入门大数据---Map/Reduce,Yarn是什么?
简单概括:Map/Reduce是分布式离线处理的一个框架。 Yarn是Map/Reduce中的一个资源管理器。
一.图形说明下Map/Reduce结构:
官方示意图:
另外还可以参考这个:
流程介绍:
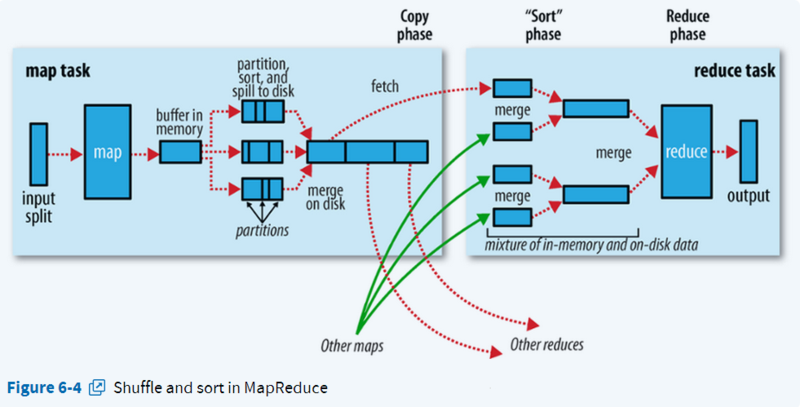
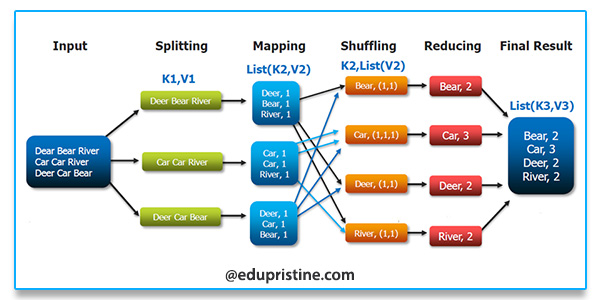
HDFS首先会把块进行逻辑上切片处理,然后进行Map映射。一个切片对应一个Map映射。
因为文件内容有可能一个单词被切到两个文件里面,这样计算就会有问题,所以Map映射时除了第一个切片完全映射,其余的映射都会从第二行开始映射,而第一行传递给上一个Map处理。
Map程序初始化会设定一个阈值,比如80%,当超过这个值的时候就会就会进行内存溢出。溢出前会进行一个【快速排序】,排完后写入硬盘分区。(不设置阈值,当内存满后,就会阻塞数据继续写入。设定的阈值根据实际情况设定,太小了会增加读写压力,太大了会产生阻塞。)
程序可以设置合并操作,当分区数超过设定值后就进行合并(combiner)。(比如分区>3后)(合并后,相同key的数据就压缩了,拉取的时候就会减少IO)
Reduce会检查是否Map完,有一个Map完后就能拉取一次。
Reduce拉取的时候会有一个真迭代器和一个假迭代器进行嵌套,比如一组数据 A 1 A 1 A 1 B 1,假迭代器会进行循环然后取下一条数据进行比较看是否相同,相同的话进行累加值,再取下一条,这样下一条下一条的取,直到key不相同时候,结束本组循环,进行下一组循环。 这样A就统计出3,B就统计出1来了。
二.图形说明下Yarn的结构:
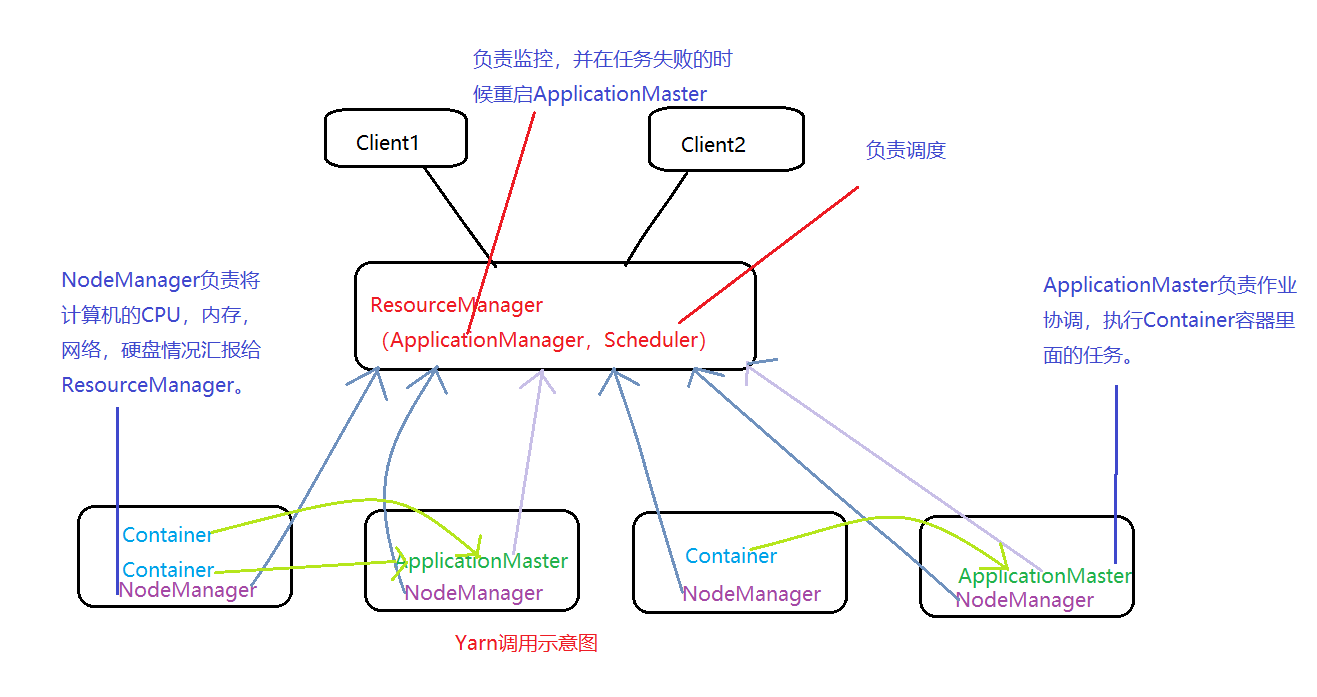
流程介绍:首先Client请求ResourceManager,然后ResourceManager分配一个Container启动ApplicationMaster,ApplicatoinMaster向ResourceManager请求分配更多Container。Container一部分执行Map任务,一部分执行Reduce任务。
三.图形说明下Map/Reduce和Yarn在整个Hadoop系统中的位置以及为什么产生Yarn:
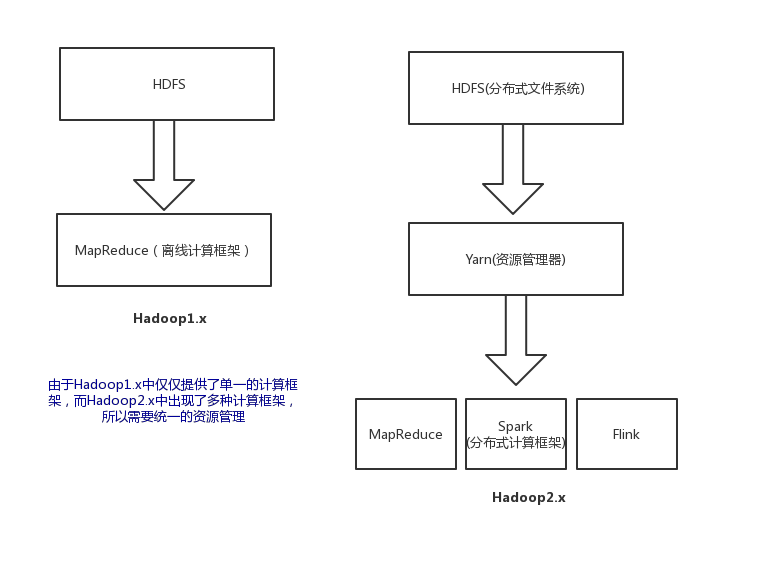
由于产生了多种计算框架,所以需要一个资源管理器来对资源进行分配使用。
系列传送门 学习官网: http://hadoop.apache.org/
入门大数据---Map/Reduce,Yarn是什么?的更多相关文章
- 大数据篇:YARN
YARN YARN是什么? YARN是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率.资源统一管理和数据共享等方面带来了巨大 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Hive数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件 emp.txt 和 dept.txt 可以从本仓库的resources 目录下载. 1.1 员工表 -- 建表语句 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---通过Flume、Sqoop分析日志
一.Flume安装 参考:Flume 简介及基本使用 二.Sqoop安装 参考:Sqoop简介与安装 三.Flume和Sqoop结合使用案例 日志分析系统整体架构图: 3.1配置nginx环境 请参考 ...
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
随机推荐
- 网络编程TCP/IP详解
网络编程TCP/IP详解 1. 网络通信 中继器:信号放大器 集线器(hub):是中继器的一种形式,区别在于集线器能够提供多端口服务,多口中继器,每个数据包的发送都是以广播的形式进行的,容易阻塞网络. ...
- (三)用less+gulp+requireJs 搭建项目(requireJs)
首先我想说下我在写js时经常遇到的问题,尤其是很大的项目: 1.我一般会把各个功能分块写在各个js文件中: 比如弹出框: dialog.js $(document).ready(function(){ ...
- Java实现 LeetCode 718 最长重复子数组(动态规划)
718. 最长重复子数组 给两个整数数组 A 和 B ,返回两个数组中公共的.长度最长的子数组的长度. 示例 1: 输入: A: [1,2,3,2,1] B: [3,2,1,4,7] 输出: 3 解释 ...
- Java实现 LeetCode 89 格雷编码
89. 格雷编码 格雷编码是一个二进制数字系统,在该系统中,两个连续的数值仅有一个位数的差异. 给定一个代表编码总位数的非负整数 n,打印其格雷编码序列.格雷编码序列必须以 0 开头. 示例 1: 输 ...
- Java实现 蓝桥杯VIP 算法提高 格子位置
算法提高 格子位置 时间限制:1.0s 内存限制:512.0MB 问题描述 输入三个自然数N,i,j (1<=i<=N,1<=j<=N),输出在一个N*N格的棋盘中,与格子(i ...
- java中Dateformat类的详细使用(详解)
DateFormat其本身是一个抽象类,SimpleDateFormat 类是DateFormat类的子类,一般情况下来讲DateFormat类很少会直接使用,而都使用SimpleDateFormat ...
- Linux网络命令详解
命令write,功能是给指定用户发信息(接收信息的用户要处于登录状态,相当于QQ的私聊),例如:用户xbb给用户liuyifei发消息:I want to eat together!(发送消息以CRT ...
- 使用PD(Power Designer)设计数据库,并且生成可执行的SQL文件创建数据库(本文以SQL Server Management Studio软件执行为例)
下载和安装PD: 分享我的软件资源,里面包含了对PD汉化包(链接出问题时可以留言,汉化包只能对软件里面部分菜单栏汉化) 链接:https://pan.baidu.com/s/1lNt1UGZhtDV8 ...
- 使用navicat连接mysql连接错误:Lost connection to Mysql server at 'waiting for initial communication packet'
使用navicat时,报错截图如下: 原因分析: mysql开启了DNS的反向解析功能,这样mysql对连接的客户端会进行DNS主机名查找. mysql处理客户端解析过程: 当mysql的client ...
- Nice Jquery Validator 内置属性
required - 必填 适用于 input.textarea.select 输入框.(checkbox 与 radio 请使用 checked 规则)字段必填,则值不能为空.字段非必填,则值为空的 ...