Social LSTM 实现代码分析
----- 2019.8.5更新 实现代码思维导图 -----

----- 初始原文 -----
Social LSTM最早提出于文献 “Social LSTM: Human Trajectory Prediction in Crowded Spaces”,但经过资料查阅目前暂未找到原文献作者所提供的程序代码和数据,而在github上有许多针对该文献的实现版本代码。
本文接下来的实现代码来自https://github.com/xuerenlv/social-lstm-tf,代码语言为Python3,代码大体实现了原论文中核心原创部分的模型,包括Vanilla LSTM(没有考虑行人轨迹之间关联性的LSTM)和Social LSTM(使用池化层考虑了行人轨迹之间关联性的LSTM模型)的模型构建、训练和小样本测试的代码,但对横向对比的其他模型、模型量化评估方法等暂未实现。
本文下面将从代码中矩阵数据和列表(list)数据的维度细说实现过程和模型的特点。
Vanilla LSTM 模型
训练数据
主要功能代码文件:util.py
数据格式:
input_data, target_data = dataLoader.next_batch()
# input_data : [batch_size, seq_length, 2]
# target_data : [batch_size, seq_length, 2]
批量处理数据大小 x 序列长度大小 x 二维地址数据(已经过标准化处理,介于\(0 - 1\))
数据解释:
- 模型在实际使用时,对于每个输入的位置数据(源于已知数据/上一步预测数据)
LSTM Cell将该运行后得到的输出就可用于下一时刻位置的预测,因此从dataLoader获得的input_data和target_data从数据维度上只在seq_length维度上有1个大小的错位,对于行人已知的\(t_0 - t_{obs}\)的轨迹,训练时参与损失函数计算的是网络预测的\(t_1 - t_{obs+1}\)轨迹。 - 同时,其在由于训练采用Minibatch,因此输入和目标数据的有大小为
batch_size的第一维度。
模型中间变量
LSTM序列网络是模型的核心部分,输入数据需要修改结构以满足数据要求,同时序列网络的输出结果也需要经过处理才能够使用,为此,模型主要有以下中间变量:
inputs, embedding_inputs
inputs是input_data的拆分版,将其拆解为序列模型每步运行时的输入数据。
embedding_inputs是将inputs使用embedding层后得到的输入数据,默认满足embedding_size = rnn_size = 128,因此数据可直接用于lstm的输入数据了。
# inputs : [N_0, N_1, N_2, ....], N_i = [batch_size, 2]
# embedding_inputs = [M_0, M_1, M_2, ....], M_i = [batch_size, embedding_size]
# embedding
embedding_w = tf.get_variables("embedding_w", [2, embedding_size])
embedding_b = tf.get_variables("embedding_b", [embedding_size])
for input in embedding_inputs:
x = tf.nn.relu(tf.nn.xw_plus_b(input, embedding_w, embedding_b))
embedding_inputs.append(x)
seq2seq.rnn_decoder
由于该源码相比tensorflow的版本更迭还是有一定的年代感,其在运行LSTM模型时使用了不常用的方法:
outputs, last_state = tf.contrib.legacy_seq2seq.rnn_decoder(embedded_inputs, self.initial_state, cell, loop_function=None, scope="rnnlm")
此LSTM模型严格来说并不是seq2seq模型,其只是借用了seq2seq中decoder相同的操作步骤用在这里(手动实现也不复杂),具体来说,就是在for循环迭代embedded_inputs列表中的元素,使LSTM的cell运行对应的次数,而后将序列模型的每步运行输出生成outputs列表,并返回最后一步运行的finial_state。
output_w, output_b
LSTM模型输出的原始outputs数据需经线性变换为合适结构才被进一步使用,在此是对于每个大小为rnn_size的输出向量,线性变为为大小为\(5\)的结果向量,有关使用目的请参见下一节。
output_size = 5 # 具体赋值目的请参见下文与原文献
# output : [batch_size * seq_length, rnn_size]
output = tf.reshape(tf.concat(outputs, 1), [-1, rnn_size])
output_w = tf.get_variable("output_w", [rnn_size, output_size])
output_b = tf.get_variable("output_b", [output_size])
# output : [batch_size * seq_length, 5]
output = tf.nn.xw_plus_b(output, output_w, output_b)
*output数据中最终含有\(batch\_size * seq\_length\)个预测的位置(每个位置由5个参数表述),相同的reshape策略可确保output中预测位置与target中实际位置的排列顺序是相同的。
模型输出
将序列模型每步输出结果合并、线性变换和变形后得到output,传入的target_data经过变形后得到flat_target_data:
# model.py
# output : [batch_size * seq_length, 5]
# flat_target_data : [batch_size * seq_length, 2]
output和flag_target_data就是最终用于(训练时)计算损失/(采样时,不依赖于target)计算下一时刻位置的数据。
两个变量的第一维度大小均为batch_size * seq_length(在reshape策略相同情况下,第二维度数据在数据批次和时间点上一一对应),而两个变量在第二维度数据量的差异是:原文献中假设了LSTM Cell输出的rnn_size大小(默认为128)的结果满足二维高斯分布(bivariate Gaussian distribution),因此使用线性变换矩阵后得到的恰是刻画二维高斯分布的5个参数$\mu_x, \mu_y, \sigma_x, \sigma_y, \rho $(有关如何基于二维高斯分布求出预测点和损失值请原文献的引用)。
Social LSTM模型
此部分暂时未完全整理出来,根据初步的代码阅读,Social LSTM与Vanilla LSTM整体的代码框架和模型构建方法是相似的,具体有下述几方面的差异:
batch_size和max pedestrian number,批量训练数据的差异:在Vanilla LSTM训练时,采用了Mini Batch的数据方式使每次模型迭代时具备一定的数量规模;而Social LSTM中由于池化层的加入使得同一时刻需要有MPN个LSTM序列迭代,而纵使存在多个LSTM序列,其实共享的是同一个Cell,因此同一场景的多位行人的轨迹(在代码中称作frame)其实就可以等价于一个batch,从而使训练Cell时有一定的数据规模。# input_data format in vanilla lstm
input_data = tf.placeholder(tf.float32, [None, seq_length, 2])
----
# input_data format in social lstm
input_data = tf.placeholder(tf.float32, [seq_length, maxNumPeds, 3])
social tensor池化层:social LSTM结构从本质上就是vanilla lstm添加了池化层,在源代码的
grid.py包含主要的social tensor的支持方法。social tensor在原文中用\(H_i^t\)表示,每个行人\(i\)在不同时间点\(t\)中都有不同的social tensor。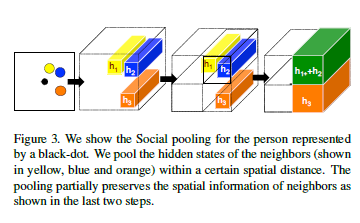
对于每个张量中的值,实际是由上一时刻其他行人的
Hidden State加和得到,Hidden State只有LSTM Cell真正跑起来才能得到,因此最终的social tensor是在模型运算中所得到的(这也是为什么运算量较大的原因以至原文献中又提出了一种能够在运算前得到张量的O-LSTM模型),不过在模型运行前,Hidden State的加和方式就可以通过输入数据推算得出,grid.py做得主要就是这部分工作,其生成了数据为01真值的Grid Mask矩阵,在模型迭代时作为参数传入,从而简化生成social tensor的过程。
Social LSTM 实现代码分析的更多相关文章
- tensorflow笔记:多层LSTM代码分析
tensorflow笔记:多层LSTM代码分析 标签(空格分隔): tensorflow笔记 tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) ten ...
- 开源项目kcws代码分析--基于深度学习的分词技术
http://blog.csdn.net/pirage/article/details/53424544 分词原理 本小节内容参考待字闺中的两篇博文: 97.5%准确率的深度学习中文分词(字嵌入+Bi ...
- vmware漏洞之三——Vmware虚拟机逃逸漏洞(CVE-2017-4901)Exploit代码分析与利用
本文简单分析了代码的结构.有助于理解. 转:http://www.freebuf.com/news/141442.html 0×01 事件分析 2017年7月19 unamer在其github上发布了 ...
- tensorflow笔记:多层CNN代码分析
tensorflow笔记系列: (一) tensorflow笔记:流程,概念和简单代码注释 (二) tensorflow笔记:多层CNN代码分析 (三) tensorflow笔记:多层LSTM代码分析 ...
- Android代码分析工具lint学习
1 lint简介 1.1 概述 lint是随Android SDK自带的一个静态代码分析工具.它用来对Android工程的源文件进行检查,找出在正确性.安全.性能.可使用性.可访问性及国际化等方面可能 ...
- pmd静态代码分析
在正式进入测试之前,进行一定的静态代码分析及code review对代码质量及系统提高是有帮助的,以上为数据证明 Pmd 它是一个基于静态规则集的Java源码分析器,它可以识别出潜在的如下问题:– 可 ...
- [Asp.net 5] DependencyInjection项目代码分析-目录
微软DI文章系列如下所示: [Asp.net 5] DependencyInjection项目代码分析 [Asp.net 5] DependencyInjection项目代码分析2-Autofac [ ...
- [Asp.net 5] DependencyInjection项目代码分析4-微软的实现(5)(IEnumerable<>补充)
Asp.net 5的依赖注入注入系列可以参考链接: [Asp.net 5] DependencyInjection项目代码分析-目录 我们在之前讲微软的实现时,对于OpenIEnumerableSer ...
- 完整全面的Java资源库(包括构建、操作、代码分析、编译器、数据库、社区等等)
构建 这里搜集了用来构建应用程序的工具. Apache Maven:Maven使用声明进行构建并进行依赖管理,偏向于使用约定而不是配置进行构建.Maven优于Apache Ant.后者采用了一种过程化 ...
随机推荐
- Java基础学习总结(二)
Java语言的特点: Java语言是简单的 Java语言是面向对象的 Java语言是跨平台(操作系统)的(即一次编写,到处运行) Java是高性能的 运行Java程序要安装和配置JDK jdk是什么? ...
- GDI4
前几篇我已经向大家介绍了如何使用GDI+来绘图,并做了一个截图的实例,这篇我向大家介绍下如何来做一个类似windows画图的工具.个人认为如果想做一个功能强大的绘图工具,那么单纯掌握GDI还远远不够, ...
- (四)Flex 布局教程和例子
布局的传统解决方案,基于盒状模型,依赖 display 属性 + position属性 + float属性.它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现. 1.flex-direction ...
- HDU - 6198 number number number(规律+矩阵快速幂)
题意:已知F0 = 0,F1 = 1,Fn = Fn - 1 + Fn - 2(n >= 2), 且若n=Fa1+Fa2+...+Fak where 0≤a1≤a2≤⋯≤a,n为正数,则n为mj ...
- 英语语法 - the + 形容词 的意义
1,表示一类人 (复数) the young 青年 the old 老年the poor 穷人 the rich 富人the sick 病人 The old need care more than ...
- 指令——df
df是disk free 的简称,这个指令的功能和作用是查看磁盘空间. 可以加上 -h 的选项,来提高可读性. [he@localhost ~]$ df -h文件系统(磁盘名称) 总容量 ...
- Go——标准库使用代理
本文知识点 Go的安装 Go使用代理 Go进阶学习 环境配置 Go的安装 确认环境都安装好了,看看go的版本. go version 代码样例 使用代理,发送GET请求 package main im ...
- Java扫雷游戏: JMine
JMine是用Java和Swing编写的扫雷程序.作者是Jerry Shen(火鸟),代码有一定年头了,最开始是作者的课程设计.阅读这种小程序对编程语言的学习挺有帮助.本文只简单介绍一些关键的地方,实 ...
- 二、JavaScript之点击按钮改变HTML样式 (CSS)
一.代码如下 二.点击前 三.点击后 <!DOCTYPE html> <html> <meta http-equiv="Content-Type" c ...
- 实验吧-杂项-flag.xls(notepad++查找)、保险箱(linux文件分解、密码破解)
flag.xls 下载文件,用notepad++打开,查找flag就能找到flag. 保险箱(linux文件分解.密码破解) 将图片保存下来,用kali的binwalk分析,发现有rar文件,然后用f ...