scikit-learn中的岭回归(Ridge Regression)与Lasso回归
一、岭回归模型
岭回归其实就是在普通最小二乘法回归(ordinary least squares regression)的基础上,加入了正则化参数λ。
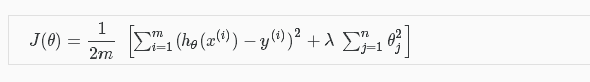
二、如何调用
class sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True, normalize=False, copy_X=True, max_iter=None, tol=0.001, solver='auto')
alpha:就是上述正则化参数λ;
fit_intercept:默认为true,数据可以拦截,没有中心化;
normalize:输入的样本特征归一化,默认false;
copy_X:复制或者重写;
max_iter:最大迭代次数;
tol: 控制求解的精度;
solver:求解器,有auto, svd, cholesky, sparse_cg, lsqr几种,一般我们选择auto,一些svd,cholesky也都是稀疏表示中常用的omp求解算法中的知识,大家有时间可以去了解。
Ridge函数会返回一个clf类,里面有很多的函数,一般我们用到的有:
clf.fit(X, y):输入训练样本数据X,和对应的标记y;
clf.predict(X):利用学习好的线性分类器,预测标记,一般在fit之后调用;
clf.corf_: 输入回归表示系数
详见:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html#sklearn.linear_model.Ridge.decision_function
三、Lasso模型(Least absolute shrinkage and selection operator-最小绝对收缩与选择算子)
Lasso构造的是一个一阶的惩罚函数,满足L1范数,从而使得模型的一些变量参数可能为0(岭回归系数为0的可能性非常低),得到的模型更为精炼。
Lasso的正则化惩罚函数形式是L1范数,属于绝对值形式,L1范数的好处是当lambda充分大时可以把某些待估参数精确地收缩到0。回归的参数估计经常会有为0的状况,对于这种参数,我们便可以选择对它们进行剔除,就不用我们进行人工选择剔除变量,而可以让程序自动根据是否为0来剔除掉变量了。剔除了无用变量后,可能会使的模型效果更好,因为会存在一些关联比较大的共线变量,从这个角度来看,Lasso回归要优于岭回归。
scikit-learn对lasso模型的调用与上述岭回归调用大同小异,详见:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
scikit-learn中的岭回归(Ridge Regression)与Lasso回归的更多相关文章
- 岭回归(Ridge Regression)
一.一般线性回归遇到的问题 在处理复杂的数据的回归问题时,普通的线性回归会遇到一些问题,主要表现在: 预测精度:这里要处理好这样一对为题,即样本的数量和特征的数量 时,最小二乘回归会有较小的方差 时, ...
- 机器学习方法:回归(二):稀疏与正则约束ridge regression,Lasso
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. "机器学习方法"系列,我本着开放与共享(open and share)的精神撰写,目的是 ...
- ISLR系列:(4.2)模型选择 Ridge Regression & the Lasso
Linear Model Selection and Regularization 此博文是 An Introduction to Statistical Learning with Applicat ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- 线性回归大结局(岭(Ridge)、 Lasso回归原理、公式推导),你想要的这里都有
本文已参与「新人创作礼」活动,一起开启掘金创作之路. 线性模型简介 所谓线性模型就是通过数据的线性组合来拟合一个数据,比如对于一个数据 \(X\) \[X = (x_1, x_2, x_3, ..., ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- Jordan Lecture Note-4: Linear & Ridge Regression
Linear & Ridge Regression 对于$n$个数据$\{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\},x_i\in\mathbb{R}^d,y ...
- 多元线性回归模型的特征压缩:岭回归和Lasso回归
多元线性回归模型中,如果所有特征一起上,容易造成过拟合使测试数据误差方差过大:因此减少不必要的特征,简化模型是减小方差的一个重要步骤.除了直接对特征筛选,来也可以进行特征压缩,减少某些不重要的特征系数 ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- 机器学习:模型泛化(LASSO 回归)
一.基础理解 LASSO 回归(Least Absolute Shrinkage and Selection Operator Regression)是模型正则化的一定方式: 功能:与岭回归一样,解决 ...
随机推荐
- c# 调用c++ 使用指针传递的时候
http://www.cnblogs.com/warensoft/archive/2011/12/09/warenosoft3d.html 上面这篇文章很好解释了. 简单记录一下: 1. 声明 注意 ...
- [STL] 如何将一个vector赋给另一个vector
vector 有个函数assign, 可以帮助执行赋值操作. assign会清空你的容器. assign函数: 函数原型: void assign(const_iterator first,const ...
- Django+haystack实现全文搜索出现错误 ImportError: cannot import name signals
原因是在你的settings.py或者其他地方使用了 "import haystack" 当我们使用django-haysatck库时,表面上会有haystack库,但实际上并不 ...
- chrome源码之恢复上次打开的标签页的学习
startup_browser_creator_impl.cc ————————>打开任何页面或浏览器的入口函数bool StartupBrowserCreatorImpl::ProcessSt ...
- [luogu5048] [Ynoi2019模拟赛] Yuno loves sqrt technology III
题目链接 洛谷. Solution 思路同[BZOJ2724] [Violet 6]蒲公英,只不过由于lxl过于毒瘤,我们有一些更巧妙的操作. 首先还是预处理\(f[l][r]\)表示\(l\sim ...
- CF498D:Traffic Jams in the Land——题解
https://vjudge.net/problem/CodeForces-498D http://codeforces.com/problemset/problem/498/D 题面描述: 一些国家 ...
- React Patterns
Contents Stateless function JSX spread attributes Destructuring arguments Conditional rendering Chil ...
- vector.clear()的内存泄露问题
在使用vector的过程中,经常会遇到以下场景 vector<int> vec; ) { vec.push_back(); vec.push_back(); vec.push_back() ...
- Qt ------ 初始化构造函数参数,parent
MainWindow::MainWindow(QWidget *parent) : QMainWindow(parent), ui(new Ui::MainWindow) { ui->setup ...
- Qt ------- QMap和QHash的区别
基本概念: QMap提供了一个从类项为key的键到类项为T的直的映射,通常所存储的数据类型是一个键对应一个值,并且按照Key的次序存储数据.同时这个类也支持一键多值的情况,用类QMultiMap可以实 ...