The Log: What every software engineer should know about real-time data's unifying abstraction
主要的思想,
将所有的系统都可以看作两部分,真正的数据log系统和各种各样的query engine
所有的一致性由log系统来保证,其他各种query engine不需要考虑一致性,安全性,只需要不停的从log系统来同步数据,如果数据丢失或crash可以从log系统replay来恢复
可以看出kafka系统在linkedin中的重要地位,不光是data aggregation,而是整个系统的核心
Part One: What Is a Log?
log定义
很简单的结构,最关键的属性是,append-only和有序性
A log is perhaps the simplest possible storage abstraction.
It is an append-only, totally-ordered sequence of records ordered by time.
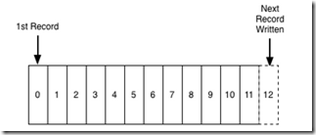
The ordering of records defines a notion of "time" since entries to the left are defined to be older then entries to the right.
The log entry number can be thought of as the "timestamp" of the entry. Describing this ordering as a notion of time seems a bit odd at first, but it has the convenient property that it is decoupled from any particular physical clock. This property will turn out to be essential as we get to distributed systems.
log和分布式系统有何关系
The answer is that logs have a specific purpose: they record what happened and when.
For distributed data systems this is, in many ways, the very heart of the problem.
和普通log的区别
Application log using syslog or log4j is unstructured error messages or trace info
The biggest difference is that text logs are meant to be primarily for humans to read and the "journal" or "data logs" I'm describing are built for programmatic access.
这里讨论的是广泛的log的概念,而日常我们常用到的应用log是它的特例,最大的区别是
日常的log是非结构化的,用于人阅读的,而我们讨论的log是结构化的可用于机器阅读的
Logs in databases
Logs最早用于db,用于保证ACID,渐渐的也被用于数据备份
The usage in databases has to do with keeping in sync the variety of data structures and indexes in the presence of crashes. To make this atomic and durable, a database uses a log to write out information about the records they will be modifying, before applying the changes to all the various data structures it maintains.
Over-time the usage of the log grew from an implementation detail of ACID to a method for replicating data between databases. It turns out that the sequence of changes that happened on the database is exactly what is needed to keep a remote replica database in sync.
Logs in distributed systems
分布式系统需要解决的核心问题就是一致性问题,即全序问题
在一样的初始状态下,执行相同顺序的指令序列,会得到相同的最终状态,这就保证了一致性
而log可以用于model这样的一致性问题,因为log决定了其中每个entry之间的全序关系
但解决分布式一致性问题,需要使用paxos协议,而算法结果可以用log来记录
State Machine Replication Principle:
If two identical, deterministic processes begin in the same state and get the same inputs in the same order, they will produce the same output and end in the same state.
The purpose of the log here is to squeeze all the non-determinism out of the input stream to ensure that each replica processing this input stays in sync.
The distributed log can be seen as the data structure which models the problem of consensus. A log, after all, represents a series of decisions on the "next" value to append. You have to squint a little to see a log in the Paxos family of algorithms, though log-building is their most common practical application.
There are a multitude of ways of applying this principle in systems depending on what is put in the log.
For example, we can log the incoming requests to a service, or the state changes the service undergoes in response to request, or the transformation commands it executes. Theoretically, we could even log a series of machine instructions for each replica to execute or the method name and arguments to invoke on each replica. As long as two processes process these inputs in the same way, the processes will remaining consistent across replicas.
使用log来备份分布式数据的方式有两种,
"state machine model" ,同步所有的request,优点传输数据小,缺点如果发生数据丢失或错误无法补救
"primary-backup model" ,直接同步最终数据,缺点传输数据大,优点是数据丢失没有关系,因为每次都会更新最新数据 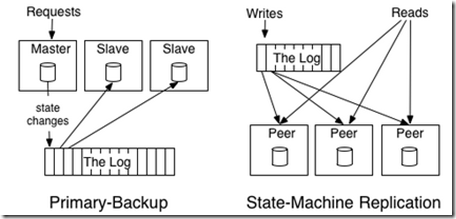
Changelog 101: Tables and Events are Dual
在DB使用中,既保留存储最终状态的tables,也保留反映中间过程的events(log)
这样不但可以简单的从初始状态replay出最终结果,而且也可以得到所有的中间结果
在这点上source control and databases很相似,因为他们都是需要管理分布式的并发更新
The magic of the log is that if it is a complete log of changes, it holds not only the contents of the final version of the table, but also allows recreating all other versions that might have existed. It is, effectively, a sort of backup of every previous state of the table.
This might remind you of source code version control. There is a close relationship between source control and databases. Version control solves a very similar problem to what distributed data systems have to solve—managing distributed, concurrent changes in state.
Part Two: Data Integration
什么是数据集成
"Data integration is making all the data an organization has available in all its services and systems."
This phrase "data integration" isn't all that common, but I don't know a better one. The more recognizable term ETL usually covers only a limited part of data integration—populating a relational data warehouse. But much of what I am describing can be thought of as ETL generalized to cover real-time systems and processing flows.
数据处理的几个步骤
1. capturing all the relevant data, being able to put it together, and modeled in a uniform way to make it easy to read and process
2. work on infrastructure to process this data in various ways—MapReduce, real-time query systems, etc with reliable and complete data flow
3. good data models and consistent well understood semantics
4. better visualization, reporting, and algorithmic processing and prediction
问题
大家往往忽略第二步中的reliable complete data flow,而直接跳到3, 4步,急功近利的表现
In my experience, most organizations have huge holes in the base of this pyramid—they lack reliable complete data flow—but want to jump directly to advanced data modeling techniques. This is completely backwards.
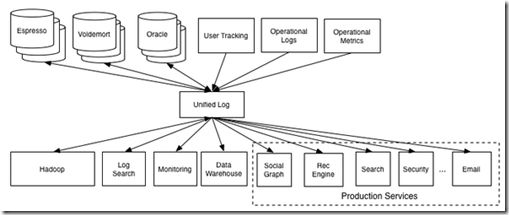
So the question is, how can we build reliable data flow throughout all the data systems in an organization? 答案是通过log系统
Log-structured data flow
The log is the natural data structure for handling data flow between systems. The recipe is very simple:
Take all the organization's data and put it into a central log for real-time subscription.
其实在linkedin中,就是基于Kafka系统,我们使用Kafka系统有2年时间,虽然也类似这样使用,但是对它的作用到此才理解的那么深刻
1. 首先用于子系统间的解耦合,每个子系统都只知道从cental log中异步的读写数据,而不需要知道其他的子系统
2. kafka系统作为中间的buffer,可以调节各个子系统之间的produce和consume速度上的差异,并且支持某些consumer crash后的replay
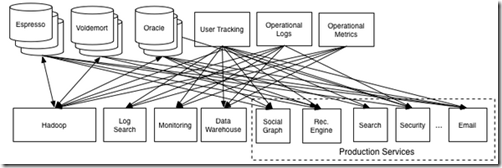
3. 所有数据都在Kafka上,使得数据集成工作变得非常有效,并可以实时的进行数据集成
在之前,数据集成工作是额外的工作,数据的产生者其实并不关心,所以也不愿意配合,工作很难做
但现在使用Kafka,所有的子系统间的数据交互都要通过这个central log来完成,所以把数据以通用的格式放到kafka中,是个必须的过程
从下面两幅图可以看出,有无central log system对系统架构和数据flow的影响
Relationship to ETL and the Data Warehouse
A data warehouse containing clean, integrated data is a phenomenal asset, but the mechanics of getting this are a bit out of date.
The key problem for a data-centric organization is coupling the clean integrated data to the data warehouse.
n my view, ETL is really two things. First, it is an extraction and data cleanup process—essentially liberating data locked up in a variety of systems in the organization and removing an system-specific non-sense. Secondly, that data is restructured for data warehousing queries
The clean, integrated repository of data should be available in real-time as well for low-latency processing as well as indexing in other real-time storage systems.
A better approach is to have a central pipeline, the log, with a well defined API for adding data. The responsibility of integrating with this pipeline and providing a clean, well-structured data feed lies with the producer of this data feed. This means that as part of their system design and implementation they must consider the problem of getting data out and into a well structured form for delivery to the central pipeline.
传统的数据仓库技术中,耦合了干净数据与数据仓库本身,干净的数据是很好的,但数据仓库技术有些out无法适应real-time和low-latency的需求
并且ETL和创建数据仓库是额外的工作,数据产生的team并不care,所以ETL和数据集成的工作量很大
提出使用central pipeline, the log, with a well defined API for adding data这样的架构来解决这个问题 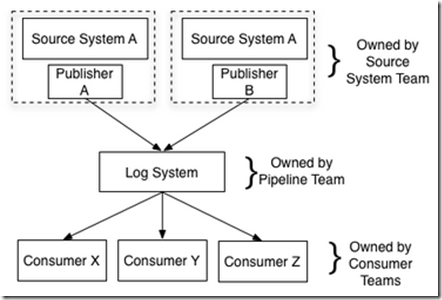
Log Files and Events
反复谈这种架构的好处,解耦合,事件驱动的系统
Let's talk a little bit about a side benefit of this architecture: it enables decoupled, event-driven systems.
At LinkedIn, we have built our event data handling in a log-centric fashion.
We are using Kafka as the central, multi-subscriber event log. We have defined several hundred event types, each capturing the unique attributes about a particular type of action. This covers everything from page views, ad impressions, and searches, to service invocations and application exceptions.
一个例子,在job page显示job posting,在原来的系统中,除了最简单的显示逻辑,还有很多附加的和其他系统交互的逻辑,如下
To understand the advantages of this, imagine a simple event—showing a job posting on the job page. The job page should contain only the logic required to display the job.
- We need to send this data to Hadoop and data warehouse for offline processing purposes
- We need to count the view to ensure that the viewer is not attempting some kind of content scraping
- We need to aggregate this view for display in the Job poster's analytics page
- We need to record the view to ensure we properly impression cap any job recommendations for that user (we don't want to show the same thing over and over)
- Our recommendation system may need to record the view to correctly track the popularity of that job
- Etc
明显这是非常糟糕的设计,代码会变得很难维护,在基于kafka的系统中,只需要显示job posting,并发布一条event,所有其他系统都通过subscribe来进行他们自己的操作
The "event-driven" style provides an approach to simplifying this. The job display page now just shows a job and records the fact that a job was shown along with the relevant attributes of the job, the viewer, and any other useful facts about the display of the job. Each of the other interested systems—the recommendation system, the security system, the job poster analytics system, and the data warehouse—all just subscribe to the feed and do their processing. The display code need not be aware of these other systems, and needn't be changed if a new data consumer is added.
Part Three: Logs & Real-time Stream Processing
So far, I have only described what amounts to a fancy method of copying data from place-to-place. But shlepping bytes between storage systems is not the end of the story. It turns out that "log" is another word for "stream" and logs are at the heart of stream processing.
什么是Stream processing?
Stream processing has nothing to do with SQL. Nor is it limited to real-time processing.
I see stream processing as something much broader: infrastructure for continuous data processing. I think the computational model can be as general as MapReduce or other distributed processing frameworks, but with the ability to produce low-latency results.
持续的数据处理,并产生低延迟的结果
产生Stream processing 的动机
The real driver for the processing model is the method of data collection. Data which is collected in batch is naturally processed in batch. When data is collected continuously, it is naturally processed continuously.
数据收集的方式,传统方式由于工具的落后,数据往往是定期批量收集的,比如人口普查数据,那么批量的收集当然就需要批量的处理
LinkedIn, for example, has almost no batch data collection at all. The majority of our data is either activity data or database changes, both of which occur continuously. In fact, when you think about any business, the underlying mechanics are almost always a continuous process—events happen in real-time, as Jack Bauer would tell us. When data is collected in batches, it is almost always due to some manual step or lack of digitization or is a historical relic left over from the automation of some non-digital process. Transmitting and reacting to data used to be very slow when the mechanics were mail and humans did the processing.
时代在进步,随着数字化和自动化的发展,数据的收集越来越流化,而非批量化,所以基于stream的处理方法有了很强的动机
比如Linkedin几乎没有用批量的方式来收集数据,而都是以流的方式进行持续收集
It turns out that the log solves some of the most critical technical problems in stream processing, which I'll describe, but the biggest problem that it solves is just making data available in real-time multi-subscriber data feeds.
Data flow graphs
当然在stream process中,log最重要的作用仍然是作为data flow infrastructure
The purpose of the log in the integration is two-fold.
First, it makes each dataset multi-subscriber and ordered.
Second, the log provides buffering to the processes. 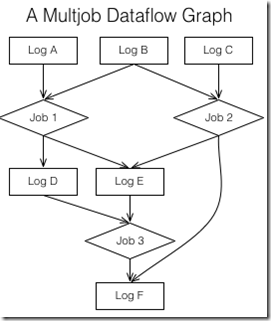
Stateful Real-Time Processing
其次log可用于维护stream processing中的中间状态
Some real-time stream processing is just stateless record-at-a-time transformation, but many of the uses are more sophisticated counts, aggregations, or joins over windows in the stream.
比如count或join,这样的比较复杂的流操作需要维持一些状态
this kind of processing ends up requiring some kind of state to be maintained by the processor: for example, when computing a count, you have the count so far to maintain. How can this kind of state be maintained correctly if the processors themselves can fail?
The simplest alternative would be to keep state in memory. However if the process crashed it would lose its intermediate state.
An alternative is to simply store all state in a remote storage system and join over the network to that store. The problem with this is that there is no locality of data and lots of network round-trips.
这些中间状态放在memory中,crash时会丢失,如果放在remote storage,明显效率上有问题
这里的方案是,把这些中间状态放在local的table中,并且用changelog记录local table的历史记录
A stream processor can keep it's state in a local "table" or "index"—a bdb, leveldb, or even something more unusual such as a Lucene or fastbit index. The contents of this this store is fed from its input streams (after first perhaps applying arbitrary transformation). It can journal out a changelog for this local index it keeps to allow it to restore its state in the event of a crash and restart. This mechanism allows a generic mechanism for keeping co-partitioned state in arbitrary index types local with the incoming stream data.
Part Four: System Building
The final topic I want to discuss is the role of the log in data system design for online data systems.
Unbundling?
这个观点很特别,可以将整个organization中的系统看做是一个单个的distributed database,其中所有的query-oriented systems (Redis, SOLR, Hive tables, and so on)只是数据的各种indexes,而stream processing systems like Storm or Samza只是一些trigger或view工具
You can see the whole of your organization's systems and data flows as a single distributed database. You can view all the individual query-oriented systems (Redis, SOLR, Hive tables, and so on) as just particular indexes on your data. You can view the stream processing systems like Storm or Samza as just a very well-developed trigger and view materialization mechanism.
当前各种数据系统爆炸式的出现,之所以这样是因为搭建分布式系统过于复杂,无法用一个系统handle所有的case,所以不同的系统都是focus在某一场景下
所以大数据中不存在one answer fits all的情况,所有的data system都是在balance和取舍
There is undeniably now an explosion of types of data systems, but in reality, this complexity has always existed.
There are many motivations for segregating data into multiple systems: scale, geography, security, and performance isolation are the most common.
My take is that the explosion of different systems is caused by the difficulty of building distributed data systems.
那么未来的情况会怎么样?
1.大量的data system会继续存在下去,那么log系统用于数据集成将变的非常重要
2.出现一个大而全的系统,这个可能性不大
3.这种情况更为现实和有吸引力,几乎所有的data system都是开源的,所以我们可以搭lego玩具一样,使用不同的开源系统,根据自己的需求搭出自己的分布式系统
I see three possible directions this could follow in the future.
The first possibility is a continuation of the status quo: the separation of systems remains more or less as it is for a good deal longer. In this case, an external log that integrates data will be very important.
The second possibility is that there could be a re-consolidation in which a single system with enough generality starts to merge back in all the different functions into a single uber-system. I think the practical difficulties of building such a system make this unlikely
Open source allows another possibility: data infrastructure could be unbundled into a collection of services and application-facing system apis. You already see this happening to a certain extent in the Java stack:
- Zookeeper handles much of the system co-ordination (perhaps with a bit of help from higher-level abstractions like Helix or Curator).
- Mesos and YARN do process virtualization and resource management
- Embedded libraries like Lucene and LevelDB do indexing
- Netty, Jetty and higher-level wrappers like Finagle and rest.li handle remote communication
- Avro, Protocol Buffers, Thrift, and umpteen zillion other libraries handle serialization
- Kafka and Bookeeper provide a backing log.
It starts to look a bit like a lego version of distributed data system engineering. You can piece these ingredients together to create a vast array of possible systems. If the implementation time for a distributed system goes from years to weeks because reliable, flexible building blocks emerge, then the pressure to coalesce into a single monolithic system disappears.
The place of the log in system architecture
其实无论未来怎么发展,log系统都会发挥重要的作用
A system that assumes an external log is present allows the individual systems to relinquish a lot of their own complexity and rely on the shared log. Here are the things I think a log can do:
- Handle data consistency (whether eventual or immediate) by sequencing concurrent updates to nodes
- Provide data replication between nodes
- Provide "commit" semantics to the writer (i.e. acknowledging only when your write guaranteed not to be lost)
- Provide the external data subscription feed from the system
- Provide the capability to restore failed replicas that lost their data or bootstrap new replicas
- Handle rebalancing of data between nodes.
系统分为两部分,log和service层
所有的write都先写到log上,由log来保证数据的一致性,可以想象成kafka系统收集各种更新
serving layer存储了各种的index,index从log subscribe更新并同步indexes
最终client以read-your-write semantics从services node读取数据
Here is how this works. The system is divided into two logical pieces: the log and the serving layer.
The log captures the state changes in sequential order.
The serving nodes store whatever index is required to serve queries (for example a key-value store might have something like a btree or sstable, a search system would have an inverted index).The serving nodes subscribe to the log and apply writes as quickly as possible to its local index in the order the log has stored them.
The client can get read-your-write semantics from any node by providing the timestamp of a write as part of its query—a serving node receiving such a query will compare the desired timestamp to its own index point and if necessary delay the request until it has indexed up to at least that time to avoid serving stale data.
the serving nodes can be completely without leaders, since the log is the source of truth.
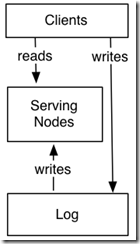
By having this log system, you get a fully developed subscription API for the contents of the data store which feeds ETL into other systems. In fact, many systems can share the same the log while providing different indexes, like this:
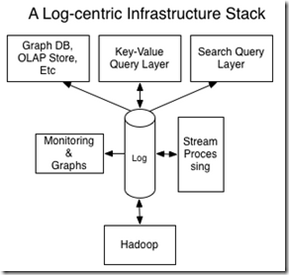
I find this view of systems as factored into a log and query api to very revealing, as it lets you separate the query characteristics from the availability and consistency aspects of the system.
有人觉得,单独保存一份log数据很浪费,其实不然
The idea of having a separate copy of data in the log (especially if it is a complete copy) strikes many people as wasteful.
First, the log can be a particularly efficient storage mechanism. We store up to 5TB on our production Kafka servers.
The serving system may also use optimized hardware. In contrast, the log system just using large multi-TB hard drives.
Finally, as in the picture above, in the case where the data is served by multiple systems, the cost of the log is amortized over multiple indexes.
The Log: What every software engineer should know about real-time data's unifying abstraction的更多相关文章
- Software Engineer Title Ladder
http://changelog.ca/log/2013/08/09/software_engineer_title_ladder Within the software engineering pr ...
- Software Engineer
1, 软件工程师 软件工程师英文是Software Engineer,是从事软件职业的人员的一种职业能力的认证,通过它说明具备了工程师的资格.软件工程师是从事软件开发相关工作的人员的统称. 它是一个广 ...
- 微软职位内部推荐-Software Engineer II-Web app
微软近期Open的职位: The Office App Services team is working on the powerful Office Web Apps including Word ...
- 微软职位内部推荐-Senior Software Engineer -Web
微软近期Open的职位: Location: Beijing, China The Office App Services team is working on the powerful Office ...
- Sr Software Engineer - Big Data Team
Sr Software Engineer - Big Data Team About UberWe’re changing the way people think about transport ...
- Security Software Engineer
Security Software Engineer Are you excited to be part of the VR revolution and work on cutting edge ...
- 微软职位内部推荐-Software Engineer
微软近期Open的职位: Job Title: Software Engineer Work Location: Suzhou, China This is a once in a lifetime ...
- 微软职位内部推荐-Software Engineer II-Senior Software Engineer for Satori
微软近期Open的职位: Title: Software Engineer II-Senior Software Engineer for Satori, STC Location: Beijing ...
- 微软职位内部推荐-Software Engineer II_VS
微软近期Open的职位: Job Title: Software Engineer II Division: Visual Studio China – Developer Division Work ...
随机推荐
- 基于Verilog语言的FIR滤波【程序和理解】
一直想找一个简单.清晰.明了的fir滤波器的设计,终于找到了一个可以应用的,和大家分享一下,有助于FPGA新手入门. 1.说道fir滤波器,滤波系数肯定是最重要的,因为后面程序中涉及到滤波系数问题,所 ...
- nginx vhosts rewrite 独立文件的方式出现
[root@web01 /]# cat /app/server/nginx/conf/nginx.conf user www www; worker_processes ; error_log /ap ...
- makefile之变量
1 变量的定义 A variable is a name defined in a makefile to represent a string of text, called the variabl ...
- docker动态添加磁盘
docker run --rm -v /usr/local/bin:/target jpetazzo/nsenter #!/bin/bash #This script is dynamic mount ...
- 在Windows下使用nmake+Makefile+编译ZThread库(附例子)
----------2015/01/09/23:21更新----------------------------------- 关于保留DEBUG信息的一个简单例子,见这篇随笔 ----------2 ...
- PYTHON中 赋值运算的若干问题总结
1.PYTHON中没有自增自减操作(++,——): 因为PYTHON中对于字符.数值等不可变的对象来说,自增自减没有意义. 2.PYTHON中l连接操作总是创建一个新对象. 举例: L=[1,2] M ...
- STM32F4_TIM输入波形捕获(脉冲频率、占空比)
推荐 分享一个大神的人工智能教程.零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到人工智能的队伍中来! http://www.captainbed.net/strongerhuang Ⅰ.概述 ...
- 清空oracle数据库
在开发过程中,可能经常需要重新初始化数据库,在初始化之前,我们肯定希望不再有以前的老表.存储过程等用户对象,用下面的教本就可以做到这一点: BEGIN FOR rec IN (SELECT objec ...
- java:eclipse-tomcat 配置
计划开始学习java.第一步 1.在servers窗口中新建server 2.弹出的界面选择对应的tomcat版本 3.这里是关键,已存在的项目不要选择过去,否则最后生成的server配置无法修改se ...
- calico性能测试
硬件环境: 三台虚拟机: 192.168.99.129 master(kube-apiserver.kube-controller-manager.kube-proxy.kube-scheduler. ...