记录实验室深度学习服务器显卡硬件故障的排查——RmInitAdapter failed! rm_init_adapter failed
实验室突然通知我说是深度学习的服务器无法查看GPU,并且在GPU上运行的程序也halt on,需要解决。于是查询服务器的运行日志得到下面的信息:
Nov 10 01:33:23 dell kernel: [3238114.018736] NVRM: Xid (PCI:0000:b1:00): 43, pid=45948, Ch 00000008
Nov 10 01:38:12 dell kernel: [3238403.448442] NVRM: Xid (PCI:0000:b1:00): 43, pid=51064, Ch 00000008
Nov 10 01:39:11 dell kernel: [3238462.127610] NVRM: Xid (PCI:0000:b1:00): 62, pid=51064, 21b3(31c4) 00000000 00000000
Nov 10 01:43:32 dell kernel: [3238722.985986] NVRM: Xid (PCI:0000:b1:00): 45, pid=3300, Ch 00000000
Nov 10 01:43:32 dell kernel: [3238722.988964] NVRM: Xid (PCI:0000:b1:00): 45, pid=3300, Ch 00000001
Nov 10 01:43:32 dell kernel: [3238722.991786] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000002
Nov 10 01:43:32 dell kernel: [3238722.993928] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000003
Nov 10 01:43:32 dell kernel: [3238722.995701] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000004
Nov 10 01:43:32 dell kernel: [3238722.997629] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000005
Nov 10 01:43:32 dell kernel: [3238722.999373] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000006
Nov 10 01:43:32 dell kernel: [3238723.001108] NVRM: Xid (PCI:0000:b1:00): 45, pid=1544, Ch 00000007
Nov 10 01:43:32 dell kernel: [3238723.002705] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000008
Nov 10 01:43:32 dell kernel: [3238723.504007] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000009
Nov 10 01:43:32 dell kernel: [3238723.505675] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000a
Nov 10 01:43:32 dell kernel: [3238723.507158] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000b
Nov 10 01:43:32 dell kernel: [3238723.508527] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000c
Nov 10 01:43:32 dell kernel: [3238723.509823] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000d
Nov 10 01:43:32 dell kernel: [3238723.511155] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000e
Nov 10 01:43:32 dell kernel: [3238723.512501] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 0000000f
Nov 10 01:43:32 dell kernel: [3238723.513788] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000010
Nov 10 01:43:32 dell kernel: [3238723.515211] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000011
Nov 10 01:43:32 dell kernel: [3238723.516537] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000012
Nov 10 01:43:32 dell kernel: [3238723.517836] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000013
Nov 10 01:43:32 dell kernel: [3238723.519163] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000014
Nov 10 01:43:32 dell kernel: [3238723.520567] NVRM: Xid (PCI:0000:b1:00): 45, pid=55094, Ch 00000015
查看nvidia官方的文档:
https://docs.nvidia.com/deploy/xid-errors/index.html

可以看到这个错误大概率是应用程序的问题。
顺着日志往前查看,发现了相似的日志信息:
Oct 25 11:46:44 dell kernel: [1892628.496902] NVRM: Xid (PCI:0000:d9:00): 43, pid=34973, Ch 00000008
Oct 28 08:02:50 dell kernel: [2138374.168198] NVRM: Xid (PCI:0000:d9:00): 43, pid=79247, Ch 00000008
很明显相似的报错信息以前也都出现过,此时的判断依然是应用程序造成的错误。
此时的故障表现就是4块显卡中有一块是丢失的,无法识别的,其他三块显卡可识别都是不工作。
首先从软件层面上考虑解决这个问题,于是升级系统版本,从ubuntu18.04升级到22.04,然后升级内核版本,等等,然后重启电脑。进系统发现还是有块显卡无法识别,其他三块显卡虽然可以被识别但是依旧无法使用,再次查看系统日志,得到信息:
Nov 10 07:11:03 dell kernel: [ 240.936646] NVRM: GPU 0000:b1:00.0: RmInitAdapter failed! (0x26:0xffff:1266)
Nov 10 07:11:03 dell kernel: [ 240.936680] NVRM: GPU 0000:b1:00.0: rm_init_adapter failed, device minor number 2
Nov 10 07:11:14 dell kernel: [ 252.387589] NVRM: GPU 0000:b1:00.0: RmInitAdapter failed! (0x26:0xffff:1266)
Nov 10 07:11:14 dell kernel: [ 252.387651] NVRM: GPU 0000:b1:00.0: rm_init_adapter failed, device minor number 2

通过日志信息可以知道,此时的0000:b1:00.0槽位上的显卡是不能初始化的,按照这个错误信息再结合一些网上的信息初步判断是该块显卡已经出现了物理故障(因为已经在软件层面上解决无效)。
--------------------------------------------------------
联系经销商,发过来一个示意图,要我们自行测试故障点:

打开机箱,拔掉一张显卡,重启,查看显卡信息:
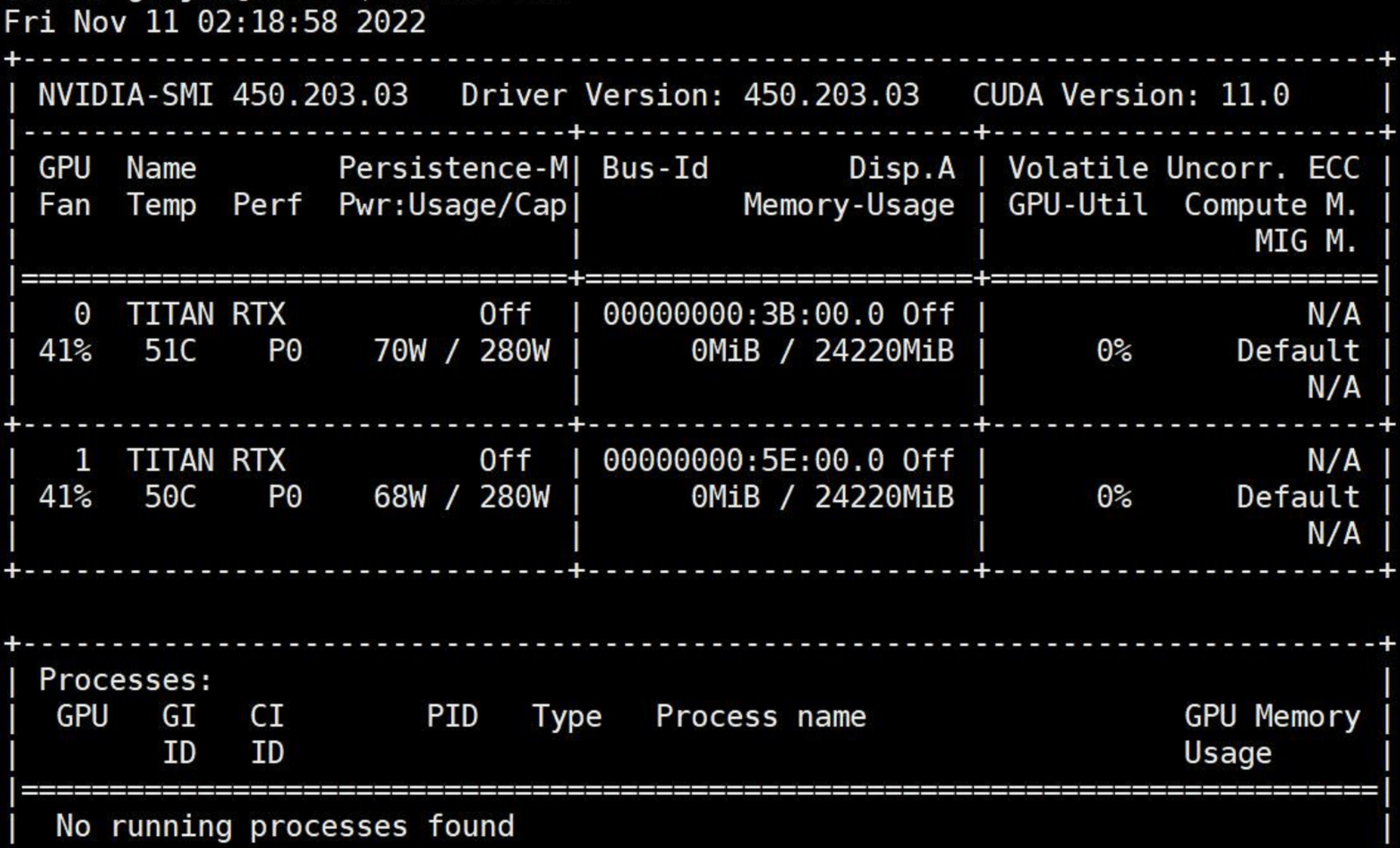
正常情况应该是4张显卡,由于一张显卡故障,一张显卡被拔掉,于是显示出只有两个显卡,这说明拔下的这个显卡并不是故障显卡。
接着把这个拔下的显卡插回去,拔另一个显卡:
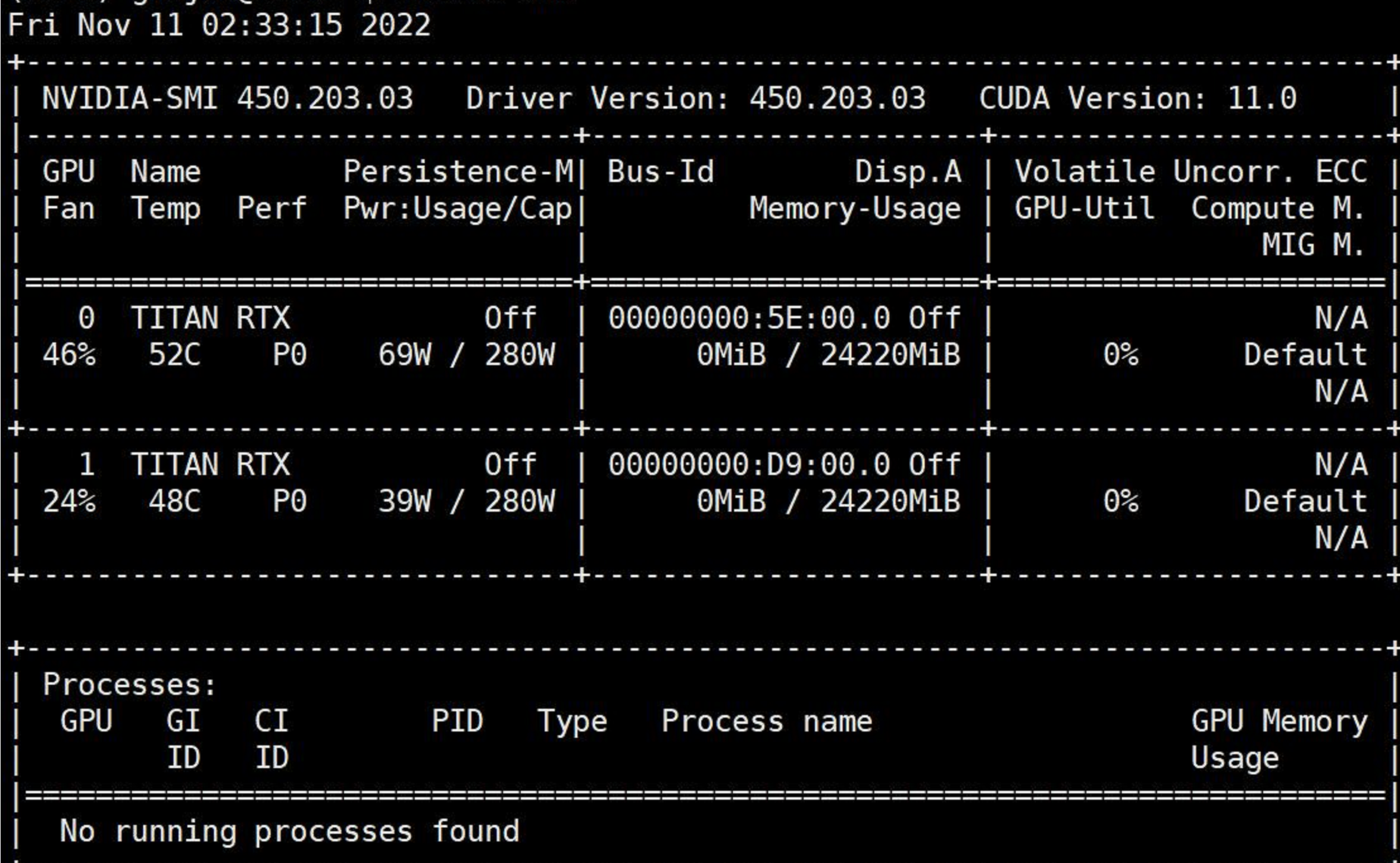
说明此时拔下的显卡依然不是故障显卡。
接着把这个拔下的显卡插回去,拔另一个显卡:
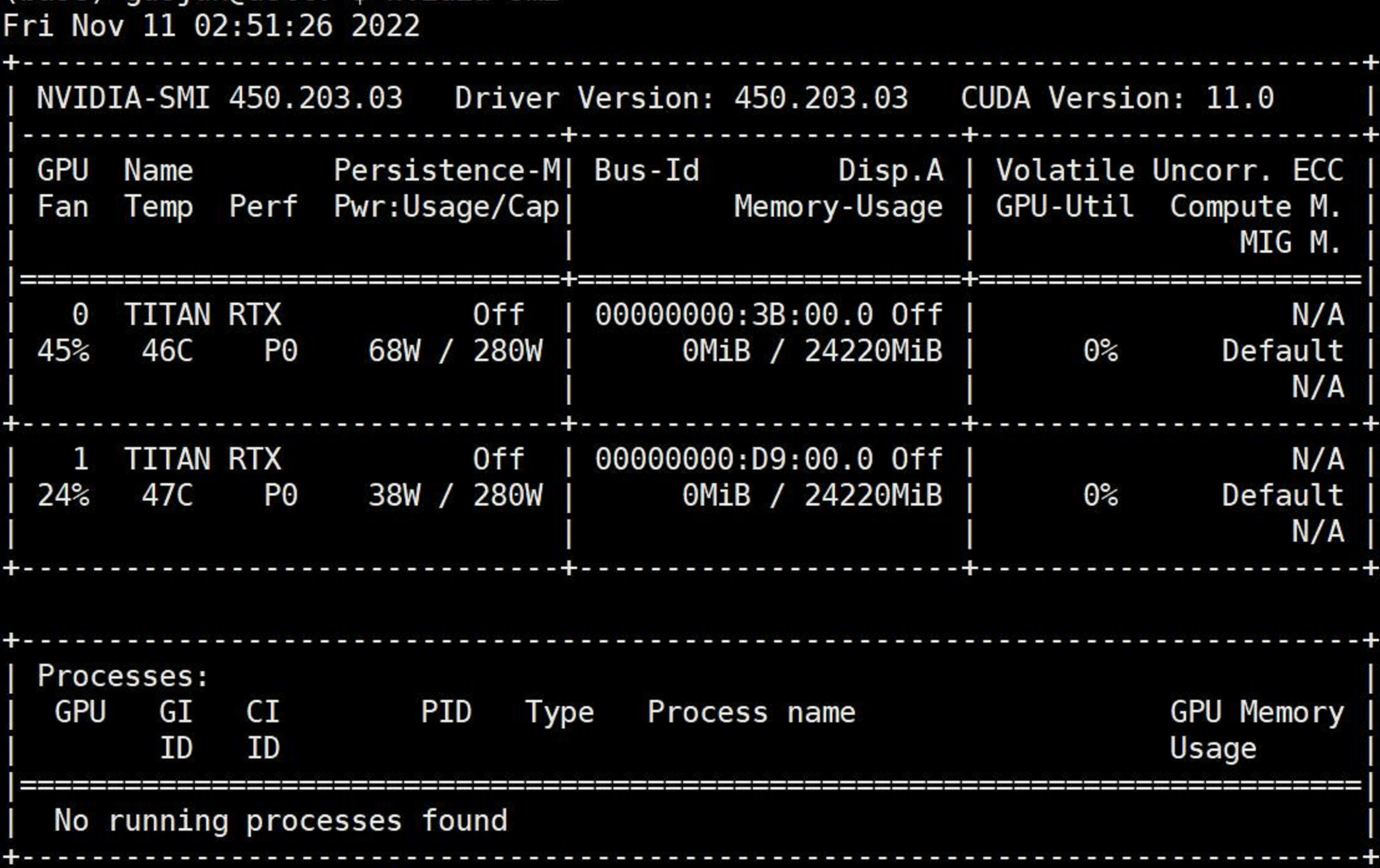
说明此时拔下的显卡依然不是故障显卡,那么可以确定没有拔下来过的显卡就是故障显卡。
刚才的拔卡的顺序:(一共四张卡,1,2,3,4号)
按机箱从上到下的顺序:321
第一张卡是1
因此可以得出结论:
00000000:5E:00.0 槽位是1号卡;
00000000:3B:00.0 槽位是2号卡;
00000000:D9:00.0 槽位是3号卡;
00000000:B1:00.0 槽位是4号卡。
根据刚才3次的拔卡重启后的信息,我们可以知道故障出在四号槽或四号卡上。
----------------------------------------------------------------------------
此时有一个问题,那就是我们无法判断出故障的是这个槽位的显卡还是这个槽位,于是我们把四号卡插到一号槽,此时1号卡被拔下来,四号槽空着,开机查询信息:
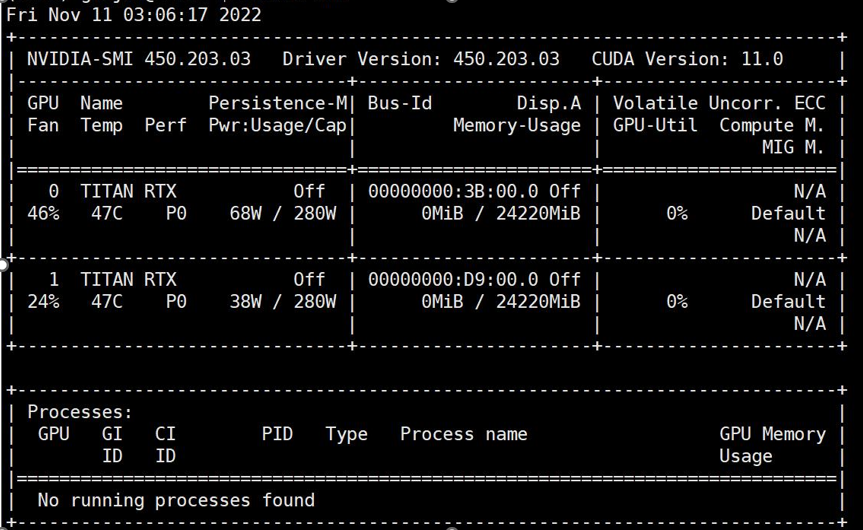
此时一号槽查询不到信息,一号槽现在插着4号卡,这说明四号卡出现硬件故障。
现在虽然得到了四号卡故障的结论,但是四号槽有没有问题还是需要再确认下的,于是1、2号卡复位(1号卡插一号槽,2号卡插二号槽),3号卡和4号卡对调(3号卡插4号槽,4号卡插3号槽),查询显卡信息:
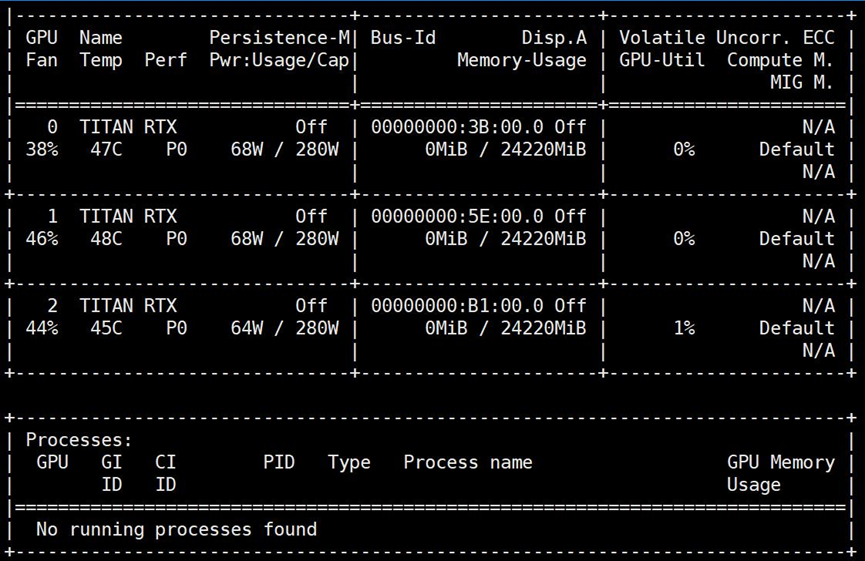
可以看到,3号卡和4号卡对调后,4号槽(00000000:B1:00.0)可以被识别,这说明四号槽没有损坏;3号槽插着4号卡没有被识别,更加说明了4号卡硬件故障。
=============================================
得到最终结论,4号卡损坏,联系经销商发给售后,走保修流程。把1,2,3号卡复位,4号卡拆出,空出4号槽,再次启动查询显卡信息:
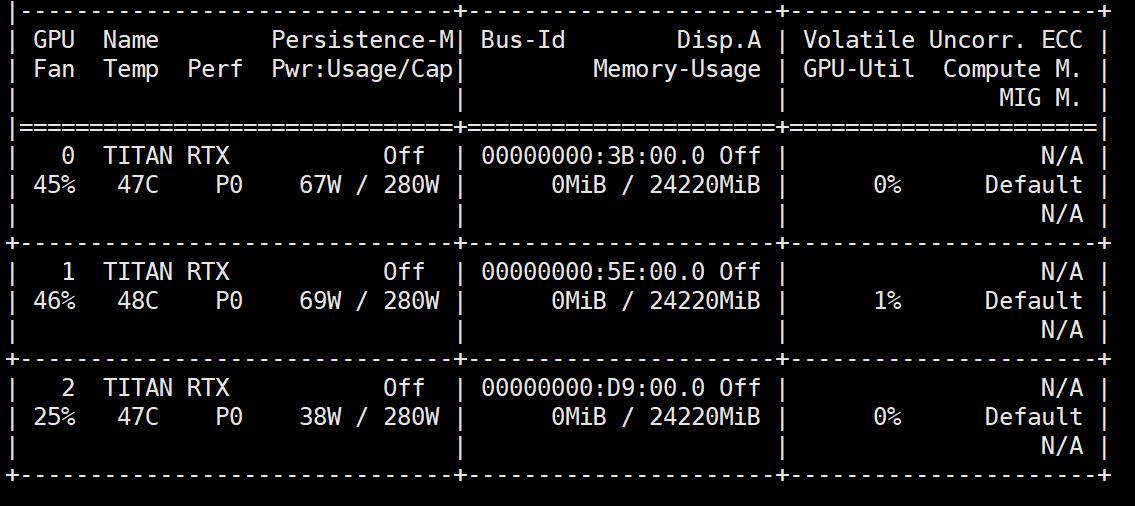
运行TensorFlow和pytorch的代码,GPU端正常运行,1,2,3号显卡可以被调用,服务器恢复正常运行。(有坏卡在PCIE槽上插着,导致其他三个正常显卡也不能正常工作,拆出坏卡后其他卡便恢复正常运行)
====================================
记录实验室深度学习服务器显卡硬件故障的排查——RmInitAdapter failed! rm_init_adapter failed的更多相关文章
- 【神经网络与深度学习】Caffe训练执行时爆出的Check failed: registry.count(t ype) == 1 (0 vs. 1) Unknown layer type
自己建立一个工程,希望调用libcaffe.lib ,各种配置好,也能成功编译,但是运行就会遇到报错 F0519 14:54:12.494139 14504 layer_factory.hpp:77] ...
- 从零开始搭建实验室Ubuntu服务器 | 深度学习工作站
一个标准的数据分析码农必须要配一台超薄笔记本和一台高性能服务器,笔记本是日常使用,各种小问题的解决,同时也是用于远程连接终端服务器:高性能服务器就是核心的处理数据的平台,CPU.内存.硬盘容量.GPU ...
- [AI开发]深度学习如何选择GPU?
机器推理在深度学习的影响下,准确性越来越高.速度越来越快.深度学习对人工智能行业发展的贡献巨大,这得益于现阶段硬件计算能力的提升.互联网海量训练数据的出现.本篇文章主要介绍深度学习过程中如何选择合适的 ...
- 深度学习PyTorch入门(1):3060 Pytorch+pycharm环境搭建
WIN10, NVIDIA GeForce RTX 3060 python 3.7, CUDAv11.1.1, PyTorch 1.9, PyCharm 1.安装anacodah和PyCharm: ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 萌新深度学习与Pytorch入门记录(一):Win10下环境安装
深度学习从入门到入土,安装软件及配置环境踩了不少坑,过程中参考了多处博主给的解决方法,遂整合一下自己的采坑记录. (若遇到不一样的错误,请参考其他博主答案解决) 笔者电脑系统为win10系统,在此环境 ...
- 服务器搭建远程docker深度学习环境
服务器搭建远程docker深度学习环境 本文大部分内容参考知乎文章 Docker+PyCharm快速搭建机器学习开发环境 搭建过程中出现ssh连接问题可以查看最后的注意事项 Docker Docker ...
- 在服务器的docker里 装anacond3深度学习环境的全流程超基础
背景: 实验室给我分配了一个服务器 已经装好了docker 和nvidi docker . 现在我的目标是创建我自己的docker 然后在我自己的docker里装上anaconda环境. 我以前从 ...
- VScode连接GPU服务器进行深度学习
VScode连接GPU服务器进行深度学习 最近用台式机跑一些小的深度学习项目,发现越来越慢了,由于一些原因,有时候需要我进行现场作业但是我的笔记本是轻薄本(Thinkpad YYDS)不带显卡,百 ...
- 深度学习菜鸟的信仰地︱Supervessel超能云服务器、深度学习环境全配置
并非广告~实在是太良心了,所以费时间给他们点赞一下~ SuperVessel云平台是IBM中国研究院和中国系统与技术中心基于POWER架构和OpenStack技术共同构建的, 支持开发者远程开发的免费 ...
随机推荐
- redisTemplate缓存方法template code
import com.alibaba.fastjson.JSONObject; @Autowired private RedisTemplate redisTemplate; String PREFI ...
- 用ESP8266-NodeMCU开发板显示一下我的QQ头像
诶,说好的自己写esp8266的开发板固件的我回来了. 20年说好的,今天回来还愿了 ESP8266串口WiFi模块 - WiFi杀手 今天我们把OLED显示屏也接上,我此次买的是4脚的OLED(12 ...
- Vite-Wechat网页聊天室|vite5.x+vue3+pinia+element-plus仿微信客户端
基于Vue3+Pinia+ElementPlus仿微信网页聊天模板Vite5-Vue3-Wechat. vite-wechat使用最新前端技术vite5+vue3+vue-router@4+pinia ...
- 05-CentOS防火墙
概述 CentOS中的防火墙有很多,如SELinux.Firewall.TCP Wrappers.iptables/netfilter. 每种防火墙都有各自擅长的地方. 这里主要讲两种:SELinux ...
- 安装tesserocr
1.下载安装包 这个包不能使用pip安装 可以在这里找到适合自己的版本安装: https://github.com/simonflueckiger/tesserocr-windows_build/re ...
- 2023/3/21 组会:ChatGPT 对数据增强的影响及 ChatGPT 的鲁棒性,Dense 和 Document 检索方法
前两个也许跟上了,后两个完全没跟上,以后再详细读读吧qwq 反正组会跟不上才是正常现象. AugGPT: Leveraging ChatGPT for Text Data Augmentation 摘 ...
- 将PaddleOCR 转为 ONNX 运行
PaddleOCR 是目前最好的开源OCR框架, 但paddle框架的兼容性实在不怎么好, 部署的时候容易出现各种各样的问题. 如果能把PaddleOCR转成ONNX, 就可以跳过paddle框架坑的 ...
- Linux 进程运行状态
背景: 以下有关的知识点是在多进程拷贝的时候,执行了sync导致卡死导致的. Linux进程状态:R (TASK_RUNNING),可执行状态.只有在该状态的进程才可能在CPU上运行.而同一时刻可能有 ...
- python_8 拆包、内置函数和高阶函数
一.查缺补漏 1. \t 子表符,用于对其二.拆包 1. 拆包:顾名思义就是将可迭代的对象如元组,列表,字符串,集合,字典,拆分出相对应的元素 2. 形式:拆包一般分两种方式,一种是以变量的方式来接收 ...
- 快速调用 GLM-4-9B-Chat 语言模型
一.确认本机显卡配置 二.下载大模型 国内可以从魔搭社区下载, 下载地址:https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/files 三.运行官方 ...