ELT已死,EtLT才是现代数据处理架构的终点!

提到数据处理,经常有人把它简称为“ETL”。但仔细说来,数据处理经历了ETL、ELT、XX ETL(例如,Reverse ETL、Zero-ETL)到现在流行的EtLT架构几次更迭。目前大家使用大数据Hadoop时代,主要都是ELT方式,也就是加载到Hadoop里进行处理,但是实时数据仓库、数据湖的流行,这个ELT已经过时了,EtLT才是实时数据加载到数据湖和实时数据仓库的标准架构。
本文主要讲解下几个架构出现的原因和擅长的场景及优缺点,以及为什么EtLT逐步取代了ETL、ELT这些常见架构,成为全球主流数据处理架构,并给出开源实践方法。
ETL时代(1990-2015)
在数据仓库早期时代,数据仓库提出者Bill Inmmon把数据仓库定义为分主题的存储和查询的数据存储架构,数据在存储时就是按主题分门别类清洗好的数据。而实际情况也如此,大部分数据源是架构化数据源(例如,mysql、Oracle、SQLServer、ERP、CRM等等),而作为数据集中处理的数据仓库大部分还是以OLTP时代查询和历史存储为主的数据库(DB2、Oracle),因此数据仓库在面对复杂ETL处理时并不得心应手。而且这些数据库购买成本都比较高,处理性能较弱,同时,各种各样的软件数据源越来越多。为了更方便地整合复杂的数据源、分担数据计算引擎负担、大量的ETL软件出现,大家耳熟能详的Informatica、Talend、Kettle都是那个年代的典型软件产品,很多软件至今还在很多企业的传统架构当中配合数据仓库使用。
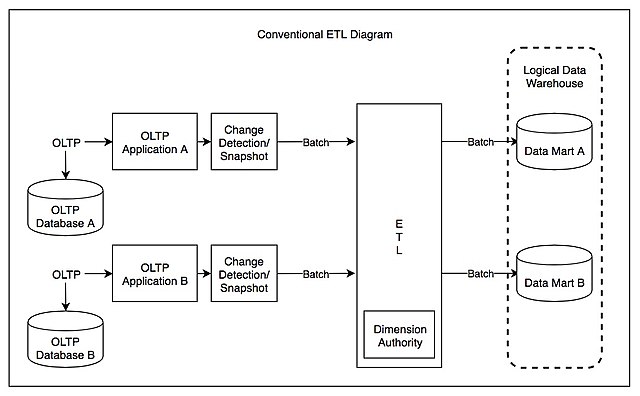
优点:技术架构清晰、复杂数据源整合顺畅、ETL软件分担接近50%的数据仓库工作
缺点:所有处理都由数据工程师实现,业务需求满足时间较长;硬件成本几乎投入双份,数据量大时硬件成本过高
在数据仓库早期和中期,数据源复杂性比较高的时候,ETL架构几乎成为行业标准流行了20多年。
ELT时代(2005-2020)
随着数据量越来越大,数据仓库的硬件成本与ETL硬件成本双向增长,而新的MPP技术、分布式技术出现导致在数据仓库中后期和大数据兴起时代,ETL的架构逐步走向ELT架构。例如,当年数据仓库最大厂商Teradata、至今流行的Hadoop Hive架构,都是ELT架构。它们的特点就是,将数据通过各种工具,几乎不做join,group等复杂转化,只做标准化(Normolization)直接抽取到数据仓库里数据准备层(Staging Layer),再在数据仓库中通过SQL、H-SQL,从数据准备层到数据原子层(DWD Layer or SOR Layer);后期再将原子层数据进入汇总层(DWS Layey or SMA Layer),最终到指标层(ADS Layer or IDX Layer)。虽然Teradata面向的结构化数据,Hadoop面向非结构化数据,但全球大数据和数据仓库几乎用的同一套架构和方法论来实现3-4层数据存储架构。
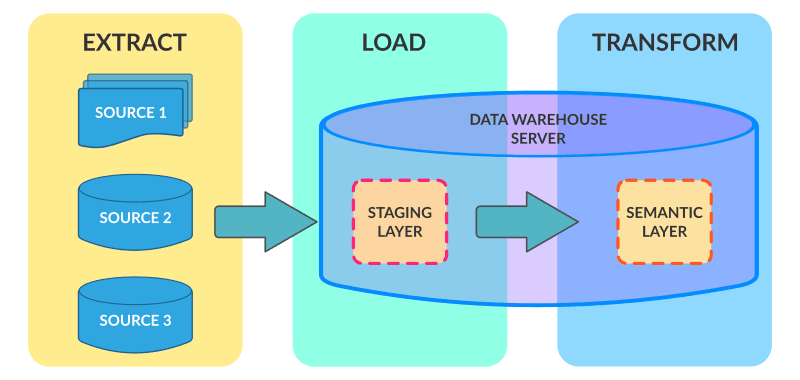
优点:利用数据仓库高性能计算处理大数据量处理,硬件ROI更高;同时,复杂业务逻辑可以通过SQL来用数据分析师和懂业务逻辑的技术人员来处理,而无需懂ETL(如Spark, MapReduce)降低数据处理人员总成本。
缺点:只适用于数据源比较简单、量比较大的情况,面对复杂的数据源明显处理方式不足;同时直接加载,数据准备层到数据原子层复杂度过高,无法通过SQL处理,往往利用Spark、MapReduce处理,而数据重复存储率较高;无法支持实时数据仓库等需求。
面对ELT的数据仓库无法加载复杂数据源,实时性比较差的问题,曾经有一个过渡性解决方案被各种公司方法采用,叫做ODS(Operational Data Store)方案。将复杂的数据源通过实时CDC或者实时API或者短时间批量(Micro-Batch)的方式ETL处理到ODS存储当中,然后再从ODS ELT到企业数据仓库当中,目前,还有很多企业采用此种方式处理。也有部分企业,把ODS放置在数据仓库当中,通过Spark、MapReduce完成前期的ETL工作,再在数据仓库(Hive、Teredata、Oracle、DB2)当中完成后期的业务数据加工工作。
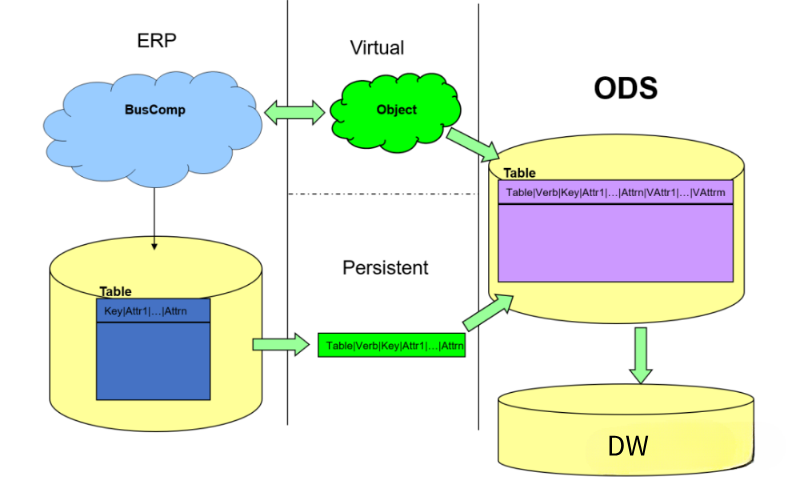
其实此时,EtLT初期的人群已经形成,它的特点是人群划分开,复杂的数据抽取、CDC、数据结构化、规整化的过程,往往由数据工程师实现,我们叫做小“t”,它的目标是从源系统到数据仓库底层数据准备层或者数据原子层;而复杂的带有业务属性的数据原子层到数据汇总层到数据指标层的处理(带有Group by、Join等复杂操作)往往是擅长使用SQL的业务数据工程师或者数据分析师来处理。
而ODS架构的独立项目也随着数据量级变大和EtLT架构的出现逐步淡出历史舞台。
EtLT (2020-未来)
EtLT的架构是由James Densmore 在《Data Pipelines Pocket Reference 2021》中总结提到的一个现代全球流行的数据处理架构。EtLT也是随着现代数据架构(Modern Data Infrastructure)变化而产生的。
EtLT架构产生的背景
现代数据架构架构有如下特点 ,导致EtLT架构出现:
- 云、SaaS、本地混合复杂数据源
- 数据湖与实时数据仓库
- 新一代大数据联邦(Big Data Federation)
- AI应用大爆发
- 企业数据社群(Data Community)分裂
复杂数据源出现
现在全球企业运行当中,除了传统的软件、数据库之外,云和SaaS的出现将本已经很复杂的数据源情况更加复杂,于是面对SaaS的处理,北美企业提出了新的数据集成(Data Ingestion)的概念,例如 Fivetran,Airbyte,以解决SaaS数据进入数据仓库(例如Snowflake)当中的ELT问题,它是传统ELT架构在SaaS环境下的升级。而云端数据存储(例如,AWS Aruroa,AWS RDS,MongoDB Service等)和传统线下数据库与软件(SAP、Oracle、DB2等)在混合云架构(Hybrid Cloud)也在迅速增加数据源复杂性。传统的ETL和ELT架构就无法满足如此复杂环境的数据源处理。
数据湖与实时数据仓库
在现代数据架构环境下,数据湖的出现融合了传统的ODS和数据仓库的特点,它可以做到贴源的数据变更和实时数据处理(例如 Apache Hudi, Apache Iceberg,Databricks Delta Lake),针对传统的CDC(Change Data Capture)和实时数据流计算都做了数据存储结构变化(Schema Evolution)和计算层面的支持。同时,实时数据仓库理念出现,很多新型计算引擎(Apache Pinnot、ClickHouse、Apache Doris)都将支持实时ETL提上日程。而传统的CDC ETL软件或者实时计算流计算(Datastream Computing)对于数据湖和实时数据仓库的支持,要么是在新型存储引擎支持要么是在新型数据源连接方面存在很大问题,缺乏很好的架构和工具支持。
新一代大数据联邦
在现代数据架构当中还有一种新型架构出现,它们以尽可能减少数据在不同数据存储间流动,直接通过连接器或者快速数据加载后直接提供复杂数据查询而见长,例如 Starburst的TrinoDB(前PrestDB)和基于Apache Hudi的OneHouse。这些工具都以数据缓存以及即席跨数据源查询为目标,各种ETL、ELT工具亦无法支撑新型的Big Data Federation架构。
大模型大爆发
随着2022年ChatGPT的出现,AI模型已经具备在企业应用中普及的算法基础,阻碍AI应用模型落地的更多的是数据的供给,数据湖和Big Data Federation出现解决了数据存储和查询问题。而数据供给侧,传统的ETL和ELT和流计算都形成了瓶颈,亦或无法快速打通各种复杂传统、新兴数据源、亦或无法用一套代码同时支持AI训练和AI线上的数据差异化需求。
企业数据社群分裂
随着数据驱动和使用的深入,企业内部的数据使用者也快速增加,从传统的数据工程师到数据分析师、AI人员甚至销售分析师、财务分析师都有从企业数据仓库当中提取数据的需求。因此,经历了No-SQL,New-SQL各种变化之后,SQL还是成为企业最后面对复杂业务分析的唯一标准。大量分析师、业务部门工程师使用SQL来解决企业数据最后一公里的问题,而复杂的非结构化数据处理,留给了专业数据工程师使用Spark、MapReduce、Flink处理。因此,两批人群的需求产生了比较大的差异,传统ETL,ELT架构无法满足新型企业使用者的需求。
EtLT架构应运而生!
在上述背景下,数据处理逐步演化成为EtLT架构:
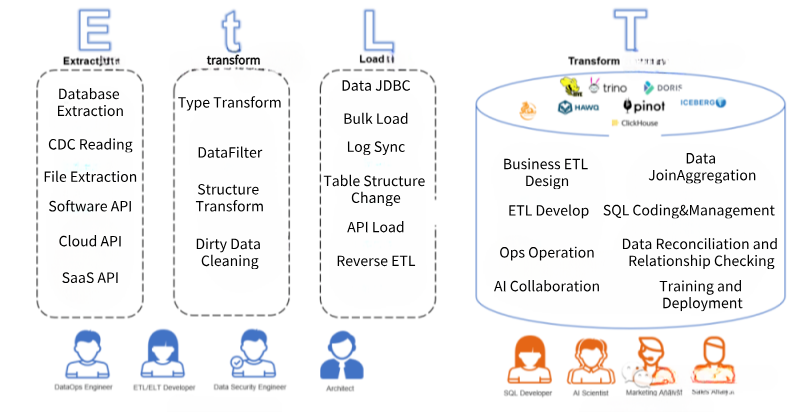
它拆分了原有ETL和ELT的结构,并力求实时和批量统一在一起处理以满足实时数据仓库和AI应用的需求:
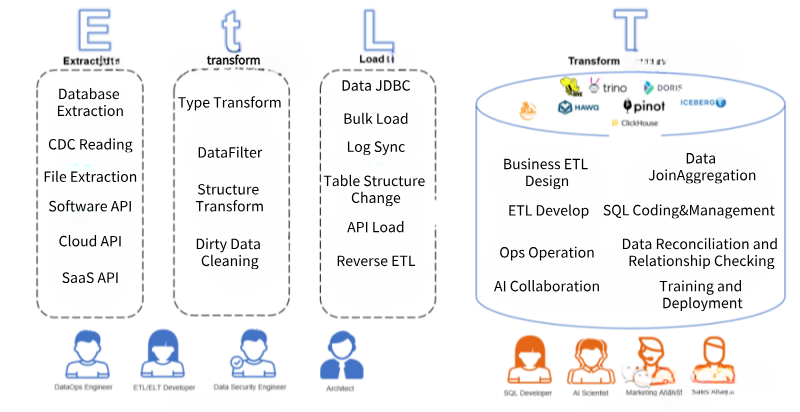
- E(xtract)抽取:从数据源角度来看,支持传统的线下数据库、传统文件、传统软件同时,还要支持新兴云上数据库、SaaS软件API以及Serverless数据源的抽取;从数据抽取方式来看,需要支持实时CDC(Change Data Capture)对数据库Binlog日志的解析,也要支持实时计算(例如Kafka Streaming),同时也需要支持大批量数据读取(多线程分区读取、限流读取等)。
- t(ransform)规范化:相对于ETL和ELT,EtLT多出了一个小t,它的目标是数据规范化(Data Normalization)将复杂、异构的抽取出来数据源,快速地变为目标端可加载的结构化数据,同时,针对CDC实时加载Binlog进行拆分、过滤、字段格式变更,并支持批量和实时方式快速分发到最终Load阶段。
- L(oad)加载:准确的说,加载阶段已经不是简单的数据加载,而是配合Et阶段,将数据源的数据结构的变更、数据内容的变更以适合数据目标端(Data Target)的形式快速、准确的加载到数据目标当中,其中,对于数据结构的变化要支持同源数据结构变更(Schema Evolution),数据加载也应该支持大批量加载(Bulk Load)、SaaS加载(Reverse ETL)、JDBC加载等。确保既支持实时数据和数据结构的变化,还要支持大批量数据快速加载。
- (T)ransform转化:在云数据仓库、线下数据仓库或新数据联邦的环境下,完成业务逻辑的加工,通常使用SQL方式,实时或批量地将复杂业务逻辑准确、快速变为业务端或者AI端使用的数据。
在EtLT架构下,使用者人群也有了明确的分工:
- EtL阶段:以数据工程师为主,他们将复杂异构的混合数据源,变为数据仓库或者数据联邦可加载的数据,放到数据存储当中,他们无需对企业指标计算规则有深入理解,但需要对各种源数据和非结构化数据变为结构化数据转化有深入理解。他们需要确保的是数据的及时性、数据源到结构化数据的准确性。
- T阶段:以数据分析师、各业务部门数据SQL开发者、AI工程师为主,他们深刻理解企业业务规则,可以将业务规则变为底层结构化数据上的SQL语句进行分析统计,最终实现企业内部的数据分析和AI应用的实现,他们需要确保的是数据逻辑关系、数据质量以及最终数据结果满足业务需求。
EtLT 架构开源实践
在新兴的EtLT架构下,其实全球有不少开源实践,例如在大T部分,DBT帮助企业分析师和业务开发者快速基于Snowflake开发相关数据应用。而以大数据任务可视化调度协同(Workflow Orchestration)见长的Apache DolphinScheduler也在规划Task IDE,让企业数据分析师可以在DolphinScheduler上直接调试Hudi、Hive、Presto、ClickHouse等的SQL任务并直接拖拽生成Workflow任务。
作为EtLT架构当中代表Apache SeaTunnel则是从云、本地数据源多种支持开始起步,逐步支持SaaS和Reverse ETL,大模型数据供给等方面,逐步完善EtLT的版图,可以看到SeaTunnel最新的Zeta计算引擎把复杂的Join,Groupby等复杂操作交给最终的数据仓库端来实现,自己只完成归一化、标准化的动作以达到实时数据和批量数据一套代码和高效引擎处理的目标,而大模型支持也放入支持列表当中:
目前Apache SeaTunnel从2022年底加入Apache孵化器的20个连接器发展到现在1年增长了5倍,目前支持的数据源超过100(https://seatunnel.apache.org/docs/Connector-v2-release-state/),从传统数据库到云上数据库最终到SaaS的支持都在逐步完善。
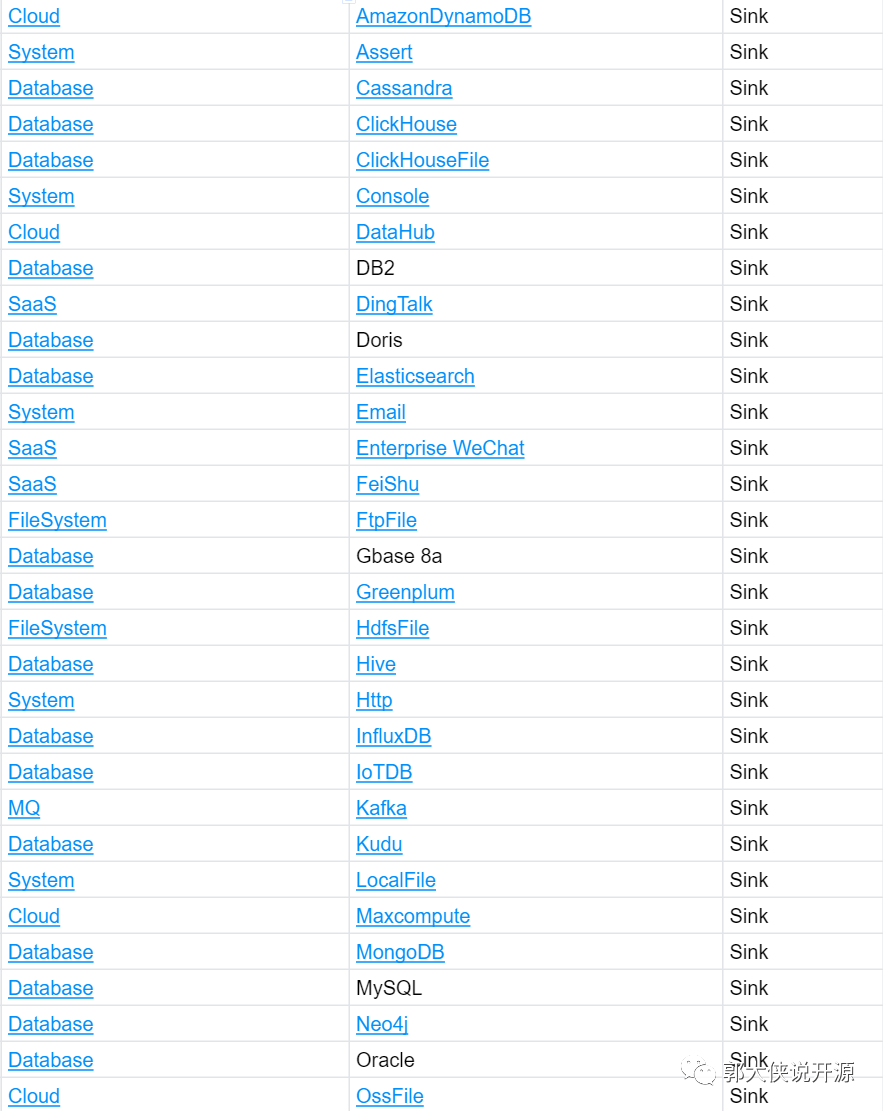
(参见https://seatunnel.apache.org/docs/2.3.2/category/source-v2浏览最新支持组件)
而Apache SeaTunnel 2.3.0 发布的SeaTunnel Zeta引擎也支持数据分布式CDC,目标源数据表变更(SchemaEvolution)和整库和多表同步诸多Feature和针对大数据量优异的性能赢得全球大量用户(例如,印度第二大运营商Bharti Airtel,新加坡电商Shopee.com,唯品会Vip.com等)。相信随着Connector数据量增多,SeaTunnel会赢得更多的企业用户的青睐。
大模型的支持
更有意思的是现在SeaTunnel已经支持了对大模型训练和向量数据库的支撑,让大模型可以直接和SeaTunnel支撑的100多种数据源交互(参见《图书搜索领域重大突破!用 Apache SeaTunnel、Milvus 和 OpenAI 提高书名相似度搜索精准度和效率》),而现在SeaTunnel更可以利用ChatGPT直接生成SaaS Connector让你的大模型和数据仓库快速获取互联网上多种信息。
随着AI、云、SaaS的复杂性增加,企业对于实时CDC、SaaS和数据湖、实时数据仓库装载的需求,简单的ETL架构已经很难满足现有企业的需求,而具有面向企业不同阶段的EtLT架构会在现代数据架构当中大放异彩。
而Apache SeaTunnel的目标就是是“连接万源,同步如飞”。
SeaTunnel社区非常活跃,当前版本也在快速迭代,加入Apache SeaTunnel社区,当前2.3.x版本还有不少地方在快速变化,也欢迎大家一起来贡献!
本文由 白鲸开源 提供发布支持!
ELT已死,EtLT才是现代数据处理架构的终点!的更多相关文章
- Android首席设计师宣称移动概念已死,开发人员应该面向屏幕编写应用而非移动
腾讯科技对Android首席设计师Duarte"移动已死"訪谈内容的翻译错得离谱,被到处转载,误人视听. 而要真正理解Duarte所想表达的含义,须要深入了解互联网前沿设计理念以及 ...
- MVC模式已死
MVC模式:Model模型 View试图 Control控制器,是目前主流模式,被当作服务器软件入门基本模式学习和掌握,主流框架Struts 1/2 JSF Wicket基本都顺理成章支持MVC模式. ...
- Jeff Atwood:软件工程已死?
原文作者:Jeff Atwood 2009年7月,Tom DeMarco在<IEEE Software>杂志上发表了一篇论文,题为"Software Engineering: A ...
- 【转】Lisp 已死,Lisp 万岁!
Lisp 已死,Lisp 万岁! 有一句古话,叫做“国王已死,国王万岁!”它的意思是,老国王已经死去,国王的儿子现在继位.这句话的幽默,就在于这两个“国王”其实指的不是同一个人,而你咋一看还以为它自相 ...
- JVM 判断对象已死,实践验证GC回收
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言 提升自身价值有多重要? 经过了风风雨雨,看过了男男女女.时间经过的岁月就没有永恒不变 ...
- 研发效能|DevOps 已死平台工程永存带来的焦虑
最近某位大神在推特上发了一个帖子,结果引来了国内众多卖课机构.培训机构的狂欢,开始贩卖焦虑,其实「平台工程」也不是什么特别高深莫测的东西.闲得无聊,把这位大神的几个帖子薅了下来,你看过之后就会觉得没啥 ...
- wp已死,metro是罪魁祸首!
1.这篇文章肯定会有类似这样的评论:“我就是喜欢wp,我就是喜欢metro,我就是软粉“等类似的信仰论者发表的评论. 2.2014年我写过一篇文章,windows phone如何才能在中国翻身? 我现 ...
- 泰泽新闻:英特尔三星双否认泰泽Tizen系统已死
7月8日 据媒体TizenExperts报道,关于“Tizen系统跳票”的传闻已经遭到了英特尔和三星否认. 此前传闻三星自行研制的智能手机Tizen操作系统流产,但如今已经遭到了官方的否认. 英特尔三 ...
- 王垠:Lisp 已死,Lisp 万岁!
王垠:Lisp 已死,Lisp 万岁!_IT新闻_博客园 王垠:Lisp 已死,Lisp 万岁!
- JVM学习记录-对象已死吗
前言 先来回顾一下,在jvm运行时数据区,分为两部分,一个部分是线程共享区,主要包括堆和方法区,另一部是线程私有区分包括本地方法栈,虚拟机栈和程序计数器.在线程私有部分的三个区域是随着线程生和灭的.栈 ...
随机推荐
- Python遥感影像叠加分析:基于一景数据提取另一数据
本文介绍基于Python中GDAL模块,实现基于一景栅格影像,对另一景栅格影像的像元数值加以叠加提取的方法. 本文期望实现的需求为:现有一景表示6种不同植被类型的.tif格式栅格数据,以及另一 ...
- Python 导入包失败,提示“most likely due to a circular import”
详细报错信息如下: ImportError: cannot import name 'DoReplace' from partially initialized module 'common.do_r ...
- 02-Python基础
文件编码 Python2中 在Python2中:默认文件编码是ASC II,所以无法正常输出中文,会报错. 解决办法 在文件的开头添加# -- coding: UTF-8 -- 或者 # coding ...
- 【Vyos-开源篇-1】- VMware 安装 VyOS 虚拟机
文章说明:使用VMware ESXi和VMware Workstation安装vyos软路由. 一.项目准备 1.1.VMware ESXi 我家里的是一台8核心,20G内存,2T的N5105工控机, ...
- QT学习:00 介绍
--- title: framework-cpp-qt-00-介绍 date: 2020-04-08 15:41:54 categories: tags: - c/c++ - qt --- 章节描述: ...
- 3568F-翼辉SylixOS国产操作系统演示案例
- CF1864C 题解
\(x = 2^k\) 是好做的,每次以 \(2^{k-1}\) 为因数即可. 对于其他情况,考虑每次让 \(x\) 减去其二进制下最低位的 \(1\) 直至变成 \(2^k\). 这种策略下显然每个 ...
- SpringCloud连接远程nacos报错,一直提示连接本地的localhost:8848
application.properties spring.cloud.nacos.discovery.server-addr=xxx.xxx.xxx.xxx:8848 spring.applicat ...
- Spring5.X的注解配置项目
pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
- 使用forEach循环异步方法,导致使用深拷贝时,得不到最新数据,控制台会打印出最新的数据
在使用forEach循环遍历一个数组,如果循环时有异步方法,会导致最终深拷贝得不到最新数据,但是控制台会打印最新的数据 `const arr = [ { name: "Jone", ...