云原生数据仓库TPC-H第一背后的Laser引擎大揭秘
一、ADB PG 和Laser 计算引擎的介绍
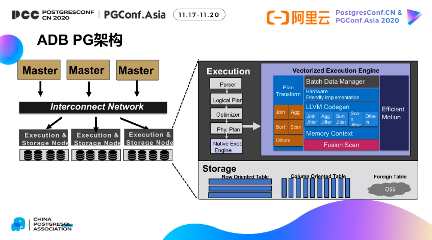
(一)ADB PG 架构
ADB PG 是一款云原生数据仓库,在保证事务ACID 能力的前提下,主要解决云上海
量数据的实时分析问题。它的架构与传统的MPP 数据仓库非常类似,主要分成两层,第一层是master 节点;第二层是work 节点。
master 节点主要承担实时写入和事务的处理,执行计划的生成。与其他的传统的
MPP 数据仓库不同的是ADB PG 的master 节点支持线性扩展,可以通过多个master
提升整体的事务能力、实时写入吞吐能力。
work 节点主要承担两个功能,第一个功能是执行,第二个功能是存储。执行引擎采用
的是向量化执行引擎,通过向量列式Batch 处理,codegen 技术,以及Fusion Scan 加速列式计算效率,在一些分析场景性能相对于普通的火山模型有了3~5 倍的提升。
同时它的存储节点不仅支持传统的行表和列表,也可以通过外表方式支持一些开源的表
结构,例如Parquet、ORC 等开源数据结构。ADB PG 可以直接分析保存在类似于像
OSS/HDFS 等分布式存储上的数据,减少数据的导入,可以大幅的降低用户的使用门槛和存储成本。
(二)为什么做Laser 计算引擎
为什么不采用PG 原生的计算引擎?
第一,PG 是一个传统的事务型数据库,它主要的优化大多来自于TP 的事务优化,并没有针对海量数据的分析计算做定制化的优化。
第二,PG 计算引擎采用解释执行的逻辑,复杂表达式采用函数执行树的递归的调用解
释执行。如图中的例子所示,每个表达式都被翻译成一个函数并组成一个执行树。每一条的数据都通过以上的函数递归调用去完成最终的计算。它带来的问题就是在海量千万以上的数据计算场景,虚函数调用大幅影响计算的性能。
第三, PG 默认只支持行存存储引擎,并不支持列存,所以它的整个计算执行过程是逐行处理数据,并没有对列存做定制化的优化。
第四, PG 代码具有非常好的扩展性、兼容性,但是在性能上考虑不多。例如说在计算过程中会涉及到内存的多次拷贝,序列化的开销比较高。
最后,PG 采用的是单分区单进程执行模式,无法充分发挥现代多核CPU 的优势。

(三)主流OLAP 业界方案
在开始ADB PG 计算引擎的选型过程,我们重点调研了当前主流的OLAP 业界主流
方案。
主要分成两大类,第一类:向量化执行;第二类:编译执行。
第一:向量化执行的基本做法,非常类似于火山模型,主要差别来自于它采用的是批量计算,每一批里优先列式计算。
这种模式优势在于可以充分发挥CPU 的流水线执行和内存的顺序访问,减少cache
的miss。缺点是第一实现逻辑比较复杂。第二,它需要批量的数据,并不适合每次计算数量较小的OLTP 场景。第三,它需要缓存批量数据,缓存本身带来一定的内存开销。
第二:编译执行基本做法是使用Codegen 技术,将所有的算子编译成函数,通过PUSH 的模型自下而上通过数据上推完成计算。
优点一:由于每次计算的都是一行数据,执行过程可以将这一行数据保存在寄存器里面,寄存器计算代替内存计算。优点二,它通过Codegen 技术把复杂的算子编译成一个函数,所以它非常适合计算复杂性非常高的计算加速。
缺点在于,PUSH 模型控制逻辑比较复杂,同时由于采用单条计算,无法做到内存的顺序访问,所以它整体的Cache miss 率比较高。典型的代表产品有Spark 和 Peloton。
ADB PG 综合考虑这两类方案的优缺点,最终使用了向量化的方案,主要考虑到ADB PG 原生PG 火山模型与向量化模型架构上较为接近,改造成向量计算引擎的逻辑顺畅,改造成本较编译执行小。

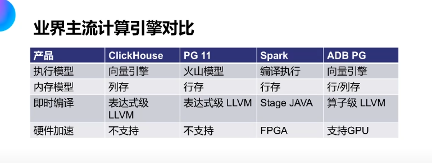
(四)业界主流计算引擎对比
我们对业界主流开源计算引擎做了对比,包括ClickHouse、PG11、Spark、ADBPG。在执行模型上,ClickHouse 和ADB PG、PG11 都采用的向量执行,Spark 采用
的是编译执行。
在内存模型上,ClickHouse 采用的是列存、PG11 采用行存、Spark 采用行存、ADB PG 采用行列混存。行列混存主要应用在类似于join、AGG 的场景,我们可以将多列group by、hashtable 数据拼成一列数据,可以充分发挥顺序访问的效率。
在即时编译上,ClickHouse 采用表达式级LLVM、PG11 采用表达式级LLVM,Spark 采用Stage Java 技术,ADB PG 采用算子级LLVM 技术。算子级LLVM 技术可以提升算子的计算性能。
在硬件加速上,ClickHouse 和PG11 都不支持硬件加速,Spark 支持FPGA 加速,ADB PG 采用IR 技术,可以通过将IR 翻译成对应的机器执行代码,从而支持GPU 加速。
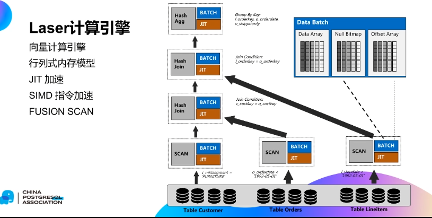
二、laser 计算引擎的核心技术
Laser 计算引擎的核心技术主要包括5 大块:
1. 向量计算引擎
2. 行列式内存模型
3. JIT 加速
4. SIMD 指令加速
5. FUSION SCAN
第一,向量计算引擎,传统火山模型中算子之间数据逐条交互,向量化计算引擎之间的交互的是BATCH 数据,然后在每个算子内部,采用的列式多条数据并行计算,这种逻辑可以充分的发挥CPU 流水线的作用。
在内存模型上,我们采用的是行列混存内存模型。在算子之间数据传递的是一个mini batch,mini batch 内部采用的行列混存的结构。由于每列数据在内存里都是连续摆放的,所以每次计算一列都是内存的顺序访问的过程。
第三,针对复杂计算,采用JIT 技术加速。可以利用LLVM CodeGen 技术将复杂计算过程转换成IR 代码,然后再通过IR 代码翻译成机器码。它的好处是可以避免类型判断,减少虚函数的调用,从而提升计算性能。
第四,针对一些简单场景(如:聚合场景、固定场景),利用现代CPU 的SIMD 指令,实现单条指令多条数据的并行执行,大幅提升这些简单场景的效率。
第五,针对列存场景,可以通过FUSION SCAN 去减少无用列读取,避免无用内存的中间拷贝,从而提升列表的计算性能。
(一)向量计算引擎
下图是一个典型的火山模型下SUM 算子的计算过程。对于火山模型,如果总共有n条数据,就会调用n 次的函数调用。右边是向量化执行过程,sum 函数接收输入参数是一个数组,而不是两个变量。整个执行过程,数据按2048 条分批处理,每2048 条数据调用一次sum 函数。

从这个例子中明显可以看出:
第一,Sum 函数调用从原来的n 次变成n÷2048,减少了多次。
第二,在函数内部处理中,由于计算的数据是一个batch,就可以充分发挥SIMD 指令加速效果,实现单条指令多条语句的并行计算。
第三,可以针对一些算子,如AGG 和JOIN,可以将AGG 和JOIN 算子函数合并一个函数,可以进一步的减少虚函数调用,提升系统性能。
由于计算过程中全部采用数组计算,可以将计算过程中的数组使用内存池化技术管理。通过MemoryPool 可以实现定长数据的内存的复用,避免频繁内存分配和释放,减少整个内存的碎片。在实际的TPC-H 的测试中,使用向量化引擎后,Q1 提升了120%,Q18提升了190%。
(二)SIMD指令加速
针对简单的加速,可以利用现代CPU 的SSE、AVX 指令,一条指令可以实现512bit 数据计算。
我们对TPCH 测试中的Lineitem 表做性能的对比测试,在使用SIMD 以后,整体的性能从原来的1 秒多降低到了200 多毫秒,有了4 倍左右的提升。

(三)Just-in-Time 编译优化
ADB PG 不仅支持表达式级的CodeGen,也支持算子级的CodeGen。每个plan的node 对应一个CodeGen 单元和一个Executor,CodeGen 单元根据plan node 生成code(IR),Executor 根据硬件平台选择不同的后端,将IR 生成对应的执行文件,并申请资源执行,最终的结果通过master 返回给客户端。
如图所示,对于这样一个简单的表达式,where a>10 and b<5,如果采用解释执行,总共包括三次函数调用,1、a>10;2、b<5;3、and 函数。
如果使用LLVM GIT 编译优化,上面的三个函数就编译成三条LLVM 指令,避免了三次函数调用的开销。
在TPCH 测试场景中,使用JIT 加速后整体的性能提升了20%~30%,并且在测试中发现,表达式越复杂,性能提升越明显。

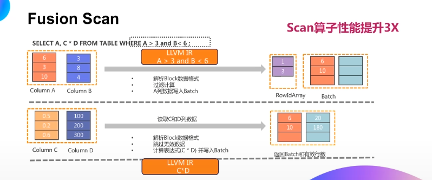
(四)Fusion Scan 优化
Fusion Scan 主要优化是减少无用列的读取,并且尽量的减少无用数据的读取和内存的拷贝。
举个例子,如果要查询满足a 大于3 和b 小于6 的a,c*d 的值,传统做法是对数据库中的每条数据数据,做a 大于3 和b 小于6 的条件过滤并且计算对应列的值。
Fusion Scan 的做法分成两阶段:
第一阶段是对过滤列做计算。把a 列和b 列的所有数据读出来,对每条数据进行判断。如图所示,满足条件的只有第一行第三行,我们把第一行第三行号保存在一个bitset中,同时把第一行和第三行的a 列值也保存在mini batch 中;
第二阶段是计算project 列,由于满足这个条件只有第一行和第三行,我们只需要把c 列和d 列的第一行和第三行的值读取出来。同时为了避免中间结果的数据拷贝,我们直接去将c 列和d 列的值结果相乘,把结果保存在mini batch 的第二列中。
在计算过程中,我们提前将表达式编译成IR 代码,可以避免了多次表达式函数的递归调用。
以上过程的主要优化点在于:
第一、避免无用列表D、E、F、G 列读取;
第二、实现了按需读取,只有满足条件的c 列和d 列的里面内容才进行计算和IO,不需要读那些不满足条件的数据。同时在c 和d 计算过程中,直接进行c 和d 的读取,无需内存中间结果的拷贝。
在实际执行过程中,Fusion Scan 结合列存块block 索引做进一步的优化。block
索引中包含了数据块的min 和max,我们可以将min 和max 值和where 条件做交集,
只有这个交集非空的话,才会去真正读取block 的值,否则可以直接跳过这个block。
通过Fusion Scan 的技术,在列存的场景Scan 算子整体的性能有3 倍以上的提升。
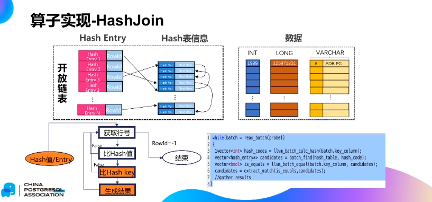
(五)算子实现-HashJoin
HashJoin 的向量化执行引擎,算法采用Hybrid Hash Join,HashTable 采用开放链表数据结构。
HashJoin 的实现过程,主要包括:
1. 把左表probe 列的值取出来计算它的Hash 值。
2. Hashcode 的值去模entry 个数,获取对应的行号。
3. 对应行号里的所有的entry 对象,比较它的哈希值,如果哈希值相同,再去比较join key。
4. 如果join key 相同,则代表probe 成功,拼接左右表的对应列并生成最终的结果。
如何将这样的执行过程用向量化实现?
1. 从左表里面读取批量数据。
2. 使用CodeGen 技术批量计算hash code 值。
3. 根据hashcode 值,批量查找hash table,得到可能的结果集。
4. 批量比较左右表的join 列值,如果匹配的话,则拼接左右表的对应列并生成最终的结果。
与原来行式的火山模型比起来,向量化执行主要差一点在于:
1. 按列计算;
2. 批量计算。
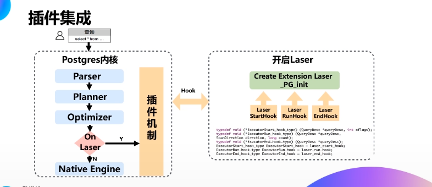
(六)插件集成
计算引擎如何与ADB PG 代码融合?
ADB PG 同时支持PG 计算引擎和Laser 向量化计算引擎。优化器会自动根据SQL 的pattern 和扫描的数据量来决定是否使用Laser。如果扫描数据量太少,则使用原生的计算引擎。如果数据量足够多,并且这些SQL pattern 比较适合使用向量化执行引擎的,就使用laser 计算引擎。
Laser 引擎的所有代码采用插件模式,代码独立。好处在于代码可以和原生代码之间完全是松耦合关系,不会影响PG 的原生代码,同时可以复用里面的一些函数和数据结构。插件模式还带来一个好处,就是可以实现热升级。因为采用动态库方式,能够在不重启PGdameon 进程的情况下,替换插件,完成升级LASER 引擎。
唯一需要修改的是三个stub 函数—ExecutorStart、ExecutorRun、ExecutorEnd。
(七)TPC-H 结果
2020 年5 月20 号,我们完成了TPC-H 30TB 场景测试,拿到了世界第一的成绩。相比于第二名微软SQL Server 2019,整体性能提升了290%,且成本只有SQL
Server 的1/4。
通过性能指标统计,Laser 计算引擎对性能提升起了至关重要的价值,相对于PG 计算引擎,性能提升了两倍之多。细分计算引擎的各种优化,其中大半的性能提升都是来自于向量化提升。其次是是JIT 加速,主要来源于表达式的计算。第三来自于是Fusion Scan,针对列存场景下,我们通过Fusion Scan,减少了内存的拷贝,减少了无用的读取。最后还有小部分来自于SIMD 指令的提升。

三、计算引擎的未来展望
整体的未来转化(以未来一年为计划):
第一:2020 年12 月,支持窗口函数,完成全算子的向量化改造。
第二:2020 年3 月,完成网络motion 重构。
第三:2020 年6 月,完成算子并行执行优化,可以充分利用多核能力。
第四:2020 年9 月,完成优化器适配。优化器不仅适配计划数据书,同时能够根据计算引擎来做动态识别,能够感知到数据的动态变化,再去动态去调整执行计划。
本文为阿里云原创内容,未经允许不得转载。
云原生数据仓库TPC-H第一背后的Laser引擎大揭秘的更多相关文章
- DTCC 2020 | 阿里云李飞飞:云原生分布式数据库与数据仓库系统点亮数据上云之路
简介: 数据库将面临怎样的变革?云原生数据库与数据仓库有哪些独特优势?在日前的 DTCC 2020大会上,阿里巴巴集团副总裁.阿里云数据库产品事业部总裁.ACM杰出科学家李飞飞就<云原生分布式数 ...
- 云原生生态周报 Vol. 13 | Forrester 发布企业级容器平台报告
业界要闻 近日,全球知名市场调研机构 Forrester 发布首个企业级公共云容器平台报告.其中,阿里云容器服务的市场表现全球前三.中国第一,同时创造中国企业最好成绩,进入强劲表现者象限.报告显示,阿 ...
- 云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
引言 随着模型规模和数据量的不断增大,分布式训练已经成为了工业界主流的 AI 模型训练方式.基于 Kubernetes 的 Kubeflow 项目,能够很好地承载分布式训练的工作负载,业已成为了云原生 ...
- 第一届云原生应用大赛火热报名中! helm install “一键安装”应用触手可及!
云原生应用,是指符合“云原生”理念的应用开发与交付模式,这是当前在云时代最受欢迎的应用开发最佳实践. 在现今的云原生生态当中,已经有很多成熟的开源软件被制作成了 Helm Charts,使得用户可以非 ...
- 新书《OpenShift云原生架构:原理与实践》第一章第三节:企业级PaaS平台OpenShift
近十年来,信息技术领域在经历一场技术大变革,这场变革正将我们由传统IT架构及其所支撑的臃肿应用系统时代,迁移至云原生架构及其所支撑的敏捷应用系统时代.在这场变革中,新技术的出现.更新和淘汰之迅速,以及 ...
- 始于阿里,回归社区:阿里8个项目进入CNCF云原生全景图
破土而出的生命力,源自理想主义者心底对技术的信念. 云原生技术正席卷全球,云原生基金会在去年KubeCon +CloudNativeCon NA的现场宣布: 其正在孵化的项目已达14个,入驻的厂家或产 ...
- Kubernetes 入门必备云原生发展简史
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使 "未来的软件一定是生长于云上的"这是云原生理念的最核心假设.而所谓"云原生",实际上就是在定义一条能 ...
- CNCF官方大使张磊:什么是云原生?
作者|张磊 阿里云容器平台高级技术专家,CNCF 官方大使 编者说: 从 2015 年 Google 牵头成立 CNCF 以来,云原生技术开始进入公众的视线并取得快速的发展,到 2018 年包括 Go ...
- 初探云原生应用管理(二): 为什么你必须尽快转向 Helm v3
系列介绍:这个系列是介绍如何用云原生技术来构建.测试.部署.和管理应用的内容专辑.做这个系列的初衷是为了推广云原生应用管理的最佳实践,以及传播开源标准和知识.在这个系列文章的开篇初探云原生应用管理(一 ...
- 云原生生态周报 Vol. 14 | K8s CVE 修复指南
业界要闻 Mesosphere 公司正式更名为 D2IQ, 关注云原生. Mesosophere 公司日前发布官方声明正式更名为:D2iQ(Day-Two-I-Q),称关注点转向 Kubernetes ...
随机推荐
- 【2311. 小于等于 K 的最长二进制子序列】贪心
class Solution { public static void main(String[] args) { Solution solution = new Solution(); System ...
- 大年学习linux(第四节---文件权限)
四.文件权限 文件类型 Linux文件类型和linux文件的文件名所代表的意义是两个不同的概念.我们通过一般应用程序而创建的比如 file.txt.file.tar.gz ,这些文件虽然要用不同的程序 ...
- 三维模型3DTile格式轻量化顶点压缩主要技术方法分析
三维模型3DTile格式轻量化顶点压缩主要技术方法分析 三维模型顶点压缩是3DTile格式轻量化压缩的重要组成部分,能有效减小数据大小,提高数据处理效率.下面将详细分析几种主要的顶点压缩技术方法: 预 ...
- 初探修模的三维模型OBJ格式轻量化压缩的遇到常见问题与处理方法
初探修模的三维模型OBJ格式轻量化压缩的遇到常见问题与处理方法 在对经过修模的三维模型进行OBJ格式轻量化压缩处理的过程中,可能会遇到一些常见问题.以下是一些常见问题以及相应的处理方法: 1.顶点丢失 ...
- Vue3.0 所采用的 Composition Api 与 Vue2.x 使用的 Options Api 有什么不同?
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 开始之前 Composition API 可以说是Vue3的最大特点,那么为什么要推出Composition Api,解决了什么问题? 通 ...
- CMake使用Boost
cmake_minimum_required(VERSION 2.8) set(Boost_INCLUDE_DIR /usr/local/src/boost_1_46_1) set(Boost_LIB ...
- 基于quartus的FPGA学习系列
基于quartus学习 1.学习目标 quartus是altera的FPGA设计软件,用起来的感觉要比xilinx快.这里可以使用其完成各种基本的设计(就是不使用非必须IP核),一些基础的实验都可以在 ...
- 优先队列(PriorityQueue)
> 此代码是在最大堆的基础上二次封装,请先阅读底层代码MaxHeap 优先队列 普通队列:先进先出:后进后出 优先队列:出队顺序和⼊入队顺序无关:和优先级相关: 为什么使用堆 代码清单 Queu ...
- 【Learning eBPF-2】eBPF 的“Hello world”
前一章讲了 eBPF 为什么这么吊,不理解没关系,现在开始,我们通过一个 "Hello world" 例子,来真正入门一下. BCC Python 框架是上手 eBPF 的最友好方 ...
- #二叉堆#JZOJ 4320 旅行
分析 有一个很重要的性质就是如果经过道路数为奇数,把两个点到根节点的路径长加起来就是两个点间的路径长(正负消掉了) 而且众所周知的是奇数+偶数=奇数 可以预处理每个点到根节点的路径长度(按照题目要求) ...