使用浪潮AI计算平台之分布式计算(Tensorflow框架下 PS/Worker模式下的异步计算)
虽然Tensorflow一直都是支持分布式计算的,但是由于只有一台电脑,一个GPU,所以别说分布式的tensorflow的使用了,就是单机多卡都是没有使用过的,由于后来可以有机会使用这个浪潮的AI计算平台于是在上面试了试tensorflow的分布式计算,这里说的是其中的PS/Worker模式下的异步计算。
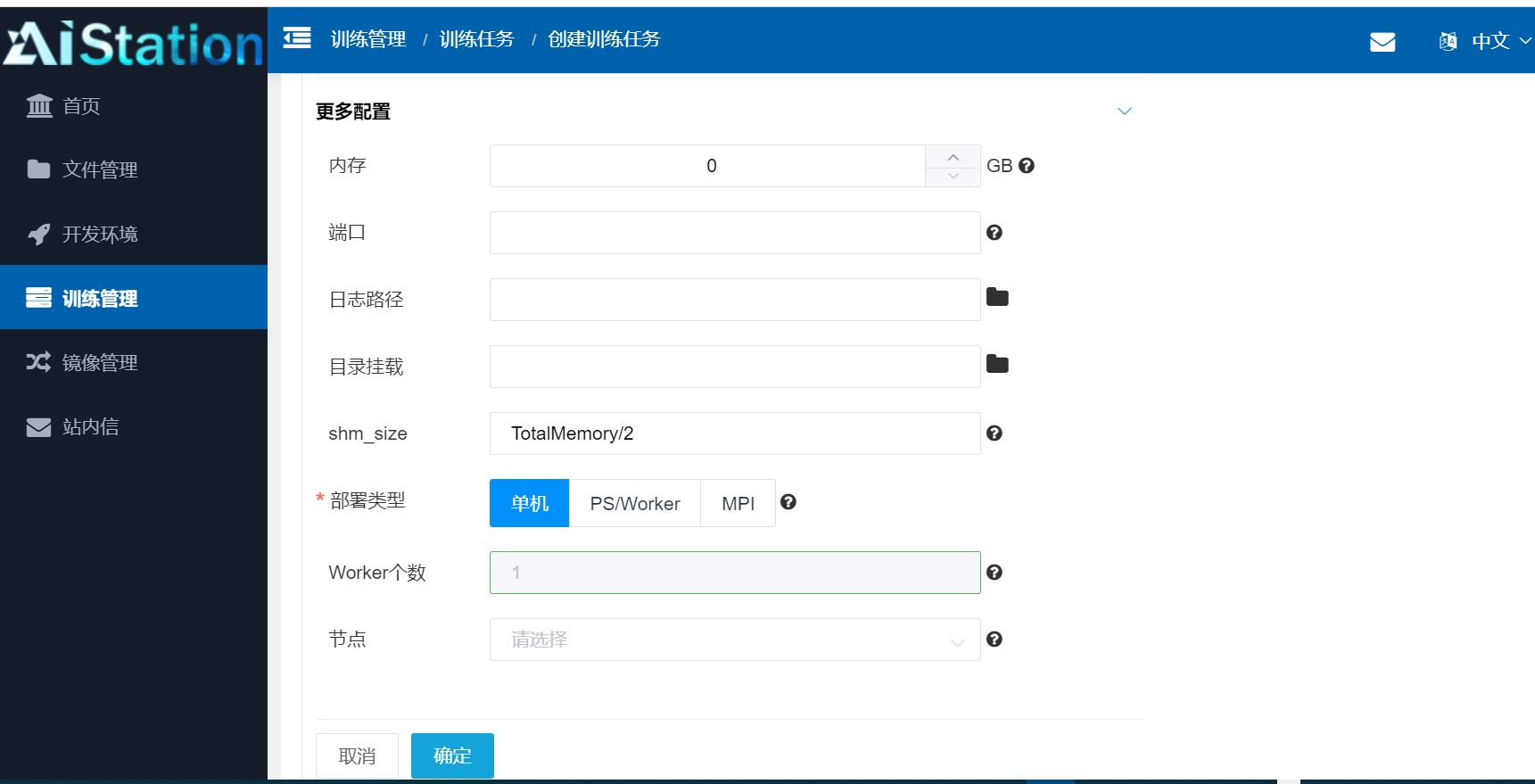
看下图,可以知道这个平台是支持单机计算,以及分布式的 PS/Worker模式和MPI模式的:
其中使用的代码为:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function import json
import os
import argparse
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf FLAGS = None def weight_variable(shape):
init = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(init) def bias_variable(shape):
init = tf.constant(0.1, shape=shape)
return tf.Variable(init) def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding="SAME") def max_pool(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") def main(_): tf_config = json.loads(os.environ.get('TF_CONFIG') or '{}')
task_config = tf_config.get('task', {})
task_type = task_config.get('type')
task_index = task_config.get('index') FLAGS.job_name = task_type
print('job_name:%s' %(task_type))
FLAGS.task_index = task_index #ps_hosts = FLAGS.ps_hosts.split(",")
#worker_hosts = FLAGS.worker_hosts.split(",") cluster_config = tf_config.get('cluster', {})
ps_hosts = cluster_config.get('ps')
worker_hosts = cluster_config.get('worker') ps_hosts_str = ','.join(ps_hosts)
worker_hosts_str = ','.join(worker_hosts) FLAGS.ps_hosts = ps_hosts_str
FLAGS.worker_hosts = worker_hosts_str # Construct the cluster and start the server
ps_spec = FLAGS.ps_hosts.split(",")
worker_spec = FLAGS.worker_hosts.split(",") # Get the number of workers.
num_workers = len(worker_spec) # Create a cluster from the parameter server and worker hosts.
#cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
cluster = tf.train.ClusterSpec({"ps": ps_spec, "worker": worker_spec}) # Create and start a server for the local task.
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index,
start=True) if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) FLAGS.batch_size = 550
step = mnist.train.num_examples / 500 - 1
print("train examples: %d, step: %d" % (mnist.train.num_examples, step) ) with tf.device(tf.train.replica_device_setter(
#worker_device="/job:worker/task:%d" % FLAGS.task_index,
worker_device="/job:worker/task:%d/gpu:%d" % (FLAGS.task_index, 0),
cluster=cluster)): x = tf.placeholder(tf.float32, [None, 784])
y_actual = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32) x_image = tf.reshape(x, [-1, 28, 28, 1]) W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool(h_conv1) W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool(h_conv2) W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 64]) # reshape
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # dropout
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # dropout W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_predict = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # softmax, [-1, 10] cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_actual * tf.log(y_predict), 1))
global_step = tf.train.get_or_create_global_step()
#global_step = tf.train.get_global_step()
optimizer = tf.train.GradientDescentOptimizer(FLAGS.learning_rate)
train_op = optimizer.minimize(cross_entropy, global_step=global_step) cross_prediction = tf.equal(tf.argmax(y_predict, 1), tf.argmax(y_actual, 1))
accuracy = tf.reduce_mean(tf.cast(cross_prediction, tf.float32)) # tensorboard
tf.summary.scalar('cost', cross_entropy)
tf.summary.scalar("accuracy", accuracy)
summary_op = tf.summary.merge_all() # The StopAtStepHook handles stopping after running given steps.
#hooks = [tf.train.StopAtStepHook(last_step=400)]
hooks = [tf.train.StopAtStepHook(last_step=(50000+step))] config = tf.ConfigProto(
allow_soft_placement=True,
log_device_placement=False,
#device_filters=["/job:ps", "/job:worker/task:%d" % FLAGS.task_index]
device_filters=["/job:ps", "/job:worker/task:%d/gpu:%d" % (FLAGS.task_index, 0)]
) # The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
# master="grpc://" + worker_hosts[FLAGS.task_index] with tf.train.MonitoredTrainingSession(master=server.target,
config=config,
is_chief=(FLAGS.task_index == 0),
hooks=hooks,
max_wait_secs = 120) as mon_sess:
while not mon_sess.should_stop(): # Run a training step asynchronously.
# See `tf.train.SyncReplicasOptimizer` for additional details on how to
# perform *synchronous* training.
# mon_sess.run handles AbortedError in case of preempted PS.
#batch_x, batch_y = mnist.train.next_batch(64)
batch_x, batch_y = mnist.train.next_batch(FLAGS.batch_size)
# step, _ = mon_sess.run([global_step, train_op], feed_dict={
# x: batch_x,
# y_actual: batch_y,
# keep_prob: 0.8}) #print("global_step: %f" % step)
#if step > 0 and step % 10 == 0:
step, _, loss, acc = mon_sess.run([global_step, train_op, cross_entropy, accuracy], feed_dict={
x: batch_x,
y_actual: batch_y,
keep_prob: 1.0})
print("step: %d, loss: %f, acc: %f" % (step, loss, acc)) if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.register("type", "bool", lambda v: v.lower() == "true")
# Flags for defining the tf.train.ClusterSpec parser.add_argument(
"--data_dir",
type=str,
default="/home/guojun/MNIST_data/",
help="data directory"
)
parser.add_argument(
"--batch_size",
type=int,
default=600,
help="batch size"
)
parser.add_argument(
"--max_step",
type=int,
default=100,
help="step num"
) parser.add_argument(
"--ps_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--worker_hosts",
type=str,
default="",
help="Comma-separated list of hostname:port pairs"
)
parser.add_argument(
"--job_name",
type=str,
default="",
help="One of 'ps', 'worker'"
)
# Flags for defining the tf.train.Server
parser.add_argument(
"--task_index",
type=int,
default=0,
help="Index of task within the job"
) parser.add_argument(
# "--checkpoint_dir",
"--model_save_path",
type=str,
default="/testsoft01/models/logs/log_tf_mnist_dist/",
help="path to a directory where to restore variables."
) parser.add_argument(
"--learning_rate",
type=float,
default=0.001,
help="learning rate"
) FLAGS, _ = parser.parse_known_args()
tf.app.run(main=main)
这里不对代码做解释,这是比较简单的PS/Worker模式下的异步计算代码。
给出配置:(以三台服务器为示例,每个进程分别运行在一台服务器上,IP及端口分别为
ps进程: "10.233.113.70:2222",
worker进程: "10.233.112.166:2223","10.233.91.193:2223"
)
环境变量设置如下:
export TF_CONFIG='{"cluster":{"ps":["10.233.113.70:2222"],"worker":["10.233.112.166:2223","10.233.91.193:2223"]},"task":{"type":"ps","index":0},"environment":"cloud"}'
export TF_CONFIG='{"cluster":{"ps":["10.233.113.70:2222"],"worker":["10.233.112.166:2223","10.233.91.193:2223"]},"task":{"type":"worker","index":0},"environment":"cloud"}'
export TF_CONFIG='{"cluster":{"ps":["10.233.113.70:2222"],"worker":["10.233.112.166:2223","10.233.91.193:2223"]},"task":{"type":"worker","index":1},"environment":"cloud"}'
如果指定某个进程对GPU的使用限制时使用如下配置:
不使用显卡, export CUDA_VISIBLE_DEVICES=-1
使用0号显卡, export CUDA_VISIBLE_DEVICES=0
使用1号显卡, export CUDA_VISIBLE_DEVICES=1

=========================================================
第一种类型试验:
task为worker的两个task同时运行在同一台电脑上(这台电脑有2个GPU),每个task分别使用一个GPU;task为ps的task运行在另一台电脑上:
运行异步aggregate(A电脑运行2个worker,每个worker使用一个GPU; B电脑为ps)
31m12.532s (ps 做汇聚时使用CPU运算, CPU有 90%利用率)
31m21.559s (ps 做汇聚时使用CPU运算, CPU有 90%利用率)
38m21.106s (ps 做汇聚时使用GPU运算 )
38m11.901s (ps 做汇聚时使用GPU运算 )
38m9.435s (ps 做汇聚时使用GPU运算 )
38m35.333s (ps 做汇聚时使用GPU运算 )
38m30.296s (ps 做汇聚时使用GPU运算 )
38m24.708s (ps 做汇聚时使用GPU运算 )
39m34.298s (ps 做汇聚时使用GPU运算 )
39m30.530s (ps 做汇聚时使用GPU运算 )
39m18.943s (ps 做汇聚时使用GPU运算 )
39m38.846s (ps 做汇聚时使用GPU运算 )
可以看到ps进程使用 CPU做汇聚时竟然比GPU做汇聚时效率高,当然这里由于只使用了两个Worker并不能完全说明问题,但是多个分布的worker不太有条件也就只能做到这里了。个人观点是分布式的数据需要相互交换,从网卡出来的数据传到内存的数据比较快,而传到显卡的速度会稍微慢些,个人感觉这里的显卡可能并没有使用nccl, 这样的话网卡数据可以直接传到显存中而不用再通过内存了,这样的话使用GPU做汇聚的时间可能就不会和CPU做汇聚有显着差距了,当然这也只是个人的猜测(计算平台明确说明使用了nccl,所以这里为什么gpu做汇聚效率不及cpu还是难以说清的)。当然这个结果还是比较有限的,如果你不是使用分布式的计算而是单机多卡,而且卡比较多的话还是推荐使用horovod框架的,毕竟
Ring Allreduce 这个东西理论上是OK的,但实际效果没用过。
在这个AI计算平台上horovod框架指的就是MPI模式的分布式计算。
---------------------------------------------------
第二种试验:
task类型为worker的两个task分别运行在两台电脑,每个worker利用1个GPU;task类型为ps的task运行在另一台电脑:
运行异步aggregate(A电脑1个worker,并使用一个GPU, B电脑1个worker,并使用一个GPU, C电脑为ps)
27m31.965s (ps CPU运算 100%) (1个CPU)
28m7.096s (ps CPU运算 100%) (1个CPU)
28m54.965s (ps CPU运算 100%) (1个CPU)
28m55.451s (ps CPU运算 100%) (1个CPU)
29m0.394s (ps CPU运算 100%) (1个CPU)
26m30.772s (ps CPU运算 100%) (1个CPU)
26m45.423s (ps CPU运算 100%) (1个CPU)
27m2.666s (ps CPU运算 100%) (1个CPU)
22m52.598s(ps CPU运算 ) (多个CPU)
23m27.257s (ps CPU运算 ) (多个CPU)
23m21.331s(ps CPU运算 ) (多个CPU)
23m35.570s(ps CPU运算 ) (多个CPU)
23m5.596s (ps CPU运算 ) (多个CPU)
27m19.363s (ps GPU运算)
27m8.633s (ps GPU运算)
27m8.849s (ps GPU运算)
27m40.217s (ps GPU运算)
27m26.957s (ps GPU运算)
27m19.115s (ps GPU运算)
可以看到第二种试验是将第一种试验中的运行在同一个电脑上的worker分别运行在两个电脑上,这样竟然提高了计算速度。
个人观点是两个worker在同一个电脑上对于网络传输的负载较大,所以导致了网络传输的速度慢了下来,这样也就解释了第一种试验中PS上用CPU做汇聚时只使用了90%,因为两个worker占用一个网卡传输数据但是整体的传输速度慢了下来,ps上做汇聚时存在等待数据的情况,于是没有把CPU跑满。而在第二种试验中两个worker分别在不同电脑上所以传输数据较快,ps电脑上利用CPU做汇聚时不需要等待,因为worker传输数据已经传过来了,网络传输数据的数据快于ps上CPU的汇聚速度,于是ps上CPU跑满了,速度也就提升了。在第二种试验中,ps上使用CPU做汇聚和使用GPU做汇聚也存在一定速度差异,gpu做汇聚操作还是要差于cpu做汇聚,说明网络传输的数据到底是传输到内存还是显存还是会一定程度的影响计算效率的。
这里传输的数据的数据量没有过大还在CPU的计算能力范围内,如果网络数据的传输速度足够快,而且数据足够大时(大于CPU汇聚速度并且小于单GPU显存时)GPU的速度会快于CPU汇聚速度,但是在数据传输速度足够快而数据量过大时(大于GPU显存时)那么只能使用CPU做汇聚了。
在第二种试验中依然可以看到GPU做汇聚时要慢于CPU,个人观点依然是数据从网卡传输到显卡的速度要稍微慢于网卡数据传输到内存的速度(或许网卡数据不能直接传输到显存还是要中间经过内存呢,这样是不是nccl并没有真的支持呢)。
个人猜测,在网络速度足够快的理想条件下(待汇聚的速度足够多),数据量在显存可以容纳的情况下,GPU做汇聚的速度会随着数据量增加而提升的。
---------------------------------------------------
第三种试验:
task为worker的两个task运行在同一台电脑(2个GPU),每个task利用一个GPU,task为ps的task运行在同一台电脑:
运行异步aggregate (A电脑2个worker,每个worker一个GPU, A电脑也运行task类型为ps的进程,且ps只使用CPU做汇聚操作)
12m31.103s
12m15.255s
12m11.336s
12m15.212s
10m27.511s
10m38.285s
10m32.073s
10m36.449s
10m20.578s
10m25.668s
10m49.644s
10m54.085s
10m33.264s
10m59.180s
10m47.720s
10m11.117s
第三种试验与第一,二种试验不同的地方是把PS端和worker端放在了同一个电脑上,ps和worker之间的数据传输不通过网卡而是直接在内核层进行交换。发现第三种试验的速度是前三种中最快的。前三种试验之所以速度不同是因为数据的网络传输导致的,不经过网卡的数据传输是最快的;每个worker都独占一个网卡进行数据传输是第二快的,两个worker共享一个网卡来传输数据是最慢的。可以看到由于网络传输造成的速度差距有几倍之多,可以讲能单机多卡的情况下绝对不使用多机多卡的。
这里给个网络测速的代码,因为服务器上不能连接外网不能安装测速软件,于是自己写了个简单的网络传输代码:
服务端,数据接收端:
import socket sk = socket.socket()
ip_port=('0.0.0.0',9999)
sk.bind(ip_port)
sk.listen(5) s = 8096*4048 for _ in range(1):
conn,address = sk.accept()
while True:
data = conn.recv(s)
#print(data)
if not data:
break
print('文件接收完成')
sk.close()
客户端,数据发送端:
import socket
import time
sk = socket.socket()
#ip_port=('10.233.119.52',9999)
ip_port=('127.0.0.1',9999)
sk.connect(ip_port)
with open('xxx.tar','rb') as f:
data = f.read()
start = time.time()
sk.send(data)
end = time.time()
print('over')
print("time", end-start)

可以看到,这里的传输数据为44GB大,传输数据时把数据完全加载到服务器上(服务器内存不到500GB)。
发送端和接收端都在同一主机上(数据传输不经过网卡而是经过内核时):
time:(秒)
1.0947113037109375
1.9611408710479736
1.1916041374206543
1.6991233825683594
1.500579833984375

平均传输速度为29.808885595040923 GB/s 。
发送端和接收端分别在两个主机上(数据传输经过网卡时):
平均传输速度为9.711139239030665 GB/s 。
可以看到经过网卡的数据传输速度是不经过网卡的3分之一。
而这个速度是什么概念呢,可以参照PCIE3.0*16的速度:
也就是说经过网卡的数据传输速度9.71 GB/s比PCI3.0*8的单向速度8GB/s快些,但是远低于PCI3.0*16的单向速度16GB/s。而不经过网卡的数据传输,从内存经过内核再回到内存的速度为 29.80 GB/s 比内存和显存之间的PCIE*16的速度 16GB/s 还要快出很多。这也解释了试验第一种时PS上用CPU做汇聚时速度稍微快于GPU做汇聚的速度。
9.71 GB/s 的网络传输速度 也就意味着 网卡的传输速度在 9.71*8Gb/s=77.68Gb/s 以上,由于是估计的算法,保守的看网卡速度在 50Gb/s 以上,从服务器的网卡配置上来看这个速度也是可以的了,但是这个速度的网卡还是不能完全发挥出多机显卡的性能。
但是,单机多卡的话可能显卡的卡槽还是有限的,这个平台上单机多卡的话最多是8卡,如果再多的卡就只能多机多卡了。
多机网络传输速度在 PCI3.0*8 这个级别上, 虽然达不到 PCI3.0*16的速度,但是现在来看也是极高的配置了,网络传输速度如果想要达到PCI3.0*16这个级别不仅是网卡,网络协议,甚至主板南桥的传输速度都是一个天然的限制(一般主板南桥和北桥的数据交互通道中 是硬盘和网卡共享带宽的)。
虽然内存数据通过内核回到内存的速度高于PCIE3.0*16, 但是GPU数据到内存或GPU间数据传输的最大速度还是PCIE3.0*16, 也就是说如果理想情况下,单机多卡的数据传输速度最高为PCIE3.0*16, 而多机多卡的(多机间速度传输速度)最高为PCIE3.0*8。
---------------------------------------------------
第四种试验:
task为worker的一个task运行在一台电脑(1个GPU),每个task利用一个GPU,task为ps的task运行在同一台电脑:
运行异步aggregate (A电脑运行1个worker类型task,worker类型task使用一个GPU; 同时A电脑也运行ps类型task,ps类型task使用CPU做汇聚操作)
24m59.654s
24m6.746s
23m22.713s
22m26.681s
24m36.398s
24m3.182s
22m54.110s
19m37.633s
20m27.468s
21m8.842s
20m46.086s
19m23.438s
21m21.057s
21m21.145s
20m11.565s
21m25.062s
21m18.727s
21m16.270s
21m13.142s
22m19.513s
21m27.789s
21m37.047s
第三种试验和第四种试验都是worker类型task和ps类型task运行在同一台电脑上,并且汇聚操作也只使用CPU,也就是说第三种和第四种的试验worker与ps之间的数据传输没有经过网卡,worker的梯度数据由GPU通过PCIE3.0*16直接传输到内存,ps用传输到内存的梯度更新网络参数并将更新好的参数从内存通过PCIE3.0*16传输会GPU显存中。第三种和第四种试验中可以看到ps和worker运行在同一电脑上时运行加速比约为worker的个数。也就是说当PS和WORKER在同一主机上时,随着worker个数的增加运算时间成倍的缩减。一个worker时时20分钟,两个worker时时10分钟,那么4个worker时就是5分钟。
于是又给第三、四种试验补充了一个试验,就是4个worker,1个ps在同个主机上,测试运行时间:
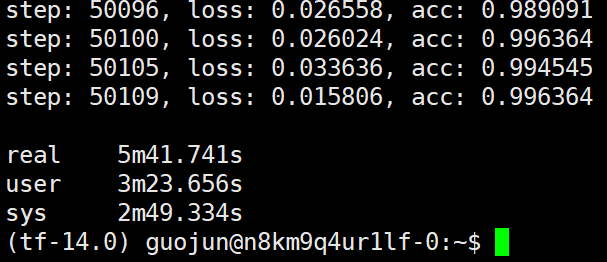
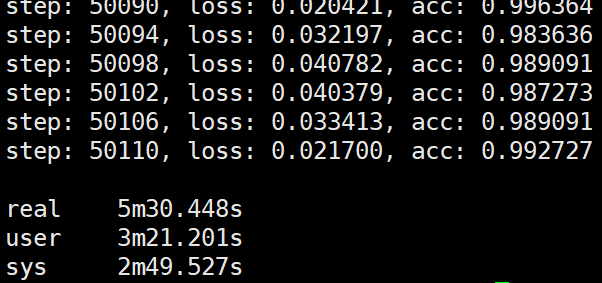
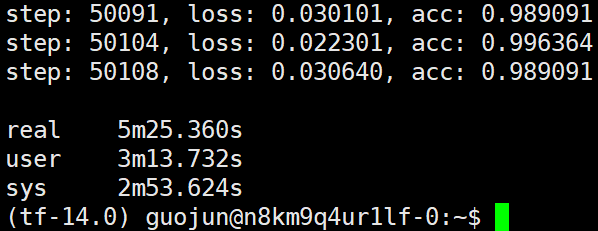
可以看到最后的结果也是5分钟多些,大致符合前面的猜测(运行加速比等于worker数),但是这种情况不会一直随着worker数的增加而增加,因为增加到一定数量的worker后,CPU或GPU做汇聚操作的速度将会小于worker提供梯度的速度从而导致加速比下降。当然一般我们也不会一直在一个主机上增加worker数,因为一个主机的显卡数是固定的(8卡,10卡基本就差不多这个数了),如果显卡的显存足够虽然我们可以在一个显卡上同时跑多个worker但是这样的设计本身就不对,如果要要在一个显卡上跑多个worker的话我们不如尽量的在一个显卡上跑较少的worker(如1个worker, 2个worker),而每个worker我们可以尽量的增加它的batch_size, 这样的话既提高了显卡的利用率又减少了ps进程做汇聚的工作负载。
---------------------------------------------------
第五种试验:
task为worker的两个task运行在两台电脑,每个task利用一个GPU,task为ps的task运行在其中一台电脑:
运行异步aggregate(A电脑1个worker,并使用一个GPU; B电脑1个worker,并使用一个GPU; A电脑上同时运行task为ps的进程)
17m17.498s
16m16.028s
16m9.360s
14m36.767s
15m39.217s
14m33.790s
15m28.215s
15m19.840s
14m33.529s
14m50.261s
15m40.956s
13m59.947s
15m32.166s
14m43.113s
15m17.454s
14m54.340s
14m42.791s
14m34.187s
14m24.599s
第三种试验中两个task和ps运行在同一个电脑上用时约11min;第二种试验中两个worker分别运行在两个电脑上,ps运行在第三台电脑上,用时约28min;而在第五种试验中ps和一个worker运行在一台电脑上,另一个worker运行在第二台电脑上,用时约15min。
---------------------------------------------------
第六种试验:
task为worker的一个task运行在一台电脑,并使用一个GPU;task为ps的task运行在另一台电脑:
运行异步aggregate(A电脑1个worker,并使用一个GPU, B电脑运行task类型为ps)
44m21.566s
45m6.509s
45m25.585s
45m53.505s
45m49.932s
46m26.030s
================================================
根据上面的试验我们知道:
ps和worker在一个主机上时,一个worker用时22min, 两个worker用时11min,四个worker用时5.5min。
ps和worker, worker和worker之间都不在一台主机上时, 一个worker用时45min,两个worker用时23min。(如果一个worker和ps在一台主机上,第二个worker在另一个主机上时用时16min)
如果两个worker在一个主机上,ps在另一个主机上时用时32min。
示意图如下:

-------------------------------------------
其中,一个worker和ps在一个主机,第二个worker在另一个主机时耗时16min,而两个worker和ps均在同一主机时用时22min,这样的话我们可以假设worker和ps在同一个主机时处理数据的速率为a, 而worker和ps不在一个主机时数据的处理速率为a*x, 那么假设总工作量为s,可得 s/2a=11min, s/(a+ax)=16min, 那么x=3/8=0.375,
那么s/(a*x)=47min, 而实际中一个worker时,且worker和ps不在同一主机时用时45min, 由于这里的计算本身就是使用少数试验来估计的,所以姑且可以认为对x的估计是相当的或者说是基本准确的。
既然ps和worker不在一个主机,worker之间也不在一个主机情况下,只有一个worker时需要耗时45min,两个worker时需要耗时23min,可以看到加速比略微小于worker数,当worker数为2时加速比45/23=1.95, 此时加速比与worker数的比值为1.95。如果worker数为3时加速比与worker数的比值仍为1.95/2,那么worker为3时加速比为2.93,耗时为预估为15.33min。当然,这里得到15.33min是假设加速比与worker数的比值不随worker数增加而改变的,具体 我们可以再加一种试验。
第七种试验
ps和task,task和task均各自在一个主机上运行,这里的具体设置为A电脑运行ps(只使用CPU), B电脑运行worker0(使用GPU), C电脑运行worker1(使用GPU), D电脑运行worker2(使用GPU)。
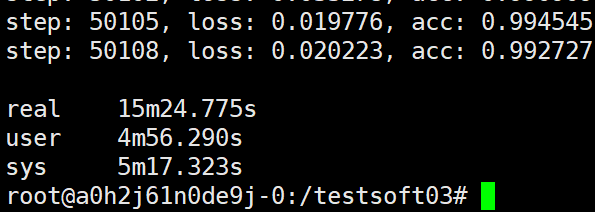
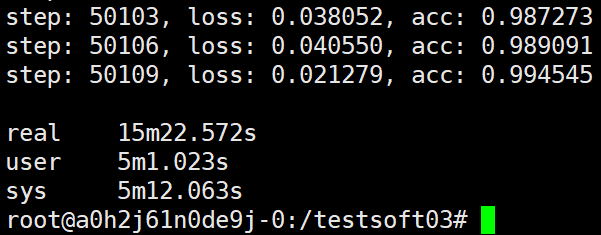
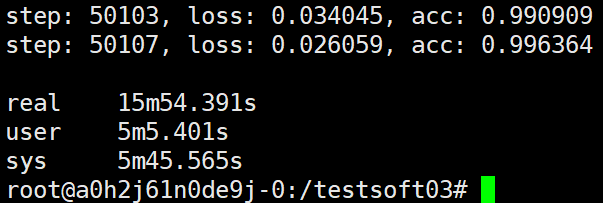
可以看到第七种试验得到的结果与我们刚才的假设(如果worker数为3时加速比与worker数的比值仍为1.95/2,那么worker为3时加速比为2.93,耗时为预估为15.33min)基本吻合。也就是说ps和worker,worker与worker均各自独占一台物理主机时加速比与worker数相当。而通过三、四种试验我们可以看到ps与worker均在同一主机时加速比也与worker数相当。但是,同时我们也可以发现worker个数相同时,ps和worker在同一主机的运算效率是ps与worker,worker与worker均独占一个主机的运算效率的2倍左右,在第六种试验中我们假设过这个倍数的数值约为8/3=2.66, 这里看的话这个估计的倍数还是不准的,8/4=2倍,这个2倍的倍数估计是更为贴近的。
但是通过2,6,7种试验,ps与worker均独占一个主机时,一个worker用时45min,两个worker用时23min,三个worker用时16min, 虽然加速比近似于worker个数,但是如果ps所在主机的网卡速率最高为PCIE3.0*8的,多个worker都是共享这个带宽的,如果这个带宽是瓶颈的话加速比不应该近似于worker个数的,对此也是不好解释的。
因为网卡最高的速率是固定的,一个网卡最高提供PCI3.0*8的速度,而这个速度是所有网络连接共享的,而不是GPU显存和内存之间各自独占PCIE3.0*16或*8的通道),因此再多的worker所提供的数据对于ps来说应该是没有办法提升速度的,而这个事情这里就互相违背了,所以还是没法解释这个问题。
-----------------------------------------
试验1中 :
主机A运行PS,主机B运行两个worker,每个worker分别使用一个GPU, 用时32分多些。
再加一个试验:
主机A运行PS,主机B运行两个worker,每个worker分别使用一个GPU, 主机C运行两个worker,每个worker分别使用一个GPU, 用时16分多些:
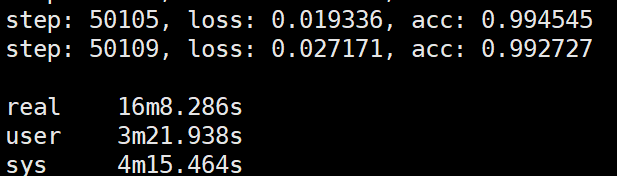
也就是说worker与ps在同一个主机的情况下加速比约等于worker数;worker与ps不在一个主机上,worker所在的主机同样克隆的话(每个worker所在主机具有相同worker个数),那么加速比约等于worker所在的主机个数。
worker与ps在同一个主机速度最快; worker与ps不在同一个主机,但是在总worker数固定的情况下worker所在的主机上worker数越少(worker主机越多),那么速度越快。且加速比都是线性的(在worker数较少的情况下)。
--------------------------------------------------------------------------------
ps和worker不在一个主机时:
ps运行在A主机,只有一个worker运行在B主机时,用时45min;
ps运行在A主机,两个worker运行在B主机时,用时32min;
ps运行在A主机,三个worker运行在B主机时,用时 29min;
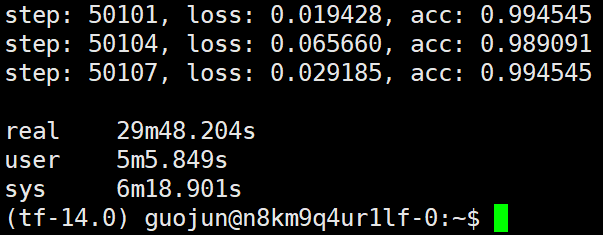
ps运行在A主机,四个worker运行在B主机时,用时28min;

可以看到如果多个worker运行在同一个主机上时加速性能非常差,随着worker数的增加加速性趋于停滞。
------------------------------------------------------------------------------
给出下面的一种试验:
ps独立运行在A电脑上(只使用CPU)
worker0运行在B电脑上(使用GPU)
worker1运行在C电脑上(使用GPU0)
worker2运行在C电脑上(使用GPU1)
worker3运行在D电脑上(使用GPU0)
worker4运行在D电脑上(使用GPU1)
worker5运行在D电脑上(使用GPU2)
worker6运行在D电脑上(使用GPU3)
根据前面的现象:多个worker运行在同一个主机上时加速性能非常差,随着worker数的增加加速性趋于停滞。
只有一个worker运行在独立主机时需要45min,两个worker运行在同一主机时需要32min,四个worker运行在同一主机时需要28min,而ps端不会因为worker的增加而影响汇聚操作的性能的话,可得:

也就是说这次的试验,如果ps端不会因为worker的增加而影响汇聚操作的性能的话,可以预估时间为11.21min。而下面的试验发现,预估的时间基本相仿:
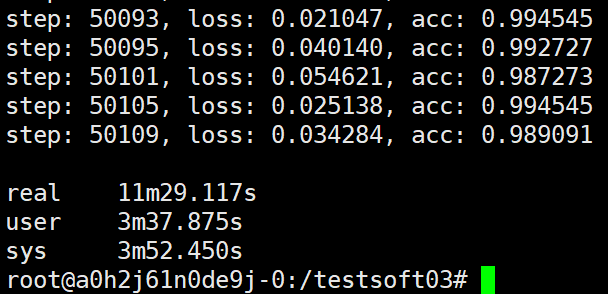
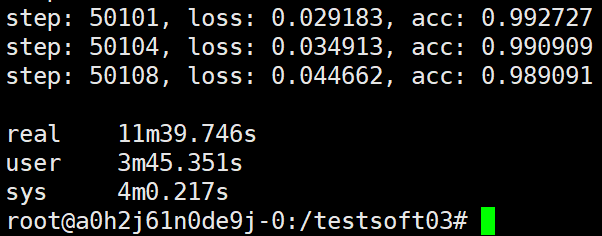
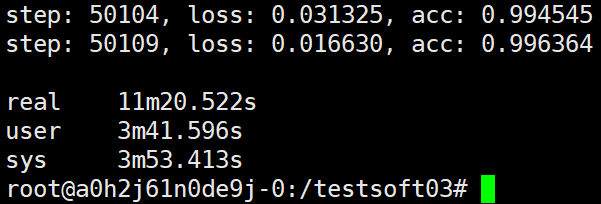
可以看出7个worker都不和ps在一个主机上,这时用11min多些时间,还没有ps和worker在同一主机但是有两个worker的速度快。
----------------------------------------------------
给出下面的一种试验:
ps独立运行在D电脑上(只使用CPU)
worker0运行在B电脑上(使用GPU)
worker1运行在C电脑上(使用GPU0)
worker2运行在C电脑上(使用GPU1)
worker3运行在D电脑上(使用GPU0)
worker4运行在D电脑上(使用GPU1)
worker5运行在D电脑上(使用GPU2)
worker6运行在D电脑上(使用GPU3)
如果上面的预估方式正确,那么这个预估时间:

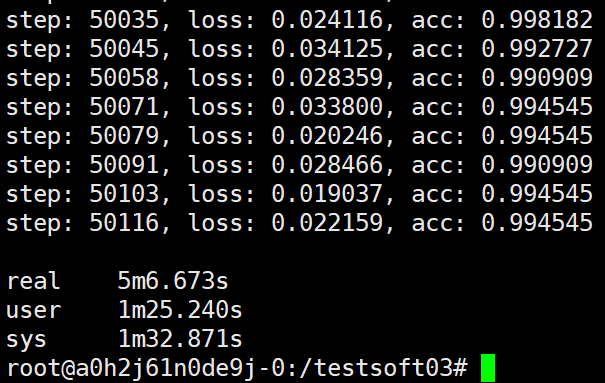
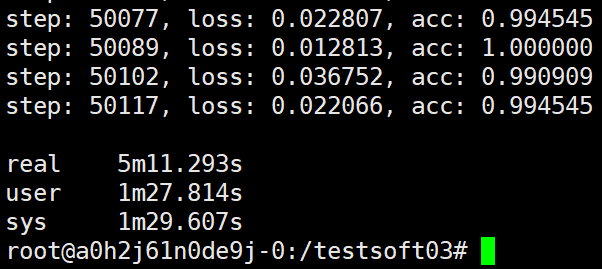
可以看到最终的结果还是要比预估的高些,这个运行时间与 ps和worker同一主机,共运行4个worker的情况是相当的,一个ps与4个worker共同主机耗时5分30左右,由此可以看到这里使用7个显卡的运算效率与4个显卡的运算效率相当,这也进一步说明了如果我们不会选择合适的多主机配置极有可能无法得到进一步的性能提升,比如这里我们其实相当于浪费了三个显卡。
总之,还是选择一个适合的主机配置才对。
分布式多主机时因为我们尽量要把ps放在性能性能最高的worker主机上,如果各个worker主机性能不同就可能会浪费掉性能较弱主机的性能,就像这里弱性能(2个GPU,1个GPU)的主机基本就没有在整个运行中发挥多大的作用。而不运行ps的主机上如果有worker也尽量只运行一个worker,因为非ps运行的主机上worker的数量增加对性能提升是由瓶颈的,比如这里不运行ps的主机不论运行多少worker运算时间都在30min左右,不运行ps的主机上如果有10个显卡也是需要30min左右的时间,而如果有10个不运行ps的worker主机每个主机一个GPU,那么这样的worker主机需要45min的运行时间,而运行ps的主机仍然需要5.5分钟的话,可得:
A主机,一个ps,4个worker(4GPU)
B主机, 10个worker(10GPU)
预估时间:
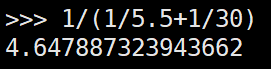
A主机,一个ps,4个worker(4GPU)
B1,2,3,4,5,6,7,8,9,10主机, 各运行一个worker,共10个worker,(共10GPU)
预估时间:(推荐的配置)

-------------------------------------------------------------------------
上面做的这些试验可以有效的说明以下问题:
1. worker与ps在同一主机时性能最高;worker和ps不在同一主机时,多个worker各自在独立的主机上(一个主机一个worker)性能最高,如果多个worker在同一个主机上时性能的提升会有一个瓶颈,上面的测试代码&环境下多个worker在一个主机时性能最高提升到30min左右就不会有明显提升了。
2. worker与ps在同一主机上时,加速比约等于worker个数;
worker与ps不在同一主机上时,且各worker独占一个主机时,加速比约等于worker个数;
worker与ps不在同一主机上时,多个worker运行在一个主机上时,如果各个worker所在的主机运行相同个数的worker,那么加速比约等于运行worker的主机个数。
从上面我们可以学到,写分布式的深度学习代码是尽量将ps和worker放在一个主机上,如果非要利用其它主机上的worker也尽量在其它主机上运行较少的worker。比如运行worker的主机上有4个GPU,我们在worker所在主机上启4个worker的性能会有瓶颈(次数4个worker的性能或许和2个worker的差不太多),而我们在worker主机上只启一个worker类型的task,在该task上同时管理4个显卡,使用多显卡梯度规约的方法(也就是单主机多显卡中的方法)会有效提升运行效率,这样我们将在worker主机上已经规约好的梯度再同其他worker主机在ps上进行再次的规约。在一个显卡上启动多个worker进行规约不如在该显卡上增加batch_size, 这样更有利于提升运行效率。
注:这里的GPU型号全部为V100,每个进程都是独占一个物理显卡的。
------------
使用浪潮AI计算平台之分布式计算(Tensorflow框架下 PS/Worker模式下的异步计算)的更多相关文章
- KubeEdge v0.2发布,全球首个K8S原生的边缘计算平台开放云端代码
KubeEdge开源背景 KubeEdge在18年11月24日的上海KubeCon上宣布开源,技术圈曾掀起一阵讨论边缘计算的风潮,从此翻开了边缘计算和云计算联动的新篇章. KubeEdge即Kube+ ...
- Android平台dalvik模式下java Hook框架ddi的分析(1)
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/75710411 一.前 言 在前面的博客中已经学习了作者crmulliner编写的, ...
- 使用QFuture类监控异步计算的结果
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/Amnes1a/article/details/65630701在Qt中,为我们提供了好几种使用线程的 ...
- 端云协同,打造更易用的AI计算平台
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<端云协同,HUAWEI HiAI Foundation打造更易用的AI计算平台>. 演讲嘉宾:华为海思AI技 ...
- 百度AI开发平台简介
AIstudio https://aistudio.baidu.com/aistudio/index 关于AI Studio AI Studio是基于百度深度学习平台飞桨的一站式AI开发平台,提供在线 ...
- 【华为昇腾】 序言:从昇腾AI软硬件平台聊起
2021年是很值得纪念的一年,从上半年开始跟随导师编写有关华为昇腾软件栈CANN的教材,一年的时间反复迭代 终于快要出版了. 这一系列博客可以视作我从编者的角度,重新梳理的全书思路.明年入职商汤之后要 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 百度AI开放平台- API实战调用
百度AI开放平台- API实战调用 一. 前言 首先说一下项目需求. 两个用户,分别上传了两段不同的文字,要计算两段文字相似度有多少,匹配数据库中的符合条件的数据,初步估计列出来会有60-1 ...
- Polaristech 刘洋:基于 OpenResty/Kong 构建边缘计算平台
2019 年 3 月 23 日,OpenResty 社区联合又拍云,举办 OpenResty × Open Talk 全国巡回沙龙·北京站,Polaristech 技术专家刘洋在活动上做了<基于 ...
- 携程实时计算平台架构与实践丨DataPipeline
文 | 潘国庆 携程大数据平台实时计算平台负责人 本文主要从携程大数据平台概况.架构设计及实现.在实现当中踩坑及填坑的过程.实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实 ...
随机推荐
- 蓝屏rtux64w10.sys
蓝屏rtux64w10.sys 环境: WIN10 + Realtek USB RTL8156B 2.5G网卡 表现: 局域网复制时,间隔性速度变为0,多次后,最终蓝屏. 解决方法: 更新驱动. 地 ...
- Chapter1 p2 vec
在上一小节中,我们完成了对BMPImage类的构建,成功实现了我们这个小小引擎的图像输出功能. 你已经完成了图像输出了,接着就开始路径追踪吧... 开个玩笑XD 对于曾经学习过一些图形学经典教材的人来 ...
- 报错解决 :Resolved [org.springframework.web.bind.MissingServletRequestParameterException
报错解决 :Resolved [org.springframework.web.bind.MissingServletRequestParameterException 解决方法:RequestPar ...
- maven和gradle环境变量配置及idea相关的设置
1.maven 环境变量添加之后,重新打开cmd窗口,验证是否配置成功. idea File >> Settings idea配置之后的验证: 2.gradle 环境变量添加之后,重新 ...
- idea编译报错 静态Map初始化报错java.lang.ExceptionInInitializerError
idea编译报错 静态Map初始化报错java.lang.ExceptionInInitializerError package cc.mrbird.utils; import java.util.H ...
- 将静态文件打包进nuget里 Net Core
我之前写了一个.net core 生成验证码的小工具 需要使用者先单独下载字体文件到本地在 install-package 感觉这样很捞也很不方便,但当时忙着做其他需求现在更新下. 其实很简单 vis ...
- DPO: Direct Preference Optimization 直接偏好优化(学习笔记)
学习参考:链接1 一.为什么要提出DPO 在之前,我们已经了解到基于人类反馈的强化学习RLHF分为三个阶段:全监督微调(SFT).奖励模型(RM).强化学习(PPO).但是RLHF面临缺陷:RLH ...
- STM32 CubeMX 学习:000-搭建开发环境
背景 了解了 STM32 标准库以后,为了紧跟发展的潮流,我们以 CubeMx为基础 开始进行 Hal(Hardware Abstract Layer, 硬件抽象层)库的学习. CubeMx 是一个 ...
- wireshark常用过滤指令
前言 wireshark是一款高效且免费的网络封包分析软件,现就自己使用过的过滤表达式进行记录,随时更新. 正文 与.或.非指令 与:and && 示例:tcp and ip.src ...
- Swift开发基础06-闭包
Swift的闭包(Closures)是一种将功能块和上下文整合并演示在代码中的一种手段.闭包可以捕获并存储其上下文中的变量和常量.与普遍存在于其他语言的匿名函数(如Python的lambda.Java ...