吴裕雄--天生自然python编程:正则表达式
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明: 参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
匹配成功re.match方法返回一个匹配的对象,否则返回None。 我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 描述
group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。
groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
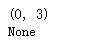
import re line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
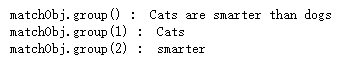
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。 函数语法:
re.search(pattern, string, flags=0)
函数参数说明: 参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
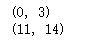
import re line = "Cats are smarter than dogs"; searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")

re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!") matchObj = re.search( r'dogs', line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")

检索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。 语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数: pattern : 正则中的模式字符串。
repl : 替换的字符串,也可为一个函数。
string : 要被查找替换的原始字符串。
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags : 编译时用的匹配模式,数字形式。
import re phone = "2004-959-559 # 这是一个电话号码" # 删除注释
num = re.sub(r'#.*$', "", phone)
print ("电话号码 : ", num) # 移除非数字的内容
num = re.sub(r'\D', "", phone)
print ("电话号码 : ", num)
import re # 将匹配的数字乘于 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2) s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
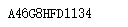
compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。 语法格式为: re.compile(pattern[, flags])
参数: pattern : 一个字符串形式的正则表达式
flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为' . '并且包括换行符在内的任意字符(' . '不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和' # '后面的注释
import re pattern = re.compile(r'\d+') # 用于匹配至少一个数字
m = pattern.match('one12twothree34four') # 查找头部,没有匹配
print(m)
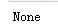
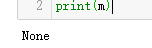
m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
print(m)
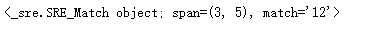
a=m.group(0) # 可省略 0
print(a)
b=m.start(0) # 可省略 0
print(b)
c=m.end(0) # 可省略 0
print(c)
d=m.span(0) # 可省略 0
print(d)

在上面,当匹配成功时返回一个 Match 对象,其中: group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
span([group]) 方法返回 (start(group), end(group))。
import re pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
m = pattern.match('Hello World Wide Web')
print(m)
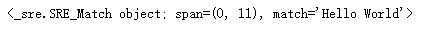
a=m.group(0) # 返回匹配成功的整个子串
print(a)
b=m.span(0) # 返回匹配成功的整个子串的索引
print(b)
c=m.group(1) # 返回第一个分组匹配成功的子串
print(c)
d=m.span(1) # 返回第一个分组匹配成功的子串的索引
print(d)
e=m.group(2) # 返回第二个分组匹配成功的子串
print(e)
f=m.span(2) # 返回第二个分组匹配成功的子串索引
print(f)
g=m.groups() # 等价于 (m.group(1), m.group(2), ...)
print(g)

findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。 注意: match 和 search 是匹配一次 findall 匹配所有。 语法格式为: re.findall(string[, pos[, endpos]])
参数: string 待匹配的字符串。
pos 可选参数,指定字符串的起始位置,默认为 0。
endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
import re pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10) print(result1)
print(result2)

re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。 re.finditer(pattern, string, flags=0)
参数: 参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )

re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下: re.split(pattern, string[, maxsplit=0, flags=0])
参数: 参数 描述
pattern 匹配的正则表达式
string 要匹配的字符串。
maxsplit 分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
import re
a=re.split('\W+', 'runoob, runoob, runoob.')
print(a)
b=re.split('(\W+)', ' runoob, runoob, runoob.')
print(b)
c=re.split('\W+', ' runoob, runoob, runoob.', 1)
print(c)
d=re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
print(d)

正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。 re.MatchObject
group() 返回被 RE 匹配的字符串。 start() 返回匹配开始的位置
end() 返回匹配结束的位置
span() 返回一个元组包含匹配 (开始,结束) 的位置
正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
修饰符 描述
re.I 使匹配对大小写不敏感
re.L 做本地化识别(locale-aware)匹配
re.M 多行匹配,影响 ^ 和 $
re.S 使 . 匹配包括换行在内的所有字符
re.U 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B.
re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式: 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。 多数字母和数字前加一个反斜杠时会拥有不同的含义。 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。 反斜杠本身需要使用反斜杠转义。 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。 下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。 模式 描述
^ 匹配字符串的开头
$ 匹配字符串的末尾。
. 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
[...] 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k'
[^...] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
re* 匹配0个或多个的表达式。
re+ 匹配1个或多个的表达式。
re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
re{ n} 匹配n个前面表达式。例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。
re{ n,} 精确匹配n个前面表达式。例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。"o{1,}"等价于"o+"。"o{0,}"则等价于"o*"。
re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
a| b 匹配a或b
(re) 匹配括号内的表达式,也表示一个组
(?imx) 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。
(?-imx) 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。
(?: re) 类似 (...), 但是不表示一个组
(?imx: re) 在括号中使用i, m, 或 x 可选标志
(?-imx: re) 在括号中不使用i, m, 或 x 可选标志
(?#...) 注释.
(?= re) 前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。
(?! re) 前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功。
(?> re) 匹配的独立模式,省去回溯。
\w 匹配数字字母下划线
\W 匹配非数字字母下划线
\s 匹配任意空白字符,等价于 [\t\n\r\f]。
\S 匹配任意非空字符
\d 匹配任意数字,等价于 [0-9]。
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。
\z 匹配字符串结束
\G 匹配最后匹配完成的位置。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
\n, \t, 等。 匹配一个换行符。匹配一个制表符, 等
\1...\9 匹配第n个分组的内容。
\10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式。
正则表达式实例
字符匹配
实例 描述
python 匹配 "python".
字符类
实例 描述
[Pp]ython 匹配 "Python" 或 "python"
rub[ye] 匹配 "ruby" 或 "rube"
[aeiou] 匹配中括号内的任意一个字母
[0-9] 匹配任何数字。类似于 [0123456789]
[a-z] 匹配任何小写字母
[A-Z] 匹配任何大写字母
[a-zA-Z0-9] 匹配任何字母及数字
[^aeiou] 除了aeiou字母以外的所有字符
[^0-9] 匹配除了数字外的字符
特殊字符类
实例 描述
. 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。
\d 匹配一个数字字符。等价于 [0-9]。
\D 匹配一个非数字字符。等价于 [^0-9]。
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
\W 匹配任何非单词字符。等价于 '[^A-Za-z0-9_]'。
吴裕雄--天生自然python编程:正则表达式的更多相关文章
- 吴裕雄--天生自然python编程:实例(2)
list1 = [10, 20, 4, 45, 99] list1.sort() print("最小元素为:", *list1[:1]) list1 = [10, 20, 1, 4 ...
- 吴裕雄--天生自然python编程:实例(1)
str = "www.runoob.com" print(str.upper()) # 把所有字符中的小写字母转换成大写字母 print(str.lower()) # 把所有字符中 ...
- 吴裕雄--天生自然python编程:实例
# 该实例输出 Hello World! print('Hello World!') # 用户输入数字 num1 = input('输入第一个数字:') num2 = input('输入第二个数字:' ...
- 吴裕雄--天生自然python编程:turtle模块绘图(3)
turtle(海龟)是Python重要的标准库之一,它能够进行基本的图形绘制.turtle图形绘制的概念诞生于1969年,成功应用于LOGO编程语言. turtle库绘制图形有一个基本框架:一个小海龟 ...
- 吴裕雄--天生自然python编程:turtle模块绘图(1)
Turtle库是Python语言中一个很流行的绘制图像的函数库,想象一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始,它根据一组函数指令的控制,在这个平面坐标系中移动,从而在它爬行 ...
- 吴裕雄--天生自然python编程:pycharm常用快捷键问题
最近在使用pycharm的时候发现不能正常使用ctrl+c/v进行复制粘贴,也无法使用tab键对大段代码进行整体缩进.后来发现是因为安装了vim插件的问题,在setting里找到vim插件,取消勾选即 ...
- 吴裕雄--天生自然python编程:实例(3)
# 返回 x 在 arr 中的索引,如果不存在返回 -1 def binarySearch (arr, l, r, x): # 基本判断 if r >= l: mid = int(l + (r ...
- 吴裕雄--天生自然python编程:turtle模块绘图(4)
import turtle bob = turtle.Turtle() for i in range(1,5): bob.fd(100) bob.lt(90) turtle.mainloop() im ...
- 吴裕雄--天生自然python编程:turtle模块绘图(2)
#彩色螺旋线 import turtle import time turtle.pensize(2) turtle.bgcolor("black") colors = [" ...
随机推荐
- MyBatis学习——动态SQL
开发人员在使用JDBC框架或者其他类似的框架进行数据库开发时,通常都要根据需求去手动拼接SQL,这样非常麻烦,而myBatis提供了对SQL语句动态组装的功能,恰好解决了这一问题. 一,动态SQL中的 ...
- Juniper srx新增接口IP,使PC直连srx(转)
转自:https://www.jianshu.com/p/bc27134bde3d Juniper srx新增接口IP,使PC直连srx 2018.11.19 14:24:15字数 424 概述 需求 ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- cJSON api的使用教程
背景说明:由于和后台通信,为了统一数据格式,选择使用json格式,客户端开发语言使用的是c,故需要借助第三方库来实现json格式的转化,cJSON是一个很好的第三方库, 下载链接1:https://g ...
- Django_JavaScript
JavaScript是什么 JavaScript是一种运行在客户端(浏览器)的编程语言,用来给网页添加动态功能. JavaScript的作用 最初目的 为了处理表单的验证操作 现在广泛的应用场景 网页 ...
- vue-resource CRUD示例
GET请求 var demo = new Vue({ el: '#app', data: { gridColumns: ['customerId', 'companyName', 'contactNa ...
- python文件读写 文件修改
#设置一个变量f为文件对象,并打开文件#写文件#f = open('user.txt','w',encoding='utf-8') #f是一个文件对象f=open(r'c:\Users\PL\Desk ...
- WOW.js 和 animate.css 使用
animate.css 动画样式,用户也可以非常容易修改设置喜欢的动画库. Wow.js 允许用户滚动页面的时候展示 CSS 动画.配合animate.css ,做出很棒的效果,它支持 animate ...
- Unable to cast object of type 'System.String' to type 'System.Int32'.
原因 数据库中 code 字段 类型为 varchar 而实体的类型为 int 导致string 类型无法转化为int 类型而报错 public int code { get; set; } 参考: ...
- ZZJ_淘淘商城项目:day02(淘淘商城01 - 项目讲解、环境搭建)
在用Eclipse的开发中,可手动排除不必要的依赖坐标传递. <!-- JPA的1.0依赖 --> <dependency> <groupId>javax.pers ...