c json实战引擎四 , 最后❤跳跃
引言 - 以前那些系列
长活短说, 写的最终 scjson 纯c跨平台引擎, 希望在合适场景中替代老的csjon引擎, 速度更快, 更轻巧.
下面也是算一个系列吧. 从cjson 中得到灵感, 外加上很久以前自己写的json引擎. 具体的可以看看下面链接.
代码也许有点乱, 但是相信你看 cjson那个源码, 那就更乱了. 有些代码不讲道理, 好吃的东西都得让你难受一下. 才有转折.
本文是为了scjson 手写引擎添加注释解析功能. 再在跨平台上再做一些修改, 最终给出完整的测试demo.
c json实战引擎四 , 最后❤跳跃 (这就是程序语言设计中自举例子)
本文最终的资源 test_scjson.zip
前言 - 那就从json文件看起
先看我们需要处理的 goods.json 文件
- [
- /*
- * 物品定义处:
- * 物品名,品质,作用值,加血,加魔,加攻击,加防御,加速度,加幸运,价格,\
- * 占用包裹,加暴击,拥有量,最大拥有,可买(1可买,0不可买),可卖(1可卖, 0不可买)
- */
- ["小灵芝", "低级★", 1, 50, 0, 0, 0, 0, 0, 20, 1, 0, 3, 99, 1, 1],
- ["中灵芝", "中级★★", 1, 100, 0, 0, 0, 0, 0, 40, 2, 0, 1, 99, 1, 1],
- ["大灵芝", "高级★★★", 1, 200, 0, 0, 0, 0, 0, 80, 3, 0, 1, 99, 1, 1],
- ["卤肉 ", "初级★", 1, 80, 0, 0, 0, 0, 0, 30, 1, 0, 0, 99, 1, 0],
- ["小鸭脖", "初级★", 1, 100, 0, 0, 0, 0, 0, 35, 1, 0, 5, 99, 1, 1],
- ["小蓝瓶", "初级★", 1, 0, 50, 0, 0, 0, 0, 20, 1, 0, 0, 99, 1, 1],
- ["中蓝瓶", "中级★★", 1, 0, 100, 0, 0, 0, 0, 40, 2, 0, 0, 99, 1, 1],
- ["大蓝瓶", "高级★★★", 1, 0, 200, 0, 0, 0, 0, 80, 3, 0, 1, 99, 1, 1],
- ["金鳌 ", "高级★★★", 3, 0, 0, 5, 0, 0, 0, 200, 2, 0, 2, 99, 1, 1],
- ["野山椒", "中级★★", 3, 0, 0, 2, 0, 0, 0, 80, 2, 0, 1, 99, 1, 1],
- ["巨蜥肉", "高级★★★", 3, 0, 0, 0, 10, 0, 0, 100, 3, 0, 1, 99, 1, 1],
- ["龙血 ", "神级★★★★★", 3, 300, 100, 2, 2, 2, 0, 600, 5, 0, 1, 99, 0, 0],
- ["龙肉 ", "神级★★★★★", 3, 0, 0, 10, 20, 10, 0, 800, 5, 0, 1, 99, 0, 0],
- ["木剑 ", "初级★", 2, 0, 0, 10, 0, 0, 0, 50, 1, 0, 1, 1, 0, 0],
- ["木衣 ", "初级★", 2, 0, 0, 0, 10, 0, 0, 50, 1, 0, 1, 1, 0, 0],
- ["木鞋 ", "初级★", 2, 0, 0, 0, 0, 10, 0, 50, 1, 0, 1, 1, 0, 0],
- ["屠龙剑", "神级★★★★★", 2, 0, 0, 100, 0, 0, 0, 10000, 0, 0, 0, 1, 1, 1],
- ["龙皮铠甲", "神级★★★★★", 2, 0, 0, 0, 200, 0, 0, 10000, 0, 0, 0, 1, 1, 1],
- ["涅槃丹", "神级★★★★", 3, 100, 100, 100, 100, 20, 10, 5000, 1, 1, 0, 1, 1, 1]
- ]
扯一点我是用notepad++ 编辑的, 请安装 JsTool 插件处理json很好用
切入正题我们处理思路是, 在文件读取的时候, 去掉无效字符和注释字符. 主要code思路如下
- // 从json文件中解析出最简json数据
- static tstr_t _cjson_newfile(const char * path) {
- char c, n;
- tstr_t tstr;
- FILE * txt = fopen(path, "r");
- if (NULL == txt) {
- CERR("fopen r %s is error!", path);
- return NULL;
- }
- //这里创建文本串对象
- tstr = tstr_new(NULL);
- while ((c = fgetc(txt)) != EOF) {
- // step 1 : 处理字符串
- if (c == '"') {
- tstr_append(tstr, c);
- for (n = c; ((c = fgetc(txt)) != EOF) && (c != '"' || n == '\\'); n = c)
- tstr_append(tstr, c);
- if (EOF != c)
- tstr_append(tstr, c);
- continue;
- }
- // step 2 : 处理不可见特殊字符
- if (c < '!')
- continue;
- if (c == '/') {
- // step 3 : 处理 // 解析到行末尾
- n = fgetc(txt);
- if (n == '/') {
- while ((c = fgetc(txt)) != EOF && c != '\n')
- ;
- continue;
- }
- // step 4 : 处理 /*
- if (n == '*') {
- while ((c = fgetc(txt)) != EOF) {
- if (c == '*') {
- n = fgetc(txt);
- if (n == '/')
- break;
- ungetc(n, txt);
- }
- }
- continue;
- }
- ungetc(n, txt);
- }
- // step 5 : 合法数据直接保存
- tstr_append(tstr, c);
- }
- fclose(txt);//很重要创建了就要释放,否则会出现隐藏的句柄bug
- return tstr;
- }
(请原谅, 这种一言不合就上源码的套路.) 主要分5类
1. "" 字符串, 不处理直接放入
2. 1-32 空字符直接舍弃, ['!' == 33, 可以查看ascii表]
3. // 注释直接 舍弃到 \n, 行尾
4. /* 舍弃到 */ 为止
5. 合法字符直接放入
附注ascii码表如下

挺不错的, 可以自行查查.
同样对于json内存串也是采用相同的处理思路
- /*
- * 将 jstr中 不需要解析的字符串都去掉,并且纪念mini 比男的还平
- * jstr : 待处理的json串
- * : 返回压缩后的json串长度
- */
- static int _cjson_mini(char * jstr) {
- char c, *in = jstr, *to = jstr;
- while ((c = *to)) {
- // step 1 : 处理字符串
- if (c == '"') {
- *in++ = c;
- while ((c = *++to) && (c != '"' || to[-] == '\\'))
- *in++ = c;
- if (c) {
- *in++ = c;
- ++to;
- }
- continue;
- }
- // step 2 : 处理不可见特殊字符
- if (c < '!') {
- ++to;
- continue;
- }
- if (c == '/') {
- // step 3 : 处理 // 解析到行末尾
- if (to[] == '/') {
- while ((c = *++to) && c != '\n')
- ;
- continue;
- }
- // step 4 : 处理 /*
- if (to[] == '*') {
- while ((c = *++to) && (c != '*' || to[] != '/'))
- ;
- if (c)
- to += ;
- continue;
- }
- }
- // step 5 : 合法数据直接保存
- *in++ = *to++;
- }
- *in = '\0';
- return in - jstr;
- }
到这里我们就为这个json引擎, 添加上了json注释功能了, 下面会搭建测试环境.
正文 - 测试环境搭建
跨平台的 scjson引擎[simple c json] , 跨平台的, 采用 Ubuntu linux 搭建一下. window上更好搞. 首先得到所有文件附在下面
schead.h
- #ifndef _H_SIMPLEC_SCHEAD
- #define _H_SIMPLEC_SCHEAD
- #include <stdio.h>
- #include <errno.h>
- #include <string.h>
- #include <stdint.h>
- #include <stddef.h>
- #include <assert.h>
- #include <stdbool.h>
- #include <scalloc.h>
- /*
- * error => 以后再说
- * 跨平台的丑陋从这里开始
- * __GNUC => linux 平台特殊操作
- * __MSC_VER => window 平台特殊操作
- */
- #ifdef __GNUC__ // 下面是依赖GCC编译器实现
- #include <unistd.h>
- #include <sys/time.h>
- #include <termio.h>
- // 统一的程序睡眠宏, 单位是毫秒颗粒度
- #define SLEEPMS(m) \
- usleep(m * )
- // 屏幕清除宏, 依赖系统脚本
- #define CONSOLECLS() \
- system("printf '\ec'")
- /*
- * 得到用户输入的一个字符
- * : 返回得到字符
- */
- extern int sh_getch(void);
- #elif _MSC_VER // 下面是依赖Visual Studio编译器实现
- #include <Windows.h>
- #include <direct.h>
- #include <conio.h>
- // window 删除目录宏
- #define rmdir _rmdir
- // window 上用_getch 替代了getch, 这里为了让其回来
- #define sh_getch _getch
- #define CONSOLECLS() \
- system("cls")
- #define SLEEPMS(m) \
- Sleep(m)
- #else
- #error "error : Currently only supports the Visual Studio and GCC!"
- #endif
- /*
- * 错误定义枚举 用于判断返回值状态的状态码 RT_*表示返回标志
- * 使用举例 :
- int flag = scconf_get("pursue");
- if(flag < RT_SuccessBase) {
- sclog_error("get config %s error! flag = %d.", "pursue", flag);
- exit(EXIT_FAILURE);
- }
- * 这里是内部 使用的通用返回值 标志. >=0 表示成功, <0 表示失败的情况
- */
- typedef enum {
- RT_SuccessBase = , //结果正确的返回宏
- RT_ErrorBase = -, //错误基类型, 所有错误都可用它, 在不清楚的情况下
- RT_ErrorParam = -, //调用的参数错误
- RT_ErrorMalloc = -, //内存分配错误
- RT_ErrorFopen = -, //文件打开失败
- RT_ErrorClose = -, //文件描述符读取关闭, 读取完毕也会返回这个
- } flag_e;
- /*
- * 定义一些通用的函数指针帮助,主要用于基库的封装中
- * 有构造函数, 释放函数, 比较函数等
- */
- typedef void * (* pnew_f)();
- typedef void (* vdel_f)(void * node);
- // icmp_f 最好 是 int cmp(const void * ln, const void * rn); 标准结构
- typedef int (* icmp_f)();
- // 循环操作函数, arg 外部参数, node 内部节点
- typedef flag_e (* each_f)(void * node, void * arg);
- /*
- * c 如果是空白字符返回 true, 否则返回false
- * c : 必须是 int 值,最好是 char 范围
- */
- #define sh_isspace(c) \
- ((c==' ')||(c>='\t'&&c<='\r'))
- // 3.0 浮点数据判断宏帮助, __开头表示不希望你使用的宏
- #define __DIFF(x, y) ((x)-(y)) //两个表达式做差宏
- #define __IF_X(x, z) ((x)<z && (x)>-z) //判断宏,z必须是宏常量
- #define EQ(x, y, c) EQ_ZERO(__DIFF(x,y), c) //判断x和y是否在误差范围内相等
- // 3.1 float判断定义的宏
- #define _FLOAT_ZERO (0.000001f) //float 0的误差判断值
- #define EQ_FLOAT_ZERO(x) __IF_X(x, _FLOAT_ZERO) //float 判断x是否为零是返回true
- #define EQ_FLOAT(x, y) EQ(x, y, _FLOAT_ZERO) //判断表达式x与y是否相等
- // 3.2 double判断定义的宏
- #define _DOUBLE_ZERO (0.000000000001) //double 0误差判断值
- #define EQ_DOUBLE_ZERO(x) __IF_X(x, _DOUBLE_ZERO) //double 判断x是否为零是返回true
- #define EQ_DOUBLE(x,y) EQ(x, y, _DOUBLE_ZERO) //判断表达式x与y是否相等
- // 4.0 控制台打印错误信息, fmt必须是双引号括起来的宏
- #ifndef CERR
- #define CERR(fmt, ...) \
- fprintf(stderr,"[%s:%s:%d][error %d:%s]" fmt "\n",\
- __FILE__, __func__, __LINE__, errno, strerror(errno), ##__VA_ARGS__)
- #endif // !CERR
- // 4.1 控制台打印错误信息并退出, t同样fmt必须是 ""括起来的字符串常量
- #ifndef CERR_EXIT
- #define CERR_EXIT(fmt,...) \
- CERR(fmt, ##__VA_ARGS__),exit(EXIT_FAILURE)
- #endif // !CERR_EXIT
- // 4.2 执行后检测,如果有错误直接退出
- #ifndef IF_CHECK
- #define IF_CHECK(code) \
- if((code) < ) \
- CERR_EXIT(#code)
- #endif // !IF_CHECK
- // 5.0 获取数组长度,只能是数组类型或""字符串常量,后者包含'\0'
- #ifndef LEN
- #define LEN(arr) \
- (sizeof(arr) / sizeof(*(arr)))
- #endif/* !ARRLEN */
- // 7.0 置空操作
- #ifndef BZERO
- // v必须是个变量
- #define BZERO(v) \
- memset(&(v), , sizeof(v))
- #endif/* !BZERO */
- // 9.0 scanf 健壮的
- #ifndef SAFETY_SCANF
- #define _STR_SAFETY_SCANF "Input error, please according to the prompt!"
- #define SAFETY_SCANF(scanf_code, ...) \
- while(printf(__VA_ARGS__), scanf_code){\
- while('\n' != getchar()) \
- ;\
- puts(_STR_SAFETY_SCANF);\
- }\
- while('\n' != getchar())
- #endif /*!SAFETY_SCANF*/
- // 简单的time帮助宏
- #ifndef TIME_PRINT
- #define _STR_TIME_PRINT "The current code block running time:%lf seconds\n"
- #define TIME_PRINT(code) \
- do{\
- clock_t __st, __et;\
- __st=clock();\
- code\
- __et=clock();\
- printf(_STR_TIME_PRINT, (0.0 + __et - __st) / CLOCKS_PER_SEC);\
- } while()
- #endif // !TIME_PRINT
- /*
- * 10.0 这里是一个 在 DEBUG 模式下的测试宏
- *
- * 用法 :
- * DEBUG_CODE({
- * puts("debug start...");
- * });
- */
- #ifndef DEBUG_CODE
- # ifdef _DEBUG
- # define DEBUG_CODE(code) code
- # else
- # define DEBUG_CODE(code)
- # endif // ! _DEBUG
- #endif // ! DEBUG_CODE
- //11.0 等待的宏 是个单线程没有加锁 | "请按任意键继续. . ."
- #define _STR_PAUSEMSG "Press any key to continue . . ."
- extern void sh_pause(void);
- #ifndef INIT_PAUSE
- # ifdef _DEBUG
- # define INIT_PAUSE() atexit(sh_pause)
- # else
- # define INIT_PAUSE() /* 别说了,都重新开始吧 */
- # endif
- #endif // !INIT_PAUSE
- //12.0 判断是大端序还是小端序,大端序返回true
- extern bool sh_isbig(void);
- /**
- * sh_free - 简单的释放内存函数,对free再封装了一下
- **可以避免野指针
- **pobj:指向待释放内存的指针(void*)
- **/
- extern void sh_free(void ** pobj);
- /*
- * 比较两个结构体栈上内容是否相等,相等返回true,不等返回false
- * a : 第一个结构体值
- * b : 第二个结构体值
- * : 相等返回true, 否则false
- */
- #define STRUCTCMP(a, b) \
- (!memcmp(&a, &b, sizeof(a)))
- #endif// ! _H_SIMPLEC_SCHEAD
schead.c
- #include <schead.h>
- //简单通用的等待函数
- inline void
- sh_pause(void) {
- rewind(stdin);
- printf(_STR_PAUSEMSG);
- sh_getch();
- }
- //12.0 判断是大端序还是小端序,大端序返回true
- inline bool
- sh_isbig(void) {
- static union {
- unsigned short _s;
- unsigned char _c;
- } __u = { };
- return __u._c == ;
- }
- /**
- * sh_free - 简单的释放内存函数,对free再封装了一下
- **可以避免野指针
- **@pobj:指向待释放内存的指针(void*)
- **/
- void
- sh_free(void ** pobj) {
- if (pobj == NULL || *pobj == NULL)
- return;
- free(*pobj);
- *pobj = NULL;
- }
- // 为linux扩展一些功能
- #if defined(__GNUC__)
- /*
- * 得到用户输入的一个字符
- * : 返回得到字符
- */
- int
- sh_getch(void) {
- int cr;
- struct termios nts, ots;
- if (tcgetattr(, &ots) < ) // 得到当前终端(0表示标准输入)的设置
- return EOF;
- nts = ots;
- cfmakeraw(&nts); // 设置终端为Raw原始模式,该模式下所有的输入数据以字节为单位被处理
- if (tcsetattr(, TCSANOW, &nts) < ) // 设置上更改之后的设置
- return EOF;
- cr = getchar();
- if (tcsetattr(, TCSANOW, &ots) < ) // 设置还原成老的模式
- return EOF;
- return cr;
- }
- #endif
scalloc.h
- #ifndef _H_SIMPLEC_SCALLOC
- #define _H_SIMPLEC_SCALLOC
- #include <stdlib.h>
- // 释放sm_malloc_和sm_realloc_申请的内存, 必须配套使用
- void sm_free_(void * ptr, const char * file, int line, const char * func);
- // 返回申请的一段干净的内存
- void * sm_malloc_(size_t sz, const char * file, int line, const char * func);
- // 返回重新申请的内存, 只能和sm_malloc_配套使用
- void * sm_realloc_(void * ptr, size_t sz, const char * file, int line, const char * func);
- /*
- * 释放申请的内存
- * ptr : 申请的内存
- */
- #define sm_free(ptr) sm_free_(ptr, __FILE__, __LINE__, __func__)
- /*
- * 返回申请的内存, 并且是填充'\0'
- * sz : 申请内存的长度
- */
- #define sm_malloc(sz) sm_malloc_(sz, __FILE__, __LINE__, __func__)
- /*
- * 返回申请到num*sz长度内存, 并且是填充'\0'
- * num : 申请的数量
- * sz : 申请内存的长度
- */
- #define sm_calloc(num, sz) sm_malloc_(num*sz, __FILE__, __LINE__, __func__)
- /*
- * 返回重新申请的内存
- * ptr : 申请的内存
- * sz : 申请内存的长度
- */
- #define sm_realloc(ptr, sz) sm_realloc_(ptr, sz, __FILE__, __LINE__, __func__)
- // 定义全局内存使用宏, 替换原有的malloc系列函数
- #ifndef _SIMPLEC_ALLOC_CLOSE
- # define free sm_free
- # define malloc sm_malloc
- # define calloc sm_calloc
- # define realloc sm_realloc
- #endif
- #endif // !_H_SIMPLEC_SCALLOC
scalloc.c
- #include <stdio.h>
- #include <stdlib.h>
- #include <string.h>
- // 标识枚举
- typedef enum {
- HF_Alloc,
- HF_Free
- } header_e;
- // 每次申请内存的[16-24]字节额外消耗, 用于记录内存申请情况
- struct header {
- header_e flag; // 当前内存使用的标识
- int line; // 申请的文件行
- const char * file; // 申请的文件名
- const char * func; // 申请的函数名
- };
- // 内部使用的malloc, 返回内存会用'\0'初始化
- void *
- sm_malloc_(size_t sz, const char * file, int line, const char * func) {
- struct header * ptr = malloc(sz + sizeof(struct header));
- // 检查内存分配的结果
- if(NULL == ptr) {
- fprintf(stderr, "_header_get >%s:%d:%s< alloc error not enough memory start fail!\n", file, line, func);
- exit(EXIT_FAILURE);
- }
- ptr->flag = HF_Alloc;
- ptr->line = line;
- ptr->file = file;
- ptr->func = func;
- memset(++ptr, , sz);
- return ptr;
- }
- // 得到申请内存的开头部分, 并检查
- static struct header * _header_get(void * ptr, const char * file, int line, const char * func) {
- struct header * node = (struct header *)ptr - ;
- // 正常情况直接返回
- if(HF_Alloc != node->flag) {
- // 异常情况, 内存多次释放, 和内存无效释放
- fprintf(stderr, "_header_get free invalid memony flag %d by >%s:%d:%s<\n", node->flag, file, line, func);
- exit(EXIT_FAILURE);
- }
- return node;
- }
- // 内部使用的realloc
- void *
- sm_realloc_(void * ptr, size_t sz, const char * file, int line, const char * func) {
- struct header * node , * buf;
- if(NULL == ptr)
- return sm_malloc_(sz, file, line, func);
- // 合理内存分割
- node = _header_get(ptr, file, line, func);
- node->flag = HF_Free;
- // 构造返回内存信息
- buf = realloc(node, sz + sizeof(struct header));
- buf->flag = HF_Alloc;
- buf->line = line;
- buf->file = file;
- buf->func = func;
- return buf + ;
- }
- // 内部使用的free, 每次释放都会打印日志信息
- void
- sm_free_(void * ptr, const char * file, int line, const char * func) {
- if(NULL != ptr) {
- // 得到内存地址, 并且标识一下, 开始释放
- struct header * node = _header_get(ptr, file, line, func);
- node->flag = HF_Free;
- free(node);
- }
- }
tstr.h
- #ifndef _H_SIMPLEC_TSTR
- #define _H_SIMPLEC_TSTR
- #include <schead.h>
- //------------------------------------------------简单字符串辅助操作----------------------------------
- /*
- * 主要采用jshash 返回计算后的hash值
- * 不冲突率在 80% 左右还可以, 不要传入NULL
- */
- extern unsigned tstr_hash(const char * str);
- /*
- * 这是个不区分大小写的比较函数
- * ls : 左边比较字符串
- * rs : 右边比较字符串
- * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
- */
- extern int tstr_icmp(const char * ls, const char * rs);
- /*
- * 这个代码是 对 strdup 的再实现, 调用之后需要free
- * str : 待复制的源码内容
- * : 返回 复制后的串内容
- */
- extern char * tstr_dup(const char * str);
- //------------------------------------------------简单文本字符串辅助操作----------------------------------
- #ifndef _STRUCT_TSTR
- #define _STRUCT_TSTR
- //简单字符串结构,并定义文本字符串类型tstring
- struct tstr {
- char * str; //字符串实际保存的内容
- int len; //当前字符串大小
- int size; //字符池大小
- };
- typedef struct tstr * tstr_t;
- #endif // !_STRUCT_TSTR
- //文本串栈上创建内容,不想用那些技巧了,就这样吧
- #define TSTR_NEW(var) \
- struct tstr $__##var = { NULL, , }, * var = &$__##var;
- #define TSTR_DELETE(var) \
- sm_free(var->str)
- /*
- * tstr_t 的创建函数, 会根据str创建一个 tstr_t 结构的字符串
- * str : 待创建的字符串
- * : 返回创建好的字符串,如果创建失败返回NULL
- */
- extern tstr_t tstr_new(const char * str);
- /*
- * tstr_t 析构函数
- * tstr : tstr_t字符串指针量
- */
- extern void tstr_delete(tstr_t tstr);
- /*
- * 向简单文本字符串tstr中添加 一个字符c
- * tstr : 简单字符串对象
- * c : 待添加的字符
- */
- extern void tstr_append(tstr_t tstr, int c);
- /*
- * 向简单文本串中添加只读字符串
- * tstr : 文本串
- * str : 待添加的素材串
- */
- extern void tstr_appends(tstr_t tstr, const char * str);
- /*
- * 复制tstr中内容,得到char *, 需要自己 free释放
- * 假如你要清空tstr_t字符串只需要 设置 len = 0.就可以了
- * tstr : 待分配的字符串
- * : 返回分配好的字符串首地址
- */
- extern char * tstr_dupstr(tstr_t tstr);
- //------------------------------------------------简单文件辅助操作----------------------------------
- /*
- * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL.
- * 需要事后使用 tstr_delete(ret); 销毁这个字符串对象
- * path : 文件路径
- * : 返回创建好的字符串内容,返回NULL表示读取失败
- */
- extern tstr_t tstr_file_readend(const char * path);
- /*
- * 文件写入,没有好说的, 会返回 RT_SuccessBase | RT_ErrorParam | RT_ErrorFopen
- * path : 文件路径
- * str : 待写入的字符串
- * : 返回操作的结果 见上面枚举
- */
- extern int tstr_file_writes(const char * path, const char * str);
- /*
- * 文件追加内容 会返回 RT_SuccessBase | RT_ErrorParam | RT_ErrorFopen
- * path : 文件路径
- * str : 待写入的字符串
- * : 返回操作的结果 见上面枚举
- */
- extern int tstr_file_append(const char * path, const char * str);
- #endif // !_H_SIMPLEC_TSTR
tstr.c
- #include <tstr.h>
- /*
- * 主要采用jshash 返回计算后的hash值
- * 不冲突率在 80% 左右还可以, 不要传入NULL
- */
- unsigned
- tstr_hash(const char * str) {
- unsigned i, h = (unsigned)strlen(str), sp = (h >> ) + ;
- unsigned char * ptr = (unsigned char *)str;
- for (i = h; i >= sp; i -= sp)
- h ^= ((h<<) + (h>>) + ptr[i-]);
- return h ? h : ;
- }
- /*
- * 这是个不区分大小写的比较函数
- * ls : 左边比较字符串
- * rs : 右边比较字符串
- * : 返回 ls>rs => >0 ; ls = rs => 0 ; ls<rs => <0
- */
- int
- tstr_icmp(const char * ls, const char * rs) {
- int l, r;
- if(!ls || !rs)
- return (int)(ls - rs);
- do {
- if((l=*ls++)>='a' && l<='z')
- l -= 'a' - 'A';
- if((r=*rs++)>='a' && r<='z')
- r -= 'a' - 'A';
- } while(l && l==r);
- return l - r;
- }
- /*
- * 这个代码是 对 strdup 的再实现, 调用之后需要free
- * str : 待复制的源码内容
- * : 返回 复制后的串内容
- */
- char *
- tstr_dup(const char * str)
- {
- size_t len;
- char * nstr;
- if (NULL == str)
- return NULL;
- len = sizeof(char) * (strlen(str) + );
- nstr = sm_malloc(len);
- // 返回最后结果
- return memcpy(nstr, str, len);
- }
- //------------------------------------------------简单文本字符串辅助操作----------------------------------
- /*
- * tstr_t 的创建函数, 会根据str创建一个 tstr_t 结构的字符串
- * str : 待创建的字符串
- * : 返回创建好的字符串,如果创建失败返回NULL
- */
- tstr_t
- tstr_new(const char * str) {
- tstr_t tstr = sm_malloc(sizeof(struct tstr));
- tstr_appends(tstr, str);
- return tstr;
- }
- /*
- * tstr_t 析构函数
- * tstr : tstr_t字符串指针量
- */
- inline void
- tstr_delete(tstr_t tstr) {
- if (tstr) {
- sm_free(tstr->str);
- sm_free(tstr);
- }
- }
- //文本字符串创建的度量值
- #define _INT_TSTRING (32)
- //简单分配函数,智力一定会分配内存的, len > size的时候调用这个函数
- static void _tstr_realloc(tstr_t tstr, int len)
- {
- int size = tstr->size;
- for (size = size < _INT_TSTRING ? _INT_TSTRING : size; size < len; size <<= )
- ;
- //分配内存
- tstr->str = sm_realloc(tstr->str, size);
- tstr->size = size;
- }
- /*
- * 向简单文本字符串tstr中添加 一个字符c
- * tstr : 简单字符串对象
- * c : 待添加的字符
- */
- void
- tstr_append(tstr_t tstr, int c) {
- //不做安全检查
- int len = tstr->len + + ; // c + '\0' 而len只指向 字符串strlen长度
- //需要的❀, 需要进行内存分配, 唯一损失
- if (len > tstr->size)
- _tstr_realloc(tstr, len);
- tstr->len = --len;
- tstr->str[len - ] = c;
- tstr->str[len] = '\0';
- }
- /*
- * 向简单文本串中添加只读字符串
- * tstr : 文本串
- * str : 待添加的素材串
- * : 返回状态码主要是 _RT_EP _RT_EM
- */
- void
- tstr_appends(tstr_t tstr, const char * str) {
- int len;
- if (!tstr || !str || !*str)
- return;
- // 检查内存是否需要重新构建
- len = tstr->len + (int)strlen(str) + ;
- if (len > tstr->size)
- _tstr_realloc(tstr, len);
- strcpy(tstr->str + tstr->len, str);
- tstr->len = len - ;
- }
- /*
- * 复制tstr中内容,得到char *, 需要自己 free释放
- * 假如你要清空tstr_t字符串只需要 设置 len = 0.就可以了
- * tstr : 待分配的字符串
- * : 返回分配好的字符串首地址
- */
- char *
- tstr_dupstr(tstr_t tstr) {
- char * str;
- if (!tstr || tstr->len <= )
- return NULL;
- //下面就可以复制了,采用最快的一种方式
- str = sm_malloc(tstr->len + );
- return memcpy(str, tstr->str, tstr->len + );
- }
- //------------------------------------------------简单文件辅助操作----------------------------------
- /*
- * 简单的文件帮助类,会读取完毕这个文件内容返回,失败返回NULL.
- * 需要事后使用 tstr_delete(ret); 销毁这个字符串对象
- * path : 文件路径
- * : 返回创建好的字符串内容,返回NULL表示读取失败
- */
- tstr_t
- tstr_file_readend(const char * path) {
- int c;
- tstr_t tstr;
- FILE * txt = fopen(path, "r");
- if (NULL == txt) {
- CERR("fopen r %s is error!", path);
- return NULL;
- }
- //这里创建文本串对象
- tstr = tstr_new(NULL);
- //这里读取文本内容
- while ((c = fgetc(txt)) != EOF)
- tstr_append(tstr, c);
- fclose(txt);//很重要创建了就要释放,否则会出现隐藏的句柄bug
- return tstr;
- }
- int _tstr_file_writes(const char * path, const char * str, const char * mode) {
- FILE* txt;
- // 检查参数是否有问题
- if (!path || !*path || !str) {
- CERR("check is '!path || !*path || !str'");
- return RT_ErrorParam;
- }
- if ((txt = fopen(path, mode)) == NULL) {
- CERR("fopen mode = '%s', path = '%s' error!", mode, path);
- return RT_ErrorFopen;
- }
- //这里写入信息
- fputs(str, txt);
- fclose(txt);
- return RT_SuccessBase;
- }
- /*
- * 文件写入,没有好说的, 会返回 RT_SuccessBase | RT_ErrorParam | RT_ErrorFopen
- * path : 文件路径
- * str : 待写入的字符串
- * : 返回操作的结果 见上面枚举
- */
- inline int
- tstr_file_writes(const char * path, const char * str) {
- return _tstr_file_writes(path, str, "wb");
- }
- /*
- * 文件追加内容 会返回 RT_SuccessBase | RT_ErrorParam | RT_ErrorFopen
- * path : 文件路径
- * str : 待写入的字符串
- * : 返回操作的结果 见上面枚举
- */
- inline int
- tstr_file_appends(const char * path, const char * str) {
- return _tstr_file_writes(path, str, "ab");
- }
scjson.h
- #ifndef _H_SIMPLEC_SCJSON
- #define _H_SIMPLEC_SCJSON
- #include <tstr.h>
- // json 中几种数据类型定义 , 对于C而言 最难的是看不见源码,而不是api复杂, 更不是业务复杂
- #define _CJSON_FALSE (0)
- #define _CJSON_TRUE (1)
- #define _CJSON_NULL (2)
- #define _CJSON_NUMBER (3)
- #define _CJSON_STRING (4)
- #define _CJSON_ARRAY (5)
- #define _CJSON_OBJECT (6)
- #define _CJSON_ISREF (256) //set 时候用如果是引用就不释放了
- #define _CJSON_ISCONST (512) //set时候用, 如果是const char* 就不释放了
- struct cjson {
- struct cjson * next, * prev;
- struct cjson * child; // type == _CJSON_ARRAY or type == _CJSON_OBJECT 那么 child 就不为空
- int type;
- char * key; // json内容那块的 key名称
- char * vs; // type == _CJSON_STRING, 是一个字符串
- double vd; // type == _CJSON_NUMBER, 是一个num值, ((int)c->vd) 转成int 或 bool
- };
- //定义cjson_t json类型
- typedef struct cjson * cjson_t;
- /*
- * 这个宏,协助我们得到 int 值 或 bool 值
- *
- * item : 待处理的目标cjson_t结点
- */
- #define cjson_getint(item) \
- ((int)((item)->vd))
- /*
- * 删除json串内容
- * c : 待释放json_t串内容
- */
- extern void cjson_delete(cjson_t c);
- /*
- * 对json字符串解析返回解析后的结果
- * jstr : 待解析的字符串
- */
- extern cjson_t cjson_newtstr(tstr_t str);
- /*
- * 将json文件解析成json内容返回. 需要自己调用 cjson_delete
- * path : json串路径
- * : 返回处理好的cjson_t 内容,失败返回NULL
- */
- extern cjson_t cjson_newfile(const char * path);
- /*
- * 根据 item当前结点的 next 一直寻找到 NULL, 返回个数. 推荐在数组的时候使用
- * array : 待处理的cjson_t数组对象
- * : 返回这个数组中长度
- */
- extern int cjson_getlen(cjson_t array);
- /*
- * 根据索引得到这个数组中对象
- * array : 数组对象
- * idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
- * : 返回查找到的当前对象
- */
- extern cjson_t cjson_getarray(cjson_t array, int idx);
- /*
- * 根据key得到这个对象 相应位置的值
- * object : 待处理对象中值
- * key : 寻找的key
- * : 返回 查找 cjson_t 对象
- */
- extern cjson_t cjson_getobject(cjson_t object, const char * key);
- // --------------------------------- 下面是 cjson 输出部分的处理代码 -----------------------------------------
- /*
- * 这里是将 cjson_t item 转换成字符串内容,需要自己free
- * item : cjson的具体结点
- * : 返回生成的item的json串内容
- */
- extern char* cjson_print(cjson_t item);
- // --------------------------------- 下面是 cjson 输出部分的辅助代码 -----------------------------------------
- /*
- * 创建一个bool的对象 b==0表示false,否则都是true, 需要自己释放 cjson_delete
- * b : bool 值 最好是 _Bool
- * : 返回 创建好的json 内容
- */
- extern cjson_t cjson_newnull();
- extern cjson_t cjson_newbool(int b);
- extern cjson_t cjson_newnumber(double vd);
- extern cjson_t cjson_newstring(const char * vs);
- extern cjson_t cjson_newarray(void);
- extern cjson_t cjson_newobject(void);
- /*
- * 按照类型,创建 对映类型的数组 cjson对象
- *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING
- * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char**
- * type : 类型目前支持 上面几种类型
- * array : 数组原始数据
- * len : 数组中元素长度
- * : 返回创建的数组对象
- */
- extern cjson_t cjson_newtypearray(int type, const void * array, int len);
- /*
- * 在array中分离第idx个索引项内容.
- * array : 待处理的json_t 数组内容
- * idx : 索引内容
- * : 返回分离的json_t内容
- */
- extern cjson_t cjson_detacharray(cjson_t array, int idx);
- /*
- * 在object json 中分离 key 的项出去
- * object : 待分离的对象主体内容
- * key : 关联的键
- * : 返回分离的 object中 key的项json_t
- */
- extern cjson_t cjson_detachobject(cjson_t object, const char * key);
- #endif // !_H_SIMPLEC_SCJSON
scjson.c
- #include <scjson.h>
- #include <float.h>
- #include <limits.h>
- #include <math.h>
- // 删除cjson
- static void _cjson_delete(cjson_t c) {
- cjson_t next;
- while (c) {
- next = c->next;
- //递归删除儿子
- if (!(c->type & _CJSON_ISREF)) {
- if (c->child) //如果不是尾递归,那就先递归
- _cjson_delete(c->child);
- if (c->vs)
- sm_free(c->vs);
- }
- else if (!(c->type & _CJSON_ISCONST) && c->key)
- sm_free(c->key);
- sm_free(c);
- c = next;
- }
- }
- /*
- * 删除json串内容,最近老是受清华的老学生打击, 会起来的......
- * c : 待释放json_t串内容
- */
- inline void
- cjson_delete(cjson_t c) {
- if (NULL == c)
- return;
- _cjson_delete(c);
- }
- //构造一个空 cjson 对象
- static inline cjson_t _cjson_new(void) {
- return sm_malloc(sizeof(struct cjson));
- }
- // 简化的代码段,用宏来简化代码书写 , 16进制处理
- #define __parse_hex4_code(c, h) \
- if (c >= '' && c <= '') \
- h += c - ''; \
- else if (c >= 'A' && c <= 'F') \
- h += + c - 'A'; \
- else if (c >= 'a' && c <= 'z') \
- h += + c - 'F'; \
- else \
- return
- // 等到unicode char代码
- static unsigned _parse_hex4(const char * str) {
- unsigned h = ;
- char c = *str;
- //第一轮
- __parse_hex4_code(c, h);
- h <<= ;
- c = *++str;
- //第二轮
- __parse_hex4_code(c, h);
- h <<= ;
- c = *++str;
- //第三轮
- __parse_hex4_code(c, h);
- h <<= ;
- c = *++str;
- //第四轮
- __parse_hex4_code(c, h);
- return h;
- }
- // 分析字符串的子函数,
- static const char* _parse_string(cjson_t item, const char * str) {
- static unsigned char _marks[] = { 0x00, 0x00, 0xC0, 0xE0, 0xF0, 0xF8, 0xFC };
- const char * ptr;
- char * nptr, * out;
- char c;
- int len;
- unsigned uc, nuc;
- if (*str != '\"') { // 检查是否是字符串内容
- CERR("need \\\" str => %s error!", str);
- return NULL;
- }
- for (ptr = str + , len = ; (c = *ptr++) != '\"' && c; ++len)
- if (c == '\\') //跳过转义字符
- ++ptr;
- out = sm_malloc(len + );
- // 这里复制拷贝内容
- for (ptr = str + , nptr = out; (c = *ptr) != '\"' && c; ++ptr) {
- if (c != '\\') {
- *nptr++ = c;
- continue;
- }
- // 处理转义字符
- switch ((c = *++ptr)) {
- case 'b': *nptr++ = '\b'; break;
- case 'f': *nptr++ = '\f'; break;
- case 'n': *nptr++ = '\n'; break;
- case 'r': *nptr++ = '\r'; break;
- case 't': *nptr++ = '\t'; break;
- case 'u': // 将utf16 => utf8, 专门的utf处理代码
- uc = _parse_hex4(ptr + );
- ptr += ;//跳过后面四个字符, unicode
- if ((uc >= 0xDC00 && uc <= 0xDFFF) || uc == ) break; /* check for invalid. */
- if (uc >= 0xD800 && uc <= 0xDBFF) { /* UTF16 surrogate pairs. */
- if (ptr[] != '\\' || ptr[] != 'u')
- break; /* missing second-half of surrogate. */
- nuc = _parse_hex4(ptr + );
- ptr += ;
- if (nuc < 0xDC00 || nuc>0xDFFF)
- break; /* invalid second-half of surrogate. */
- uc = 0x10000 + (((uc & 0x3FF) << ) | (nuc & 0x3FF));
- }
- len = ;
- if (uc < 0x80)
- len = ;
- else if (uc < 0x800)
- len = ;
- else if (uc < 0x10000)
- len = ;
- nptr += len;
- switch (len) {
- case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
- case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
- case : *--nptr = ((uc | 0x80) & 0xBF); uc >>= ;
- case : *--nptr = (uc | _marks[len]);
- }
- nptr += len;
- break;
- default: *nptr++ = c;
- }
- }
- *nptr = '\0';
- if (c == '\"')
- ++ptr;
- item->vs = out;
- item->type = _CJSON_STRING;
- return ptr;
- }
- // 分析数值的子函数,写的可以
- static const char * _parse_number(cjson_t item, const char * str) {
- double n = 0.0, ns = 1.0, nd = 0.0; //n把偶才能值, ns表示开始正负, 负为-1, nd 表示小数后面位数
- int e = , es = ; //e表示后面指数, es表示 指数的正负,负为-1
- char c;
- if ((c = *str) == '-' || c == '+') {
- ns = c == '-' ? -1.0 : 1.0; //正负号检测, 1表示负数
- ++str;
- }
- //处理整数部分
- for (c = *str; c >= '' && c <= ''; c = *++str)
- n = n * + c - '';
- if (c == '.')
- for (; (c = *++str) >= '' && c <= ''; --nd)
- n = n * + c - '';
- // 处理科学计数法
- if (c == 'e' || c == 'E') {
- if ((c = *++str) == '+') //处理指数部分
- ++str;
- else if (c == '-')
- es = -, ++str;
- for (; (c = *str) >= '' && c <= ''; ++str)
- e = e * + c - '';
- }
- //返回最终结果 number = +/- number.fraction * 10^+/- exponent
- n = ns * n * pow(10.0, nd + es * e);
- item->vd = n;
- item->type = _CJSON_NUMBER;
- return str;
- }
- // 递归下降分析 需要声明这些函数
- static const char * _parse_array(cjson_t item, const char * str);
- static const char * _parse_object(cjson_t item, const char * str);
- static const char * _parse_value(cjson_t item, const char * value);
- // 分析数组的子函数, 采用递归下降分析
- static const char * _parse_array(cjson_t item, const char * str) {
- cjson_t child;
- if (*str != '[') {
- CERR("array str error start: %s.", str);
- return NULL;
- }
- item->type = _CJSON_ARRAY;
- str = str + ;
- if (*str == ']') // 低估提前结束
- return str + ;
- item->child = child = _cjson_new();
- str = _parse_value(child, str);
- if (NULL == str) { // 解析失败 直接返回
- CERR("array str error e n d one: %s.", str);
- return NULL;
- }
- while (*str == ',') {
- cjson_t nitem = _cjson_new();
- child->next = nitem;
- nitem->prev = child;
- child = nitem;
- str = _parse_value(child, str + );
- if (NULL == str) {// 写代码是一件很爽的事
- CERR("array str error e n d two: %s.", str);
- return NULL;
- }
- }
- if (*str != ']') {
- CERR("array str error e n d: %s.", str);
- return NULL;
- }
- return str + ; // 跳过']'
- }
- // 分析对象的子函数
- static const char * _parse_object(cjson_t item, const char * str) {
- cjson_t child;
- if (*str != '{') {
- CERR("object str error start: %s.", str);
- return NULL;
- }
- item->type = _CJSON_OBJECT;
- str = str + ;
- if (*str == '}')
- return str + ;
- //处理结点, 开始读取一个 key
- item->child = child = _cjson_new();
- str = _parse_string(child, str);
- if (!str || *str != ':') {
- CERR("_skip _parse_string is error : %s!", str);
- return NULL;
- }
- child->key = child->vs;
- child->vs = NULL;
- str = _parse_value(child, str + );
- if (!str) {
- CERR("_parse_object _parse_value is error 2!");
- return NULL;
- }
- // 递归解析
- while (*str == ',') {
- cjson_t nitem = _cjson_new();
- child->next = nitem;
- nitem->prev = child;
- child = nitem;
- str = _parse_string(child, str + );
- if (!str || *str != ':'){
- CERR("_parse_string need name or no equal ':' %s.", str);
- return NULL;
- }
- child->key = child->vs;
- child->vs = NULL;
- str = _parse_value(child, str+);
- if (!str) {
- CERR("_parse_string need item two ':' %s.", str);
- return NULL;
- }
- }
- if (*str != '}') {
- CERR("object str error e n d: %s.", str);
- return NULL;
- }
- return str + ;
- }
- // 将value 转换塞入 item json值中一部分
- static const char * _parse_value(cjson_t item, const char * value) {
- char c;
- if ((value) && (c = *value)) {
- switch (c) {
- // n = null, f = false, t = true
- case 'n' : return item->type = _CJSON_NULL, value + ;
- case 'f' : return item->type = _CJSON_FALSE, value + ;
- case 't' : return item->type = _CJSON_TRUE, item->vd = 1.0, value + ;
- case '\"': return _parse_string(item, value);
- case '' : case '': case '': case '': case '': case '': case '': case '': case '': case '':
- case '+' : case '-': return _parse_number(item, value);
- case '[' : return _parse_array(item, value);
- case '{' : return _parse_object(item, value);
- }
- }
- // 循环到这里是意外 数据
- CERR("params value = %s!", value);
- return NULL;
- }
- /*
- * 对json字符串解析返回解析后的结果
- * jstr : 待解析的字符串
- * : 返回解析好的字符串内容
- */
- static cjson_t _cjson_parse(const char * jstr) {
- cjson_t c = _cjson_new();
- const char * end;
- if (!(end = _parse_value(c, jstr))) {
- CERR("_parse_value params end = %s!", end);
- cjson_delete(c);
- return NULL;
- }
- //这里是否检测 返回测试数据
- return c;
- }
- /*
- * 将 jstr中 不需要解析的字符串都去掉,并且纪念mini 比男的还平
- * jstr : 待处理的json串
- * : 返回压缩后的json串长度
- */
- static int _cjson_mini(char * jstr) {
- char c, *in = jstr, *to = jstr;
- while ((c = *to)) {
- // step 1 : 处理字符串
- if (c == '"') {
- *in++ = c;
- while ((c = *++to) && (c != '"' || to[-] == '\\'))
- *in++ = c;
- if (c) {
- *in++ = c;
- ++to;
- }
- continue;
- }
- // step 2 : 处理不可见特殊字符
- if (c < '!') {
- ++to;
- continue;
- }
- if (c == '/') {
- // step 3 : 处理 // 解析到行末尾
- if (to[] == '/') {
- while ((c = *++to) && c != '\n')
- ;
- continue;
- }
- // step 4 : 处理 /*
- if (to[] == '*') {
- while ((c = *++to) && (c != '*' || to[] != '/'))
- ;
- if (c)
- to += ;
- continue;
- }
- }
- // step 5 : 合法数据直接保存
- *in++ = *to++;
- }
- *in = '\0';
- return in - jstr;
- }
- /*
- * 对json字符串解析返回解析后的结果
- * jstr : 待解析的字符串
- */
- inline cjson_t
- cjson_newtstr(tstr_t str) {
- str->len = _cjson_mini(str->str);
- return _cjson_parse(str->str);
- }
- // 从json文件中解析出最简json数据
- static tstr_t _cjson_newfile(const char * path) {
- char c, n;
- tstr_t tstr;
- FILE * txt = fopen(path, "r");
- if (NULL == txt) {
- CERR("fopen r %s is error!", path);
- return NULL;
- }
- //这里创建文本串对象
- tstr = tstr_new(NULL);
- while ((c = fgetc(txt)) != EOF) {
- // step 1 : 处理字符串
- if (c == '"') {
- tstr_append(tstr, c);
- for (n = c; ((c = fgetc(txt)) != EOF) && (c != '"' || n == '\\'); n = c)
- tstr_append(tstr, c);
- if (EOF != c)
- tstr_append(tstr, c);
- continue;
- }
- // step 2 : 处理不可见特殊字符
- if (c < '!')
- continue;
- if (c == '/') {
- // step 3 : 处理 // 解析到行末尾
- n = fgetc(txt);
- if (n == '/') {
- while ((c = fgetc(txt)) != EOF && c != '\n')
- ;
- continue;
- }
- // step 4 : 处理 /*
- if (n == '*') {
- while ((c = fgetc(txt)) != EOF) {
- if (c == '*') {
- n = fgetc(txt);
- if (n == '/')
- break;
- ungetc(n, txt);
- }
- }
- continue;
- }
- ungetc(n, txt);
- }
- // step 5 : 合法数据直接保存
- tstr_append(tstr, c);
- }
- fclose(txt);//很重要创建了就要释放,否则会出现隐藏的句柄bug
- return tstr;
- }
- /*
- * 将json文件解析成json内容返回. 需要自己调用 cjson_delete
- * path : json串路径
- * : 返回处理好的cjson_t 内容,失败返回NULL
- */
- cjson_t
- cjson_newfile(const char * path) {
- cjson_t root;
- tstr_t tstr = _cjson_newfile(path);
- if (!tstr) {
- CERR("_cjson_dofile_tstr path:%s is error!", path);
- return NULL;
- }
- root = _cjson_parse(tstr->str);
- tstr_delete(tstr);
- return root;
- }
- /*
- * 根据 item当前结点的 next 一直寻找到 NULL, 返回个数. 推荐在数组的时候使用
- * array : 待处理的cjson_t数组对象
- * : 返回这个数组中长度
- */
- int
- cjson_getlen(cjson_t array) {
- int len = ;
- if (array) {
- for (array = array->child; array; array = array->next)
- ++len;
- }
- return len;
- }
- /*
- * 根据索引得到这个数组中对象
- * array : 数组对象
- * idx : 查找的索引 必须 [0,cjson_getlen(array)) 范围内
- * : 返回查找到的当前对象
- */
- cjson_t
- cjson_getarray(cjson_t array, int idx) {
- cjson_t c;
- DEBUG_CODE({
- if (!array || idx < ) {
- CERR("array:%p, idx=%d params is error!", array, idx);
- return NULL;
- }
- });
- for (c = array->child; c&&idx > ; c = c->next)
- --idx;
- return c;
- }
- /*
- * 根据key得到这个对象 相应位置的值
- * object : 待处理对象中值
- * key : 寻找的key
- * : 返回 查找 cjson_t 对象
- */
- cjson_t
- cjson_getobject(cjson_t object, const char* key) {
- cjson_t c;
- DEBUG_CODE({
- if (!object || !key || !*key) {
- CERR("object:%p, key=%s params is error!", object, key);
- return NULL;
- }
- });
- for (c = object->child; c && tstr_icmp(key, c->key); c = c->next)
- ;
- return c;
- }
- // --------------------------------- 下面是 cjson 输出部分的处理代码 -----------------------------------------
- // 2^n>=x , n是最小的整数
- static int _pow2gt(int x) {
- --x;
- x |= x >> ;
- x |= x >> ;
- x |= x >> ;
- x |= x >> ;
- x |= x >> ;
- return x + ;
- }
- /*
- * 这里使用 tstr_t 结构 size 这里表示 字符串总大小,没有变化
- * len 表示当前字符串的字符串起始偏移量 即 tstr_t->str + tstr_t->len 起始的
- */
- static char* _ensure(tstr_t p, int need) {
- char * nbuf;
- int nsize;
- if (!p || !p->str) {
- CERR("p:%p need:%d is error!", p, need);
- return NULL;
- }
- need += p->len;
- if (need <= p->size) //内存够用直接返回结果
- return p->str + p->len;
- nsize = _pow2gt(need);
- // 一定会成功, 否则一切都回归奇点
- nbuf = sm_malloc(nsize * sizeof(char));
- //这里复制内容
- memcpy(nbuf, p->str, p->size);
- sm_free(p->str);
- p->size = nsize;
- p->str = nbuf;
- return nbuf + p->len;
- }
- // 这里更新一下 当前字符串, 返回当前字符串的长度
- static inline int _update(tstr_t p) {
- return (!p || !p->str) ? : p->len + (int)strlen(p->str+p->len);
- }
- // 将item 中值转换成字符串 保存到p中
- static char * _print_number(cjson_t item, tstr_t p) {
- char* str = NULL;
- double d = item->vd;
- int i = (int)d;
- if (d == ) { //普通0
- str = _ensure(p, );
- if (str)
- str[] = '', str[] = '\0';
- }
- else if ((fabs(d - i)) <= DBL_EPSILON && d <= INT_MAX && d >= INT_MIN) {
- str = _ensure(p, ); //int 值
- if (str)
- sprintf(str, "%d", i);
- }
- else {
- str = _ensure(p, ); //double值
- if (str) {
- double nd = fabs(d); //得到正值开始比较
- if(fabs(floor(d) - d) <= DBL_EPSILON && nd < 1.0e60)
- sprintf(str, "%.0f", d);
- else if(nd < 1.0e-6 || nd > 1.0e9) //科学计数法
- sprintf(str, "%e", d);
- else
- sprintf(str, "%f", d);
- }
- }
- return str;
- }
- // 输出字符串内容
- static char * _print_string(char * str, tstr_t p) {
- const char * ptr;
- char * nptr, * out;
- int len = , flag = ;
- unsigned char c;
- if (!str || !*str) { //最特殊情况,什么都没有 返回NULL
- out = _ensure(p, );
- if (!out)
- return NULL;
- out[] = '\"', out[] = '\"', out[] = '\0';
- return out;
- }
- for (ptr = str; (c=*ptr); ++ptr)
- flag |= ((c > && c < ) || c == '\"' || c == '\\');
- if (!flag) { //没有特殊字符直接处理结果
- len = (int)(ptr - str);
- out = _ensure(p,len + );
- if (!out)
- return NULL;
- nptr = out;
- *nptr++ = '\"';
- strcpy(nptr, str);
- nptr[len] = '\"';
- nptr[len + ] = '\0';
- return out;
- }
- //处理 存在 "和转义字符内容
- for (ptr = str; (c = *ptr) && ++len; ++ptr) {
- if (strchr("\"\\\b\f\n\r\t", c))
- ++len;
- else if (c < ) //隐藏字符的处理, 这里可以改
- len += ;
- }
- if ((out = _ensure(p, len + )) == NULL)
- return NULL;
- //先添加 \"
- nptr = out;
- *nptr++ = '\"';
- for (ptr = str; (c = *ptr); ++ptr) {
- if (c > && c != '\"' && c != '\\') {
- *nptr++ = c;
- continue;
- }
- *nptr++ = '\\';
- switch (c){
- case '\\': *nptr++ = '\\'; break;
- case '\"': *nptr++ = '\"'; break;
- case '\b': *nptr++ = 'b'; break;
- case '\f': *nptr++ = 'f'; break;
- case '\n': *nptr++ = 'n'; break;
- case '\r': *nptr++ = 'r'; break;
- case '\t': *nptr++ = 't'; break;
- default: sprintf(nptr, "u%04x", c);nptr += ; /* 不可见字符 采用 4字节字符编码 */
- }
- }
- *nptr++ = '\"';
- *nptr = '\0';
- return out;
- }
- //这里是 递归下降 的函数声明处, 分别是处理值, 数组, object
- static char * _print_value(cjson_t item, tstr_t p);
- static char * _print_array(cjson_t item, tstr_t p);
- static char * _print_object(cjson_t item, tstr_t p);
- // 定义实现部分, 内部私有函数 认为 item 和 p都是存在的
- static char * _print_value(cjson_t item, tstr_t p) {
- char * out = NULL;
- switch ((item->type) & UCHAR_MAX) { // 0xff
- case _CJSON_FALSE: if ((out = _ensure(p, ))) strcpy(out, "false"); break;
- case _CJSON_TRUE: if ((out = _ensure(p, ))) strcpy(out, "true"); break;
- case _CJSON_NULL: if ((out = _ensure(p, ))) strcpy(out, "null"); break;
- case _CJSON_NUMBER: out = _print_number(item, p); break;
- case _CJSON_STRING: out = _print_string(item->vs, p); break;
- case _CJSON_ARRAY: out = _print_array(item, p); break;
- case _CJSON_OBJECT: out = _print_object(item, p); break;
- }
- return out;
- }
- // 同样 假定 item 和 p都是存在且不为NULL
- static char * _print_array(cjson_t item, tstr_t p)
- {
- char * ptr;
- cjson_t child = item->child;
- int ncut, i;
- // 得到孩子结点的深度
- for (ncut = ; (child); child = child->child)
- ++ncut;
- if (!ncut) { //没有孩子结点 直接空数组返回结果
- char* out = NULL;
- if (!(out = _ensure(p, )))
- strcpy(out, "[]");
- return out;
- }
- i = p->len;
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr = '[';
- ++p->len;
- for (child = item->child; (child); child = child->next) {
- _print_value(child, p);
- p->len = _update(p);
- if (child->next) {
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr++ = ',';
- *ptr = '\0';
- p->len += ;
- }
- }
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr++ = ']';
- *ptr = '\0';
- return p->str + i;
- }
- // 同样 假定 item 和 p都是存在且不为NULL, 相信这些代码是安全的
- static char * _print_object(cjson_t item, tstr_t p)
- {
- char * ptr;
- int i, ncut, len;
- cjson_t child = item->child;
- // 得到孩子结点的深度
- for (ncut = ; child; child = child->child)
- ++ncut;
- if (!ncut) {
- char* out = NULL;
- if (!(out = _ensure(p, )))
- strcpy(out, "{}");
- return out;
- }
- i = p->len;
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr++ = '{';
- *ptr -= '\0';
- p->len += ;
- // 根据子结点 处理
- for (child = item->child; (child); child = child->next) {
- _print_string(child->key, p);
- p->len = _update(p);
- //加入一个冒号
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr++ = ':';
- p->len += ;
- //继续打印一个值
- _print_value(child, p);
- p->len = _update(p);
- //结算最后内容
- len = child->next ? : ;
- if ((ptr = _ensure(p, len + )) == NULL)
- return NULL;
- if (child->next)
- *ptr++ = ',';
- *ptr = '\0';
- p->len += len;
- }
- if (!(ptr = _ensure(p, )))
- return NULL;
- *ptr++ = '}';
- *ptr = '\0';
- return p->str + i;
- }
- #define _INT_CJONSTR (256)
- /*
- * 这里是将 cjson_t item 转换成字符串内容,需要自己free
- * item : cjson的具体结点
- * : 返回生成的item的json串内容
- */
- char *
- cjson_print(cjson_t item) {
- struct tstr p;
- char * out;
- if (NULL == item) {
- CERR("item is error = %p!", item);
- return NULL;
- }
- // 构建内存
- p.str = sm_malloc(sizeof(char) * _INT_CJONSTR);
- p.size = _INT_CJONSTR;
- p.len = ;
- out = _print_value(item, &p); //从值处理开始, 返回最终结果
- if (out == NULL) {
- sm_free(p.str);
- CERR("_print_value item:%p, p:%p is error!", item, &p);
- return NULL;
- }
- return sm_realloc(out, strlen(out) + ); // 体积变小 realloc返回一定成功
- }
- // --------------------------------- 下面是 cjson 输出部分的辅助代码 -----------------------------------------
- /*
- * 创建一个bool的对象 b==0表示false,否则都是true, 需要自己释放 cjson_delete
- * b : bool 值 最好是 _Bool
- * : 返回 创建好的json 内容
- */
- inline cjson_t
- cjson_newnull() {
- cjson_t item = _cjson_new();
- item->type = _CJSON_NULL;
- return item;
- }
- inline cjson_t
- cjson_newbool(int b) {
- cjson_t item = _cjson_new();
- item->vd = item->type = b ? _CJSON_TRUE : _CJSON_FALSE;
- return item;
- }
- inline cjson_t
- cjson_newnumber(double vd)
- {
- cjson_t item = _cjson_new();
- item->type = _CJSON_NUMBER;
- item->vd = vd;
- return item;
- }
- inline cjson_t
- cjson_newstring(const char* vs)
- {
- cjson_t item = _cjson_new();
- item->type = _CJSON_STRING;
- item->vs = tstr_dup(vs);
- return item;
- }
- inline cjson_t
- cjson_newarray(void)
- {
- cjson_t item = _cjson_new();
- item->type = _CJSON_ARRAY;
- return item;
- }
- inline cjson_t
- cjson_newobject(void)
- {
- cjson_t item = _cjson_new();
- item->type = _CJSON_OBJECT;
- return item;
- }
- /*
- * 按照类型,创建 对映类型的数组 cjson对象
- *目前支持 _CJSON_NULL _CJSON_BOOL/FALSE or TRUE , _CJSON_NUMBER, _CJSON_STRING
- * NULL => array 传入NULL, FALSE 使用char[],也可以传入NULL, NUMBER 只接受double, string 只接受char**
- * type : 类型目前支持 上面几种类型
- * array : 数组原始数据
- * len : 数组中元素长度
- * : 返回创建的数组对象
- */
- cjson_t
- cjson_newtypearray(int type, const void * array, int len) {
- int i;
- cjson_t n = NULL, p = NULL, a;
- // _DEBUG 模式下简单检测一下
- DEBUG_CODE({
- if(type < _CJSON_FALSE || type > _CJSON_STRING || len <=){
- CERR("check param is error! type = %d, len = %d.", type, len);
- return NULL;
- }
- });
- // 这里是实际执行代码
- a = cjson_newarray();
- for(i=; i<len; ++i){
- switch(type){
- case _CJSON_NULL: n = cjson_newnull(); break;
- case _CJSON_FALSE: n = cjson_newbool(array? ((char*)array)[i] : ); break;
- case _CJSON_TRUE: n = cjson_newbool(array? ((char*)array)[i] : ); break;
- case _CJSON_NUMBER: n = cjson_newnumber(((double*)array)[i]); break;
- case _CJSON_STRING: n = cjson_newstring(((char**)array)[i]);break;
- }
- if(i){ //有你更好
- p->next = n;
- n->prev = p;
- }
- else
- a->child = n;
- p = n;
- }
- return a;
- }
- /*
- * 在array中分离第idx个索引项内容.
- * array : 待处理的json_t 数组内容
- * idx : 索引内容
- * : 返回分离的json_t内容
- */
- cjson_t
- cjson_detacharray(cjson_t array, int idx) {
- cjson_t c;
- DEBUG_CODE({
- if(!array || idx<){
- CERR("check param is array:%p, idx:%d.", array, idx);
- return NULL;
- }
- });
- for(c=array->child; idx> && c; c = c->next)
- --idx;
- if(c>){
- CERR("check param is too dig idx:sub %d.", idx);
- return NULL;
- }
- //这里开始拼接了
- if(c->prev)
- c->prev->next = c->next;
- if(c->next)
- c->next->prev = c->prev;
- if(c == array->child)
- array->child = c->next;
- c->prev = c->next = NULL;
- return c;
- }
- /*
- * 在object json 中分离 key 的项出去
- * object : 待分离的对象主体内容
- * key : 关联的键
- * : 返回分离的 object中 key的项json_t
- */
- cjson_t
- cjson_detachobject(cjson_t object, const char * key) {
- cjson_t c;
- DEBUG_CODE({
- if(!object || !object->child || !key || !*key){
- CERR("check param is object:%p, key:%s.", object, key);
- return NULL;
- }
- });
- for(c=object->child; c && tstr_icmp(c->key, key); c=c->next)
- ;
- if(!c) {
- CERR("check param key:%s => vlaue is empty.", key);
- return NULL;
- }
- if(c->prev)
- c->prev->next = c->next;
- if(c->next)
- c->next->prev = c->prev;
- if(c == object->child)
- object->child = c->next;
- c->prev = c->next = NULL;
- return c;
- }
主要测试文件 test_cjson.c
- #include <schead.h>
- #include <scjson.h>
- // 测试 cjson 函数
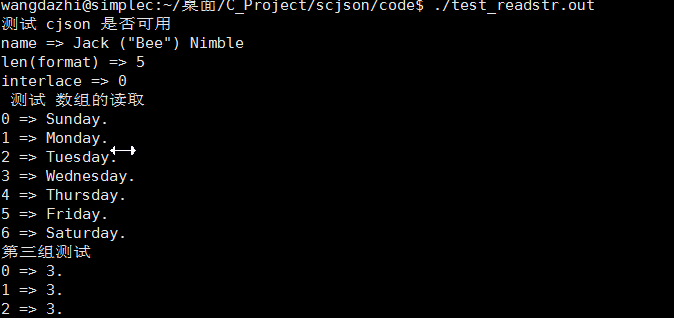
- void test_readstr(void) {
- // 第二个 测试 json 串的解析
- puts("测试 cjson 是否可用");
- char text1[] = "{\n\"name\": \"Jack (\\\"Bee\\\") Nimble\", \n\"format\": {\"type\": \"rect\", \n\"width\": 1920, \n\"height\": 1080, \n\"interlace\": false,\"frame rate\": 24\n}\n}";
- TSTR_NEW(jstr1);
- jstr1->str = text1;
- cjson_t js = cjson_newtstr(jstr1);
- cjson_t name = cjson_getobject(js, "name");
- printf("name => %s\n", name->vs);
- cjson_t format = cjson_getobject(js, "format");
- printf("len(format) => %d\n", cjson_getlen(format));
- cjson_t interlace = cjson_getobject(format, "interlace");
- printf("interlace => %d\n", cjson_getint(interlace));
- cjson_delete(js);
- //进行第三组测试
- puts(" 测试 数组的读取");
- char text2[] = "[\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\", \"Friday\", \"Saturday\"]";
- TSTR_NEW(jstr2);
- jstr2->str = text2;
- js = cjson_newtstr(jstr2);
- int len = cjson_getlen(js);
- int i;
- for (i = ; i < len; ++i) {
- cjson_t item = cjson_getarray(js,i);
- printf("%d => %s.\n", i, item->vs);
- }
- cjson_delete(js);
- puts("第三组测试");
- char text3[] = "[\n [0, -1, 0],\n [1, 0, 0],\n [0, 0, 1]\n ]\n";
- TSTR_NEW(jstr3);
- jstr3->str = text3;
- js = cjson_newtstr(jstr3);
- len = cjson_getlen(js);
- for (i = ; i < len; ++i) {
- cjson_t item = cjson_getarray(js, i);
- printf("%d => %d.\n", i, cjson_getlen(item));
- }
- cjson_delete(js);
- exit(EXIT_SUCCESS);
- }
- /*
- * simple c 框架业务层启动的代码
- */
- void test_readfile(void) {
- // 测试json解析结果是否正常
- cjson_t goods = cjson_newfile("./goods.json");
- // 数据输出
- int len = cjson_getlen(goods);
- printf("len = %d\n", len);
- // 打印其中一个数据
- int idx = len / ;
- cjson_t jsidx = cjson_getarray(goods, idx);
- int ilen = cjson_getlen(jsidx);
- printf("ilen = %d\n", ilen);
- printf("[\"%s\", \"%s\", %d, %d, %d, %d, %d, %d, %d, %d, %d, %d, %d, %d, %d, %d]\n",
- cjson_getarray(jsidx, )->vs,
- cjson_getarray(jsidx, )->vs,
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, )),
- cjson_getint(cjson_getarray(jsidx, ))
- );
- cjson_delete(goods);
- exit(EXIT_SUCCESS);
- }
最后链接过程, 编译文件 Makefile
- CC = gcc
- DEBUG = -ggdb3 -Wall -D_DEBUG
- DIR = -I.
- LIB = -lm
- RUN = $(CC) $(DEBUG) -o $@ $^ $(LIB)
- RUNO = $(CC) -c -o $@ $< $(DIR)
- TEST = -nostartfiles -e $(*F)
- RUNMAIN = $(RUN) $(TEST)
- all:test_readstr.out test_readfile.out
- # 库文件编译
- %.o:%.c
- $(RUNO)
- test_readstr.out:test_cjson.o scalloc.o tstr.o schead.o scjson.o
- $(RUNMAIN)
- test_readfile.out:test_cjson.o scalloc.o tstr.o schead.o scjson.o
- $(RUNMAIN)
- # 清除命令
- .PHONY:clean
- clean:
- rm -rf *.i *.s *.o *.out *~ ; ls
编译结果展示
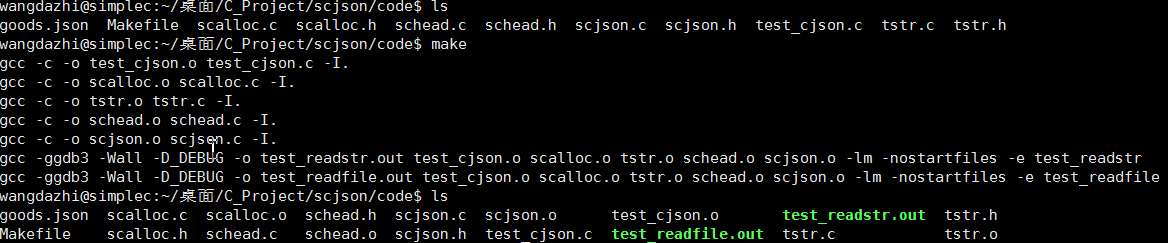
分别测试解析串和文件结果如下
还有解析goods.json 文件结果的

到这里基本测试完毕了, 这个scjson 引擎也可以收官''截稿'', 欢迎尝试, 也就1200行代码. 很实在, 应该好懂吧. 扯一点对于开发中编码问题, 推荐用UTF-8编码,
对于配置资源, 和操作系统原始编码保持一致.
文末分享一个BUG, 很有意思. 是标准函数是fgetc引起的
- _Success_(return != EOF)
- _Check_return_opt_
- _ACRTIMP int __cdecl fgetc(
- _Inout_ FILE* _Stream
- );
当你用 int c = fgetc(txt) 的时候, c 总是 >=0 . 走 unsigend char 差不多. 因而造成了逻辑分支出错, 这里需要统一定义为 char c = fgetc(txt);
这个BUG在解析utf-8编码文件会遇到. 是不是很神奇. 切记不要趟坑.
后记 - OK
错误是难免, 欢迎指正, 代码不好读, 说明你没有读过更加意外, 扯蛋的代码.
一个师傅三个徒弟 http://music.163.com/#/song?id=199768

c json实战引擎四 , 最后❤跳跃的更多相关文章
- c json实战引擎五 , 优化重构
引言 scjson是一个小巧的纯c跨平台小巧引擎. 适用于替换老的cJSON引擎的场景. 数据结构和代码布局做了大量改进.优势体现在以下几个方面: 1) 跨平台 (window 10 + VS2017 ...
- C json实战引擎 三 , 最后实现部分辅助函数
引言 大学读的是一个很时髦的专业, 学了四年的游戏竞技. 可惜没学好. 但认真过, 比做什么都认真. 见证了 ...... 打的所有游戏人物中 分享一位最喜爱 的 “I've been alone ...
- C json实战引擎 二 , 实现构造部分
引言 这篇博文和前一篇 C json实战引擎一,实现解析部分设计是相同的,都是采用递归下降分析. 这里扯一点 假如你是学生 推荐一本书 给 大家 自制编程语言 http://baike.baidu.c ...
- C json实战引擎 一 , 实现解析部分
引言 以前可能是去年的去年,写了一个 c json 解析引擎用于一个统计实验数据项目开发中. 基本上能用. 去年在网上 看见了好多开源的c json引擎 .对其中一个比较标准的 cJSON 引擎 深入 ...
- c json实战引擎六 , 感觉还行
前言 看到六, 自然有 一二三四五 ... 为什么还要写呢. 可能是它还需要活着 : ) 挣扎升级中 . c json 上面代码也存在于下面项目中(维护的最及时) structc json 这次版本 ...
- MySQL数据库性能优化与监控实战(阶段四)
MySQL数据库性能优化与监控实战(阶段四) 作者 刘畅 时间 2020-10-20 目录 1 sys数据库 1 2 系统变量 1 3 性能优化 1 3.1 硬件层 1 3.2 系统层 1 3.3 软 ...
- Javascript多线程引擎(四)
Javascript多线程引擎(四)--之C语言单继承 因为使用C语言做为开发语言, 而C语言在类的支持方面几乎为零, 而Javascript语言的Object类型是一个非常明显的类支持对象,所以这里 ...
- python机器学习实战(四)
python机器学习实战(三) 版权声明:本文为博主原创文章,转载请指明转载地址 www.cnblogs.com/fydeblog/p/7364317.html 前言 这篇notebook是关于机器学 ...
- apollo客户端springboot实战(四)
1. apollo客户端springboot实战(四) 1.1. 前言 经过前几张入门学习,基本已经完成了apollo环境的搭建和简单客户端例子,但我们现在流行的通常是springboot的客户端 ...
随机推荐
- Go语言【第一篇】:Go初识
Go语言特色 简洁.快速.安全 并行.有趣.开源 内存管理.数据安全.编译迅速 Go语言用途 Go语言被设计成一门应用于搭载Web服务器,存储集群或类似用途的巨型中央服务器的系统编程语言.对于高性能分 ...
- 廖雪峰老师Python教程读后笔记
廖老师网站:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 花几天时间看了廖老师的 ...
- Gevent-socket
1. 通过Gevent实现单线程下的多socket并发. server 端: #server side import sys import socket import time import geve ...
- [BZOJ4036] [HAOI2015]按位或
传送门:https://lydsy.com/JudgeOnline/problem.php?id=4036 Description 刚开始你有一个数字0,每一秒钟你会随机选择一个[0,2^n-1]的数 ...
- Linux实验一
一.Linux 简介 1.Linux 就是一个操作系统,就像你多少已经了解的 Windows(xp,7,8)和 Max OS , 我们的 Linux 也就是系统调用和内核那两层,当然直观的来看,我们使 ...
- HDOJ(HDU).2159 FATE (DP 带个数限制的完全背包)
HDOJ(HDU).2159 FATE (DP 带个数限制的完全背包) 题意分析 与普通的完全背包大同小异,区别就在于多了一个个数限制,那么在普通的完全背包的基础上,增加一维,表示个数.同时for循环 ...
- Linux环境下用Weblogic发布项目【一】 -- 安装Weblogic
一.Weblogic安装系统环境: 1.前提条件: a.在笔记本[Windows7]上安装远程连接Linux软件:F-Secure SSH File Transfer Trial[简写为:FSSH] ...
- HDU 5656
CA Loves GCD Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)To ...
- Codeforces Round #342 (Div. 2) C
C. K-special Tables time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- 重载(Overload)和重写(Override)的区别。重载的方法能否根据返回类型进行区分?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性.重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同.参数个数不同或者二者都不同)则视 ...