机器学习-特征工程-Missing value和Category encoding
好了,大家现在进入到机器学习中的一块核心部分了,那就是特征工程,洋文叫做Feature Engineering。实际在机器学习的应用中,真正用于算法的结构分析和部署的工作只占很少的一部分,相反,用于特征工程的时间基本都占70%以上,因为是实际的工作中,绝大部分的数据都是非标数据。因而这一块的内容是非常重要和必要的,如果想要提高机器学习应用开发的效率,feature engineering就像一把钥匙,一个加速器,能给整个项目带来事半功倍的效果。另外,feature engineering做的好不好,直接关系到后面的模型的质量。正因为上面的原因,feature engineering我准备详细的解释,我准备花三篇随笔说完。这是第一篇,主要介绍两部分,分别是missing value的处理和categorical data的处理。其中missing value的处理相对简单,复杂的是categorical data的处理,有很多种处理方式,我们在这边就直说常用的5中方式。那么好啦,咱们就直接进入主题内容吧。
- Missing value
missing value 顾名思义就是有些实际数据中,有很多的数值是缺失的,那么怎么处理这些缺失的数据,就变成了一个很有必要的事情。基本上,咱们处理missing value的方法就是三种,分别是:dropping, Imputation, 和 An extension to imputation。那下面就这三种方法分别来进行代码的演示和结果的展示
- Dropping。顾名思义,dropping的意思就是整个删除掉一整行的数据。这里的意思就是,如果某一列数据含有空数据NaN, 那么就直接删除掉这一整行的数据,它的操作如下所示
missing_data_cols = [col for col in train_X.columns if train_X[col].isna().any()]
#drop missing data columns
reduced_train_X = train_X.drop(missing_data_cols, axis =1)上面代码的第一句是为了找出所有含有空数据的column,第二句代码的意思就是删除掉这些含有空数据的column,记住axis参数设置成1代表着是column,如果设置成0或者没有设置,则默认指删除行row。
- Imputation。这里对于处理missing value的第二种方法是指的填充的方法(不知道翻译的对不对哈),它是什么意思呢,其实很简单,它的意思就是将这个空值的element,根据一定的条件填充数据,这里的条件可以是平均值,中位数,出现频率最高的等,具体采用哪种方式,还是按照里面的参数strategy进行设置的。具体的代码实现方式,是通过下面来演示
from sklearn.impute import SimpleImputer
my_imputer = SimpleImputer(strategy = "mean")
my_imputer.fit_transform(train_X)
imputed_train_X = pd.DataFrame(my_imputer.fit_transform(train_X))注意这里需要引进一个新的库进行数据处理,那就是sklearn, 它是sci-kit learn的缩写。这个库也是一个很牛逼的库,它和TensorFlow的功能一样,提供了丰富的数据处理方面的接口,可以极大的方便咱们的数据处理,也提供了很多常用的模型供咱们选择,在机器学习领域可以说是经常用到的。上面第二行代码就是设置通过什么方式来impute,这里设置的是平均数。第三行返回的是一个numpy array,第四行咱们将这个impute过后的numpy array转化成dataframe。
- An Extension to Imputation。从这个命名咱们可以看出它是对上面imputation的一种补充,是基于imputation的。它实际上是先添加几个column(有哪些column有missing value,咱们就添加几个column),这些添加的column是boolean值,如果某一行对应是missing value,这个Boolean值就是True, 如果不是missing value,则是False。咱们看看下面的代码和图片能够更加深刻的理解。
X_train_extension = train_X.copy()
X_val_extension = val_X.copy() #making columns with missing data
for col in missing_data_cols:
X_train_extension[col + "_was_missing"] = train_X[col].isnull() #imputation
my_imputer = SimpleImputer()
X_train_extension_impute = pd.DataFrame(my_imputer.fit_transform(X_train_extension))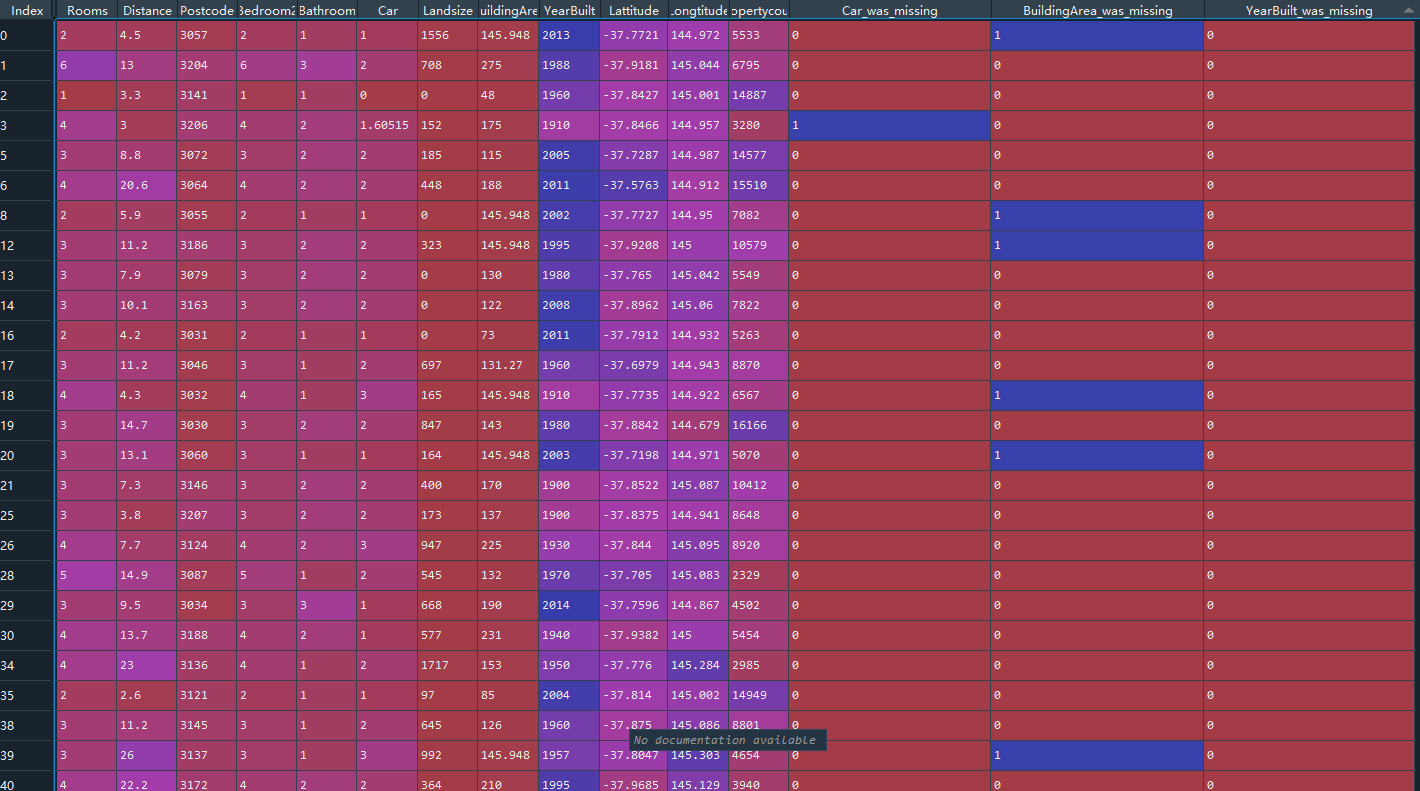
上面展示了代码还有一小段结果的截图。大家可以很明显的看出来添加了三个新的columns。这里的顺序根据代码也可以看出来,是先添加新的columns,然后再imputation。
- Categorical Data encoding
上面一节主要讲的是Missing value的一些简单的处理方式,在实际的数据处理中,咱们大部分时间遇到的数据并不是numerical data,相反,咱们大部分时间遇到的都是categorical data,可是在咱们的计算机处理数据的时候,处理的都是numerical data,所以咱们得想办法将这些categorical data转成numerical才行。实际中咱们经常使用的策略就是下面的五种方式,下面咱们来一个个讲解一下,这一块也是咱们的重点内容。
- dropping。和前面的missing data一样,直接dropping是最简单粗暴的方法,虽然这是最简单的方法,但是实际中,这种方式却并不常用,因为她往往不利于咱们的模型。极端的想一下,如果咱们的dataframe都是categorical的数据,难道咱们直接把他们全部删除?????哈哈,那咱们还训练个毛模型。但是,咱们还是得了解一下,毕竟在极少数的情况下,咱们还是要用到的。咱们直接看代码演示,然后解释一下
X_train_result_drop = X_train_result.select_dtypes(exclude=["object"])
看看上面这一句简单的代码,通过dataframe的select_dtypes方法,传递一个exclude参数,因为在dataframe中object的数据类型就是categorical data,所以上面的api直接就是删除了所有categorical data的数据。
- Label encoding。对于有些categorical data,咱们可以给每一个category赋值一个数字,例如Female=0,Male = 1等等。那么哪些categorical data适合label encoding呢?就是那些一列数据中category的种类不是特别多的数据。例如一列categorical data一共有20个category或者50个category都是OK的,如果直接有1000多category,那么简单的labeling的效率就不高了,结果也可能不理想。这其实在实际的处理中还是经常会用到的。下面通过一句简单的代码进行演示。注意,这里都是用sklearn这个组件来进行的演示的,并没有用其他的例如TensorFlow来演示。
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
X_train_result_label[col] = label_encoder.fit_transform(X_train_result[col])#one column after one column咱们也可以看出,咱们得先创建一个LabelEncoder实例对象,然后对每一个categorical data的column分别应用encoder, 如果需要对多个categorical column进行lable encoding, 咱们得写一个循环,分别对每一个column 进行label encoding。
one-hot encoding。这是一个大家可能最常用到的一种category encoding的方法,至少在我学习机器学习的过程中,这是最常见到的一种方式,那么到底什么是one-hot encoding呢?这里没有一个官方的定义,最直接的方法就是先看一下下面的图片,这是最直接的方式,也最简单易懂
 现在咱们来解释一下,首先先计算出一个category column中一共有多少个categories,然后有多少category就创建多少个columns,每一个category对应一个column,最后在相对应的位置填充1,其他则填充0。故而新创建的dataframe中,每一行只有一个1 其他都是0。这也是one-hot encoding这个名字的来历。那咱们来看看one hot encoding的代码实现吧
现在咱们来解释一下,首先先计算出一个category column中一共有多少个categories,然后有多少category就创建多少个columns,每一个category对应一个column,最后在相对应的位置填充1,其他则填充0。故而新创建的dataframe中,每一行只有一个1 其他都是0。这也是one-hot encoding这个名字的来历。那咱们来看看one hot encoding的代码实现吧from sklearn.preprocessing import OneHotEncoder
one_hot_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
X_train_result_one_hot = pd.DataFrame(one_hot_encoder.fit_transform(X_train_result[object_cols]))和之前的label encoding一样,它也需要引用sklearn这个库,但是它是先实例化一个OneHotEncoder对象,然后用这个encoder一次性的应用于多个categorical columns, 而不像label encoding那样要一个column一个column的调用。one hot encoding是categorical data encoding中最常用的技术了,但是在有些情况下也不是很适用,例如:如果一个categorical column的categories太多的话,例如1000个,10000个等等,那么它就不适用于one hot encoding了,因为有1000个categories,就会产生1000个columns,产生的数据就太大了,而且很容易会产生overfitting的情况。
Count encoding
这也是一种简单而且高效的encoding方法,它是先计算一个categorical column中的每一个category出现的次数,然后就将这些category用次数来代替,同一个category被代替后,数值是一样的,有点和series.values_countt()有点类似,大家满满体会一下哈。这种方式和label encoding一样的简单,而且Python也帮助咱们处理好了细节部分,咱们可以通过下面的方式直接调用它的接口进行计算
import category_encoders as ce
count_encoder = ce.CountEncoder()
categorical_data_ce = count_encoder.fit_transform(ks[categorical_cols])从上面的代码,咱们可以看出来,它也是encoder直接作用于多个categorical columns。
Target encoding Target encoding是根据target来计算category的,然后来替代的。那么它的具体流程是什么呢? 其实呢它是很简单的,就是先看每一个category对应的target值,然后计算相对应的target的平均数,最后用这个平均数来代替每一个category。其实就是这么的so easy。老规矩,咱们先看看如何实现的
import category_encoders as ce
target_encoder = ce.TargetEncoder(cols=categorical_cols)
target_encoder.fit_transform(train[categorical_cols], train.outcome)从上面咱们可以看出,整体的步骤和count encoding很相似。但是这种方法也有一个致命的弱点,那就是这里的encoding太过于依赖target了,有很大的可能会有data leakage的风险,target encoding与target有很强的correlation,就有很强的data leakage的风险。所以大家在选择target encoding的时候一定要仔细考虑分析数据后在选择。
总结:最后国际惯例咱们先来总结一下feature engineering的第一部分,就是category data和missing value的处理。上面的一些方法是最简单常用的一些方法了,大家一定要熟悉理解应用,这里也设计到一些库的使用,我会在后面详细叫大家怎么用。missing value常用的处理方式是:1. dropping
2. Imputation
3. Extension to Imputation
然后category data的处理主要是下面的5中方式,这里大家一定要理解
1. Dropping
2. Label encoding
3. one hot encoding (最常用)
4. Count encoding
5. Target encoding (risk of data leakage)
机器学习-特征工程-Missing value和Category encoding的更多相关文章
- 机器学习-特征工程-Feature generation 和 Feature selection
概述:上节咱们说了特征工程是机器学习的一个核心内容.然后咱们已经学习了特征工程中的基础内容,分别是missing value handling和categorical data encoding的一些 ...
- 2022年Python顶级自动化特征工程框架⛵
作者:韩信子@ShowMeAI 机器学习实战系列:https://www.showmeai.tech/tutorials/41 本文地址:https://www.showmeai.tech/artic ...
- Python机器学习笔记 使用sklearn做特征工程和数据挖掘
特征处理是特征工程的核心部分,特征工程是数据分析中最耗时间和精力的一部分工作,它不像算法和模型那样式确定的步骤,更多的是工程上的经验和权衡,因此没有统一的方法,但是sklearn提供了较为完整的特征处 ...
- 谷歌大规模机器学习:模型训练、特征工程和算法选择 (32PPT下载)
本文转自:http://mp.weixin.qq.com/s/Xe3g2OSkE3BpIC2wdt5J-A 谷歌大规模机器学习:模型训练.特征工程和算法选择 (32PPT下载) 2017-01-26 ...
- python 机器学习库 —— featuretools(自动特征工程)
文档:https://docs.featuretools.com/#minute-quick-start 所谓自动特征工程,即是将人工特征工程的过程自动化.以 featuretools 为代表的自动特 ...
- 想搞机器学习,不会特征工程?你TM逗我那!
原文:http://dataunion.org/20276.html 作者:JasonDing1354 引言 在之前学习机器学习技术中,很少关注特征工程(Feature Engineering),然而 ...
- 机器学习 数据量不足问题----1 做好特征工程 2 不要用太多的特征 3 做好交叉验证 使用线性svm
来自:https://www.zhihu.com/question/35649122 其实这里所说的数据量不足,可以换一种方式去理解:在维度高的情况下,数据相对少.举一个特例,比如只有一维,和1万个数 ...
- python 机器学习(一)机器学习概述与特征工程
一.机器学习概述 1.1.什么是机器学习? 机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测 1.2.为什么需要机器学习? 解放生产力,智能客服,可以不知疲倦的24小时作业 ...
- 机器学习实战基础(十七):sklearn中的数据预处理和特征工程(十)特征选择 之 Embedded嵌入法
Embedded嵌入法 嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行.在使用嵌入法时,我们先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大 ...
随机推荐
- 【u236】火炬
Time Limit: 1 second Memory Limit: 128 MB 2008北京奥运会,你想成为四川汶川的一名火炬手,结果层层选拔,终于到了最后一关,这一关是一道很难的题:任意给定一个 ...
- ASP.NET Core 开启后台任务
本文告诉大家如何通过 Microsoft.Extensions.Hosting.BackgroundService 开启后台任务 实现 BackManagerService 类继承 Backgroun ...
- 备战省赛组队训练赛第六场(UPC)
传送门 外来博客题解1:戳这里 外来博客题解2:戳这里 CRWG全方位题解:戳这里
- Eclipse GlassFish Server 配置
一.下载GlassFish Server 通过如下地址下载合适版本: http://glassfish.java.net/public/downloadsindex.html htt ...
- Wannafly挑战赛25 因子 [数论]
一.题意 令 X = n!, 给定一大于1的正整数p 求一个k使得 p ^k | X 并且 p ^(k + 1) 不是X的因子 输入为两个数n, p (1e18>= n>= 10000 & ...
- python类型常用整理
# 一.数字 # int(..) # 二.字符串 # replace find join strip startswith split upper lower format # tempalte = ...
- Helm Chart 一键部署 Jenkins
Jenkins Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建.测试和部署软件.目前提供超过1000个插件来支持构建.部署.自动化, 满足任何项目的需要. Jenki ...
- mysql中information_schema.triggers字段说明
1. 获取所有触发器信息(TRIGGERS) SELECT * FROM information_schema.TRIGGERS WHERE TRIGGER_SCHEMA='数据库名'; TR ...
- macaca安装(mac)
macaca 安装 安装Homebrew/Node/npm/cnpm/carthage 这些工具的安装参见 appium 环境搭建 安装相关工具 $ brew install usbmuxd $ br ...
- JavaScript之DOM操作,事件操作,节点操作
1,DOM操作 1.1 概念 所谓DOM,全称Document Object Model 文档对象模型,DOM是W3C(World Wide Web Consortuum )标准,同时也定义了访问诸 ...