搭建Hadoop2.6.0+Spark1.1.0集群环境
前几篇文章主要介绍了单机模式的hadoop和spark的安装和配置,方便开发和调试。本文主要介绍,真正集群环境下hadoop和spark的安装和使用。
1. 环境准备
集群有三台机器:
master:W118PC01VM01/192.168.0.112
slave1:W118PC02VM01/192.168.0.113
slave2:W118PC03VM01/192.168.0.114
首先配置/etc/hosts中ip和主机名的映射关系:
|
192.168.0.112 W118PC01VM01 192.168.0.113 W118PC02VM01 192.168.0.114 W118PC03VM01 |
其次配置3台机器互相免密码ssh连接,参考《在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境》。
2. 基本安装步骤
(1) 安装Java(本例使用jdk1.7.0_55)和Scala(使用scala2.10.4)。
(2) 安装Hadoop2.6.0集群。
(3) 安装Spark1.1.0集群。
3. Jdk和Scala安装
在master和slave机器的安装路径和环境变量配置保持一致。安装过程参考《在Win7虚拟机下搭建Hadoop2.6.0+Spark1.4.0单机环境》。
4. Hadoop集群安装
4.1. 安装Hadoop并配置环境变量
安装Hadoop2.6.0版本,安装目录如下。在~/.bash_profile中配置环境变量,参考《在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境》。
4.2. 修改Hadoop配置文件
涉及到的hadoop配置文件主要有以下7个:
|
/home/ap/cdahdp/tools/hadoop/etc/hadoop/hadoop-env.sh /home/ap/cdahdp/tools/hadoop/etc/hadoop/yarn-env.sh /home/ap/cdahdp/tools/Hadoop/etc/hadoop/slaves /home/ap/cdahdp/tools/hadoop/etc/hadoop/core-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/hdfs-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/mapred-site.xml /home/ap/cdahdp/tools/hadoop/etc/hadoop/yarn-site.xml |
配置 hadoop-env.sh(修改JAVA_HOME)
|
# The java implementation to use. export JAVA_HOME=/home/ap/cdahdp/tools/jdk1.7.0_55 |
配置 yarn-env.sh (修改JAVA_HOME)
|
# some Java parameters export JAVA_HOME=/home/ap/cdahdp/tools/jdk1.7.0_55 |
配置slaves(增加slave节点)
|
W118PC02VM01 W118PC03VM01 |
配置 core-site.xml(增加hadoop核心配置)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.112:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/ap/cdahdp/app/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
配置hdfs-site.xml(增加hdfs配置信息,namenode、datanode端口和目录位置)
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.0.112:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/ap/cdahdp/app/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/ap/cdahdp/app/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.du.reserved</name>【配置磁盘中保留不用作hdfs集群的空间大小,单位是Byte】
<value>10240000000</value>
</property>
</configuration>
配置mapred-site.xml(增加mapreduce配置,使用yarn框架、jobhistory地址以及web地址)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.0.112:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.0.112:19888</value>
</property>
</configuration>
配置 yarn-site.xml(增加yarn功能)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.0.112:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.0.112:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.0.112:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.0.112:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.0.112:8088</value>
</property>
</configuration>
将配置好的hadoop文件copy到两台slave机器上,配置和路径和master一模一样。
4.3. 格式化namenode
在master和slave机器上分别操作:
|
cd ~/tools/hadoop/bin ./hdfs namenode -format |
4.4. 启停hdfs和yarn
|
cd ~/tools/hadoop/sbin ./start-hdfs.sh ./stop-hdfs.sh ./start-yarn.sh ./stop-yarn.sh |
启动后可以用jps查看进程,通常有这几个:
NameNode、SecondaryNameNode、ResourceManager、DataNode
如果启动异常,可以查看日志,在master机器的/home/ap/cdahdp/tools/hadoop/logs目录。
4.5. 查看集群状态
查看hdfs:http://192.168.0.112:50070/
查看RM:http://192.168.0.112:8088/
4.6. 运行wordcount示例程序
上传几个文本文件到hdfs,路径为/tmp/input/
之后运行:
查看执行结果:

正常运行,表示hadoop集群安装成功。
5. Spark集群部署
5.1. 安装Spark并配置环境变量
安装Spark1.1.0版本,安装目录如下。在~/.bash_profile中配置环境变量。
5.2. 修改Hadoop配置文件
配置slaves(增加slave节点)

配置spark-env.sh(设置spark运行的环境变量)
把spark-env.sh.template复制为spark-env.sh

将配置好的spark文件copy到两台slave机器上,配置和路径和master一模一样。
5.3. Spark的启停
|
cd ~/tools/spark/sbin ./start-all.sh ./stop-all.sh |
5.4. 查看集群状态
spark集群的web管理页面:http://192.168.0.112:8080/
spark WEBUI页面:http://192.168.0.112:4040/
启动spark-shell控制台:
5.5. 运行示例程序
往hdfs上上传一个文本文件README.txt:
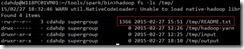
在spark-shell控制台执行:
统计README.txt中有多少单词:

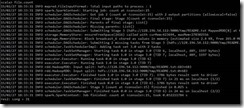
过滤README.txt包括The单词有多少行:
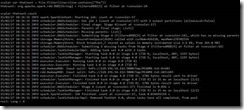
正常运行,表示Spark集群安装成功。
搭建Hadoop2.6.0+Spark1.1.0集群环境的更多相关文章
- Kubernetes的搭建与配置(一):集群环境搭建
1.环境介绍及准备: 1.1 物理机操作系统 物理机操作系统采用Centos7.3 64位,细节如下. [root@localhost ~]# uname -a Linux localhost.loc ...
- 搭建 MongoDB分片(sharding) / 分区 / 集群环境
1. 安装 MongoDB 三台机器 关闭防火墙 systemctl stop firewalld.service 192.168.252.121 192.168.252.122 192.168.25 ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- 不卸载ceph重新获取一个干净的集群环境
不卸载ceph重新获取一个干净的集群环境 标签(空格分隔): ceph ceph环境搭建 运维 部署了一个ceph集群环境,由于种种原因需要回到最开始完全clean的状态,而又不想卸载ceph客户端或 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二)安装hadoop2.9.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- 分享一份关于Hadoop2.2.0集群环境搭建文档
目录 一,准备环境 三,克隆VM 四,搭建集群 五,Hadoop启动与测试 六,安装过程中遇到的问题及其解决方案 一,准备环境 PC基本配置如下: 处理器:Intel(R) Core(TM) i5-3 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(七)针对hadoop2.9.0启动DataManager失败问题
DataManager启动失败 启动过程中发现一个问题:slave1,slave2,slave3都是只启动了DataNode,而DataManager并没有启动: [spark@slave1 hado ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- tp3.2开启允许跨域
在入口文件<?PHP下加上 header('Access-Control-Allow-Origin:*');header("Access-Control-Allow-Headers: ...
- is not mapped 错误改正
我出现的错误是:oorg.hibernate.hql.ast.QuerySyntaxException: DEPT is not mapped [from DEPT] 配置文件如下: <?xml ...
- js 两个小括号 ()() 的用法
实现一个函数fn, 使fn(1)(2)的结果为两个参数的和,刚开始没反应过来,其实细细一想第二个括号就是函数再调用的问题,废话不多说,代码奉上: var fn = function(n) { func ...
- hdu 1162 Eddy's picture (Kruskal 算法)
题目连接:http://acm.hdu.edu.cn/showproblem.php?pid=1162 Eddy's picture Time Limit: 2000/1000 MS (Java/Ot ...
- 【活动】畅想云端加油站,赢iPad
中石化联手阿里云升级石油化工业务,已运行2月 中石化的“互联网+”战略正在不断深化.4月20日消息,中石化与阿里云共同宣布,双方将展开技术合作,借助阿里巴巴在云计算.大数据方面的技术优势,对部分传统石 ...
- J2EE项目工具集(转)
1.支持重构,TDD, Debug J2EE应用和Flying Error提示的IDE a.重构:即使团队用的最多的只是Rename,Move,Extract Method等有限几个最基本的功能,但J ...
- SQL Server ->> 尝试优化ETL中优化Merge性能
这几天突发想到在ETL中Merge性能的问题.思路的出发点是Merge到目标表需要扫描的数据太多,而现实情况下,假设应该是只有一小部分会被更新,而且这部分数据也应该是比较新的数据,比方说对于想Fact ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- UnicodeDecodeError: 'utf8' codec can't decode byte in position invalid start byte
在scrapy项目中,由于编码问题,下载的网页中中文都是utf-8编码,在Pipeline.py中方法process_item将结果保存到数据库中时,提示UnicodeDecodeError: 'ut ...
- SQL Server 有序GUID,SequentialGuid,
问题描述 有序的GUID性能对比,堪比自增ID integer 一个大神告诉我NEWSEQUENTIALID() 在数据迁移的时候会有问题(感谢大神指点),所以我就深挖一下这个函数. 关于NEWSEQ ...