Leetcode——863.二叉树中所有距离为 K 的结点
给定一个二叉树(具有根结点 root), 一个目标结点 target ,和一个整数值 K 。
返回到目标结点 target 距离为 K 的所有结点的值的列表。 答案可以以任何顺序返回。
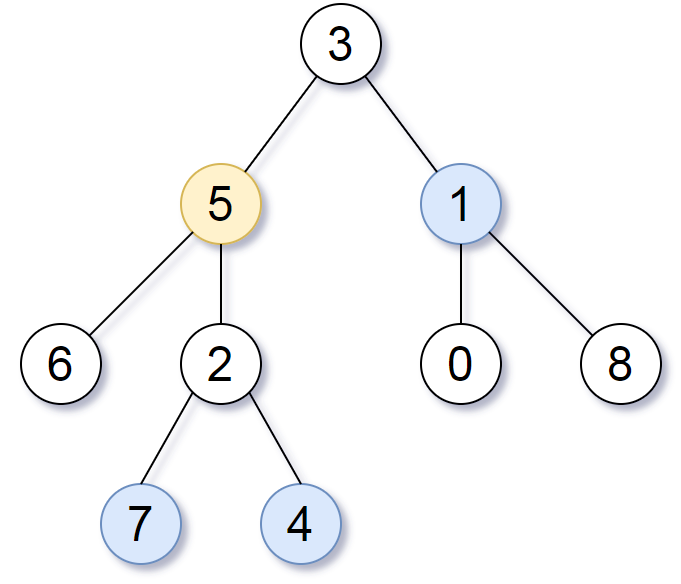
示例 1:
输入:root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2
输出:[7,4,1]
解释:
所求结点为与目标结点(值为 5)距离为 2 的结点,
值分别为 7,4,以及 1
注意,输入的 "root" 和 "target" 实际上是树上的结点。
上面的输入仅仅是对这些对象进行了序列化描述。
提示:
给定的树是非空的,且最多有 K 个结点。
树上的每个结点都具有唯一的值 0 <= node.val <= 500 。
目标结点 target 是树上的结点。
0 <= K <= 1000.
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/all-nodes-distance-k-in-binary-tree
一
这道题给了我们一棵二叉树,一个目标结点 target,还有一个整数K,让返回所有跟目标结点 target 相距K的结点。我们知道在子树中寻找距离为K的结点很容易,因为只需要一层一层的向下遍历即可,难点就在于符合题意的结点有可能是祖先结点,或者是在旁边的兄弟子树中,这就比较麻烦了,因为二叉树只有从父结点到子结点的路径,反过来就不行。既然没有,我们就手动创建这样的反向连接即可,这样树的遍历问题就转为了图的遍历(其实树也是一种特殊的图)。建立反向连接就是用一个 HashMap 来来建立每个结点和其父结点之间的映射,使用先序遍历建立好所有的反向连接,然后再开始查找和目标结点距离K的所有结点,这里需要一个 HashSet 来记录所有已经访问过了的结点。
在递归函数中,首先判断当前结点是否已经访问过,是的话直接返回,否则就加入到 visited 中。再判断此时K是否为0,是的话说明当前结点已经是距离目标结点为K的点了,将其加入结果 res 中,然后直接返回。否则分别对当前结点的左右子结点调用递归函数,注意此时带入 K-1,这两步是对子树进行查找。之前说了,还得对父结点,以及兄弟子树进行查找,这是就体现出建立的反向连接 HashMap 的作用了,若当前结点的父结点存在,我们也要对其父结点调用递归函数,并同样带入 K-1,这样就能正确的找到所有满足题意的点了,参见代码如下:
解法一:
class Solution {
public:
vector<int> distanceK(TreeNode* root, TreeNode* target, int K) {
if (!root) return {};
vector<int> res;
unordered_map<TreeNode*, TreeNode*> parent;
unordered_set<TreeNode*> visited;
findParent(root, parent);
helper(target, K, parent, visited, res);
return res;
}
void findParent(TreeNode* node, unordered_map<TreeNode*, TreeNode*>& parent) {
if (!node) return;
if (node->left) parent[node->left] = node;
if (node->right) parent[node->right] = node;
findParent(node->left, parent);
findParent(node->right, parent);
}
void helper(TreeNode* node, int K, unordered_map<TreeNode*, TreeNode*>& parent, unordered_set<TreeNode*>& visited, vector<int>& res) {
if (visited.count(node)) return;
visited.insert(node);
if (K == 0) {res.push_back(node->val); return;}
if (node->left) helper(node->left, K - 1, parent, visited, res);
if (node->right) helper(node->right, K - 1, parent, visited, res);
if (parent[node]) helper(parent[node], K - 1, parent, visited, res);
}
};
既然是图的遍历,那就也可以使用 BFS 来做,为了方便起见,我们直接建立一个邻接链表,即每个结点最多有三个跟其相连的结点,左右子结点和父结点,使用一个 HashMap 来建立每个结点和其相邻的结点数组之间的映射,这样就几乎完全将其当作图来对待了,建立好邻接链表之后,原来的树的结构都不需要用了。既然是 BFS 进行层序遍历,就要使用队列 queue,还要一个 HashSet 来记录访问过的结点。在 while 循环中,若K为0了,说明当前这层的结点都是符合题意的,就把当前队列中所有的结点加入结果 res,并返回即可。否则就进行层序遍历,取出当前层的每个结点,并在邻接链表中找到和其相邻的结点,若没有访问过,就加入 visited 和 queue 中即可。记得每层遍历完成之后,K要自减1,参见代码如下:
解法二:
class Solution {
public:
vector<int> distanceK(TreeNode* root, TreeNode* target, int K) {
if (!root) return {};
vector<int> res;
unordered_map<TreeNode*, vector<TreeNode*>> m;
queue<TreeNode*> q{{target}};
unordered_set<TreeNode*> visited{{target}};
findParent(root, NULL, m);
while (!q.empty()) {
if (K == 0) {
for (int i = q.size(); i > 0; --i) {
res.push_back(q.front()->val); q.pop();
}
return res;
}
for (int i = q.size(); i > 0; --i) {
TreeNode *t = q.front(); q.pop();
for (TreeNode *node : m[t]) {
if (visited.count(node)) continue;
visited.insert(node);
q.push(node);
}
}
--K;
}
return res;
}
void findParent(TreeNode* node, TreeNode* pre, unordered_map<TreeNode*, vector<TreeNode*>>& m) {
if (!node) return;
if (m.count(node)) return;
if (pre) {
m[node].push_back(pre);
m[pre].push_back(node);
}
findParent(node->left, node, m);
findParent(node->right, node, m);
}
};
其实这道题也可以不用 HashMap,不建立邻接链表,直接在递归中完成所有的需求,真正体现了递归的博大精深。在进行递归之前,我们要先判断一个 corner case,那就是当 K==0 时,此时要返回的就是目标结点值本身,可以直接返回。否则就要进行递归了。这里的递归函数跟之前的有所不同,是需要返回值的,这个返回值表示的含义比较复杂,若为0,表示当前结点为空或者当前结点就是距离目标结点为K的点,此时返回值为0,是为了进行剪枝,使得不用对其左右子结点再次进行递归。当目标结点正好是当前结点的时候,递归函数返回值为1,其他的返回值为当前结点离目标结点的距离加1。还需要一个参数 dist,其含义为离目标结点的距离,注意和递归的返回值区别,这里不用加1,且其为0时候不是为了剪枝,而是真不知道离目标结点的距离。
在递归函数中,首先判断若当前结点为空,则直接返回0。然后判断 dist 是否为k,是的话,说目标结点距离当前结点的距离为K,是符合题意的,需要加入结果 res 中,并返回0,注意这里返回0是为了剪枝。否则判断,若当前结点正好就是目标结点,或者已经遍历过了目标结点(表现为 dist 大于0),那么对左右子树分别调用递归函数,并将返回值分别存入 left 和 right 两个变量中。注意此时应带入 dist+1,因为是先序遍历,若目标结点之前被遍历到了,那么说明目标结点肯定不在当前结点的子树中,当前要往子树遍历的话,肯定离目标结点又远了一些,需要加1。若当前结点不是目标结点,也还没见到目标结点时,同样也需要对左右子结点调用递归函数,但此时 dist 不加1,因为不确定目标结点的位置。若 left 或者 right 值等于K,则说明目标结点在子树中,且距离当前结点为K(为啥呢?因为目标结点本身是返回1,所以当左右子结点返回K时,和当前结点距离是K)。接下来判断,若当前结点是目标结点,直接返回1,这个前面解释过了。然后再看 left 和 right 的值是否大于0,若 left 值大于0,说明目标结点在左子树中,我们此时就要对右子结点再调用一次递归,并且 dist 带入 left+1,同理,若 right 值大于0,说明目标结点在右子树中,我们此时就要对左子结点再调用一次递归,并且 dist 带入 right+1。这两步很重要,是之所以能不建立邻接链表的关键所在。若 left 大于0,则返回 left+1,若 right 大于0,则返回 right+1,否则就返回0,参见代码如下:
解法三:
class Solution {
public:
vector<int> distanceK(TreeNode* root, TreeNode* target, int K) {
if (K == 0) return {target->val};
vector<int> res;
helper(root, target, K, 0, res);
return res;
}
int helper(TreeNode* node, TreeNode* target, int k, int dist, vector<int>& res) {
if (!node) return 0;
if (dist == k) {res.push_back(node->val); return 0;}
int left = 0, right = 0;
if (node->val == target->val || dist > 0) {
left = helper(node->left, target, k, dist + 1, res);
right = helper(node->right, target, k, dist + 1, res);
} else {
left = helper(node->left, target, k, dist, res);
right = helper(node->right, target, k, dist, res);
}
if (left == k || right == k) {res.push_back(node->val); return 0;}
if (node->val == target->val) return 1;
if (left > 0) helper(node->right, target, k, left + 1, res);
if (right > 0) helper(node->left, target, k, right + 1, res);
if (left > 0 || right > 0) return left > 0 ? left + 1 : right + 1;
return 0;
}
};
二
方法一: 深度优先搜索
思路
如果节点有指向父节点的引用,也就知道了距离该节点 1 距离的所有节点。之后就可以从 target 节点开始进行深度优先搜索了。
算法
对所有节点添加一个指向父节点的引用,之后做深度优先搜索,找到所有距离 target 节点 K 距离的节点。
class Solution {
Map<TreeNode, TreeNode> parent;
public List<Integer> distanceK(TreeNode root, TreeNode target, int K) {
parent = new HashMap();
dfs(root, null);
Queue<TreeNode> queue = new LinkedList();
queue.add(null);
queue.add(target);
Set<TreeNode> seen = new HashSet();
seen.add(target);
seen.add(null);
int dist = 0;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node == null) {
if (dist == K) {
List<Integer> ans = new ArrayList();
for (TreeNode n: queue)
ans.add(n.val);
return ans;
}
queue.offer(null);
dist++;
} else {
if (!seen.contains(node.left)) {
seen.add(node.left);
queue.offer(node.left);
}
if (!seen.contains(node.right)) {
seen.add(node.right);
queue.offer(node.right);
}
TreeNode par = parent.get(node);
if (!seen.contains(par)) {
seen.add(par);
queue.offer(par);
}
}
}
return new ArrayList<Integer>();
}
public void dfs(TreeNode node, TreeNode par) {
if (node != null) {
parent.put(node, par);
dfs(node.left, node);
dfs(node.right, node);
}
}
}
Python
class Solution(object):
def distanceK(self, root, target, K):
def dfs(node, par = None):
if node:
node.par = par
dfs(node.left, node)
dfs(node.right, node)
dfs(root)
queue = collections.deque([(target, 0)])
seen = {target}
while queue:
if queue[0][1] == K:
return [node.val for node, d in queue]
node, d = queue.popleft()
for nei in (node.left, node.right, node.par):
if nei and nei not in seen:
seen.add(nei)
queue.append((nei, d+1))
return []
复杂度分析
时间复杂度: O(N),其中 NN 是树中节点个数。
空间复杂度: O(N)。
方法二: 计算节点之间距离
思路
如果 target 节点在 root 节点的左子树中,且 target 节点深度为 3,那所有 root 节点右子树中深度为 K - 3 的节点到 target 的距离就都是 K。
算法
深度优先遍历所有节点。定义方法 dfs(node),这个函数会返回 node 到 target 的距离。在 dfs(node) 中处理下面四种情况:
如果 node == target,把子树中距离 target 节点距离为 K 的所有节点加入答案。
如果 target 在 node 左子树中,假设 target 距离 node 的距离为 L+1,找出右子树中距离 target 节点 K - L - 1 距离的所有节点加入答案。
如果 target 在 node 右子树中,跟在左子树中一样的处理方法。
如果 target 不在节点的子树中,不用处理。
实现的算法中,还会用到一个辅助方法 subtree_add(node, dist),这个方法会将子树中距离节点 node K - dist 距离的节点加入答案。
Java
class Solution {
List<Integer> ans;
TreeNode target;
int K;
public List<Integer> distanceK(TreeNode root, TreeNode target, int K) {
ans = new LinkedList();
this.target = target;
this.K = K;
dfs(root);
return ans;
}
// Return vertex distance from node to target if exists, else -1
// Vertex distance: the number of vertices on the path from node to target
public int dfs(TreeNode node) {
if (node == null)
return -1;
else if (node == target) {
subtree_add(node, 0);
return 1;
} else {
int L = dfs(node.left), R = dfs(node.right);
if (L != -1) {
if (L == K) ans.add(node.val);
subtree_add(node.right, L + 1);
return L + 1;
} else if (R != -1) {
if (R == K) ans.add(node.val);
subtree_add(node.left, R + 1);
return R + 1;
} else {
return -1;
}
}
}
// Add all nodes 'K - dist' from the node to answer.
public void subtree_add(TreeNode node, int dist) {
if (node == null) return;
if (dist == K)
ans.add(node.val);
else {
subtree_add(node.left, dist + 1);
subtree_add(node.right, dist + 1);
}
}
}
Python
class Solution(object):
def distanceK(self, root, target, K):
ans = []
# Return distance from node to target if exists, else -1
# Vertex distance: the # of vertices on the path from node to target
def dfs(node):
if not node:
return -1
elif node is target:
subtree_add(node, 0)
return 1
else:
L, R = dfs(node.left), dfs(node.right)
if L != -1:
if L == K: ans.append(node.val)
subtree_add(node.right, L + 1)
return L + 1
elif R != -1:
if R == K: ans.append(node.val)
subtree_add(node.left, R + 1)
return R + 1
else:
return -1
# Add all nodes 'K - dist' from the node to answer.
def subtree_add(node, dist):
if not node:
return
elif dist == K:
ans.append(node.val)
else:
subtree_add(node.left, dist + 1)
subtree_add(node.right, dist + 1)
dfs(root)
return ans
复杂度分析
时间复杂度: O(N),其中 N 树的大小。
空间复杂度: O(N)。
Leetcode——863.二叉树中所有距离为 K 的结点的更多相关文章
- Leetcode 863. 二叉树中所有距离为 K 的结点
863. 二叉树中所有距离为 K 的结点 显示英文描述 我的提交返回竞赛 用户通过次数39 用户尝试次数59 通过次数39 提交次数174 题目难度Medium 给定一个二叉树(具有根结点 ro ...
- 【前缀思想】二叉树中所有距离为 K 的结点
863. 二叉树中所有距离为 K 的结点 class Solution { Map<TreeNode,String>map=new HashMap<>(); String pa ...
- [Swift]LeetCode863. 二叉树中所有距离为 K 的结点 | All Nodes Distance K in Binary Tree
We are given a binary tree (with root node root), a targetnode, and an integer value K. Return a lis ...
- 链表中获取倒数第K个结点
/* * 链表中查找倒数第K个结点.cpp * * Created on: 2018年5月1日 * Author: soyo */ #include<iostream> using nam ...
- 链表习题(8)-寻找单链表中数据域大小为k的结点,并与前一结点交换,如果前一结点存在的情况下
/*寻找单链表中数据域大小为k的结点,并与前一结点交换,如果前一结点存在的情况下*/ /* 算法思想:定义两个指针,pre指向前驱结点,p指向当前结点,当p->data == k的时候,交换 p ...
- LeetCode 230.二叉树中第k小的元素
题目: 给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素. 说明:你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数. 这道题在leetCode上难 ...
- LeetCode 671. 二叉树中第二小的节点(Second Minimum Node In a Binary Tree) 9
671. 二叉树中第二小的节点 671. Second Minimum Node In a Binary Tree 题目描述 给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 ...
- Leetcode Lect4 二叉树中的分治法与遍历法
在这一章节的学习中,我们将要学习一个数据结构——二叉树(Binary Tree),和基于二叉树上的搜索算法. 在二叉树的搜索中,我们主要使用了分治法(Divide Conquer)来解决大部分的问题. ...
- Leetcode 671.二叉树中第二小的节点
二叉树中第二小的节点 给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0.如果一个节点有两个子节点的话,那么这个节点的值不大于它的子节点的值. 给出这样的一个二叉树 ...
随机推荐
- hihocoder:#1082 : 然而沼跃鱼早就看穿了一切(用string)
题目是这样的: 描述 fjxmlhx每天都在被沼跃鱼刷屏,因此他急切的找到了你希望你写一个程序屏蔽所有句子中的沼跃鱼("marshtomp",不区分大小写).为了使句子不缺少成分, ...
- 【数据库】MyQSL数据完整性
不知道怎么取标题,简单提一下数据库的完整性实现问题 在MySQL中一种不用写trigger也可以实现级联的方式——直接使用外键实现参照完整性(当然trigger的功能不只是实现级联修改/删除,还可以实 ...
- 深入浅出Python装饰器
1.前言 装饰器是Python的特有的语法,刚接触装饰器的同学可能会觉得装饰器很难理解,装饰器的功能也可以不用装饰器实现,但是装饰器无疑是提高你Python代码质量的利器(尤其是使用在一些具有重复功能 ...
- 51nod 1393:0和1相等串
1393 0和1相等串 基准时间限制:1 秒 空间限制:131072 KB 分值: 20 难度:3级算法题 收藏 关注 给定一个0-1串,请找到一个尽可能长的子串,其中包含的0与1的个数相等. I ...
- c++ 模板联系4
//定义类成员函数特化类型 #include "stdafx.h" #include <iostream> using namespace std; typedef f ...
- python3+Opencv 搭建环境和基本操作
一.必备前提: Python3.5及以上版本.pip.windows环境 二.搭建opencv 该部分可以创建隔绝的Python环境来引入,参照virtualenv的使用 在目标的cmd窗口,依次输入 ...
- VMWare WorkStation15--Win10下开机启动虚拟机
参考 https://www.cnblogs.com/qmfsun/p/6284236.html http://www.cnblogs.com/eliteboy/p/7838091.html VMWa ...
- 使用Map,统计字符串中每个字符出现的次数
package seday13; import java.util.HashMap; import java.util.Map; /** * @author xingsir * 统计字符串中每个字符出 ...
- php魔术常量,_CLASS_,_METHOD_,_FUNCTION_
_CLASS_: 返回当前类的类名 _METHOD_:返回当前类方法的方法名(并显示类的调用,类名::方法名) _FUNCTION_:返回当前函数的函数名 _FILE_:当前文件的绝对路径(包含_FI ...
- winform操作windows系统计算器
winform对系统计算器的调用,启动,最大化最小化显示,在mainwindow设置topmost=true时,正常显示计算器并置顶. /// <summary> /// 获取窗体的句柄函 ...