libsvm的安装,数据格式,常见错误,grid.py参数选择,c-SVC过程,libsvm参数解释,svm训练数据,libsvm的使用详解,SVM核函数的选择
直接conda install libsvm安装的不完整,缺几个.py文件。
第一种安装方法:
在/home/common/anaconda3/lib/python3.6/site-packages下创建一个libsvm文件夹,并将libsvm.so.2复制到到libsvm文件夹中(libsvm.so.2放在上一层文件夹中?),此外在该文件夹下再创建一个空的__init__.py文件,在libsvm中的Python文件夹中也添加_init_.py文件?。把python/下的svm.py、svmutil.py、commonutil.py三个文件考到新建的这个libsvm下的python文件夹中。
cp -r python/*.py /home/common/anaconda3/lib/python3.6/site-packages/libsvm/python/。
得到:
/home/common/anaconda3/lib/python3.6/site-packages/libsvm/
├── _init_.py
├── libsvm.so.2
├── python
├───── svm.py
├───── svmutil.py
└───── commonutil.py
这是我找的一个测试代码,运行结果如下:
optimization finished, #iter = 1
nu = 0.062500
obj = -0.250000, rho = 0.000000
nSV = 2, nBSV = 0
Total nSV = 2
Model supports probability estimates, but disabled in predicton.
Accuracy = 100% (1/1) (classification)
[1.0]
第二种装方式(适用于python项目移植到别的电脑上仍可用):在python IDE中新建一个项目,例如classify,在classify下面可以有自己的py代码文件,例如test.py。这时候,在classify下面建一个python package,例如名叫libsvm(切记,python package与普通文件夹的区别在于有一个init.py空文件!),这时候,将libsvm.so.2文件复制到这个libsvm文件夹下,然后再在libsvm文件夹下建一个python package,然后将svm.py、svmutil.py、commonutil.py都复制进来。那么在test.py中,就可以利用from libsvm.python import svmutil了。
windows上安装未测:
https://blog.csdn.net/m624197265/article/details/41894311
1. 从LIBSVM官网上https://www.csie.ntu.edu.tw/~cjlin/libsvm/#download下载所需要的安装LIBSVM版本,解压后文件夹重命名为libsvm,将之放入~Python36\Lib\site-packages目录,将libsvm文件夹下的tools和windows这两个文件夹加入到系统路径path里;
2. 到https://www.lfd.uci.edu/%7Egohlke/pythonlibs/#libsvm 下载对应版本的libsvm,pip进行安装成功后,在~Python36\Lib\site-packages目录下找到新生成的libsvm.dll,将其放到C:\windows\system32
测试:
from libsvm.svmutil import *
from libsvm.svm import *
y, x = [1, -1], [{1: 1, 2: 1}, {1: -1, 2: -1}]
prob = svm_problem(y, x)
param = svm_parameter('-t 0 -c 4 -b 1')
model = svm_train(prob, param)
yt = [1]
xt = [{1: 1, 2: 1}]
p_label, p_acc, p_val = svm_predict(yt, xt, model)
print(p_label)
如果输出结果为:
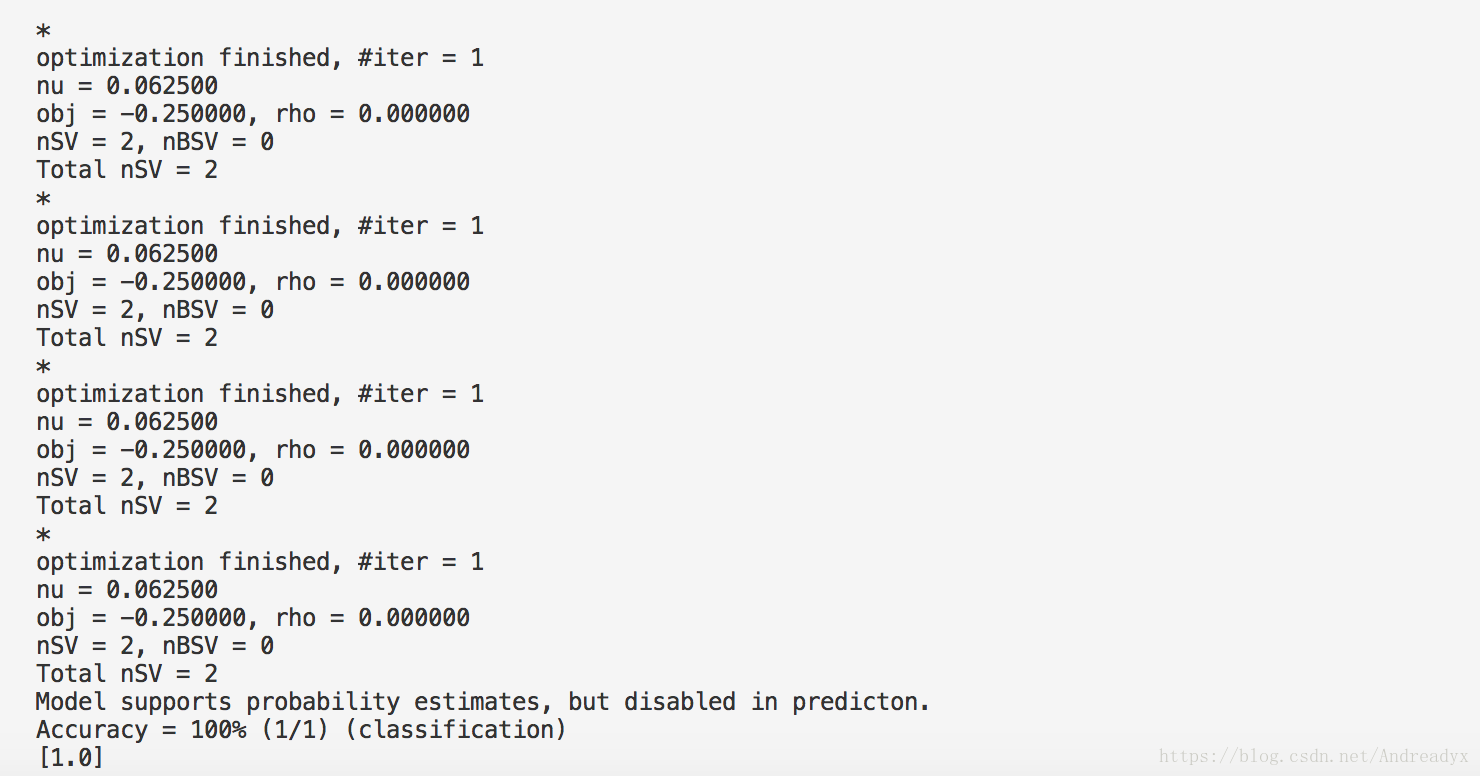
证明配置成功!
1.准备
https://github.com/cjlin1/libsvm
https://github.com/search?o=desc&q=libsvm&s=stars&type=Repositories
测试数据集:http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/
在windows下下载并使用MATLAB,则将matlab当前工作目录切换到libsvm**\matlab\子文件夹下,使用mex -setup,根据提示进行编译,编译完成之后该文件下多出四个.mexwin64/.mexwin32的文件。
之后输入make命令,安装完成。测试用例为:libsvmread(‘heart_scale’).
2. 测试举例
python环境变量配置测试: 进入libsvm下的子目录tools中,使用命令python测试python环境便令配置是否正确。
grid.py参数寻优测试: 进入libsvm子目录tools中,使用命令 python grid.py heart_scale,看输出最后一行 2048.0 0.0001220703125 84.0741 或者在tools目录下打开heart_scale.png,看到最佳c和g的值。
svm-train: 进入libsvm目录下,使用命令./svm-train heart_scale
,将结果保存在heart_scale.model中
svm-predict:还是在libsvm目录下,使用命令./svm-predict heart_scale heart_scale.model heart_scale.out,看输出最后一行Accuracy=??? 预测之后的标签保存在文件heart_scale.out中
3. svm-train和svm-predict使用说明:使用libsvm目录下的README,官方版使用说明,很全面。
4.libsvm数据格式:
本博客中使用libsvm310版本。
LIBSVM工具箱中集成了libsvm数据格式读取函数,在子目录matlab下,有源代码libsvmread.c和libsvmwrite.c。LIBSVM需要的数据格式如下:
0 1:-0.961538 2:-0.830769 # 标签列 index:value
0 1:-0.941545 2:-0.778706 # 均为归一化数据
0 1:-0.972158 2:-0.730858 #
4.1 libsvmread.c
打开README文档,发现对于libsvmread函数给出了具体用法。在libsvmread.c中也给出了“Usage”
void exit_with_help()
{
mexPrintf(
“Usage: [label_vector, instance_matrix] = libsvmread(‘filename’);\n”
);
} // label_vector:filename 第一列 , instance_matrix:特征数据
这是简单的应用,具体请看README或者libsvmread.c代码,这里不再赘述。
4.2 libsvmwrite.c
一般情况下,我们需要训练的是一组数据,想要使用LIBSVM还需要进行数据格式转换。使用matlab转换格式首先需要将输入数据转为矩阵,矩阵第一列为数据标签,使用libsvmwrite函数就可以成功转换。
网上有许多使用FormatDataLibsvm.xls工具的,但是又有人测试发现该工具只处理2000行一下数据,想要使用该工具的请参考http://blog.csdn.net/kobesdu/article/details/8944851。但我建议还是选择libsvmwrite函数进行libsvm格式转换。
void exit_with_help()
{
mexPrintf(
“Usage: libsvmwrite(‘filename’, label_vector, instance_matrix);\n”
);
}
使用libsvm时最好将instance_matrix归一化,避免过拟合。
使用实例
libsvm在工具包中已有示例数据heart_scale,可以直接测试。
[label_vector, instance_matrix] = libsvmread(‘heart_scale’)
libsvmwrite(‘heart_scale’, label_vector, instance_matrix)
5.常见错误
错误一:Traceback (most recent call last):
File “grid.py”, line 223, in run
if rate is None: raise RuntimeError(“get no rate”)
RuntimeError: get no rate
LIBSVM版本问题,刚开始我使用最高版本libsvm-321版本,显示一直是该错误,no rate,查了众多资料发现更改libsvm版本可以完美解决该问题,我使用的是libsvm310版本,python2.7,gnuplot4.6.6,在Windows和linux下均编译成功。
错误二:Timeout: gnuplot is not ready
该错误是gnuplot启动出错,解决方案为:重新执行。
重新打开一个窗口,进入到libsvm\tools\目录下,执行grid.py和easy.py.
错误三:set term x11
在linux下,使用gnuplot时显示set term x11,该错误可以忽略,但是想要修改的小伙伴们可以参考这里:http://blog.csdn.net/sweet_life/article/details/7251307。
错误四:gnuplot not found
解决方案:gnuplot路径设置错误,修改grid.py中 else条件后的gnuplot_exe路径。
if not is_win32:
svmtrain_exe = "../svm-train"
gnuplot_exe = "/usr/bin/gnuplot"
else:
# example for windows
svmtrain_exe = r"..\windows\svm-train.exe"
# gnuplot_exe = r"c:\tmp\gnuplot\bin\pgnuplot.exe"
gnuplot_exe = r"D:\Program Files\gnuplot466\bin\pgnuplot.exe"
6.grid.py参数选择
在libsvm 工具包中,作者很友好的将参数优选自动化,再也不需要手动调参了,下面讲解一下大概的使用以及参数选择原则。
使用grid.py需要安装python 和gnuplot两个软件,具体安装方法详见:
http://blog.csdn.net/u014772862/article/details/51828967
在这篇文章中给出了这两个软件的下载地址。
安装成功之后修改环境变量,将python 安装目录添加到计算机的环境变量path下。
1. 参数选择原则
在训练svm时, Chih-Jen Lin 提供了一个自动化参数选优的方式—grid search(由C和r组成),对每一个参数,使用libsvm得到一个cross-validation(CV)准确率,最优参数就是准确率最高时采用的参数。该方法常用在RBF核函数参数优选中。
以下内容摘自《MATLAB 神经网络30个案例分析》第13章:
“关于SVM参数的优化选取,国际上并没有公认统一的最好的方法,现在目前常用的方法就是让c和g在一定的范围内取值,对于取定的c和g对于把训练集作为原始数据集利用K-CV方法得到在此组c和g下训练集验证分类准确率,最终取使得训练集验证分类准确率最高的那组c和g做为最佳的参数,但有一个问题就是可能会有多组的c和g对应于最高的验证分类准确率,这种情况怎么处理?这里采用的手段是选取能够达到最高验证分类准确率中参数c最小的那组c和g做为最佳的参数,如果对应最小的c有多组g,就选取搜索到的第一组c和g做为最佳的参数。这样做的理由是:过高的c会导致过学习状态发生,即训练集分类准确率很高而测试集分类准确率很低(分类器的泛化能力降低),所以在能够达到最高验证分类准确率中的所有的成对的c和g中认为较小的惩罚参数c是更佳的选择对象。”
2. grid.py 使用
使用IDLE打开grid.py,切记不要使用notepad++等其他软件打开该文件。
修改gnuplot pathname:打开README,我们发现有这样一段话:
For windows users, please use pgnuplot.exe.
If you use cygwin on windows, please use gunplot-x11.根据上面的理解,在gnuplot安装目录下,打开bin目录,寻找pgnuplot.exe或者gunplot-x11。在linux下的话修改if条件后的路径,在windows下的话修改else下面的路径就ok啦。
找到gnuplot 的安装目录,打开gnuplot\bin\,复制该目录替换上面的c:\tmp\gnuplot\bin\pgnuplot.exe”,在windows环境下的修改方式如下:
if not is_win32:
svmtrain_exe = "../svm-train"
gnuplot_exe = "/usr/bin/gnuplot"
else:
# example for windows
svmtrain_exe = r"..\windows\svm-train.exe"
gnuplot_exe = r"D:\Program Files\gnuplot466\bin\pgnuplot.exe"修改成功后保存即可。grid.py 使用说明
3. 实例
- 测试输入:在使用grid.py之前,先将使用说明Usage列出:
grid.py [-log2c begin,end,step] [-log2g begin,end,step] [-v fold] [-svmtrain pathname] [-gnuplot pathname] [-out pathname] [-png pathname] [additional parameters for svm-train] dataset- 1
打开cmd窗口,将目录切换到grid.py所在的目录,执行以下命令:
#这里,采用默认参数
python grid.py heart_scale
#默认参数为:
fold = 5
c_begin, c_end, c_step = -5, 15, 2
g_begin, g_end, g_step = 3, -15, -2- 中间结果:执行grid.py,在cmd窗口和gnuplot 输出结果:
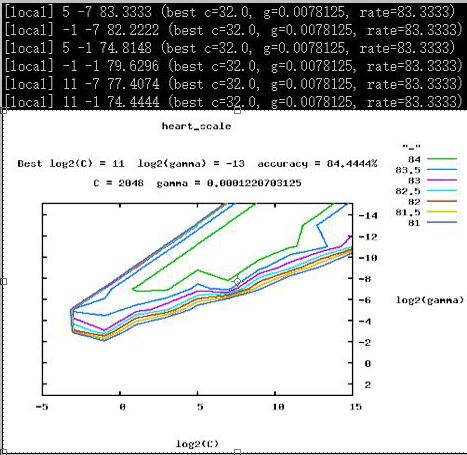
这里将上图窗口中的输出解释一下:
workers c1 g2 rate (best_c, best_g, best_rate)
# 其中,
best_c = 2.0**c1
best_g = 2.0**g1
if (rate > best_rate) or
(rate==best_rate and g1==best_g1 and c1<best_c1):
best_rate = rate
best_c1,best_g1=c1,g1
best_c = 2.0**c1
best_g = 2.0**g1
# grid.py 默认5-fold cross-validate,也就是说,一个(c,g)组可能对应多个rate,best_rate = max(rates)(最大最优原则)。- 结果输出:grid.py输出两个文件:
- dataset.png: the CV accuracy contour plot generated by gnuplot,测试heart_scale,输出heart_scale.png图像在 tools目录下,该图像显示了数据集名称以及最优(c,g)和best_rate。
- dataset.out: the CV accuracy at each (log2(C),log2(gamma)),输出每一个(c,g)组以及交叉验证结果。
7.代码结构及c-SVC过程
最近看LIBSVM,代码结构不是很明白,上网查到了很多关于代码结构注解的资料,在这里将 我认为比较好的一些资料进行汇总一下,当然,在文章最后有这些资料的链接地址。
libsvm中主要使用到的类(svm.cpp)
在做分类过程中,我们先看文件svm.cpp,该文件中包含了类的继承和组合(实线表示继承关系,虚线表示组合关系)
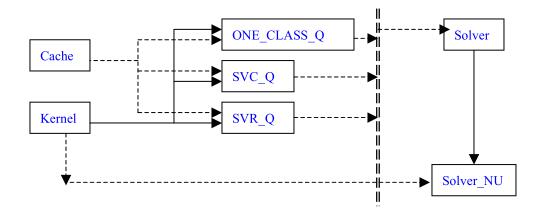
class Cache:本类主要负责运算所涉及的内存的管理,包括申请、释放等。
class Kernel:本类主要包括核函数的定义、克隆,矩阵Q(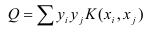
class Solver:An SMO algorithm in Fan et al., JMLR 6(2005), p. 1889–1918,是二次规划问题,使用算法SMO。
class Solver_NU:该类继承Solver类,Solver for nu-svm classification and regression。
class SVC_Q:继承Kernel类,Q matrices for various formulations。
class ONE_CLASS_Q:继承Kernel类,只处理 1 类分类问题(?),故不保留 y[i]。编号只有 1 类。
class SVR_Q:继承Kernel类,本类主要是用于做回归。
svm-train过程(这里只解释分类过程)
svm-train函数原型为:
svm_model *svm_train(const svm_problem *prob, const svm_parameter *param)根据选择的算法,来组织参加训练的分样本,以及进行训练结果的保存。其中会对样本进行初步的统计。如下为训练过程:
→统计类别总数,同时记录类别的标号,统计每个类的样本数目
→将属于相同类的样本分组,连续存放, svm_group_classes
→计算权重C
→训练n(n-1)/2个模型
→初始化nozero数组,便于统计SV
→//初始化概率数组
→训练过程中,需要重建子数据集,样本的特征不变,但样本的类别要改为 +1/-1
→//如果有必要,先调用svm_binary_svc_probability
→训练子数据集svm_train_one
→统计一下nozero,如果nozero已经是真,就不变,如果为假,则改为真
→输出模型
→主要是填充svm_model,
→清除内存svm-predict预测过程
svm-predict函数使用说明:
"Usage: svm-predict [-b 0/1] test_file model_file output_file\n"
"-b probability_estimates: whether to predict probability estimates, 0 or 1 (default 0); for one-class SVM only 0 is supported\n");预测过程如下:
→参数获取,读取预测数据
→模型加载svm_load_model
→预测并输出predict-label
→if (predict_probability && (svm_type==C_SVC || svm_type==NU_SVC)) 调用svm_predict_probability函数
→else 调用svm_predict函数
→清除内存svm_free_and_destroy_modelc-svc计算过程


参考资料及简介
- http://download.csdn.net/detail/xiahouzuoxin/5778927
林智仁SVM讲义(英文),SVM理论基础看这个就够了 - http://www.csie.ntu.edu.tw/~cjlin/papers/libsvm.pdf
该文档是台湾林智仁提供的LIBSVM使用说明文档。 - http://download.csdn.net/detail/lpcarl/8235115
这是上海交大模式分析与机器智能实验室对LIBSVM的注解,非常全面。上面的一部分资料也是摘自该文章。 - http://blog.csdn.net/zy_zhengyang/article/details/45009431
给出了C-SVC的计算过程,以图解的方式快速直观的看懂c-svc训练过程。 - http://www.cppblog.com/guijie/archive/2012/03/26/169034.html
这是一个中文版的理解型的FAQ,有很多你疑惑的问题可以从这里找到。
8.libsvm参数解释
最近学习libsvm库,将一些个人认为可以mark的东西做了记录,虽然README文档很清晰,但是在这篇文章中列出了dual problemd和核函数的公式,这样在选择参数时更加清楚。刚开始学习LIBSVM库时直接一脸懵,现在也还是在不断摸索中,如若有理解错误,请指出哦,谢谢!
Libsvm 使用步骤:
1. 按照libsvm要求的数据格式,将要训练和预测的数据准备好;http://blog.csdn.net/u014772862/article/details/51828981
2. 使用svm-scale实现数据缩放,可有可没有,需要按照特征的相关性进行操作;
3. 考虑svm-train时是否使用核函数以及核函数的选择,建议首先考虑RBF核函数;
4. 采用grid.py选择最优参数c和g;http://blog.csdn.net/u014772862/article/details/51829727
5. 设置svm-train参数,对整个数据集训练获取svm模型;
6. 利用svm-predict加载训练好的模型进行测试与预测。
1. svmscale 的用法
对数据集缩放的目的在于:
1)避免原始数据中部分特征范围过大而另一部分特征范围过小;
2)避免在训练时选择核函数计算内积时引起数值计算的困难;
3)加快训练速度,提高准确率。
因此,将数据缩放到[-1,1]或者[0,1]之间。
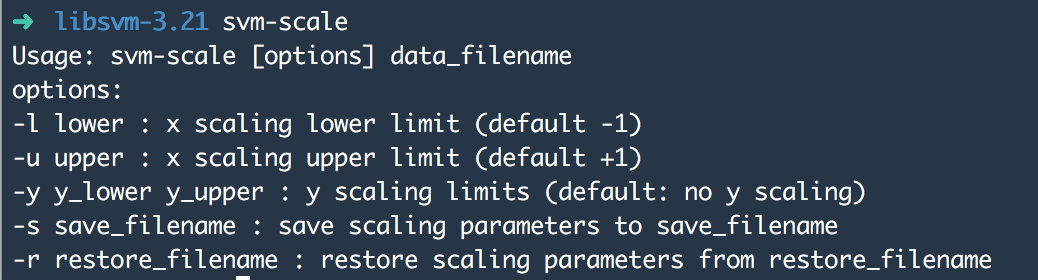
用法:svm-scale [options] data_filename”
其中,options选择如下:
-l lower,数据下限标记,设置lower值表示缩放后数据下限,默认为-1;
-u upper,数据上限标记,设置upper值表示缩放后数据上限,默认为1;
-y y_lower y_upper,是否对目标值同时进行缩放,y_lower 表示下限值, y_upper表示上限值;
-s save_filename,将缩放的规则保存为文件save_filename;
-r restore_filename,表示将缩放规则文件restore_filename载入后按此缩放;
filename,待缩放的数据文件。
缩放规则文件可以使用notepad++或者其他文本操作软件打开,格式为:
lower upper
index1 lval1 uval1
index 2 lval2 uval2
……………….
其中,lower和upper是数据的上下限,与参数设置中的lower和upper含义相同,index表示测试数据集的特征维数,lval 为该index维特征对应转换后下限lower 的特征值,uval 为该index维特征对应转换后上限upper 的特征值。输入命令./svm-scale -s heart_scale.range heart_scale>heart_scale.scale测试svm-scale,下面是缩放heart_scale数据输出的缩放规则文件heart_scale.range.
x
-1 1
1 -1 1
2 -1 1
3 -1 1使用示例:
1) svmscale –s train.range train>train.scale
表示采用缺省值(将特征缩放到[-1,1]之间,对y目标值不进行缩放)对数据集train进行缩放,其结果保存在文件train.scale中,缩放规则保存在文件train.range中。
2) svmscale –r train.range test>test.scale
表示载入缩放规则文件train.range,按照文件中的上下限对应的特征值和上下限值线性的对数据test进行缩放操作,并将其结果保存在文件train.scale中。
2. svm-train的用法
用法: svm-train [options] training_set_file [model_file]
其中,
-s svm训练,默认0, 其中前三种用来做分类问题,后两种用来实现回归问题。
0 c-SVC,
1 nu-SVC, 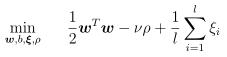
2 one-class SVM,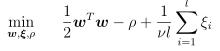
3 epsilon-SVR,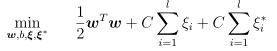
4. v-SVR,
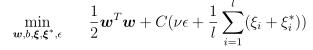
-t 核函数类型
0 线性核函数,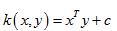
1 多项式核函数,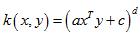
2 RBF核函数,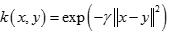
3 sigmoid核函数,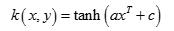
4 自定义核函数
-v n, n-fold交叉验证。
-d degree,设置多项式核函数的参数d,默认为3。
-g gamma,设置多项式、RBF 、sigmoid核函数的参数,在多项式和sigmoid中gamma表示为a,在RBF中表示为r,默认为1/num_features。
-r 设置多项式和sigmoid核函数中的常数项c,默认为0。
-c cost,设置c-svc,epsilon-SVR,nu-SVR类型的惩罚系数C,默认为1。
-n nu,设置nu-SVC,one-class SVM,nu-SVR类型的参数v,默认为0.5。
-p epsilon,设置epsilon-SVR的loss function参数,默认为0.1。
-m cachesize ,设置cache大小,默认为100MB。
-e epsilon,设置终止条件,默认为0.001。
-h shrinking,是否运用shrinking启发式,默认为1。
-b probability_estimates,是否使用概率估计模型,默认0。
-wi weight,将i类的参数C设置为weight*C,默认为1。
-v n, n-fold交叉验证。
使用示例:
svmtrain train3.scale train3.model
训练 train3.scale, 将模型保存于文件 train3.model, 并在 dos 窗口中输出如下结果:
optimization finished, #iter = 1756
nu = 0.464223
obj = -551.002342, rho = -0.337784
nSV = 604, nBSV = 557
Total nSV = 604其中,#iter 为迭代次数,nu 与前面的操作参数-n ν 相同,obj 为 SVM 文件转换为的二次规划求解得到的最小值,rho 为判决函数的常数项 b ,nSV 为支持向量个数,nBSV 为边界上的支持向量个数,Total nSV 为支持向量总个数。
模型文件介绍:
svm_type c_svc % 训练所采用的svm类型,此处为C SVC −
kernel_type rbf % 训练采用的核函数类型,此处为RBF核
gamma 0.047619 % 与操作参数设置中的 γ 含义相同
nr_class 2 % 分类时的类别数,此处为两分类问题
total_sv 604 % 总共的支持向量个数
rho -0.337784 % 决策函数中的常数项 b
label 0 1 % 类别标签
nr_sv 314 290 % 各类别标签对应的支持向量个数
SV % 以下为支持向量
1 1:-0.963808 2:0.906788 ... 19:-0.197706 20:-0.928853 21:-1
1 1:-0.885128 2:0.768219 ... 19:-0.452573 20:-0.980591 21:-1
... ... ...
1 1:-0.847359 2:0.485921 ... 19:-0.541457 20:-0.989077 21:-1 3. svm-predict的用法
用法:svm-predict [options] test_file model_file output_file
其中
-b probability_estimates,是否需要进行概率估计预测,可选值为 0 或者 1,默认值为 0。
est_file 是要进行预测的数据文件;
model_file 是由 svmtrain 产生的模型文件;
output_file 是 svmpredict 的输出文件,表示预测的结果值。
svmpredict 没有其它的选项。
训练数据
假设训练数据集文件路径为:G:\train.txt
预测数据集文件路径为:G:\predict.txt
则使用svm方法为:
//第一步,加载文件数据到序列或元组,让svm接口能够使用
//其中label是类别,value是特征值
train_label, train_value = svm_read_problem("G:\\train.txt") #训练数据集
predict_label, predict_value = svm_read_problem("G:\\predict.txt") #预测数
据集
//训练模型
model = svm_train(train_label,train_value)
//用模型预测数据类别
//结构返回为,预测类别集合,准确率,
p_label, p_acc, p_val = svm_predict(predict_label, predict_value, model)
print(p_acc) #打印预测结果
某完整代码如下:
from libsvm.python.svm import *
from libsvm.python.svmutil import *
train_label,train_pixel = svm_read_problem('G:\\data\\good-image-data')
predict_label,predict_pixel = svm_read_problem('G:\\data\\predict-image-data')
model = svm_train(train_label, train_pixel)
print("result:")
p_label, p_acc, p_val = svm_predict(predict_label, predict_pixel, model);
print(p_acc)
更详细的使用libsvm接口的办法请查看libsvm中的readme文件。
MAC上libsvm的使用详解
网上大部分文章都是在windows下如何使用的教程,自己摸索加上各种谷歌,终于搞定。参数选择工具prid.py在mac下的使用尤其折腾。
libsvm的使用
libsvm的基本使用(不使用grid.py的情况下)
- 可选择使用命令行直接编译或者链接在python/matlab(本人常用这两个)平台上。由于matlab使用最新版,貌似是有点问题的,就使用了python平台和命令行。
- python平台下的使用等稍后再专门写一篇博文,先讲较为简单的命令行编译。
(1)第一步:转换格式,网上找到excel的一个宏文件,可以一键从正常格式转换为libsvm的格式,也可以再转换回去。在我的资源下载可以下载到,链接为http://download.csdn.net/my/downloads
或http://download.csdn.net/my/uploads。(2)第二步:数据归一化,使用svm-scale。在终端进入libsvm的文件夹后,使用自带的测试数据heart_scale,输入如下,讲归一化之后的文件保存为heart_scale.scaled:
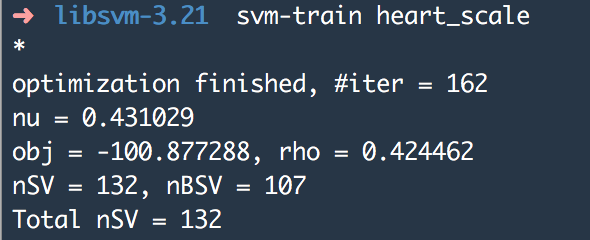
使用参数设置可输入svm-scale后参考:(3)训练样本,生成model,使用svn-train训练(使用最简单的默认参数)
默认生成的model名称为heart_scale.model。
查看详细的参数调整,输入svm-train即可。(4)测试数据,使用svm-predict,分类的结果输出到result中(1/-1的二分类,结果为1或-1)
- 可看到预测正确率为86.7%。


libsvm的使用grid.py调整参数
下载gnuplot
可使用homebrew下载,homebrew的使用和安装网上有很多说明。
其安装路径为/usr/local/Cellar,但是会同时自动在/usr/local/bin安装。修改grid.py的默认路径,指向gnuplot
安装python
mac是有自带的python的,这一步可以略过。讲训练数据拷贝到tools文件夹下,使用python grid.py [data]选择参数,成功后如下图:
最下面的一行前两个数即为选出来的c和g。
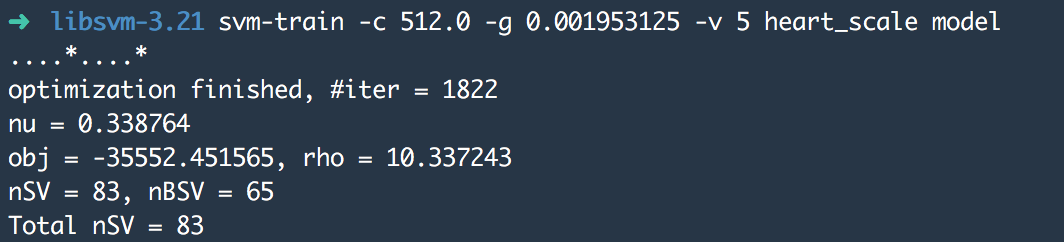
同时会生成heart_scale.png和heart_scale.out,显示参数选择过程:使用选出来的参数训练新的model
退回到上一层文件夹,使用添加了参数的svm-train训练。-v 5为交叉验证,分成5份。自定义生成的模型名为model。使用model进行test,利用svm-predict





SVM 核函数的选择
1、经常使用的核函数
核函数的定义并不困难,根据泛函的有关理论,只要一种函数K(xi,xj)满足Mercer条件,它就对应某一变换空间的内积.对于判断哪些函数是核函数到目前为止也取得了重要的突破,得到Mercer定理和以下常用的核函数类型:
(1)线性核函数
K(x,xi)=x⋅xi
(2)多项式核
K(x,xi)=((x⋅xi)+1)d
(3)径向基核(RBF)
K(x,xi)=exp(−∥x−xi∥2σ2)
Gauss径向基函数则是局部性强的核函数,其外推能力随着参数σ的增大而减弱。多项式形式的核函数具有良好的全局性质。局部性较差。
(4)傅里叶核
K(x,xi)=1−q22(1−2qcos(x−xi)+q2)
(5)样条核
K(x,xi)=B2n+1(x−xi)
(6)Sigmoid核函数
K(x,xi)=tanh(κ(x,xi)−δ)
采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。
2、核函数的选择
在选取核函数解决实际问题时,通常采用的方法有:一是利用专家的先验知识预先选定核函数;二是采用Cross-Validation方法,即在进行核函数选取时,分别试用不同的核函数,归纳误差最小的核函数就是最好的核函数.如针对傅立叶核、RBF核,结合信号处理问题中的函数回归问题,通过仿真实验,对比分析了在相同数据条件下,采用傅立叶核的SVM要比采用RBF核
的SVM误差小很多.三是采用由Smits等人提出的混合核函数方法,该方法较之前两者是目前选取核函数的主流方法,也是关于如何构造核函数的又一开创性的工作.将不同的核函数结合起来后会有更好的特性,这是混合核函数方法的基本思想.
libsvm的安装,数据格式,常见错误,grid.py参数选择,c-SVC过程,libsvm参数解释,svm训练数据,libsvm的使用详解,SVM核函数的选择的更多相关文章
- CentOS6.5下如何正确下载、安装Intellij IDEA、Scala、Scala-intellij-bin插件、Scala IDE for Eclipse助推大数据开发(图文详解)
不多说,直接上干货! 第一步:卸载CentOS中自带openjdk Centos 6.5下的OPENJDK卸载和SUN的JDK安装.环境变量配置 第二步:安装Intellij IDEA 若是3节点 ...
- PHP编译安装时常见错误解决办法,php编译常见错误
PHP编译安装时常见错误解决办法,php编译常见错误 1.configure: error: xslt-config not found. Please reinstall the libxslt & ...
- Elasticsearch学习之ElasticSearch 5.0.0 安装部署常见错误或问题
ElasticSearch 5.0.0 安装部署常见错误或问题 问题一: [--06T16::,][WARN ][o.e.b.JNANatives ] unable to install syscal ...
- python的多版本安装以及常见错误(长期更新)
(此文长期更新)Python安装常见错误汇总 注:本教程以python3.6为基准 既然是总结安装过程中遇到的错误,就顺便记录一下我的安装过程好了. 先来列举一下安装python3.6过程中可能需要的 ...
- win下安装Redmine常见错误解决方案
成长型公司,最近需要项目管理的软件,所以在windows的服务器上搭建了redmine,其中也遇到了两个坑,现记录下来. Redmine是用Ruby开发的基于web的项目管理软件,是用ROR框架开发的 ...
- Ubuntu下postgresql安装及常见错误处理
依赖工具库 注意: 默认用户名是postgres 以下命令是Ubuntu操作系统中的命令 make GCC Zlib 安装命令:sudo apt-get install zlib1g-dev 注意有些 ...
- ELK(Elasticsearch/Logstash/Kibana)安装时常见错误总结
问题一: [2016-11-06T16:27:21,712][WARN ][o.e.b.JNANatives ] unable to install syscall filter: Java.lang ...
- Lnmp 源码编译安装、常见错误整理
简介: Lnmp 环境的搭建还是非常简单的,之前由于博客迁移等原因,导致丢失了好多博文,这次重新整理记录一下. Lnmp 即:Linux .Nginx .Mysql .PHP Lnmp 是一套 Web ...
- 【转】ubuntu源码编译安装php常见错误解决办法
./configure -prefix=/usr/local/php -with-config-file-path=/etc -with-mysql=mysqlnd -with-mysqli=mysq ...
随机推荐
- 运行Jmeter时,响应数据中文乱码问题解决办法
需要修改jmeter中的配置,在Jmeter安装目录/bin/jmeter.properties文件中进行修改: sampleresult.default.encoding默认为ISO-8859-1, ...
- Linux C/C++开发
首先就是要熟练在vim里面写代码,其实就是没有提示和自动补全了,这个问题并不大. 我服务器gcc版本是4.8.5,所以就按照这个来了 https://gcc.gnu.org/onlinedocs/gc ...
- vue的table组件
一个vue-table的组件 说明: 1.基于element-ui开发的vue表格组件. 功能: 1.支持树形数据的展示 2.行拖拽排序 3.单元格拖拽排序 github 使用方法: 1.下载npm包 ...
- vue-cli3.0 资源加载的优化方案
20180829 更新 今天反复试了,不用区分 测试环境还是 生产环境,统一都用 cdn 就可以了 背景 之前自己搭建了一个 vue + tp5.1 的后台项目(https://segmentfaul ...
- 电影的微信小程序
最近,工作没有那么忙,学习了一下小程序开发,感觉上手比较简单. 在项目中学习是最好的方式,于是就自己模仿豆瓣电影开发一款微信小程序版的豆瓣电影 准备工作: 数据来源:豆瓣电影API 功能: 电影榜单列 ...
- 如何建一个Liferay 7的theme
首先附上原文链接Creating theme and Deploying in liferay 7 by using Eclipse 1.第一步:建一个Liferay module 项目,选择them ...
- 微服务开源生态报告 No.6
「微服务开源生态报告」,汇集各个开源项目近期的社区动态,帮助开发者们更高效的了解到各开源项目的最新进展. 社区动态包括,但不限于:版本发布.人员动态.项目动态和规划.培训和活动. 非常欢迎国内其他微服 ...
- jq处理JSON数据, jq Manual (development version)
jq 允许你直接在命令行下对 JSON 进行操作,包括分片.过滤.转换等等.让我们通过几个例子来说明 jq 的功能:一.输出格式化,漂亮的打印效果如果我们用文本编辑器打开 JSON,有时候可能看起来会 ...
- hdu3917 最大权闭合图
题意:有N个城市,M个公司.现在需要建立交通是获得的利益最大.如果2个公司A,B, A修的路为Xa->Ya,B的路为Xb->Yb,如果Ya==Xb,那么这2个公司有关系. 对于每个公司都有 ...
- Java程序中如何使用事物
在java操作数据库是,为了保证数据的一致性,比如转账操作,从一个账户减掉10元,在另一个账户加上10元. 在类中定义的成员属性(变量)不用赋初值,但在函数里头定义的变量就一定要赋初值. packag ...