火山引擎在行为分析场景下的ClickHouse JOIN优化
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
背景
火山引擎增长分析DataFinder基于ClickHouse来进行行为日志的分析,ClickHouse的主要版本是基于社区版改进开发的字节内部版本。主要的表结构:

事件表:存储用户行为数据,以用户ID分shard存储。
--列出了主要的字段信息
CREATE TABLE tob_apps_all
(
`tea_app_id` UInt32, --应用ID
`device_id` String DEFAULT '', --设备ID
`time` UInt64,--事件日志接受时间
`event` String,--事件名称
`user_unique_id` String,--用户ID
`event_date` Date,--事件日志日期,由time转换而来
`hash_uid` UInt64 --用户ID hash过后的id,用来join降低内存消耗
)│
用户表:存储用户的属性数据,以用户ID分shard存储。
--列出了主要的字段信息
CREATE TABLE users_unique_all
(
`tea_app_id` UInt32, --应用ID
`user_unique_id` String DEFAULT '', -- 用户ID
`device_id` String DEFAULT '', -- 用户最近的设备ID
`hash_uid` UInt64,--用户ID hash过后的id,用来join降低内存消耗
`update_time` UInt64,--最近一次更新时间
`last_active_date` Date --用户最后活跃日期
)
设备表:存储设备相关的数据,以设备ID分shard存储。
--列出了主要的字段信息
CREATE TABLE devices_all
(
`tea_app_id` UInt32, --应用ID
`device_id` String DEFAULT '', --设备ID
`update_time` UInt64, --最近一次更新时间
`last_active_date` Date --用户最后活跃日期
)
业务对象表:存储业务对象相关的数据,每个shard存储全量的数据
--列出了主要的字段信息
CREATE TABLE rangers.items_all
(
`tea_app_id` UInt32,
`hash_item_id` Int64,
`item_name` String, --业务对象名称。比如商品
`item_id` String, --业务对象ID。比如商品id 1000001
`last_active_date` Date
)
业务挑战
随着接入应用以及应用的DAU日益增加,ClickHouse表的事件量增长迅速;并且基于行为数据需要分析的业务指标越来越复杂,需要JOIN的表增多;我们遇到有一些涉及到JOIN的复杂SQL执行效率低,内存和CPU资源占用高,导致分析接口响应时延和错误率增加。

关于Clickhouse的JOIN
在介绍优化之前,先介绍一下基本的ClickHouse JOIN的类型和实现方式
1. 分布式JOIN
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
基本执行过程:
- 一个Clickhouse节点作为Coordinator节点,给每个节点分发子查询,子查询sql(tob_apps_all替换成本地表,users_unique_all保持不变依然是分布式表)
每个节点执行Coordinator分发的sql时,发现users_unique_all是分布式表,就会去所有节点上去查询以下SQL(一共有N*N。N为shard数量)
- SELECT device_id, hash_uid FROM users_unique WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
- 每个节点从其他N-1个节点拉取2中子查询的全部数据,全量存储(内存or文件),进行本地JOIN
- Coordinator节点从每个节点拉取3中的结果集,然后做处理返回给client
存在的问题: - 子查询数量放大
- 每个节点都全量存储全量的数据
2. 分布式Global JOIN
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
GLOBAL ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
基本执行过程:
- 一个Clickhouse节点作为Coordinator节点,分发查询。在每个节点上执行sql(tob_apps_all替换成本地表,右表子查询替换成别名ut)
- Coordinator节点去其他节点拉取users_unique_all的全部数据,然后分发到全部节点(作为1中别名表ut的数据)
- 每个节点都会存储全量的2中分发的数据(内存or文件),进行本地local join
- Coordinator节点从每个节点拉取3中的结果集,然后做处理返回给client
存在的问题: - 每个节点都全量存储数据
- 如果右表较大,分发的数据较大,会占用网络带宽资源
3. 本地JOIN
SQL里面只有本地表的JOIN,只会在当前节点执行
SELECT et.os_name,ut.device_id AS user_device_id
FROM tob_apps et any LEFT JOIN
(SELECT device_id,
hash_uid
FROM rangers.users_unique
WHERE tea_app_id = 268411
AND last_active_date>='2022-08-06') ut
ON et.hash_uid=ut.hash_uid
WHERE tea_app_id = 268411
AND event='app_launch'
AND event_date='2022-08-06'
3.1 Hash join
- 右表全部数据加载到内存,再在内存构建hash table。key为joinkey
- 从左表分批读取数据,从右表hash table匹配数据
- 优点是:速度快 缺点是:右表数据量大的情况下占用内存
3.2 Merge join - 对右表排序,内部 block 切分,超出内存部分 flush 到磁盘上,内存大小通过参数设定
- 左表基于 block 排序,按照每个 block 依次与右表 merge
- 优点是:能有效控制内存 缺点是:大数据情况下速度会慢
优先使用hash join当内存达到一定阈值后再使用merge join,优先满足性能要求
解决方案
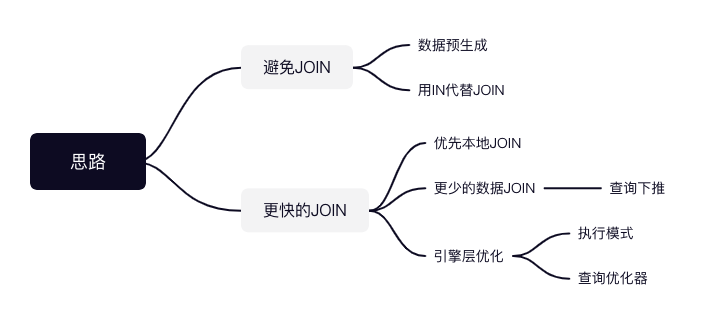
1. 避免JOIN
1.1 数据预生成
数据预生成(由Spark/Flink或者Clickhouse物化视图产出数据),形成大宽表,基于单表的查询是ClickHouse最为擅长的场景
我们有个指标,实现的SQL比较复杂(如下),每次实时查询很耗时,我们单独建了一个表table,由Spark每日构建出这个指标,查询时直接基于table查询
SELECT event_date,count(distinct uc1) AS uv,sum(value) AS sum_value, ......
FROM
(SELECT event_date,hash_uid AS uc1,sum(et.float_params{'amount'}) AS value, count(1) AS cnt, value*cnt AS multiple
FROM tob_apps_all et GLOBAL ANY LEFT JOIN
(SELECT hash_uid AS join_key,int_profiles{'$ab_time_34'}*1000 AS first_time
FROM users_unique_all
WHERE app_id = 10000000 AND last_active_date >= '2022-07-19' AND first_time is NOT null) upt
ON et.hash_uid=upt.join_key
WHERE (查询条件)
GROUP BY uc1,event_date)
GROUP BY event_date;
数据量2300W,查询时间由7秒->0.008秒。当然这种方式,需要维护额外的数据构建任务。总的思路就是不要让ClickHouse实时去JOIN

1.2 使用IN代替JOIN
JOIN需要基于内存构建hash table且需要存储右表全部的数据,然后再去匹配左表的数据。而IN查询会对右表的全部数据构建hash set,但是不需要匹配左表的数据,且不需要回写数据到block
比如
SELECT event_date, count()
FROM tob_apps_all et global any INNER JOIN
(SELECT hash_uid AS join_key
FROM users_unique_all
WHERE app_id = 10000000
AND last_active_date >= '2022-01-01') upt
ON et.hash_uid = upt.join_key
WHERE app_id = 10000000
AND event_date >= '2022-01-01'
AND event_date <= '2022-08-02'
GROUP BY event_date
可以改成如下形式:
SELECT event_date,
count()
FROM tob_apps_all
WHERE app_id = 10000000
AND event_date >= '2022-01-01'
AND event_date <= '2022-08-02'
AND hash_uid global IN
(SELECT hash_uid
FROM users_unique_all
WHERE (tea_app_id = 10000000)
AND (last_active_date >= '2022-01-01') )
GROUP BY event_date
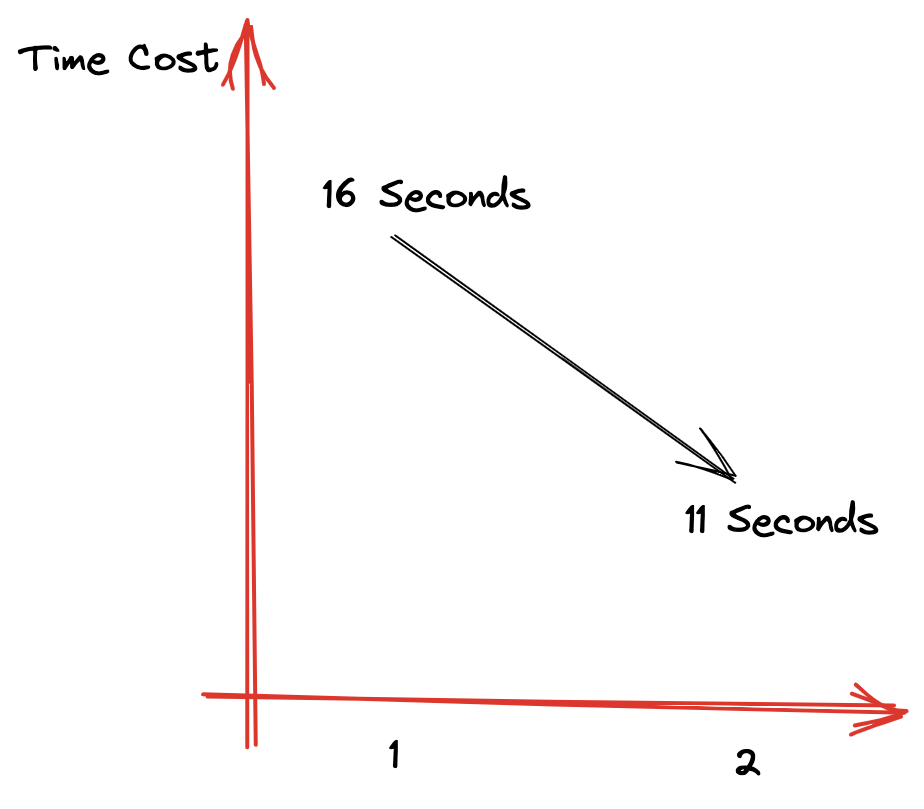
如果需要从右表提取出属性到外层进行计算,则不能使用IN来代替JOIN相同的条件下,上面的测试SQL,由JOIN时的16秒优化到了IN查询时的11秒
2. 更快的JOIN
2.1 优先本地JOIN
2.1.1 数据预先相同规则分区
也就是Colocate JOIN。优先将需要关联的表按照相同的规则进行分布,查询时就不需要分布式的JOIN
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
settings distributed_perfect_shard=1
比如事件表tob_apps_all和用户表users_unique_all都是按照用户ID来分shard存储的,相同的用户的两个表的数据都在同一个shard上,因此这两个表的JOIN就不需要分布式JOIN了
distributed_perfect_shard这个settings key是字节内部ClickHouse支持的,设置过这个参数,指定执行计划时就不会再执行分布式JOIN了
基本执行过程:
- 一个ClickHouse节点作为Coordinator节点,分发查询。在每个节点上执行sql(tob_apps_all、users_unique_all替换成本地表)
- 每个节点都执行1中分发的本地表join的SQL(这一步不再分发右表全量的数据)
- 数据再回传到coordinator节点,然后返回给client
2.1.2 数据冗余存储
如果一个表的数据量比较小,可以不分shard存储,每个shard都存储全量的数据,例如我们的业务对象表。查询时,不需要分布式JOIN,直接在本地进行JOIN即可
SELECT count()
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT item_id
FROM items_all
WHERE (tea_app_id = 268411)
) AS it ON et.item_id = it.item_id
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
settings distributed_perfect_shard=1
例如这个SQL,items_all表每个shard都存储同样的数据,这样也可以避免分布式JOIN带来的查询放大和全表数据分发问题
2.2 更少的数据
不论是分布式JOIN还是本地JOIN,都需要尽量让少的数据参与JOIN,既能提升查询速度也能减少资源消耗
2.2.1 SQL下推
ClickHouse对SQL的下推做的不太好,有些复杂的SQL下推会失效。因此,我们手动对SQL做了下推,目前正在测试基于查询优化器来帮助实现下推优化,以便让SQL更加简洁
下推的SQL:
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411)
AND (last_active_date >= '2022-08-06'
AND 用户属性条件1 OR 用户属性条件2)
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
settings distributed_perfect_shard=1
对应的不下推的SQL:
SELECT
et.os_name,
ut.device_id AS user_device_id
FROM tob_apps_all AS et
ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM rangers.users_unique_all
WHERE (tea_app_id = 268411)
AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
WHERE (tea_app_id = 268411)
AND (event = 'app_launch')
AND (event_date = '2022-08-06')
AND (ut.用户属性条件1 OR ut.用户属性条件2)
settings distributed_perfect_shard=1
可以看到,不下推的SQL更加简洁,直接基于JOIN过后的宽表进行过滤。但是ClickHouse可能会将不满足条件的users_unique_all数据也进行JOIN我们使用中有一个复杂的case,用户表过滤条件不下推有1千万+,SQL执行了3000秒依然执行超时,而做了下推之后60秒内就执行成功了

2.3Clickhouse引擎层优化
一个SQL实际在Clickhouse如何执行,对SQL的执行时间和资源消耗至关重要。社区版的Clickhouse在执行模型和SQL优化器上还要改进的空间,尤其是复杂SQL以及多JOIN的场景下
执行模型优化社区版的Clickhouse
目前还是一个两阶段执行的执行模型。第一阶段,Coordinator在收到查询后,将请求发送给对应的Worker节点。第二阶段,Worker节点完成计算,Coordinator在收到各Worker节点的数据后进行汇聚和处理,并将处理后的结果返回。
有以下几个问题:
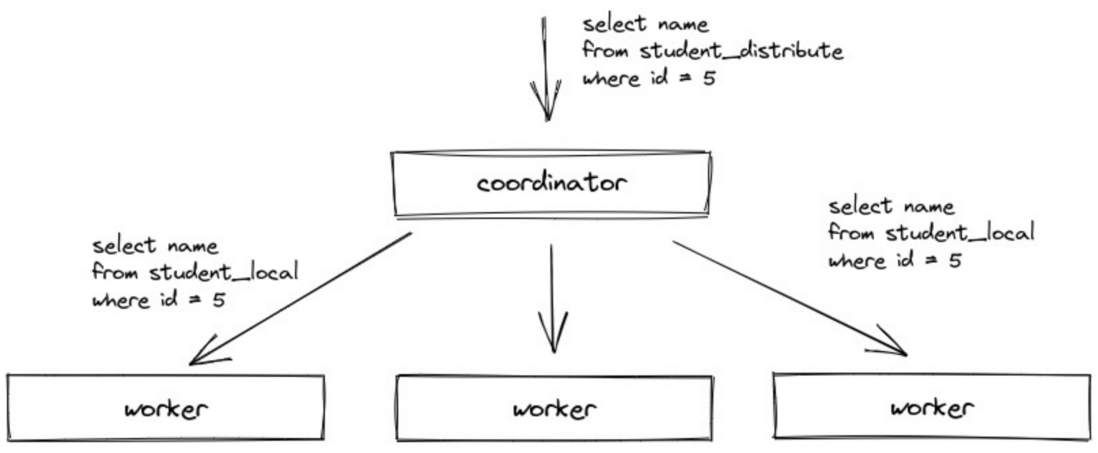
- 第二阶段的计算比较复杂时,Coordinator的节点计算压力大,容易成为瓶颈
- 不支持shuffle join,hash join时右表为大表时构建慢,容易OOM
- 对复杂查询的支持不友好
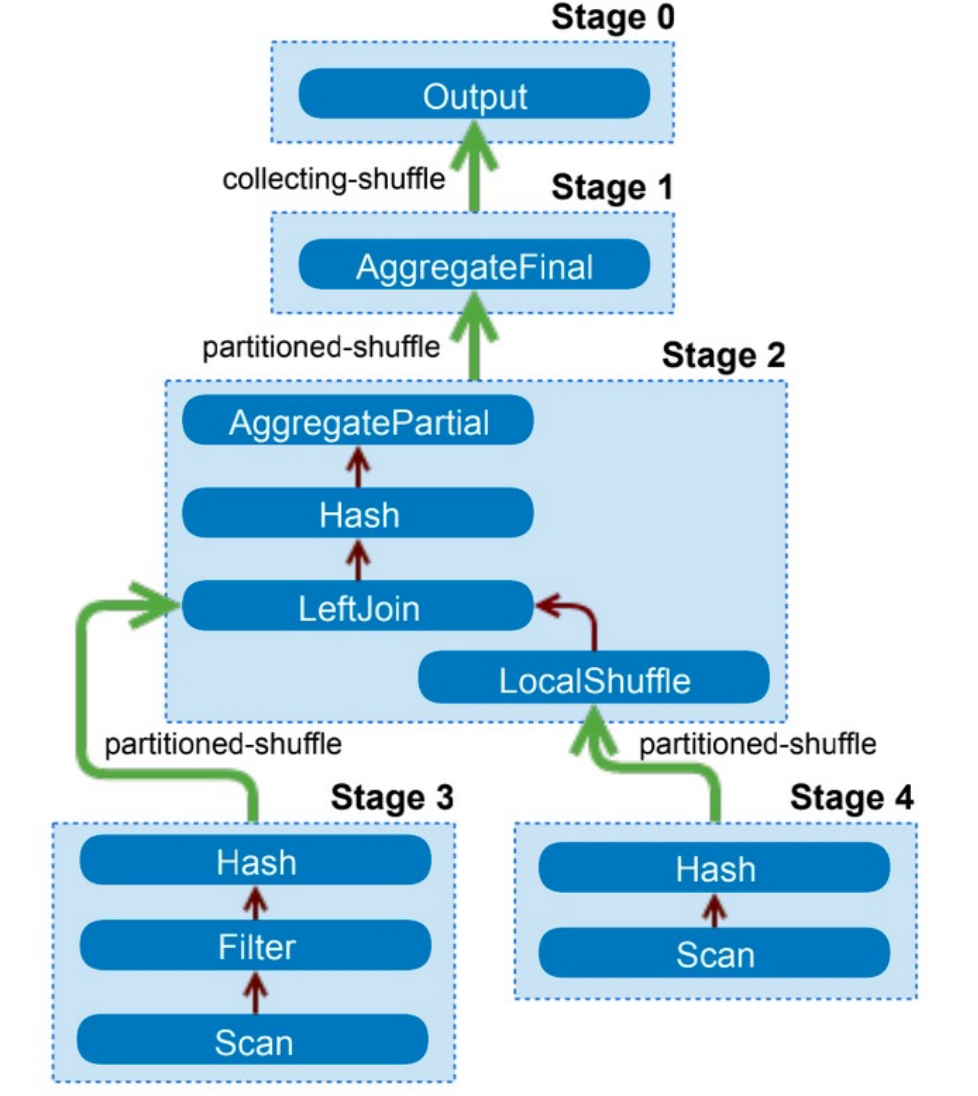
字节跳动ClickHouse团队为了解决上述问题,改进了执行模型,参考其他的分布式数据库引擎(例如Presto等),将一个复杂的Query按数据交换情况切分成多个 Stage,各Stage之间则通过Exchange完成数据交换。根据Stage依赖关系定义拓扑结构,产生DAG图,并根据DAG图调度Stage。例如两表Join,会先调度左右表读取Stage,之后再调度Join这个Stage,Join的Stage依赖于左右表的Stage。
举个例子
SELECT
et.os_name,
ut.device_id AS user_device_id,
dt.hash_did AS device_hashid
FROM tob_apps_all AS et
GLOBAL ANY LEFT JOIN
(
SELECT
device_id,
hash_uid
FROM users_unique_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS ut ON et.hash_uid = ut.hash_uid
GLOBAL ANY LEFT JOIN
(
SELECT
device_id,
hash_did
FROM devices_all
WHERE (tea_app_id = 268411) AND (last_active_date >= '2022-08-06')
) AS dt ON et.device_id = dt.device_id
WHERE (tea_app_id = 268411) AND (event = 'app_launch') AND (event_date = '2022-08-06')
LIMIT 10
Stage执行模型基本过程(可能的):
- 读取tob_apps_all数据,按照join key(hash_uid)进行shuffle,数据分发到每个节点。这是一个Stage
- 读取users_unique_all数据,按照join key(hash_uid)进行shuffle,数据分发到每个节点。这是一个Stage
- 上述两个表的数据,在每个节点上的数据进行本地join,然后再按照join key(device_id)进行shuffle。这是一个Stage
- 读取devices_all数据,按照join key(device_id)进行shuffle,这是一个Stage
- 第3步、第4步的数据,相同join key(device_id)的数据都在同一个节点上,然后进行本地JOIN,这是一个Stage
- 汇总数据,返回limit 10的数据。这是一个Stage
统计效果如下:
查询优化器
有了上面的stage的执行模型,可以灵活调整SQL的执行顺序,字节跳动Clickhouse团队自研了查询优化器,根据优化规则(基于规则和代价预估)对SQL的执行计划进行转换,一个执行计划经过优化规则后会变成另外一个执行计划,能够准确的选择出一条效率最高的执行路径,然后构建Stage的DAG图,大幅度降低查询时间
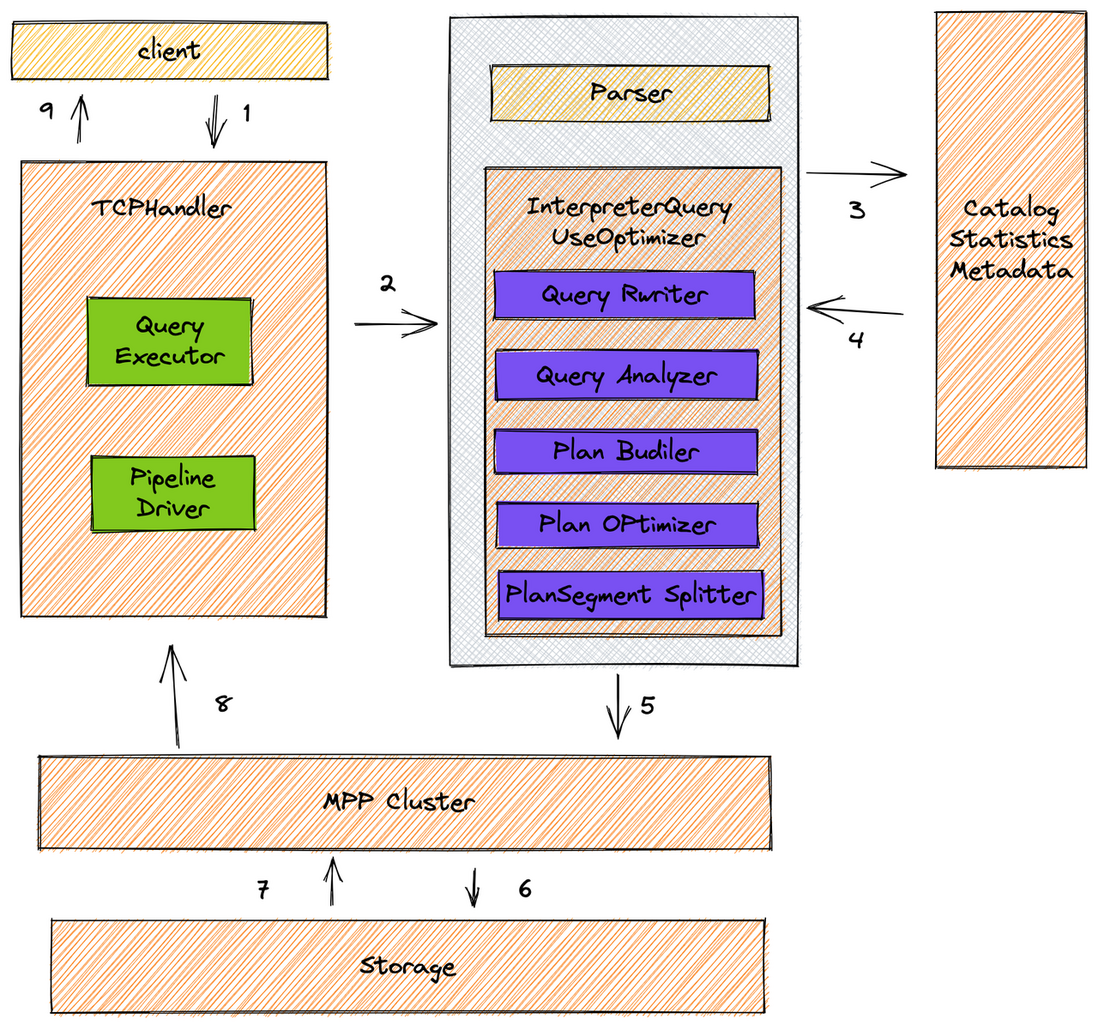
下图描述了整个查询的执行流程,从 SQL parse 到执行期间所有内容全部进行了重新实现(其中紫色模块),构建了一套完整的且规范的查询优化器。
还是上面的三表JOIN的例子,可能的一个执行过程是: - 查询优化器发现users_unique_all表与tob_apps_all表的分shard规则一样(基于用户ID),所以就不会先对表按 join key 进行 shuffle,users_unique与tob_apps直接基于本地表JOIN,然后再按照join key(device_id)进行shuffle。这是一个Stage
- 查询优化器根据规则或者代价预估决定设备表devices_all是需要broadcast join还是shuffle join 如果broadcast join:在一个节点查到全部的device数据,然后分发到其他节点。这是一个Stage 如果shuffle join:在每个节点对device数据按照join key(device_id)进行shuffle。这是一个Stage
- 汇总数据,返回limit 10的数据。这是一个Stage
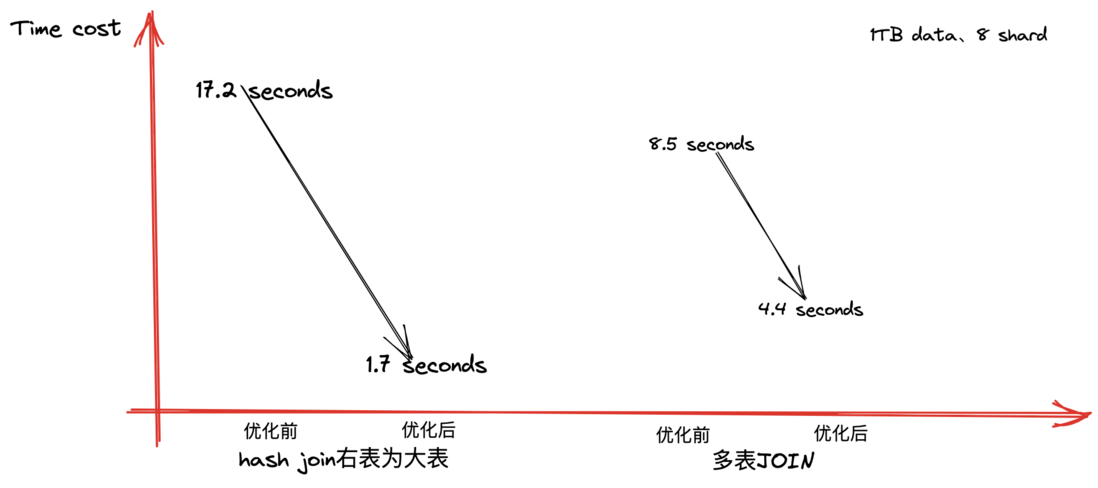
效果:可以看到,查询优化器能优化典型的复杂的SQL的执行效率,缩短执行时间
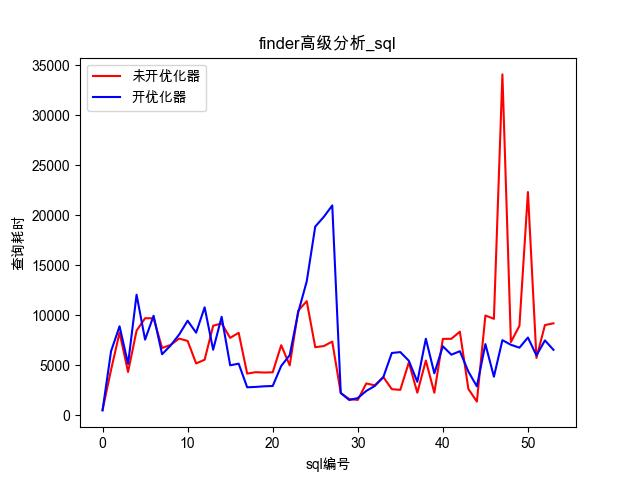
总结
ClickHouse最为擅长的领域是一个大宽表来进行查询,多表JOIN时Clickhouse性能表现不佳。作为业内领先的用户分析与运营平台,火山引擎增长分析DataFinder基于海量数据做到了复杂指标能够秒级查询。本文介绍了我们是如何优化Clickhouse JOIN查询的。
主要有以下几个方面:
- 减少参与JOIN的表以及数据量
- 优先使用本地JOIN,避免分布式JOIN带来的性能损耗
- 优化本地JOIN,优先使用内存进行JOIN
- 优化分布式JOIN的执行逻辑,依托于字节跳动对ClickHouse的深度定制化
立即跳转火山引擎DataFinder官网了解详情
火山引擎在行为分析场景下的ClickHouse JOIN优化的更多相关文章
- MySQL在大数据、高并发场景下的SQL语句优化和"最佳实践"
本文主要针对中小型应用或网站,重点探讨日常程序开发中SQL语句的优化问题,所谓“大数据”.“高并发”仅针对中小型应用而言,专业的数据库运维大神请无视.以下实践为个人在实际开发工作中,针对相对“大数据” ...
- 高性能场景下,HashMap的优化使用建议
1. HashMap 在JDK 7 与 JDK8 下的差别 顺便理一下HashMap.get(Object key)的几个关键步骤,作为后面讨论的基础. 1.1 获取key的HashCode并二次加工 ...
- 一种特殊场景下的HASH JOIN的优化为NEST LOOP.
应用场景: 有如下的SQL: select t.*, t1.ownerfrom t, t1where t.id=t1.id; 表t ,t1的数据量比较大,比如200W行.但是两张表能关联的行数却很少, ...
- 域控场景下windows安全日志的分析--审计认证行为和命令的历史记录
https://www.cnblogs.com/KevinGeorge/p/8563458.html 一.域控windows安全日志基本操作 1.打开powershell或者cmd 1 #gpedit ...
- 硬核测试:Pulsar 与 Kafka 在金融场景下的性能分析
背景 Apache Pulsar 是下一代分布式消息流平台,采用计算存储分层架构,具备多租户.高一致.高性能.百万 topic.数据平滑迁移等诸多优势.越来越多的企业正在使用 Pulsar 或者尝试将 ...
- 从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
本文来自火山引擎公众号,原文发布于2021-09-06. 近日,字节跳动旗下的企业级技术服务平台火山引擎正式对外发布「ByteHouse」,作为 ClickHouse 企业版,解决开源技术上手难 &a ...
- 火山引擎MARS-APM Plus x 飞书 |降低线上OOM,提高App性能稳定性
通过使用火山引擎MARS-APM Plus的memory graph功能,飞书研发团队有效分析定位问题线上case多达30例,线上OOM率降低到了0.8‰,降幅达到60%.大幅提升了用户体验,为飞书的 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
随机推荐
- [vue]精宏技术部试用期学习笔记 I
精宏技术部试用期学习笔记(vue) 什么是vue? 我个人对 vue 的理解 是把 html\css\js 三件套融合起来的结构,同时用组件化的思维把一个页面装填起来 同时让页面形成树状结构 优点是方 ...
- 通过HTML和JavaScript实现随机抽取幸运员工
需求描述: 公司经常会要求IT部门做一个随机抽取员工页面,今天我们通过HTML和JavaScript来实现 HTML 结构 首先,我们需要编写 HTML 代码来定义页面结构和元素.下面是 HTML 代 ...
- Kubernetes: kube-apiserver 之认证
kubernetes:kube-apiserver 系列文章: Kubernetes:kube-apiserver 之 scheme(一) Kubernetes:kube-apiserver 之 sc ...
- C语言二进制转换成八,十,十六进制
代码目前只支持整数转换,小数转换后续更新呀 #include <stdio.h> #include <math.h> void B_O(int n); void B_H(int ...
- 【Java】Java中StringBuilder()成员方法append()和toString()
StringBuilder就相当于C++的String长度可变,用于构造字符串对象,内部使用自动扩容的数组操作字符串数据. StringBuilder和StringBuffer使用的是相同的API[区 ...
- Linux下^m符号删除
Linux下^m符号删除 从Windows上复制的代码到Linux尾会有M字符,通过下命令可以删除. :%s/\r//
- 基于DotNetty实现自动发布 - 实现一键打包发布
前言 上一篇,我只实现了一键检测代码变化,本篇才是真正的实现了一键打包发布 效果图 客户端打包待发布文件 /// <summary> /// 把多个文件添加到压缩包 (保留文件夹层级关系) ...
- 用python将卡尔曼滤波技术和统计套利应用在期货市场
背景 根据当前中国的交易规则,股票不能做空.与更发达的市场相反,套利机会不容易实现.这表明那些寻找并能够利用它们的人可能会有机会. 因此,我决定使用统计套利和配对交易技术专注于中国的期货市场. 战略理 ...
- bash shell笔记整理——head命令
作用 我直接搬运官方英文了,这英文真的简单直白了,我英语辣鸡...毕竟我学历不行,觉得翻译不好就直接自己来吧.. Print the first 10 lines of each FILE to st ...
- 【eBPF-01】初见:基于 BCC 框架的第一个 eBPF 程序
闲言少叙,本文记录了如何零基础通过 BCC 框架,入门 eBPF 程序的开发,并实现几个简易的程序. 有关 eBPF 的介绍,网络上的资料有很多,本文暂且先不深入讨论,后面会再出一篇文章详细分析其原理 ...