day5-xml模块
一、简述
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。它用于不同语言或者程序之间进行数据交换,从这点上讲与json差不多,只不过json看起来更美观、可读性更强。另外json诞生的时间并不是很久,在json出现以前,数据交换只能选择xml,即便是json已经在大面积使用的现在,xml依然被广泛使用,java项目中随处可见啊。
二、xml的结构
先来看一个栗子把:
1 <?xml version="1.0"?>
2 <data>
3 <country name="Liechtenstein">
4 <rank updated="yes">2</rank>
5 <year>2008</year>
6 <gdppc>141100</gdppc>
7 <neighbor name="Austria" direction="E"/>
8 <neighbor name="Switzerland" direction="W"/>
9 </country>
10 <country name="Singapore">
11 <rank updated="yes">5</rank>
12 <year>2011</year>
13 <gdppc>59900</gdppc>
14 <neighbor name="Malaysia" direction="N"/>
15 </country>
16 <country name="Panama">
17 <rank updated="yes">69</rank>
18 <year>2011</year>
19 <gdppc>13600</gdppc>
20 <neighbor name="Costa Rica" direction="W"/>
21 <neighbor name="Colombia" direction="E"/>
22 </country>
23 </data>
OK,从结构上,它很像我们常见的HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。
结构特征解读如下:
- 它由成对的标签组成 <data></data>
一级标签称为根节点,其他级别的标签称为节点 - 标签可以有属性 <country name="Panama">
- 标签对可以嵌入数据 <year>2011</year>
嵌入的数据即为节点的值 - 标签可以嵌入子标签(具有层级关系)
三、通过python操作xml文件
就以上面的xml文件为例来看看怎么通过python操作xml文件把。
3.1 读取xml文件内容
1 import xml.etree.ElementTree as et
2 tree = et.parse('test.xml')
3 root = tree.getroot() #获取根节点
4 print(root.tag) #打印根节点
5
6
7 for child in root:
8 print('-----')
9 print('\t', child.tag, child.attrib) #分别打印子节点名称和子节点属性
10 #遍历子节点下的所有节点
11 for i in child:
12 print('\t\t', i.tag, i.text, i.attrib) #打印子节点下节点的节点名、节点值和属性
13 #只遍历year节点
14 for i in child.iter('year'):
15 print('\t\t\t', i.tag, i.text)
16
17 print('')
18 for node in root.iter('year'): #从根节点上直接遍历year节点
19 print(node.tag, node.text)
20
21 程序输出:
22 data
23 -----
24 country {'name': 'Liechtenstein'}
25 rank 2 {'updated': 'yes'}
26 year 2008 {}
27 gdppc 141100 {}
28 neighbor None {'name': 'Austria', 'direction': 'E'}
29 neighbor None {'name': 'Switzerland', 'direction': 'W'}
30 year 2008
31 -----
32 country {'name': 'Singapore'}
33 rank 5 {'updated': 'yes'}
34 year 2011 {}
35 gdppc 59900 {}
36 neighbor None {'name': 'Malaysia', 'direction': 'N'}
37 year 2011
38 -----
39 country {'name': 'Panama'}
40 rank 69 {'updated': 'yes'}
41 year 2011 {}
42 gdppc 13600 {}
43 neighbor None {'name': 'Costa Rica', 'direction': 'W'}
44 neighbor None {'name': 'Colombia', 'direction': 'E'}
45 year 2011
46
47 year 2008
48 year 2011
49 year 2011
50
2 tree = et.parse('test.xml')
3 root = tree.getroot() #获取根节点
4 print(root.tag) #打印根节点
5
6
7 for child in root:
8 print('-----')
9 print('\t', child.tag, child.attrib) #分别打印子节点名称和子节点属性
10 #遍历子节点下的所有节点
11 for i in child:
12 print('\t\t', i.tag, i.text, i.attrib) #打印子节点下节点的节点名、节点值和属性
13 #只遍历year节点
14 for i in child.iter('year'):
15 print('\t\t\t', i.tag, i.text)
16
17 print('')
18 for node in root.iter('year'): #从根节点上直接遍历year节点
19 print(node.tag, node.text)
20
21 程序输出:
22 data
23 -----
24 country {'name': 'Liechtenstein'}
25 rank 2 {'updated': 'yes'}
26 year 2008 {}
27 gdppc 141100 {}
28 neighbor None {'name': 'Austria', 'direction': 'E'}
29 neighbor None {'name': 'Switzerland', 'direction': 'W'}
30 year 2008
31 -----
32 country {'name': 'Singapore'}
33 rank 5 {'updated': 'yes'}
34 year 2011 {}
35 gdppc 59900 {}
36 neighbor None {'name': 'Malaysia', 'direction': 'N'}
37 year 2011
38 -----
39 country {'name': 'Panama'}
40 rank 69 {'updated': 'yes'}
41 year 2011 {}
42 gdppc 13600 {}
43 neighbor None {'name': 'Costa Rica', 'direction': 'W'}
44 neighbor None {'name': 'Colombia', 'direction': 'E'}
45 year 2011
46
47 year 2008
48 year 2011
49 year 2011
50
说明:
1. getroot()用于返回根节点,tag返回节点名,attrib返回节点属性,text返回节点的值
2. 只返回某个节点的信息,使用iter(节点名)即可
3.2 修改xml文件内容
1 import xml.etree.ElementTree as et
2 tree = et.parse('test.xml')
3 root = tree.getroot()
4
5 print(type(root.iter('year')))
6 for node in root.iter('year'):
7 new_year = int(node.text) + 1
8 node.text = str(new_year) #修改节点值
9 node.tag = 'next_year' #修改节点名称
10 node.set('Maxwell','handsome') #修改节点属性
11
12 tree.write('test2.xml') #保存文件
2 tree = et.parse('test.xml')
3 root = tree.getroot()
4
5 print(type(root.iter('year')))
6 for node in root.iter('year'):
7 new_year = int(node.text) + 1
8 node.text = str(new_year) #修改节点值
9 node.tag = 'next_year' #修改节点名称
10 node.set('Maxwell','handsome') #修改节点属性
11
12 tree.write('test2.xml') #保存文件
注意最后一步保存操作不能漏掉!
修改的实际效果如下: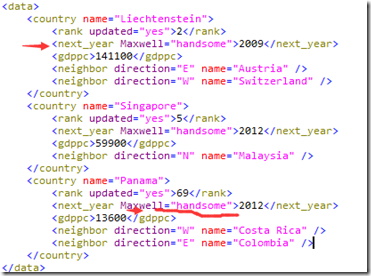
3.3 删除xml节点
1 import xml.etree.ElementTree as et
2
3 tree = et.parse('test.xml')
4 root = tree.getroot()
5
6
7 for country in root.findall('country'): #查找第一层子节点
8 rank = int(country.find('rank').text) #查找子节点下的子节点
9 if rank > 50:
10 root.remove(country) #删除符合条件的节点
11
12 tree.write('test2.xml')
2
3 tree = et.parse('test.xml')
4 root = tree.getroot()
5
6
7 for country in root.findall('country'): #查找第一层子节点
8 rank = int(country.find('rank').text) #查找子节点下的子节点
9 if rank > 50:
10 root.remove(country) #删除符合条件的节点
11
12 tree.write('test2.xml')
注意:
- findall()从根节点只能根据第一层的子节点名查找,并且返回第一层子节点的内存地址
- 删除节点用remove()方法
- 删除后需要write保存
3.4 创建新的xml文件
1 import xml.etree.ElementTree as et
2
3 #创建根节点
4 new_xml = et.Element('profile')
5 #创建根节点的第一层子节点,参数依次表示父节点,子节点名称,子节点属性
6 name = et.SubElement(new_xml, 'name', attrib={'Luzhishen':'HuaHeSang'})
7 age = et.SubElement(name, 'age', attrib={'adult':'yes'})
8 #设置子节点的值
9 age.text = '22'
10 gender = et.SubElement(name, 'gender')
11 gender.text = 'man'
12 #创建第二个根节点的第一层子节点
13 name2 = et.SubElement(new_xml, 'name', attrib={'WuYong':'Zhiduoxing'})
14 age2 = et.SubElement(name2, 'age')
15 age2.text = '23'
16
17 #生成新的xml文档
18 ET = et.ElementTree(new_xml)
19 #保存文档
20 ET.write('my.xml', encoding='utf-8', xml_declaration='true')
21 #打印文档格式
22 et.dump(new_xml)
2
3 #创建根节点
4 new_xml = et.Element('profile')
5 #创建根节点的第一层子节点,参数依次表示父节点,子节点名称,子节点属性
6 name = et.SubElement(new_xml, 'name', attrib={'Luzhishen':'HuaHeSang'})
7 age = et.SubElement(name, 'age', attrib={'adult':'yes'})
8 #设置子节点的值
9 age.text = '22'
10 gender = et.SubElement(name, 'gender')
11 gender.text = 'man'
12 #创建第二个根节点的第一层子节点
13 name2 = et.SubElement(new_xml, 'name', attrib={'WuYong':'Zhiduoxing'})
14 age2 = et.SubElement(name2, 'age')
15 age2.text = '23'
16
17 #生成新的xml文档
18 ET = et.ElementTree(new_xml)
19 #保存文档
20 ET.write('my.xml', encoding='utf-8', xml_declaration='true')
21 #打印文档格式
22 et.dump(new_xml)
创建的xml文档格式:

可以看出与一般的xml文件相比就差缩进了,不过不影响数据交换啦。
注意:
SubElement()方法用于创建新的节点,它的第一个参数决定了新节点属于什么节点的子节点。
day5-xml模块的更多相关文章
- oop、configparser、xml模块
本节大纲:一:在python中,有两种编程思想.1:函数式编程.2:oop.无论是函数式编程还是oop都是相辅相成.并不是说oop比函数式编程就好.各有各的优缺点.在其他语言中java等只能以面向对象 ...
- python解析xml模块封装代码
在python中解析xml文件的模块用法,以及对模块封装的方法.原文转自:http://www.jbxue.com/article/16586.html 有如下的xml文件:<?xml vers ...
- python 学习day5(模块)
一.模块介绍 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能 ...
- s14 第5天 时间模块 随机模块 String模块 shutil模块(文件操作) 文件压缩(zipfile和tarfile)shelve模块 XML模块 ConfigParser配置文件操作模块 hashlib散列模块 Subprocess模块(调用shell) logging模块 正则表达式模块 r字符串和转译
时间模块 time datatime time.clock(2.7) time.process_time(3.3) 测量处理器运算时间,不包括sleep时间 time.altzone 返回与UTC时间 ...
- python全栈开发-hashlib模块(数据加密)、suprocess模块、xml模块
一.hashlib模块 1.什么叫hash:hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 ...
- 【python标准库模块五】Xml模块学习
Xml模块 xml本身是一种格式规范,是一种包含了数据以及数据说明的文本格式规范.在json没有兴起之前各行各业进行数据交换的时候用的就是这个.目前在金融行业也在广泛在运用. 举个简单的例子,xml是 ...
- Python xml 模块
Python xml 模块 TOC 什么是xml? xml和json的区别 xml现今的应用 xml的解析方式 xml.etree.ElementTree SAX(xml.parsers.expat) ...
- python之xml模块
# XML 模块的操作参考链接 # http://www.cnblogs.com/yuanchenqi/articles/5732581.html
- python 之路 day5 - 常用模块
模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configparser has ...
- hashlib,hmac,subprocess,configparser,xlrd,xlwt,xml模块基本功能
hashlib模块:加密 import hashlib# 基本使用cipher = hashlib.md5('需要加密的数据的二进制形式'.encode('utf-8'))print(cipher.h ...
随机推荐
- Springboot入门-日志框架配置(转载)
默认情况下,Spring Boot会用Logback来记录日志,并用INFO级别输出到控制台. Logback是log4j框架的作者开发的新一代日志框架,它效率更高.能够适应诸多的运行环境,同时天然支 ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- [Python] Send emails to the recepients specified in Message["CC"]
Recently, I'm working on a small program which needs to send emails to specific accounts. When I wan ...
- HackerRank - common-child【DP】
HackerRank - common-child[DP] 题意 给出两串长度相等的字符串,找出他们的最长公共子序列e 思路 字符串版的LCS AC代码 #include <iostream&g ...
- iOS 多线程安全 与 可变字典
这周最大的收获是稍稍通透了 多线程安全字典的重要性. 诱因是,发现了有字典坏地址错误 果断以为是 value 或者 key 是可能出现了空值,补充了潜在的判断,虽然有的位置已经预判断的,但 ...
- poj2993
#include<stdio.h> #include<string.h> #include<algorithm> using namespace std; stru ...
- Nginx 限制php解析、限制浏览器访问
限制php解析 1.有时候会根据目录来限制php解析: location ~ .*(diy|template|attachments|forumdata|attachment|image)/.*\.p ...
- Your app uses or references the following non-public APIs的解决方案
之前接了一个旧的项目,代码混乱,年代久远,不得不吐槽一波,好不容易改完需求提交代码,说用到了non-public APIs,搞了好久终于找到地方了,下面是我的解决过程,让大家少走弯路: 下面的被驳回的 ...
- JAVA基础补漏--static
静态方法不能访问非静态变量的原因 静态的方法和变量在内存中先产生,非静态的后产生,在静态调用时非静态可能还未创建,所以会发生错误,故不能访问. static的内存图 静态代码块 static { Sy ...
- nagios无法载入静态资源
使用nginx+nagios无法载入静态资源,看了下url中增加了一个/nagios 查看是/usr/local/nagios/etc/cgi.conf中url_html_path=/nagios 将 ...