HADOOP/HDFS Essay
HDFS架构
the core of HADOOP/distributed systems is storeage(HDFS) and resource manager(YARN) for computing engines built on it.
Master/Slave: The character of distribution system follows M/S pattern.
Name Node
NN is the master and single active node. it contains / manges the namespace of files/dirs so called metadata , keeps block location andallocate data nodes.
Metadata is just like the one in linux file system including file name,size,owner/user,group,permission(umask) and HDFS specified elements like block ids , replication factor and block size and so on. Meta is in both memory and disk for fast access and restore respectively. NN also contains block location but it does not save it which is actually from DN. When a client access HDFS, it talks to NN first , NN checks the the permission, file existing just like the normal operation in a non-distributed linux system.
Data Node
The one actually stores files in form of blocks.
once a NN starts up, it sends its block report to NN like 'I(NN-1) has blocks #1,#2....' and it sends it periodically. So,NN can build a mapping of which bock in which DNs to serve file access request. DN also sends heartbeat information every 3 seconds to report its status along with actual data storage(total, free, used space and data transfer current in progress....) which is used for block allocating and and load banlancing by NN. a DN is considered dead if NN does not receive the HB within 10 mins. What is about the replication? It is for fault tolerance. If a block lost or a DN goes down, there is other nodes containing the same blocks. Also, based on the replciation, the system will also automatically replica the blocks if the number of copies does not meet the level.

Rack is nothing but a box with machines. dedicated power suply and network switch.
HDFS写
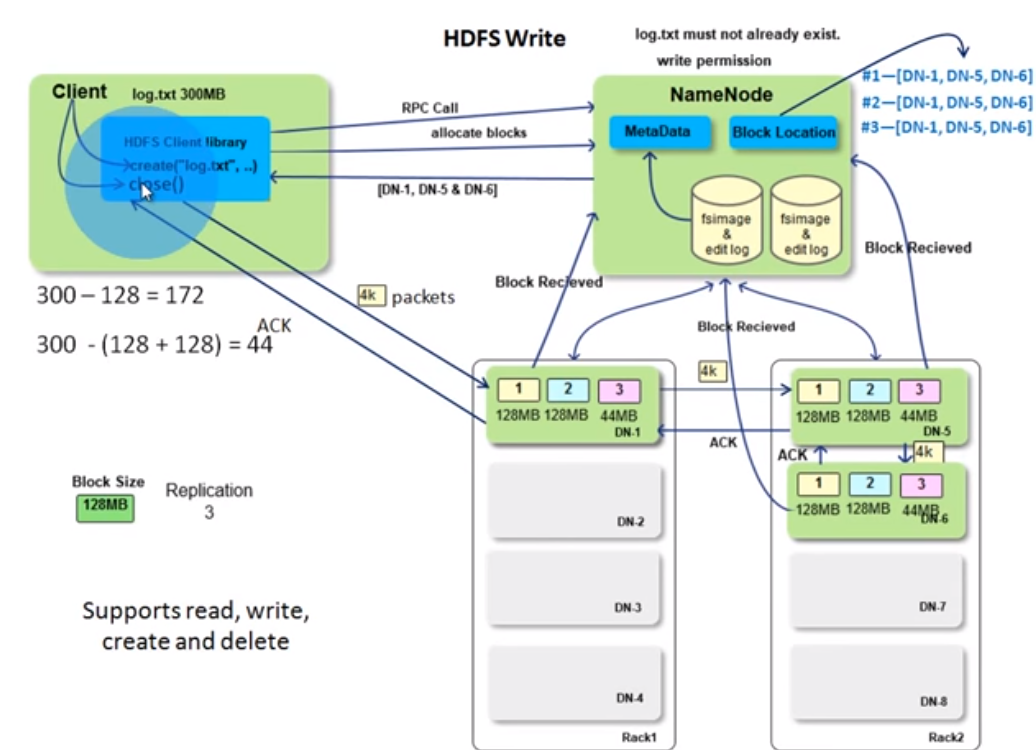
It should be easy to understand if you know the hdfs arch. client uses the hdfs client lib to manuplicate files. The communication is done thru RPC call. As mentioned before, NN will check metadata to see if client is qualified to write files. Then clients request NN to allocates blocks and NN returns the DN list(NN knows the status for each DN). for client to write the first 128MB block which is accumulated in the client library's managed space. This is the leader-folower pattern.The write to DNs is a pipleline so it is synchronized writing? client/leader writes data in a 4k packets and followers sends ACK so i guess it is synchronized writing. DNs also send the information to NN once it recieved the blocks. So, NN can build the block location in the write process as well. Then it contines to write the next 128 MB blocks. It loops till reach the EOF of the file. finally the client close() and indicates the operation is completed.
HDFS读
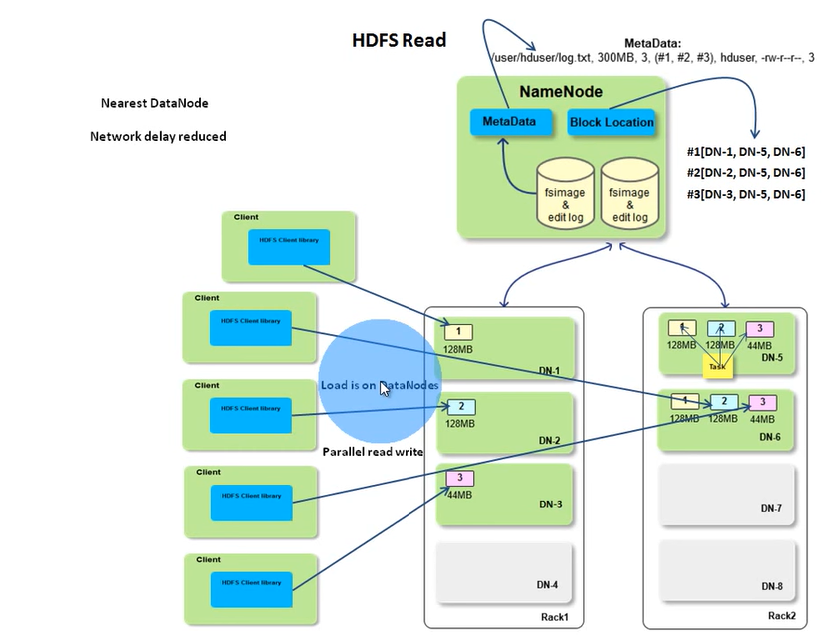
As mentioned before, you need HDFS java client library to perform the read operation like open the file, read the stream. client will call NN thru RPC to get the block id and block location. NN metadata has the block IDs for a file and the block location holds the mapping. Both of them are in memory and it should be fast. The actually read is between client and the DN. If the client is in a DN like a map task, the NN will return the block location with a list of network distance sort so the network delay will be reduced between racks. If the DN the map task is running on contains the blocks it needs, it will read directly locally. If the reading fails, client will switch to another node to read in the location list. Because of the data transfermation is between clients(you may have many current reads) and data nodes and name node only provides the block location, so, the load is distributed across the cluster. That's why HDFS is scalable. It may be not good to store vary large number of small files as name node may response poorly due to managing too much metadata.
When a DN is down
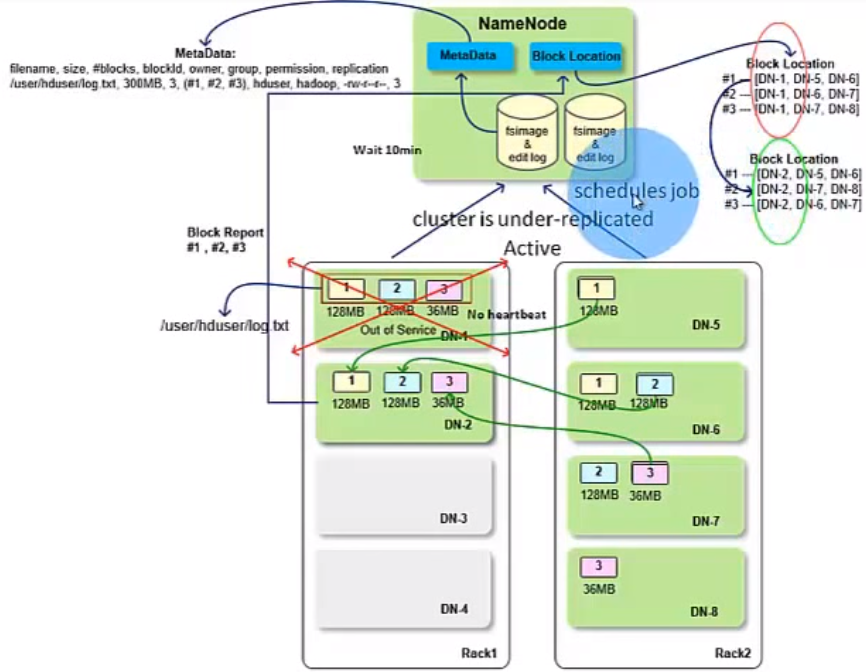
As we know, HDFS is reliable. If a data node goes down(NN does not receive its heart beat within 10 mins), there must be other data nodes storing the copies of the blocks in the failed data node depending on the replication level. So, the system is still available. But in this situation, the cluster is unser-replicated, and NN will schedule MR jobs to write the blocks to available data nodes to meet the replication level. When the data node(s) will send block report to NN , the block location will be updated accordingly.
Trade off among reliability, performance/network bandwidth
If you want to gain more reliability, for example, make the replication level to a big value (5?), the write operation will be very expensive(it not only involes writing data to disk of multiple data nodes but also count in tranferring data across data nodes so the performance is low) and vice versa.
HADOOP/HDFS Essay的更多相关文章
- Hadoop HDFS 用户指南
This document is a starting point for users working with Hadoop Distributed File System (HDFS) eithe ...
- Hadoop HDFS负载均衡
Hadoop HDFS负载均衡 转载请注明出处:http://www.cnblogs.com/BYRans/ Hadoop HDFS Hadoop 分布式文件系统(Hadoop Distributed ...
- Hive:org.apache.hadoop.hdfs.protocol.NSQuotaExceededException: The NameSpace quota (directories and files) of directory /mydir is exceeded: quota=100000 file count=100001
集群中遇到了文件个数超出限制的错误: 0)昨天晚上spark 任务突然抛出了异常:org.apache.hadoop.hdfs.protocol.NSQuotaExceededException: T ...
- Hadoop程序运行中的Error(1)-Error: org.apache.hadoop.hdfs.BlockMissingException
15/03/18 09:59:21 INFO mapreduce.Job: Task Id : attempt_1426641074924_0002_m_000000_2, Status : FAIL ...
- Hadoop HDFS编程 API入门系列之HDFS_HA(五)
不多说,直接上代码. 代码 package zhouls.bigdata.myWholeHadoop.HDFS.hdfs3; import java.io.FileInputStream;import ...
- Hadoop HDFS编程 API入门系列之简单综合版本1(四)
不多说,直接上代码. 代码 package zhouls.bigdata.myWholeHadoop.HDFS.hdfs4; import java.io.IOException; import ja ...
- [转]hadoop hdfs常用命令
FROM : http://www.2cto.com/database/201303/198460.html hadoop hdfs常用命令 hadoop常用命令: hadoop fs 查看H ...
- org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory /user/hive/warehouse/page_view. Name node is in safe mode
FAILED: Error in metadata: MetaException(message:Got exception: org.apache.hadoop.ipc.RemoteExceptio ...
- Hadoop HDFS文件常用操作及注意事项
Hadoop HDFS文件常用操作及注意事项 1.Copy a file from the local file system to HDFS The srcFile variable needs t ...
随机推荐
- GoBelieve IM 服务端编译
#部署im1. 安装go编译环境参考链接:https://golang.org/doc/install 2. 下载im_service代码 cd $GOPATH/src/github.com/GoBe ...
- (二、下) springBoot 、maven 、mysql、 mybatis、 通用Mapper、lombok 简单搭建例子 《附项目源码》
接着上篇文章中 继续前进. 一.在maven 的pom.xm中添加组件依赖, mybatis通用Mapper,及分页插件 1.mybatis通用Mapper <!-- mybatis通用Mapp ...
- ubuntu系统的软件包管理工具
ubuntu系统的软件包管理工具有两种,一种是离线管理,另一种是在线管理 1.离线管理 dpkg工具可以对本地存放的deb安装包进行安装,卸载,查看状态等. dpkg -i app_name_vers ...
- 也说java虚拟机
学习java的人如果不了解java虚拟机,那真是白学了. java为什么可以跨平台,就是因为虚拟机的作用,java虚拟机就相当于一个计算机,它有自己的内存结构,当java程序 ...
- table表单制作个人简历
应用table表单,编程个人简历表单,同时运用了跨行rowspan和跨列colspan. <!DOCTYPE html> <html> <head> <met ...
- CentOS7 LNMP+phpmyadmin环境搭建(一、虚拟机及centos7安装)
前一阵子配公司的服务器的时候,发现网上好多教程杂乱无章,然后便根据网上已有资料自己整理了一个lnmp环境的安装教程.因为懒,已经好久没写过博客了.趁着这次公司招新人,把之前整理的文档又整理了一次,顺便 ...
- IDELPHI是一个MIS系统初学者的乐园空间
DELPHI的长处之一是MIS系统,此空间介绍了MIS中种种问题,及使用DELPHI XE做的办法. 为什么选择DELPHI? DELPHI是开发效率很高的一个工具,但也许很多人都喜欢选择微软.NET ...
- Vue directive自定义指令+canvas实现H5图片压缩上传-Base64格式
前言 最近优化项目-手机拍照图片太大,回显速度比较慢,使用了vue的自定义指令实现H5压缩上传base64格式的图片 canvas自定义指令 Vue.directive("canvas&qu ...
- 利用谷歌浏览器断点调试js反向解析,解密
目标网站:https://www.aqistudy.cn/html/city_detail.html 点击按钮才会去后台请求数据, 第一步:将click打开, 第二步:找个后台请求数据的url h ...
- Python学习手册之类和继承
在上一篇文章中,我们介绍了 Python 的函数式编程,现在我们介绍 Python 的类和继承. 查看上一篇文章请点击:https://www.cnblogs.com/dustman/p/100106 ...