Java集合之ArrayList与LinkList
注:示例基于JDK1.8版本
参考资料:Java知音公众号
本文超长,也是搬运的干货,希望小伙伴耐心看完。
Collection集合体系
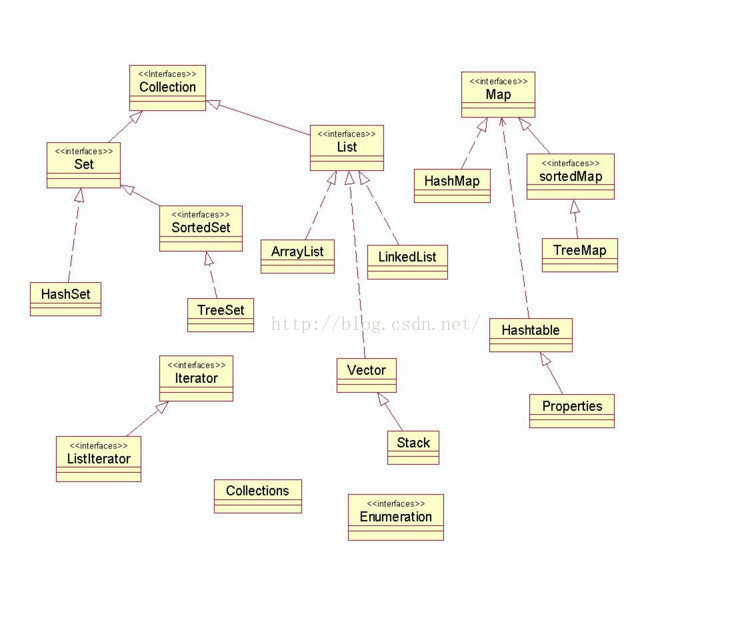
List、Set、Map是集合体系的三个接口。
其中List和Set继承了Collection接口。
List有序且元素可以重复,默认大小为10;ArrayList、LinkedList和Vector是三个主要的实现类。
Set元素不可以重复,HashSet和TreeSet是两个主要的实现类。
Map也属于集合系统,但和Collection接口不同。Map是key-value键值对形式的集合,key值不能重复,value可以重复;HashMap、TreeMap和Hashtable是三个主要的实现类。
--------------------------------------------------------------------------------------------------------------------
一、ArrayList
ArrayList基层是以数组实现的,可以存储任何类型的数据,但数据容量有限制,超出限制时会扩增50%容量,查找元素效率高。
ArrayList是一个简单的数据结构,因超出容量会自动扩容,可认为它是常说的动态数组。
源码分析
A、属性分析
/**
* 默认初始化容量
*/
private static final int DEFAULT_CAPACITY = 10; /**
* 如果自定义容量为0,则会默认用它来初始化ArrayList。或者用于空数组替换。
*/
private static final Object[] EMPTY_ELEMENTDATA = {}; /**
* 如果没有自定义容量,则会使用它来初始化ArrayList。或者用于空数组比对。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; /**
* 这就是ArrayList底层用到的数组 * 非私有,以简化嵌套类访问
* transient 在已经实现序列化的类中,不允许某变量序列化
*/
transient Object[] elementData; /**
* 实际ArrayList集合大小
*/
private int size; /**
* 可分配的最大容量
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
B、构造方法分析
1、不带参数初始化,默认容量为10
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
2、根据initialCapacity初始化一个空数组,如果值为0,则初始化一个空数组
/**
* 根据initialCapacity 初始化一个空数组
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
3、通过集合做参数的形式初始化,如果集合为空,则初始化为空数组
/**
* 通过集合做参数的形式初始化
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
C、主要方法
1、trimToSize()方法:
用来最小实例化存储,将容器大小调整为当前元素所占用的容量大小。
/**
* 这个方法用来最小化实例存储。
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
判断size的值,若为0,则将elementData置为空集合,若大于0,则将一份数组容量大小的集合复制给elementData。
2、clone()方法
克隆一个新数组。
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
通过调用Object的clone()方法来得到一个新的ArrayList对象,然后将elementData复制给该对象并返回。
3、add(E e)
在ArrayList末尾添加元素。
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
该方法首先调用了ensureCapacityInternal()方法,注意参数是size+1(数组已有参数个数+1个新参数),先来看看ensureCapacityInternal的源码:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
方法说明:计算容量+确保容量(上上代码)
计算容量:若elementData为空,则minCapacity值为默认容量和size+1(minCapacity)的最大值;若elementData不为空,minCapacity(size+1)不用进行操作
确保容量:如果size+1 > elementData.length证明数组已经放满,则增加容量,调用grow()。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//计算修改次数
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩展为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果扩为1.5倍还不满足需求,直接扩为需求值
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
增加容量grow():默认1.5倍扩容。
获取当前数组长度=>oldCapacity
oldCapacity>>1 表示将oldCapacity右移一位(位运算),相当于除2。再加上1,相当于新容量扩容1.5倍。
如果
newCapacity<mincapacity`,则`newcapacity mincapacity="size+1=2" elementdata="1" newcapacity="1+1""">>1=1,1<2所以如果不处理该情况,扩容将不能正确完成。如果新容量比最大值还要大,则将新容量赋值为VM要求最大值。
将elementData拷贝到一个新的容量中。
也就是说,当增加数据的时候,如果ArrayList的大小已经不满足需求时,那么就将数组变为原长度的1.5倍,之后的操作就是把老的数组拷到新的数组里面。
例如,默认的数组大小是10,也就是说当我们add10个元素之后,再进行一次add时,就会发生自动扩容,数组长度由10变为了15具体情况如下所示:
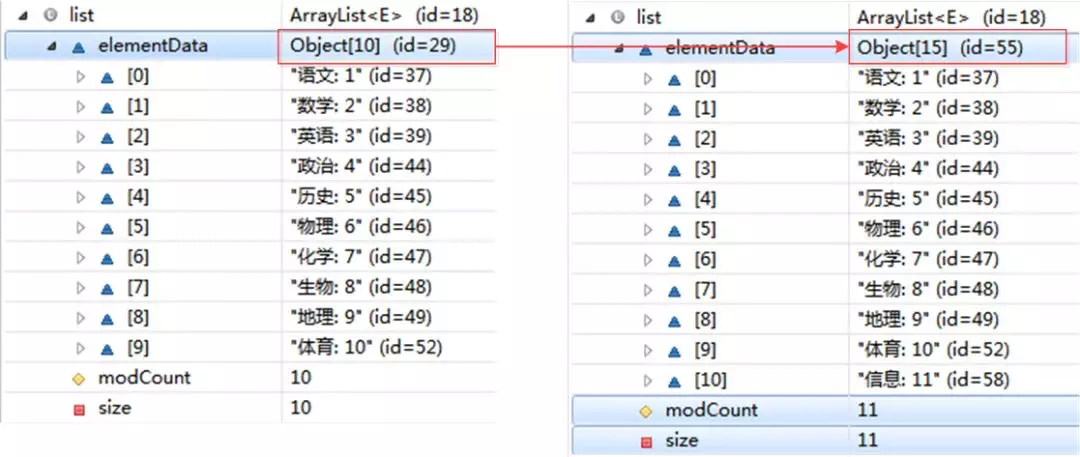
4、add(int index, E element)方法
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
rangeCheckForAdd()是越界异常检测方法。
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
System.arraycopy方法:
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
Object src : 原数组
int srcPos : 从元数据的起始位置开始
Object dest : 目标数组
int destPos : 目标数组的开始起始位置
int length : 要copy的数组的长度
5、set(int index, E element)方法:
用指定元素替换此列表中指定位置的元素。
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
E elementData(int index) {
return (E) elementData[index];
}
6、indexOf(Object o):
返回数组中第一个与参数相等的值的索引,允许null。
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
7、get(int index)方法:
返回指定下标处的元素的值。
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
rangeCheck(index)会检测index值是否合法,如果合法则返回索引对应的值。
8、remove(int index):
删除指定下标的元素。
public E remove(int index) {
// 检测index是否合法
rangeCheck(index);
// 数据结构修改次数
modCount++;
E oldValue = elementData(index);
// 记住这个算法
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
ArrayList优缺点
优点:
1、因为其底层是数组,所以修改和查询效率高。
2、自动扩容(1.5倍)。
缺点:
1、插入和删除效率不高。(文末对比LinkedList)
2、线程不安全。
二、LinkedList
LinkList以双向链表实现,链表无容量限制,但双向链表本身使用了更多空间,每插入一个元素都要构造一个额外的Node对象,也需要额外的链表指针操作。允许元素为null,线程不安全。
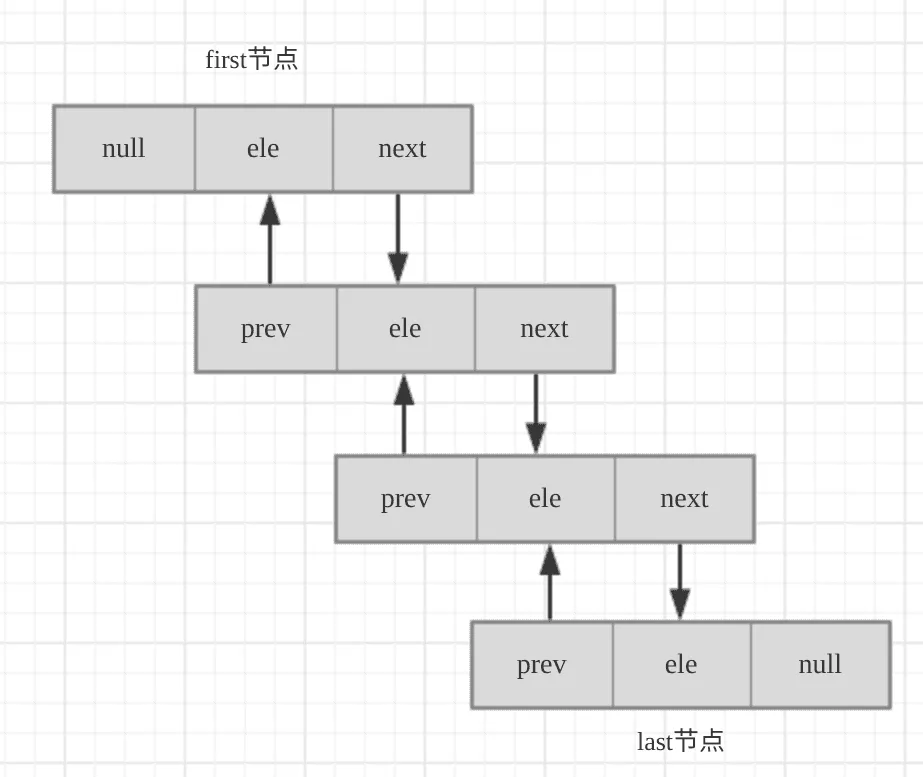
源码分析
1、变量
/**
* 集合元素数量
**/
transient int size = 0; /**
* 指向第一个节点的指针
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first; /**
* 指向最后一个节点的指针
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
2、构造方法
/**
* 无参构造方法
*/
public LinkedList() {
} /**
* 将集合c所有元素插入链表中
*/
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
3、Node节点
private static class Node<E> {
// 值
E item;
// 后继
Node<E> next;
// 前驱
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node既有prev也有next,所以证明它是一个双向链表。
4、添加元素
a、addAll(Collection c)方法
将集合c添加到链表,如果不传index,则默认是添加到尾部。如果调用addAll(int index, Collection<? extends E> c)方法,则添加到index后面。
/**
* 将集合添加到链尾
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
} /**
*
*/
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); // 拿到目标集合数组
Object[] a = c.toArray();
//新增元素的数量
int numNew = a.length;
//如果新增元素数量为0,则不增加,并返回false
if (numNew == 0)
return false; //定义index节点的前置节点,后置节点
Node<E> pred, succ;
// 判断是否是链表尾部,如果是:在链表尾部追加数据
//尾部的后置节点一定是null,前置节点是队尾
if (index == size) {
succ = null;
pred = last;
} else {
// 如果不在链表末端(而在中间部位)
// 取出index节点,并作为后继节点
succ = node(index);
// index节点的前节点 作为前驱节点
pred = succ.prev;
} // 链表批量增加,是靠for循环遍历原数组,依次执行插入节点操作
for (Object o : a) {
@SuppressWarnings("unchecked")
// 类型转换
E e = (E) o;
// 前置节点为pred,后置节点为null,当前节点值为e的节点newNode
Node<E> newNode = new Node<>(pred, e, null);
// 如果前置节点为空, 则newNode为头节点,否则为pred的next节点
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
} // 循环结束后,如果后置节点是null,说明此时是在队尾追加的
if (succ == null) {
// 设置尾节点
last = pred;
} else {
//否则是在队中插入的节点 ,更新前置节点 后置节点
pred.next = succ;
succ.prev = pred;
} // 修改数量size
size += numNew;
//修改modCount
modCount++;
return true;
} /**
* 取出index节点
*/
Node<E> node(int index) {
// assert isElementIndex(index); // 如果index 小于 size/2,则从头部开始找
if (index < (size >> 1)) {
// 把头节点赋值给x
Node<E> x = first;
for (int i = 0; i < index; i++)
// x=x的下一个节点
x = x.next;
return x;
} else {
// 如果index 大与等于 size/2,则从后面开始找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
} // 检测index位置是否合法
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
} // 检测index位置是否合法
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
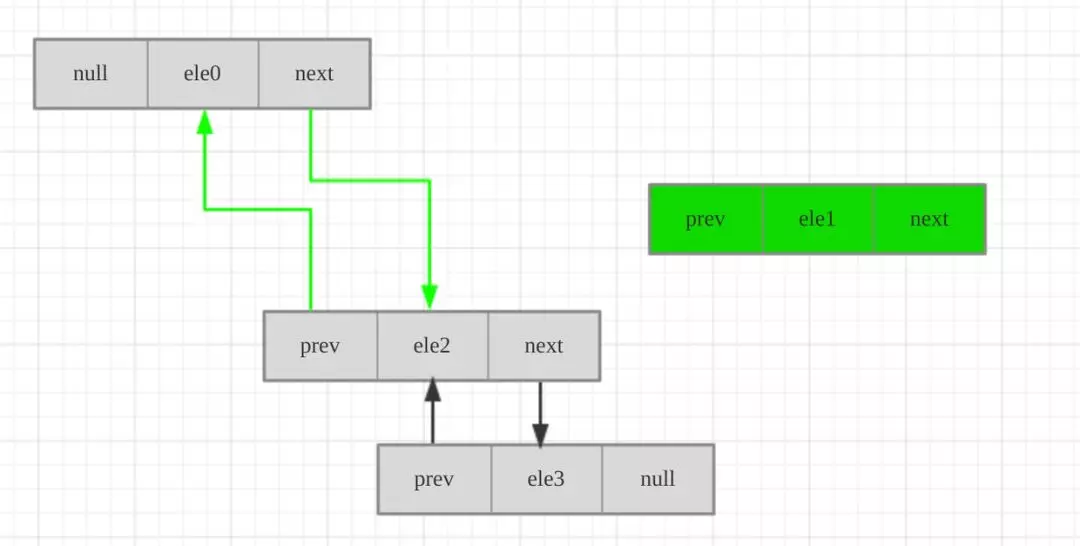
假设我们要在index=2处添加{1,2}到链表中,图解如下:
第一步:拿到index=2的前驱节点 prev=ele1
第二步:遍历集合prev.next=newNode,并实时更新prev节点以便下一次遍历:prev=newNode
第三步:将index=2的节点ele2接上:prev.next=ele2,ele2.prev=prev
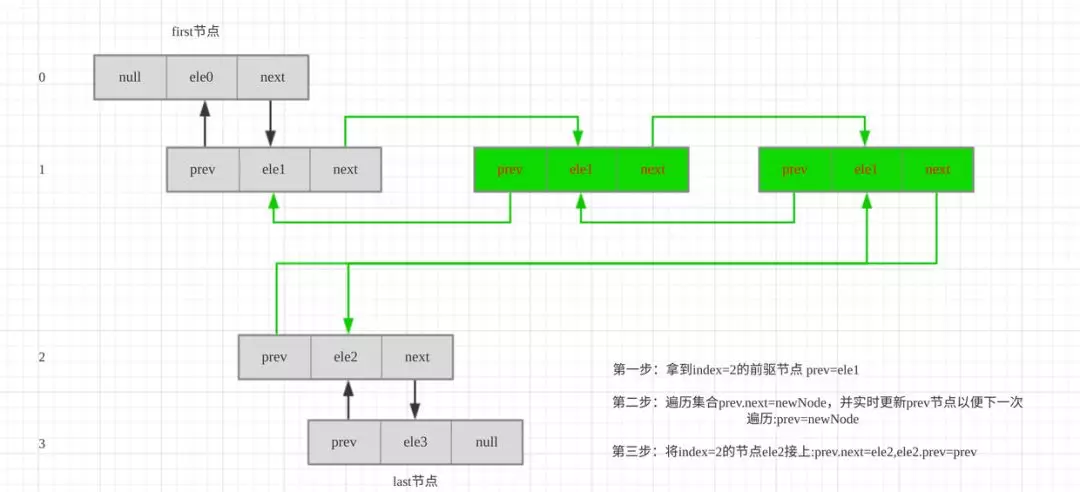
注意node(index)方法:方法:寻找处于index的节点,有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
b、addFirst(E e)方法
将e元素添加到链表并设置其为头节点(first)。
public void addFirst(E e) {
linkFirst(e);
}
//将e链接成列表的第一个元素
private void linkFirst(E e) {
final Node<E> f = first;
// 前驱为空,值为e,后继为f
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
//若f为空,则表明列表中还没有元素,last也应该指向newNode
if (f == null)
last = newNode;
else
//否则,前first的前驱指向newNode
f.prev = newNode;
size++;
modCount++;
}
拿到first节点命名为f
新创建一个节点newNode设置其next节点为f节点
将newNode赋值给first
若f为空,则表明列表中还没有元素,last也应该指向newNode;否则,前first的前驱指向newNode。
图解如下:
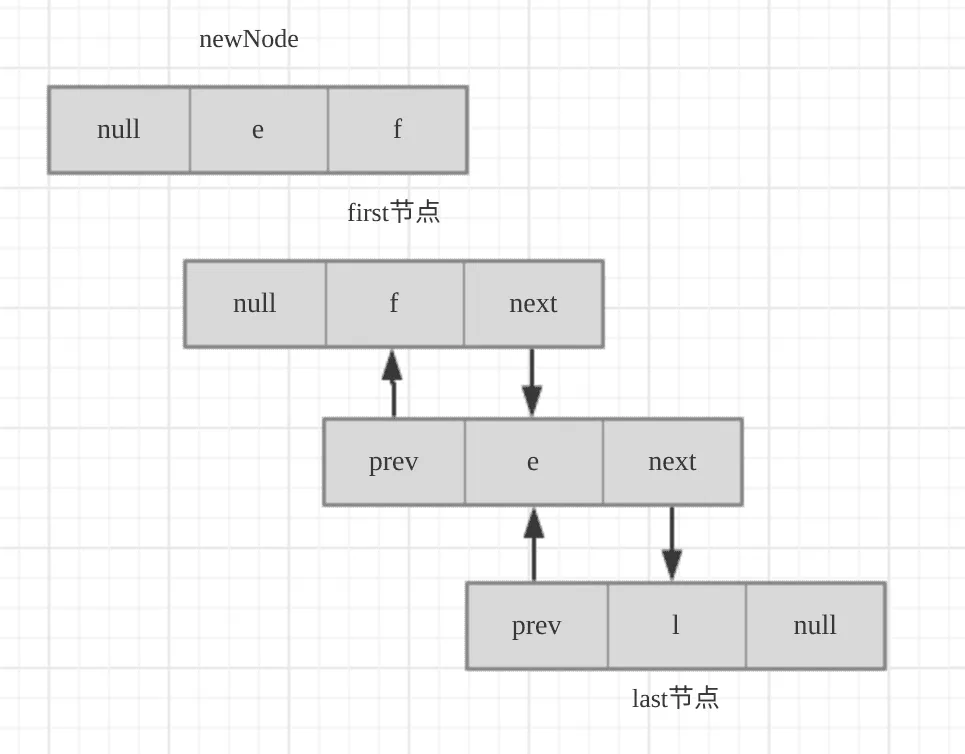

c、addLast(E e)方法
将e元素添加到链表并设置其为尾节点(last)。
public void addLast(E e) {
linkLast(e);
}
/**
* 将e链接成列表的last元素
*/
void linkLast(E e) {
final Node<E> l = last;
// 前驱为前last,值为e,后继为null
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
//最后一个节点为空,说明列表中无元素
if (l == null)
//first同样指向此节点
first = newNode;
else
//否则,前last的后继指向当前节点
l.next = newNode;
size++;
modCount++;
}
过程与linkFirst()方法类似,这里略过。
d、add(E e)方法
在尾部追加元素e。
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
// 前驱为前last,值为e,后继为null
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
//最后一个节点为空,说明列表中无元素
if (l == null)
//first同样指向此节点
first = newNode;
else
//否则,前last的后继指向当前节点
l.next = newNode;
size++;
modCount++;
}
e、add(int index, E element)方法
在链表的index处添加元素element.
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
* 在succ节点前增加元素e(succ不能为空)
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
// 拿到succ的前驱
final Node<E> pred = succ.prev;
// 新new节点:前驱为pred,值为e,后继为succ
final Node<E> newNode = new Node<>(pred, e, succ);
// 将succ的前驱指向当前节点
succ.prev = newNode;
// pred为空,说明此时succ为首节点
if (pred == null)
// 指向当前节点
first = newNode;
else
// 否则,将succ之前的前驱的后继指向当前节点
pred.next = newNode;
size++;
modCount++;
}
5、获取/查询元素
a、get(int index)
根据索引获取链表中的元素。
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
// 检测index合法性
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
// 根据index 获取元素
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
b、getFirst()方法
获取头节点。
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
c、getLast()方法
获取尾节点。
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
6、删除元素
a、remove(Object o)
根据Object对象删除元素。
public boolean remove(Object o) {
// 如果o是空
if (o == null) {
// 遍历链表查找 item==null 并执行unlink(x)方法删除
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
// 保存x的元素值
final E element = x.item;
//保存x的后继
final Node<E> next = x.next;
//保存x的前驱
final Node<E> prev = x.prev;
//如果前驱为null,说明x为首节点,first指向x的后继
if (prev == null) {
first = next;
} else {
//x的前驱的后继指向x的后继,即略过了x
prev.next = next;
// x.prev已无用处,置空引用
x.prev = null;
}
// 后继为null,说明x为尾节点
if (next == null) {
// last指向x的前驱
last = prev;
} else {
// x的后继的前驱指向x的前驱,即略过了x
next.prev = prev;
// x.next已无用处,置空引用
x.next = null;
}
// 引用置空
x.item = null;
size--;
modCount++;
// 返回所删除的节点的元素值
return element;
}
遍历链表查找 item==null 并执行unlink(x)方法删除
如果前驱为null,说明x为首节点,first指向x的后继,x的前驱的后继指向x的后继,即略过了x.
如果后继为null,说明x为尾节点,last指向x的前驱;否则x的后继的前驱指向x的前驱,即略过了x,置空x.next
引用置空:
x.item = null图解:
b、remove(int index)方法
根据链表的索引删除元素。
public E remove(int index) {
checkElementIndex(index);
//node(index)会返回index对应的元素
return unlink(node(index));
}
c、removeLast()方法
删除尾节点。
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
// 取出尾节点中的元素
final E element = l.item;
// 取出尾节点中的后继
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
// last指向前last的前驱,也就是列表中的倒数2号位
last = prev;
// 如果此时倒数2号位为空,那么列表中已无节点
if (prev == null)
// first指向null
first = null;
else
// 尾节点无后继
prev.next = null;
size--;
modCount++;
// 返回尾节点保存的元素值
return element;
}
7、修改元素
修改元素比较简单,先找到index对应节点,然后对值进行修改。
public E set(int index, E element) {
checkElementIndex(index);
// 获取到需要修改元素的节点
Node<E> x = node(index);
// 保存之前的值
E oldVal = x.item;
// 执行修改
x.item = element;
// 返回旧值
return oldVal;
}
LinkedList优点:不需要扩容和预留空间,空间效率高。
三、ArrayList与LinkedList插入和查找消耗时间测试对比
参考链接:https://blog.csdn.net/dearKundy/article/details/84663512
在ArrayList和LinkedList的头部、尾部和中间三个位置插入与查找100000个元素所消耗的时间来进行对比测试,下面是测试结果:(时间单位ms)
| 插入 | 查找 | |
| ArrayList尾部 | 26 | 12 |
| ArrayList头部 | 859 | 7 |
| ArrayList中间 | 1848 | 13 |
| LinkedList尾部 | 28 | 9 |
| LinkedList头部 | 15 | 11 |
| LinkedList中间 | 15981 | 34928 |
测试结论:
ArrayList的查找性能绝对是一流的,无论查询的是哪个位置的元素
ArrayList除了尾部插入的性能较好外(位置越靠后性能越好),其他位置性能就不如人意了
LinkedList在头尾查找、插入性能都是很棒的,但是在中间位置进行操作的话,性能就差很远了,而且跟ArrayList完全不是一个量级的
根据源码分析所得结论:
- 对于LinkedList来说,头部插入和尾部插入时间复杂度都是O(1)
- 但是对于ArrayList来说,头部的每一次插入都需要移动size-1个元素,效率可想而知
- 但是如果都是在最中间的位置插入的话,ArrayList速度比LinkedList的速度快将近10倍
Java集合之ArrayList与LinkList的更多相关文章
- 从源码看Java集合之ArrayList
Java集合之ArrayList - 吃透增删查改 从源码看初始化以及增删查改,学习ArrayList. 先来看下ArrayList定义的几个属性: private static final int ...
- Java:List,ArrayList和LinkList的区别
1.大学数据结构中ArrayList是实现了基于动态数组的数据结构,LinkList基于链表的数据结构 2.对于随机访问get和set,ArrayList优于LinkList,因为LinkedList ...
- Java集合关于ArrayList
ArrayList实现源码分析 2016-04-11 17:52 by 淮左, 207 阅读, 0 评论, 收藏, 编辑 本文将以以下几个问题来探讨ArrayList的源码实现1.ArrayList的 ...
- Java集合干货——ArrayList源码分析
ArrayList源码分析 前言 在之前的文章中我们提到过ArrayList,ArrayList可以说是每一个学java的人使用最多最熟练的集合了,但是知其然不知其所以然.关于ArrayList的具体 ...
- java集合之ArrayList,TreeSet和HashMap分析
java集合是一个重点和难点,如果我们刻意记住所有的用法与区别则是不太现实的,之前一直在使用相关的集合类,但是没有仔细研究区别,现在来把平时使用比较频繁的一些集合做一下分析和总结,目的就是以后在需要使 ...
- Java集合:ArrayList的实现原理
Java集合---ArrayList的实现原理 目录: 一. ArrayList概述 二. ArrayList的实现 1) 私有属性 2) 构造方法 3) 元素存储 4) 元素读取 5) 元素删除 ...
- 【源码阅读】Java集合之一 - ArrayList源码深度解读
Java 源码阅读的第一步是Collection框架源码,这也是面试基础中的基础: 针对Collection的源码阅读写一个系列的文章,从ArrayList开始第一篇. ---@pdai JDK版本 ...
- Java集合(六)--ArrayList、LinkedList和Vector对比
在前两篇博客,学习了ArrayList和LinkedList的源码,地址在这: Java集合(五)--LinkedList源码解读 Java集合(四)--基于JDK1.8的ArrayList源码解读 ...
- Java 集合源代码——ArrayList
(1)可以查看大佬们的 详细源码解析 : 连接地址为 : https://blog.csdn.net/zhumingyuan111/article/details/78884746 (2) Array ...
随机推荐
- 南阳ACM 题目275:队花的烦恼一 Java版
队花的烦恼一 时间限制:3000 ms | 内存限制:65535 KB 难度:1 描述 ACM队的队花C小+经常抱怨:"C语言中的格式输出中有十六.十.八进制输出,然而却没有二进制输出, ...
- java web中resources路径
UserBean.class.getClassLoader().getResource(filePath).getPath() 或者 Thread.currentThread().getContext ...
- 51Nod 1344 走格子 | 贪心
Input示例 5 1 -2 -1 3 4 Output示例 2 贪心 #include <bits/stdc++.h> using namespace std; typedef long ...
- linux sh脚本异常:/bin/sh^M:bad interpreter: No such file or directory
在Linux中执行.sh脚本,异常/bin/sh^M: bad interpreter: No such file or directory.这是不同系统编码格式引起的:在windows系统中编辑的. ...
- MyBatis框架的使用及源码分析(九) Executor
从<MyBatis框架的使用及源码分析(八) MapperMethod>文中我们知道执行Mapper的每一个接口方法,最后调用的是MapperMethod.execute方法.而当执行Ma ...
- 【BZOJ4819】【SDOI2017】新生舞会 [费用流][分数规划]
新生舞会 Time Limit: 10 Sec Memory Limit: 128 MB[Submit][Status][Discuss] Description 学校组织了一次新生舞会,Cathy ...
- bzoj 1594: [Usaco2008 Jan]猜数游戏——二分+线段树
Description 为了提高自己低得可怜的智商,奶牛们设计了一个新的猜数游戏,来锻炼她们的逻辑推理能力. 游戏开始前,一头指定的奶牛会在牛棚后面摆N(1 <= N<= 1,000,00 ...
- lua滚动文字效果
基本的思想都是创建一个clippingNode,将要截取的节点添加到clippingNode中,节点加上action即可. 下面是左右滚动的代码,如果是上下滚动,更简单了,只需修改Y坐标即可,都不用动 ...
- 【转】IOS版本自定义字体步骤
本文转载自:http://quick.cocoachina.com/wiki/doku.php?id=ios%E7%89%88%E6%9C%AC%E4%BD%BF%E7%94%A8%E8%87%AA% ...
- 项目记录 -- zpool set
zfs set <property=value> <filesystem|volume|snapshot> root@UA4300D-spa:~/hanhuakai/pro_0 ...