JDK源码学习笔记——LinkedHashMap
HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。
LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。通过维护一个双向链表实现。
需要在理解HashMap实现原理的基础上学习LinkedHashMap,JDK源码学习笔记——HashMap
一、数据结构
实际上就是在HashMap的基础上加了LinkedList

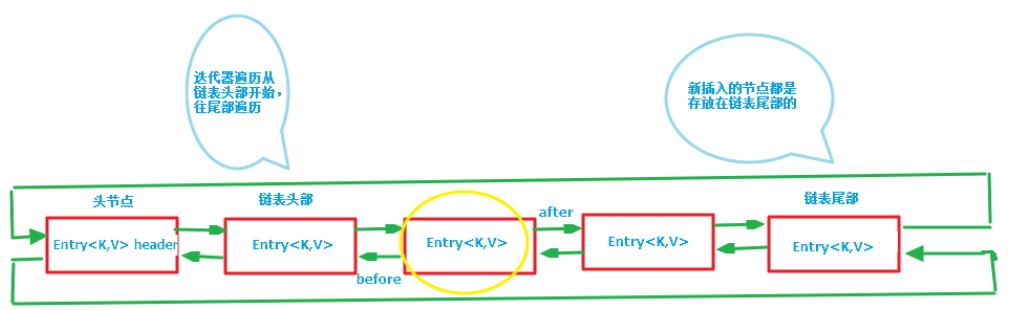
(图片来自Java集合之LinkedHashMap)
LinkedHashMap.Entry继承了HashMap.Node,并扩展了before ,after属性
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
二、类
继承了HashMap
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
三、属性
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
final boolean accessOrder;//true表示按照访问顺序迭代(最近访问在后),false时表示按照插入顺序(先插入在前,默认)
四、主要方法
put
/**
* 直接使用HashMap的put方法
* 重写了newNode()方法:维护双向链表
* 重写了afterNodeAccess(e)方法:如果按访问顺序排序,把node移动到双链表的尾端
*/
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
} void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
get
/**
* 重写了get方法
* 如果按访问顺序排序,把node移动到双链表的尾端
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);// 如果按访问顺序排序,把node移动到双链表的尾端
return e.value;
}
remove
/**
* 直接使用HashMap的remove方法
* 重写了afterNodeRemoval()方法:维护双端链表
*/
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
遍历
/**
* 主要看nextNode()方法
* 直接遍历的双向链表
*/
final class LinkedKeyIterator extends LinkedHashIterator implements Iterator<K> {
public final K next() {
return nextNode().getKey();
}
} final class LinkedValueIterator extends LinkedHashIterator implements Iterator<V> {
public final V next() {
return nextNode().value;
}
} final class LinkedEntryIterator extends LinkedHashIterator implements Iterator<Map.Entry<K, V>> {
public final Map.Entry<K, V> next() {
return nextNode();
}
} abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount; LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
} public final boolean hasNext() {
return next != null;
} final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
} public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
JDK源码学习笔记——LinkedHashMap的更多相关文章
- jdk源码阅读笔记-LinkedHashMap
Map是Java collection framework 中重要的组成部分,特别是HashMap是在我们在日常的开发的过程中使用的最多的一个集合.但是遗憾的是,存放在HashMap中元素都是无序的, ...
- JDK源码学习笔记——String
1.学习jdk源码,从以下几个方面入手: 类定义(继承,实现接口等) 全局变量 方法 内部类 2.hashCode private int hash; public int hashCode() { ...
- JDK源码学习笔记——Integer
一.类定义 public final class Integer extends Number implements Comparable<Integer> 二.属性 private fi ...
- JDK源码学习笔记——Enum枚举使用及原理
一.为什么使用枚举 什么时候应该使用枚举呢?每当需要一组固定的常量的时候,如一周的天数.一年四季等.或者是在我们编译前就知道其包含的所有值的集合. 利用 public final static 完全可 ...
- JDK源码学习笔记——Object
一.源码解析 public class Object { /** * 一个本地方法,具体是用C(C++)在DLL中实现的,然后通过JNI调用 */ private static native void ...
- JDK源码学习笔记——HashMap
Java集合的学习先理清数据结构: 一.属性 //哈希桶,存放链表. 长度是2的N次方,或者初始化时为0. transient Node<K,V>[] table; //最大容量 2的30 ...
- JDK源码学习笔记——HashSet LinkedHashSet TreeSet
你一定听说过HashSet就是通过HashMap实现的 相信我,翻一翻HashSet的源码,秒懂!! 其实很多东西,只是没有静下心来看,只要去看,说不定一下子就明白了…… HashSet 两个属性: ...
- JDK源码学习笔记——TreeMap及红黑树
找了几个分析比较到位的,不再重复写了…… Java 集合系列12之 TreeMap详细介绍(源码解析)和使用示例 [Java集合源码剖析]TreeMap源码剖析 java源码分析之TreeMap基础篇 ...
- JDK源码学习笔记——LinkedList
一.类定义 public class LinkedList<E> extends AbstractSequentialList<E> implements List<E& ...
随机推荐
- Android跳转到拨打电话的页面
在Android6.0之后,拨打电话需要用户授予动态权限,项目中有此需求,有一种简单的方法,直接携带电话号码跳转到系统拨打电话的页面,很多应用也是这么做的,这样可以减轻工作量 代码如下: Androi ...
- 我的spring boot,杨帆、起航!
快速新建一个spring boot工程可以去http://start.spring.io/这个网址,配置完后会自动下载一个工程的压缩包,解压后导入相关ide工具即可使用. 工程中会自带一个class启 ...
- Bagging和Boosting 概念及区别(转)
Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法.即将弱分类器组装成强分类器的方法. 首先介绍Boot ...
- 概率DP入门学习QAQ
emmmm博客很多都烂尾了...但是没空写..先写一下正在学的东西好了 概率DP这东西每次考到都不会..听题解也是一脸懵逼..所以决定学习一下这个东东..毕竟NOIP考过...比什么平衡树实在多了QA ...
- python基础===进程,线程,协程的区别(转)
本文转自:http://blog.csdn.net/hairetz/article/details/16119911 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度. 线程拥有自 ...
- problems when installed mysql in linux ubuntu
reference:http://www.jb51.net/article/87160.htm?pc 1.ERROR 2002 (HY000): Can't connect to local MySQ ...
- JS中类型检测方式
在js中的类型检测目前我所知道的是三种方式,分别有它们的应用场景: 1.typeof:主要用于检测基本类型. typeof undefined;//=> undefined typeof 'a' ...
- artDialog的一些例子与一些属性的介绍。
1.支持自定义按钮 var dialog = art.dialog({ title: '警告', content: '点击管理按钮将让删除按钮可用', width: '20em', button: [ ...
- 20:django中的安全问题
本节主要是讲解django中的安全特性,讲述django是如何应对网站一般面临的安全性问题 跨站点脚本(XXS)攻击 跨站点脚本攻击是指一个用户把客户端脚本注入到其他用户的浏览器中.通常是通过在数据库 ...
- Activiti如何替换已部署流程图
首先交代下背景:我们有一个已经上线的activiti工作流系统,对于流程图的操作已经封装好部署,查看,删除的接口.此时客户提出要修改个别流程图里的节点名称. 我的第一个想法就是本地修改流程图bpmn文 ...