在ubuntu下使用Eclipse搭建Hadoop开发环境
一、安装准备
1、JDK版本:jdk1.7.0(jdk-7-linux-i586.tar.gz)
2、hadoop版本:hadoop-1.1.1(hadoop-1.1.1.tar.gz)
3、eclipse版本:Eclipse Java EE IDE for Web Developers.
Version: Juno Service Release 1
Build id: 20120920-0800(eclipse-jee-juno-SR1-linux-gtk.tar.gz)
4、eclipse与hadoop集成插件:hadoop-eclipse-plugin-1.1.1.jar
5、操作系统:ubuntu10.10
注:jdk、hadoop、eclipse、hadoop-eclipse-plugin存在兼容问题,建议大家按上面的版本进行实践(本人在搭建该环境时吃了不少亏~~)。
二、安装操作
1、安装JDK,此步省略…(不懂的点击这里 )。
2、安装hadoop,此步省略…(不懂的点击这里 )。
3、安装eclipse,操作步骤如下:
1)、把安装文件拷贝到home目录下
cp eclipse-jee-juno-SR1-linux-gtk.tar.gz /home
2)、安装eclipse(即解压就可使用)
tar -zxvf eclipse-jee-juno-SR1-linux-gtk.tar.gz
4)、启动eclipse,并创建workspace作为eclipse的工作空间
cd /home/eclipse #切换到eclipse目录下
./eclipse
三、配置Eclipse、Hadoop开发环境
第一步:安装Eclipse-Hadoophadoop集成插件
把hadoop-eclipse-plugin-1.1.1.jar插件放到/home/eclipse/plugins中,然后重新启动Eclipse如下图。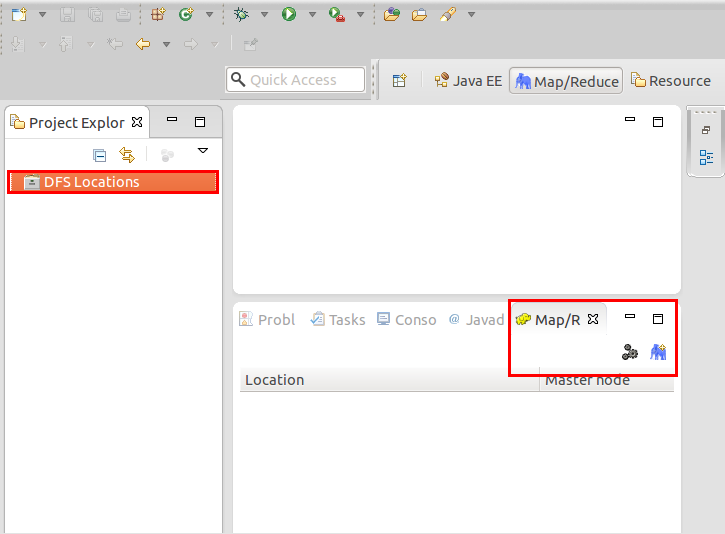
细心的你从上图左侧“Project Explorer”下面发现“DFS Locations”,说明Eclipse已经识别刚才放入的Hadoop Eclipse插件了。
第二步:在Eclipse中指定Hadoop的安装目录
选择“Window”菜单下的“Preference”,然后弹出一个窗体,在窗体的左侧中找到“Hadoop Map/Reduce”选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:/home/hadoop/hadoop-1.1.1)。结果如下图: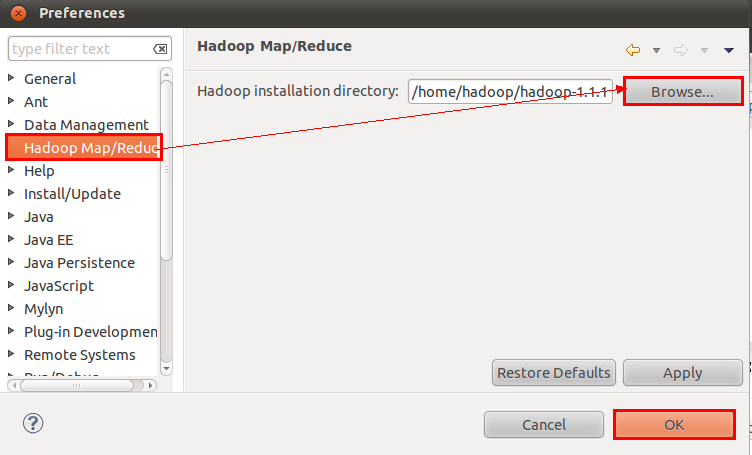
第三步:切换“Map/Reduce”工作目录
有两种方法:
1)、选择“Window”菜单下选择“Open Perspective–>Other”,弹出一个窗体,从中选择“Map/Reduce”选项即可进行切换。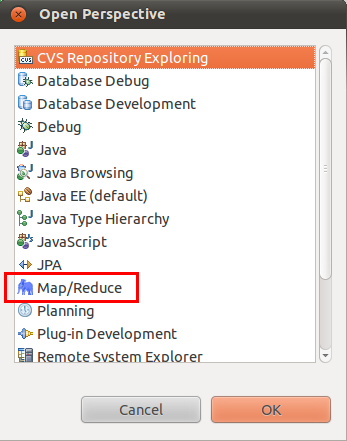
2)、在Eclipse软件的右上角,点击图标“ ”中的“
”中的“ ”,从中选择“Map/Reduce”,然后点击“OK”即可确定。
”,从中选择“Map/Reduce”,然后点击“OK”即可确定。
切换到“Map/Reduce”工作目录下的界面如下图所示。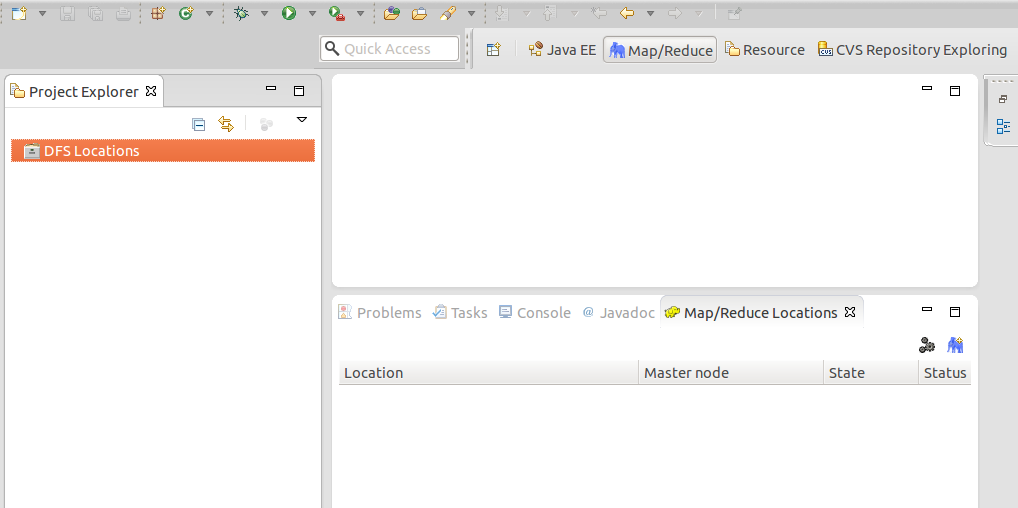
第四步:配置DFS Locations
建立与Hadoop集群的连接,在Eclipse软件下面的“Map/Reduce Locations”进行右击,弹出一个选项,选择“New Hadoop Location ”,然后弹出一个窗体。
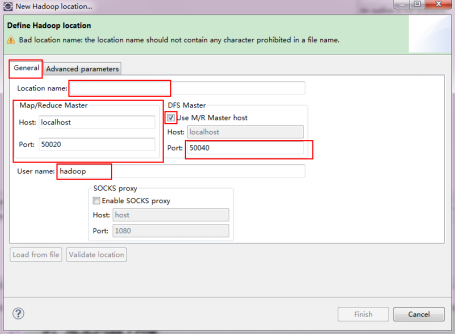
注意上图中的红色标注的地方,是需要我们关注的地方。
Location Name:可以任意填,标识一个“Map/Reduce Location”
Map/Reduce Master
Host:xx.xx.xx.xx(Master.Hadoop的IP地址,即/home/hadoop/hadoop-1.1.1/conf/mapred-site.xml中ip)
Port:xx(即/home/hadoop/hadoop-1.1.1/conf/mapred-site.xml中端口)
DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Host:xx.xx.xx.xx(/home/hadoop/hadoop-1.1.1/conf/core-site.xml中ip)
Port:xxxx (/home/hadoop/hadoop-1.1.1/conf/core-site.xml中端口)
User name:hadoop(操作hadoop的用户)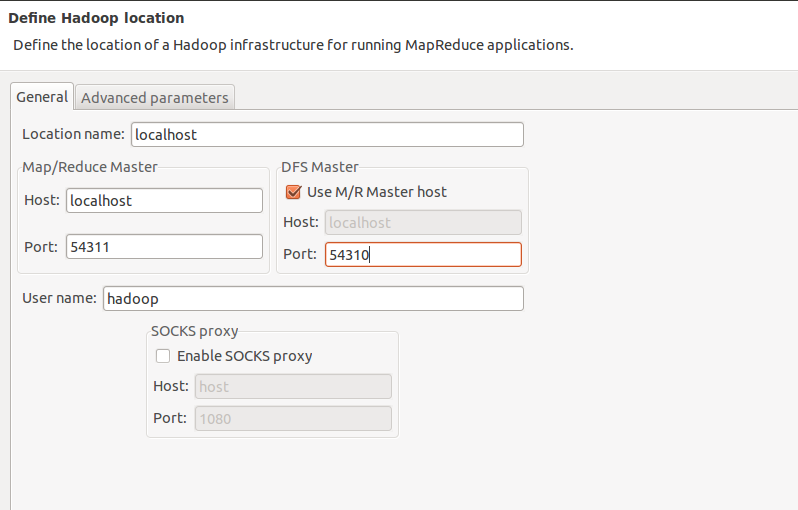
接着点击“Advanced parameters”从中找到“hadoop.tmp.dir”,修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是“/home/hadoop/hadoop-datastore/”,这个参数在“core-site.xml”进行了配置。
再从中找到“fs.default.name”,修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是“hdfs://localhost:54310”,这个参数在“core-site.xml”进行了配置。
点击“finish”之后,会发现Eclipse软件下面的“Map/Reduce Locations”出现一条信息, 就是我们刚才建立的“Map/Reduce Location ”。
第五步:查看HDFS文件系统
查看HDFS文件系统,点击Eclipse软件左侧的“DFS Locations”下面的“localhost”,就会展示出HDFS上的文件结构(记得要先启动hadoop,不然看不到效果)。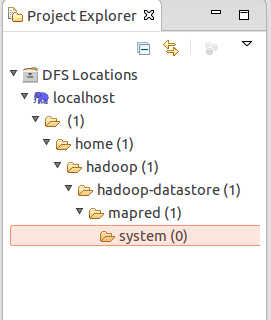
到此为止,我们的Hadoop Eclipse开发环境已经配置完毕。
在ubuntu下使用Eclipse搭建Hadoop开发环境的更多相关文章
- 【转】在Ubuntu下建立Eclipse的Android开发环境
本文将介绍如何建立Ubuntu下基于Eclipse的Android开发环境的方法. 大部分的Android开发者都是使用Eclipse来开发Android,本文将向各位介绍一下建立Ubuntu下基于E ...
- 【Hadoop】:Windows下使用IDEA搭建Hadoop开发环境
笔者鼓弄了两个星期,终于把所有有关hadoop的环境配置好了,一是虚拟机上的完全分布式集群,但是为了平时写代码的方便,则在windows上也配置了hadoop的伪分布式集群,同时在IDEA上就可以编写 ...
- 基于Eclipse搭建hadoop开发环境
一.基础环境准备 1.Eclipse 下载地址:http://pan.baidu.com/s/1slArxAP 2.JDK1.8 下载地址:http://pan.baidu.com/s/1i5iNy ...
- Ubuntu 14.04下安装eclipse搭建C++开发环境
安装过程分为两部分:1.JAVA开发环境,即JDK的安装:2.eclipse的安装: 一.安装包下载 1.JDK官网下载地址:http://www.oracle.com/technetwork/jav ...
- 在windows环境中用eclipse搭建hadoop开发环境
1. 整体环境和设置 1.1 hadoo1.0.4集群部署在4台VMWare虚拟机中,这四台虚拟机都是通过NAT模式连接主机 集群中/etc/hosts文件配置 #本机127.0.0.1 localh ...
- 详解Window10下使用IDEA搭建Hadoop开发环境
前言 经过三次重装,查阅无数资料后成功完成hadoop在win10上实现伪分布式集群,以及IDEA开发环境的搭建.一步一步跟着本文操作可以避免无数天坑. 下载安装Hadoop 下载安装包 进入官网下载 ...
- 使用eclipse搭建hadoop开发环境
下载一个 hadoop-eclipse-plugin-*.jar的eclipse插件,并放在plugins目录下 重启eclipse 打开视象,找“大象” 连接HDFS success 编程准 ...
- HBase学习3(win下使用Eclipse搭建hbase开发环境)
第一步:创建一个java project命名为wujiadong_hbase 第二步:在该工程下创建一个folder命名为lib(储存依赖的jar包) 第三步:将集群中的hbase安装目录下载一份到w ...
- Ubuntu下利用vim搭建python开发环境
1. 安装vim $ sudo apt-get install vim 2. 安装ctags,ctags用于支持taglist,必需! $ sudo apt-get install ctags 3. ...
随机推荐
- Kernel-----EXPORT_SYMBOL使用
EXPORT_SYMBOL只出现在2.6内核中,在2.4内核默认的非static 函数和变量都会自动 导入到kernel 空间的, 都不用EXPORT_SYMBOL() 做标记的. 2.6就必须用EX ...
- C/C++文件输入输出流
C++方式 C方式 头文件 fstream stdio.h open file.open(const char *filename,const char *mode) FILE* fo ...
- K8s集群安装--最新版 Kubernetes 1.14.1
K8s集群安装--最新版 Kubernetes 1.14.1 前言 网上有很多关于k8s安装的文章,但是我参照一些文章安装时碰到了不少坑.今天终于安装好了,故将一些关键点写下来与大家共享. 我安装是基 ...
- C# 根据实体类的属性动态生成字符串
情景: 目前有两个实体类:Student,ClassInfo. public class Student { public string Name { get; set; } public strin ...
- LeetCode 刷题指南(1):为什么要刷题
虽然刷题一直饱受诟病,不过不可否认刷题确实能锻炼我们的编程能力,相信每个认真刷题的人都会有体会.现在提供在线编程评测的平台有很多,比较有名的有 hihocoder,LintCode,以及这里我们关注的 ...
- Elasticsearch学习(2) windows环境下Elasticsearch同步mysql数据库
在上一章中,我们已经能够通过spring boot来使用Elasticsearch,但是由于我们习惯性的将数据写入mysql,所以为了解决这个问题,Elasticsearch为我们提供了一个插件log ...
- Logstash使用grok解析IIS日志
Logstash使用grok解析IIS日志 1. 安装配置 安装Logstash前请确认Elasticsearch已经安装正确,参见RedHat6.4安装Elasticsearch5.2.0. 下载链 ...
- [Flex] 组件Tree系列 —— 利用firstVisibleItem属性,设置或取得第一个显示节点
mxml: <?xml version="1.0" encoding="utf-8"?> <!--功能描述: 利用firstVisibleIt ...
- Badboy安装和介绍
Badboy安装和介绍 [前言] 欢迎来到我的博客 Badboy是用C++开发的动态应用测试工具,拥有强大的屏幕录制和回放功能,可提供图形结果分析功能,同时Badboy提供了将Web测试脚本直接导出生 ...
- 一步一步带你安装史上最难安装的 vim 插件 —— YouCompleteMe
YouCompleteMe is a fast, as-you-type, fuzzy-search code completion engine for Vim.参考: https://github ...