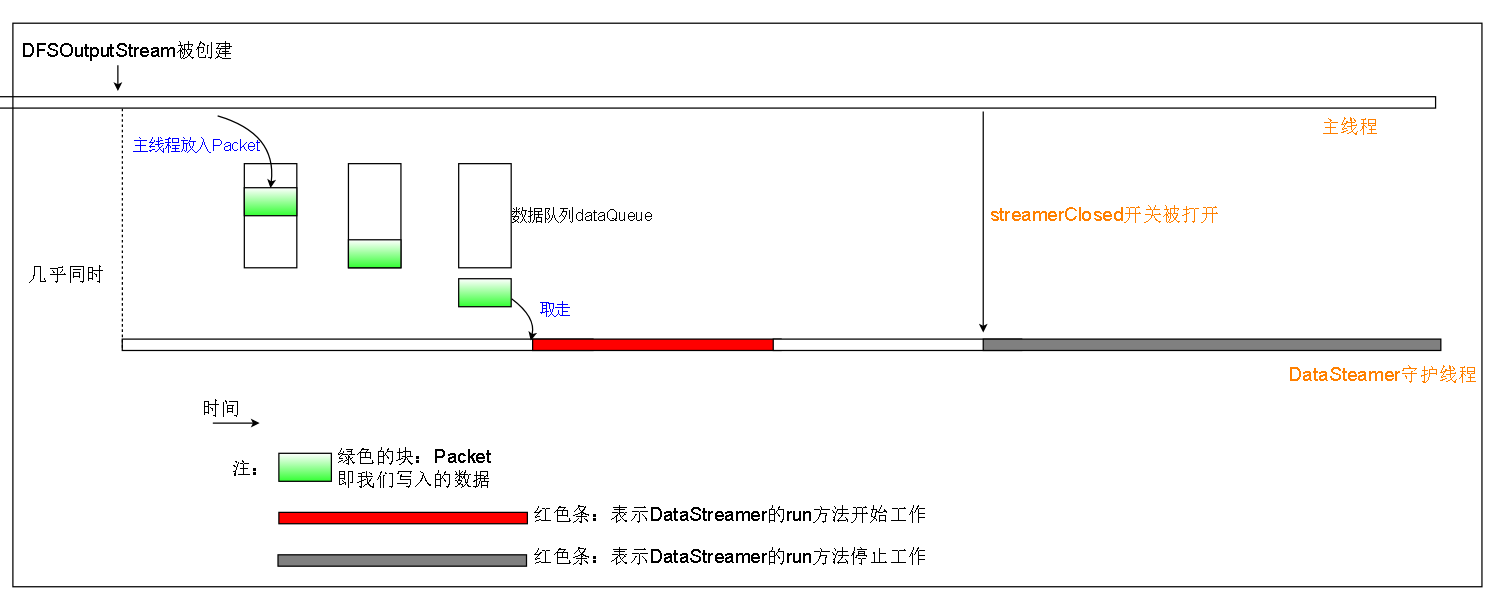
1.在DFSOutputStream被创建的时候同时被创建,并且作为一个守护线程,被主线程开启
2.DataStreamer维护一个数据队列dataQueue,并且等待主线程往这个队列放入数据包(Packet),当有数据包的时候开始工作
关于数据包是怎么来的,相关博文 : Hadoop3.1.1源码Client详解 : 入队前数据写入
3.当文件被close的时候,DataStreamer的streamerClosed开关被打开,DataStreamer使命完成
流程图:
重点:分析DataStreamer的工作流程
首先我们要知道DataStreamer是一个有工作状态的守护线程,并且状态存储在stage这个成员变量中。
这个成员变量的类型是枚举BlockConstructionStage,关于这个枚举各个值的含义如下:
关于流水线(PipeLine)以及恢复(Recovery),详见:
Hadoop架构: 流水线(PipeLine)
Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)
以下分析的是DataStreamer的run方法
以下2张图取自DataStreamer的run方法中,DataStreamer是一个守护线程(下文有介绍),他负责在他的run方法中启动一个循环,一直监听数据队列的动静
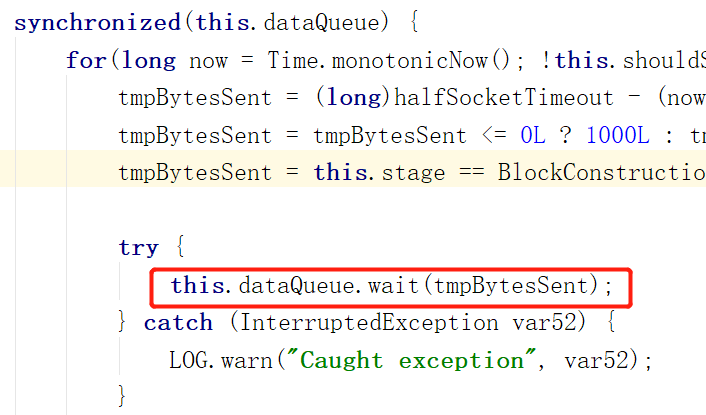
第一张图:
在run方法的while循环中锁住了dataQueue,并且内部有一个for循环,来判断是否让当前线程睡眠一段时间(tmpBytesSent)
进入for循环的条件是 (以下所有条件都要成立)
.DataStreamer不停止工作
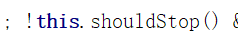
2.消息队列为空,表示暂时没有数据可传输

3.DataSteamer不处于数据传输阶段,或者数据包发送较快(未证实是否符合第二个条件意思)
如果不处于发送数据阶段,可能要发送心跳包,而后面的时间可能是用来限制心跳发送频率的。
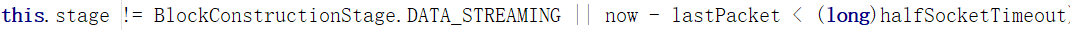
或者
.
doSleep变量为真,而这个变量取决于下图这个方法
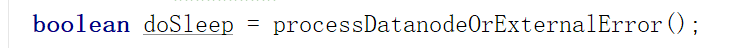
关于这个方法请见:
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 处理异常
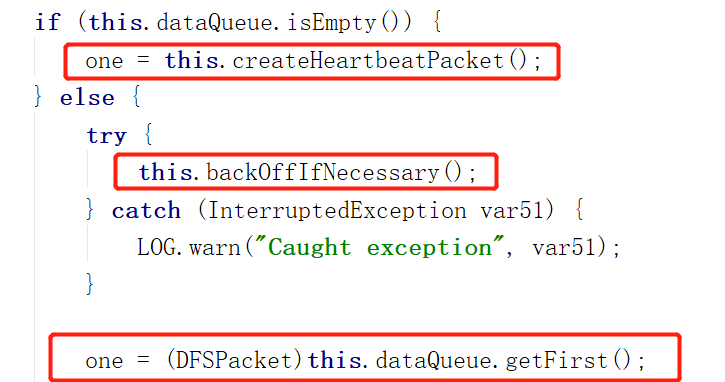
第二张图:
第二张图告诉我们,DataStreamer首先会检查数据队列是否为空,如果是,那么发送给DataNode的将是一个心跳包,来告诉DataNode,客户端还在线(活着),
在队列不空的情况下,会检查客户端的请求是否太过频繁,导致DataNode来不及处理,如果是,则会歇一会(当前线程sleep)。
以上情况都不是的话,才是从数据队列真正获取数据包
获取数据包后做什么呢?
主要是建立起数据传输的流水线,也就是setUp Pipeline
分两种情况建立(红框)
.当前的数据需要写入新的Block。( 客户端会向NameNode申请新的Block )
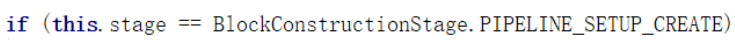
.当前数据需要写入旧有的Block(Append : 追加) 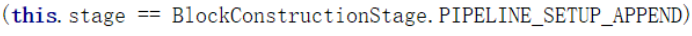
分需求架设流水线:

这里提前说一下 this.stage 这个成员变量,这个成员变量的类型是枚举

状态切换简述:当我们调用的是create方法,要新建文件的时候,stage默认是PIPELINE_SETUP_CREATE
当一个块写完之后,需要添加新的块,会在上一个块end掉的时候(调用endBlock),把stage设置成PIPELINE_SETUP_CREATE,这样一来下次流水线也是被建立来创建新的块,达到添加块的目的。

最后蓝色框告诉我们,两中情况除了流水线的建立不同,其他过程并没有什么区别。建立完流水线后共有的操作是调用initDataStreaming函数,这个为数据传输提供环境
.设置一下当前DataStream的名字(名字由当前正在传输的文件 + 当前正在传输的块组成)
.创建一个ResponseProcessor,并且开启他,这个线程负责接收DataNode发送回来的ACK(每当我们发出一个数据Packet,DataNode都需要发送ACK回复我们表示他收到了,类似TCP连接)
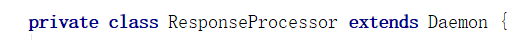
. 将当前DataStreamer状态设置成 DATA_STREAMING,表示正在传输数据
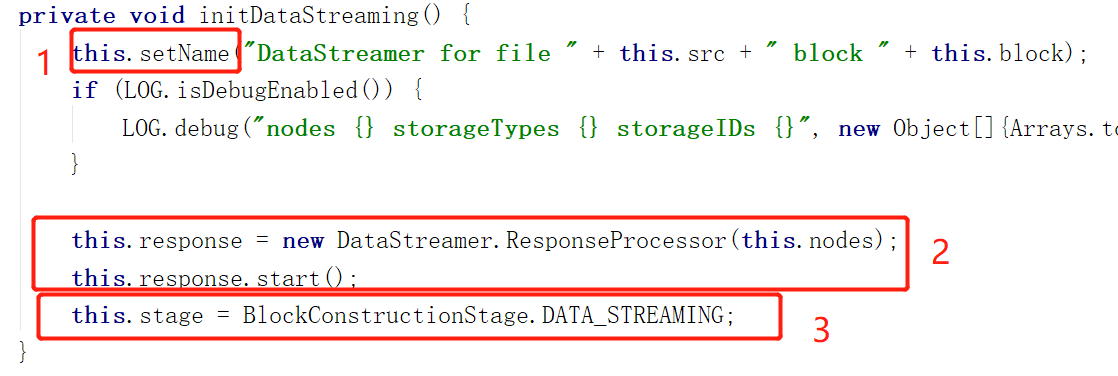
ResponseProcessor可以和DataStreamer线程并行工作,也就是一个负责发,一个负责收,可以同时工作。
我们来看一下ResponseProcessor是怎么处理DataNode发回来的ACK的
首先ResponseProcessor的run方法中维持着一个循环,用来接收ACK。只要ResponseProcessor不被关闭,客户端正在运行,就会一直接收ACK。
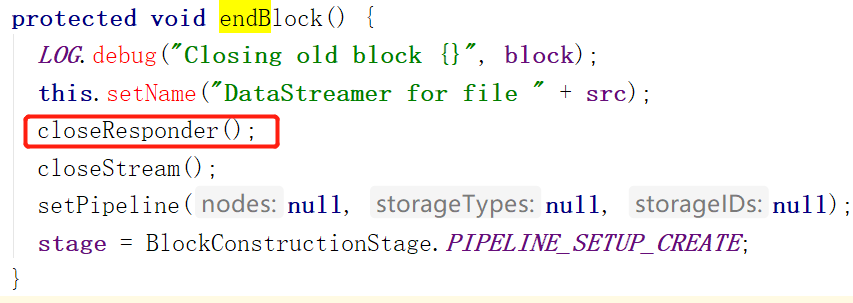
什么时候关闭呢?当调用endBlock方法的时候。也就是说每个Block在DataStreamer这对应一个ResponseProcessor来接收ACK,如果一个Block写完了,会调用endBlock把当前的ResponseProcessor
关闭并销毁。当再创建一个块,需要传输数据的时候,会再创建一个ResponseProcessor。


ResponseProcessor具体的工作原理,请见:Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
似乎架设流水线被忘记了。我们一 一道来
请见:
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 创建块
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 流水线架设 : 流水线恢复/append
我们接着讲DataStreamer的run方法
紧接着initDataStreaming之后:如果当前要写入流水线的Packet是最后一个包,也就是用来通知流水线上DataNode当前Block已经写完了的包。(称为lastPacket)
那么此处会等待所有lastPacket之前的Packet被确认。然后把流水线状态设置为关闭,但是此时还没有把lastPacket写到流水线上。在把lastPacket写到流水线上到客户端确认lastPacket被DataNode收到
的过程中,流水线可能失败,那么就会发生流水线关闭阶段失败的恢复。详细请见 Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery) 的文末

接着是把Packet进行移动

终于要把Packet写入流水线了。
如果Packet不能成功写入流水线,就会调用markFirstNodeIfNotMarked函数
markFirstNodeIfNotMarked的作用是如果流水线上没有DataNode被认为是不正常工作的。那么将会把第一个DataNode当成是不能工作的DataNode

收尾工作

DataStream从架构流水线到传输Packet的流程讲解完毕。
Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之DataStreamer(Packet发送) : 主干的更多相关文章
- Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之ResponseProcessor(ACK接收)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇文章: Hadoop3.1.1源码Client详解 : Packet入队后消息系统运作之D ...
- Hadoop3.1.1源码Client详解 : 入队前数据写入
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 紧接着上一篇: Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立 先给出 ...
- Hadoop3.1.1源码Client详解 : 写入准备-RPC调用与流的建立
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 关于RPC(Remote Procedure Call),如果没有概念,可以参考一下RMI(Remot ...
- Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览
一.设计原理 1.Hadoop架构: 流水线(PipeLine) 2.Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS 3.Hadoop架构: 关于Recovery (Lease ...
- NopCommerce源码架构详解--初识高性能的开源商城系统cms
很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从中学习很多企业系统.软件开发的规范和一些新的技术.技巧,可以快速地提高我们 ...
- NopCommerce源码架构详解
NopCommerce源码架构详解--初识高性能的开源商城系统cms 很多人都说通过阅读.学习大神们高质量的代码是提高自己技术能力最快的方式之一.我觉得通过阅读NopCommerce的源码,可以从 ...
- Nop--NopCommerce源码架构详解专题目录
最近在研究外国优秀的ASP.NET mvc电子商务网站系统NopCommerce源码架构.这个系统无论是代码组织结构.思想及分层都值得我们学习.对于没有一定开发经验的人要完全搞懂这个源码还是有一定的难 ...
- vue项目打包后使用reverse-sourcemap反编译到源码(详解版)
首先得说一下,vue项目中productionSourceMap这个属性.该属性对应的值为true|false. 当productionSourceMap: true,时: 1.打包后能看到xxx ...
- linux 基础入门(8) 软件安装 rpm、yum与源码安装详解
8.软件 RPM包安装 8.1rpm安装 rpm[选项]软件包名称 主选项 -i 安装 -e卸载 -U升级 -q查找 辅助选项 -ⅴ显示过程 -h --hash 查询 -a-all查询所有安装的包 - ...
随机推荐
- Unity网络通讯(一)获取计算机的MAC地址
1 string GetMac() { string mac = ""; mac = GetMacAddressBySendARP(); return mac; } [DllImp ...
- static静态不是很静
在类中定义变量时,不会开辟存储空间,只有类定义一个对象时才会开辟类中成员变量的内存空间,且建立一个对象开辟一次,大小与类中的成员变量及函数有关.而static在静态区开辟内存空间,不占用内存空间. 1 ...
- mysql的优化(经典必看)
1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽 ...
- flask 路由规划(blueprint)
# 统一路由蓝牙规划 # file:blueprint_route.py from flask import Blueprint route_test = Blueprint("home&q ...
- 第四篇,JavaScript面试题汇总
JavaScript是一种属于网络的脚本语言,已经被广泛用于web实用开发,常用来为网页添加各种各样的动态功能,为用户提供更流畅美观的浏览效果.通常JavaScript脚本是通过嵌入在HTML中来实现 ...
- c数据结构 -- 栈与队列
栈和队列 ·栈和队列是两种常用的.重要的数据结构 ·栈和队列是限定插入和删除只能在表的“端点”进行的线性表 栈 只能在队尾插入,只能在队尾删除 -- 后进后出 表尾称为栈顶:表头称为栈底 插入元素到栈 ...
- Failed to start mysqld.service: Unit not found
输入命令 systemctl start mysql.service 要启动MySQL数据库是却是这样的提示 Failed to start mysqld.service: Unit not foun ...
- jar包和war包的介绍和区别(转载)
来源:https://www.jianshu.com/p/3b5c45e8e5bd 做Java开发,jar包和war包接触的挺多的,有必要对它们做一个深入的了解,特总结整理如下: 1.jar包的介绍 ...
- maskrcnn实现.md
mask rcnn学习 Mask R-CNN实现(https://engineering.matterport.com/splash-of-color-instance-segmentation-wi ...
- DVWA全级别之Insecure CAPTCHA(不安全的验证码)
Insecure CAPTCHA Insecure CAPTCHA,意思是不安全的验证码,CAPTCHA是Completely Automated Public Turing Test to Tell ...