图解Python的垃圾回收机制
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题。通过“分代回收”(generation collection)以空间换取时间来进一步提高垃圾回收的效率。
引用计数机制:
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
}PyObject;
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
引用计数为0时,该对象生命就结束了。
引用计数机制的优点:
1、简单
2、实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点:
1、维护引用计数消耗资源
2、循环引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。
对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。
上面说到python里回收机制是以引用计数为主,标记-清除和分代收集两种机制为辅。
1、标记-清除机制
标记-清除机制,顾名思义,首先标记对象(垃圾检测),然后清除垃圾(垃圾回收)。如图:
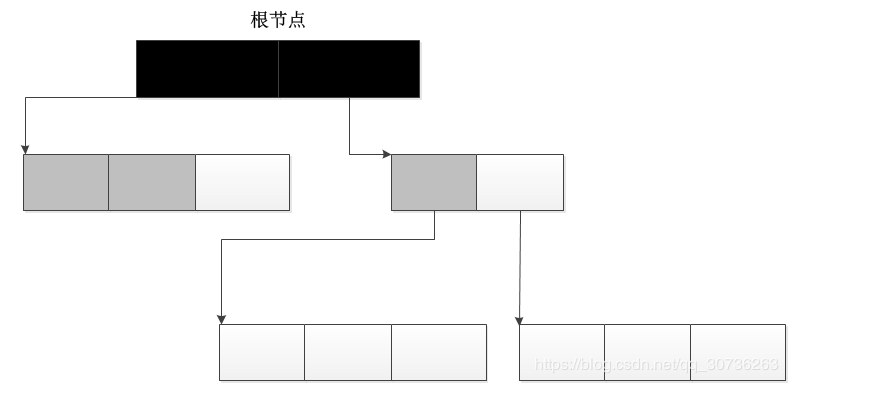
首先初始所有对象标记为白色,并确定根节点对象(这些对象是不会被删除),标记它们为黑色(表示对象有效)。将有效对象引用的对象标记为灰色(表示对象可达,但它们所引用的对象还没检查),检查完灰色对象引用的对象后,将灰色标记为黑色。重复直到不存在灰色节点为止。最后白色结点都是需要清除的对象。
2、回收对象的组织
这里所采用的高级机制作为引用计数的辅助机制,用于解决产生的循环引用问题。而循环引用只会出现在“内部存在可以对其他对象引用的对象”,比如:list,class等。
为了要将这些回收对象组织起来,需要建立一个链表。自然,每个被收集的对象内就需要多提供一些信息,下面代码是回收对象里必然出现的。
/* GC information is stored BEFORE the object structure. */
typedef union _gc_head {
struct {
union _gc_head *gc_next;
union _gc_head *gc_prev;
Py_ssize_t gc_refs;
} gc;
long double dummy; /* force worst-case alignment */
} PyGC_Head;
一个对象的实际结构如图所示:

过PyGC_Head的指针将每个回收对象连接起来,形成了一个链表,也就是在1里提到的初始化的所有对象。
3、分代技术
分代技术是一种典型的以空间换时间的技术,这也正是java里的关键技术。这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。
这样的思想,可以减少标记-清除机制所带来的额外操作。分代就是将回收对象分成数个代,每个代就是一个链表(集合),代进行标记-清除的时间与代内对象
存活时间成正比例关系
/*** Global GC state ***/
struct gc_generation {
PyGC_Head head;
int threshold; /* collection threshold */
int count; /* count of allocations or collections of younger
generations */
};//每个代的结构
#define NUM_GENERATIONS 3//代的个数
#define GEN_HEAD(n) (&generations[n].head)
/* linked lists of container objects */
static struct gc_generation generations[NUM_GENERATIONS] = {
/* PyGC_Head, threshold, count */
{{{GEN_HEAD(0), GEN_HEAD(0), 0}}, 700, 0},
{{{GEN_HEAD(1), GEN_HEAD(1), 0}}, 10, 0},
{{{GEN_HEAD(2), GEN_HEAD(2), 0}}, 10, 0},
};
PyGC_Head *_PyGC_generation0 = GEN_HEAD(0);
从上面代码可以看出python里一共有三代,每个代的threshold值表示该代最多容纳对象的个数。默认情况下,当0代超过700,或1,2代超过10,垃圾回收机制将触发。
0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。
这篇算是一个完整的收集流程:链表建立,确定根节点,垃圾标记,垃圾回收~
1、链表建立
首先,中里在分代技术说过:0代触发将清理所有三代,1代触发会清理1,2代,2代触发后只会清理自己。在清理0代时,会将三个链表(代)链接起来,清理1代的时,会链接1,2两代。在后面三步,都是针对的这个建立之后的链表。
2、确定根节点
图1为一个例子。list1与list2循环引用,list3与list4循环引用。a是一个外部引用。
对于这样一个链表,我们如何得出根节点呢。python里是在引用计数的基础上又提出一个有效引用计数的概念。顾名思义,有效引用计数就是去除循环引用后的计数。
下面是计算有效引用计数的相关代码:
/* Set all gc_refs = ob_refcnt. After this, gc_refs is > 0 for all objects
* in containers, and is GC_REACHABLE for all tracked gc objects not in
* containers.
*/
static void
update_refs(PyGC_Head *containers)
{
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc = gc->gc.gc_next) {
assert(gc->gc.gc_refs == GC_REACHABLE);
gc->gc.gc_refs = Py_REFCNT(FROM_GC(gc));
assert(gc->gc.gc_refs != 0);
}
} /* A traversal callback for subtract_refs. */
static int
visit_decref(PyObject *op, void *data)
{
assert(op != NULL);
if (PyObject_IS_GC(op)) {
PyGC_Head *gc = AS_GC(op);
/* We're only interested in gc_refs for objects in the
* generation being collected, which can be recognized
* because only they have positive gc_refs.
*/
assert(gc->gc.gc_refs != 0); /* else refcount was too small */
if (gc->gc.gc_refs > 0)
gc->gc.gc_refs--;
}
return 0;
} /* Subtract internal references from gc_refs. After this, gc_refs is >= 0
* for all objects in containers, and is GC_REACHABLE for all tracked gc
* objects not in containers. The ones with gc_refs > 0 are directly
* reachable from outside containers, and so can't be collected.
*/
static void
subtract_refs(PyGC_Head *containers)
{
traverseproc traverse;
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc=gc->gc.gc_next) {
traverse = Py_TYPE(FROM_GC(gc))->tp_traverse;
(void) traverse(FROM_GC(gc),
(visitproc)visit_decref,
NULL);
}
}
update_refs函数里建立了一个引用的副本。
visit_decref函数对引用的副本减1,subtract_refs函数里traverse的作用是遍历对象里的每一个引用,执行visit_decref操作。
最后,链表内引用计数副本非0的对象,就是根节点了。
说明:
1、为什么要建立引用副本?
答:这个过程是寻找根节点的过程,在这个时候修改计数不合适。subtract_refs会对对象的引用对象执行visit_decref操作。如果链表内对象引用了链表外对象,那么链表外对象计数会减1,显然,很有可能这个对象会被回收,而回收机制里根本不应该对非回收对象处理。
2、traverse的疑问(未解决)?
答:一开始,有个疑问。上面例子里,subtract_refs函数中处理完list1结果应该如下: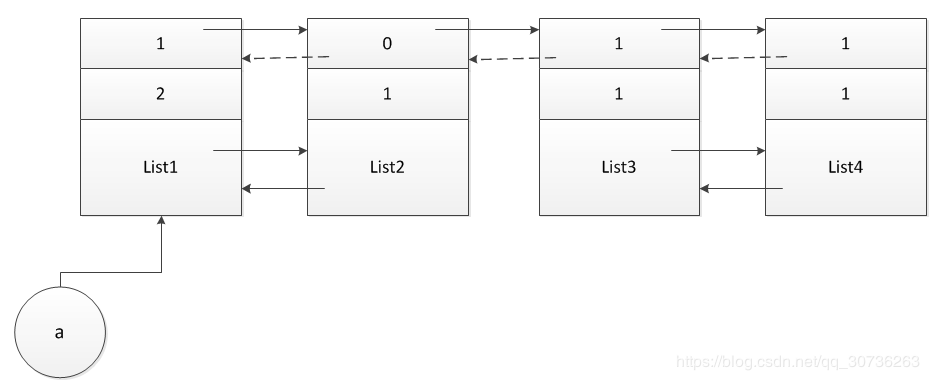
然后gc指向list2,此时list2的副本(为0)不会减少,但是list2对list1还是存在实际上的引用,那么list1副本会减1吗?显然,如果减1就出问题了。
所以list1为0时,traverse根本不会再去处理list1这些引用(或者说,list2对list1名义上不存在引用了)。
此时,又有一个问题,如果存在一个外部对象b,对list2引用,subtract_refs函数中处理完list1后,如下图: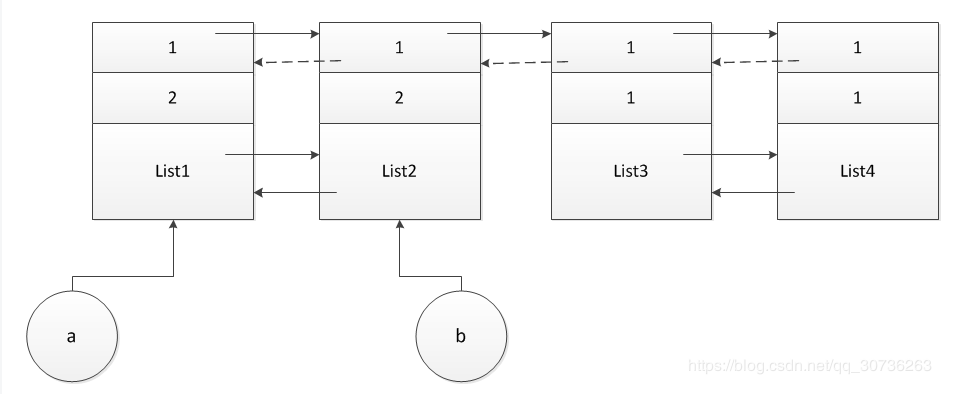
当subtract_refs函数中遍历到list2时,list2的副本还会减1吗?显然traverse的作用还是没有理解。
3、垃圾标记
接下来,python建立两条链表,一条存放根节点,以及根节点的引用对象。另外一条存放unreachable对象。
标记的方法就是中里的标记思路,代码如下:
/* A traversal callback for move_unreachable. */
static int
visit_reachable(PyObject *op, PyGC_Head *reachable)
{
if (PyObject_IS_GC(op)) {
PyGC_Head *gc = AS_GC(op);
const Py_ssize_t gc_refs = gc->gc.gc_refs; if (gc_refs == 0) {
/* This is in move_unreachable's 'young' list, but
* the traversal hasn't yet gotten to it. All
* we need to do is tell move_unreachable that it's
* reachable.
*/
gc->gc.gc_refs = 1;
}
else if (gc_refs == GC_TENTATIVELY_UNREACHABLE) {
/* This had gc_refs = 0 when move_unreachable got
* to it, but turns out it's reachable after all.
* Move it back to move_unreachable's 'young' list,
* and move_unreachable will eventually get to it
* again.
*/
gc_list_move(gc, reachable);
gc->gc.gc_refs = 1;
}
/* Else there's nothing to do.
* If gc_refs > 0, it must be in move_unreachable's 'young'
* list, and move_unreachable will eventually get to it.
* If gc_refs == GC_REACHABLE, it's either in some other
* generation so we don't care about it, or move_unreachable
* already dealt with it.
* If gc_refs == GC_UNTRACKED, it must be ignored.
*/
else {
assert(gc_refs > 0
|| gc_refs == GC_REACHABLE
|| gc_refs == GC_UNTRACKED);
}
}
return 0;
} /* Move the unreachable objects from young to unreachable. After this,
* all objects in young have gc_refs = GC_REACHABLE, and all objects in
* unreachable have gc_refs = GC_TENTATIVELY_UNREACHABLE. All tracked
* gc objects not in young or unreachable still have gc_refs = GC_REACHABLE.
* All objects in young after this are directly or indirectly reachable
* from outside the original young; and all objects in unreachable are
* not.
*/
static void
move_unreachable(PyGC_Head *young, PyGC_Head *unreachable)
{
PyGC_Head *gc = young->gc.gc_next; /* Invariants: all objects "to the left" of us in young have gc_refs
* = GC_REACHABLE, and are indeed reachable (directly or indirectly)
* from outside the young list as it was at entry. All other objects
* from the original young "to the left" of us are in unreachable now,
* and have gc_refs = GC_TENTATIVELY_UNREACHABLE. All objects to the
* left of us in 'young' now have been scanned, and no objects here
* or to the right have been scanned yet.
*/ while (gc != young) {
PyGC_Head *next; if (gc->gc.gc_refs) {
/* gc is definitely reachable from outside the
* original 'young'. Mark it as such, and traverse
* its pointers to find any other objects that may
* be directly reachable from it. Note that the
* call to tp_traverse may append objects to young,
* so we have to wait until it returns to determine
* the next object to visit.
*/
PyObject *op = FROM_GC(gc);
traverseproc traverse = Py_TYPE(op)->tp_traverse;
assert(gc->gc.gc_refs > 0);
gc->gc.gc_refs = GC_REACHABLE;
(void) traverse(op,
(visitproc)visit_reachable,
(void *)young);
next = gc->gc.gc_next;
}
else {
/* This *may* be unreachable. To make progress,
* assume it is. gc isn't directly reachable from
* any object we've already traversed, but may be
* reachable from an object we haven't gotten to yet.
* visit_reachable will eventually move gc back into
* young if that's so, and we'll see it again.
*/
next = gc->gc.gc_next;
gc_list_move(gc, unreachable);
gc->gc.gc_refs = GC_TENTATIVELY_UNREACHABLE;
}
gc = next;
}
}
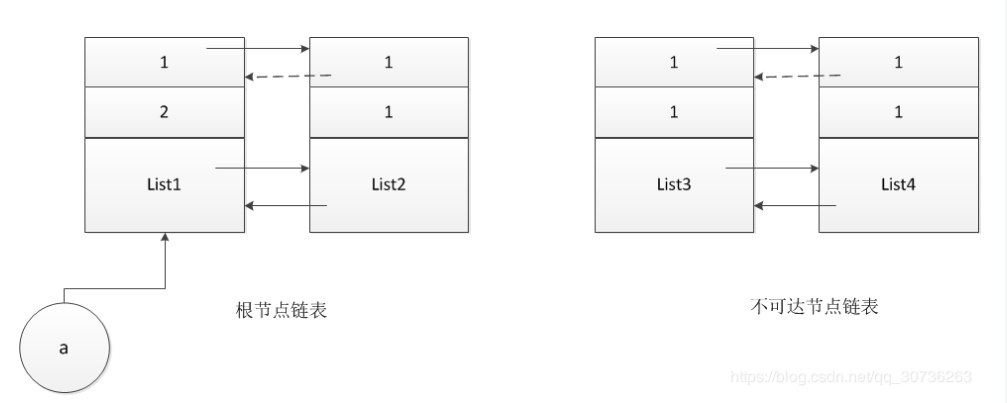
标记之后,链表如上图。
4、垃圾回收
回收的过程,就是销毁不可达链表内对象。下面代码就是list的清除方法:
/* Methods */ static void
list_dealloc(PyListObject *op)
{
Py_ssize_t i;
PyObject_GC_UnTrack(op);
Py_TRASHCAN_SAFE_BEGIN(op)
if (op->ob_item != NULL) {
/* Do it backwards, for Christian Tismer.
There's a simple test case where somehow this reduces
thrashing when a *very* large list is created and
immediately deleted. */
i = Py_SIZE(op);
while (--i >= 0) {
Py_XDECREF(op->ob_item[i]);
}
PyMem_FREE(op->ob_item);
}
if (numfree < PyList_MAXFREELIST && PyList_CheckExact(op))
free_list[numfree++] = op;
else
Py_TYPE(op)->tp_free((PyObject *)op);
Py_TRASHCAN_SAFE_END(op)
}
python学习路线图 https://www.bilibili.com/video/BV1V741117Zt/
python就业方向和职业前景https://www.bilibili.com/video/BV1ut4y1U7bM/
图解Python的垃圾回收机制的更多相关文章
- 详解python的垃圾回收机制
python的垃圾回收机制 一.引子 我们定义变量会申请内存空间来存放变量的值,而内存的容量是有限的,当一个变量值没有用了(简称垃圾)就应该将其占用的内存空间给回收掉,而变量名是访问到变量值的唯一方式 ...
- 谈一谈python的垃圾回收机制
[python的垃圾回收机制是怎么实现的] 在C语言时代程序员要负责内存的申请和释放,虽然这样的程序可以对资源进行精细的控制.但是它也有它的问题.这就要求程序员 要写许多与业务逻辑无关的内容在代码里面 ...
- python的垃圾回收机制和析构函数__del__
析构函数__del__定义:在类里定义,如果不定义,Python 会在后台提供默认析构函数. 析构函数__del__调用: A.使用del 显式的调用析构函数删除对象时:del对象名: class F ...
- python之垃圾回收机制
一.前言 Python 是一门高级语言,使用起来类似于自然语言,开发的时候自然十分方便快捷,原因是Python在背后为我们默默做了很多事情,其中一件就是垃圾回收,来解决内存管理,内存泄漏的问题. 内存 ...
- Python核心技术与实战——二十|Python的垃圾回收机制
今天要讲的是Python的垃圾回收机制 众所周知,我们现在的计算机都是图灵架构.图灵架构的本质,就是一条无限长的纸带,对应着我们的存储器.随着寄存器.异失性存储器(内存)和永久性存储器(硬盘)的出现, ...
- Python的 垃圾回收机制
垃圾回收 1. 小整数对象池 整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间. Python 对小整数的定义是 [-5, 257) 这些整 ...
- Python的垃圾回收机制
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾.在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的 ...
- 【Python】 垃圾回收机制和gc模块
垃圾回收机制和gc模块 Py的一个大好处,就是灵活的变量声明和动态变量类型.虽然这使得学习py起来非常方便快捷,但是同时也带来了py在性能上的一些不足.其中相关内存比较主要的一点就是py不会对已经销毁 ...
- Python的垃圾回收机制(引用计数+标记清除+分代回收)
一.写在前面: 我们都知道Python一种面向对象的脚本语言,对象是Python中非常重要的一个概念.在Python中数字是对象,字符串是对象,任何事物都是对象,而它们的核心就是一个结构体--PyOb ...
随机推荐
- 学习笔记-EL
仅作为学习过程中笔记作用,若有不正确的地方欢迎指正 目标 理解El的作用,熟练使用EL EL表达式与Jsp表达式对比来记 EL表达式的概念,作用,语法 Jsp作用主要是用来实现动态网页的,而动态网页中 ...
- 剖析手写Vue,你也可以手写一个MVVM框架
剖析手写Vue,你也可以手写一个MVVM框架# 邮箱:563995050@qq.com github: https://github.com/xiaoqiuxiong 作者:肖秋雄(eddy) 温馨提 ...
- 《Three.js 入门指南》3.0 - 代码构建的最基本结构。
3.0 代码构建的最基本结构 说明: 我们必需首先知道,Three.js 的一些入门级概念: 我们需要知道,OpenGL 是一套三维实现的标准,为什么说是标准,因为它是跨平台,跨语言的.甚至CAD以及 ...
- Vmware安装CentOs7.4
转载https://blog.csdn.net/qq_42545206/article/details/90301472
- 浅谈Java接口(Interface)
浅谈Java接口 先不谈接口,不妨设想一个问题? 如果你写了个Animal类,有许多类继承了他,包括Hippo(河马), Dog, Wolf, Cat, Tiger这几个类.你把这几个类拿给别人用,但 ...
- Centos下载新版内核
下载新版内核的安装文 ...
- python的字符串、列表、字典和函数
一.字符串 在python中字符串无需通过像php中的explode或者javascript中的split进行分解即可完成切片,可以直接通过下标获取字符串中的每一个字符,下标从0开始,如果从厚望签署, ...
- 从String 聊源码解读
@ 目录 源码实现 构造方法 equals 其他方法 常见面试题 你真的了解String吗?之前一篇博客写jvm时,就觉得String可以单独拎出来写一篇博客,毕竟几乎所有的面试都是以String开始 ...
- Linux学习,path,环境变量的配置
方法一: 1.查看当前环境变量配置的所与信息 echo $PATH 注意: echo是输出的意思 加$表示它是一个变量 2.配置环境命令 PATH="$PATH":comdir 注 ...
- 五个简单的shell脚本
1.编写shell脚本 ex1.sh,提示用户输入用户名,并判断此用户名是否存在. (提示:利用read.grep和/etc/passwd) #!/bin/bash echo "请输入用户名 ...