Spring官网阅读(五)BeanDefinition(下)
上篇文章已经对
BeanDefinition做了一系列的介绍,这篇文章我们开始学习BeanDefinition合并的一些知识,完善我们整个BeanDefinition的体系,Spring在创建一个bean时多次进行了BeanDefinition的合并,对这方面有所了解也是为以后阅读源码做准备。本文主要对应官网中的1.7小节
在上篇文章中,我们学习了BeanDefinition的一些属性,其中有以下几个属性:
// 是否抽象
boolean isAbstract();
// 获取父BeanDefinition的名称
String getParentName();
上篇文章中说过,这几个属性跟BeanDefinition的合并相关,那么我先考虑一个问题,什么是合并呢?
什么是合并?
我们来看官网上的一段介绍:

大概翻译如下:
一个BeanDefinition包含了很多的配置信息,包括构造参数,setter方法的参数还有容器特定的一些配置信息,比如初始化方法,静态工厂方法等等。一个子的BeanDefinition可以从它的父BeanDefinition继承配置信息,不仅如此,还可以覆盖其中的一些值或者添加一些自己需要的属性。使用BeanDefinition的父子定义可以减少很多的重复属性的设置,父BeanDefinition可以作为BeanDefinition定义的模板。
我们通过一个例子来观察下合并发生了什么,编写一个Demo如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="parent" abstract="true"
class="com.dmz.official.merge.TestBean">
<property name="name" value="parent"/>
<property name="age" value="1"/>
</bean>
<bean id="child"
class="com.dmz.official.merge.DerivedTestBean"
parent="parent" >
<property name="name" value="override"/>
</bean>
</beans>
public class DerivedTestBean {
private String name;
private int age;
// 省略getter setter方法
}
public class TestBean {
private String name;
private String age;
// 省略getter setter方法
}
public class Main {
public static void main(String[] args) {
ClassPathXmlApplicationContext cc = new ClassPathXmlApplicationContext("application.xml");
DerivedTestBean derivedTestBean = (DerivedTestBean) cc.getBean("child");
System.out.println("derivedTestBean的name = " + derivedTestBean.getName());
System.out.println("derivedTestBean的age = " + derivedTestBean.getAge());
}
}
运行:
derivedTestBean的name = override
derivedTestBean的age = 1
在上面的例子中,我们将DerivedTestBean的parent属性设置为了parent,指向了我们的TestBean,同时将TestBean的age属性设置为1,但是我们在配置文件中并没有直接设置DerivedTestBean的age属性。但是在最后运行结果,我们可以发现,DerivedTestBean中的age属性已经有了值,并且为1,就是我们在其parent Bean(也就是TestBean)中设置的值。也就是说,子BeanDefinition会从父BeanDefinition中继承没有的属性。另外,DerivedTestBean跟TestBean都指定了name属性,但是可以发现,这个值并没有被覆盖掉,也就是说,子BeanDefinition中已经存在的属性不会被父BeanDefinition中所覆盖。
合并的总结:
所以我们可以总结如下:
- 子
BeanDefinition会从父BeanDefinition中继承没有的属性 - 这个过程中,子
BeanDefinition中已经存在的属性不会被父BeanDefinition中所覆盖
关于合并需要注意的点:
另外我们需要注意的是:
- 子
BeanDefinition中的class属性如果为null,同时父BeanDefinition又指定了class属性,那么子BeanDefinition也会继承这个class属性。 - 子
BeanDefinition必须要兼容父BeanDefinition中的所有属性。这是什么意思呢?以我们上面的demo为例,我们在父BeanDefinition中指定了name跟age属性,但是如果子BeanDefinition中子提供了一个name的setter方法,这个时候Spring在启动的时候会报错。因为子BeanDefinition不能承接所有来自父BeanDefinition的属性 - 关于
BeanDefinition中abstract属性的说明:- 并不是作为父
BeanDefinition就一定要设置abstract属性为true,abstract只代表了这个BeanDefinition是否要被Spring进行实例化并被创建对应的Bean,如果为true,代表容器不需要去对其进行实例化。 - 如果一个
BeanDefinition被当作父BeanDefinition使用,并且没有指定其class属性。那么必须要设置其abstract为true abstract=true一般会跟父BeanDefinition一起使用,因为当我们设置某个BeanDefinition的abstract=true时,一般都是要将其当作BeanDefinition的模板使用,否则这个BeanDefinition也没有意义,除非我们使用其它BeanDefinition来继承它的属性
- 并不是作为父
Spring在哪些阶段做了合并?
下文将所有
BeanDefinition简称为bd
1、扫描并获取到bd:
这个阶段的操作主要发生在invokeBeanFactoryPostProcessors,对应方法的调用栈如下:
对应的执行该方法的类为:PostProcessorRegistrationDelegate
方法源码如下:
public static void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory,
List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// .....
// 省略部分代码,省略的代码主要时用来执行程序员手动调用API注册的容器的后置处理器
// .....
// 发生一次bd的合并
// 这里只会获取实现了BeanDefinitionRegistryPostProcessor接口的Bean的名字
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 筛选实现了PriorityOrdered接口的后置处理器
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 去重
processedBeans.add(ppName);
}
}
// .....
// 只存在一个internalConfigurationAnnotationProcessor 处理器,用于扫描
// 这里只会执行了实现了PriorityOrdered跟BeanDefinitionRegistryPostProcessor的后置处理器
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
// .....
// 这里又进行了一个bd的合并
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 筛选实现了Ordered接口的后置处理器
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
// .....
// 执行的是实现了BeanDefinitionRegistryPostProcessor接口跟Ordered接口的后置处理器
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
boolean reiterate = true;
while (reiterate) {
reiterate = false;
// 这里再次进行了一次bd的合并
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
// 筛选只实现了BeanDefinitionRegistryPostProcessor的后置处理器
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
// 执行的是普通的后置处理器,即没有实现任何排序接口(PriorityOrdered或Ordered)
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// .....
// 省略部分代码,这部分代码跟BeanfactoryPostProcessor接口相关,这节bd的合并无关,下节容器的扩展点中我会介绍
// .....
}
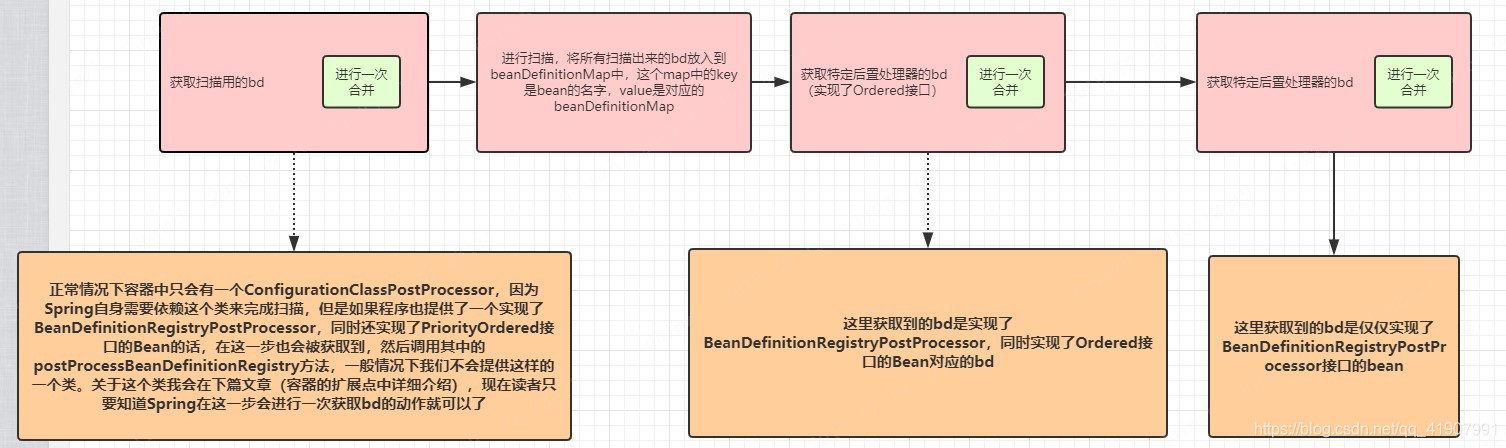
大家可以结合我画的图跟上面的代码过一遍流程,只要弄清楚一点就行,即每次调用beanFactory.getBeanNamesForType都进行了一次bd的合并。getBeanNamesForType这个方法主要目的是为了或者指定类型的bd的名称,之后通过bd的名称去找到指定的bd,然后获取对应的Bean,比如上面方法三次获取的都是BeanDefinitionRegistryPostProcessor这个类型的bd。
我们可以思考一个问题,为什么这一步需要合并呢?大家可以带着这个问题继续往下看,在后文我会解释。
2、实例化
Spring在实例化一个对象也会进行bd的合并。
第一次:
org.springframework.beans.factory.support.DefaultListableBeanFactory#preInstantiateSingletons
public void preInstantiateSingletons() throws BeansException {
// .....
// 省略跟合并无关的代码
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
// .....
第二次:
org.springframework.beans.factory.support.AbstractBeanFactory#doGetBean
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
// .....
// 省略跟合并无关的代码
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
checkMergedBeanDefinition(mbd, beanName, args);
// Guarantee initialization of beans that the current bean depends on.
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
// ....
}
if (mbd.isSingleton()) {
// ....
}
// ....
我们可以发现这两次合并有一个共同的特点,就是在合并之后立马利用了合并之后的bd我们简称为mbd做了一系列的判断,比如上面的dependsOn != null和mbd.isSingleton()。基于上面几个例子我们来分析:为什么需要合并?
为什么需要合并?
在扫描阶段,之所以发生了合并,是因为Spring需要拿到指定了实现了BeanDefinitionRegistryPostProcessor接口的bd的名称,也就是说,Spring需要用到bd的名称。所以进行了一次bd的合并。在实例化阶段,是因为Spring需要用到bd中的一系列属性做判断所以进行了一次合并。我们总结起来,其实就是一个原因:Spring需要用到bd的属性,要保证获取到的bd的属性是正确的。
那么问题来了,为什么获取到的bd中属性可能不正确呢?
主要两个原因:
- 作为子
bd,属性本身就有可能缺失,比如我们在开头介绍的例子,子bd中本身就没有age属性,age属性在父bd中 - Spring提供了很多扩展点,在启动容器的时候,可能会修改
bd中的属性。比如一个正常实现了BeanFactoryPostProcessor就能修改容器中的任意的bd的属性。在后面的容器的扩展点中我再介绍
合并的代码分析:
因为合并的代码其实很简单,所以一并在这里分析了,也可以加深对合并的理解:
protected RootBeanDefinition getMergedLocalBeanDefinition(String beanName) throws BeansException {
// Quick check on the concurrent map first, with minimal locking.
// 从缓存中获取合并后的bd
RootBeanDefinition mbd = this.mergedBeanDefinitions.get(beanName);
if (mbd != null) {
return mbd;
}
// 如何获取不到的话,开始真正的合并
return getMergedBeanDefinition(beanName, getBeanDefinition(beanName));
}
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, @Nullable BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
// Check with full lock now in order to enforce the same merged instance.
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null) {
// 如果没有parentName的话直接使用自身合并
// 就是new了RootBeanDefinition然后再进行属性的拷贝
if (bd.getParentName() == null) {
if (bd instanceof RootBeanDefinition) {
mbd = ((RootBeanDefinition) bd).cloneBeanDefinition();
}
else {
mbd = new RootBeanDefinition(bd);
}
}
else {
// 需要进行父子的合并
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());
if (!beanName.equals(parentBeanName)) {
// 这里是递归,在将父子合并时,需要确保父bd已经合并过了
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
// 一般不会进这个判断
// 到父容器中找对应的bean,然后进行合并,合并也发生在父容器中
BeanFactory parent = getParentBeanFactory();
if (parent instanceof ConfigurableBeanFactory) {
pbd = ((ConfigurableBeanFactory) parent).getMergedBeanDefinition(parentBeanName);
}
// 省略异常信息......
}
}
// 省略异常信息......
//
mbd = new RootBeanDefinition(pbd);
//用子bd中的属性覆盖父bd中的属性
mbd.overrideFrom(bd);
}
// 默认设置为单例
if (!StringUtils.hasLength(mbd.getScope())) {
mbd.setScope(RootBeanDefinition.SCOPE_SINGLETON);
}
// 当前bd如果内部嵌套了一个bd,并且嵌套的bd不是单例的,但是当前的bd又是单例的
// 那么将当前的bd的scope设置为嵌套bd的类型
if (containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()) {
mbd.setScope(containingBd.getScope());
}
// 将合并后的bd放入到mergedBeanDefinitions这个map中
// 之后还是可能被清空的,因为bd可能被修改
if (containingBd == null && isCacheBeanMetadata()) {
this.mergedBeanDefinitions.put(beanName, mbd);
}
}
return mbd;
}
}
上面这段代码整体不难理解,可能发生疑惑的主要是两个点:
pbd = getMergedBeanDefinition(parentBeanName);
这里进行的是父bd的合并,是方法的递归调用,这是因为在合并的时候父bd可能也还不是一个合并后的bd
containingBd != null && !containingBd.isSingleton() && mbd.isSingleton()
我查了很久的资料,经过验证后发现,如果进行了形如下面的嵌套配置,那么containingBd会不为null
<bean id="luBanService" class="com.dmz.official.service.LuBanService" scope="prototype">
<property name="lookUpService">
<bean class="com.dmz.official.service.LookUpService" scope="singleton"></bean>
</property>
</bean>
在这个例子中,containingBd为LuBanService,此时,LuBanService是一个原型的bd,但lookUpService是一个单例的bd,那么这个时候经过合并,LookUpService也会变成一个原型的bd。大家可以拿我这个例子测试一下。
总结:
这篇文章我觉得最重要的是,我们要明白Spring为什么要进行合并,之所以再每次需要用到BeanDefinition都进行一次合并,是为了每次都拿到最新的,最有效的BeanDefinition,因为利用容器提供了一些扩展点我们可以修改BeanDefinition中的属性。关于容器的扩展点,比如上文提到了BeanFactoryPostProcessor以及BeanDefinitionRegistryPostProcessor,我会在后面的几篇文章中一一介绍。
BeanDefinition的学习就到这里了,这个类很重要,是整个Spring的基石,希望大家可以多花时间多研究研究相关的知识。加油,共勉!
Spring官网阅读(五)BeanDefinition(下)的更多相关文章
- Spring官网阅读 | 总结篇
接近用了4个多月的时间,完成了整个<Spring官网阅读>系列的文章,本文主要对本系列所有的文章做一个总结,同时也将所有的目录汇总成一篇文章方便各位读者来阅读. 下面这张图是我整个的写作大 ...
- Spring官网阅读(十八)Spring中的AOP
文章目录 什么是AOP AOP中的核心概念 切面 连接点 通知 切点 引入 目标对象 代理对象 织入 Spring中如何使用AOP 1.开启AOP 2.申明切面 3.申明切点 切点表达式 excecu ...
- Spring官网阅读(十七)Spring中的数据校验
文章目录 Java中的数据校验 Bean Validation(JSR 380) 使用示例 Spring对Bean Validation的支持 Spring中的Validator 接口定义 UML类图 ...
- Spring官网阅读(十六)Spring中的数据绑定
文章目录 DataBinder UML类图 使用示例 源码分析 bind方法 doBind方法 applyPropertyValues方法 获取一个属性访问器 通过属性访问器直接set属性值 1.se ...
- Spring官网阅读(三)自动注入
上篇文章我们已经学习了1.4小结中关于依赖注入跟方法注入的内容.这篇文章我们继续学习这结中的其他内容,顺便解决下我们上篇文章留下来的一个问题-----注入模型. 文章目录 前言: 自动注入: 自动注入 ...
- Spring官网阅读(一)容器及实例化
从今天开始,我们一起过一遍Spring的官网,一边读,一边结合在路神课堂上学习的知识,讲一讲自己的理解.不管是之前关于动态代理的文章,还是读Spring的官网,都是为了之后对Spring的源码做更全面 ...
- Spring官网阅读(二)(依赖注入及方法注入)
上篇文章我们学习了官网中的1.2,1.3两小节,主要是涉及了容器,以及Spring实例化对象的一些知识.这篇文章我们继续学习Spring官网,主要是针对1.4小节,主要涉及到Spring的依赖注入.虽 ...
- Spring官网阅读(四)BeanDefinition(上)
前面几篇文章已经学习了官网中的1.2,1.3,1.4三小结,主要是容器,Bean的实例化及Bean之间的依赖关系等.这篇文章,我们继续官网的学习,主要是BeanDefinition的相关知识,这是Sp ...
- Spring官网阅读(十三)ApplicationContext详解(下)
文章目录 BeanFactory 接口定义 继承关系 接口功能 1.HierarchicalBeanFactory 2.ListableBeanFactory 3.AutowireCapableBea ...
随机推荐
- Anadi and Domino--codeforces div2
题目链接:https://codeforces.com/contest/1230/problem/C 题目大意:21枚多米诺牌,给你一个图,将多米诺牌放到图的边上,由同一个点发出的所有边,边上多米诺牌 ...
- 调用sleep后,我做了一个噩梦
sleep系统调用 我是一个线程,生活在Linux帝国.一直以来辛勤工作,日子过得平平淡淡,可今天早上发生了一件事让我回想起来都后怕. 早上,我还是如往常一样执行着人类编写的代码指令,不多时走到了一个 ...
- Linux下nginx自启动配置
1.在linux系统的/etc/init.d/目录下创建nginx文件 vim /etc/init.d/nginx 在脚本中添加一下命令(内容主要参考官方文档) #!/bin/sh # # nginx ...
- C# LINQ查询之对象
LINQ是一组查询技术的统称,其主要思想是将各种查询功能直接集成到C#语言中,可以对 对象.XML文档.SQL数据库.外部应用程序等进行操作. 这里面讲的简单的几个子句, 必须以from子句开头,以s ...
- 博云DevOps 3.0重大升级 | 可用性大幅提升、自研需求管理&自定义工作流上线,满足客户多样化需求
DevOps能够为企业带来更高的部署频率.更短的交付周期与更快的客户响应速度.标准化.规范化的管理流程,可视化和数字化的研发进度管理和可追溯的版本也为企业带来的了更多的价值.引入DevOps成为企业实 ...
- Elasticsearch 集群部署
本文部署环境 $ cat /etc/redhat-release CentOS Linux release (Core) 部署前系统优化 $ /etc/security/limits.conf roo ...
- deepin15.11小毛病解决
目录 边缘花屏问题 QQ`Tim头像问题 ssh卡死问题 看直播卡 边缘花屏问题 sudo apt install systemsettings 打开kde系统设置 打开显示与设置,修改如图下,基本上 ...
- Java集合:ArrayList (JDK1.8 源码解读)
ArrayList ArrayList几乎是每个java开发者最常用也是最熟悉的集合,看到ArrayList这个名字就知道,它必然是以数组方式实现的集合 关注点 说一下ArrayList的几个特点,也 ...
- Visual Studio 添加图标和版本
在Visual Studio中,如果你创建的是纯C语言的工程,那么给可执行程序添加图标就没有便捷的入口. 但也只是入口不好找了,添加步骤还是比较简单的,以下为具体操作方法: 1. 右键点击C工 ...
- MySQL事务与并发
很多程序员都学过MySQL,而且也会写SQL语句.但仅仅会写还远远不够,在面试中以及在工作中,还必须要会事务和并发. 一.事务 事务是满足 ACID 特性的操作,可以通过 Commit 提交事务, ...