[转帖]TLB缓存是个神马鬼,如何查看TLB miss?
https://zhuanlan.zhihu.com/p/79607142
介绍TLB之前,我们先来回顾一个操作系统里的基本概念,虚拟内存。
虚拟内存
在用户的视角里,每个进程都有自己独立的地址空间,A进程的4GB和B进程4GB是完全独立不相关的,他们看到的都是操作系统虚拟出来的地址空间。但是呢,虚拟地址最终还是要落在实际内存的物理地址上进行操作的。操作系统就会通过页表的机制来实现进程的虚拟地址到物理地址的翻译工作。其中每一页的大小都是固定的。这一段我不想介绍的太过于详细,对这个概念不熟悉的同学回去翻一下操作系统的教材。
页表管理有两个关键点,分别是页面大小和页表级数
- 1.页面大小
在Linux下,我们通过如下命令可以查看到当前操作系统的页大小
# getconf PAGE_SIZE
4096可以看到当前我的Linux机器的页表是4KB的大小。
- 2.页表级数
- 页表级数越少,虚拟地址到物理地址的映射会很快,但是需要管理的页表项会很多,能支持的地址空间也有限。
- 相反页表级数越多,需要的存储的页表数据就会越少,而且能支持到比较大的地址空间,但是虚拟地址到物理地址的映射就会越慢。
32位系统的虚拟内存实现:二级页表
为了帮助大家回忆这段知识,我举个例子。如果想支持32位的操作系统下的4GB进程虚拟地址空间,假设页表大小为4K,则共有2的20次方页面。如果采用速度最快的1级页表,对应则需要2的20次方个页表项。一个页表项假如4字节,那么一个进程就需要(1048576*4=)4M的内存来存页表项。
如果是采用2级页表,如图1,则创建进程时只需要有一个页目录就可以了,占用(1024*4)=4KB的内存。剩下的二级页表项只有用到的时候才会再去申请。
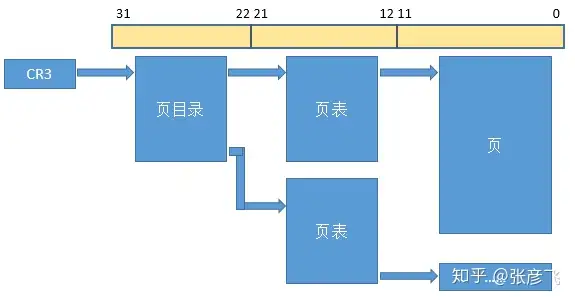
图1 二级页表
64位系统的虚拟内存实现:四级页表
现在的操作系统需要支持的可是48位地址空间(理论上可以支持64位,但其实现在只支持到了48位,也足够用了),而且要支持成百上千的进程,如果不采用分级页表的方式,则创建进程时就需要为其维护一个2的36次方个页表项(64位Linux目前只使用了地址中的48位的,在这里面,最后12位都是页内地址,只有前36位才是用来寻找页表的), 2的36次方*4Byte=32GB,这个更不能忍了。 也必须和32位系统一样,用分级页表的方法降低内存使用,但级数要更多一点。
Linux在v2.6.11以后,最终采用的方案是4级页表,分别是:
- PGD:page Global directory(47-39), 页全局目录
- PUD:Page Upper Directory(38-30),页上级目录
- PMD:page middle directory(29-21),页中间目录
- PTE:page table entry(20-12),页表项
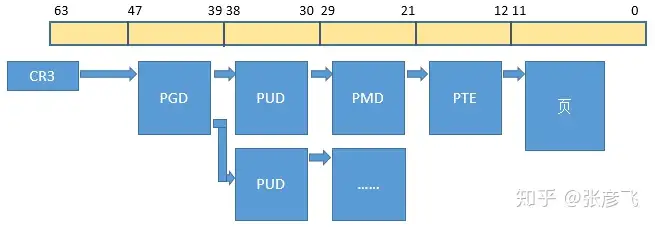
图2 四级页表
这样,一个64位的虚拟空间,初始创建的时候只需要维护一个2的9次方大小的一个页全局目录就够了,现在的页表数据结构被扩展到了8byte。这个页全局目录仅仅需要(2的9次方*8=)4K,剩下的中间页目录、页表项只需要在使用的时候再分配就好了。Linux就是通过这种方式支持起(2的48次方=)256T的进程地址空间的。
页表带来的问题
上面终于费劲扒了半天Linux虚拟内存的实现,我终于可以开始说我想说的重点了。
虽然创建一个支持256T的地址空间的进程在初始的时候只需要4K的页全局目录,但是,这也带来了额外的问题,页表是存在内存里的。那就是一次内存IO光是虚拟地址到物理地址的转换就要去内存查4次页表,再算上真正的内存访问,最坏情况下需要5次内存IO才能获取一个内存数据!!
TLB应运而生
和CPU的L1、L2、L3的缓存思想一致,既然进行地址转换需要的内存IO次数多,且耗时。那么干脆就在CPU里把页表尽可能地cache起来不就行了么,所以就有了TLB(Translation Lookaside Buffer),专门用于改进虚拟地址到物理地址转换速度的缓存。其访问速度非常快,和寄存器相当,比L1访问还快。
我本来想实际看一下TLB的信息,但翻遍了Linux的各种命令,也没有找到像sysfs这么方便查看L1、L2、L3大小的方法。仅仅提供下图供大家参考吧! (谁要是找到了查看TLB的命令,别忘了分享给飞哥啊,谢谢!)
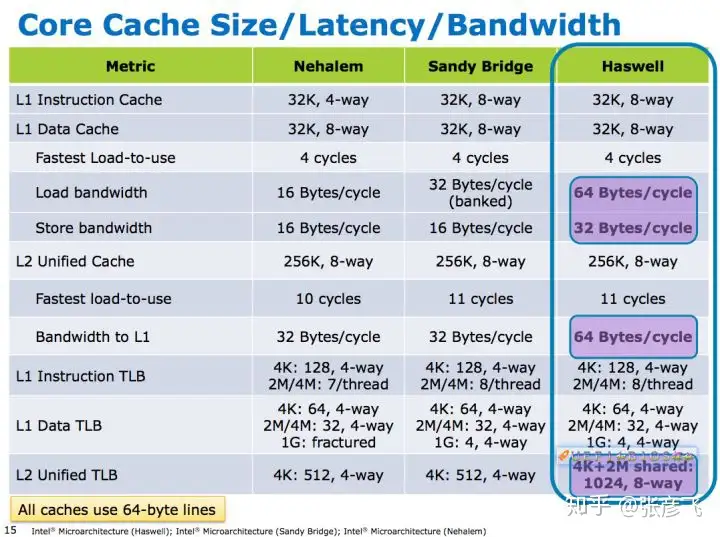
图3 CPU的TLB大小
有了TLB之后,CPU访问某个虚拟内存地址的过程如下
- 1.CPU产生一个虚拟地址
- 2.MMU从TLB中获取页表,翻译成物理地址
- 3.MMU把物理地址发送给L1/L2/L3/内存
- 4.L1/L2/L3/内存将地址对应数据返回给CPU
由于第2步是类似于寄存器的访问速度,所以如果TLB能命中,则虚拟地址到物理地址的时间开销几乎可以忽略。如果想了解TLB更详细的工作机制,请参考《深入理解计算机系统-第9章虚拟内存》
工具
既然TLB缓存命中很重要,那么有什么工具能够查看你的系统里的命中率呢? 还真有
# perf stat -e dTLB-loads,dTLB-load-misses,iTLB-loads,iTLB-load-misses -p $PID
Performance counter stats for process id '21047':
627,809 dTLB-loads
8,566 dTLB-load-misses # 1.36% of all dTLB cache hits
2,001,294 iTLB-loads
3,826 iTLB-load-misses # 0.19% of all iTLB cache hits扩展
因为TLB并不是很大,只有4k,而且现在逻辑核又造成会有两个进程来共享。所以可能会有cache miss的情况出现。而且一旦TLB miss造成的后果可比物理地址cache miss后果要严重一些,最多可能需要进行5次内存IO才行。建议你先用上面的perf工具查看一下你的程序的TLB的miss情况,如果确实不命中率很高,那么Linux允许你使用大内存页,很多大牛包括PHP7作者鸟哥也这样建议。这样将会大大减少页表项的数量,所以自然也会降低TLB cache miss率。所要承担的代价就是会造成一定程度的内存浪费。在Linux里,大内存页默认是不开启的。
关注知乎专栏《开发内功修炼》或搜索微信公众号“kfngxl”,收获更多知识!
参考文献
[转帖]TLB缓存是个神马鬼,如何查看TLB miss?的更多相关文章
- [转帖]Tensor是神马?为什么还会Flow?
Tensor是神马?为什么还会Flow? 互联网爱好者 百家号17-05-2310:03 大数据文摘作品,转载要求见文末 编译 | 邵胖胖,江凡,笪洁琼,Aileen 也许你已经下载了TensorFl ...
- SQLSERVER 里经常看到的CACHE STORES是神马东东?
SQLSERVER 里经常看到的CACHE STORES是神马东东? 当我们在SSMS里执行下面的SQL语句清空SQLSERVER的缓存的时候,我们会在SQL ERRORLOG里看到一些信息 DBCC ...
- 给你的网站添加谷歌AMP、百度MIP、神马MIP链接自动提交功能
我们在做网站的时候,经常会听到别人说SEO优化,网站优化等等.但是我们经常听的云里雾里的,但是经过我们运营一段时间之后,我们慢慢的就会熟悉了,知道什么是SEO.SEO中文译名为搜索引擎优化,既然是叫搜 ...
- 神马玩意,EntityFramework Core 1.1又更新了?走,赶紧去围观
前言 哦,不搞SQL了么,当然会继续,周末会继续更新,估计写完还得几十篇,但是我会坚持把SQL更新完毕,绝不会烂尾,后续很长一段时间没更新的话,不要想我,那说明我是学习新的技能去了,那就是学习英语,本 ...
- javascript 函数初探 (一)--- 神马是函数
神马是函数? 所谓函数,本质上是一种代码的分组形式.我们可以通过这种形式赋予某组代码一个名字,以便与之后的调用.下面,我们来示范以下函数的声明: function sum(a, b){ var c = ...
- [C++中级进阶]001_C++0x里的完美转发到底是神马?
[C++中级进阶]001_C++0x里的完美转发到底是神马? 转载至:http://www.cnblogs.com/alephsoul-alephsoul/archive/2013/01/10/285 ...
- 记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?)
记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?) 前几天帮客户优化一个数据库,那个数据库的大小是6G 这麽小的数据库按道理不会有太大的性能问题的, ...
- X-UA-Compatible是神马
X-UA-Compatible是神马 X-UA-Compatible是IE8的一个专有<meta>属性,它告诉IE8采用何种IE版本去渲染网页,在html的<head>标签中使 ...
- 神马小说:使用opensearch打造高性能搜索服务
神马小说--- 使用opensearch打造高性能搜索服务 [使用背景] 神马小说是最早使用opensearch的用户,和opensearch一起成长.目前神马小说每天2亿搜索pv,1000w 用户. ...
- [置顶] 【Git入门之一】Git是神马?
1.Git是神马? 一个开源的分布式版本控制系统,可以有效的高速的控制管理各种从小到大的项目版本.他的作者就是大名鼎鼎的Linux系统创始人Linus. 2.分布式又是神马? 先看看集中式.简单说来, ...
随机推荐
- DVWA Insecure CAPTCHA(不安全的验证码)全等级
Insecure CAPTCHA(不安全的验证码) 目录: Insecure CAPTCHA(不安全的验证码) 1. Low 2.Medium 3. High 4.Impossible 加载验证码需要 ...
- Map的特性(有序和无序)讨论
目录 什么是红黑树? 在 Java 中,基础java.util.Map 接口本身并不保证元素的顺序.具体的实现类 HashMap 和 TreeMap 的行为(无序.有序)有所不同: HashMap 类 ...
- 文心一言 VS 讯飞星火 VS chatgpt (50)-- 算法导论6.2 2题
二.参考过程 MAX-HEAPIFY,写出能够维护相应最小堆的 MIN-HEAPIFY(A,i)的伪代码,并比较 MIN-HEAPIFY 与 MAX-HEAPIFY 的运行时间. 文心一言: MIN- ...
- ChatGPT Prompts整理总结
最近一直在学习ChatGPT Prompt的编写技巧,做了一些验证和整理,分享给大家 Act as a Linux Terminal 英文Prompt I want you to act as a l ...
- 避坑指南:关于SPDK问题分析过程
[前言] 这是一次充满曲折与反转的问题分析,资料很少,代码很多,经验很少,概念很多,当内核态,用户态,DIF,LBA,大页内存,SGL,RDMA,NVME和SSD一起迎面而来的时候,问题是单点的意外, ...
- 后CNN探索,如何用RNN进行图像分类
摘要:RNN可以用于描述时间上连续状态的输出,有记忆功能,能处理时间序列的能力,让我惊叹. 本文分享自华为云社区<用RNN进行图像分类--CNN之后的探索>,作者: Yin-Manny. ...
- 五一高铁票难抢?用RPA机器人试试!
随着信息数字化的高速发展,RPA在各行业中得到广泛应用,热度大增.这匹"技术黑马"已然成为构建业务流程自动化的重要引擎之一,助力企业组织向"智能自动化转型. 什么是RPA ...
- 带你读顶会论文丨基于溯源图的APT攻击检测
摘要:本次分享主要是作者对APT攻击部分顶会论文阅读的阶段性总结,将从四个方面开展. 本文分享自华为云社区<[论文阅读] (10)基于溯源图的APT攻击检测安全顶会总结>,作者:eastm ...
- 带你了解Node.js包管理工具:包与NPM
摘要:包与NPM Node组织了自身的核心模块,也使得第三方文件模块可以有序的编写和使用. 本文分享自华为云社区<NodeJs深入浅出之旅:包与NPM>,作者:空城机. 包与NPM Nod ...
- 物联网企业该如何与华为云合作,这份FAQ值得一看
摘要:关于华为云DevRun智联生活行业加速器,梳理出伙伴和企业最关心的问题,并逐一解答. 自华为云DevRun智联生活行业加速器发布以来,一直在为产业链上下游的企业提供技术.生态建设.商业变现等资源 ...