2019-05-19 Python之第一个爬虫和测试
一.使用request和get访问某个网页20次并且打印返回状态,内容
扩展:常见状态码含义 200 - 服务器成功返回网页,404 - 请求的网页不存在,403(禁止)服务器拒绝请求,404(未找到)服务器找不到请求的网页,503 - 服务器超时,3xx (重定向)
(1)request库简介:处理HTTP请求的第三方库,建立在urllib3库的基础上
(2)常用函数 get(url[,timeout = n ]), post
delete,head,options,put等等
(3)status_code返回状态。 text返回字符串形式。encoding返回编码方式。content返回二进制形式。注:response.text是解过码的字符串(比如html代码)。当requests发送请求到一个网页时,requests库会推测目标网页的编码,并对其解码,转为字符串(str)。这种方法比较容易出现乱码。
(4)实例代码
import requests
r = requests.get('https://www.sogou.com/', timeout = 4) #使用get方式请求搜狗网站
print("状态码 = {}".format( r.status_code))#输出状态码
print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
(5)输出结果:
状态码 = 200
。。。。。。。。。。。。。。。。省略
编码方式 = UTF-8
二进制形式 = b'<!DOCTYPE。。。。。。。。。。。。省略
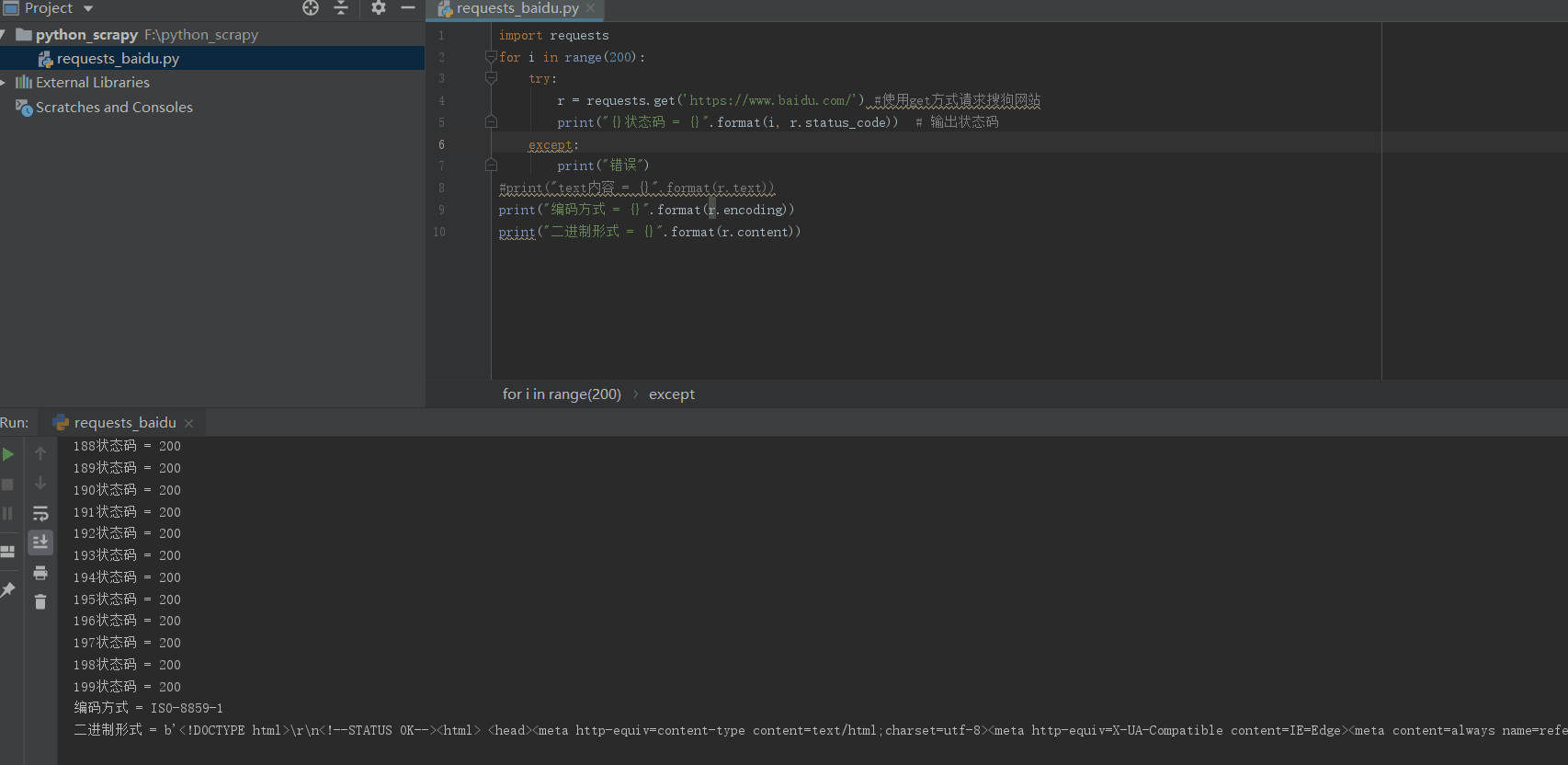
(6)测试连续访问20次的结果
import requests
for i in range(200):
r = requests.get('https://www.baidu.com/') #使用get方式请求搜狗网站
print("状态码 = {}".format(r.status_code)) # 输出状态码
#print("text内容 = {}".format(r.text))
print("编码方式 = {}".format(r.encoding))
print("二进制形式 = {}".format(r.content))
二.使用beautifulsoup4解析HTML页面格式,提取有用信息
(1)beautifulsoup4库的简介:解析和处理HTML和XML
(2)常用函数head获取<head>内容,title,body,p第一个<p>内容,strings所有程序在web上的字符串,即标签的内容,stripped_strings所有呈现在web上的非空字符串
(3)示例
三.爬取中国大学排名
from bs4 import BeautifulSoup
import requests
import pandas as pd allUniv = [] def getHTMLText(url):
try:
r = requests.get(url, timeout=10)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return ""
def filUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd) == 0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
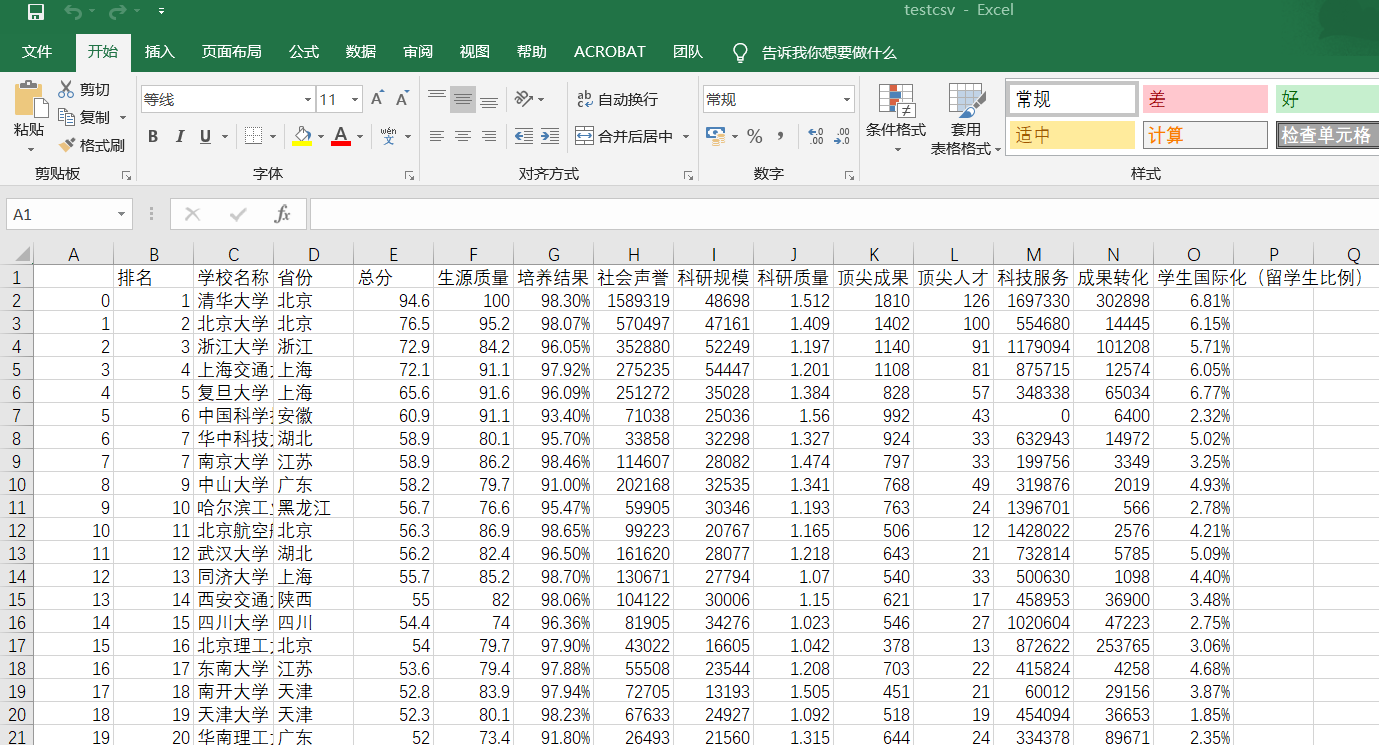
write_csv(allUniv) def write_csv(list):
name = ['排名', '学校名称', '省份', '总分', '生源质量(新生高考成绩得分)', '培养结果(毕业生就业率)', '社会声誉(社会捐赠收入·千元)', '科研规模(论文数量·篇)',\
'科研质量(论文质量·FWCI)', '顶尖成果(高被引论文·篇)', '顶尖人才(高被引学者·人)', '科技服务(企业科研经费·千元)', '成果转化(技术转让收入·千元)', '学生国际化(留学生比例)']
name2 = ['a', 'b', 'c']
test = pd.DataFrame(columns=name, data=list)
test.to_csv('e:/testcsv.csv', encoding='gbk') def main():
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
filUnivList(soup)
print("完成") main()
效果图:
2019-05-19 Python之第一个爬虫和测试的更多相关文章
- 孤荷凌寒自学python第八十天开始写Python的第一个爬虫10
孤荷凌寒自学python第八十天开始写Python的第一个爬虫10 (完整学习过程屏幕记录视频地址在文末) 原计划今天应当可以解决读取所有页的目录并转而取出所有新闻的功能,不过由于学习时间不够,只是进 ...
- 孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9并使用pydocx模块将结果写入word文档
孤荷凌寒自学python第七十九天开始写Python的第一个爬虫9 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天终于完成了对docx模块针对 ...
- 孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5
孤荷凌寒自学python第七十五天开始写Python的第一个爬虫5 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4
孤荷凌寒自学python第七十四天开始写Python的第一个爬虫4 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3
孤荷凌寒自学python第七十三天开始写Python的第一个爬虫3 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2
孤荷凌寒自学python第七十二天开始写Python的第一个爬虫2 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 直接上代码.详细过程见文末屏幕录像 ...
- 孤荷凌寒自学python第七十一天开始写Python的第一个爬虫
孤荷凌寒自学python第七十一天开始写Python的第一个爬虫 (完整学习过程屏幕记录视频地址在文末) 在了解了requests模块和BeautifulSoup模块后,今天开始真正写一个自己的爬虫代 ...
- 孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8
孤荷凌寒自学python第七十八天开始写Python的第一个爬虫8 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 到今天止基本完成了对docx模块针 ...
- 孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7
孤荷凌寒自学python第七十七天开始写Python的第一个爬虫7 (完整学习过程屏幕记录视频地址在文末) 今天在上一天的基础上继续完成对我的第一个代码程序的书写. 今天的学习仍然是在纯粹对docx模 ...
随机推荐
- iOS 原生库(AVFoundation)实现二维码扫描,封装的工具类,不依赖第三方库,可高度自定义扫描动画及界面(Swift 4.0)
Create QRScanner.swift file // // QRScanner.swift // NativeQR // // Created by Harvey on 2017/10/24. ...
- Java 中,如何对日期进行加减操作
今天在做项目时,遇到了对时间的加减进行操作的需求,根据传入的日期字符串,操作参数("+","-"),加数(要操作的天数),对日期进行加减操作,经查询资料,自己写 ...
- Burpsuite被动扫描流量转发插件:Passive Scan Client
编译成品:链接: https://pan.baidu.com/s/1E0vsPGgPgB9bXCW-8Yl1gw 提取码: 49eq Passive Scan Client Burpsuite被动扫描 ...
- Redis缓存设计与性能优化
Redis我们一般是用作缓存,扛并发:或者用于某些特定的业务场景,比如前面说到redis各种数据类型的使用场景以及redis的哨兵和集群模式. 这里主要整理了下redis用作缓存,存在的一些问题,以及 ...
- VirtualBox 版本 6.1.2 r135662, ubuntu18 配置共享文件夹、openssh-server
续上章安装完ubuntu18. 输入账号密码,登录成功. 但是使用ssh工具,却登录失败. 1.安装openssh-server sudo apt install openssh-server 2.检 ...
- 从源码和doc揭秘——Java中的Char究竟几个字节,Java与Unicode的关系
#编码与字符编码 (懂编码的建议直接跳过) 在计算机世界中,任何事物都是用二进制图片数字表示的,图片可以编码为JPG,PNG格式的字节流,音频,视频有MP3,MP4格式的字节流.这些JPG,MP3等都 ...
- Netty:初识Netty
前文总结了NIO的内容,有了NIO的一些基础之后,我们就可以来看下Netty.Netty是Java领域的高性能网络传输框架,RPC的技术核心就是网络传输和序列化,所以Netty给予了RPC在网络传输领 ...
- python之目录
一.python基础 python之字符串str操作方法 python之int (整型) python之bool (布尔值) python之str (字符型) python之ran ...
- POJ 1797 最短路变形所有路径最小边的最大值
题意:卡车从路上经过,给出顶点 n , 边数 m,然后是a点到b点的权值w(a到b路段的承重),求卡车最重的重量是多少可以从上面经过. 思路:求所有路径中的最小的边的最大值.可以用迪杰斯特拉算法,只需 ...
- 编译器移植到.NET Core失败记录和对.NET未来感想
.NET Core是微软力推的新平台,影响力好像还越来越大.为了对这一行业趋势有所准备,最近把自己搞的编程语言的编译器从.NET移植.NET Core,以实现跨平台在Linux上运行,然而失败了. 原 ...