从运维域看 Serverless 真的就是万能银弹吗?
作者说
在开始本篇内容前我想与各位开发者达成几个共识。
第一个共识,软件工程没有银弹, Serverless 也不是银弹,它并不是解决所有问题的万能公式。
第二个共识,Serverless 能够解决的是运维域的问题,它是解决特定领域问题的一个技术,并不是无限延伸的,与低代码没有关系。
第三个共识是复杂度守恒定律-泰斯勒定律(Tesler’s law)。典型例子就是苹果,苹果的产品很容易上手操作。但本质上它整体的复杂度是守恒的,它其实是把复杂的事情留给了系统开发工程师和软件开发的工程师,让用户可以顺滑体验。同理 Serverless 也是如此,把部署 or 运维应用、网站的烦复转交给了云服务商,但整体的复杂度是不变的。
第四个共识是邓宁-克鲁格效应(The Dunning-Kruger Effect),大家在认知学习过程中,都会出现这样的发展曲线:从刚开始一无所知,到对新知识的幻想,再到失望的低谷,缓慢爬坡。我们学习任何一个新事物都会经历这样一个曲线过程。Gartner采用邓宁-克鲁格曲线,来解释新技术的发展周期。
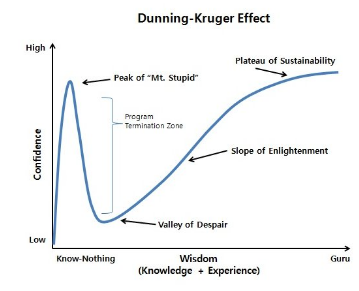
个人认知曲线
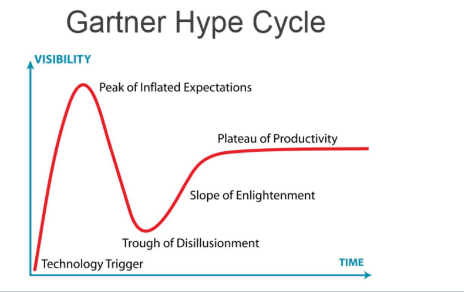
Gartern 技术发展曲线
作为开发工程师经常会有这种体感,新的技术层出不穷学的很累。Serverless 刚推出来时也一样,大家对这个技术充满了无限的想象,当想象到了一个巅峰以后,会慢慢认识到想象与现实的差距,切身去体会在产品中使用时就会掉到技术的低谷,然后再缓慢的爬坡。
Serverless 正当时
本文将会通过三个部分,为各位介绍 Serverless:
第一个部分是“复杂化 for 云开发商”
第二个部分是“简化 for 开发者”
第三个部分,会介绍一些我自己和我们团队使用 Serverless 时的最佳场景。
1、复杂化 for 云开发商
(1) Serverless 架构
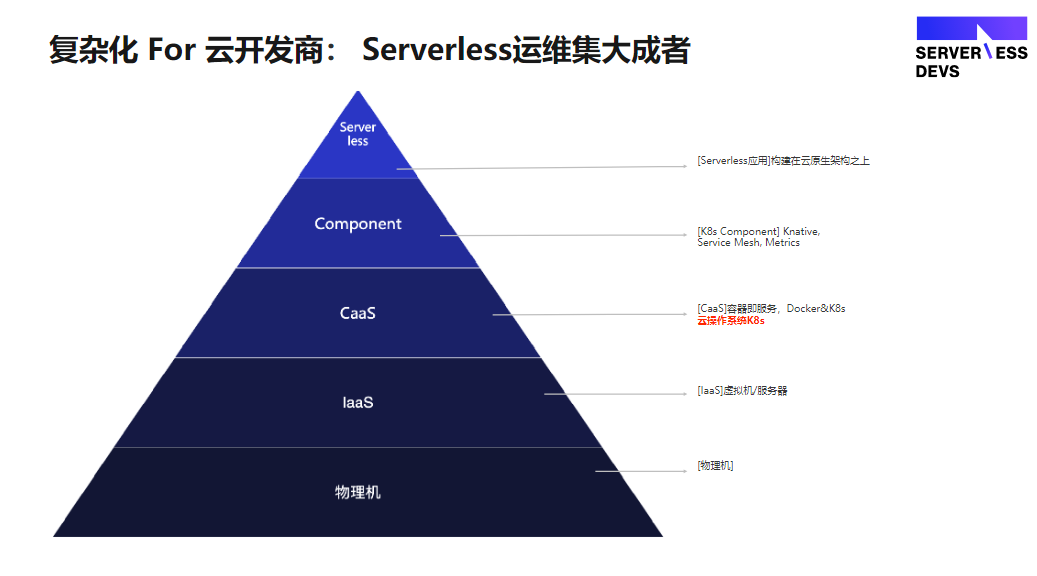
Serverless 是一个集大成者,它的整发展历史是站在巨人的肩膀上的。现在很多云服务商去跑一个函数,底层都是这样架构。首先 Serverless 的运行底层会有一个 CaaS 层。它是一个Serverless化的容器服务,大部分的应用服务都会跑在这一层上面,容器调度现在开源的比较好的解决方案就是 K8s,用 K8s 来调度容器,底层 laaS 就是虚拟机,最底层则是物理机。
CaaS 的实现的方式有很多,Serverless 应用底层必须有CaaS服务的支撑。除了Docker以外,vm 也可以是 CaaS ;例如 Node.js 的 vm 也可以做 CaaS ,webassembly 也可以做 CaaS 等等。另外在做整体架构设计的时候,还需要一个 Component 层去解决网络东西流量和南北流量的问题,例如service Mesh和ingress的方案,总体来说 Serverless 背后的架构设计基本都是如此。
(2) 云开发商:不可变基础设施
CNCF对云开发商来说会有vendor-unlock的危机,当所有云服务作为不可变基础建设,复杂度下沉到K8s层,架构变得通用。因为CNCF的架构整套框架是根据配置文件去迁移的,可以部署在阿里云、也可以腾讯云、亚马逊的云上,甚至自己搭建的私有云。
另外对云服务商来说,他们以前积累的传统的优势(虚拟机 laas 层的运维优势和 Caas 层的平台级的优势)就会渐渐失去。所以如果是 vendor-unlock 云服务商之间就会白热化地打价格战,看谁能提供更好更便宜的服务。
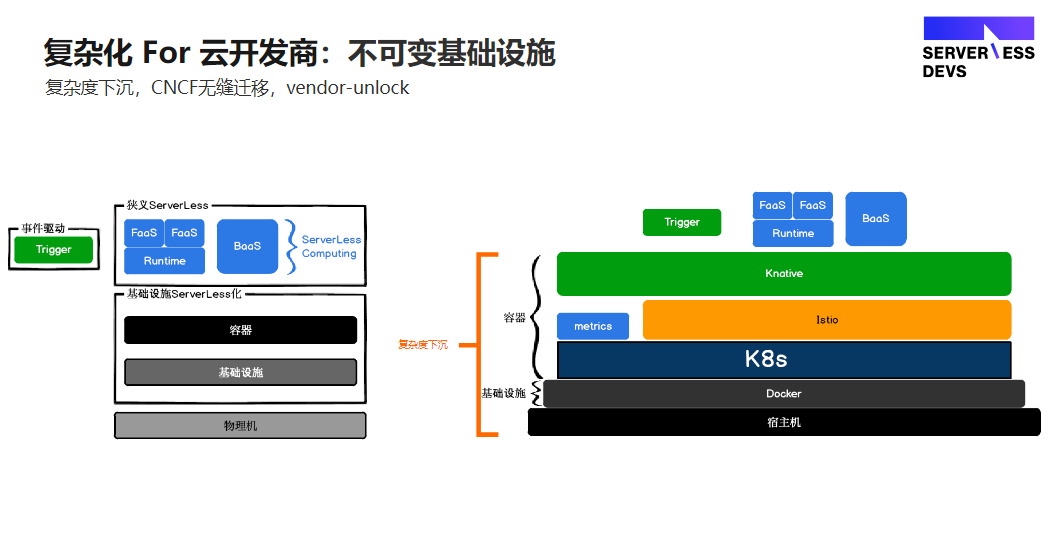
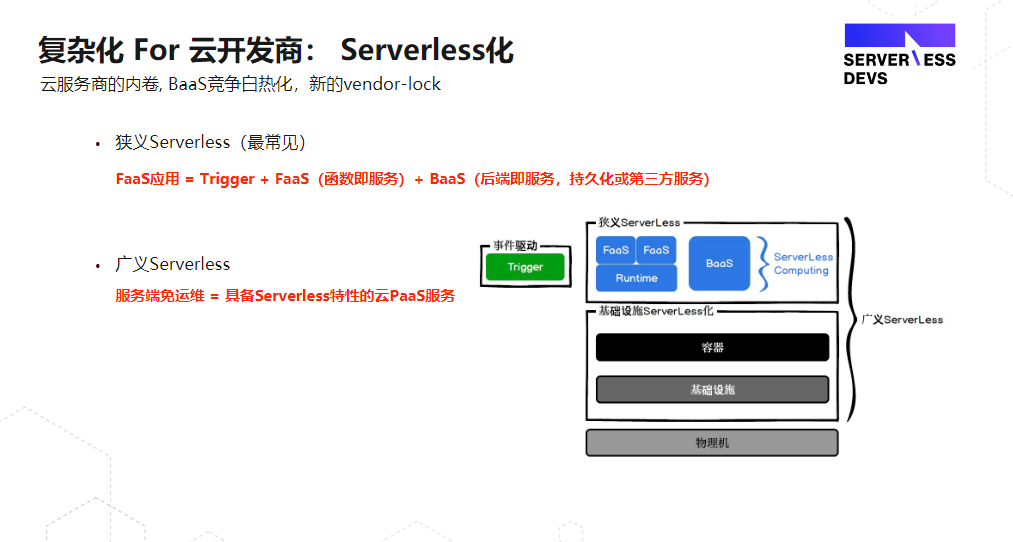
广义的 Serverless 是整个云服务商运维体系的 Serverless 化。如传统提供一个MySQL 或 Redis,必须让开发者意识到这是跑在服务器上的,需要提供出来个 ip ,但 Serverless 化(Baas 化)后,开发者不需要再去关心这个服务到底是运行在哪里,只需要申明我需要一个DB,应用就可以自动去链接并消费DB。
狭义的 Serverless 不仅仅是 Severless Computing,还指一个 FaaS 的应用,是由 trigger(也可以归并为BaaS) + FaaS+ BaaS 的架构组成的。现在云开发商在 Serverless FaaS 的这一层的核心竞争力是不断推出新的 BaaS 能力,而 BaaS 主要是跟 FaaS 配套去使用的。
上面讲到的云服务商的不可变基础建设,如下图所示,开发者在最上面这层去部署应用,根本不用关心底层的这些基础建设。现在云服务商提供的 Baas SDK实际上已经包含在你的这个 FaaS 的runtime里面,开发者只需要把它当成一个函数接口去直接调用,不用关心数据库部署在什么地方、要不要保持长链接等等。
2、简化 for 开发者
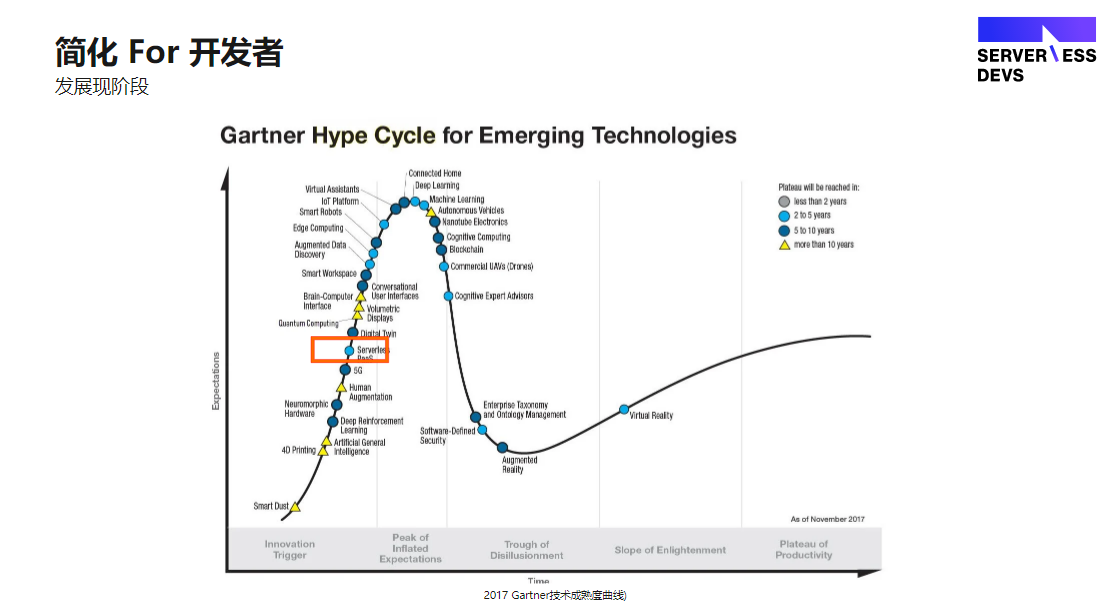
此图是 Gartner 在 2017 年推出的新兴技术发展状态,当时Gartner觉得 Serverless 还是一个比较新的概念,大家对它的认知还处于爬坡阶段;但实际上到今天2021年,Serverless 已经进入了平缓爬升期了,大家对Serverless 可以解决运维域的问题,有哪些边界的限制等等这些问题已经有了清晰的认知。
为什么最近这几年没有什么特别新的东西推出了?原因在于 Serverless 这层没有特别新的概念诞生,大家更多是在做FaaS应用基础建设。现有的各种Web应用场景场景是否可以Serverless化,比如近期已经支持了的,数据库 BaaS 化, websocket 支持 FaaS,另外还有很多Web应用场景都是通过诸位的努力慢慢爬坡实现,使其能够接近理想中的 Serverless 。
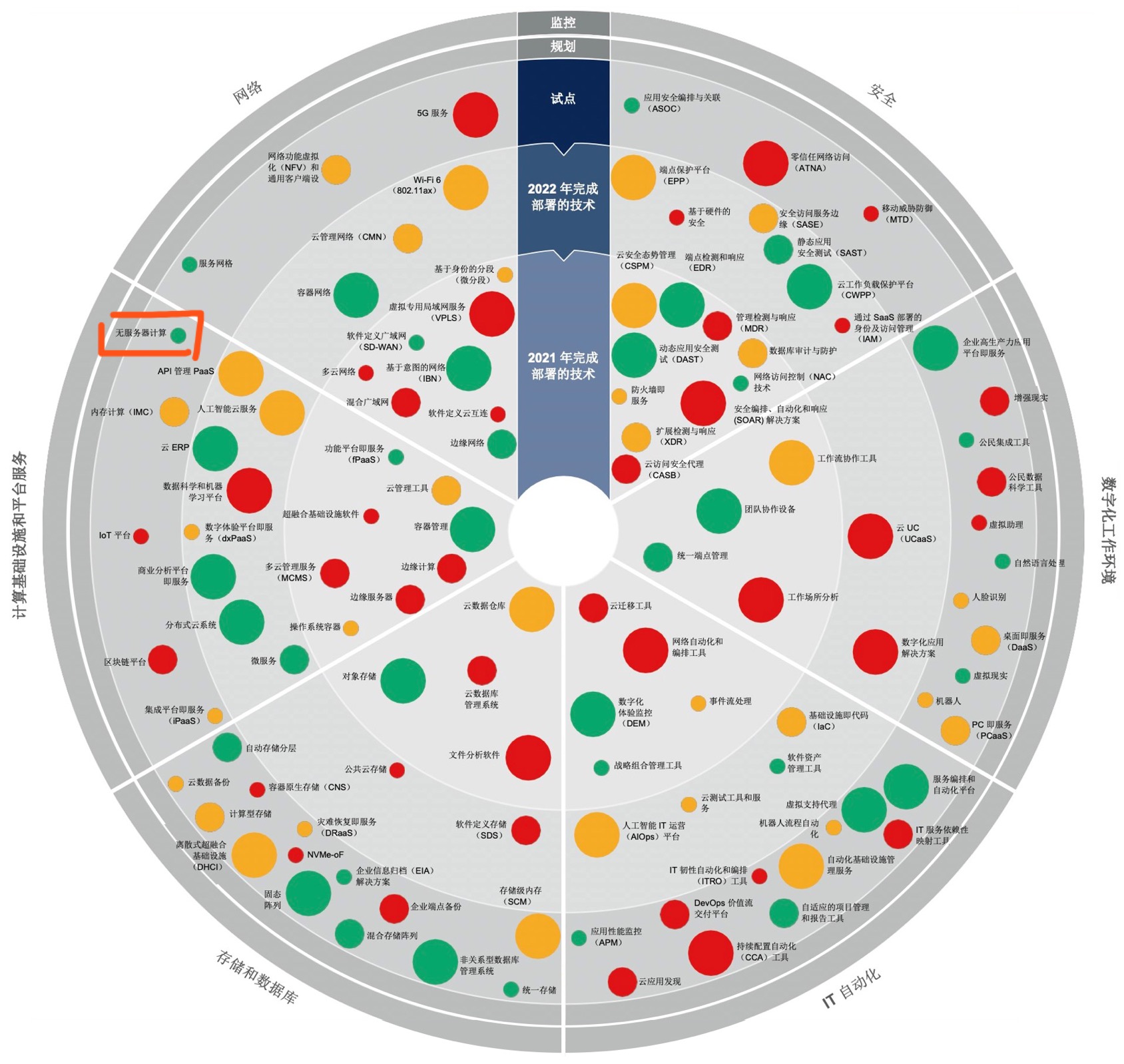
2021 年 Gartner 技术采纳建议图
图中画框的位置就是 Serverless,绿色代表已经成熟,可以看出,现在的 Serverless 已经是一个比较成熟的技术了,支持大部分Web应用的场景了,所以各位开发者大家可以放心大胆地去尝试Serverless。
(1) 运维领域的 Serverless
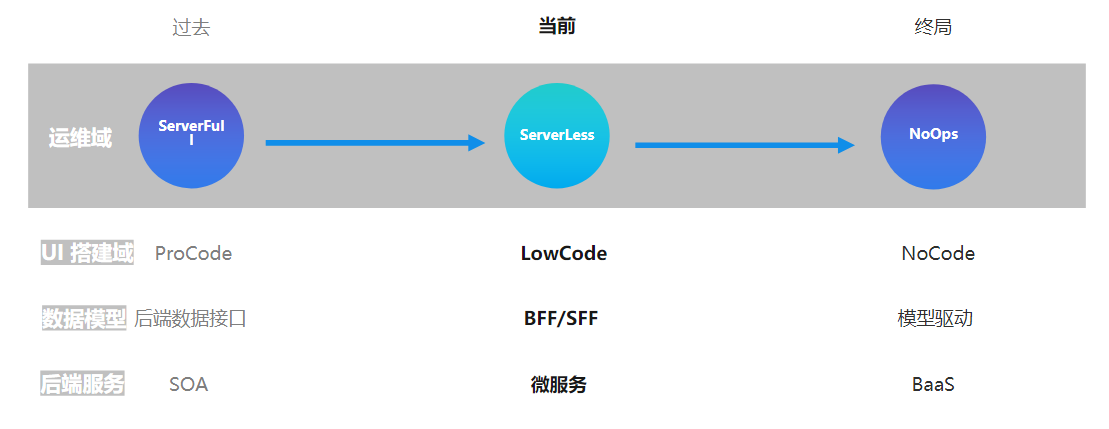
国内很多人把 Serverless 翻译成无服务器或者叫无服务,这都不太准确,Severless的反义词是 Serverful,Severful 的意思是需要特别关注服务器,Serverless 的本质是为了降低心智负担,不需要十分关心服务器,只专注部署函数就行,至于它怎么运行、底层有多少容器、底层有多少服务器来支撑它,开发者都不需要关心。
传统的模式的前后端开发模式是由:后端提供数据服务,以前叫 SOA 是面向服务的编程,现在比较流行的是领域驱动微服务,前端消费组装数据。后端数据接口传统的方式是提供 HTTP API,到现在的流行的 BFF (Backend For Frontend) 胶水层函数编排。配合微服务提供全量数据,是目前业界比较流行的做法。那么未来的趋势将会全部 BaaS 化,理想的状态是前后端一体化模型驱动,不再需要再写接口。
结合 Serverless 做技术变革
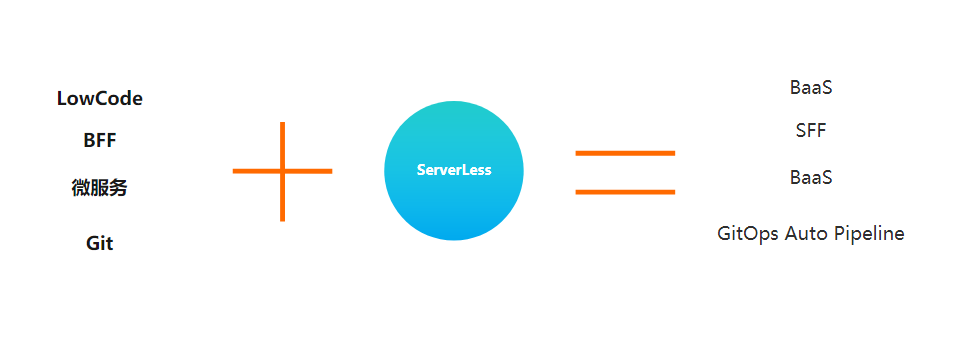
Serverless + = ...
当下 Serverless 所处的阶段的优势是跟其他领域的技术结合, Serverless 结合其他领域来引爆许多技术变革。例如,传统的微服务 + Serverless 结合起来后,可以做成 BaaS 化微服务。以前提供一个微服务,是需要开发者去关心这个微服务部署在哪里,但是加上 Serverless 后,便不用管部署在哪里,只需要关心怎么去调用即可。LowCode 加上 Serverless 可以让搭建出来的页面快速部署并上线;之前的接口函数编排如传统的 BFF,在未来都可以 Serverless 化,变成SFF(Serverless for frontend),很适合做前后端一体化方案。
(2)开发角色的转变:前后端一体化
Serverless 出现后,未来还会出现前后端一体化的局面。现在已经出现逻辑编排可视化的工具,例如狼叔的 iMove ,目前已经可以做到后端接口的可视化编排,前端工程师去做一个后端的接口编排变得非常简单。由此可以预见,前端工程师未来的职责可以往后端去延伸。
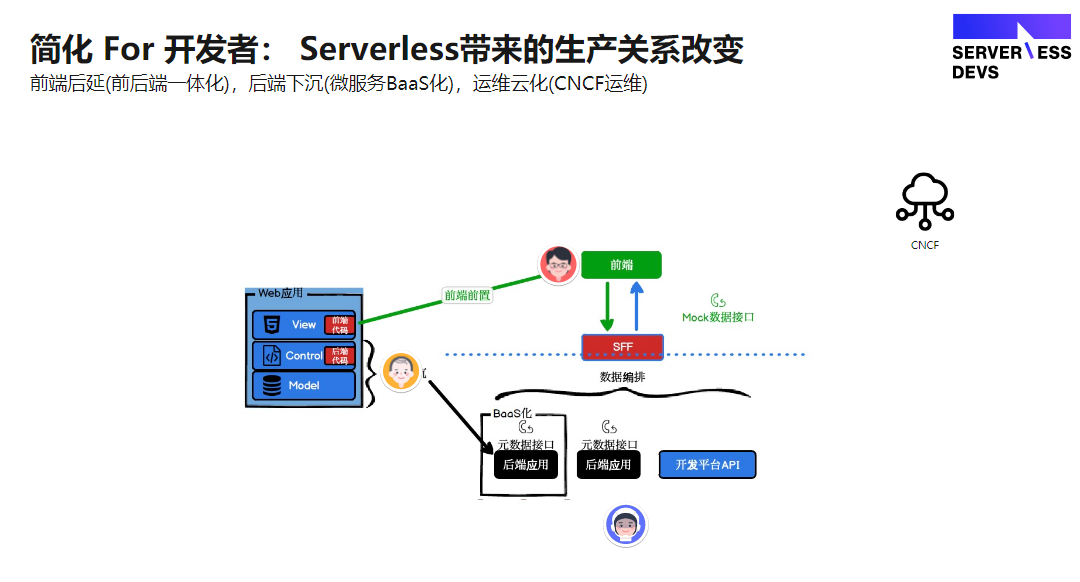
而原来的后端工程师会从传统的应用部署逐渐转化去做 BaaS 化服务级别的开发,而未来运维工程师也会更偏向于向云端迁移。这个就是 Serverless 对研发生产链路带来的一系列变革。
3、Serverless 的最佳场景实践
对于 Serverless 使用最近场景的判定,最便捷的方式就是去看云开发商支持哪些 Trigger 事件触发。
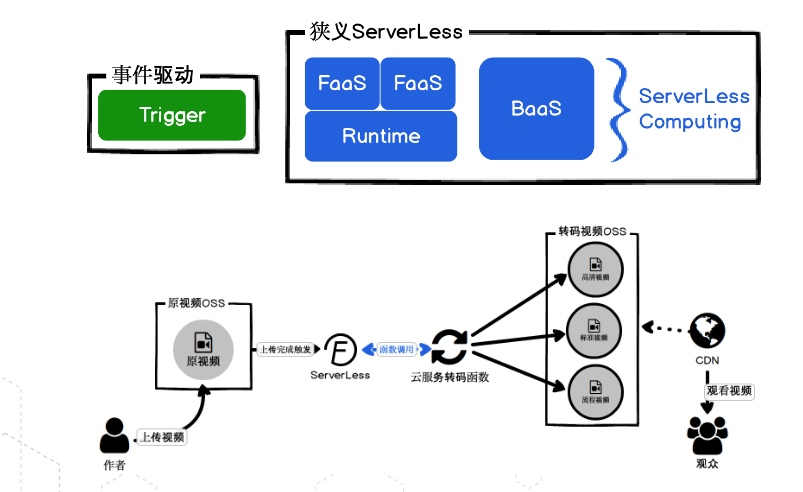
所以目前这个阶段,各个云开发商都在不停的增加新的 Trigger。如图所示,开发人员在写 FaaS 时,是将HTTP request 包装成了 Trigger,可以把FaaS函数想象成在封闭的一个包裹里面,要如何唤醒这个包裹,怎么打开这个包裹呢?其实就是通过 Trigger 来唤醒。
另外Serverless的现阶段,开发语言的重要性没那么高了,语言只是去实现功能所需要的工具。CNCF 推出来以后 FaaS 就已经是与语言无关的了,那么其实到底是Node.js,PHP,Python 亦或是其他主流语言的代码FaaS都可以,你甚至可以自建一个镜像自定义语言和执行环境。因此在Serverless后,多语言的优势我们都可以借用,比如用Python去处理AI数据,Node.js去处理高并发网络I/O等等。
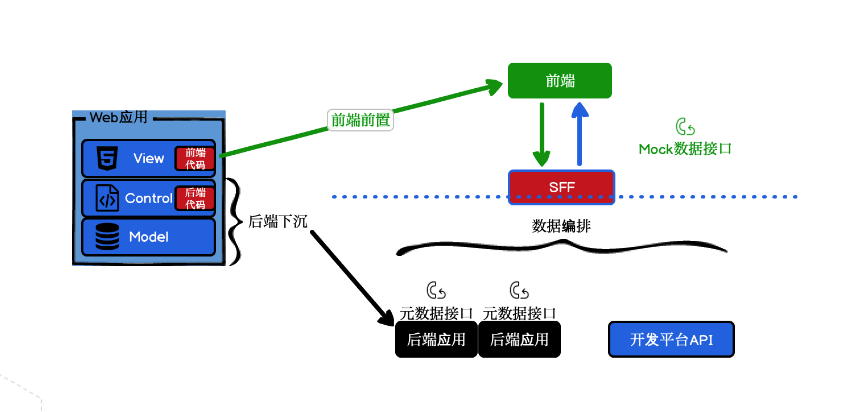
(1)SFF 数据编排
最佳实践就是 BFF + Serverless,这在阿里集团内部是十分常见的。由于阿里内部的大多场景后端都是 Java 工程师,前端团队需要跟工程师去对接,而后端工程师提供的就是HSF微服务,可以把它理解为一堆 RPC 接口。以前就是部署一个 Node.js 应用去调接口,拿到数据后对这些数据进行是清洗、处理,放到前端页面去渲染。但是采用 Serverless 部署BFF的Node.js应用后,基本不需要考虑跟进流量扩缩容、节省成本等问题。
(2)GitOps 模型
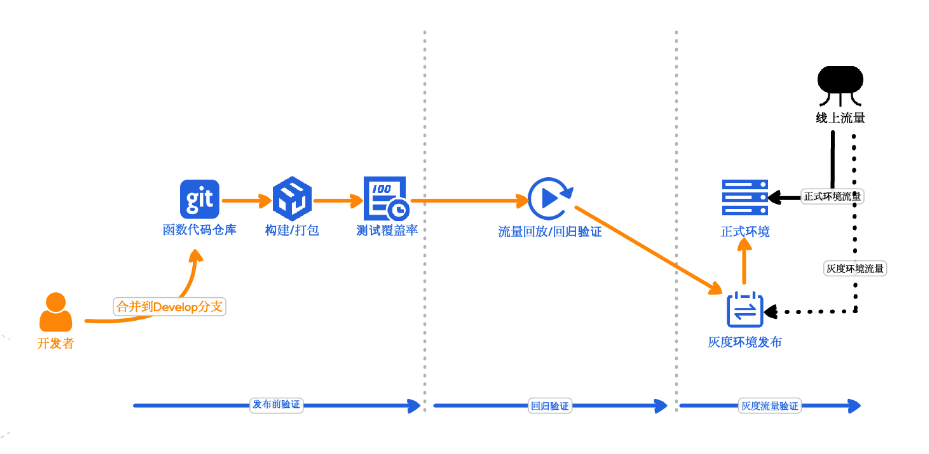
GitOps 对于小企业来说,是非常适用的场景,相当于可以自建一套自动发布上线的管道,不再需要像以前一样,修改一个版本便要测试一遍,目前整个方案已经十分成熟了。Git 本身支持大量的 hook 函数,所以打造这样一个流程也是非常容易的。需要关注的是要结合云开发商的能力,比如阿里云发布流程便十分自动化,在云下平台发布上线后可以支持线上的流量录制、回放。
(3)小而美的技术团队
最后一点是打造小而美的团队。在我的认知中,技术架构有个强大制约就是:组织架构会决定我们的技术架构。
就像前后端分离,大多是因为组织架构定义了:前端有前端的领导,后端有后端的领导,所以就会产生前端由前端的开发,后端由后端的开发,需要中间去联调基于API沟通。那我们如果要想打造一个小而美的团队怎样打破这个隔阂呢?
Serverless 一个比较适合的场景就是,通过前端的服务编排 SFF 将解决掉中间API沟通的问题,后端去提供全量的服务即可。这种变革会迫使后端去做微服务化,甚至后端研发采用Serverless 去做 BaaS 化,这是反向的导推过程。如果我们的前端团队掌握了 Serverless, 有三个优势:前端的数据编排便不再需要再找后端工程师了;GitOps 解决部署运维,可以降低前端心智负担;前端同学能够专心抽象业务模型。
作者简介:
蒲松洋,花名秦粤。极客时间《Serverless 入门课》作者。Serverless 和 Node.js 布道者,目前负责阿里巴巴前端委员会标准化小组,低代码小组--中后台搭建,Node.js 应用微服务架构。在微服务、Serverless 以及中台项目中有着丰富经验。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。
从运维域看 Serverless 真的就是万能银弹吗?的更多相关文章
- linux 运维一些常见的简单安全设置 运维必看
1. 修改ssh服务的默认端口,这个是十分有必要的,因为密码爆破一直存在.ssh服务的默认端口是22,一般的恶意用户也往往扫描或尝试连接22端口.所以第一步就是修改这个默认端口打开/etc/ssh/s ...
- nginx 编译参数详解(运维不得不看)
nginx参数: --prefix= 指向安装目录 --sbin-path 指向(执行)程序文件(nginx) --conf-path= 指向配置文件(nginx.conf) --error-log- ...
- 常用Oracle进程资源查询语句(运维必看)
(一)根据程序名称查找相关信息select A.process,B.spid,A.sid,A.serial#,A.sql_address,A.username,A.program,A.status,A ...
- nginx 编译参数详解(运维必看--转)
nginx参数: –prefix= 指向安装目录 –sbin-path 指向(执行)程序文件(nginx) –conf-path= 指向配置文件(nginx.conf) –error-log-path ...
- nginx 编译参数详解(运维必看)
nginx参数: –prefix= 指向安装目录 –sbin-path 指向(执行)程序文件(nginx) –conf-path= 指向配置文件(nginx.conf) –error-log-path ...
- 看DLI服务4核心如何提升云服务自动化运维
摘要:今天我们来说说DLI是如何实现监控告警来提升整体运维能力,从而为客户更好的提供Serverless的DLI. DLI是支持多模引擎的Serverless大数据计算服务,免运维也是其作为Serve ...
- Python自动化运维开发实战 一、初识Python
导语 都忘记是什么时候知道python的了,我是搞linux运维的,早先只是知道搞运维必须会shell,要做一些运维自动化的工作,比如实现一些定时备份数据啊.批量执行某个操作啊.写写监控脚本什么的. ...
- 从一到万的运维之路,说一说VM/Docker/Kubernetes/ServiceMesh
摘要:本文从单机真机运营的历史讲起,逐步介绍虚拟化.容器化.Docker.Kubernetes.ServiceMesh的发展历程.并重点介绍了容器化阶段之后,各项重点技术的安装.使用.运维知识.可以说 ...
- Knative Serverless 之道:如何 0 运维、低成本实现应用托管?
作者 | 牛秋霖(冬岛) 阿里云容器平台技术专家 关注"阿里巴巴云原生"公众号,回复关键词"1205"即可观看 Knative-Demo 演示视频. 导读:S ...
- 从一个简单的约束看规范性的SQL脚本对数据库运维的影响
之前提到了约束的一些特点,看起来也没什么大不了的问题,http://www.cnblogs.com/wy123/p/7350265.html以下以实际生产运维中遇到的一个问题来说明规范的重要性. 如下 ...
随机推荐
- 洛谷5789 [TJOI2017]可乐(矩阵快速幂,Floyd思想)
题意:可乐机器人有三种行为: 停在原地,去下一个相邻的城市,自爆.它每一秒都会随机触发一种行为.现在给加里敦星球城市图,在第 0秒时可乐机器人在 1号城市,问经过了 t秒,可乐机器人的行为方案数是多少 ...
- [ABC264F] Monochromatic Path
Problem Statement We have a grid with $H$ rows and $W$ columns. Each square is painted either white ...
- 5分钟搞懂Kubernetes:轻松理解所有组件
之前我曾经提到了一系列关于服务网格的内容.然而,我意识到有些同学可能对Kubernetes的了解相对较少,更不用说应用服务网格这个概念了.因此,今天我决定带着大家快速理解Kubernetes中的一些专 ...
- 如何使用sharding-sphere完成读写分离和分库分表?
一.sharding-sphere配置读写分离 1.先搭建好一个MySQL的主从集群,可以参考[MySQL主从集群搭建] 2.在项目中导入相关依赖(记得刷新Maven) <!--读写分离--&g ...
- Golang标准库 container/list(双向链表) 的图文解说
Golang标准库 container/list(双向链表) 的图文解说 提到单向链表,大家应该是比较熟悉的了.今天介绍的是 golang 官方库提供的 双向链表. 1.基础介绍 单向链表中的每个节点 ...
- CTFHub 栈溢出 ret2text exp代码
exp代码: from pwn import * host='challenge-1868f48f1e630fd3.sandbox.ctfhub.com' port=27988 p=connect(h ...
- STM32CubeMX教程10 RTC 实时时钟 - 周期唤醒、闹钟A/B事件和备份寄存器
本实验主要使用STM32CubeMX软件配置STM32F407开发板实现RTC周期唤醒.闹钟A/B事件功能,周期唤醒中输出RTC时间,闹钟A/B事件发生时利用串口输出闹钟A/B事件发生提示 1.准备材 ...
- 面试Java时碰到过的那些问题
项目终于忙完了,难得不加班,但回到家中却不知道干啥,打开自己的云笔记,看到了以前面试时碰到的一些面试题,下面将会把以前面试时被问到的问题都分享出来,下面的题看看小伙伴们可以答的怎样吧 HashMap实 ...
- Spark Streaming快速入门
Spark Streaming快速入门 一.简介 Spark Streaming 是构建在 Spark Core 基础之上的流处理框架(但实际上是微批次处理框架),是 Spark 非常重要的组成部分. ...
- 案例解析丨 Spark Hive 自定义函数应用
摘要:Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数. 1. 简介 Spark目前支持UDF,UDTF,UDAF三种类型的自定义函数.UDF使用场景:输入一行,返回一个结果,一对一, ...