技术解读:英特尔 x86 平台上,AI 能力是如何进行演进的?(附PPT)
简介:AI 生态系统是怎样的?其中又有哪些关键技术?
AI 计算力的指数增长意味着,为了解决越来越复杂的用例,即使是 1000 倍的计算性能增长也很容易被消耗。因此,需要通过软件生态系统的助力,才能达到更好的性能。我们相信,构建 AI 软件生态系统,是将人工智能和数据科学项目推向生产的关键。本文整理自龙蜥大讲堂技术直播第四期,由龙蜥社区AI SIG核心成员、英特尔 AI 软件开发⼯程师黄文欢分享——用技术和实例讲解英特尔 x86 平台 AI 能力演进的关键。

以下是本期龙蜥大讲堂技术直播回顾文:
人工智能的发展为社会各个领域带来了无限可能,但这些应用都需要很强的计算性能和优化来提供准确、及时的结果。人工智能模型复杂性的增长速度是飞速的,大约三年前,像 ELMo 这样的自然语言模型只有 9400 万个参数,而今年最大的模型达到了超过 1 万亿个参数。
一、英特尔 x86 平台 AI 能力演进
自 Skylake 以来,英特尔通过从 AVX256 升级到 AVX512,将 AVX 的能力提高了一倍,这极大地提高了深度学习训练和推理能力。一年后,在 Cascade Lake 中引入 DL Boost VNNI,大大提高 INT8 乘加吞吐量。自 Cooper Lake 之后,英特尔将BFloat16(BF16) 添加到 DL Boost 指令集中,以进一步提高深度学习训练和推理性能。硬件一直在向前发展,AMX 自 Sapphire Rapids 开始推出,将会进一步提高 VNNI 和 BF16 从 1 维-向量到 2 维-矩阵的能力。英特尔可扩展处理器通过英特尔
Deep Learning Boost (IntelDL Boost) 将嵌入式 AI 性能提升到一个新的水平。英特尔的 Deep Learning Boost ( DL Boost ) 是 x86-64 上指令集架构功能的名称,旨在提高深度学习任务(例如训练和推理)的性能。DL Boost 包含两组关键技术:
- AVX-512 VNNI:主要用于卷积神经网络的快速乘法累加。
- AVX-512 BF16:用于更快计算的低精度 BFloat16 浮点数。

图1. 英特尔x86平台AI能力演进
Intel DL Boost – VNNI
英特尔深度学习加速包括 AVX512 VNNI,VNNI 代表向量神经网络指令,是对标准英特尔指令集 AVX512 的扩展。AVX512 VNNI 旨在加速基于卷积神经网络的算法。AVX512 通过引入 4 个新指令加快内部卷积神经网络环路。AVX512 VNNI 扩展背后的主要动机是观察到许多紧密的循环需要两个 16 位值或两个 8 位值的重复乘法,并将结果累加到 32 位累加器。
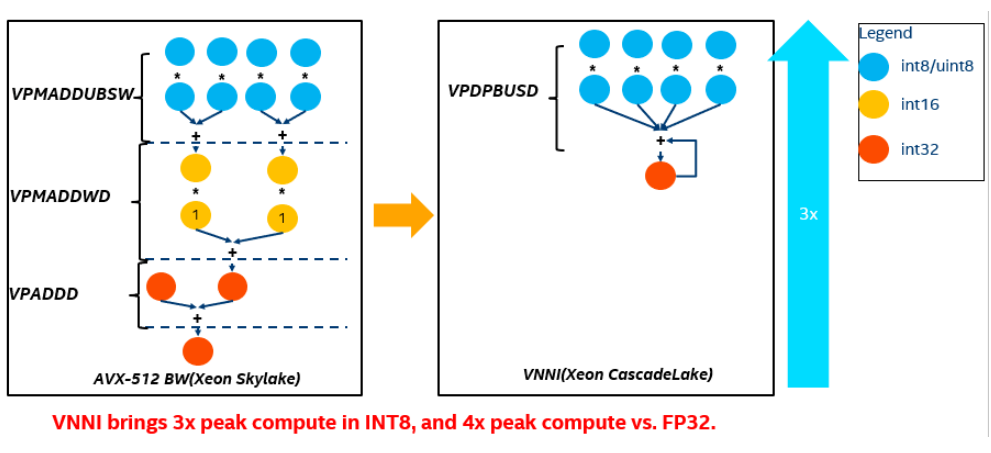
图2. 利用基础AVX 512 vs. 利用AVX512 VNNI 做向量乘加
深度学习的核心计算可以简化为乘加运算。在 VNNI 之前,我们需要做图 1 中这样的向量乘加,使用基础 AVX-512,对于 16 位,这可以使用两条指令实现 VPMADDWD用于将两个 16 位对相乘并将它们加在一起,然后将 VPADDD 添加累加值。利用基础 AVX512 需要 3 条指令,而 VNNI 只需要 1 个周期就可以完成。通过将三条指令融合为一条,可以最大化利用计算资源,提升 cache 利用率及避免潜在的带宽瓶颈。因此,在这个意义上,VNNI 通过与非 VNNI 比较,将为 INT8 带来 3x 峰值计算的提升。此外,由于在一个 AVX512 寄存器中,与 FP32 相比可以容纳 4 倍 INT8 数据,如果与 FP32 相比又可以带来 4x 峰值计算的提升。
Intel DL Boost – BFloat16
BFloat16(BF16) 主要思想是提供 16 位浮点格式,其动态范围与标准 IEEE-FP32 相同,但精度较 FP32 变低。相当于指数区和 FP32 保持了相同的 8 位,并将 FP32 分数字段的小数区缩减到到了 7 位。大多数情况下,用户在进行神经网络计算时,BF16 格式与 FP32 一样准确,但是以一半的位数完成任务。因此,与 32 位相比,采用 BF16 吞吐量可以翻倍,内存需求可以减半。此外,fp32 到 bf16 的转化,相对于 fp32 到 fp16 的转化更加简单。
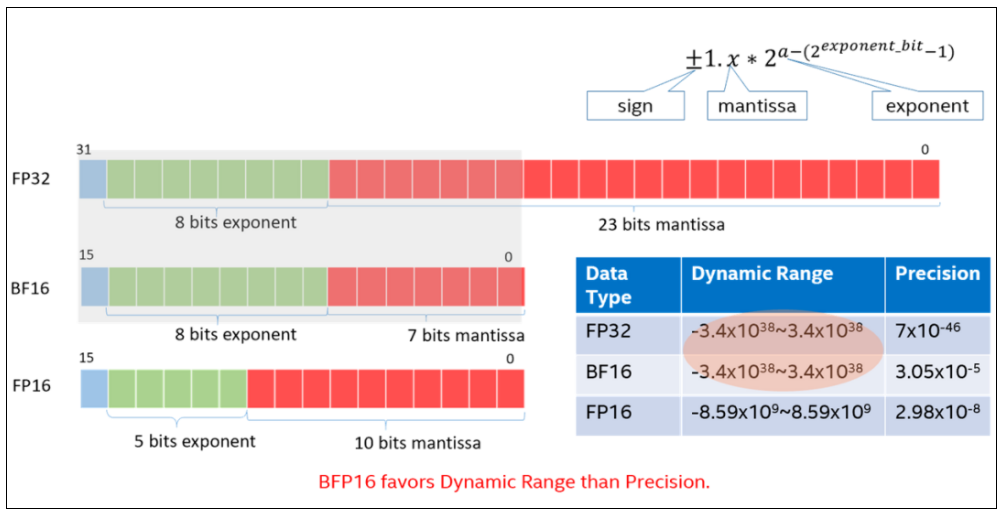
图3. BFloat16数据类型介绍
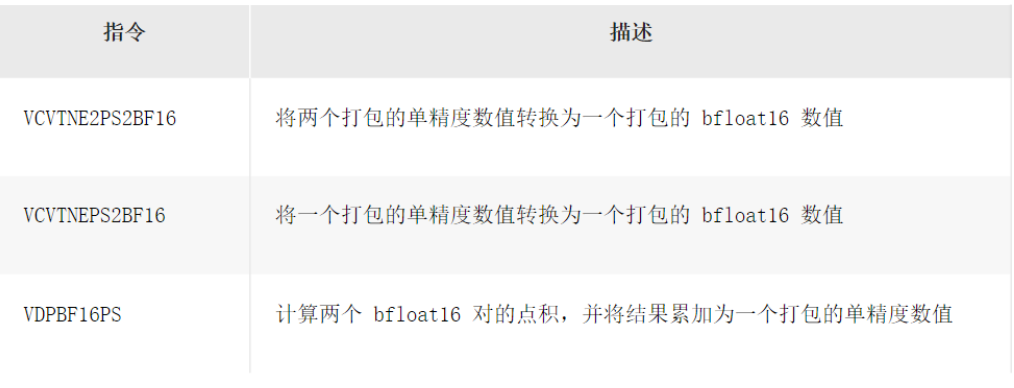
英特尔 深度学习加速技术包括以下 BFloat16 指令:
二、英特尔AI 软件开发及部署生态系统
随着 AI 应用在视觉、语音、推荐系统等方面不断增长和多样化,英特尔的目标是提供一套优越的 AI 开发和部署生态系统,使每个开发人员、数据科学家、研究人员和数据工程师尽可能无缝使用,以加快他们从边缘到云端的 AI 之旅。对于所有硬件和软件优化以及模型量化算法,我们需要了解它们以更好地利用,为了使每个用户都可以便捷使用这些优化,英特尔提供了一套自顶向下的全栈 AI 软件系统。对于不同需求的工程师,都可以在英特尔 AI 软件生态系统中找到适合他们的应用。对于想要开发自己的高性能应用程序或库的深度开发人员,可以直接调用相关的指令。对于想要摆脱框架开销的框架开发人员或 AI工程师,你可以直接使用 OneDNN。对于那些已经拥有 TensorFlow/PyTorch 等 AI 框架训练的模型的人来说,Intel 已经将大部分补丁上流到开源中,直接使用它们并享受性能,或者进一步使用英特尔对于这些框架的扩展优化。对于那些想要追求更多特定于推理的优化的人,可以使用 INC 工具库。
2.1 深度神经网络库 OneDNN
oneDNN 是一个开源的跨平台高性能库,包含用于深度学习应用程序的基本构建模块。基于英特尔平台,oneDNN 对深度神经网络进行 op 级以及指令集级的优化。
- 帮助开发人员创建高性能深度学习框架
- 相同的 API 为英特尔 cpu 和 gpu,使用最好的技术来完成这项工作
- 支持 Linux、Windows 和 macOS
该底层库围绕四个概念建立:
1.原语(Primitive):是一个封装了特定计算过程的函数对象,特定计算过程如前向卷积,LSTM 反向计算等。可以通过原语的属性来控制原语表达更复杂的融合操作,例如前向卷积和 ReLU 的融合。这里需要注意的是创建原语是重量级操作,最好的方式是一次创建、重复使用。或者可以通过缓存具有相同参数的原语来减少原语创建成本。
2.引擎(Engine):是计算设备的抽象,包括 CPU,特定 GPU 卡等。创建的大多数原语是在一个特定引擎上执行计算,引擎类似于异构计算的 host 和 device 概念的统一,是可执行计算的设备的抽象。
3.流(Stream):是绑定到特定引擎的执行上下文的封装。
4.内存对象 (memory): 封装了分配给特定引擎的内存句柄、 tensor 的维度、数据类型、数据排布等信息。内存对象在执行期间被传递给原语进行处理。可以通过内存描述符 (memory::desc) 创建内存对象。
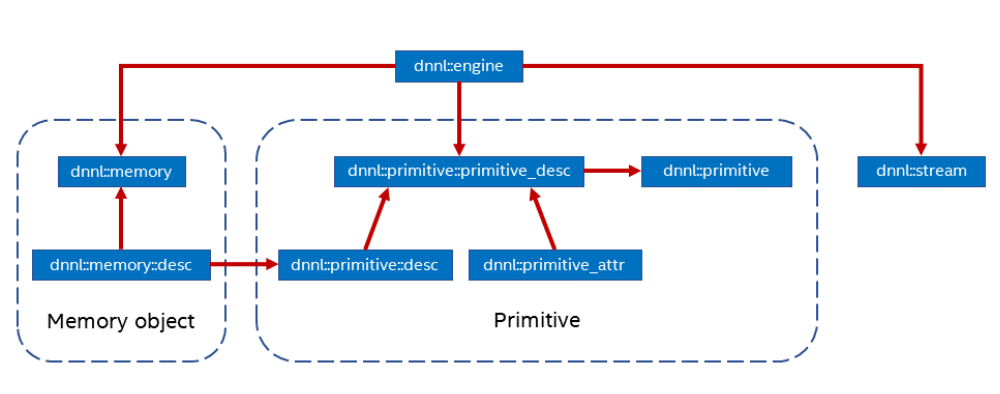
图4. OneDNN 关系图
优势:
- 支持关键数据类型:float32、float16、bfloat16 和 int8
- 实现了丰富的操作:convolution, matrix multiplication, pooling, batch normalization, activation functions, recurrent neural network (RNN) cells, and long short-term memory (LSTM) cells
- 支持自动检测硬件指令,提高神经网络在指定硬件,特别是英特尔 CPU 和 GPU 上的执行速度。
2.2 优化深度学习框架:TensorFlow, PyTorch
深度学习框架通过高级编程接口为数据科学家、AI开发人员和研究人员提供模块,以构建、训练、验证和部署模型。英特尔通过 oneDNN 库进行的软件优化为几个流行的深度学习框架带来了数量级的性能提升,而且大多数优化已经上传到默认框架分发版中。但是,对于 TensorFlow 和 PyTorch,我们还维护单独的 Intel 扩展作为尚未上传的优化的缓冲区。
2.2.1 Intel Optimization for TensorFlow*
英特尔对于 TensorFlow 的优化主要包括以下三个方面:
1)在算子优化部分,将默认的(Eigen)内核替换为(使用oneDNN)高度优化的内核,OneDNN优化了一系列TensorFlow操作。OneDNN 库是开源的,在构建 TensorFlow时自动下载。
2)在图优化方面,图优化主要是希望在不影响模型的数值特性的基础上,通过图变换达到简化计算、资源开销,提升性能,所以是性能优化时的首选方法之一。Intel Optimization for TensorFlow*中所做的图优化包括算子融合及布局传播。
- 算子融合
算子融合是一个常见的性能优化方法,在融合之前,每个算子计算前后都需要把数据从内存读到缓存,再从缓存写回到内存。而融合之后,可以避免算子之间内存读写从而提高性能。
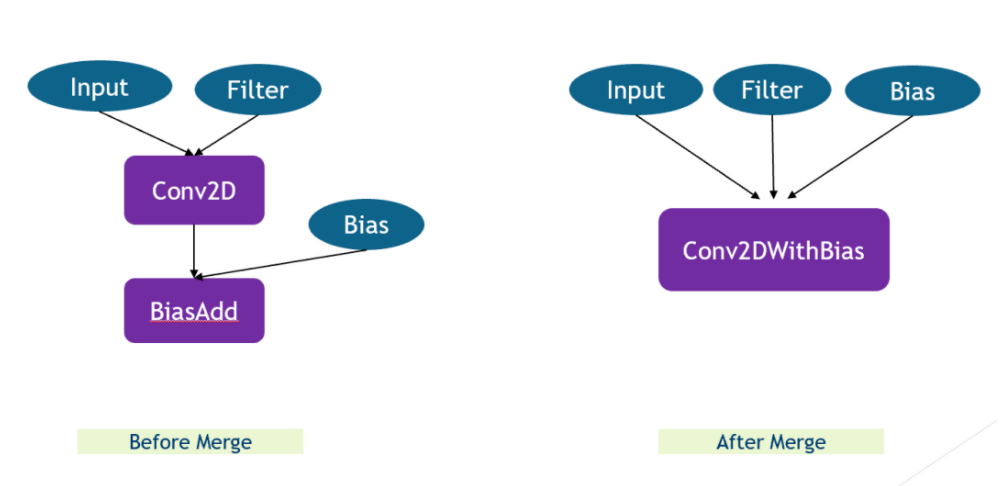
图5. 算子融合
所以在做算子融合的时候本质上便是把多个 Tensor 整合到一个 Node 下。虽然只是简单的算子融合,但是在计算过程中可以提高速度。
- 布局传播
在布局传播方面,数据布局是会很大程度影响性能的,因此,我们需要做到:
- 顺序访问
- 尽可能在最内层的循环中进行迭代,提高向量利用率
- 尽可能的重用数据,例如卷积层中的权重
通常,对于 CPU 上的某些张量操作,原生 TensorFlow 数据格式并不是最有效的数据布局。对于 TensorFlow 中的 tensor, 所有 OneDNN 中的算子使用都是高度优化的数据布局。在这种情况下,我们插入一个从 TensorFlow 原生格式到内部格式的数据布局转换操作,在 CPU 上执行操作,并将操作输出转换回 TensorFlow 原生格式。需要注意的是我们应该避免冗余的转化开销。而这些转换会带来性能开销,因此带来的挑战在于如何避免不必要的转换。所以,我们应该采用布局传播方式,布局传播就是用于识别出相邻的互逆 reorder,并消除它们,从而减少了无效的操作。也就是最右边的这张图中的结构。

图6. 布局传播
在布局传播方面,Intel Optimization for TensorFlow*中所做的优化为
- 查找子图,这个子图中所有算子都有OneDNN支持
- 在这样的子图的边界上,引入数据布局转换
3)在系统级优化方面,包括负载均衡与内存分配两部分。对于负载均衡,我们知道不正确的设定线程模型参数会引发性能问题。因此,可以参阅TensorFLow里的相关说明文档,正确的为模型设置参数。对于内存分配,TensorFlow中的神经网络算子会分配大量的内存。但 TensoeFlow 中默认的 CPU 分配器不能很好地处理这种情况: 频繁alloc/dealloc 会带来频繁的mmap/munmap。在Intel Optimization for TensorFlow*中实现了 Pool allocator 来解决这个问题。
2.2.2 IntelOptimization for PyTorch*
我们已经将大部分优化上传到 社区版本的 PyTorch 中,同时还保留了一个单独的英特尔 PyTorch 扩展包(Intel Extension for PyTorch* (IPEX))作为目前尚未upstream的这些优化的一个缓冲区。
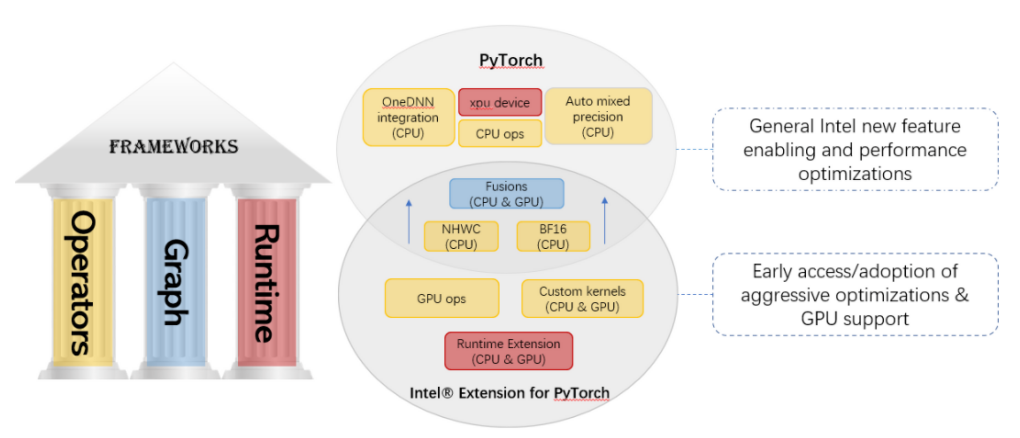
图7. Intel Extension for PyTorch*
IPEX 在英特尔硬件上对比社区版本的 pytorch 具有额外的性能提升。大多数优化最终将包含在社区 PyTorch 版本中,扩展包的目的是在英特尔硬件上为 PyTorch 提供最新的特性和优化,包括 AVX512 VNNI) 和 IntelAMX。IPEX可以作为Python程序中的模块进行加载,也可以作为 C++ 程序的 C++ 库链接。用户可以通过导入 intel_extension_for_pytorch 在脚本中动态启用这些优化。优化扩展包 IPEX 中所包含的优化有:
- 算子优化:为提高性能,IPEX优化了算子并实现了多个定制的算子。(通过ATen注册机制,一些ATen操作符会被在Intel Extension for PyTorch*的优化版本所取代。)还针对几种流行的拓扑实现了一些定制算子。如Mask R-CNN中的 ROIAlign and NMS.
- 图优化:IPEX支持常用的算子融合,如Conv2D+ReLU, Linear+ReLU等。算子融合带来的好处以透明的方式传递给用户。IPEX支持FP32 和 BF16 融合模式,以及INT8融合模式
- Runtime 优化: 为用户提供了多个 PyTorch 前端 API,以便对线程运行时进行更细粒度的控制。它提供
- 通过 Python 前端模块 MultiStreamModule 进行多流推理
- 从 Python 和 C++ 前端生成异步任务
- 从 Python 和 C++ 前端为 OpenMP 线程配置核心绑定
2.3 优化工具 INC
INC全称为Intel Neural Compressor,是一个运行在Intel CPU和GPU上的开源Python 库,它为流行的网络压缩技术 (如量化、剪枝、知识蒸馏) 提供跨多个深度学习框架的统一接口。

图8. INC基础架构图
可以看到,这个工具支持自动的精度驱动的调优策略,帮助用户快速找到最佳量化模型。 这些调优策略包括贝叶斯/MSE/TPE…对于量化部分,模型量化主要是通过降低模型中tensor和weights精度的手段,从而减少计算需求和数据存储与传输需求,来达到加速的目的。主要方法分两派:一是训练后量化(Post-training Quantization),二是量化感知训练(Quantization-Aware Training)。INC工具支持
- 训练后静态量化(Post-training Static Quatization)
- 训练后动态量化(Post training dynamic Quatization)
- 量化感知训练(Quantization-aware training)
对于剪枝部分,深度学习网络模型从卷积层到全连接层存在着大量冗余的参数,大量神经元激活值趋近于 0,将这些神经元去除后可以表现出同样的模型表达能力,这种情况被称为过参数化,而对应的技术则被称为模型剪枝。INC 中采用多种剪枝算法,如非结构化剪枝(Magnitude-based 基于幅度剪枝), 结构化剪枝(Gradient sensitivity梯度敏感剪枝),生成具有预定义稀疏性目标的剪枝模型。
同时 INC 也支持知识蒸馏。模型蒸馏采用的是迁移学习的方法,通过采用预先训练好的复杂模型(Teacher Model)的输出作为监督信号去训练另外一个简单的网络(Student Model),最后把 Student Model 用于推理。
以在 TensorFlow 上的使用举例,用户模型可以是 saved model、 ckpt、 pb 各种形式,通过 INC 工具运行后,得到一个优化后的模型,依然为之前的用户模型格式,可以在 Tensorflow 上使用,相较于原始模型来说获得更好的性能效果。
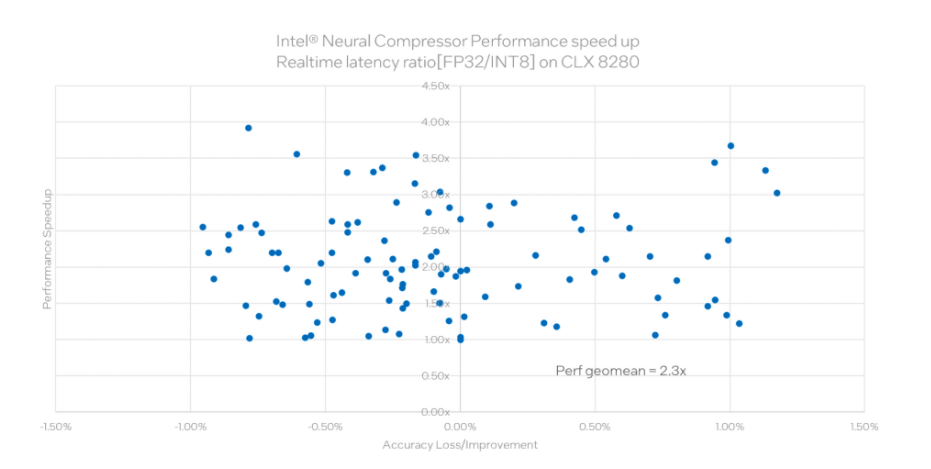
图9. INC性能表现
这是在 150+ 个业内常用的模型,使用 INC 工作后的评估结果。这些模型涉及各个领域,包括图像分类中常用的ResNet、GoogLeNet、Inception,目标检测中常用的Mobilenet、Yolo、Faster RCNN,推荐中常用的 Wide&deep、DLRM,自然语言处理中常用的 bert 等。这张图展现的是 int8 相对于fp32 的性能结果比较。横轴为相应的精度改变,纵轴为 Int8 与 fp32 相比在实时 latency 的提升。可以看到几何平均提升达到 2.3 倍。
三、性能优化方法及案例分享
3.1 性能优化方法
在推理的性能优化方面, 工作可归成四类:算子优化、图优化、模型压缩和部署优化。
算子优化: 算子优化中微架构优化的主要焦点是如何充分利用好微架构的内置加速器的能力去最大化算子的性能。OneDNN底层库就可以帮大家很好的做这部分的优化。
图优化:主要通过子图变换和算子融合等方式来达到减少计算量或者其他系统开销(如访存开销),从而达到性能优化的目的。图优化主要是希望在不影响模型的数值特性的基础上,通过图变换达到简化计算、资源开销,提升性能,所以是性能优化时的首选方法之一。英特尔对于深度学习框架tensroflow, pytorch的优化包含这些图优化。
模型压缩:如果还需要额外的性能增益,这时候需要考虑模型压缩方案。模型压缩(Compression)主要手段有:模型量化、剪枝和模型蒸馏。工程师们也可以通过刚刚介绍的INC压缩工具来便捷的使用到这些压缩方案。
部署优化:主要通过调整模型在部署时的资源分配和调度的参数来进一步优化性能。
3.2 案例分享:Bfloat16 优化在第三代英特尔至强可扩展处理器上提升阿里云 BERT 模型性能
BERT 模型是一个自然语言处理中的一个常用模型。阿里巴巴阿里云团队与 Intel 工程师密切合作进行 BERT 推理性能优化。接下去介绍我们是怎样一步步开展这些优化的。首先,我们在原始数据类型,即fp32的情况下,我们首先使用“模型转换”将多层多操作的复杂 BERT 模型替换为单个 BERT 操作。为了在 TensorFlow上实现高效的 BERT op,我们需要创建一个优化的Kernel,从而产生一个新的自定义 BERT 算子。这是一个具有 算子 融合和优化的实现。
在 TensorFlow 中,“前端”负责图描述,“后端”负责算子的执行。因此,我们可以将模型从原始 BERT 模型转换为前端带有 BERT op 的新模型,并将新的 BERT 内核实现注册到后端。因此,我们不需要重新安装 TensorFlow 框架。我们只需要加载实现 BERT 代码的动态库即可,并通过 oneAPI 深度神经网络库 (oneDNN)等高性能工具,来提升性能。
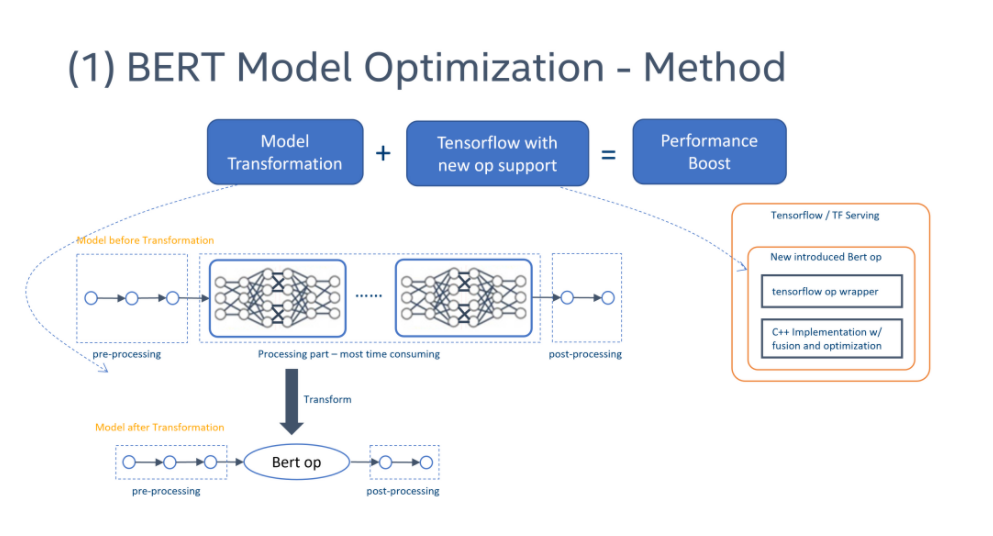
图10. BERT 模型优化方案
对于优化实现,我们分析BERT图进行层融合和张量融合。这张图显示了 12 层 BERT 中的一层细节。在这个案例中,又可以进行横向融合和纵向融合。关于横向融合,我们可以看到三个张量,即查询 query、键 key 和值 value,都需要进行 MatMul 和 BiasAdd 操作。我们可以把这些操作融合为一个操作,即 QKV MatMul 和 BiasAdd。关于纵向融合,可以参照下图。
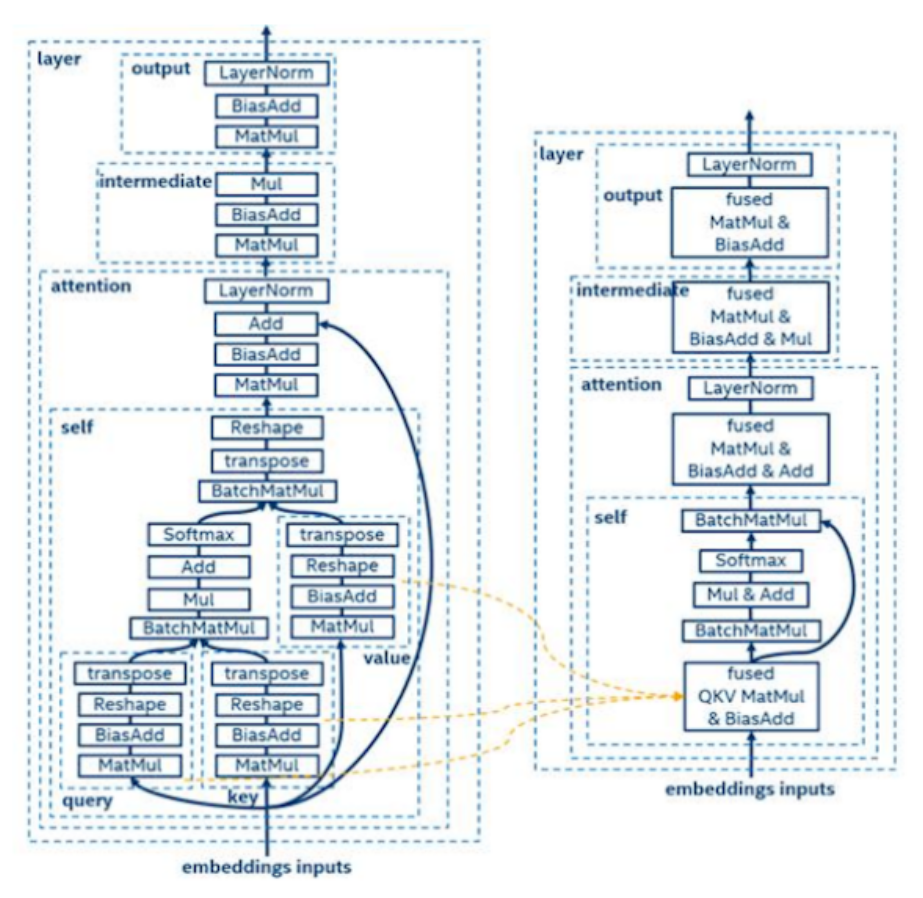
图11. 新BERT模型实现
接下去,我们分析优化的 FP32 BERT 模型时,我们注意到推理过程中超过 80% 的运行时间花费在 MatMul 操作中。如何优化 MatMul 运算以减少延迟已成为最紧迫的挑战之一。众所周知,减少内存访问、优化缓存、提高并行度可以优化程序性能。随着第 3 代英特尔至强可扩展处理器的引入,使用最开始介绍的英特尔 DL Boost 的 bfloat16 指令,与 FP32 的点积相比,在理论上能将 BF16 的点积加速 2 倍。
英特尔 深度学习加速技术包括以下 BFloat16 指令:

为了减少内存访问,我们将 FP32 权重转换为 BF16 权重,像下图中右边的图结构所示。我们将 FP32 权重转换为 BF16 权重并将 BF16 权重缓存在 BF16 MatMul op 中以供重用,并在每次执行时并行的将 FP32 输入转换为 BF16 输入。
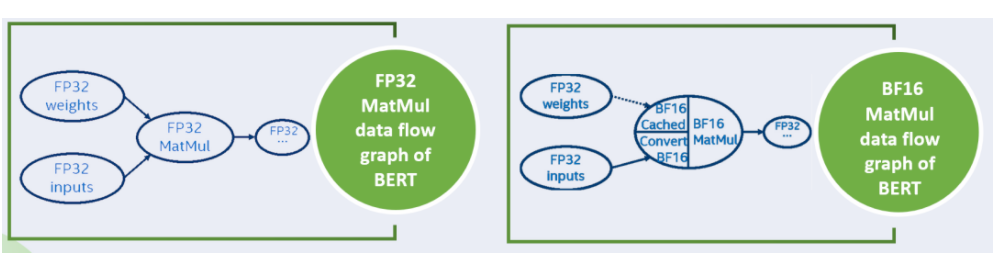
图12. BFloat16 优化方案
在这样的转化下,我们可以使用 bfloat16 的点积计算 MatMul op,可以看到输入为 BF16 类型, 输出为 fp32 类型。这些实现是利用了 oneDNN的 支持。因此,我们只需要创建一个新的 BF16 MatMul op 来替换优化的 FP32 解决方案(Baseline)MatMul op,然后我们就可以实现BF16与 FP32 优化相比带来的性能提升。
对于 BF16 优化方案,通过简单的运算替换来提高性能,可以保持尽可能高的精度。对于 BiasAdd 操作,我们仍然保持 FP32 操作,以减少精度损失。
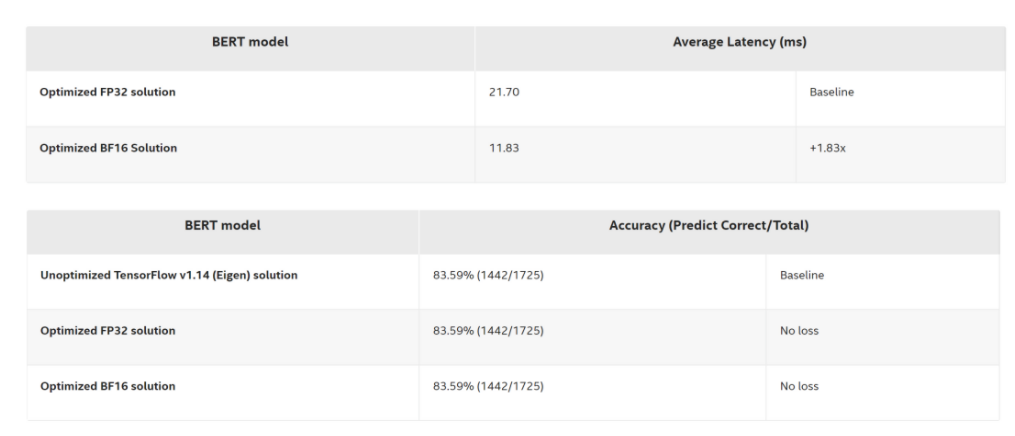
最后是一个优化后方案的性能和进度评估结果,为了比较优化后的 FP32 Bert 和优化后的 BF16 Bert 的性能差异,我们将batch size 设为1,token size 设为128,这也符合实际的线上业务。输入是 MRPC 数据集。以延时为 21.70 毫秒的 FP32 解决方案为基准,可以看到优化的 BF16 解决方案与基线相比,延迟为 11.83 毫秒,端到端的性能提升达到了 1.83 倍,并且没有 Accuracy 的损失。

敲重点啦
本次直播视频回放已上线至龙蜥社区官网(首页-社区-视频),直播 PPT 获取方式:关注龙蜥社区公众号,后台回复【龙蜥课件】或【龙蜥视频回放】即可。
本文为阿里云原创内容,未经允许不得转载。
技术解读:英特尔 x86 平台上,AI 能力是如何进行演进的?(附PPT)的更多相关文章
- 面向英特尔® x86 平台的 Unity* 优化指南: 第 1 部分
原文地址 目录 工具 Unity 分析器 GPA 系统分析器 GPA 帧分析器 如要充分发挥 x86 平台的作用,您可以在项目中进行多种性能优化,以最大限度地提升性能. 在本指南中,我们将展示 Uni ...
- 运行在TQ2440开发板上以及X86平台上的linux内核编译
一.运行在TQ2440开发板上的linux内核编译 1.获取源码并解压 直接使用天嵌移植好的“linux-2.6.30.4_20100531.tar.bz2”源码包. 解压(天嵌默认解压到/opt/E ...
- x86平台上的Windows页表映射机制
首先,在x86架构的处理器上,一个正常页面大小为4KB,非PAE模式下,CR3持有页目录页面的物理地址,PDE和PTE格式相同大小为4字节.此时每个页表页面包含1024个PTE,可以映射1024个页面 ...
- 英特尔与 Facebook 合作采用第三代英特尔® 至强® 可扩展处理器和支持 BFloat16 加速的英特尔® 深度学习加速技术,提高 PyTorch 性能
英特尔与 Facebook 曾联手合作,在多卡训练工作负载中验证了 BFloat16 (BF16) 的优势:在不修改训练超参数的情况下,BFloat16 与单精度 32 位浮点数 (FP32) 得到了 ...
- 英特尔® 至强® 平台集成 AI 加速构建数据中心智慧网络
英特尔 至强 平台集成 AI 加速构建数据中心智慧网络 SNA 通过 AI 方法来实时感知网络状态,基于网络数据分析来实现自动化部署和风险预测,从而让企业网络能更智能.更高效地为最终用户业务提供支撑. ...
- Intel 英特尔
英特尔 英特尔 基本资料 公司名称:英特尔(集成电路公司) 外文名称:Intel Corporation(Integrated Electronics Corporation) 总部地 ...
- 英特尔发布全新英特尔® INDE 2015工具套件
2014年10月15日,英特尔发布了全新的英特尔® Integrated Native Developer Experience 2015工具套件(简称英特尔® INDE).该产品提供了一系列最佳工具 ...
- 英特尔® 硬件加速执行管理器安装指南 — Microsoft Windows*
介绍 本文将指导您安装英特尔® 硬件加速执行管理器(英特尔® HAXM),这是一款可以使用英特尔® 虚拟化技术(VT)加快 Android* 开发速度的硬件辅助虚拟化引擎(管理程序). 前提条件 英特 ...
- 将 Android* Bullet 物理引擎移植至英特尔® 架构
简单介绍 因为眼下的移动设备上可以使用更高的计算性能.移动游戏如今也可以提供震撼的画面和真实物理(realistic physics). 枪战游戏中的手雷爆炸效果和赛车模拟器中的汽车漂移效果等便是由物 ...
- [转帖]抢先AMD一步,英特尔推出新处理器,支持LPDDR5!
抢先AMD一步,英特尔推出新处理器,支持LPDDR5! http://www.eetop.cn/cpu_soc/6946240.html 2019.10 intel的最新技术发展. 近日,知名硬件爆料 ...
随机推荐
- stream使用汇总
整理了下java使用stream处理list的几个便捷的方法 准备数据 List<KnowledgeInfoTable> knowledgeInfoTables = knowledgeIn ...
- Java反序列化学习
前言 早知前路多艰辛,仙尊悔而我不悔.Java反序列化,免费一位,开始品鉴,学了这么久web,还没深入研究Java安全,人生一大罪过.诸君,请看. 序列化与反序列化 简单demo: import ja ...
- 常用命令rsyncscp-1
常用命令:rsync/scp scp scp命令文件传输 scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的.可能 ...
- FreeRTOS教程7 事件组
1.准备材料 正点原子stm32f407探索者开发板V2.4 STM32CubeMX软件(Version 6.10.0) Keil µVision5 IDE(MDK-Arm) 野火DAP仿真器 XCO ...
- module 'numpy' has no attribute 'bool'
module 'numpy' has no attribute 'bool' 问题: Traceback (most recent call last): File "/home/test. ...
- Linux电脑如何下载QGIS?
本文介绍在Linux操作系统Ubuntu版本中,通过命令行的方式,配置QGIS软件的方法. 在Ubuntu等Linux系统中,可以对空间信息加以可视化的遥感.GIS软件很少,比如ArcGIS下 ...
- 初学STM32 CAN通信(一)
# 初学STM32 CAN通信(一) 1. CAN协议简介 CAN是控制器局域网络(Controller Area Network)的简称, 是国际上应用最广泛的现场总线之一 ,近年来,它具有的高 ...
- 面试题,关于int类型转byte类型结果溢出
1 package com.atguigu.chapter03 2 /* 3 byte:-128~127 4 128 : Int类型,占4个字节,32位 5 计算机中的整型数据都以补码的形式存储,正数 ...
- 数据库知识 DDL/DML/DCL
DDL DDL的概述 DDL(Data Definition Language 数据定义语言)用于操作对象和对象的属性,这种对象包括数据库本身,以及数据库对象,像:表.视图等等,DDL对这些对象和属性 ...
- 正则表达式 (?<= 与 (?= 的区别
(?=pattern) 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串.这是一个非获取匹配, 也就是说,该匹配不需要获取供以后使用.例如,"Windows(?=95|98 ...