论文阅读:Reducing Transformer Depth On Demand With Structured Dropout
Introduction
这篇paper是做Transformer压缩的,但其实bert的核心也就是transformer,这篇paper的实验里也做了bert的压缩。作者的主要工作是提出了LayerDrop的方法,即一种结构化的dropout的方法来对transformer模型进行训练,从而在不需要fine-tune的情况下选择一个大网络的子网络。
这篇paper方法的核心是通过Dropout来去从大模型中采样子网络,但是这个dropout是对分组权重进行dropout的,具体而言,这篇paper是layerwise的dropout,可见下图:
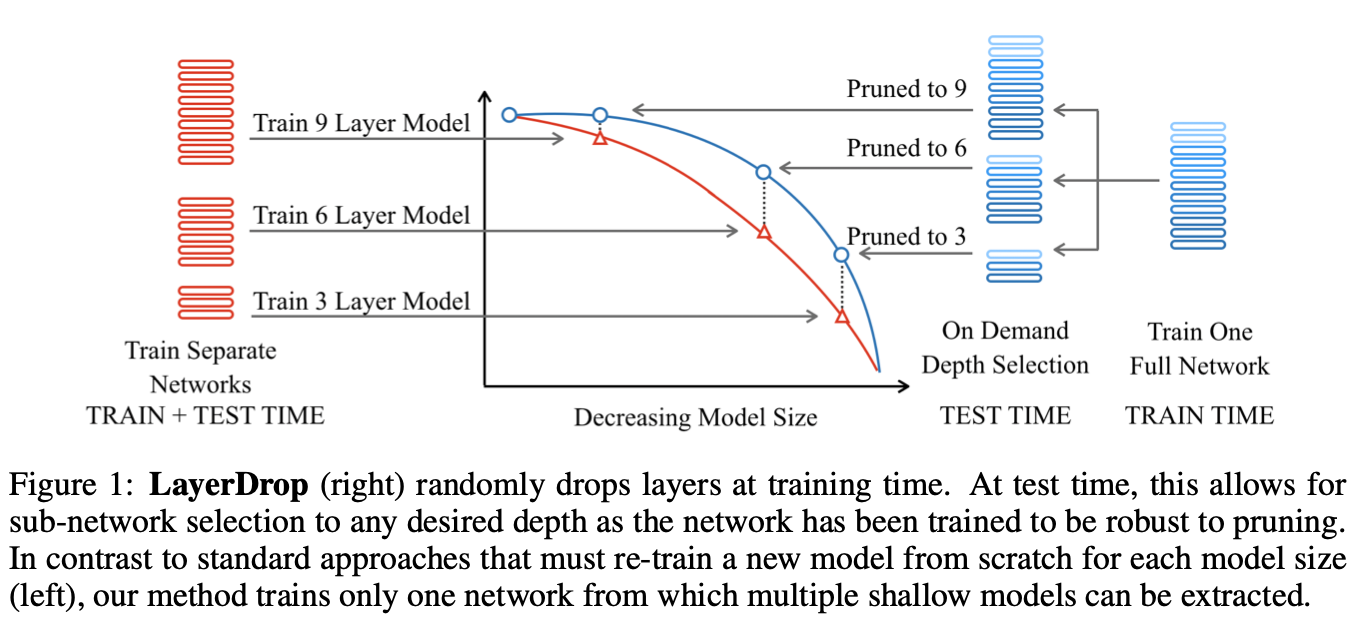
作者提出的方法是用LayerDrop的方法只训练一遍网络,然后在测试的时候可以根据不同的需求来选择不同的深度。
Method
Transformer Architecture
首先回顾一下transformer的结构,一个transformer由若干个层组成,每个层包含一个多头注意力模块和一个全连接的前向层,每个注意力头的输入是一个矩阵X,X的每一行输入句子的每一个元素,然后进行下面的运算:
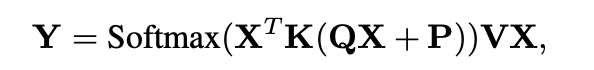
其中K、V、Q是三个参数矩阵,这一步输入的多个注意力头的结果会被拼接和变形为同样大小的X向量,然后经过一个全连接层:
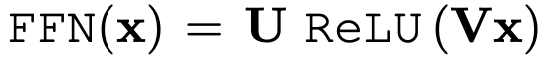
然后transformer中其实还是有一个类似于ResNet的残差模块,因为在整个transformer中的生成的向量维度都一样,所以可以方便的进行addnorm操作来避免梯度消失的问题,同时transformer还引入了layer normalization的操作,这个是对同一层中的所有输出做标准化,而BN是对一个batch中的所有样本输出做标准化。
whatever,前面只是一个对transformer的复习~
Training Transformers with Random Structured Pruning
作者提出了一个可以让transformer能够在测试过程中使用不同深度的正则项训练方法,主要关注点在于剪枝层数。那为什么作者选择减少层数呢?举例而言,如果减少attention head的数量,那么其实是不能起到加速作用的,因为attention模块的计算是并行的。
那么最重要的问题就是要剪哪些层呢?作者考虑了不同的剪枝策略:
Every Other
即每隔一层就以一定概率剪枝一层
Search on Valid
计算不同组合的layer在验证集上的表现,这种往往非常耗时
Data Driven Pruning
对每一个layer学习一个参数p,使得全局剪枝率为p*,然后对每个layer的输出添加这么一个非线性函数,在前向的时候只选择计算分数最高的k个layer。
Conclusion
这篇transformer压缩其实主要的工作在于很多的实验,因为还不太了解这块的各种数据集,所以就没有细看实验。这篇paper通过结构化的dropout来对网络进行训练,主要剪的是层数。
论文阅读:Reducing Transformer Depth On Demand With Structured Dropout的更多相关文章
- 论文阅读---Reducing the Dimensionality of Data with Neural Networks
通过训练多层神经网络可以将高维数据转换成低维数据,其中有对高维输入向量进行改造的网络层.梯度下降可以用来微调如自编码器网络的权重系数,但是对权重的初始化要求比较高.这里提出一种有效初始化权重的方法,允 ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读(Lukas Neumann——【ICCV2017】Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recognition Framework)
Lukas Neumann——[ICCV2017]Deep TextSpotter_An End-to-End Trainable Scene Text Localization and Recogn ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
随机推荐
- IDEA设置导入主题样式皮肤,加入背景图片
主题下载地址:http://www.riaway.com/theme.php 里面有很多主题,看个人喜好,这里我用的Monokai Sublime Text 3. 导入主题打开IDEA,找到File ...
- Spring Boot中的Properties
文章目录 简介 使用注解注册一个Properties文件 使用属性文件 Spring Boot中的属性文件 @ConfigurationProperties yaml文件 Properties环境变量 ...
- vue2.x学习笔记(三十)
接着前面的内容:https://www.cnblogs.com/yanggb/p/12682902.html. 状态管理 类Flux状态管理的官方实现 由于状态零散地分布在许多组件和组件之间的交互中, ...
- 2019/02/16 STL容器 :栈
一.栈(stack) 1.定义: 栈是一种只能在某一端插入和删除数据的特殊线性表.他按照先进先出的原则存储数据,先进的数据被压入栈底,最后进入的数据在栈顶,需要读数据的时候从栈顶开始弹出数据(最后被压 ...
- 图论--SCC缩点--Tarjan
// Tarjan算法求有向图强连通分量并缩点 /*强连通缩点与双连通缩点大同小异,也就是说将强连通分支缩成一个点之后,没有强连通,成为有向无环图,在对图进行题目的操作.*/ #include< ...
- IDEA 打可执行jar包(maven项目)
1. Ctrl+Shift+Alt+S 打开 Project Structure 2.选择要执行的文件, 依次选择 项目, 方法所在文件(必须有main方法), 保存 3.如果之前路径下曾经打过 ...
- 《Docker从入门到跑路》之镜像和容器的基本操作
一.获取镜像 官方提供了一个公共镜像仓库Docker Hub,默认是从这上面获取镜像的. 搜素镜像使用docker search 命令: # docker search --help Usage: d ...
- MES系统的模型结构和主要功能(二)
上一节,我们主要说了Mes系统是什么,以及它的特点和难点,本节,再来讨论一下一个合格的MES系统的模型结构和基本功能. 现代工厂的快速发展,对MES系统提出了更高的要求,其必须满足范围广泛的任务要求, ...
- 王颖奇 201771010129《面向对象程序设计(java)》第七周学习总结
实验七 继承附加实验 实验时间 2018-10-11 1.实验目的与要求 (1)进一步理解4个成员访问权限修饰符的用途: A.仅对本类可见-private B.对所有类可见-public C.对本包和 ...
- 完了!CPU一味求快出事儿了!
自我介绍 我叫阿Q,是CPU一号车间里的员工,我所在的这个CPU足足有8个核,就有8个车间,干起活来杠杠滴. 我所在的一号车间里,除了负责执行指令的我,还有负责取指令的小A,负责分析指令的小胖和负责结 ...