HBase 在统一内容平台业务的优化实践
作者:来自 vivo 互联网服务器团队-Leng Jianyu、Huang Haitao
HBase是一款开源高可靠性、扩展性、高性能和灵活性的分布式非关系型数据库,本文围绕数据库选型以及使用HBase的痛点展开,从四个方面对HBase的使用进行优化,取得了一些不错效果。
一、业务简介
统一内容平台主要承担vivo内容生态的内容审核、内容理解、内容智作和内容分发等核心功能,通过聚合全网内容,建设行业级的业务中台和内容生态,为上下游提供优质可靠的一站式服务,目前服务的业务方包括视频业务、泛信息流业务等。
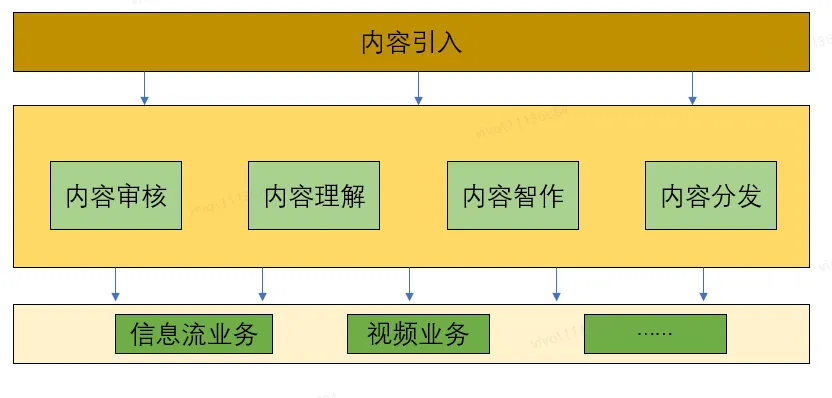
作为一个内容中台,每天要新增存储大量图文和视频内容来满足分发的需要。与此同时,对这些内容加工处理的数据也都需要存储,包括基础信息,分类标签信息,审核信息等等。而且不仅仅是需要存储的数据量级很大,对数据的读取和写入操作也非常频繁,当前对数据库的读写主要集中在两个方面:
核心链路的内容处理包含了大量对内容特征信息的读取和写入操作;
对外提供的查询服务会产生很多回源查询数据库的操作。
在经过多年累积后,当前存储的数据量越变越大,并且可以预见数据量级会不断膨胀下去,如何选择一种可靠的存储选型,来保证服务稳定性和扩展性成了当前项目架构的重中之重。
二、存在的问题
在选用HBase之前,内容平台核心数据的存储以Mongodb为主要存储选型,但是在日常的使用中,发现存储侧存在如下一些痛点问题:
核心数据量大,大表有20TB 以上,总存储 60TB 以上,Mongodb 的存储架构,无法满足良好扩展性要求;
访问查询流量大,需要承载智慧push、泛信息流、视频推荐侧的大回源查询流量,保持查询接口高性能;
为了维护Mongodb的稳定性,需要定期切换 Mongodb 数据库主从节点,重做实例,需要运维长期投入,维护成本高。
所以我们迫切需要寻找一个更适合当前场景的数据库来满足业务请求量和存储大小日益增长的需求,并且要求具备高性能、高稳定、可扩展、低维护成本的特性。
三、存储选型
经过一些调研后发现HBase的一些特性能很好地满足当前场景的要求。
(1)高性能
HBase采用的是Key/Value的列式存储方式(对比Mongodb是行式数据库),同一个列族的数据存放在一个文件中,随着文件的增长会进行分裂,分散到其他机器上,所以即使随着数据量增大,也不会导致读写性能的下降。HBase具备毫秒级的读写性能,如果写入数据量大,还可以使用bulkload导入数据的方式进行高效入库。
(2)高扩展性、高容错性
HBase的存储是基于Hadoop的,Hadoop实现了一个分布式文件系统(HDFS),HDFS的副本机制使得其具有高容错性的特点,并且HDFS的Federation机制使得其具有高扩展性。基于Hadoop意味着HBase与生俱来的超强扩展性和高容错性。
(3)强一致性
HBase的数据是强一致性的,从CAP理论来看,HBase是属于CP的。CAP 定理表明,在存在网络分区的情况下,一致性和可用性必须二选一。HBase在写入数据时,先把操作的记录写入到预写日志中(Write-ahead log,WAL),然后再被加载到Memstore的。就算某个节点机器宕掉了,由于WAL的数据是存储在HDFS上的,所以数据并不会丢失,后续可以通过读取预写日志恢复内容。
(4)列值支持多版本
HBase的多版本特性可以针对某个列族控制列值的版本数,默认是1,即每个key保存一个版本,同一个rowkey的情况下,后面的列值会覆盖前面的列值。可以动态修改列族的版本数,每个版本使用时间戳进行标记,默认是写入时间作为该版本的时间戳,也可以在写入时指定时间戳。
综合以上特性,HBase是非常适合当前项目对数据库选型的要求。
四、HBase 优化实践
随着HBase在整个项目中逐步扩大使用,也发现了一些使用规范问题以及一些查询的性能问题。比如查询毛刺比较多、夜间Compact期间耗时比较高、流量高峰期的时候少量请求会有延迟。针对这些问题,我们从下面四个方面,对HBase的使用进行了优化。
4.1 集群升级
刚开始使用HBase的时候,我们使用的HBase集群版本是1.2版本的,此版本存在诸多弊端,如:RIT(Region-In-Transition)问题频发、请求延时突刺、建删表速度慢、meta 表稳定性差、节点故障恢复速度慢等问题。我们在使用过程发现的主要问题是响应时间突刺问题,该问题会导致我们实时查询接口在回源时超时较多,导致接口的响应时间有突刺被下游业务方熔断,影响业务查询。与HBase团队讨论与评估后,决定将业务使用的集群升级到HBase 2.4.8 版本。该版本在公司较多的业务场景中已经得到验证,可以解决大部分1.2.0版本存在的痛点问题,可以大幅提升读写性能,有效降低读毛刺,单机处理性能的提升可减少20%左右机器成本。
下面是集群升级后的读写平均耗时对比图。可以看到在升级之前,平均响应时间经常会有一些突刺,最高能达到超过10s,升级后几乎不存在这么高的平均响应时间突刺,能保持在10ms以下,偶尔较高也是几十毫秒级别。
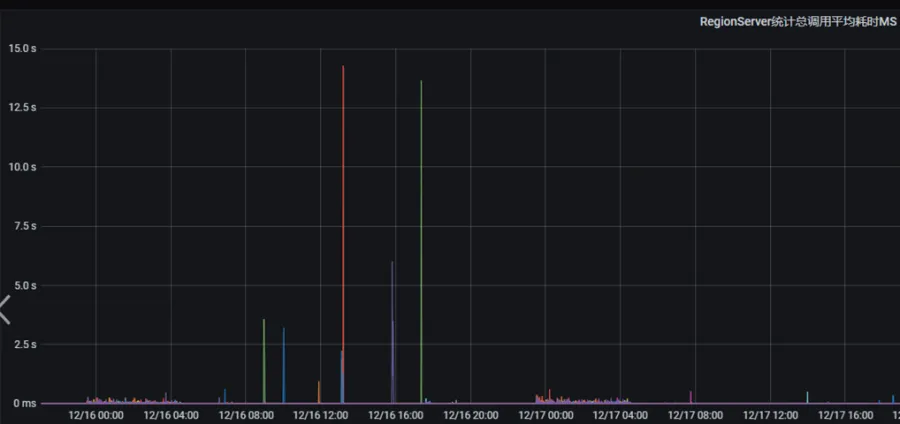
升级前
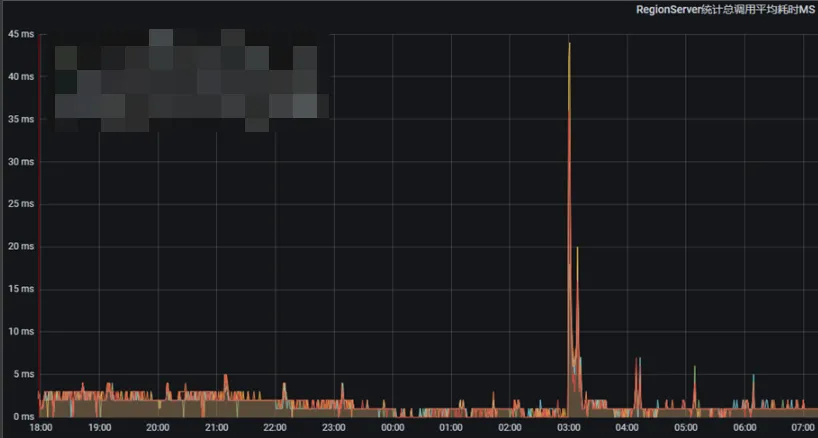
升级后
4.2 连接池使用和连接预热
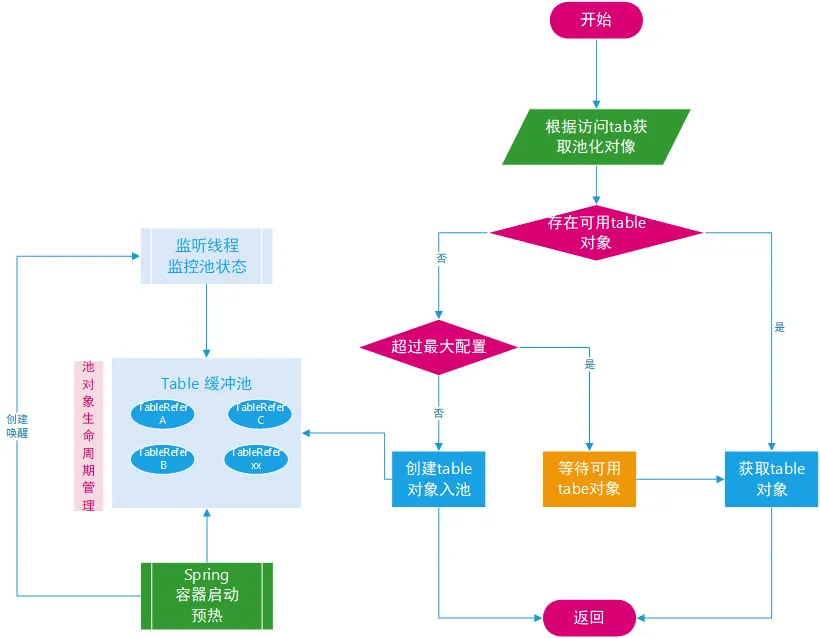
HBase Connection 创建对象并不是简单对应一个socket连接,需要与Zookeeper以及HMaster、RegionServer都建立连接,所以该过程是一个非常耗资源的过程,一般只创建一个 Connection 实例,其它地方共享该实例。在Connection初始化之后,用connection下的getTable方法实现对表格的连接。为了减少与表格连接带来的网络开销,我们建立了对不同表格的连接池来管理客户端和服务端的连接。大致流程图如下图所示。
通过建立连接池,带来了以下三点优势:
(1)对表和表之间进行了连接资源隔离,避免互相影响;
(2)对连接实现了复用,减少了创建连接的网络开销;
(3)防止突增的流量带来的影响,实现平滑处理流量。
此外,图中可以看到,在程序启动阶段,可以实现对HBase表连接的预热,提前建立对表格的连接,可以有效避免在程序启动阶段由于大量建立连接导致读写的响应时间变长,影响整体性能。
连接池通过使用Apache Commons Pool提供的GenericObjectPool通用对象池来实现,GenericObjectPool包含丰富的配置选项,能够定期回收空闲对象,并且支持对象验证,具有强大的线程安全性和可扩展性。然后将不同表格的连接池对象放到本地缓存LoadingCache中,LoadingCache底层通过LRU算法实现对最久远且没有使用的数据的淘汰,保证没有使用的表格连接能及时释放。通过使用第三方的对象池和本地缓存,建立了对HBase表格的连接池,并且实现了预加载,减少了一些读写HBase的开销,降低了读写耗时,对于刚启动服务时的读写突刺带来了一些改善。
4.3 按列读取
HBase建表的时候是不需要确定列的,因为列是可变的,它非常灵活,唯一需要确定的就是列族。一张表的很多属性比如过期时间、数据块缓存以及是否压缩等都是定义在列族上,而不是定义在表上或者列上,这一点做法跟以往的数据库有很大的区别。同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性。一个没有列族的表是没有意义的,因为列必须依赖列族而存在,所以在HBase中一个列的名称前面总是带着它所属的列族。列族存在使得HBase会把相同列族的列尽量放在同一台机器上,不同列族的列分布在不同的机器上。
一般情况下,从客户端发起请求读取数据,到数据返回大致有如下几步:
客户端从ZooKeeper中获取meta表所在regionServer节点信息。
客户端访问meta表所在的regionServer节点,获取region所在节点信息。
客户端访问具体region所在regionServer,找到对应的region。
首先从blockCache中读取数据,存在则返回,不存在则去memstore中读取数据,存在则返回,不存在去storeFile(HFile)中读取数据,存在会先将数据写入到blockCache中,然后返回数据,不存在则返回空。
简单的示意图如下所示:
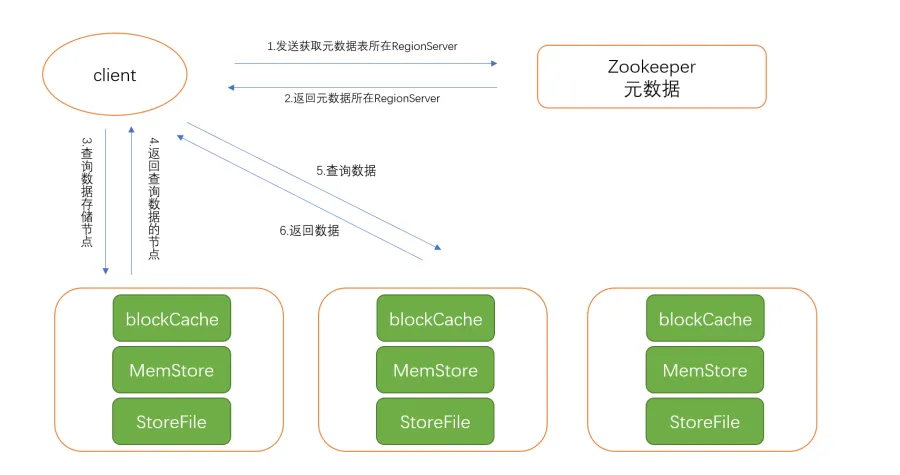
整个过程中如果读取字段过多,或者字段长度过大,那么返回所有列的数据会导致大量无效的数据传输,进而导致集群网络带宽等系统资源被大量占用,必然导致读取性能降低,所以需要减少一些不必要字段的查询。
Get类是HBase官方提供的查询类,在该类中主要有以下几个方法提供来实现减少字段读取:
addFamily:添加要取出的列族;
addColumn:添加要取出的列;
setTimeRange:设置要取出的版本范围;
setMaxVersions:设置取出版本数量。
当前项目中没有使用到HBase的版本范围和版本数量的特性,但是主要场景使用的表字段都比较多(如内容的基本属性能达到上百个字段),或者字段的大小都比较大(如内容解析的一些向量字段),原本在查询时,都是直接读取所有字段,导致很多字段其实不需要使用也被一直读取,浪费性能。通过改用按列读取的方式来实现不同场景下不同字段的查询,避免了超过一半无用字段的返回,平均响应时间也下降了一些。
4.4 compact优化
HBase是基于LSM树存储模型的分布式NoSQL数据库。LSM树相比于普遍使用在各种数据库的B+树来说,能够获得较高随机写性能的同时,也能保持可靠的随机读性能。在进行读请求的时候,LSM树要把多个子树(类似B+树结构)进行归并查询, 因此归并查询的子树数越少,查询的性能就越高。当MemStore超过阀值的时候,就要flush到HDFS上生成一个HFile。因此随着不断写入,HFile的数量将会越来越多,根据前面所述,HFile数量过多会降低读性能。为了避免对读性能的影响,可以对这些HFile进行compact操作,把多个HFile合并成一个HFile。compact操作需要对HBase的数据进行多次的重新读写,因此这个过程会产生大量的IO。可以看到compact操作的本质就是以IO操作换取后续的读性能的提高。
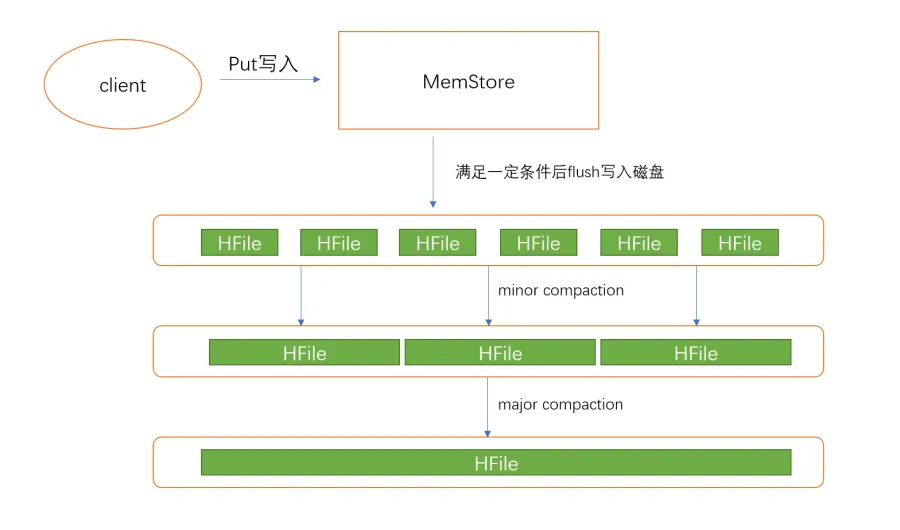
HBase的compact是针对HRegion的HFile文件进行操作的。compact操作分为major和minor两种。major compaction会把所有的HFile都compact为一个HFile,并同时忽略标记为delete的KeyValue(被删除的KeyValue只有在compact过程中才真正被"删除"),可以想象major compaction会产生大量的IO操作,对HBase的读写性能产生影响。minor则只会选择数个HFile文件compact为一个HFile,minor的过程一般较快,而且IO相对较低。在业务高峰期间,都会禁止major操作,只在业务空闲的时段定时执行。
hbase.hstore.compaction.throughput.higher.bound是HBase中控制HFile文件合并(compaction)速度的参数之一。它指定了一个HFile文件每秒最大合并数据大小的上限,以字节为单位。如果一个HFile文件的大小超过了这个上限,HBase就会尝试将其分裂成较小的文件来加快合并速度。通过调整该参数,可以控制HBase在什么条件下开始尝试合并HFile文件。较小的值会导致更频繁的文件合并,也会降低HBase的性能。较大的值则可能导致HFile文件的大小增长过快,从而影响读取性能。
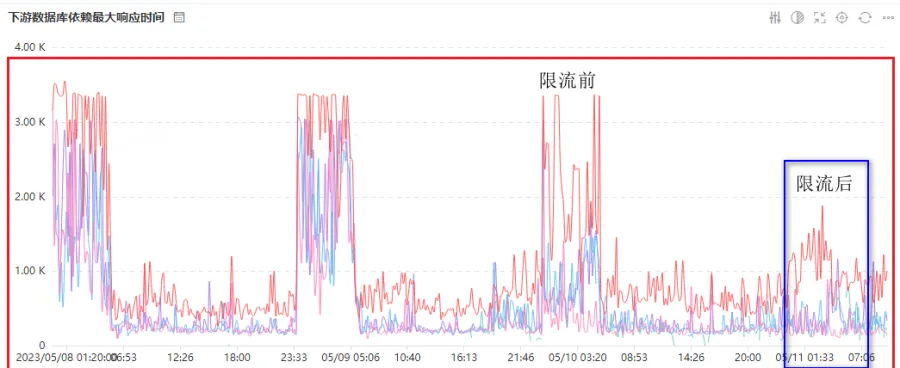
hbase.hstore.compaction.throughput.lower.bound也是HBase中控制HFile文件合并速度的参数之一。它指定了一个HFile文件每秒最小合并数据大小的下限,以字节为单位。当合并速度达到这个下限时,HBase会停止合并更小的HFile文件,而等待更多的数据到达之后再进行合并操作。与higher.bound参数相比,lower.bound参数更加影响文件合并频率和性能。过高的值会导致较少的文件合并和较大的HFile文件,这会影响读取性能和写入并发性。反之,过低的值会导致过于频繁的文件合并,从而占用过多的CPU和磁盘I/O资源,影响整个HBase集群的性能。针对Compact对业务耗时的影响,我们对Compact 操作进行了限流,并且通过多次测试调整Compact上文提到的两个限流的阈值,取得了非常好的效果。Compact期间的耗时下降了70%y以上。下图展示了采取限流前后的耗时对比。
4.5 字段级版本管理
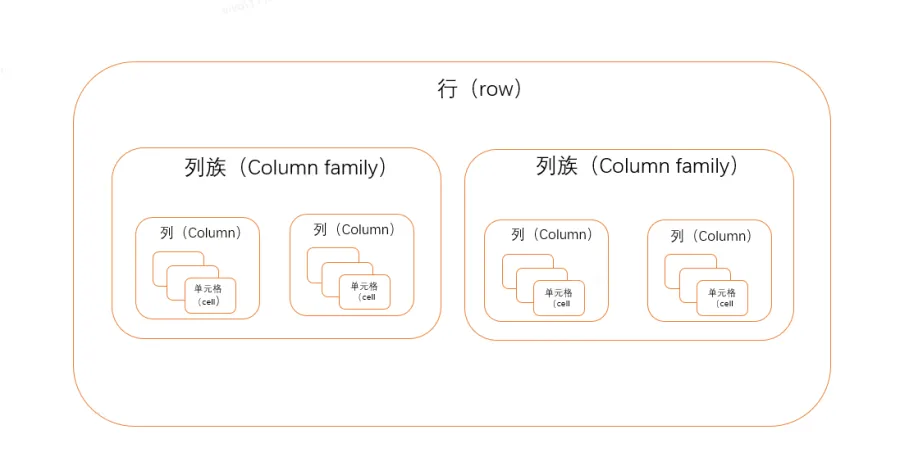
除了上述提到的优化点,我们也探索了一些HBase的其它特性,以备将来用来优化其他方面。上文提到,通过对HBase进行按列读取数据,可以减少get查询的时间,通常意义来讲,列(也就是每个字段)已经是每条数据的最基本单位了,但是HBase中的数据粒度比传统数据结构更细一级,同一个位置的数据还细分成多个版本,一个列上可以存储多个版本的值,多个版本的值被存储在多个单元格里面,多个版本之间用版本号( version)来区分。所以,唯一确定一条结果的表达式应该是行键:列族:列:版本号(rowkey:column family:column:version)。不过,版本号通常是可以省略的,如果写入时不写版本号,每个列或者单元格的值都被赋予一个时间戳,这个时间戳默认是由系统制定的,当然写入时也可以由用户显式指定具体的版本号。在查询时如果不指定版本号,HBase默认获取最后一个版本的数据返回给你。当然也可以指定版本号返回需要的其他版本的数据。简单的示意图如下所示:
同时HBase为了避免数据存在过多的版本造成不必要的负担,HBase提供了两种数据版本的回收方式,一是按照数量维度,保存最后的n个版本,二是按照时间维度,保存最近一段时间的版本数据,比如保存一个月。通过多版本同时存储,对于一些有时序要求的场景非常友好,通过指定版本的时间戳,可以避免在已经更新了新数据的情况下,被旧数据覆盖。当前我们建表是都是只指定了一个版本,使用也都是用的以时间戳为版本号的默认版本,没有采取版本管理的措施,不同单元格可以记录多版本的特性可以考虑应用于字段更新时记录下多个版本的数据,在不影响读写效率的情况下,方便后续在没有相关日志的情况下,回溯最近几次更新的值,并且可以防止误操作或数据损坏,因为用户可以恢复到之前的版本数据。此外我们的系统中存在一些通过消息队列异步更新场景,此时可以使用消息体中的时间戳作为当前版本号,这样可以在多线程消费时,也能保证消费的时序性,因为低版本的版本号无法更新高版本的版本号。
五、总结
本文在对统一内容平台在数据库选型分析和优化的基础上,简要介绍了HBase在实际使用中的一些优化方案,经优化后,项目整体读取和写入性能都有比较明显的提升,较好的保障了统一内容平台业务的稳定性,并且大大降低了业务侧的运维成本。Hbase本身就具备强大的功能,在大数据领域有独有的优势,但是在不同的业务场景,对于HBase的要求也是不一样的,可以结合具体的实际情况,从使用的数据库版本、从HBase底层机制的调参、从客户端调用机制的优化等多方面挖掘,探索更适合业务的方式,希望本文中提到的一些优化方案能给读者带来一些启发。
HBase 在统一内容平台业务的优化实践的更多相关文章
- HBase实践案例:知乎 AI 用户模型服务性能优化实践
用户模型简介 知乎 AI 用户模型服务于知乎两亿多用户,主要为首页.推荐.广告.知识服务.想法.关注页等业务场景提供数据和服务, 例如首页个性化 Feed 的召回和排序.相关回答等用到的用户长期兴趣特 ...
- 分布式统一配置平台-Disconf.Net
源码地址:https://github.com/qkbao/Disconf.Net 作者:青客宝 联系qq:后续奉上 为了更好的解决分布式环境下多台服务实例的配置统一管理问题,本文提出了一套完整的分 ...
- 【.NET Core项目实战-统一认证平台】第十四章 授权篇-自定义授权方式
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章我介绍了如何强制令牌过期的实现,相信大家对IdentityServer4的验证流程有了更深的了解,本篇我将介绍如何使用自定义的授权方 ...
- 【.NET Core项目实战-统一认证平台】第十一章 授权篇-密码授权模式
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章介绍了基于Ids4客户端授权的原理及如何实现自定义的客户端授权,并配合网关实现了统一的授权异常返回值和权限配置等相关功能,本篇将介绍 ...
- 【.NET Core项目实战-统一认证平台】第十章 授权篇-客户端授权
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章介绍了如何使用Dapper持久化IdentityServer4(以下简称ids4)的信息,并实现了sqlserver和mysql两种 ...
- 【.NET Core项目实战-统一认证平台】第九章 授权篇-使用Dapper持久化IdentityServer4
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章介绍了IdentityServer4的源码分析的内容,让我们知道了IdentityServer4的一些运行原理,这篇将介绍如何使用d ...
- 【.NET Core项目实战-统一认证平台】第七章 网关篇-自定义客户端限流
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章我介绍了如何在网关上增加自定义客户端授权功能,从设计到编码实现,一步一步详细讲解,相信大家也掌握了自定义中间件的开发技巧了,本篇我们 ...
- 【.NET Core项目实战-统一认证平台】第一章 功能及架构分析
[.NET Core项目实战-统一认证平台]开篇及目录索引 从本文开始,我们正式进入项目研发阶段,首先我们分析下统一认证平台应该具备哪些功能性需求和非功能性需求,在梳理完这些需求后,设计好系统采用的架 ...
- 【.NET Core项目实战-统一认证平台】第二章网关篇-定制Ocelot来满足需求
[.NET Core项目实战-统一认证平台]开篇及目录索引 这篇文章,我们将从Ocelot的中间件源码分析,目前Ocelot已经实现那些功能,还有那些功能在我们实际项目中暂时还未实现,如果我们要使用这 ...
- 【.NET Core项目实战-统一认证平台】第六章 网关篇-自定义客户端授权
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章我们介绍了网关使用Redis进行缓存,并介绍了如何进行缓存实现,缓存信息清理接口的使用.本篇我们将介绍如何实现网关自定义客户端授权, ...
随机推荐
- WebGL:使用着色器进行几何造型
前言 本文将介绍如何使用着色器来进行几何造型,说到几何图形大家一定都不陌生,比如说三角形.圆形,接触过WebGL基础使用的小伙伴一定都知道怎么去在画布上绘制一个三角形,只要传入三个顶点坐标,并选择绘图 ...
- Springboot+Mybatis+Clickhouse+jsp 搭建单体应用项目(二)(添加日志打印和源码地址)
一.添加yaml设置 1 logging: 2 level: 3 com.mrliu.undertow.mapper : debug 二.添加pom的Hutool工具,完善日志打印处理 1 <d ...
- Unraid 使用 Docker Compose 安装 Immich 套件无法启用人脸识别的原因及修复方法
原因 问题原因是官方教程中的 docker-compose.yml 指明的机器学习组件 immich-machine-learning 中的 container_name 与 也就是 docker-c ...
- Pageoffice6 实现后台批量生成PDF文档
在实际项目开发中经常会遇到批量后台动态生成PDF文档的需求,目前网上有一些针对此需求的方案,如果您想要了解这些方案的对比,请查看后台生成单个Word文档中的"方案对比". 如果一次 ...
- saltstack使用
saltstack中salt-key的用法 介绍: saltstack中master和minion是依靠证书来进行加密通信的.在saltstack中salt-key命令是用来管理证书的 用法: sal ...
- .NET常用库-Ocelot
一 介绍 1.简介 Ocelot是一个.NET API网关. Ocelot仅适用于.NET Core,目前是为netstandard2.0构建的. Ocelot是一组按特定顺序排列的中间件. Ocel ...
- IMX6ULL基本环境搭建
基本环境搭建 1 交叉编译工具 在虚拟机中安装交叉编译工具,为后续开发做准备. 1.1 工具版本 工具版本:Linaro Releases 当前虚拟机为64位系统,因此下载64位系统的工具: $ un ...
- LTSC系统,唯一未被微软宣传过,却备受用户赞誉,CPU占用暴降
微软拥有多款操作系统,如Windows XP.Windows 7.Windows 10以及最新的Windows 11等. 其中,Windows XP和Windows 7因其稳定性和用户友好性而广受好评 ...
- tab切换之循环遍历
<style> *{ margin: 0; padding:0; } ul,ol,li{ ...
- 项目管理--PMBOK 读书笔记(7)【项目成本管理】
1.成本术语: 2.三点估算(PERT): 平均估算值=(最可能持续时间*4+最乐观+最悲观)/6 标准差=(最乐观-最悲观)/6 68.26%.95.46%.99.73% 3.估算成本的工具:质量成 ...