Quick BI产品核心功能大图(四):Quick引擎加速--十亿数据亚秒级分析
简介: 随着数字化进程的深入,数据应用的价值被越来越多的企业所重视。基于数据进行决策分析是应用价值体现的重要场景,不同行业和体量的公司广泛依赖BI产品制作报表、仪表板和数据门户,以此进行决策分析。
在利用BI产品进行数据分析过程中,数据处理“慢”会为业务带来很多的困扰,可以想象一下:
- 给老板看的报表加载展示非常慢,有的时候还会崩掉,本想做好向上汇报,但却给老板带来了糟糕的体验~
- 分析师或业务同学,做数据探索式分析,拖拽一个指标需要几分钟才能看到结果,严重影响工作效率,打断分析思路~
“慢”虽然只是一种难以精确定义的体感,但想要解决以上问题,就需要BI产品拥有很强的大数据处理架构和能力,可以横向扩展支持不断增长的数据量和计算任务。
Quick BI:阿里云飞天操作系统上的云BI
Quick BI产品是在阿里云飞天操作系统上打造的云BI软件,支持SAAS模式和私有化部署,定位多场景、多端、多行业的消费式BI,本篇为大家详细介绍产品内核Quick引擎。

Quick BI基于阿里云横向可扩展的架构底座,不但拥有可视化分析、中国式报表、自助分析等传统BI能力,同时拥有企业级安全底座、移动端和三方系统开放集成能力。
Quick BI构建了自己的计算内核Quick引擎,托管在阿里云上的SAAS服务实测数据十亿级数据在0.5秒以内完成聚合分析,另外由于依托阿里云,计算资源支持横向扩展,通过增加服务器还可以提供更强大的数据分析计算能力。
Quick引擎:多模式BI计算引擎
Quick引擎作为Quick BI的计算底座,是一个多模式的BI计算引擎,支持数据库直接连接、抽取加速、实时加速、查询缓存、维值加速等多种计算模式,为不同用户提供最适合自身场景的高效计算方案。

上图为Quick引擎架构图,从Quick BI产品使用链路上,分为数据源、数据集和数据作品三部分。数据源是底层的数据库连接,数据集用于对数据源里的表进行建模(表关联、字段类型建模等),把一张或多张表变成一个上层数据作品(仪表板、电子表格、即席分析)可用的数据对象。
Quick引擎架构在数据源和数据集之间,用来处理上层数据作品发送到数据集最终下放到数据源上的查询,在技术实现上Quick引擎分为三条链路,数据库直连、数据库实时加速、数据库抽取,在这三条链路进行了技术层抽象。
从用户使用视角来看,我们提供如下5种计算模式:
(1)直连模式:计算负载直接跑在连接到BI产品的数据库或数仓上,支持几十种数据源,所有版本用户都可使用,非常适用于底层计算资源满足查询负载的场景;
(2)抽取加速:把客户数据库或数仓的数据抽取到Quick引擎的高性能列式存储引擎中,支持全量模式和增量模式,分析计算负载直接跑在Quick BI引擎中,充分利用Quick引擎性能的同时,减少客户数仓的负担,专业版客户可用,非常适用于企业没有独立数仓或数仓负载过重的情况;
(3)实时加速:基于阿里云DLA(Data Lake Analysis)内存计算引擎,查询时实时从客户数据库取数据,中间用DLA内存引擎加速计算,专业版客户可用,目前支持阿里云Max Compute数仓,非常适合Max Compute数仓实时分析,更多数据库支持开通中;
(4)查询缓存:所有版本用户可用,应用端报表、仪表板在访问时临时查询结果被缓存下来,在配置的缓存有效时间内,接下来其他用户相同的查询直接取缓存结果,加快返回速度同时避免重复计算的资源消耗,非常适合应用端是重复查询较多的场景,比如可视化展示类;
(5)维值加速:所有版本用户可用,基于直连模式和维表配置实现,通过配置维值加速使得高频且耗时的维度字段查询计算直接在数据库维表上进行,而不是在原始的明细表上进行,比如即席分析和查询控件的维值查询,在这类场景下相比不进行维值加速可快速返回结果且节省计算资源;
Quick引擎 - 使用指南
在正式开始介绍每种引擎具体用法时,先结合每种引擎特点给出一个场景使用指南,方便用户在不同场景下选择最合适的引擎。

Quick引擎通过数据集不同配置会采用不同计算模式,依据数据集不同情况,建议如下:
(1)数据集默认采用直连模式,如果查询性能良好,则可不进行额外配置,如果无法满足要求,则进行以下判断
(2)数据集主要被用在仪表板、报表中,偏固定数据展示类的,没有被很多查询控件控制
- 实效性要求不是非常高,很适合配缓存,基本可以解决问题了(可能80%以上可以解决)
- 实效性要求不是非常高,如果配了缓存还不行,比如某个数据集被做了很多报表,第一次缓存查询就吃不消,MySQL类非OLAP数据库建议用抽取加速,ADB类的OLAP数据库,建议首先优化下数据建模(比如是不是大表join大表),其次建议采用抽取加速分担些负载
- 实效性要求很高,每次看,都想看最新数据,ODPS数据源可以用DLA实时加速
(3)数据集主要被用在即席分析、电子表格分析这类偏个性分析查询中,或者有非常多查询控件的仪表板报表中,配缓存意义不是很大(有点作用),建议:
- 底层数据库不是OLAP,比如MySQL,运行很慢,首先建议采用抽取加速,其次建议优化数据建模
- 底层数据库是OLAP,比如ADB,运行很慢,建议首先优化下数据建模(比如是不是大表join大表),其次建议采用抽取加速分担些负载
- 底层数据库是ODPS,运行很慢,如果实效性要求高,建议DLA实时加速,实效性要求不高,建议抽取加速
(4)数据集维度字段被频繁用于查询控件或即席分析,推荐为该字段配置维值加速
Quick引擎 - 直连模式
直连模式是Quick引擎查询的默认模式,所有的查询会发送给底层数据库或数仓执行,Quick BI直连模式支持几十种云和自建数据库。
在数据集页面点击“新建数据集”,选择已配置的数据源,左侧面板会展示该数据源里的所有表,拖入一张或多张表到面板中,即可在数据预览区域进行字段配置,配置完成后保存数据集,方可进行后续分析。数据集保存后,后续所建的分析查询默认直连模式。

Quick引擎 - 抽取加速
当直连模式查询过多或者数据量过大时,会导致底层数据库负载过重查询变慢,上层仪表表展示和分析就会变慢,出现文章开头所讲的困扰,此时可以考虑Quick引擎的抽取加速。
抽取加速是专业版特有功能,目前覆盖MySQL、ADB for MySQL和MaxCompute三种数据源,支持全量抽取和增量抽取数据到Quick引擎的高性能列式存储分析型数据库中,抽取后的数据查询直接在列式分析数据库中完成而无需发到客户数据库上,提升数据查询性能,同时减少客户数据库负载。
点击数据集菜单,选择“加速配置”,在第一个 “Quick引擎”Tab点击开启引擎,选择抽取加速:
- 加速时间可选“手动触发”和“定时加速”,定时加速设置时间后定期触发抽取任务
- 智能聚合抽取支持“全表加速”、“预计算”、“全表计算+预计算”三种模式,其中全表加速抽取全表数据,预计算基于历史查询智能预计算查询结果,节省抽取空间
- 勾选按日期加速,可以选择日期字段,每日根据日期字段增量抽取
配置完成后,点击保存,抽取任务即会自动触发,抽取完成后,之后的数据查询将在抽取引擎数据库中完成。
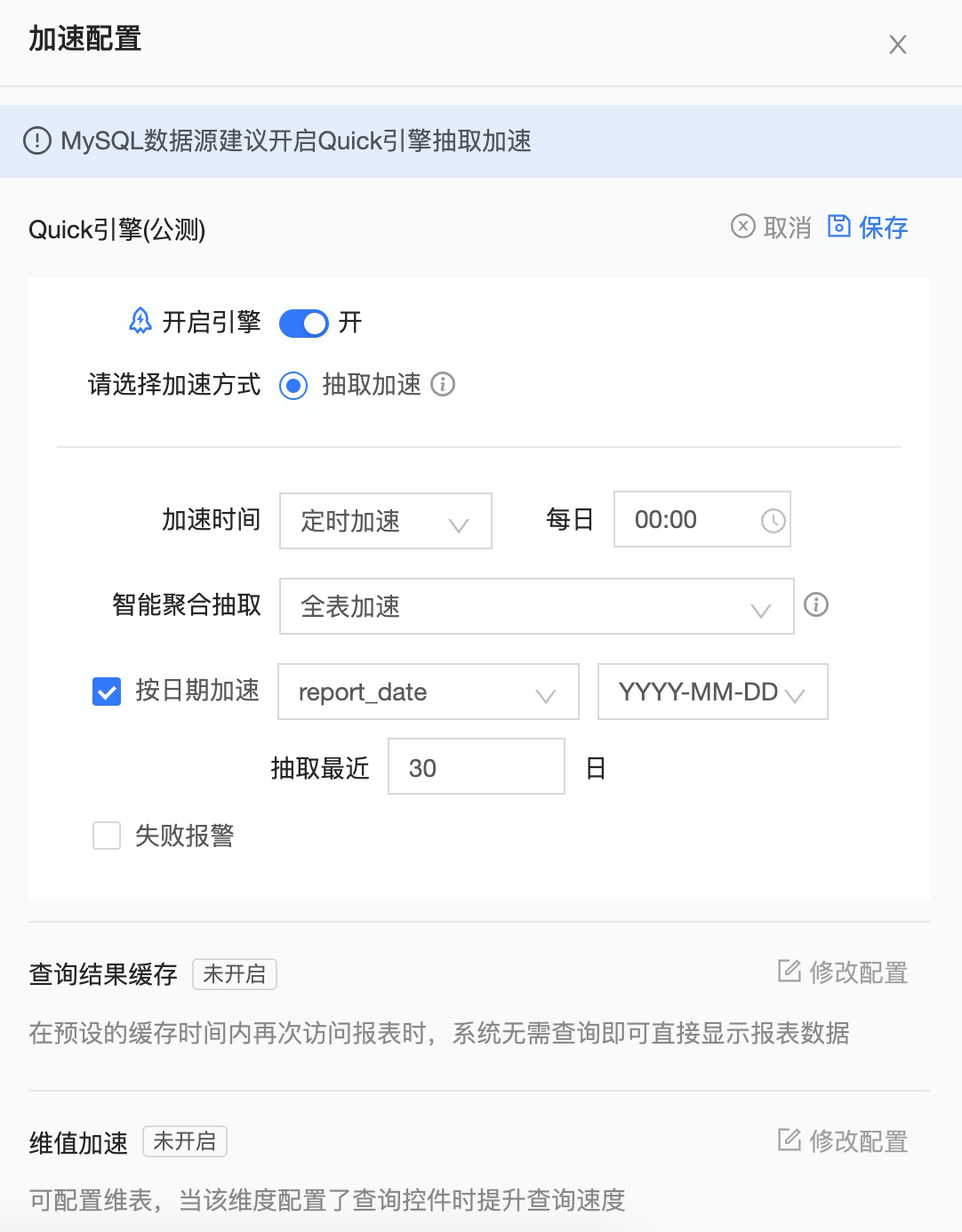
Quick引擎抽取加速性能测试,10亿数据sum、count、avg和median等聚合均在0.5秒内返回,具备十亿级数据亚秒级分析的能力,如下表为性能测试结果。
|
数据量 |
sum聚合 |
count聚合 |
avg聚合 |
median聚合 |
|
1亿 |
0.043 s |
0.044 s |
0.040 s |
0.061 s |
|
10亿 |
0.3 s |
0.21 s |
0.25 s |
0.35 s |
同时由于Quick BI是依托于阿里云飞天底座的产品架构,具备横向扩展的能力,Quick引擎随着机器数量的增加数据处理能力会不断增强,理论上具有无限扩展的能力。
Quick引擎 - 实时加速
当直连模式出现性能问题,同时对数据的实效性要求较高,天粒度更新无法满足要求,而需要小时或分钟粒度数据更新,由于抽取加速是天粒度数据更新而无法采用,此时可以考虑另一种选择,采用实时加速来进行高实效数据的查询加速。
与抽取加速一样,实时加速也是专业版特有功能,目前支持MaxCompute数据源,基于阿里云DLA(Data Lake Analysis)内存计算引擎,查询时把数据实时加载到DLA中进行计算,提升查询性能,可以把离线型数仓MaxCompute通过实时加速变成在线分析型数仓。
在数据集加速配置页面,开启Quick引擎,切换到实时加速,保存即可开启数据集实时加速模式。

Quick引擎 - 查询缓存
查询缓存的原理是应用端报表、仪表板在访问时临时查询结果被缓存下来,在配置的缓存有效时间内,接下来其他用户相同的查询直接取缓存结果,命中缓存的查询可以立即返回结果,没有命中缓存的查询会被发到底层数据库进行查询,查询返回后该查询也会被缓存下来供接下来使用。
结果缓存是一种应用范围很广且非常有效的数据查询加速方式,它适用于所有数据源,对不同版本用户都可用,对一定时间内存在重复查询的数据集都可以配置查询缓存,特别是重复查询较多的场景,比如仪表板展示类,可以大幅提升查询性能。
在加速配置页面,开启查询结果缓存,可配置不同缓存时间,表示缓存生效的有效期,如果数据是非小时粒度实效性,建议选择12小时。

Quick引擎 - 维值加速
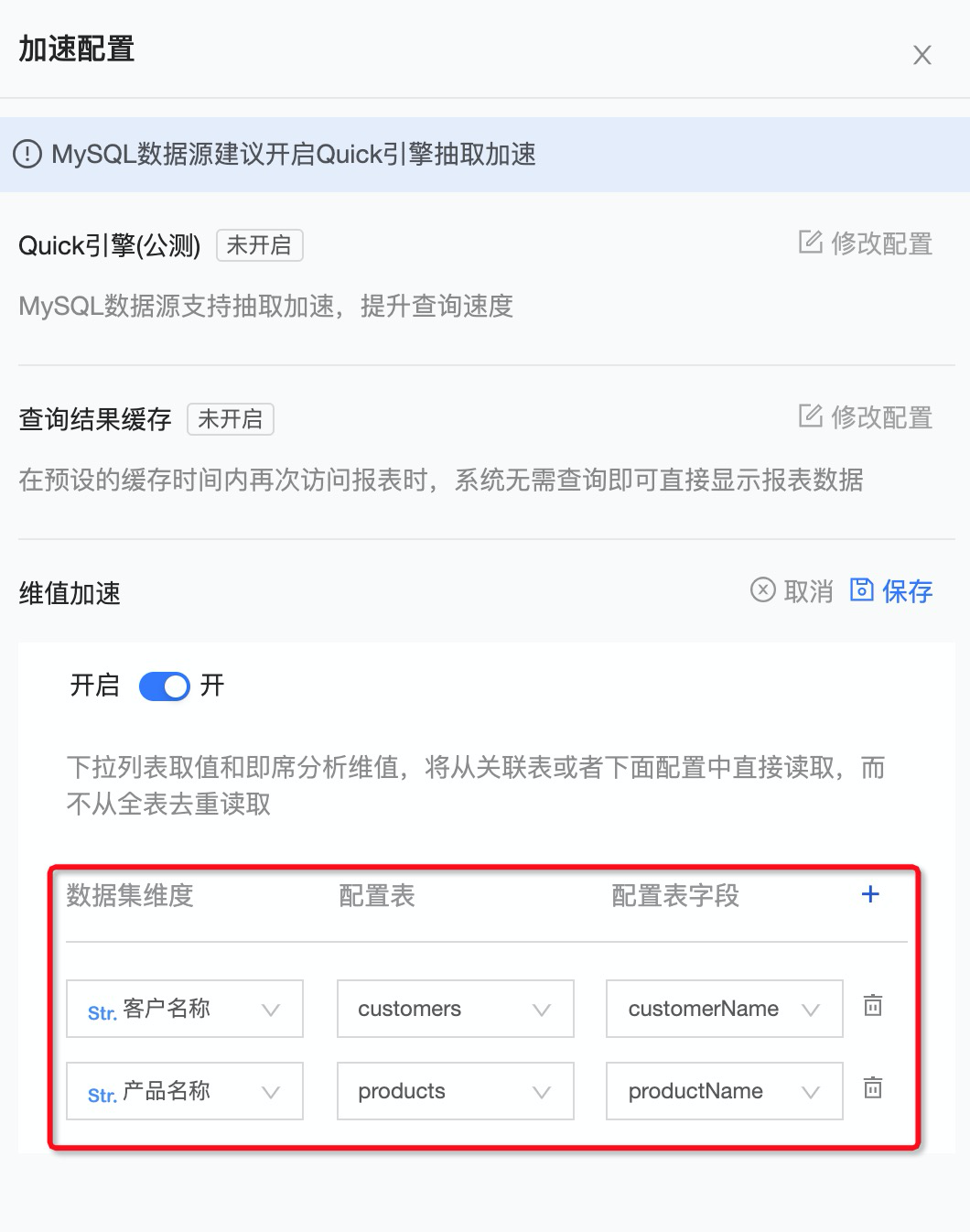
在直连查询中,关于维度值的查询是比较耗时的,比如商品名称、客户名称、城市名称等,因为这类查询在直连模式下需要去底层数据库做去重聚合操作,要扫描全表数据,所以比较耗时。而在某些场景下,这类查询操作可能会非常频繁的出现,比如即席分析的维度值分析和查询控件的维度值查询,在这类场景下可以通过配置维值加速提升查询性能。
在加速配置页面,开启维值加速,该数据集是一张订单明细表,在前端仪表板页面经常需要基于客户名称和产品名称查询成交情况,因此把这两个字段配置维值加速,分别对应上底层数据库两张用户和商品维表的字段,之后维度值的查询将直接从这两张维表中取,而无需去明细表做聚合,从而提升查询速度。
以上是关于Quick BI的计算内核Quick引擎的功能和使用场景的介绍,依托阿里云的计算底座,Quick引擎实现了十亿级数据亚秒级分析的能力,让上层分析可视化应用在大数据时代真正飞起来。
原文链接
本文为阿里云原创内容,未经允许不得转载。
Quick BI产品核心功能大图(四):Quick引擎加速--十亿数据亚秒级分析的更多相关文章
- Quick BI的宝藏工具——交叉表
对于普通的表格展示数据,相信大家都非常熟悉了,今天给大家介绍的是BI领域的分析利器-交叉表,这个在BI分析场景中使用占比最多的分析利器.通过交叉表对数据的承载和管理,用户可以一目了然地分析出各种场景指 ...
- Quick BI 支持多种数据源进行多维分析
一.摘要 随着互联网的高速发展,数据量爆发式增长的同时,数据的存储形式也开始呈现出多样性,有结构化存储,如 Mysql, Oracle, SQLServer 等,半结构化甚至非结构化存储,如HBase ...
- 大数据下BI产品如何发挥最大价值
看到这个题目,你是否总感觉云里雾里?你是否真正懂什么叫“大数据”?商业智能BI和大数据又有着什么千丝万缕的联系?为什么说商业智能BI能在大数据中发挥价值? 大数据,指的是所涉及的数据资料量规模巨大到无 ...
- Quick BI功能篇之(一):20分钟入门
前言: 最近小编帮助隔壁团队一个小姐姐解决了个大难题:给老板汇报业绩分析,频次提高.效率提升,还得保证团队中的小伙伴们都得有点大数据时代的基本数据能力.小编觉得这么好的经验可以分享给更多志同道合的朋友 ...
- 阿里云Quick BI——让人人都成为分析师
在3月29日深圳云栖大会的数据分析与可视化专场中,阿里云产品专家潘炎峰(陌停)对大数据智能分析产品 Quick BI 进行了深入的剖析.大会现场的精彩分享也赢得观众们的一直认可和热烈的反响. Quic ...
- Quick BI的SQL传参建模可以用在什么场景
Quick B的SQL传参建模功能提供基于SQL的数据加工处理能力,减轻了IT支撑人员的工作量.在即席查询SQL中,我们用物理字段显示别名来表示参数的占位符,配置完占位符后,就可以在查询控件中进行参数 ...
- Quick BI支持哪些数据源(配置操作篇)
Quick BI 潜心打造了核心技术底座(OLAP分析引擎),实现了SQL解析.SQL调度.SQL优化.查询加速等基础能力,支撑Quick BI的数据分析和查询加速.OLAP分析引擎包括数据源连接.数 ...
- Quick BI 的模型设计与生成SQL原理剖析
一.摘要 随着物联网的告诉发展,数据量呈现井喷式的增长,如何来分析和使用这些数据,使数据产生商业价值,已经变得越来越重要.值得高兴的是,当前越来越多的人已经意识到了用数据分析决定商业策略的重要性,也都 ...
- Quick BI助力云上大数据分析---深圳云栖大会
在3月29日深圳云栖大会的数据分析与可视化专场中,阿里云产品专家陌停对大数据智能分析产品 Quick BI 进行了深入的剖析.大会现场的精彩分享也赢得观众们的一直认可和热烈的反响. 大数据分析之路的挑 ...
- 当移动数据分析需求遇到Quick BI
我叫洞幺,是一名大型婚恋网站“我在这等你”的资深老员工,虽然在公司五六年,还在一线搬砖.“我在这等你”成立15年,目前积累注册用户高达2亿多,在我们网站成功牵手的用户达2千多万.目前我们的公司在CEO ...
随机推荐
- TX2 核心板 GPIO、IO扩展器、拨码开关、LED灯 使用总结
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- [leetcode 496. 下一个更大元素 I] 单调栈
单调栈的写法: import java.util.ArrayDeque; import java.util.Deque; import java.util.HashMap; import java.u ...
- hdfs disk balancer 磁盘均衡器
目录 1.背景 2.hdfs balancer和 hdfs disk balancer有何不同? 3.操作 3.1 生成计划 3.2 执行计划 3.3 查询计划 3.4 取消计划 4.和disk ba ...
- FPGA之PLD的简单设计
FPGA之PLD的简单设计 1.实验原理 PLD是可编程逻辑器件的简称,是FPGA的前身(FPGA是在PLD的基础上发展出来的).从PLD设计可以感受早期可编程逻辑器件的特点,了解FPGA在器件层的原 ...
- OREPA:阿里提出训练也很快的重参数策略,内存减半,速度加倍 | CVPR 2022
论文提出了在线重参数方法OREPA,在训练阶段就能将复杂的结构重参数为单卷积层,从而降低大量训练的耗时.为了实现这一目标,论文用线性缩放层代替了训练时的BN层,保持了优化方向的多样性和特征表达能力.从 ...
- 【已解决】linux centos7系统磁盘扩容
第一步要手动加硬盘(我的操作是在20G的基础上加了30G) [reliable@hadoop102 ~]$ su root密码: 查看当前磁盘挂载情况: [root@hadoop102 reliabl ...
- DevSecOps 中的漏洞管理(上)
DevSecOps意味着在DevOps交付管道把安全性包含进去.该模型尽可能早地将安全原则集成到软件开发生命周期的所有适用阶段中.下图展示了安全方面在DevOps后期阶段的集成,但DevSecOps安 ...
- Spring Bean 的一生
Spring Bean 的一生包括其从创建到消亡的整个过程: 实例创建 => 填充 => 初始化 => 使用 => 销毁. 这里需要注意的是,从 bean 实例的创建到可以使用 ...
- Python 条件和 if 语句
Python支持来自数学的通常逻辑条件: 等于:a == b 不等于:a != b 小于:a < b 小于或等于:a <= b 大于:a > b 大于或等于:a >= b 这些 ...
- 【Kotlin】类和对象
1 前言 Kotlin 是面向对象编程语言,与 Java 语言类似,都有类.对象.属性.构造函数.成员函数,都有封装.继承.多态三大特性,不同点如下. Java 有静态(static)代码块,Ko ...