JVM(Java虚拟机)整理(二):排错调优
前言
上一篇内容:JVM(Java虚拟机)整理(一)
Java 内存模型(JMM)详解
声明:本章节转载自 Info 上 深入理解Java内存模型。PDF文档下载 深入理解Java内存模型【程晓明】
作者:程晓明
说明:这篇文章对JMM讲得很清楚了,大致分三部分:重排序与顺序一致性;三个同步原语(lock,volatile,final)的内存语义,重排序规则及在处理器中的实现;Java内存模型的设计,及其与处理器内存模型和顺序一致性内存模型的关系。
# 基础
# 并发编程模型的分类
在并发编程中,我们需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体)。通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递。
在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写 - 读内存中的公共状态来隐式进行通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
同步是指程序用于控制不同线程之间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java 的并发采用的是共享内存模型,Java 线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。如果编写多线程程序的 Java 程序员不理解隐式进行的线程之间通信的工作机制,很可能会遇到各种奇怪的内存可见性问题。
# Java 内存模型的抽象
在 Java 中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态域和数组元素)。局部变量(Local variables),方法定义参数(Java 语言规范称之为 formal method parameters)和异常处理器参数(exception handler parameters)不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
Java 线程之间的通信由 Java 内存模型(本文简称为 JMM)控制,JMM 决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM 定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读 / 写共享变量的副本。本地内存是 JMM 的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java 内存模型的抽象示意图如下:
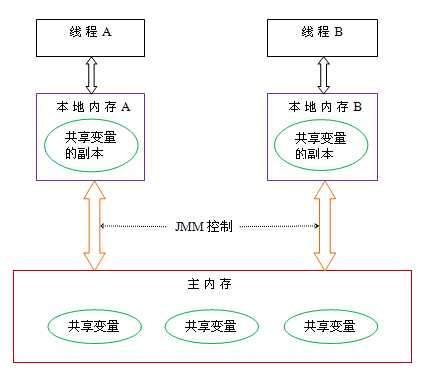
从上图来看,线程 A 与线程 B 之间如要通信的话,必须要经历下面 2 个步骤:
- 首先,线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中去。
- 然后,线程 B 到主内存中去读取线程 A 之前已更新过的共享变量。
下面通过示意图来说明这两个步骤:
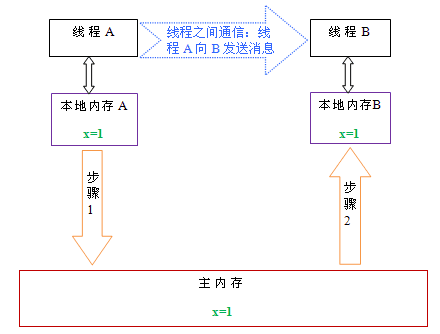
如上图所示,本地内存 A 和 B 有主内存中共享变量 x 的副本。假设初始时,这三个内存中的 x 值都为 0。线程 A 在执行时,把更新后的 x 值(假设值为 1)临时存放在自己的本地内存 A 中。当线程 A 和线程 B 需要通信时,线程 A 首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。随后,线程 B 到主内存中去读取线程 A 更新后的 x 值,此时线程 B 的本地内存的 x 值也变为了 1。
从整体来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,来为 java 程序员提供内存可见性保证。
# 重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读 / 写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从 java 源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

上述的 1 属于编译器重排序,2 和 3 属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM 的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM 的处理器重排序规则会要求 java 编译器在生成指令序列时,插入特定类型的内存屏障(memory barriers,intel 称之为 memory fence)指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM 属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
# 处理器重排序与内存屏障指令
现代的处理器使用写缓冲区来临时保存向内存写入的数据。写缓冲区可以保证指令流水线持续运行,它可以避免由于处理器停顿下来等待向内存写入数据而产生的延迟。同时,通过以批处理的方式刷新写缓冲区,以及合并写缓冲区中对同一内存地址的多次写,可以减少对内存总线的占用。虽然写缓冲区有这么多好处,但每个处理器上的写缓冲区,仅仅对它所在的处理器可见。这个特性会对内存操作的执行顺序产生重要的影响:处理器对内存的读 / 写操作的执行顺序,不一定与内存实际发生的读 / 写操作顺序一致!为了具体说明,请看下面示例:
// Processor A
a = 1; //A1
x = b; //A2
// Processor B
b = 2; //B1
y = a; //B2
// 初始状态:a = b = 0;处理器允许执行后得到结果:x = y = 0
假设处理器 A 和处理器 B 按程序的顺序并行执行内存访问,最终却可能得到 x = y = 0 的结果。具体的原因如下图所示:
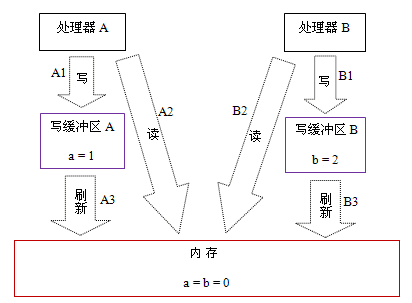
这里处理器 A 和处理器 B 可以同时把共享变量写入自己的写缓冲区(A1,B1),然后从内存中读取另一个共享变量(A2,B2),最后才把自己写缓存区中保存的脏数据刷新到内存中(A3,B3)。当以这种时序执行时,程序就可以得到 x = y = 0 的结果。
从内存操作实际发生的顺序来看,直到处理器 A 执行 A3 来刷新自己的写缓存区,写操作 A1 才算真正执行了。虽然处理器 A 执行内存操作的顺序为:A1->A2,但内存操作实际发生的顺序却是:A2->A1。此时,处理器 A 的内存操作顺序被重排序了(处理器 B 的情况和处理器 A 一样,这里就不赘述了)。
这里的关键是,由于写缓冲区仅对自己的处理器可见,它会导致处理器执行内存操作的顺序可能会与内存实际的操作执行顺序不一致。由于现代的处理器都会使用写缓冲区,因此现代的处理器都会允许对写 - 读操做重排序。
下面是常见处理器允许的重排序类型的列表:
| Load-Load | Load-Store | Store-Store | Store-Load | 数据依赖 | |
|---|---|---|---|---|---|
| sparc-TSO | N | N | N | Y | N |
| x86 | N | N | N | Y | N |
| ia64 | Y | Y | Y | Y | N |
| PowerPC | Y | Y | Y | Y | N |
上表单元格中的“N”表示处理器不允许两个操作重排序,“Y”表示允许重排序。
从上表我们可以看出:常见的处理器都允许 Store-Load 重排序;常见的处理器都不允许对存在数据依赖的操作做重排序。sparc-TSO 和 x86 拥有相对较强的处理器内存模型,它们仅允许对写 - 读操作做重排序(因为它们都使用了写缓冲区)。
- ※注 1:sparc-TSO 是指以 TSO(Total Store Order) 内存模型运行时,sparc 处理器的特性。
- ※注 2:上表中的 x86 包括 x64 及 AMD64。
- ※注 3:由于 ARM 处理器的内存模型与 PowerPC 处理器的内存模型非常类似,本文将忽略它。
- ※注 4:数据依赖性后文会专门说明。
为了保证内存可见性,java 编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM 把内存屏障指令分为下列四类:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 确保 Load1 数据的装载,之前于 Load2 及所有后续装载指令的装载。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 确保 Store1 数据对其他处理器可见(刷新到内存),之前于 Store2 及所有后续存储指令的存储。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 确保 Load1 数据装载,之前于 Store2 及所有后续的存储指令刷新到内存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 确保 Store1 数据对其他处理器变得可见(指刷新到内存),之前于 Load2 及所有后续装载指令的装载。 |
StoreLoad Barriers 会使该屏障之前的所有内存访问指令(存储和装载指令)完成之后,才执行该屏障之后的内存访问指令。
StoreLoad Barriers 是一个“全能型”的屏障,它同时具有其他三个屏障的效果。现代的多处理器大都支持该屏障(其他类型的屏障不一定被所有处理器支持)。执行该屏障开销会很昂贵,因为当前处理器通常要把写缓冲区中的数据全部刷新到内存中(buffer fully flush)。
# happens-before
happens-before八大规则
- 单一线程规则(Single Thread rule):在一个线程内,在程序前面的操作先行发生于后面的操作。
- 管道锁定规则(Monitor Lock Rule):一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
- Volatile变量规则(Volatile Variable Rule):对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
- 线程启动规则(Thread Start Rule):Thread 对象的
start()方法调用先行发生于此线程的每一个动作。 - 线程加入规则(Thread Join Rule):Thread 对象的结束先行发生于
join()方法返回。 - 线程中断规则(Thread Interruption Rule):对线程
interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过interrupted()方法检测到是否有中断发生。 - 对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的
finalize()方法的开始。 - 传递性(Transitivity):如果操作 A 先行发生于操作 B,操作 B 先行发生于操作 C,那么操作 A 先行发生于操作 C。
从 JDK5 开始,Java 使用新的 JSR -133 内存模型(本文除非特别说明,针对的都是 JSR- 133 内存模型)。JSR-133 提出了 happens-before 的概念,通过这个概念来阐述操作之间的内存可见性。如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在 happens-before 关系。这里提到的两个操作既可以是在一个线程之内,也可以是在不同线程之间。 与程序员密切相关的 happens-before 规则如下:
- 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile 变量规则:对一个 volatile 域的写,happens- before 于任意后续对这个 volatile 域的读。
- 传递性:如果 A happens- before B,且 B happens- before C,那么 A happens- before C。
注意,两个操作之间具有 happens-before 关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前(the first is visible to and ordered before the second)。happens- before 的定义很微妙,后文会具体说明 happens-before 为什么要这么定义。
happens-before 与 JMM 的关系如下图所示:
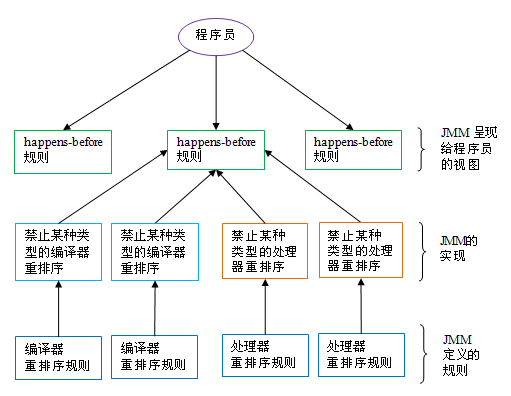
如上图所示,一个 happens-before 规则通常对应于多个编译器重排序规则和处理器重排序规则。对于 java 程序员来说,happens-before 规则简单易懂,它避免程序员为了理解 JMM 提供的内存可见性保证而去学习复杂的重排序规则以及这些规则的具体实现。
# 重排序
# 数据依赖性
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖分下列三种类型:
| 名称 | 代码示例 | 说明 |
|---|---|---|
| 写后读 | a = 1;b = a; | 写一个变量之后,再读这个位置。 |
| 写后写 | a = 1;a = 2; | 写一个变量之后,再写这个变量。 |
| 读后写 | a = b;b = 1; | 读一个变量之后,再写这个变量。 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。
前面提到过,编译器和处理器可能会对操作做重排序。编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
# as-if-serial 语义
as-if-serial 语义的意思指:不管怎么重排序(编译器和处理器为了提高并行度),(单线程)程序的执行结果不能被改变。编译器,runtime 和处理器都必须遵守 as-if-serial 语义。
为了遵守 as-if-serial 语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例:
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
上面三个操作的数据依赖关系如下图所示:
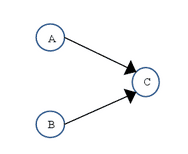
如上图所示,A 和 C 之间存在数据依赖关系,同时 B 和 C 之间也存在数据依赖关系。因此在最终执行的指令序列中,C 不能被重排序到 A 和 B 的前面(C 排到 A 和 B 的前面,程序的结果将会被改变)。但 A 和 B 之间没有数据依赖关系,编译器和处理器可以重排序 A 和 B 之间的执行顺序。下图是该程序的两种执行顺序:
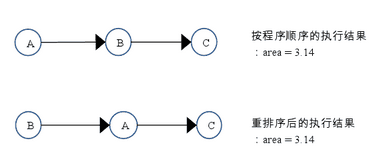
as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器,runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。as-if-serial 语义使单线程程序员无需担心重排序会干扰他们,也无需担心内存可见性问题。
# 程序顺序规则
根据 happens- before 的程序顺序规则,上面计算圆的面积的示例代码存在三个 happens- before 关系:
- A happens- before B;
- B happens- before C;
- A happens- before C;
这里的第 3 个 happens- before 关系,是根据 happens- before 的传递性推导出来的。
这里 A happens- before B,但实际执行时 B 却可以排在 A 之前执行(看上面的重排序后的执行顺序)。在第一章提到过,如果 A happens- before B,JMM 并不要求 A 一定要在 B 之前执行。JMM 仅仅要求前一个操作(执行的结果)对后一个操作可见,且前一个操作按顺序排在第二个操作之前。这里操作 A 的执行结果不需要对操作 B 可见;而且重排序操作 A 和操作 B 后的执行结果,与操作 A 和操作 B 按 happens- before 顺序执行的结果一致。在这种情况下,JMM 会认为这种重排序并不非法(not illegal),JMM 允许这种重排序。
在计算机中,软件技术和硬件技术有一个共同的目标:在不改变程序执行结果的前提下,尽可能的开发并行度。编译器和处理器遵从这一目标,从 happens- before 的定义我们可以看出,JMM 同样遵从这一目标。
# 重排序对多线程的影响
现在让我们来看看,重排序是否会改变多线程程序的执行结果。请看下面的示例代码:
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
flag 变量是个标记,用来标识变量 a 是否已被写入。这里假设有两个线程 A 和 B,A 首先执行 writer() 方法,随后 B 线程接着执行 reader() 方法。线程 B 在执行操作 4 时,能否看到线程 A 在操作 1 对共享变量 a 的写入?
答案是:不一定能看到。
由于操作 1 和操作 2 没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作 3 和操作 4 没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作 1 和操作 2 重排序时,可能会产生什么效果? 请看下面的程序执行时序图:
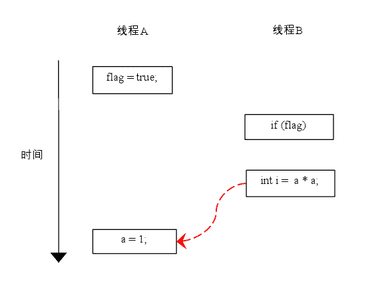
如上图所示,操作 1 和操作 2 做了重排序。程序执行时,线程 A 首先写标记变量 flag,随后线程 B 读这个变量。由于条件判断为真,线程 B 将读取变量 a。此时,变量 a 还根本没有被线程 A 写入,在这里多线程程序的语义被重排序破坏了!
※注:本文统一用红色的虚箭线表示错误的读操作,用绿色的虚箭线表示正确的读操作。
下面再让我们看看,当操作 3 和操作 4 重排序时会产生什么效果(借助这个重排序,可以顺便说明控制依赖性)。下面是操作 3 和操作 4 重排序后,程序的执行时序图:
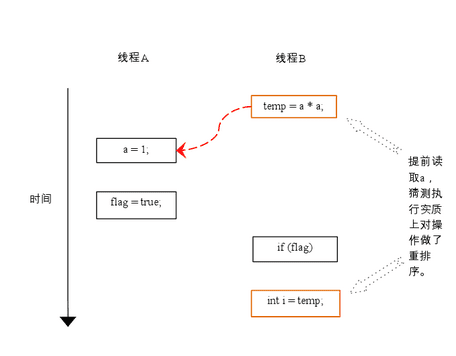
在程序中,操作 3 和操作 4 存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程 B 的处理器可以提前读取并计算 a*a,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作 3 的条件判断为真时,就把该计算结果写入变量 i 中。
从图中我们可以看出,猜测执行实质上对操作 3 和 4 做了重排序。重排序在这里破坏了多线程程序的语义!
在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是 as-if-serial 语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。
# 顺序一致性
# 数据竞争与顺序一致性保证
当程序未正确同步时,就会存在数据竞争。java 内存模型规范对数据竞争的定义如下:
- 在一个线程中写一个变量,
- 在另一个线程读同一个变量,
- 而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果(前一章的示例正是如此)。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。
JMM 对正确同步的多线程程序的内存一致性做了如下保证:
- 如果程序是正确同步的,程序的执行将具有顺序一致性(sequentially consistent)-- 即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同(马上我们将会看到,这对于程序员来说是一个极强的保证)。这里的同步是指广义上的同步,包括对常用同步原语(lock,volatile 和 final)的正确使用。
# 顺序一致性内存模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行。 +(不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。 顺序一致性内存模型为程序员提供的视图如下:

在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程。同时,每一个线程必须按程序的顺序来执行内存读 / 写操作。从上图我们可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读 / 写操作串行化。
为了更好的理解,下面我们通过两个示意图来对顺序一致性模型的特性做进一步的说明。
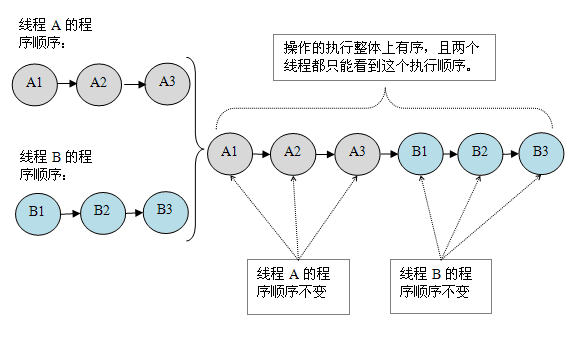
假设有两个线程 A 和 B 并发执行。其中 A 线程有三个操作,它们在程序中的顺序是:A1->A2->A3。B 线程也有三个操作,它们在程序中的顺序是:B1->B2->B3。
假设这两个线程使用监视器来正确同步:A 线程的三个操作执行后释放监视器,随后 B 线程获取同一个监视器。那么程序在顺序一致性模型中的执行效果将如下图所示:
现在我们再假设这两个线程没有做同步,下面是这个未同步程序在顺序一致性模型中的执行示意图:
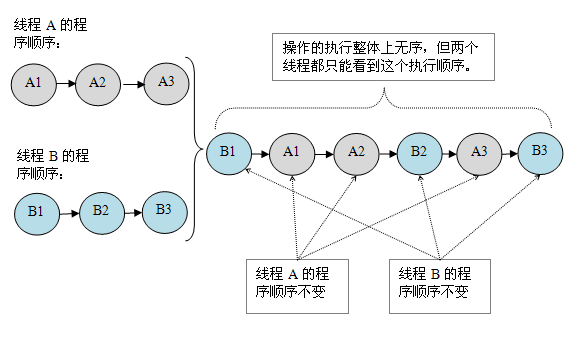
未同步程序在顺序一致性模型中虽然整体执行顺序是无序的,但所有线程都只能看到一个一致的整体执行顺序。以上图为例,线程 A 和 B 看到的执行顺序都是:B1->A1->A2->B2->A3->B3。之所以能得到这个保证是因为顺序一致性内存模型中的每个操作必须立即对任意线程可见。
但是,在 JMM 中就没有这个保证。未同步程序在 JMM 中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,且还没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本还没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其它线程看到的操作执行顺序将不一致。
# 同步程序的顺序一致性效果
下面我们对前面的示例程序 ReorderExample 用监视器来同步,看看正确同步的程序如何具有顺序一致性。
请看下面的示例代码:
class SynchronizedExample {
int a = 0;
boolean flag = false;
public synchronized void writer() {
a = 1;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a;
……
}
}
}
上面示例代码中,假设 A 线程执行 writer() 方法后,B 线程执行 reader() 方法。这是一个正确同步的多线程程序。根据 JMM 规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。下面是该程序在两个内存模型中的执行时序对比图:
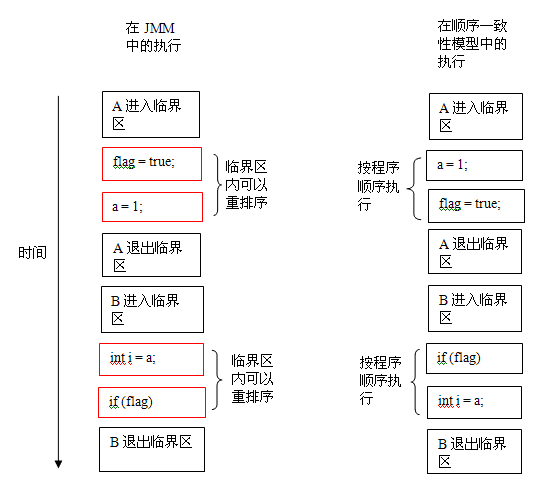
在顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在 JMM 中,临界区内的代码可以重排序(但 JMM 不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM 会在退出监视器和进入监视器这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图(具体细节后文会说明)。虽然线程 A 在临界区内做了重排序,但由于监视器的互斥执行的特性,这里的线程 B 根本无法“观察”到线程 A 在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
从这里我们可以看到 JMM 在具体实现上的基本方针:在不改变(正确同步的)程序执行结果的前提下,尽可能的为编译器和处理器的优化打开方便之门。
# 未同步程序的执行特性
对于未同步或未正确同步的多线程程序,JMM 只提供最小安全性:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false),JMM 保证线程读操作读取到的值不会无中生有(out of thin air)的冒出来。为了实现最小安全性,JVM 在堆上分配对象时,首先会清零内存空间,然后才会在上面分配对象(JVM 内部会同步这两个操作)。因此,在以清零的内存空间(pre-zeroed memory)分配对象时,域的默认初始化已经完成了。
JMM 不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为未同步程序在顺序一致性模型中执行时,整体上是无序的,其执行结果无法预知。保证未同步程序在两个模型中的执行结果一致毫无意义。
和顺序一致性模型一样,未同步程序在 JMM 中的执行时,整体上也是无序的,其执行结果也无法预知。同时,未同步程序在这两个模型中的执行特性有下面几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而 JMM 不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。这一点前面已经讲过了,这里就不再赘述。
- 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而 JMM 不保证所有线程能看到一致的操作执行顺序。这一点前面也已经讲过,这里就不再赘述。
- JMM 不保证对 64 位的 long 型和 double 型变量的读 / 写操作具有原子性,而顺序一致性模型保证对所有的内存读 / 写操作都具有原子性。
第 3 个差异与处理器总线的工作机制密切相关。在计算机中,数据通过总线在处理器和内存之间传递。每次处理器和内存之间的数据传递都是通过一系列步骤来完成的,这一系列步骤称之为总线事务(bus transaction)。总线事务包括读事务(read transaction)和写事务(write transaction)。读事务从内存传送数据到处理器,写事务从处理器传送数据到内存,每个事务会读 / 写内存中一个或多个物理上连续的字。这里的关键是,总线会同步试图并发使用总线的事务。在一个处理器执行总线事务期间,总线会禁止其它所有的处理器和 I/O 设备执行内存的读 / 写。下面让我们通过一个示意图来说明总线的工作机制:
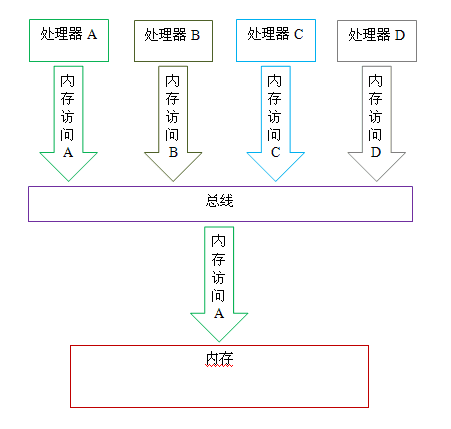
如上图所示,假设处理器 A,B 和 C 同时向总线发起总线事务,这时总线仲裁(bus arbitration)会对竞争作出裁决,这里我们假设总线在仲裁后判定处理器 A 在竞争中获胜(总线仲裁会确保所有处理器都能公平的访问内存)。此时处理器 A 继续它的总线事务,而其它两个处理器则要等待处理器 A 的总线事务完成后才能开始再次执行内存访问。假设在处理器 A 执行总线事务期间(不管这个总线事务是读事务还是写事务),处理器 D 向总线发起了总线事务,此时处理器 D 的这个请求会被总线禁止。
总线的这些工作机制可以把所有处理器对内存的访问以串行化的方式来执行;在任意时间点,最多只能有一个处理器能访问内存。这个特性确保了单个总线事务之中的内存读 / 写操作具有原子性。
在一些 32 位的处理器上,如果要求对 64 位数据的读 / 写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java 语言规范鼓励但不强求 JVM 对 64 位的 long 型变量和 double 型变量的读 / 写具有原子性。当 JVM 在这种处理器上运行时,会把一个 64 位 long/ double 型变量的读 / 写操作拆分为两个 32 位的读 / 写操作来执行。这两个 32 位的读 / 写操作可能会被分配到不同的总线事务中执行,此时对这个 64 位变量的读 / 写将不具有原子性。
当单个内存操作不具有原子性,将可能会产生意想不到后果。请看下面示意图:
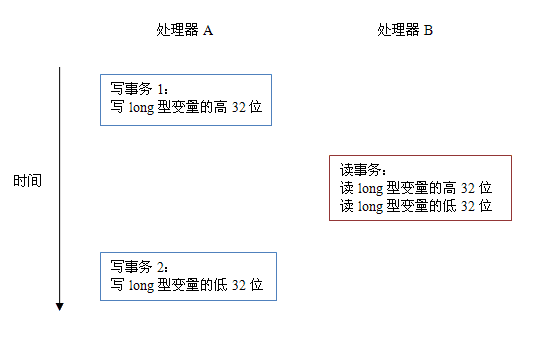
如上图所示,假设处理器 A 写一个 long 型变量,同时处理器 B 要读这个 long 型变量。处理器 A 中 64 位的写操作被拆分为两个 32 位的写操作,且这两个 32 位的写操作被分配到不同的写事务中执行。同时处理器 B 中 64 位的读操作被拆分为两个 32 位的读操作,且这两个 32 位的读操作被分配到同一个的读事务中执行。当处理器 A 和 B 按上图的时序来执行时,处理器 B 将看到仅仅被处理器 A“写了一半“的无效值。
# 总结
# 处理器内存模型
顺序一致性内存模型是一个理论参考模型,JMM 和处理器内存模型在设计时通常会把顺序一致性内存模型作为参照。JMM 和处理器内存模型在设计时会对顺序一致性模型做一些放松,因为如果完全按照顺序一致性模型来实现处理器和 JMM,那么很多的处理器和编译器优化都要被禁止,这对执行性能将会有很大的影响。
根据对不同类型读 / 写操作组合的执行顺序的放松,可以把常见处理器的内存模型划分为下面几种类型:
- 放松程序中写 - 读操作的顺序,由此产生了 total store ordering 内存模型(简称为 TSO)。
- 在前面 1 的基础上,继续放松程序中写 - 写操作的顺序,由此产生了 partial store order 内存模型(简称为 PSO)。
- 在前面 1 和 2 的基础上,继续放松程序中读 - 写和读 - 读操作的顺序,由此产生了 relaxed memory order 内存模型(简称为 RMO)和 PowerPC 内存模型。
注意,这里处理器对读 / 写操作的放松,是以两个操作之间不存在数据依赖性为前提的(因为处理器要遵守 as-if-serial 语义,处理器不会对存在数据依赖性的两个内存操作做重排序)。
下面的表格展示了常见处理器内存模型的细节特征:
| 内存模型名称 | 对应的处理器 | Store-Load 重排序 | Store-Store 重排序 | Load-Load 和 Load-Store 重排序 | 可以更早读取到其它处理器的写 | 可以更早读取到当前处理器的写 |
|---|---|---|---|---|---|---|
| TSO | sparc-TSO X64 | Y | Y | |||
| PSO | sparc-PSO | Y | Y | Y | ||
| RMO | ia64 | Y | Y | Y | Y | |
| PowerPC | PowerPC | Y | Y | Y | Y | Y |
在这个表格中,我们可以看到所有处理器内存模型都允许写 - 读重排序,原因在第一章以说明过:它们都使用了写缓存区,写缓存区可能导致写 - 读操作重排序。同时,我们可以看到这些处理器内存模型都允许更早读到当前处理器的写,原因同样是因为写缓存区:由于写缓存区仅对当前处理器可见,这个特性导致当前处理器可以比其他处理器先看到临时保存在自己的写缓存区中的写。
上面表格中的各种处理器内存模型,从上到下,模型由强变弱。越是追求性能的处理器,内存模型设计的会越弱。因为这些处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。
由于常见的处理器内存模型比 JMM 要弱,java 编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。同时,由于各种处理器内存模型的强弱并不相同,为了在不同的处理器平台向程序员展示一个一致的内存模型,JMM 在不同的处理器中需要插入的内存屏障的数量和种类也不相同。下图展示了 JMM 在不同处理器内存模型中需要插入的内存屏障的示意图:
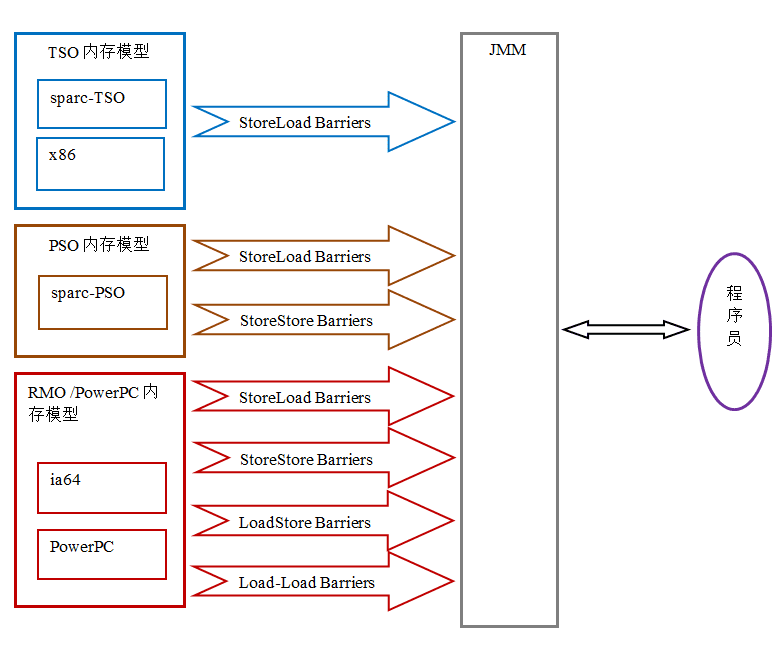
如上图所示,JMM 屏蔽了不同处理器内存模型的差异,它在不同的处理器平台之上为 java 程序员呈现了一个一致的内存模型。
# JMM,处理器内存模型与顺序一致性内存模型之间的关系
JMM 是一个语言级的内存模型,处理器内存模型是硬件级的内存模型,顺序一致性内存模型是一个理论参考模型。下面是语言内存模型,处理器内存模型和顺序一致性内存模型的强弱对比示意图:
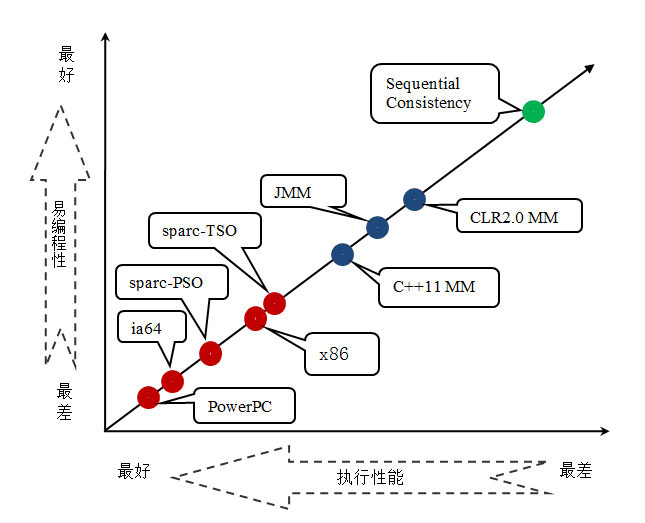
从上图我们可以看出:常见的 4 种处理器内存模型比常用的 3 中语言内存模型要弱,处理器内存模型和语言内存模型都比顺序一致性内存模型要弱。同处理器内存模型一样,越是追求执行性能的语言,内存模型设计的会越弱。
# JMM 的设计
从 JMM 设计者的角度来说,在设计 JMM 时,需要考虑两个关键因素:
- 程序员对内存模型的使用。程序员希望内存模型易于理解,易于编程。程序员希望基于一个强内存模型来编写代码。
- 编译器和处理器对内存模型的实现。编译器和处理器希望内存模型对它们的束缚越少越好,这样它们就可以做尽可能多的优化来提高性能。编译器和处理器希望实现一个弱内存模型。
由于这两个因素互相矛盾,所以 JSR-133 专家组在设计 JMM 时的核心目标就是找到一个好的平衡点:一方面要为程序员提供足够强的内存可见性保证;另一方面,对编译器和处理器的限制要尽可能的放松。下面让我们看看 JSR-133 是如何实现这一目标的。
为了具体说明,请看前面提到过的计算圆面积的示例代码:
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r; //C
上面计算圆的面积的示例代码存在三个 happens- before 关系:
- A happens- before B;
- B happens- before C;
- A happens- before C;
由于 A happens- before B,happens- before 的定义会要求:A 操作执行的结果要对 B 可见,且 A 操作的执行顺序排在 B 操作之前。 但是从程序语义的角度来说,对 A 和 B 做重排序即不会改变程序的执行结果,也还能提高程序的执行性能(允许这种重排序减少了对编译器和处理器优化的束缚)。也就是说,上面这 3 个 happens- before 关系中,虽然 2 和 3 是必需要的,但 1 是不必要的。因此,JMM 把 happens- before 要求禁止的重排序分为了下面两类:
- 会改变程序执行结果的重排序。
- 不会改变程序执行结果的重排序。
JMM 对这两种不同性质的重排序,采取了不同的策略:
- 对于会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序。
- 对于不会改变程序执行结果的重排序,JMM 对编译器和处理器不作要求(JMM 允许这种重排序)。
下面是 JMM 的设计示意图:
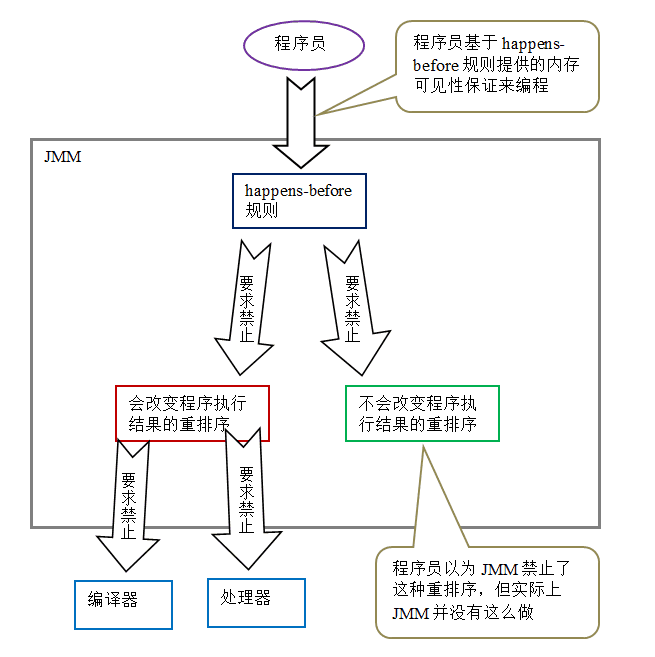
从上图可以看出两点:
- JMM 向程序员提供的 happens- before 规则能满足程序员的需求。JMM 的 happens- before 规则不但简单易懂,而且也向程序员提供了足够强的内存可见性保证(有些内存可见性保证其实并不一定真实存在,比如上面的 A happens- before B)。
- JMM 对编译器和处理器的束缚已经尽可能的少。从上面的分析我们可以看出,JMM 其实是在遵循一个基本原则:只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。比如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。再比如,如果编译器经过细致的分析后,认定一个 volatile 变量仅仅只会被单个线程访问,那么编译器可以把这个 volatile 变量当作一个普通变量来对待。这些优化既不会改变程序的执行结果,又能提高程序的执行效率。
# JMM 的内存可见性保证
Java 程序的内存可见性保证按程序类型可以分为下列三类:
- 单线程程序。单线程程序不会出现内存可见性问题。编译器,runtime 和处理器会共同确保单线程程序的执行结果与该程序在顺序一致性模型中的执行结果相同。
- 正确同步的多线程程序。正确同步的多线程程序的执行将具有顺序一致性(程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同)。这是 JMM 关注的重点,JMM 通过限制编译器和处理器的重排序来为程序员提供内存可见性保证。
- 未同步 / 未正确同步的多线程程序。JMM 为它们提供了最小安全性保障:线程执行时读取到的值,要么是之前某个线程写入的值,要么是默认值(0,null,false)。
下图展示了这三类程序在 JMM 中与在顺序一致性内存模型中的执行结果的异同:
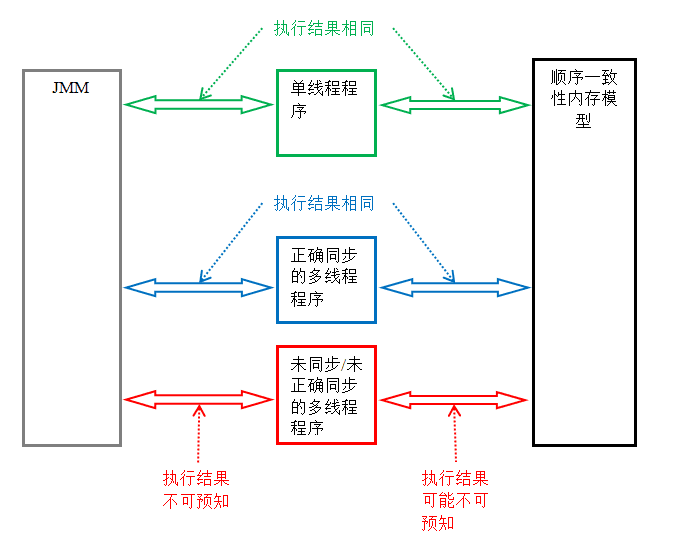
只要多线程程序是正确同步的,JMM 保证该程序在任意的处理器平台上的执行结果,与该程序在顺序一致性内存模型中的执行结果一致。
# JSR-133 对旧内存模型的修补
JSR-133 对 JDK5 之前的旧内存模型的修补主要有两个:
- 增强 volatile 的内存语义。旧内存模型允许 volatile 变量与普通变量重排序。JSR-133 严格限制 volatile 变量与普通变量的重排序,使 volatile 的写 - 读和锁的释放 - 获取具有相同的内存语义。
- 增强 final 的内存语义。在旧内存模型中,多次读取同一个 final 变量的值可能会不相同。为此,JSR-133 为 final 增加了两个重排序规则。现在,final 具有了初始化安全性。
Java问题排查之Linux命令
声明:此章节内容整理自 @pdai:调试排错 - Java 问题排查之Linux命令
文本操作
文本查找 - grep
grep常用命令:
# 基本使用
grep yoursearchkeyword f.txt # 文件查找
grep 'KeyWord otherKeyWord' f.txt cpf.txt # 多文件查找, 含空格加引号
grep 'KeyWord' /home/admin -r -n # 目录下查找所有符合关键字的文件
grep 'keyword' /home/admin -r -n -i # -i 忽略大小写
grep 'KeyWord' /home/admin -r -n --include *.{vm,Java} # 指定文件后缀
grep 'KeyWord' /home/admin -r -n --exclude *.{vm,Java} # 反匹配
# cat + grep
cat f.txt | grep -i keyword # 查找所有keyword且不分大小写
cat f.txt | grep -c 'KeyWord' # 统计Keyword次数
# seq + grep
seq 10 | grep 5 -A 3 # 上匹配
seq 10 | grep 5 -B 3 # 下匹配
seq 10 | grep 5 -C 3 # 上下匹配,平时用这个就妥了
Grep的参数:
--color=auto # 显示颜色;
-i, --ignore-case # 忽略字符大小写;
-o, --only-matching # 只显示匹配到的部分;
-n, --line-number # 显示行号;
-v, --invert-match # 反向显示,显示未匹配到的行;
-E, --extended-regexp # 支持使用扩展的正则表达式;
-q, --quiet, --silent # 静默模式,即不输出任何信息;
-w, --word-regexp # 整行匹配整个单词;
-c, --count # 统计匹配到的行数; print a count of matching lines;
-B, --before-context=NUM:print NUM lines of leading context # 后#行
-A, --after-context=NUM:print NUM lines of trailing context # 前#行
-C, --context=NUM:print NUM lines of output context # 前后各#行
文本分析 - awk
awk基本命令:
# 基本使用
awk '{print $4,$6}' f.txt
awk '{print NR,$0}' f.txt cpf.txt
awk '{print FNR,$0}' f.txt cpf.txt
awk '{print FNR,FILENAME,$0}' f.txt cpf.txt
awk '{print FILENAME,"NR="NR,"FNR="FNR,"$"NF"="$NF}' f.txt cpf.txt
echo 1:2:3:4 | awk -F: '{print $1,$2,$3,$4}'
# 匹配
awk '/ldb/ {print}' f.txt # 匹配ldb
awk '!/ldb/ {print}' f.txt # 不匹配ldb
awk '/ldb/ && /LISTEN/ {print}' f.txt # 匹配ldb和LISTEN
awk '$5 ~ /ldb/ {print}' f.txt # 第五列匹配ldb
内建变量
NR: NR表示从awk开始执行后,按照记录分隔符读取的数据次数,默认的记录分隔符为换行符,因此默认的就是读取的数据行数,NR可以理解为Number of Record的缩写
FNR: 在awk处理多个输入文件的时候,在处理完第一个文件后,NR并不会从1开始,而是继续累加,因此就出现了FNR,每当处理一个新文件的时候,FNR就从1开始计数,FNR可以理解为File Number of Record
NF: NF表示目前的记录被分割的字段的数目,NF可以理解为Number of Field
更多请参考:Linux awk 命令
# 文本处理 - sed
sed常用:
# 文本打印
sed -n '3p' xxx.log # 只打印第三行
sed -n '$p' xxx.log # 只打印最后一行
sed -n '3,9p' xxx.log # 只查看文件的第3行到第9行
sed -n -e '3,9p' -e '=' xxx.log # 打印3-9行,并显示行号
sed -n '/root/p' xxx.log # 显示包含root的行
sed -n '/hhh/,/omc/p' xxx.log # 显示包含"hhh"的行到包含"omc"的行之间的行
# 文本替换
sed -i 's/root/world/g' xxx.log # 用world 替换xxx.log文件中的root; s==search 查找并替换, g==global 全部替换, -i: implace
# 文本插入
sed '1,4i hahaha' xxx.log # 在文件第一行和第四行的每行下面添加hahaha
sed -e '1i happy' -e '$a new year' xxx.log #【界面显示】在文件第一行添加happy,文件结尾添加new year
sed -i -e '1i happy' -e '$a new year' xxx.log #【真实写入文件】在文件第一行添加happy,文件结尾添加new year
# 文本删除
sed '3,9d' xxx.log # 删除第3到第9行,只是不显示而已
sed '/hhh/,/omc/d' xxx.log # 删除包含"hhh"的行到包含"omc"的行之间的行
sed '/omc/,10d' xxx.log # 删除包含"omc"的行到第十行的内容
# 与find结合
find . -name "*.txt" |xargs sed -i 's/hhhh/\hHHh/g'
find . -name "*.txt" |xargs sed -i 's#hhhh#hHHh#g'
find . -name "*.txt" -exec sed -i 's/hhhh/\hHHh/g' {} \;
find . -name "*.txt" |xargs cat
更多请参考:Linux sed 命令 或者 Linux sed命令详解
文件操作
文件监听 - tail
最常用的tail -f filename
# 基本使用
tail -f xxx.log # 循环监听文件
tail -300f xxx.log # 倒数300行并追踪文件
tail +20 xxx.log # 从第 20 行至文件末尾显示文件内容
# tailf使用
tailf xxx.log # 等同于tail -f -n 10 打印最后10行,然后追踪文件
tail -f 与tail F 与tailf三者区别
tail -f 等于--follow=descriptor,根据文件描述进行追踪,当文件改名或删除后,停止追踪
tail -F 等于 --follow=name ==retry,根据文件名字进行追踪,当文件改名或删除后,保持重试,当有新的文件和他同名时,继续追踪
tailf 等于tail -f -n 10(tail -f或-F默认也是打印最后10行,然后追踪文件),与tail -f不同的是,如果文件不增长,它不会去访问磁盘文件,所以tailf特别适合那些便携机上跟踪日志文件,因为它减少了磁盘访问,可以省电
tail的参数
-f 循环读取
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
文件查找 - find
sudo -u admin find /home/admin /tmp /usr -name \*.log(多个目录去找)
find . -iname \*.txt(大小写都匹配)
find . -type d(当前目录下的所有子目录)
find /usr -type l(当前目录下所有的符号链接)
find /usr -type l -name "z*" -ls(符号链接的详细信息 eg:inode,目录)
find /home/admin -size +250000k(超过250000k的文件,当然+改成-就是小于了)
find /home/admin f -perm 777 -exec ls -l {} \; (按照权限查询文件)
find /home/admin -atime -1 1天内访问过的文件
find /home/admin -ctime -1 1天内状态改变过的文件
find /home/admin -mtime -1 1天内修改过的文件
find /home/admin -amin -1 1分钟内访问过的文件
find /home/admin -cmin -1 1分钟内状态改变过的文件
find /home/admin -mmin -1 1分钟内修改过的文件
pgm
批量查询vm-shopbase满足条件的日志
pgm -A -f vm-shopbase 'cat /home/admin/shopbase/logs/shopbase.log.2017-01-17|grep 2069861630'
查看网络和进程
查看所有网络接口的属性
[root@pdai.tech ~]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.31.165.194 netmask 255.255.240.0 broadcast 172.31.175.255
ether 00:16:3e:08:c1:ea txqueuelen 1000 (Ethernet)
RX packets 21213152 bytes 2812084823 (2.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25264438 bytes 46566724676 (43.3 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
loop txqueuelen 1000 (Local Loopback)
RX packets 502 bytes 86350 (84.3 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 502 bytes 86350 (84.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
查看防火墙设置
[root@pdai.tech ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
查看路由表
[root@pdai.tech ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.31.175.253 0.0.0.0 UG 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
172.31.160.0 0.0.0.0 255.255.240.0 U 0 0 0 eth0
netstat
查看所有监听端口
[root@pdai.tech ~]# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 1249/Java
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1547/sshd
tcp6 0 0 :::3306 :::* LISTEN 1894/mysqld
查看所有已经建立的连接
[root@pdai.tech ~]# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 1249/Java
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 970/nginx: master p
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1547/sshd
tcp 0 0 172.31.165.194:53874 100.100.30.25:80 ESTABLISHED 18041/AliYunDun
tcp 0 64 172.31.165.194:22 xxx.194.1.200:2649 ESTABLISHED 32516/sshd: root@pt
tcp6 0 0 :::3306 :::* LISTEN 1894/m
查看当前连接
[root@pdai.tech ~]# netstat -nat|awk '{print $6}'|sort|uniq -c|sort -rn
5 LISTEN
2 ESTABLISHED
1 Foreign
1 established)
查看网络统计信息进程
[root@pdai.tech ~]# netstat -s
Ip:
21017132 total packets received
0 forwarded
0 incoming packets discarded
21017131 incoming packets delivered
25114367 requests sent out
324 dropped because of missing route
Icmp:
18088 ICMP messages received
692 input ICMP message failed.
ICMP input histogram:
destination unreachable: 4241
timeout in transit: 19
echo requests: 13791
echo replies: 4
timestamp request: 33
13825 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 1
echo replies: 13791
timestamp replies: 33
IcmpMsg:
InType0: 4
InType3: 4241
InType8: 13791
InType11: 19
InType13: 33
OutType0: 13791
OutType3: 1
OutType14: 33
Tcp:
12210 active connections openings
208820 passive connection openings
54198 failed connection attempts
9805 connection resets received
...
netstat 请参考这篇文章: Linux netstat命令详解
查看所有进程
[root@pdai.tech ~]# ps -ef | grep Java
root 1249 1 0 Nov04 ? 00:58:05 Java -jar /opt/tech_doc/bin/tech_arch-0.0.1-RELEASE.jar --server.port=9999
root 32718 32518 0 08:36 pts/0 00:00:00 grep --color=auto Java
查看磁盘和内存相关
查看内存使用 - free -m
[root@pdai.tech ~]# free -m
total used free shared buff/cache available
Mem: 1837 196 824 0 816 1469
Swap: 2047 255 1792
查看各分区使用情况
[root@pdai.tech ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 909M 0 909M 0% /dev
tmpfs 919M 0 919M 0% /dev/shm
tmpfs 919M 452K 919M 1% /run
tmpfs 919M 0 919M 0% /sys/fs/cgroup
/dev/vda1 40G 15G 23G 40% /
tmpfs 184M 0 184M 0% /run/user/0
查看指定目录的大小
[root@pdai.tech ~]# du -sh
803M
查看内存总量
[root@pdai.tech ~]# grep MemTotal /proc/meminfo
MemTotal: 1882088 kB
查看空闲内存量
[root@pdai.tech ~]# grep MemFree /proc/meminfo
MemFree: 74120 kB
查看系统负载磁盘和分区
[root@pdai.tech ~]# grep MemFree /proc/meminfo
MemFree: 74120 kB
查看系统负载磁盘和分区
[root@pdai.tech ~]# cat /proc/loadavg
0.01 0.04 0.05 2/174 32751
查看挂接的分区状态
[root@pdai.tech ~]# mount | column -t
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,size=930732k,nr_inodes=232683,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
...
查看所有分区
[root@pdai.tech ~]# fdisk -l
Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0x0008d73a
Device Boot Start End Blocks Id System
/dev/vda1 * 2048 83884031 41940992 83 Linux
查看所有交换分区
[root@pdai.tech ~]# swapon -s
Filename Type Size Used Priority
/etc/swap file 2097148 261756 -2
查看硬盘大小
[root@pdai.tech ~]# fdisk -l |grep Disk
Disk /dev/vda: 42.9 GB, 42949672960 bytes, 83886080 sectors
Disk label type: dos
Disk identifier: 0x0008d73a
查看用户和组相关
查看活动用户
[root@pdai.tech ~]# w
08:47:20 up 45 days, 18:54, 1 user, load average: 0.01, 0.03, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 xxx.194.1.200 08:32 0.00s 0.32s 0.32s -bash
查看指定用户信息
[root@pdai.tech ~]# id
uid=0(root) gid=0(root) groups=0(root)
查看用户登录日志
[root@pdai.tech ~]# last
root pts/0 xxx.194.1.200 Fri Dec 20 08:32 still logged in
root pts/0 xxx.73.164.60 Thu Dec 19 21:47 - 00:28 (02:41)
root pts/0 xxx.106.236.255 Thu Dec 19 16:00 - 18:24 (02:23)
root pts/1 xxx.194.3.173 Tue Dec 17 13:35 - 17:37 (04:01)
root pts/0 xxx.194.3.173 Tue Dec 17 13:35 - 17:37 (04:02)
...
查看系统所有用户
[root@pdai.tech ~]# cut -d: -f1 /etc/passwd
root
bin
daemon
adm
...
查看系统所有组
cut -d: -f1 /etc/group
查看服务,模块和包相关
# 查看当前用户的计划任务服务
crontab -l
# 列出所有系统服务
chkconfig –list
# 列出所有启动的系统服务程序
chkconfig –list | grep on
# 查看所有安装的软件包
rpm -qa
# 列出加载的内核模块
lsmod
查看系统,设备,环境信息
# 常用
env # 查看环境变量资源
uptime # 查看系统运行时间、用户数、负载
lsusb -tv # 列出所有USB设备的linux系统信息命令
lspci -tv # 列出所有PCI设备
head -n 1 /etc/issue # 查看操作系统版本,是数字1不是字母L
uname -a # 查看内核/操作系统/CPU信息的linux系统信息命令
# /proc/
cat /proc/cpuinfo # 查看CPU相关参数的linux系统命令
cat /proc/partitions # 查看linux硬盘和分区信息的系统信息命令
cat /proc/meminfo # 查看linux系统内存信息的linux系统命令
cat /proc/version # 查看版本,类似uname -r
cat /proc/ioports # 查看设备io端口
cat /proc/interrupts # 查看中断
cat /proc/pci # 查看pci设备的信息
cat /proc/swaps # 查看所有swap分区的信息
cat /proc/cpuinfo |grep "model name" && cat /proc/cpuinfo |grep "physical id"
tsar
tsar是淘宝开源的的采集工具很好用, 将历史收集到的数据持久化在磁盘上,所以我们快速来查询历史的系统数据当然实时的应用情况也是可以查询的啦大部分机器上都有安装
tsar ## 可以查看最近一天的各项指标
tsar --live ## 可以查看实时指标,默认五秒一刷
tsar -d 20161218 ## 指定查看某天的数据,貌似最多只能看四个月的数据
tsar --mem
tsar --load
tsar --cpu ## 当然这个也可以和-d参数配合来查询某天的单个指标的情况
具体可以看这篇文章:linux 淘宝开源监控工具tsa
# Java内存问题排查
内存泄漏(memory leak):在Java中如果不再使用一个对象,但是该对象依然在GC ROOT的引用链上,这个对象就不会被垃圾回收器回收,这种情况就称之为内存泄漏。
- 内存泄漏绝大多数情况都是由堆内存泄漏引起的。
内存溢出:指的是内存的使用量超过了Java虚拟机可以分配的上限,最终产生了内存溢出OutOfMemory的错误。
解决内存溢出的思路:
- 发现问题:通过监控工具尽可能尽早地发现内存慢慢变大的现象。
- 诊断原因:通过分析内存快照或者在线分析方法调用过程,诊断问题产生的根源,定位到出现问题的源代码。
- 修复问题:尝试重现问题,如借助jmeter什么鬼之类的。之后修复,如源代码中的bug问题、技术方案不合理、业务设计不合理等等。
- 验证测试:在测试环境验证问题是否已经解决,最后发布上线。
内存溢出产生的原因:
- 持续的内存泄漏:内存泄漏持续发生,不可被回收同时不再使用的内存越来越多,就像滚雪球雪球越滚越大,最终内存被消耗完无法分配更多的内存取使用,导致内存溢出。
这种原因一般就是代码中的内存泄漏,所以一般在测试阶段就会被测试出来,如下示例:
- 不正确的
eauals()和hashcode():定义新类时没有重写正确的equals()和hashCode()方法。在使用HashMap的场景下,如果使用这个类对象作为key,HashMap在判断key是否已经存在时会使用这些方法,如果重写方式不正确,会导致相同的数据被保存多份。
此种情况的解决方式:定义新实体类时记得重写这两个方法,且重写时使用“唯一标识”去区分不同对象,以及在使用HashMap时key使用实体的“唯一标识”。
- 非静态内部类和匿名内部类的错误使用:非静态的内部类默认会持有外部类,尽管代码上不再使用外部类,所以如果有地方引用了这个非静态内部类,会导致外部类也被引用,垃圾回收时无法回收这个外部类。另外就是匿名内部类对象如果在非静态方法中被创建,会持有调用者对象,垃圾回收时无法回收调用者。
此种情况的解决方式:使用静态内部类和静态方法即可。
- ThreadLocal的错误使用:由于线程池中的线程不被回收导致的ThreadLocal内存泄漏。
如果仅仅使用手动创建的线程,就算没有调用ThreadLocal的remove方法清理数据,也不会产生内存泄漏。因为当线程被回收时,ThreadLocal也同样被回收。但是如果使用线程池就不一定了。
此种情况的解决方式:线程方法执行完,记得调用ThreadLocal中的remove方法清理对象。
- 静态变量的错误使用(很常见哦):大量的数据在静态变量中被引用,但不再使用,就成为了内存泄漏。
如果大量的数据在静态变量中被长期引用,数据就不会被释放,如果这些数据不再使用,就成为了内存泄漏。
此种情况的解决方式:
一是:尽量减少将对象长时间的保存在静态变量中,如果不再使用,必须将对象删除(比如在集合中)或者将静态变量设置为null。
二是:使用单例模式时,尽量使用懒加载,而不是立即加载。
三是:Spring的Bean中不要长期存放大对象,如果是缓存用于提升性能,尽量设置过期时间定期失效。
- 资源没有正常关闭:由于资源没有调用
close()方法正常关闭,”可能“导致内存泄漏。
连接和流这些资源会占用内存,如果使用完之后没有关闭,这部分内存"不一定"会出现内存泄漏,但是会导致close方法不被执行。
不一定的原因:如下列代码
public static void lead() throws SQLException { // 此方法执行完
Startement stmt = null;
Connection conn = DriverManager.getConnection(DB_URL, USER, PASS);
// 则Connection不在GC Roots引用链上,就会被回收,从而conn关联的Startement、RestultSet这些对象也会被回收,从而不会造成内存泄漏
stmt = conn.createStatement();
String sql = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx";
RestultSet rs = stmt.executeQuery(sql);
while(rs.next()){
// ...............
}
// 最终没有关闭流管道
}
此种情况的解决方式:在finally块中关闭不再使用的资源。另外就是从 Java 7 开始,可以使用try-with-resources语法可以用于自动关闭资源。

- 并发请求问题:用户通过发送请求向Java应用获取数据,正常情况下Java应用将数据返回之后,这部分数据就可以在内存中被释放掉。但是由于用户的并发请求量有可能很大,同时处理数据的时间很长,导致大量的数据存在于内存中,最终超过了内存的上限,导致内存溢出。
发现问题
Java 调试入门工具
声明:此节内容整理自@pdai:调试排错 - Java 问题排查之工具单。
jps:查看当前进程
jps是JDK提供的一个查看当前Java进程的小工具, 可以看做是Java Virtual Machine Process Status Tool的缩写
jps常用命令
jps # 显示进程的ID 和 类的名称
jps –l # 输出完全的包名,应用主类名,jar的完全路径名
jps –v # 输出JVM参数
jps –q # 显示Java进程号
jps -m # main 方法
jps -l xxx.xxx.xx.xx # 远程查看
jps参数:
-q # 仅输出VM标识符,不包括Classname,jar name,arguments in main method
-m # 输出main method的参数
-l # 输出完全的包名,应用主类名,jar的完全路径名
-v # 输出JVM参数
-V # 输出通过flag文件传递到JVM中的参数(.hotspotrc文件或-XX:Flags=所指定的文件
-Joption # 传递参数到vm,例如:-J-Xms512m
jps原理
Java程序在启动以后,会在Java.io.tmpdir指定的目录下,就是临时文件夹里,生成一个类似于hsperfdata_User的文件夹,这个文件夹里(在Linux中为/tmp/hsperfdata_{userName}/),有几个文件,名字就是Java进程的pid,因此列出当前运行的Java进程,只是把这个目录里的文件名列一下而已。至于系统的参数什么,就可以解析这几个文件获得
更多请参考 jps - Java Virtual Machine Process Status Tool
jstack:线程的栈信息
jstack是JDK自带的线程堆栈分析工具,使用该命令可以查看或导出 Java 应用程序中线程堆栈信息
jstack常用命令:
# 基本
jstack 2815
# Java和native c/c++框架的所有栈信息
jstack -m 2815
# 额外的锁信息列表,查看是否死锁
jstack -l 2815
jstack参数:
-l # 长列表. 打印关于锁的附加信息,例如属于Java.util.concurrent 的 ownable synchronizers列表.
-F # 当’jstack [-l] pid’没有相应的时候强制打印栈信息
-m # 打印Java和native c/c++框架的所有栈信息.
-h | -help # 打印帮助信息
jinfo:查看参数信息
jinfo 是 JDK 自带的命令,可以用来查看正在运行的 Java 应用程序的扩展参数,包括Java System属性和JVM命令行参数;也可以动态的修改正在运行的 JVM 一些参数。当系统崩溃时,jinfo可以从core文件里面知道崩溃的Java应用程序的配置信息
jinfo常用命令:
# 输出当前 JVM 进程的全部参数和系统属性
jinfo 2815
# 输出所有的参数
jinfo -flags 2815
# 查看指定的 JVM 参数的值
jinfo -flag PrintGC 2815
# 开启/关闭指定的JVM参数
jinfo -flag +PrintGC 2815
# 设置flag的参数
jinfo -flag name=value 2815
# 输出当前 JVM 进行的全部的系统属性
jinfo -sysprops 2815
jinfo参数:
no option # 输出全部的参数和系统属性
-flag name # 输出对应名称的参数
-flag [+|-]name # 开启或者关闭对应名称的参数
-flag name=value # 设定对应名称的参数
-flags # 输出全部的参数
-sysprops # 输出系统属性
更多请参考:JVM 性能调优工具之 jinfo
jmap:生成dump文件 和 查看堆情况
JDK自带的jmap是一个多功能的命令。它可以生成 Java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
- PS:dump文件是什么去这里:https://www.cnblogs.com/toSeeMyDream/p/7151635.html
两个用途
# 查看堆的情况
jmap -heap 2815
# dump
jmap -dump:live,format=b,file=/tmp/heap2.bin 2815 # 只保留存活对象(GC Roots引用链上的对象)
jmap -dump:format=b,file=/tmp/heap3.bin 2815 # 全部对象(即在GC Roots引用链上和不在的都保存)
# 使用情况:有时显示内存很高,但使用上面一种生成存活对象的快照时内存变很小了
# 原因是生成dump时会进行Full GC,所以不利于分析,从而采用下面这种,让快照包含全部对象。
# 查看堆的占用
jmap -histo 2815 | head -10
jmap参数:
no option # 查看进程的内存映像信息,类似 Solaris pmap 命令
heap # 显示Java堆详细信息
histo[:live] # 显示堆中对象的统计信息
clstats # 打印类加载器信息
finalizerinfo # 显示在F-Queue队列等待Finalizer线程执行finalizer方法的对象
dump:<dump-options> # 生成堆转储快照
F # 当-dump没有响应时,使用-dump或者-histo参数. 在这个模式下,live子参数无效.
help # 打印帮助信息
J<flag> # 指定传递给运行jmap的JVM的参数
更多请参考:
# jstat:总结垃圾回收统计
缺点:无法精确到GC产生的时间,只能用于判断GC是否存在问题。
jstat参数众多,但是使用一个就够了。
# 命令格式:jstat -gcutil pid interval(间隔,单位ms)
jstat -gcutil 2815 1000
C代表Capacity容量,U代表Used使用量
S – 幸存者区,E – 伊甸园区,O – 老年代,M – 元空间
YGC、YGT:年轻代GC次数和GC耗时(单位:秒)
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
更多请参考:Java的jstat命令使用详解
jdb:预发debug
jdb可以用来预发debug,假设你预发的Java_home是/opt/Java/,远程调试端口是8000,那么
jdb -attach 8000
出现以上代表jdb启动成功。后续可以进行设置断点进行调试。
具体参数可见oracle官方说明jdb - The Java Debugger
Linux:Top命令
top除了看一些基本信息之外,剩下的就是配合来查询vm的各种问题了。
缺点:只能查看最基础的进程信息,无法查看到每个部分的内存占用(堆、方法区、堆外)
top命令是Linux下用来查看系统信息的一个命令,它提供给我们去实时地去查看系统的资源,比如执行时的进程、线程和系统参数等信息。
关于下列两个概念的说明:
- 常驻内存:当前进程总的使用了多少内存。
- PS:常驻内存包含了“共享内存”,所以当前进程真正使用的内存是:常驻内存 - 共享内存。
- 共享内存:当前进程第三方依赖需要的内存。只加载一次,其他地方就可以用了,故而称为“共享”。
# top -H -p pid
top - 08:37:51 up 45 days, 18:45, 1 user, load average: 0.01, 0.03, 0.05
Threads: 28 total, 0 running, 28 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.7 us, 0.7 sy, 0.0 ni, 98.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1882088 total(堆的总内存), 74608 free(空闲内存,若此值极小则说明本服务器的程序有问题), 202228 used(已使用内存), 1605252 buff/cache(缓存) # 关注点
KiB Swap: 2097148 total, 1835392 free, 261756 used. 1502036 avail Mem
# %CPU 当前进程对CPU的使用率 若此值长期保持很高,则需要关注程序请求量是否过大,或出现死循环之类的
# %MEM 当前进程占总内存的比率 若上面的 free值很小,而此值很高,则可以确定系统内存不足就是当前进程所造成的
# TIME+ 当前进程自启动以来所消耗的CPU累计时间
# COMMAND 启动命令
PID USER PR NI VIRT(虚拟内存) RES(常驻内存) SHR(共享内存) S %CPU %MEM TIME+ COMMAND
1347 root 20 0 2553808 113752 1024 S 0.3 6.0 48:46.74 VM Periodic Tas
1249 root 20 0 2553808 113752 1024 S 0.0 6.0 0:00.00 Java
1289 root 20 0 2553808 113752 1024 S 0.0 6.0 0:03.74 Java
...
JConsole:本地+远程监控
Jconsole (Java Monitoring and Management Console),JDK自带的基于JMX的可视化监视、管理工具 官方文档可以参考这里
路径:JDK\bin\jconsole.exe
本地连接 或 远程连接:
注:远程连接在“测试环境”用就可以了,别在线上环境用。
VisualVM:本地+远程监控
VisualVM 是一款免费的,集成了多个 JDK 命令行工具的可视化工具,整合了命令行 JDK 工具和轻量级分析功能,它能为您提供强大的分析能力,对 Java 应用程序做性能分析和调优这些功能包括生成和分析海量数据、跟踪内存泄漏、监控垃圾回收器、执行内存和 CPU 分析,同时它还支持在 MBeans 上进行浏览和操作。
注:这款软件在Oracle JDK 6~8 中发布(路径:JDK\bin\jvisualvm.exe),但是在 Oracle JDK 9 之后不在JDK安装目录下需要单独下载。下载地址:https://visualvm.github.io/
优点:支持IDEA插件,开发过程中也可以使用。
缺点:对大量集群化部署的Java进程需要手动进行管理。
本地连接:JDK\bin\jvisualvm.exe的方式,这种是中文版
IDEA插件的方式:
以下两种方式均可启动VisualVM
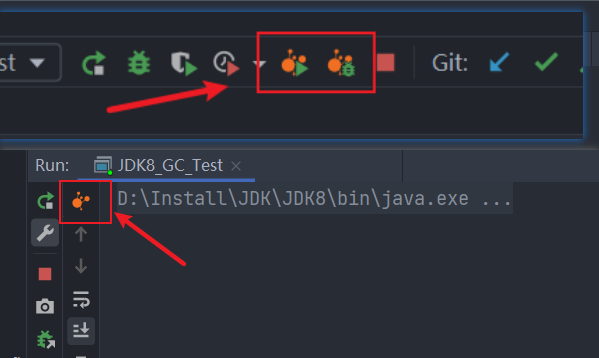
远程连接:
注:只可用于“测试环境”,不可用于“生产环境”。因为操作VisualVM中提供的功能时会停掉线程,从而影响用户。
- 服务器中开启JMX远程连接
java -jar \
-Djava.rmi.server.hostname=xxxxxxxx \ # 配置主机名 就是服务器ip
-Dcom.sun.management.jmxremote \ # 开启JMX远程连接
-Dcom.sun.management.jmxremote.port=xxxx \ # 设置连接的端口号
-Dcom.sun.management.jmxremote.ssl=false \ # 关闭ssl连接
-Dcom.sun.management.jmxremote.authenticate=false \ # 关闭身份验证
xxxxx.jar # 要启动的服务jar包
- 使用VisualVM建立远程连接
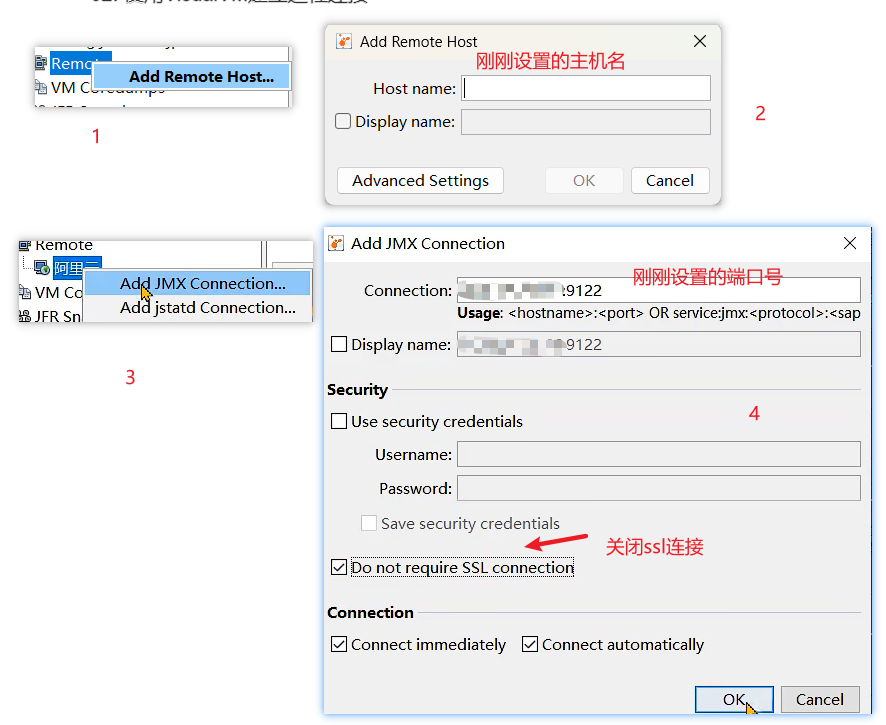
Arthas Tunnel
官网地址:https://arthas.aliyun.com/doc/tunnel.html
优点:
- 功能强大,不止于监控基础的信息,还能监控单个方法的执行耗时等细节内容。
- 支持应用的集群管理.
大概流程如下:
大概操作流程如下:
- 添加依赖(目前仅支持Spring Boot2.x版本),在配置文件中添加tunnel服务端的地址,便于tunnel去监控所有的程序。
<dependency>
<groupId>com.taobao.arthas</groupId>
<artifactId>arthas-spring-boot-starter</artifactId>
<version>3.7.1</version>
</dependency>
YAML配置:
arthas:
# tunnel部署的地址
tunnel-server: ws://localhost:7777/ws
# tunnel显示的应用名称:注册到tunnel上的每个服务都要有个名称
app-name: ${spring.application.name}
# arthas http访问的端口 和 远程连接的端口 这两个端口不可重复
http-port: 8888
telnet-port: 9999
- 将tunnel服务端程序部署在某台服务器上并启动
注:需要去官网下载 tunnel的jar包丢在服务器目录中,
# 启动命令
nohup java -jar \ # nohup 即no hang up(不挂起),后台不挂断
-Darthas.detail.pages=true \ # 打开可视化页面 注:这个页面占用的端口是80
arthas-tunnel-server-下载的某版本-fatjar.jar $ # 别忘了有个 $ 即:将这个任务放到后台执行
页面网址:部署tunnel的ip:8080/apps.html
- 启动Java程序,然后再上一步的页面中就可以看到对应的应用名称了。打开tunnel的服务端页面,查看所有的进程列表,并选择进程(应用名称)就可进入arthas进行arthas的操作。
排错:在 arthas-tunnel-server-下载的某版本-fatjar.jar 所在的目录中有一个nohup.out文件,打开即可排错,如:有些服务没注册上来之类的。
Eclipse Memory Analyzer (MAT)
这玩意儿可以说在开发中都会接触到,所以需要好好了解一下。
MAT 是一种快速且功能丰富的 Java 堆分析器,可帮助你发现内存泄漏并减少内存消耗。MAT在的堆内存分析问题使用极为广泛,需要重点掌握。
提示:启动时可能会提示某某版本的JDK不支持,需要某某版本或以上,那安装对应的JDK版本,然后将其bin目录路径放到path配置中即可,但:建议将此版本配置移到最上面或比其他版本的JDK更靠上。
先来了解三个东西:也是MAT的原理
- 支配树(Dominator Tree):MAT提供了支配树的对象图。支配树展示的是对象实例间的支配关系。
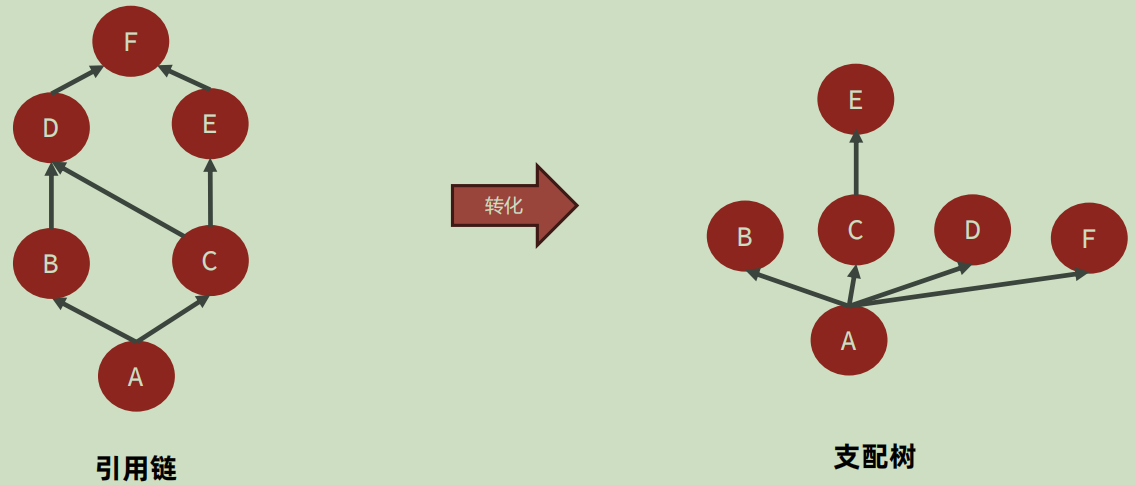
如上图所示:
- 对于B来说:B引用了A,而B并没有再引用其他的(即:到B只有一条路,A ->B),所以就是说:A支配B(如右图所示)。
- 而C是同理,对于D和F来说(用D来举例):D引用了B,而B引用了A;同时D引用了C,而C引用了A(所以是两条线),但归根到底就是A支配了D。
- 其他E、F也是和D是同理分析的。
- 深堆(Retained Heap)和浅堆(Shallow Heap)
浅堆(Shallow Heap):支配树中对象本身占用的空间。
深堆(Retained Heap):支配树中对象的子树就是所有被该对象支配的内容,这些内容组成了对象的深堆(Retained Heap),也称之为保留集( Retained Set ) 。深堆的大小表示该对象如果可以被回收,能释放多大的内存空间。
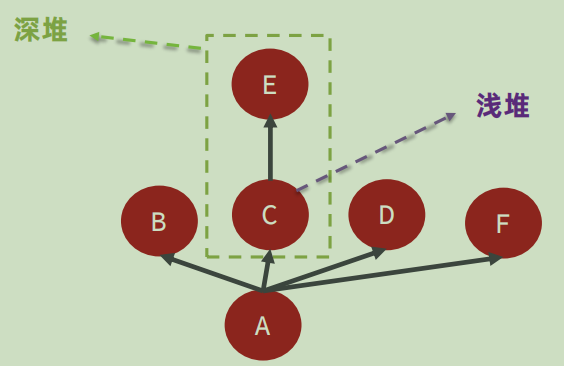
如上图所示:在这个支配树中,对于C这个对象来说
- 这个对象本身占用的空间就是"浅堆"。
- C这个对象 以及 它的子树 所组成的空间大小就是深堆,若C对象被回收,那能够回收的空间大小就是:C对象本身+其子树E对象 这二者的总空间大小。
MAT内存泄漏检测的原理:MAT就是根据支配树,从叶子节点向根节点遍历,如果发现深堆的大小超过整个堆内存的一定比例阈值,就会将其标记成内存泄漏的“嫌疑对象”。
使用MAT发现问题
- 当堆内存溢出时,可以在堆内存溢出时将整个堆内存保存下来,生成内存快照(Heap Profile )文件。
使用内存快照的目的:找出是程序哪里引发的问题、定位到问题出现的地方。
生成内存快照的Java虚拟机参数:
-XX:+HeapDumpOnOutOfMemoryError 发生OutOfMemoryError错误时,自动生成hprof内存快照文件
-XX:HeapDumpPath=<path> 指定hprof文件的输出路径
- 使用MAT打开hprof文件(file -> open head dump),并选择内存泄漏检测功能(Leak Suspects Report 即内存泄漏检测报告),MAT会自行根据内存快照中保存的数据分析内存泄漏的根源。
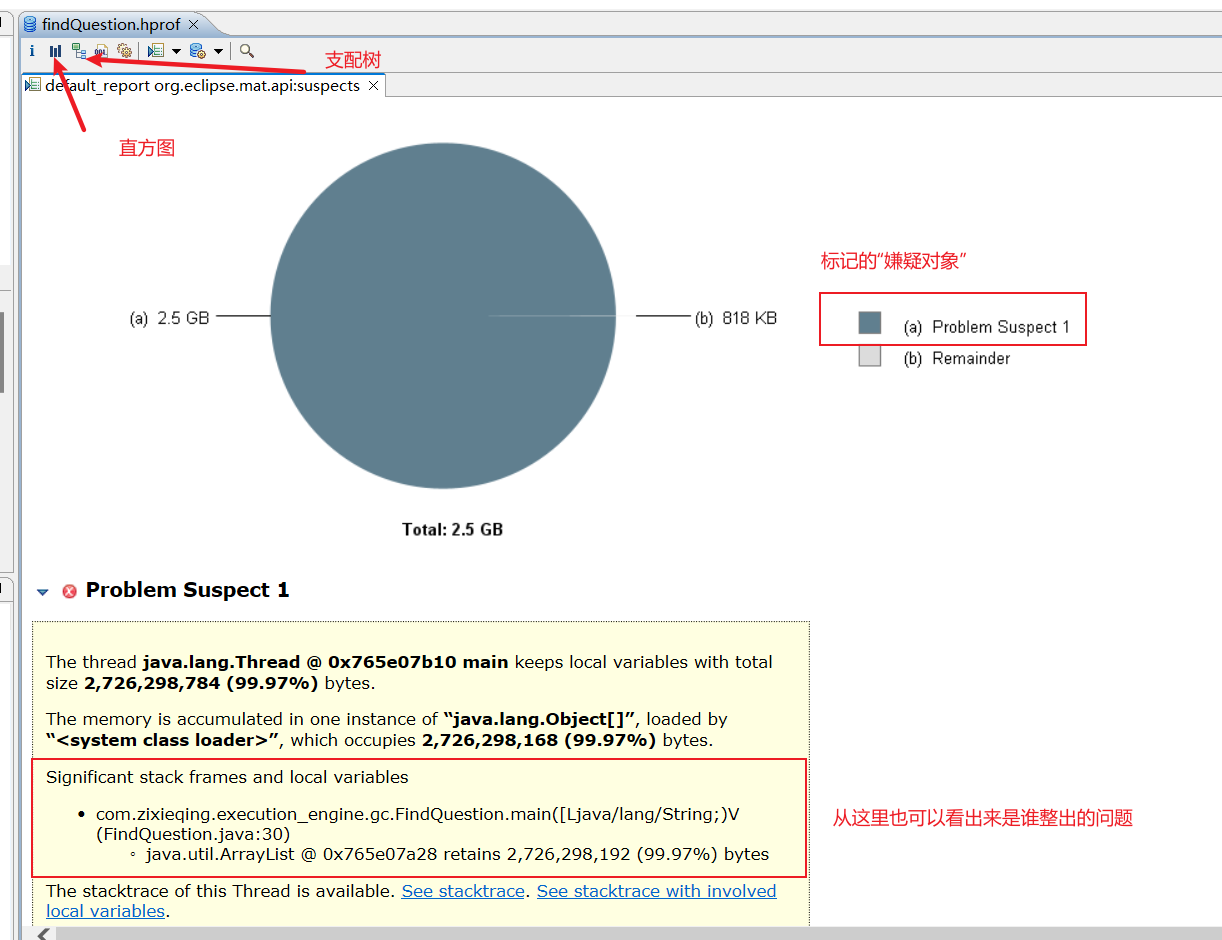
服务器中导出运行中系统的内存快照的简单方式:场景为内存在持续增长,但未发生内存泄漏,所以上面的
-XX:+HeapDumpOnOutOfMemoryError就不能用。
- 通过JDK自带的jmap命令导出,格式为:
# 生成存活对象的内存快照(GC Roots引用链上的对象)
jmap -dump:live,format=b,file=文件路径和文件名 进程ID
# 进程ID获取方式
ps -ef|grep java
- 通过arthas的heapdump命令导出,格式为:
heapdump --live 文件路径\文件名
导出的dump文件还可以直接使用在线工具 HeapHero 打开来分析。
生成的堆内存报告很大怎么办?
机器内存范围之内的快照文件,直接使用MAT打开分析即可。
但是经常会遇到生成的快照文件很大,要下载到本地来也要很久。此时就需要下载服务器操作系统对应的MAT。下载地址:https://eclipse.dev/mat/downloads.php
然后将下载的对应版本MAT丢在某服务器中,如:Linux中。
注意:服务器中放MAT的目录记得将读写权限打开。
之后通过MAT中的脚本生成分析报告:生成的报告就是像上面那种静态页面
注意:默认MAT分析时只使用了1G的堆内存,如果快照文件超过1G,需要修改MAT目录下的MemoryAnalyzer.ini配置文件调整最大堆内存(
-Xmx值)。
# 生成之后,在快照文件路径中会有几个压缩包,对应:内存泄漏报告、系统总览图、组件,下载自己需要的压缩包到本地即可
./ParseHeapDump.sh 快照文件路径 org.eclipse.mat.api:suspects org.eclipse.mat.api:overview org.eclipse.mat.api:top_components
最后将分析报告下载到本地,打开即可(一般有一个index.html)。
涉及到SpringMVC时,怎么定位到是哪个接口导致的问题?
- 生成内存快照,使用MAT打开
- 打开支配树,使用深堆(Retained Heap)排序,找到当前执行线程,如下面的taskThread,随便打开一个即可。
- 找到当前线程正在执行的方法是哪一个。即找handleMethod,右键选择list objects(当前对象关联的对象) -> outgoing references(当前对象引用了哪些对象)
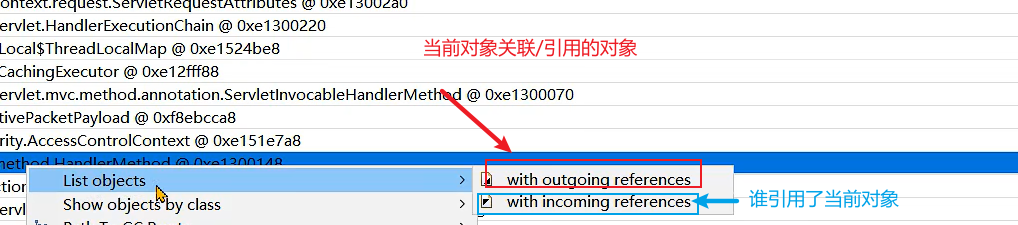
- 找到description,这里就可找到到底是哪个controller的哪个方法导致的问题。
- 然后将本地代码的Java虚拟机参数弄成和服务器一样,之后重现问题(借助压测jmeter什么鬼之类的)。
- 最后结合前面内存快照得到的原因,解决问题,验证测试即可。
在线定位问题:Arthas之stack命令 和 btrace工具
诊断和解决问题一般有两种方案:离线分析(即生成内存快照分析)、在线定位。
内存快照分析:
优点:有完整的内存快照,从而能更准确地判断出问题的原因。
缺点:
- 内存较大时,生成内存快照较慢,这个过程会影响用户的使用。
- 通过MAT分析内存快照,至少要准备 1.5 - 2倍大小的内存空间。
在线定位
优点:无需生成内存快照,整个过程对用户的影响“较小”。
缺点:
- 无法查看到详细的内存信息。
- 需要具备一定的经验。而且一般还需要借助另外的工具(本章节使用arthas的stack命令 和 btrace工具)。
Arthas的stack在线定位大致思路
- 将内存中存活对象以直方图的形式保存到文件中,这个过程会影响用户的时间,但是时间比较短暂。使用命令如下:
jmap -histo:live 进程ID > 文件路径/文件名 # 表示:将 > 符号左边的内容 输出到 右边这个路径中
- 查看直方图,分析内存占用最多的对象(直方图是排好序的),一般这些对象就是造成内存泄漏的原因。
- 使用arthas的 stack 命令,追踪第2步中分析的对象创建的方法被调用的调用路径,找到对象创建的根源。
使用命令如下:假设2中分析出来的对象是UserEntity
注意:别忘了把Arthas的jar包上传到服务器目录中,不然下面的命令能用个毛线。
stack com.zixieqing.jvm.entity.UserEntity -n 1 # 意思:输出1次com.zixieqing.jvm.entity.UserEntity这个类的所有方法的调用路径
通过上面的方式就可以找到是:哪个类那个方法哪一行了,然后尝试重现问题,修复问题、验证测试即可。
btrace工具
btrace是一个在Java 平台上执行的追踪工具,可以有效地用于线上运行系统的方法追踪,具有侵入性小、对性能的影响微乎其微等特点。是生产环境&预发的排查问题大杀器。项目中可以使用btrace工具,实现定制化,打印出方法被调用的栈信息等等。
使用方法:btrace 具体可以参考这里:https://github.com/btraceio/btrace
- 下载btrace工具, 官方地址:https://github.com/btraceio/btrace/releases/latest
- 编写btrace脚本,通常是一个Java文件。如下两个示例:
编写时为了有提示和提供对应注解方法且不报错,可以加入如下依赖:路径改为自己下载的本地btrace
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-agent</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:Install\btrace-v2.2.4-bin\libs\btrace-agent.jar</systemPath>
</dependency>
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-boot</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:Install\btrace-v2.2.4-bin\libs\btrace-boot.jar</systemPath>
</dependency>
<dependency>
<groupId>org.openjdk.btrace</groupId>
<artifactId>btrace-client</artifactId>
<version>${btrace.version}</version>
<scope>system</scope>
<systemPath>D:Install\btrace-v2.2.4-bin\libs\btrace-client.jar</systemPath>
</dependency>
- 查看当前谁调用了ArrayList的add方法,同时只打印当前ArrayList的size大于500的线程调用栈。编写如下Java代码
@BTrace
public class TracingAdd {
@OnMethod(clazz = "Java.util.ArrayList", method="add",
location = @Location(value = Kind.CALL, clazz = "/./", method = "/./")
)
public static void m(@ProbeClassName String probeClass, @ProbeMethodName String probeMethod,
@TargetInstance Object instance, @TargetMethodOrField String method) {
if(getInt(field("Java.util.ArrayList", "size"), instance) > 479){
println("check who ArrayList.add method:" + probeClass + "#" + probeMethod + ", method:" + method + ", size:" + getInt(field("Java.util.ArrayList", "size"), instance));
jstack();
println();
println("===========================");
println();
}
}
}
- 监控当前服务方法被调用时返回的值以及请求的参数
@BTrace
public class TaoBaoNav {
@OnMethod(clazz = "com.taobao.sellerhome.transfer.biz.impl.C2CApplyerServiceImpl", method="nav",
location = @Location(value = Kind.RETURN)
)
public static void mt(long userId, int current, int relation,
String check, String redirectUrl, @Return AnyType result) {
println("parameter# userId:" + userId + ", current:" + current + ", relation:" + relation + ", check:" + check + ", redirectUrl:" + redirectUrl + ", result:" + result);
}
}
- 将btrace工具和脚本上传到服务器,在服务器上执行如下格式的命令:
注意:需要配置环境变量BTRACE_HOME,和配置JDK是一样的。
btrace 进程ID 脚本文件名
- 观察执行结果。
上面示例看起来懵的话,直接去看这个示例:https://www.cnblogs.com/wei-zw/p/9502274.html
IDEA本地调试和远程调试
直接去这里:IDEA本地调试和远程调试
Java应用在线调试Arthas整理
参考资料:
Arthas简介
在学习Arthas之前,推荐先看后面的 @美团技术团队:Java动态调试技术原理,这样你会对它最底层技术有个了解。可以看下文中最后有个对比图:Greys(Arthas也是基于它做的二次开发)和Java-debug-tool
Arthas是什么
Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱
Arthas能解决什么问题
当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
- 这个类从哪个 jar 包加载的? 为什么会报各种类相关的 Exception?
- 我改的代码为什么没有执行到? 难道是我没 commit? 分支搞错了?
- 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
- 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
- 是否有一个全局视角来查看系统的运行状况?
- 有什么办法可以监控到JVM的实时运行状态?
Arthas支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断
Arthas资源推荐
Arthas基于哪些工具发展而来
- greys-anatomy: Arthas代码基于Greys二次开发而来
- termd: Arthas的命令行实现基于termd开发,是一款优秀的命令行程序开发框架
- crash: Arthas的文本渲染功能基于crash中的文本渲染功能开发,可以从这里看到源码
- cli: Arthas的命令行界面基于vert.x提供的cli库进行开发
- compiler Arthas里的内存编绎器代码来源
- Apache Commons Net Arthas里的Telnet Client代码来源
JavaAgent:运行在 main方法之前的拦截器,它内定的方法名叫 premain ,也就是说先执行 premain 方法然后再执行 main 方法ASM:一个通用的Java字节码操作和分析框架。它可以用于修改现有的类或直接以二进制形式动态生成类。ASM提供了一些常见的字节码转换和分析算法,可以从它们构建定制的复杂转换和代码分析工具。ASM提供了与其他Java字节码框架类似的功能,但是主要关注性能。因为它被设计和实现得尽可能小和快,所以非常适合在动态系统中使用(当然也可以以静态方式使用,例如在编译器中)
同类工具有哪些
- BTrace
- 美团 Java-debug-tool
- 去哪儿Bistoury: 一个集成了Arthas的项目
- 一个使用MVEL脚本的fork
Arthas入门
Arthas 上手前
推荐先在线使用下arthas:官方在线教程(推荐)
Arthas 安装
下载arthas-boot.jar,然后用Java -jar的方式启动:
curl -O https://alibaba.github.io/arthas/arthas-boot.jar # 也可以选择去官网下载jar然后丢到服务器中
Java -jar arthas-boot.jar
Arthas 案例展示
Dashboard:当前系统的实时数据
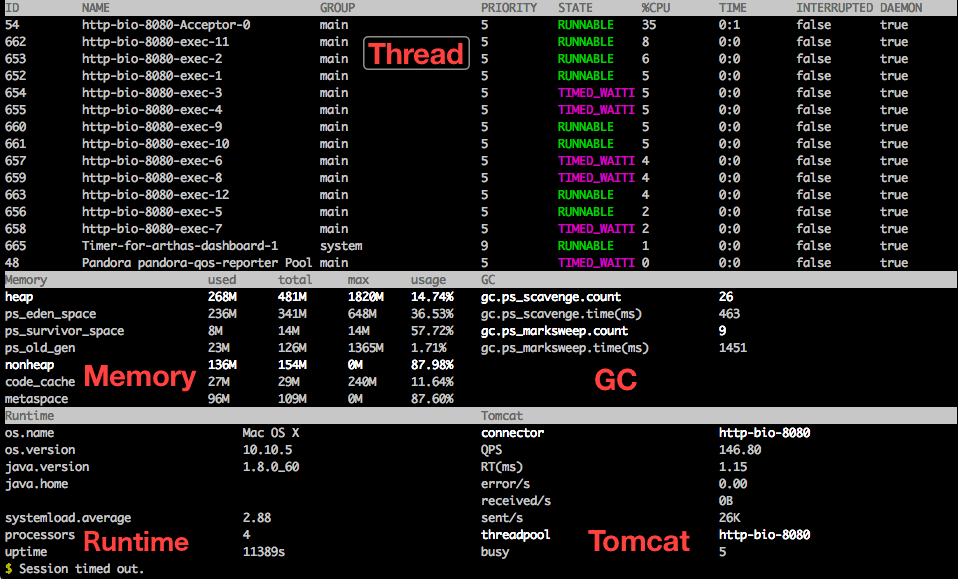
Thread:查看当前线程信息、线程的堆栈
一目了然的了解系统的状态,哪些线程比较占cpu? 他们到底在做什么?
$ thread -n 3
"as-command-execute-daemon" Id=29 cpuUsage=75% RUNNABLE
at sun.management.ThreadImpl.dumpThreads0(Native Method)
at sun.management.ThreadImpl.getThreadInfo(ThreadImpl.Java:440)
at com.taobao.arthas.core.command.monitor200.ThreadCommand$1.action(ThreadCommand.Java:58)
at com.taobao.arthas.core.command.handler.AbstractCommandHandler.execute(AbstractCommandHandler.Java:238)
at com.taobao.arthas.core.command.handler.DefaultCommandHandler.handleCommand(DefaultCommandHandler.Java:67)
at com.taobao.arthas.core.server.ArthasServer$4.run(ArthasServer.Java:276)
at Java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.Java:1145)
at Java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.Java:615)
at Java.lang.Thread.run(Thread.Java:745)
Number of locked synchronizers = 1
- Java.util.concurrent.ThreadPoolExecutor$Worker@6cd0b6f8
"as-session-expire-daemon" Id=25 cpuUsage=24% TIMED_WAITING
at Java.lang.Thread.sleep(Native Method)
at com.taobao.arthas.core.server.DefaultSessionManager$2.run(DefaultSessionManager.Java:85)
"Reference Handler" Id=2 cpuUsage=0% WAITING on Java.lang.ref.Reference$Lock@69ba0f27
at Java.lang.Object.wait(Native Method)
- waiting on Java.lang.ref.Reference$Lock@69ba0f27
at Java.lang.Object.wait(Object.Java:503)
at Java.lang.ref.Reference$ReferenceHandler.run(Reference.Java:133)
jad:反编译已加载类
对类进行反编译:
$ jad Javax.servlet.Servlet
ClassLoader:
+-Java.net.URLClassLoader@6108b2d7
+-sun.misc.Launcher$AppClassLoader@18b4aac2
+-sun.misc.Launcher$ExtClassLoader@1ddf84b8
Location:
/Users/xxx/work/test/lib/servlet-api.jar
/*
* Decompiled with CFR 0_122.
*/
package Javax.servlet;
import Java.io.IOException;
import Javax.servlet.ServletConfig;
import Javax.servlet.ServletException;
import Javax.servlet.ServletRequest;
import Javax.servlet.ServletResponse;
public interface Servlet {
public void init(ServletConfig var1) throws ServletException;
public ServletConfig getServletConfig();
public void service(ServletRequest var1, ServletResponse var2) throws ServletException, IOException;
public String getServletInfo();
public void destroy();
}
mc:Java文件生成Class文件
Memory Compiler/内存编译器,编译.Java文件生成.Class
mc /tmp/Test.Java
redefine:加载外部Class文件
加载外部的.Class文件,redefine JVM已加载的类。推荐使用 retransform 命令
redefine /tmp/Test.Class
redefine -c 327a647b /tmp/Test.Class /tmp/Test\$Inner.Class
sc:查看JVM已加载的类信息
查找JVM中已经加载的类
$ sc -d org.springframework.web.context.support.XmlWebApplicationContext
Class-info org.springframework.web.context.support.XmlWebApplicationContext
code-source /Users/xxx/work/test/WEB-INF/lib/spring-web-3.2.11.RELEASE.jar
name org.springframework.web.context.support.XmlWebApplicationContext
isInterface false
isAnnotation false
isEnum false
isAnonymousClass false
isArray false
isLocalClass false
isMemberClass false
isPrimitive false
isSynthetic false
simple-name XmlWebApplicationContext
modifier public
annotation
interfaces
super-Class +-org.springframework.web.context.support.AbstractRefreshableWebApplicationContext
+-org.springframework.context.support.AbstractRefreshableConfigApplicationContext
+-org.springframework.context.support.AbstractRefreshableApplicationContext
+-org.springframework.context.support.AbstractApplicationContext
+-org.springframework.core.io.DefaultResourceLoader
+-Java.lang.Object
Class-loader +-org.apache.catalina.loader.ParallelWebappClassLoader
+-Java.net.URLClassLoader@6108b2d7
+-sun.misc.Launcher$AppClassLoader@18b4aac2
+-sun.misc.Launcher$ExtClassLoader@1ddf84b8
ClassLoaderHash 25131501
stack
输出当前方法被调用的调用路径
$ stack test.arthas.TestStack doGet
Press Ctrl+C to abort.
Affect(Class-cnt:1 , method-cnt:1) cost in 286 ms.
ts=2018-09-18 10:11:45;thread_name=http-bio-8080-exec-10;id=d9;is_daemon=true;priority=5;TCCL=org.apache.catalina.loader.ParallelWebappClassLoader@25131501
@test.arthas.TestStack.doGet()
at Javax.servlet.http.HttpServlet.service(HttpServlet.Java:624)
at Javax.servlet.http.HttpServlet.service(HttpServlet.Java:731)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.Java:303)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.Java:208)
at org.apache.tomcat.websocket.server.WsFilter.doFilter(WsFilter.Java:52)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.Java:241)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.Java:208)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.Java:241)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.Java:208)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.Java:220)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.Java:110)
...
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.Java:169)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.Java:103)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.Java:116)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.Java:451)
at org.apache.coyote.http11.AbstractHttp11Processor.process(AbstractHttp11Processor.Java:1121)
at org.apache.coyote.AbstractProtocol$AbstractConnectionHandler.process(AbstractProtocol.Java:637)
at org.apache.tomcat.util.net.JIoEndpoint$SocketProcessor.run(JIoEndpoint.Java:316)
at Java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.Java:1142)
at Java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.Java:617)
at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.Java:61)
at Java.lang.Thread.run(Thread.Java:745)
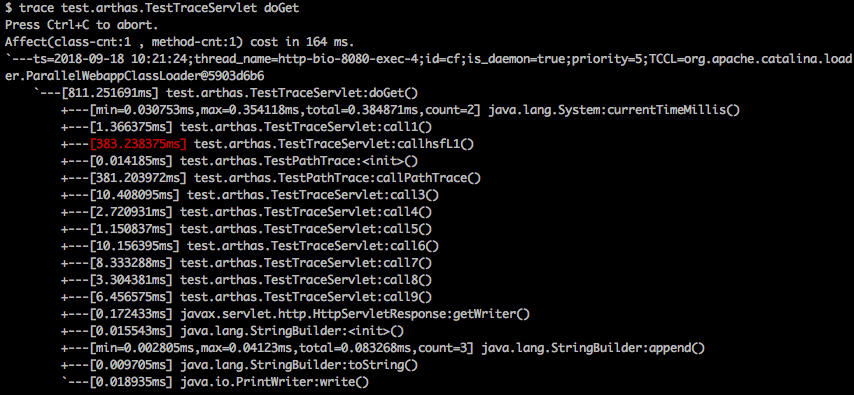
Trace:方法内部调用路径,并输出方法路径上的每个节点上耗时
观察方法执行的时候哪个子调用比较慢:
Watch:方法执行数据观测
观察方法 test.arthas.TestWatch#doGet 执行的入参,仅当方法抛出异常时才输出
$ watch test.arthas.TestWatch doGet {params[0], throwExp} -e
Press Ctrl+C to abort.
Affect(Class-cnt:1 , method-cnt:1) cost in 65 ms.
ts=2018-09-18 10:26:28;result=@ArrayList[
@RequestFacade[org.apache.catalina.connector.RequestFacade@79f922b2],
@NullPointerException[Java.lang.NullPointerException],
]
Monitor:方法执行监控
监控某个特殊方法的调用统计数据,包括总调用次数,平均rt,成功率等信息,每隔5秒输出一次
$ monitor -c 5 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello
Press Ctrl+C to abort.
Affect(Class-cnt:1 , method-cnt:1) cost in 109 ms.
timestamp Class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:32 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 0.67 0.00%
timestamp Class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:37 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 1.00 0.00%
timestamp Class method total success fail avg-rt(ms) fail-rate
----------------------------------------------------------------------------------------------------------------------------
2018-09-20 09:45:42 org.apache.dubbo.demo.provider.DemoServiceImpl sayHello 5 5 0 0.43 0.00%
tt(Time Tunnel):记录方法调用信息
记录方法调用信息,支持事后查看方法调用的参数,返回值,抛出的异常等信息,仿佛穿越时空隧道回到调用现场一般
$ tt -t org.apache.dubbo.demo.provider.DemoServiceImpl sayHello
Press Ctrl+C to abort.
Affect(Class-cnt:1 , method-cnt:1) cost in 75 ms.
INDEX TIMESTAMP COST(ms) IS-RET IS-EXP OBJECT Class METHOD
-------------------------------------------------------------------------------------------------------------------------------------
1000 2018-09-20 09:54:10 1.971195 true false 0x55965cca DemoServiceImpl sayHello
1001 2018-09-20 09:54:11 0.215685 true false 0x55965cca DemoServiceImpl sayHello
1002 2018-09-20 09:54:12 0.236303 true false 0x55965cca DemoServiceImpl sayHello
1003 2018-09-20 09:54:13 0.159598 true false 0x55965cca DemoServiceImpl sayHello
1004 2018-09-20 09:54:14 0.201982 true false 0x55965cca DemoServiceImpl sayHello
1005 2018-09-20 09:54:15 0.214205 true false 0x55965cca DemoServiceImpl sayHello
1006 2018-09-20 09:54:16 0.241863 true false 0x55965cca DemoServiceImpl sayHello
1007 2018-09-20 09:54:17 0.305747 true false 0x55965cca DemoServiceImpl sayHello
1008 2018-09-20 09:54:18 0.18468 true false 0x55965cca DemoServiceImpl sayHello
Classloader:类加载器
了解当前系统中有多少类加载器,以及每个加载器加载的类数量,帮助您判断是否有类加载器泄露
$ Classloader
name numberOfInstances loadedCountTotal
BootstrapClassLoader 1 3346
com.taobao.arthas.agent.ArthasClassloader 1 1262
Java.net.URLClassLoader 2 1033
org.apache.catalina.loader.ParallelWebappClassLoader 1 628
sun.reflect.DelegatingClassLoader 166 166
sun.misc.Launcher$AppClassLoader 1 31
com.alibaba.fastjson.util.ASMClassLoader 6 15
sun.misc.Launcher$ExtClassLoader 1 7
org.jvnet.hk2.internal.DelegatingClassLoader 2 2
sun.reflect.misc.MethodUtil 1 1
Web Console
Arthas 命令集
基础命令
- help——查看命令帮助信息
- cat——打印文件内容,和linux里的cat命令类似
- grep——匹配查找,和linux里的grep命令类似
- pwd——返回当前的工作目录,和linux命令类似
- cls——清空当前屏幕区域
- session——查看当前会话的信息
- reset——重置增强类,将被 Arthas 增强过的类全部还原,Arthas 服务端关闭时会重置所有增强过的类
- version——输出当前目标 Java 进程所加载的 Arthas 版本号
- history——打印命令历史
- quit——退出当前 Arthas 客户端,其他 Arthas 客户端不受影响
- stop / shutdown——关闭 Arthas 服务端,所有 Arthas 客户端全部退出
- keymap——Arthas快捷键列表及自定义快捷键
- profiler——使用async-profiler生成火焰图。
注意:profiler这个命令无法在Windows中运行,可以在Linux或MacOS中运行。
JVM相关
- dashboard——当前系统的实时数据面板
- thread——查看当前 JVM 的线程堆栈信息
- JVM——查看当前 JVM 的信息
- sysprop——查看和修改JVM的系统属性
- sysenv——查看JVM的环境变量
- vmoption——查看和修改JVM里诊断相关的option
- logger——查看和修改logger
- getstatic——查看类的静态属性
- ognl——执行ognl表达式
- mbean——查看 Mbean 的信息
- heapdump——dump Java heap, 类似jmap命令的heap dump功能
Class/Classloader相关
- sc——查看JVM已加载的类信息
- sm——查看已加载类的方法信息
- jad——反编译指定已加载类的源码
- mc——内存编绎器,内存编绎
.Java文件为.Class文件 - redefine——加载外部的
.Class文件,redefine到JVM里 - dump——dump 已加载类的 byte code 到特定目录
- Classloader——查看Classloader的继承树,urls,类加载信息,使用Classloader去getResource
# monitor/watch/trace相关
请注意:这些命令,都通过字节码增强技术来实现的,会在指定类的方法中插入一些切面来实现数据统计和观测,因此在线上、预发使用时,请尽量明确需要观测的类、方法以及条件,诊断结束要执行
shutdown或stop亦或将增强过的类执行reset命令
- monitor——方法执行监控
- watch——方法执行数据观测
- trace——方法内部调用路径,并输出方法路径上的每个节点上耗时
- stack——输出当前方法被调用的调用路径
- tt——方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
options
- options——查看或设置Arthas全局开关
管道
Arthas支持使用管道对上述命令的结果进行进一步的处理,如sm Java.lang.String * | grep 'index'
- grep——搜索满足条件的结果
- plaintext——将命令的结果去除ANSI颜色
- wc——按行统计输出结果
后台异步任务
当线上出现偶发的问题,比如需要watch某个条件,而这个条件一天可能才会出现一次时,异步后台任务就派上用场了,详情请参考这里
- 使用 > 将结果重写向到日志文件,使用 & 指定命令是后台运行,session断开不影响任务执行(生命周期默认为1天)
- jobs——列出所有job
- kill——强制终止任务
- fg——将暂停的任务拉到前台执行
- bg——将暂停的任务放到后台执行
# Arthas场景实战
查看最繁忙的线程,以及是否有阻塞情况发生?
场景:我想看下最繁忙的线程,以及是否有阻塞情况发生? 常规查看线程,一般我们可以通过 top 等系统命令进行查看,但是那毕竟要很多个步骤,很麻烦
thread -n 3 # 查看最繁忙的三个线程栈信息
thread # 以直观的方式展现所有的线程情况
thread -b # 找出当前阻塞其他线程的线程
确认某个类是否已被系统加载?
场景:我新写了一个类或者一个方法,我想知道新写的代码是否被部署了?
# 即可以找到需要的类全路径,如果存在的话
sc *MyServlet
# 查看这个类所有的方法
sm pdai.tech.servlet.TestMyServlet *
# 查看某个方法的信息,如果存在的话
sm pdai.tech.servlet.TestMyServlet testMethod
如何查看一个Class类的源码信息?
场景:我新修改的内容在方法内部,而上一个步骤只能看到方法,这时候可以反编译看下源码
# 直接反编译出Java 源代码,包含一此额外信息的
jad pdai.tech.servlet.TestMyServlet
重要:如何跟踪某个方法的返回值、入参.... ?
场景:我想看下我新加的方法在线运行的参数和返回值?或者是 在使用trace定位到性能较低的方法之后,使用watch命令监控该方法,获得更为详细的方法信息。
# 同时监控入参,返回值,及异常
watch pdai.tech.servlet.TestMyServlet testMethod "{params, returnObj, throwExp}" -e -x 2
# 参数
"{params, returnObj, throwExp}" 单引号、双引号都行。打印参数、返回值、抛出异常 可以任意选择,一般都只看params,从而模拟现象
‘#cost>毫秒值' 只打印耗时超过该毫秒值的调用。
-e 在 函数异常之后 观察
-x 2 打印的结果中如果有嵌套(比如对象里有属性),最多只展开2层。允许设置的最大值为4。
对该命令注意前面说的 monitor/watch/trace相关 注意事项,监控完了需要使用命令结束。
具体看 watch 命令
如何看方法调用栈的信息?
场景:我想看下某个方法的调用栈的信息?
# stack 类名 方法名
stack pdai.tech.servlet.TestMyServlet testMethod
运行此命令之后需要即时触发方法才会有响应的信息打印在控制台上。
具体请看 stack 命令
# 重要:找到最耗时的方法调用?
场景:testMethod这个方法入口响应很慢,如何找到最耗时的子调用?即方法嵌套,找出具体是哪个方法耗时。
# 执行的时候每个子调用的运行时长,可以找到最耗时的子调用
# trace 类名 方法名
trace pdai.tech.servlet.TestMyServlet testMethod
# 此命令此场景常用参数
--skipJDKMethod false 可以输出JDK核心包中的方法及耗时。
‘#cost>毫秒值’ 只打印耗时超过该毫秒值的调用。
–n 数值 最多显示该数值条数的数据。
对该命令注意前面说的 monitor/watch/trace相关 注意事项,监控完了需要使用命令结束。
运行此命令之后需要即时触发方法才会有响应的信息打印在控制台上,然后一层一层看子调用。
更多请看 trace 命令。
重要:如何临时更改代码运行?
场景:我找到了问题所在,能否线上直接修改测试,而不需要在本地改了代码后,重新打包部署,然后重启观察效果?
# 先反编译出Class源码
jad --source-only com.example.demo.arthas.user.UserController > /tmp/UserController.Java
# 然后使用外部工具编辑内容
mc /tmp/UserController.Java -d /tmp # 再编译成Class
# 最后,重新载入定义的类,就可以实时验证你的猜测了
redefine /tmp/com/example/demo/arthas/user/UserController.Class
如上,是直接更改线上代码的方式,但是一般好像是编译不成功的,所以,最好是本地ide编译成 Class文件后,再上传替换为好!
总之,已经完全不用重启和发布了!这个功能真的很方便,比起重启带来的代价,真的是不可比的,比如,重启时可能导致负载重分配,选主等等问题,就不是你能控制的了
我如何测试某个方法的性能问题?
场景:我想看下某个方法的性能
monitor -c 5 demo.MathGame primeFactors
如何定位偏底层的性能问题?
场景:通过前面的排查之后,发现是偏底层的API耗时长,我怎么确定是底层什么原因导致的?如:for循环中向ArrayList添加数据。
可以采用trace+watch,但稍微麻烦,下面说明 profiler 命令生成性能监控火焰图来直观的查看。
# 步骤一
profiler start 开始监控方法执行性能。运行此命令之后需要即时触发方法才会进行监控
注意:该命令不可在Windows中执行。
# 步骤二
profiler stop --format html 以HTML的方式生成火焰图
火焰图中一般找绿色部分Java中栈顶上比较平(比较宽)的部分,很可能就是性能的瓶颈。
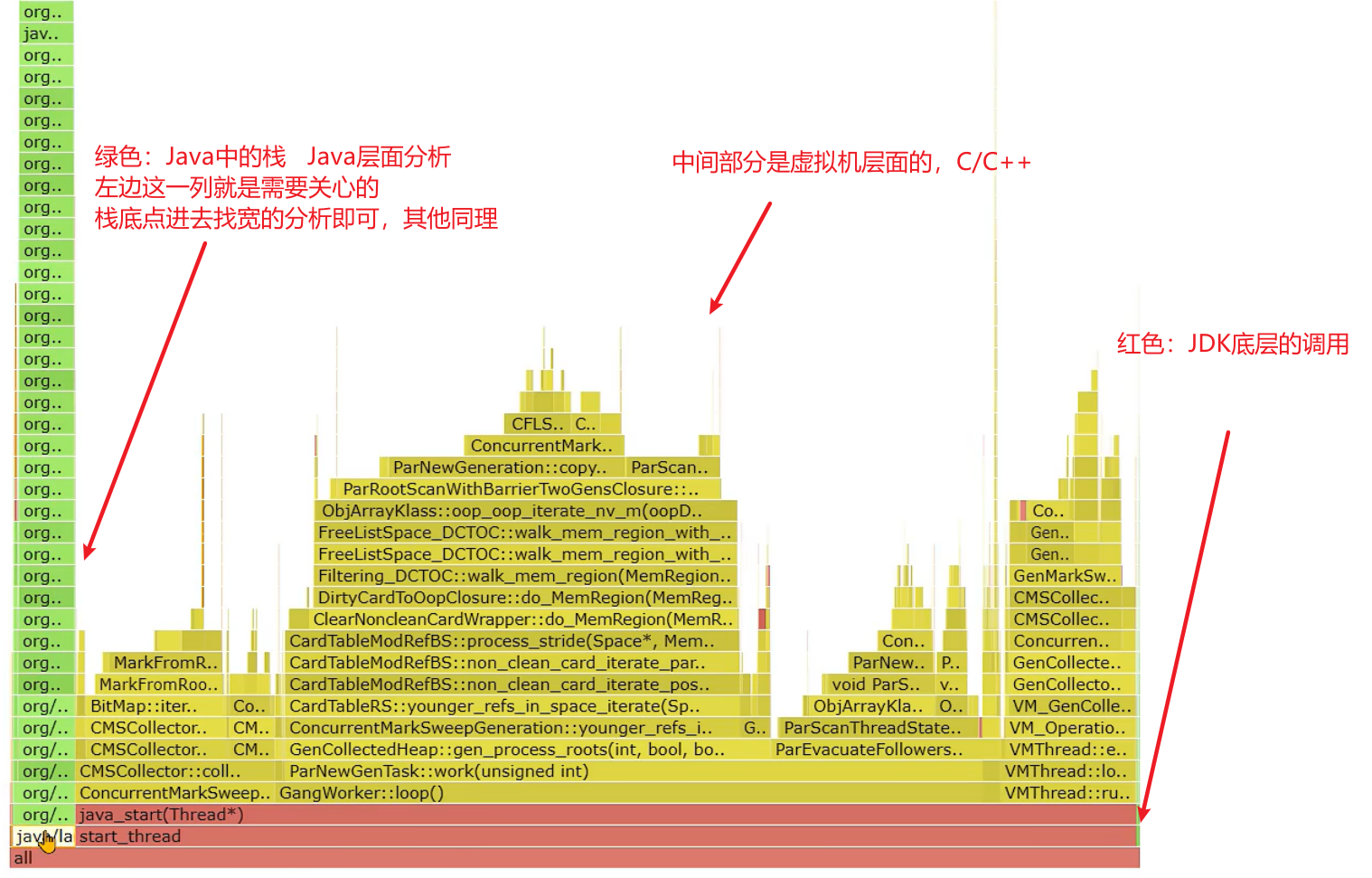
更多请看这里:profiler
更多
请参考: 官方Issue墙
Arthas源码
首先我们先放出一张整体宏观的模块调用图:
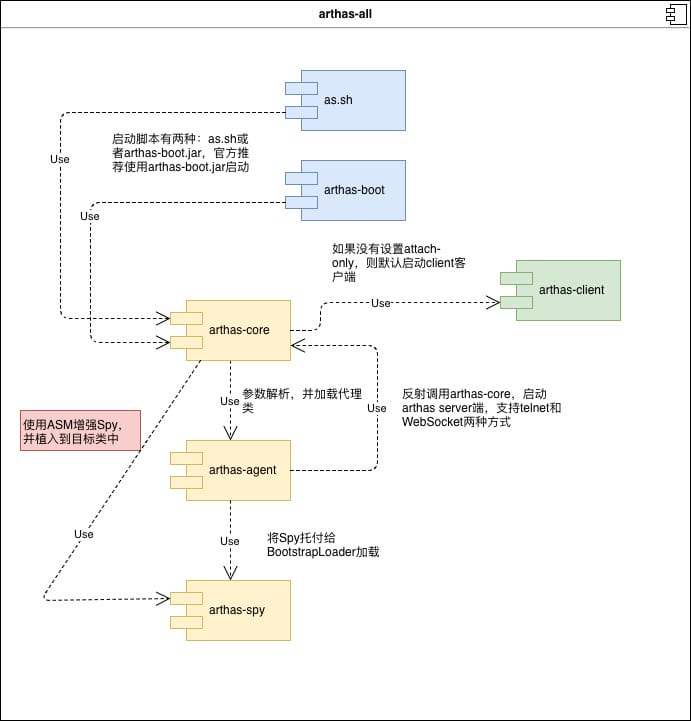
源码理解可以这篇文章:https://yq.aliyun.com/articles/704228
Java动态调试技术原理
本文转载自 @美团技术团队:Java 动态调试技术原理及实践, 通过学习Java agent方式进行动态调试了解目前很多大厂开源的一些基于此的调试工具(Arthas原理用了这玩意儿)
作者:胡健
简介
断点调试是我们最常使用的调试手段,它可以获取到方法执行过程中的变量信息,并可以观察到方法的执行路径但断点调试会在断点位置停顿,使得整个应用停止响应在线上停顿应用是致命的,动态调试技术给了我们创造新的调试模式的想象空间。本文将研究Java语言中的动态调试技术,首先概括Java动态调试所涉及的技术基础,接着介绍我们在Java动态调试领域的思考及实践,通过结合实际业务场景,设计并实现了一种具备动态性的断点调试工具Java-debug-tool,显著提高了故障排查效率
JVMTI (JVM Tool Interface)是Java虚拟机对外提供的Native编程接口,通过JVMTI,外部进程可以获取到运行时JVM的诸多信息,比如线程、GC等。Agent是一个运行在目标JVM的特定程序,它的职责是负责从目标JVM中获取数据,然后将数据传递给外部进程。加载Agent的时机可以是目标JVM启动之时,也可以是在目标JVM运行时进行加载,而在目标JVM运行时进行Agent加载具备动态性,对于时机未知的Debug场景来说非常实用。下面将详细分析Java Agent技术的实现细节
Agent的实现模式
JVMTI是一套Native接口,在Java SE 5之前,要实现一个Agent只能通过编写Native代码来实现。从Java SE 5开始,可以使用Java的Instrumentation接口(Java.lang.instrument)来编写Agent。无论是通过Native的方式还是通过Java Instrumentation接口的方式来编写Agent,它们的工作都是借助JVMTI来进行完成,下面介绍通过Java Instrumentation接口编写Agent的方法
通过Java Instrumentation API
- 【[可选]:在maven中可以添加maven-assembly-plugin插件,此插件可以打包出java agent的jar包。】
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plgin</artifactId>
<configuration>
<!-- 将所有依赖都打入一个jar包中 -->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<!-- 指定java agent相关配置文件 -->
<archive>
<manifestFile>src/main/resources/MANIFEST.MF</manifestFile>
</archive>
</configuration>
</plugin>
</plugins>
</build>
- 实现Agent启动方法:新建类,根据需要使用如下API即可,如AgentMain类
Java Agent支持目标JVM启动时加载(即静态加载模式),也支持在目标JVM运行时加载(即动态加载模式),这两种不同的加载模式会使用不同的入口函数,如果需要在目标JVM启动的同时加载Agent,那么可以选择实现下面的方法:
// 静态加载模式
[1] public static void premain(String agentArgs, Instrumentation inst);
[2] public static void premain(String agentArgs);
JVM将首先寻找[1],如果没有发现[1],再寻找[2]。
如果希望在目标JVM运行时加载Agent,则需要实现下面的方法:
// 动态加载模式
[1] public static void agentmain(String agentArgs, Instrumentation inst);
[2] public static void agentmain(String agentArgs);
这两组方法的第一个参数AgentArgs是随同 “-Javaagent”一起传入的程序参数,如果这个字符串代表了多个参数,就需要自己解析这些参数,inst是Instrumentation类型的对象,是JVM自动传入的,我们可以拿这个参数进行类增强等操作
- 指定Main-Class
Agent需要打包成一个jar包,在resources中新建MANIFEST.MF文件,此文件主要用于描述java agent的配置属性,比如使用哪一个类的agentmain方法。
注意:使用时去掉下面的注释
Mainfest-Version: 1.0
# 静态加载模式:指定 public static void premain() 方法所在的类路径
Premain-Class: xxxx.xxxx.xxxx.xxx.xxx.PreAgentMain
# 动态加载模式:指定 public static void agentmain()方法所在的类路径
Agent-Class: xxxx.xxxx.xxxx.xxx.xxx.AgentMain
# 在Java Agent中能否重新定义一个类
Can-Redefine-Classes: true
# 能否将老的类转换成新的类
Can-Retransform-Classes: true
# 能否在Java Agent中生成native本地方法,有需要可以使用C/C++创建native方法
Can-Set-Native-Method-Prefix: true
# 注意:这里最好空一行,不然可能会报错
- 挂载到目标JVM:可以选择新建类,如AttachMain类
将编写的Agent打成jar包后,就可以挂载到目标JVM上去了如果选择在目标JVM启动时加载Agent,则可以使用 “-Javaagent:[=]“,具体的使用方法可以使用“Java -Help”来查看。如果想要在运行时挂载Agent到目标JVM,就需要做一些额外的开发了
com.sun.tools.attach.VirtualMachine 这个类代表一个JVM抽象,可以通过这个类找到目标JVM,并且将Agent挂载到目标JVM上。下面是使用com.sun.tools.attach.VirtualMachine进行动态挂载Agent的一般实现:
private void attachAgentToTargetJVM() throws Exception {
List<VirtualMachineDescriptor> virtualMachineDescriptors = VirtualMachine.list();
VirtualMachineDescriptor targetVM = null;
for (VirtualMachineDescriptor descriptor : virtualMachineDescriptors) {
// 通过指定的进程ID找到目标JVM
if (descriptor.id().equals(configure.getPid())) {
targetVM = descriptor;
break;
}
}
if (targetVM == null) {
throw new IllegalArgumentException("could not find the target JVM by process id:" + configure.getPid());
}
VirtualMachine virtualMachine = null;
try {
// 通过Attach挂载到目标JVM上 最核心的就是这两步
virtualMachine = VirtualMachine.attach(targetVM);
virtualMachine.loadAgent("{agent}", "{params}");
} catch (Exception e) {
if (virtualMachine != null) {
// 将Agent从目标JVM卸载
virtualMachine.detach();
}
}
}
首先通过指定的进程ID找到目标JVM,然后通过Attach挂载到目标JVM上,执行加载Agent操作。VirtualMachine的Attach方法就是用来将Agent挂载到目标JVM上去的,而Detach则是将Agent从目标JVM卸载。关于Agent是如何挂载到目标JVM上的具体技术细节,将在下文中进行分析
启动时加载Agent
参数解析
创建JVM时,JVM会进行参数解析,即解析那些用来配置JVM启动的参数,比如堆大小、GC等;本文主要关注解析的参数为-agentlib、 -agentpath、 -Javaagent,这几个参数用来指定Agent,JVM会根据这几个参数加载Agent。下面来分析一下JVM是如何解析这几个参数的
// -agentlib and -agentpath
if (match_option(option, "-agentlib:", &tail) ||
(is_absolute_path = match_option(option, "-agentpath:", &tail))) {
if(tail != NULL) {
const char* pos = strchr(tail, '=');
size_t len = (pos == NULL) ? strlen(tail) : pos - tail;
char* name = strncpy(NEW_C_HEAP_ARRAY(char, len + 1, mtArguments), tail, len);
name[len] = '\0';
char *options = NULL;
if(pos != NULL) {
options = os::strdup_check_oom(pos + 1, mtArguments);
}
#if !INCLUDE_JVMTI
if (valid_jdwp_agent(name, is_absolute_path)) {
jio_fprintf(defaultStream::error_stream(),
"Debugging agents are not supported in this VM\n");
return JNI_ERR;
}
#endif // !INCLUDE_JVMTI
add_init_agent(name, options, is_absolute_path);
}
// -Javaagent
} else if (match_option(option, "-Javaagent:", &tail)) {
#if !INCLUDE_JVMTI
jio_fprintf(defaultStream::error_stream(),
"Instrumentation agents are not supported in this VM\n");
return JNI_ERR;
#else
if (tail != NULL) {
size_t length = strlen(tail) + 1;
char *options = NEW_C_HEAP_ARRAY(char, length, mtArguments);
jio_snprintf(options, length, "%s", tail);
add_init_agent("instrument", options, false);
// Java agents need module Java.instrument
if (!create_numbered_property("JDK.module.addmods", "Java.instrument", addmods_count++)) {
return JNI_ENOMEM;
}
}
#endif // !INCLUDE_JVMTI
}
上面的代码片段截取自hotspot/src/share/vm/runtime/arguments.cpp中的 Arguments::parse_each_vm_init_arg(const JavaVMInitArgs* args, bool* patch_mod_Javabase, Flag::Flags origin) 函数,该函数用来解析一个具体的JVM参数。这段代码的主要功能是解析出需要加载的Agent路径,然后调用add_init_agent函数进行解析结果的存储。下面先看一下add_init_agent函数的具体实现:
// -agentlib and -agentpath arguments
static AgentLibraryList _agentList;
static void add_init_agent(const char* name, char* options, bool absolute_path)
{ _agentList.add(new AgentLibrary(name, options, absolute_path, NULL)); }
AgentLibraryList是一个简单的链表结构,add_init_agent函数将解析好的、需要加载的Agent添加到这个链表中,等待后续的处理
这里需要注意,解析-Javaagent参数有一些特别之处,这个参数用来指定一个我们通过Java Instrumentation API来编写的Agent,Java Instrumentation API底层依赖的是JVMTI,对-JavaAgent的处理也说明了这一点,在调用add_init_agent函数时第一个参数是“instrument”,关于加载Agent这个问题在下一小节进行展开。到此,我们知道在启动JVM时指定的Agent已经被JVM解析完存放在了一个链表结构中。下面来分析一下JVM是如何加载这些Agent的
执行加载操作
在创建JVM进程的函数中,解析完JVM参数之后,下面的这段代码和加载Agent相关:
// Launch -agentlib/-agentpath and converted -Xrun agents
if (Arguments::init_agents_at_startup()) {
create_vm_init_agents();
}
static bool init_agents_at_startup() {
return !_agentList.is_empty();
}
当JVM判断出上一小节中解析出来的Agent不为空的时候,就要去调用函数create_vm_init_agents来加载Agent,下面来分析一下create_vm_init_agents函数是如何加载Agent的
void Threads::create_vm_init_agents() {
AgentLibrary* agent;
for (agent = Arguments::agents(); agent != NULL; agent = agent->next()) {
OnLoadEntry_t on_load_entry = lookup_agent_on_load(agent);
if (on_load_entry != NULL) {
// Invoke the Agent_OnLoad function
jint err = (*on_load_entry)(&main_vm, agent->options(), NULL);
}
}
}
create_vm_init_agents这个函数通过遍历Agent链表来逐个加载Agent。通过这段代码可以看出,首先通过lookup_agent_on_load来加载Agent并且找到Agent_OnLoad函数,这个函数是Agent的入口函数。如果没找到这个函数,则认为是加载了一个不合法的Agent,则什么也不做,否则调用这个函数,这样Agent的代码就开始执行起来了。对于使用Java Instrumentation API来编写Agent的方式来说,在解析阶段观察到在add_init_agent函数里面传递进去的是一个叫做”instrument”的字符串,其实这是一个动态链接库。在Linux里面,这个库叫做libinstrument.so,在BSD系统中叫做libinstrument.dylib,该动态链接库在{Java_HOME}/jre/lib/目录下
instrument动态链接库
libinstrument用来支持使用Java Instrumentation API来编写Agent,在libinstrument中有一个非常重要的类称为:JPLISAgent(Java Programming Language Instrumentation Services Agent),它的作用是初始化所有通过Java Instrumentation API编写的Agent,并且也承担着通过JVMTI实现Java Instrumentation中暴露API的责任
我们已经知道,在JVM启动的时候,JVM会通过-Javaagent参数加载Agent。最开始加载的是libinstrument动态链接库,然后在动态链接库里面找到JVMTI的入口方法:Agent_OnLoad。下面就来分析一下在libinstrument动态链接库中,Agent_OnLoad函数是怎么实现的
JNIEXPORT jint JNICALL
DEF_Agent_OnLoad(JavaVM *vm, char *tail, void * reserved) {
initerror = createNewJPLISAgent(vm, &agent);
if ( initerror == JPLIS_INIT_ERROR_NONE ) {
if (parseArgumentTail(tail, &jarfile, &options) != 0) {
fprintf(stderr, "-Javaagent: memory allocation failure.\n");
return JNI_ERR;
}
attributes = readAttributes(jarfile);
premainClass = getAttribute(attributes, "Premain-Class");
/* Save the jarfile name */
agent->mJarfile = jarfile;
/*
* Convert JAR attributes into agent capabilities
*/
convertCapabilityAttributes(attributes, agent);
/*
* Track (record) the agent Class name and options data
*/
initerror = recordCommandLineData(agent, premainClass, options);
}
return result;
}
上述代码片段是经过精简的libinstrument中Agent_OnLoad实现,大概的流程就是:先创建一个JPLISAgent,然后将ManiFest中设定的一些参数解析出来, 比如(Premain-Class)等。创建了JPLISAgent之后,调用initializeJPLISAgent对这个Agent进行初始化操作。跟进initializeJPLISAgent看一下是如何初始化的:
JPLISInitializationError initializeJPLISAgent(JPLISAgent *agent, JavaVM *vm, JVMtiEnv *JVMtienv) {
/* check what capabilities are available */
checkCapabilities(agent);
/* check phase - if live phase then we don't need the VMInit event */
JVMtierror = (*JVMtienv)->GetPhase(JVMtienv, &phase);
/* now turn on the VMInit event */
if ( JVMtierror == JVMTI_ERROR_NONE ) {
JVMtiEventCallbacks callbacks;
memset(&callbacks, 0, sizeof(callbacks));
callbacks.VMInit = &eventHandlerVMInit;
JVMtierror = (*JVMtienv)->SetEventCallbacks(JVMtienv,&callbacks,sizeof(callbacks));
}
if ( JVMtierror == JVMTI_ERROR_NONE ) {
JVMtierror = (*JVMtienv)->SetEventNotificationMode(JVMtienv,JVMTI_ENABLE,JVMTI_EVENT_VM_INIT,NULL);
}
return (JVMtierror == JVMTI_ERROR_NONE)? JPLIS_INIT_ERROR_NONE : JPLIS_INIT_ERROR_FAILURE;
}
这里,我们关注callbacks.VMInit = &eventHandlerVMInit;这行代码,这里设置了一个VMInit事件的回调函数,表示在JVM初始化的时候会回调eventHandlerVMInit函数。下面来看一下这个函数的实现细节,猜测就是在这里调用了Premain方法:
void JNICALL eventHandlerVMInit( JVMtiEnv *JVMtienv,JNIEnv *jnienv,jthread thread) {
// ...
success = processJavaStart( environment->mAgent, jnienv);
// ...
}
jboolean processJavaStart(JPLISAgent *agent,JNIEnv *jnienv) {
result = createInstrumentationImpl(jnienv, agent);
/*
* Load the Java agent, and call the premain.
*/
if ( result ) {
result = startJavaAgent(agent, jnienv, agent->mAgentClassName, agent->mOptionsString, agent->mPremainCaller);
}
return result;
}
jboolean startJavaAgent( JPLISAgent *agent,JNIEnv *jnienv,const char *Classname,const char *optionsString,jmethodID agentMainMethod) {
// ...
invokeJavaAgentMainMethod(jnienv,agent->mInstrumentationImpl,agentMainMethod, ClassNameObject,optionsStringObject);
// ...
}
看到这里,Instrument已经实例化,invokeJavaAgentMainMethod这个方法将我们的premain方法执行起来了。接着,我们就可以根据Instrument实例来做我们想要做的事情了
运行时加载Agent
比起JVM启动时加载Agent,运行时加载Agent就比较有诱惑力了,因为运行时加载Agent的能力给我们提供了很强的动态性,我们可以在需要的时候加载Agent来进行一些工作。因为是动态的,我们可以按照需求来加载所需要的Agent,下面来分析一下动态加载Agent的相关技术细节
AttachListener
Attach机制通过Attach Listener线程来进行相关事务的处理,下面来看一下Attach Listener线程是如何初始化的
// Starts the Attach Listener thread
void AttachListener::init() {
// 创建线程相关部分代码被去掉了
const char thread_name[] = "Attach Listener";
Handle string = Java_lang_String::create_from_str(thread_name, THREAD);
{ MutexLocker mu(Threads_lock);
JavaThread* listener_thread = new JavaThread(&attach_listener_thread_entry);
// ...
}
}
我们知道,一个线程启动之后都需要指定一个入口来执行代码,Attach Listener线程的入口是attach_listener_thread_entry,下面看一下这个函数的具体实现:
static void attach_listener_thread_entry(JavaThread* thread, TRAPS) {
AttachListener::set_initialized();
for (;;) {
AttachOperation* op = AttachListener::dequeue();
// find the function to dispatch too
AttachOperationFunctionInfo* info = NULL;
for (int i=0; funcs[i].name != NULL; i++) {
const char* name = funcs[i].name;
if (strcmp(op->name(), name) == 0) {
info = &(funcs[i]); break;
}}
// dispatch to the function that implements this operation
res = (info->func)(op, &st);
//...
}
}
整个函数执行逻辑,大概是这样的:
- 拉取一个需要执行的任务:AttachListener::dequeue
- 查询匹配的命令处理函数
- 执行匹配到的命令执行函数
其中第二步里面存在一个命令函数表,整个表如下:
static AttachOperationFunctionInfo funcs[] = {
{ "agentProperties", get_agent_properties },
{ "datadump", data_dump },
{ "dumpheap", dump_heap },
{ "load", load_agent },
{ "properties", get_system_properties },
{ "threaddump", thread_dump },
{ "inspectheap", heap_inspection },
{ "setflag", set_flag },
{ "printflag", print_flag },
{ "jcmd", jcmd },
{ NULL, NULL }
};
对于加载Agent来说,命令就是“load”现在,我们知道了Attach Listener大概的工作模式,但是还是不太清楚任务从哪来,这个秘密就藏在AttachListener::dequeue这行代码里面,接下来我们来分析一下dequeue这个函数:
LinuxAttachOperation* LinuxAttachListener::dequeue() {
for (;;) {
// wait for client to connect
struct sockaddr addr;
socklen_t len = sizeof(addr);
RESTARTABLE(::accept(listener(), &addr, &len), s);
// get the credentials of the peer and check the effective uid/guid
// - check with jeff on this.
struct ucred cred_info;
socklen_t optlen = sizeof(cred_info);
if (::getsockopt(s, SOL_SOCKET, SO_PEERCRED, (void*)&cred_info, &optlen) == -1) {
::close(s);
continue;
}
// peer credential look okay so we read the request
LinuxAttachOperation* op = read_request(s);
return op;
}
}
这是Linux上的实现,不同的操作系统实现方式不太一样。上面的代码表面,Attach Listener在某个端口监听着,通过accept来接收一个连接,然后从这个连接里面将请求读取出来,然后将请求包装成一个AttachOperation类型的对象,之后就会从表里查询对应的处理函数,然后进行处理
Attach Listener使用一种被称为“懒加载”的策略进行初始化,也就是说,JVM启动的时候Attach Listener并不一定会启动起来。下面我们来分析一下这种“懒加载”策略的具体实现方案
// Start Attach Listener if +StartAttachListener or it can't be started lazily
if (!DisableAttachMechanism) {
AttachListener::vm_start();
if (StartAttachListener || AttachListener::init_at_startup()) {
AttachListener::init();
}
}
// Attach Listener is started lazily except in the case when
// +ReduseSignalUsage is used
bool AttachListener::init_at_startup() {
if (ReduceSignalUsage) {
return true;
} else {
return false;
}
}
上面的代码截取自create_vm函数,DisableAttachMechanism、StartAttachListener和ReduceSignalUsage这三个变量默认都是false,所以AttachListener::init();这行代码不会在create_vm的时候执行,而vm_start会执行下面来看一下这个函数的实现细节:
void AttachListener::vm_start() {
char fn[UNIX_PATH_MAX];
struct stat64 st;
int ret;
int n = snprintf(fn, UNIX_PATH_MAX, "%s/.Java_pid%d",
os::get_temp_directory(), os::current_process_id());
assert(n < (int)UNIX_PATH_MAX, "Java_pid file name buffer overflow");
RESTARTABLE(::stat64(fn, &st), ret);
if (ret == 0) {
ret = ::unlink(fn);
if (ret == -1) {
log_debug(attach)("Failed to remove stale attach pid file at %s", fn);
}
}
}
这是在Linux上的实现,是将/tmp/目录下的.Java_pid{pid}文件删除,后面在创建Attach Listener线程的时候会创建出来这个文件。上面说到,AttachListener::init()这行代码不会在create_vm的时候执行,这行代码的实现已经在上文中分析了,就是创建Attach Listener线程,并监听其他JVM的命令请求。现在来分析一下这行代码是什么时候被调用的,也就是“懒加载”到底是怎么加载起来的
// Signal Dispatcher needs to be started before VMInit event is posted
os::signal_init();
这是create_vm中的一段代码,看起来跟信号相关,其实Attach机制就是使用信号来实现“懒加载“的。下面我们来仔细地分析一下这个过程
void os::signal_init() {
if (!ReduceSignalUsage) {
// Setup JavaThread for processing signals
EXCEPTION_MARK;
Klass* k = SystemDictionary::resolve_or_fail(vmSymbols::Java_lang_Thread(), true, CHECK);
instanceKlassHandle klass (THREAD, k);
instanceHandle thread_oop = klass->allocate_instance_handle(CHECK);
const char thread_name[] = "Signal Dispatcher";
Handle string = Java_lang_String::create_from_str(thread_name, CHECK);
// Initialize thread_oop to put it into the system threadGroup
Handle thread_group (THREAD, Universe::system_thread_group());
JavaValue result(T_VOID);
JavaCalls::call_special(&result, thread_oop,klass,vmSymbols::object_initializer_name(),vmSymbols::threadgroup_string_void_signature(),
thread_group,string,CHECK);
KlassHandle group(THREAD, SystemDictionary::ThreadGroup_klass());
JavaCalls::call_special(&result,thread_group,group,vmSymbols::add_method_name(),vmSymbols::thread_void_signature(),thread_oop,CHECK);
os::signal_init_pd();
{ MutexLocker mu(Threads_lock);
JavaThread* signal_thread = new JavaThread(&signal_thread_entry);
// ...
}
// Handle ^BREAK
os::signal(SIGBREAK, os::user_handler());
}
}
JVM创建了一个新的进程来实现信号处理,这个线程叫“Signal Dispatcher”,一个线程创建之后需要有一个入口,“Signal Dispatcher”的入口是signal_thread_entry:

这段代码截取自signal_thread_entry函数,截取中的内容是和Attach机制信号处理相关的代码。这段代码的意思是,当接收到“SIGBREAK”信号,就执行接下来的代码,这个信号是需要Attach到JVM上的信号发出来,这个后面会再分析。我们先来看一句关键的代码:AttachListener::is_init_trigger():
bool AttachListener::is_init_trigger() {
if (init_at_startup() || is_initialized()) {
return false; // initialized at startup or already initialized
}
char fn[PATH_MAX+1];
sprintf(fn, ".attach_pid%d", os::current_process_id());
int ret;
struct stat64 st;
RESTARTABLE(::stat64(fn, &st), ret);
if (ret == -1) {
log_trace(attach)("Failed to find attach file: %s, trying alternate", fn);
snprintf(fn, sizeof(fn), "%s/.attach_pid%d", os::get_temp_directory(), os::current_process_id());
RESTARTABLE(::stat64(fn, &st), ret);
}
if (ret == 0) {
// simple check to avoid starting the attach mechanism when
// a bogus user creates the file
if (st.st_uid == geteuid()) {
init();
return true;
}
}
return false;
}
首先检查了一下是否在JVM启动时启动了Attach Listener,或者是否已经启动过。如果没有,才继续执行,在/tmp目录下创建一个叫做.attach_pid%d的文件,然后执行AttachListener的init函数,这个函数就是用来创建Attach Listener线程的函数,上面已经提到多次并进行了分析。到此,我们知道Attach机制的奥秘所在,也就是Attach Listener线程的创建依靠Signal Dispatcher线程,Signal Dispatcher是用来处理信号的线程,当Signal Dispatcher线程接收到“SIGBREAK”信号之后,就会执行初始化Attach Listener的工作
运行时加载Agent的实现
我们继续分析,到底是如何将一个Agent挂载到运行着的目标JVM上,在上文中提到了一段代码,用来进行运行时挂载Agent,可以参考上文中展示的关于“attachAgentToTargetJVM”方法的代码。这个方法里面的关键是调用VirtualMachine的attach方法进行Agent挂载的功能。下面我们就来分析一下VirtualMachine的attach方法具体是怎么实现的
public static VirtualMachine attach(String var0) throws AttachNotSupportedException, IOException {
if (var0 == null) {
throw new NullPointerException("id cannot be null");
} else {
List var1 = AttachProvider.providers();
if (var1.size() == 0) {
throw new AttachNotSupportedException("no providers installed");
} else {
AttachNotSupportedException var2 = null;
Iterator var3 = var1.iterator();
while(var3.hasNext()) {
AttachProvider var4 = (AttachProvider)var3.next();
try {
return var4.attachVirtualMachine(var0);
} catch (AttachNotSupportedException var6) {
var2 = var6;
}
}
throw var2;
}
}
}
这个方法通过attachVirtualMachine方法进行attach操作,在MacOS系统中,AttachProvider的实现类是BsdAttachProvider。我们来看一下BsdAttachProvider的attachVirtualMachine方法是如何实现的:
public VirtualMachine attachVirtualMachine(String var1) throws AttachNotSupportedException, IOException {
this.checkAttachPermission();
this.testAttachable(var1);
return new BsdVirtualMachine(this, var1);
}
BsdVirtualMachine(AttachProvider var1, String var2) throws AttachNotSupportedException, IOException {
int var3 = Integer.parseInt(var2);
this.path = this.findSocketFile(var3);
if (this.path == null) {
File var4 = new File(tmpdir, ".attach_pid" + var3);
createAttachFile(var4.getPath());
try {
sendQuitTo(var3);
int var5 = 0;
long var6 = 200L;
int var8 = (int)(this.attachTimeout() / var6);
do {
try {
Thread.sleep(var6);
} catch (InterruptedException var21) {
;
}
this.path = this.findSocketFile(var3);
++var5;
} while(var5 <= var8 && this.path == null);
} finally {
var4.delete();
}
}
int var24 = socket();
connect(var24, this.path);
}
private String findSocketFile(int var1) {
String var2 = ".Java_pid" + var1;
File var3 = new File(tmpdir, var2);
return var3.exists() ? var3.getPath() : null;
}
findSocketFile方法用来查询目标JVM上是否已经启动了Attach Listener,它通过检查”tmp/“目录下是否存在Java_pid{pid}来进行实现。如果已经存在了,则说明Attach机制已经准备就绪,可以接受客户端的命令了,这个时候客户端就可以通过connect连接到目标JVM进行命令的发送,比如可以发送“load”命令来加载Agent;如果Java_pid{pid}文件还不存在,则需要通过sendQuitTo方法向目标JVM发送一个“SIGBREAK”信号,让它初始化Attach Listener线程并准备接受客户端连接。可以看到,发送了信号之后客户端会循环等待Java_pid{pid}这个文件,之后再通过connect连接到目标JVM上
load命令的实现
下面来分析一下,“load”命令在JVM层面的实现:
static jint load_agent(AttachOperation* op, outputStream* out) {
// get agent name and options
const char* agent = op->arg(0);
const char* absParam = op->arg(1);
const char* options = op->arg(2);
// If loading a Java agent then need to ensure that the Java.instrument module is loaded
if (strcmp(agent, "instrument") == 0) {
Thread* THREAD = Thread::current();
ResourceMark rm(THREAD);
HandleMark hm(THREAD);
JavaValue result(T_OBJECT);
Handle h_module_name = Java_lang_String::create_from_str("Java.instrument", THREAD);
JavaCalls::call_static(&result,SystemDictionary::module_Modules_klass(),vmSymbols::loadModule_name(),
vmSymbols::loadModule_signature(),h_module_name,THREAD);
}
return JVMtiExport::load_agent_library(agent, absParam, options, out);
}
这个函数先确保加载了Java.instrument模块,之后真正执行Agent加载的函数是 load_agent_library ,这个函数的套路就是加载Agent动态链接库,如果是通过Java instrument API实现的Agent,则加载的是libinstrument动态链接库,然后通过libinstrument里面的代码实现运行agentmain方法的逻辑,这一部分内容和libinstrument实现premain方法运行的逻辑其实差不多,这里不再做分析至此,我们对Java Agent技术已经有了一个全面而细致的了解
动态字节码修改的限制
上文中已经详细分析了Agent技术的实现,我们使用Java Instrumentation API来完成动态类修改的功能,在Instrumentation接口中,通过addTransformer方法来增加一个类转换器,类转换器由类ClassFileTransformer接口实现ClassFileTransformer接口中唯一的方法transform用于实现类转换,当类被加载的时候,就会调用transform方法,进行类转换在运行时,我们可以通过Instrumentation的redefineClasses方法进行类重定义,在方法上有一段注释需要特别注意:
* The redefinition may change method bodies, the constant pool and attributes.
* The redefinition must not add, remove or rename fields or methods, change the
* signatures of methods, or change inheritance. These restrictions maybe be
* lifted in future versions. The Class file bytes are not checked, verified and installed
* until after the transformations have been applied, if the resultant bytes are in
* error this method will throw an exception.
这里面提到,我们不可以增加、删除或者重命名字段和方法,改变方法的签名或者类的继承关系。认识到这一点很重要,当我们通过ASM获取到增强的字节码之后,如果增强后的字节码没有遵守这些规则,那么调用redefineClasses方法来进行类的重定义就会失败。那redefineClasses方法具体是怎么实现类的重定义的呢? 它对运行时的JVM会造成什么样的影响呢? 下面来分析redefineClasses的实现细节
重定义类字节码的实现细节
上文中我们提到,libinstrument动态链接库中,JPLISAgent不仅实现了Agent入口代码执行的路由,而且还是Java代码与JVMTI之间的一道桥梁。我们在Java代码中调用Java Instrumentation API的redefineClasses,其实会调用libinstrument中的相关代码,我们来分析一下这条路径
public void redefineClasses(ClassDefinition... var1) throws ClassNotFoundException {
if (!this.isRedefineClassesSupported()) {
throw new UnsupportedOperationException("redefineClasses is not supported in this environment");
} else if (var1 == null) {
throw new NullPointerException("null passed as 'definitions' in redefineClasses");
} else {
for(int var2 = 0; var2 < var1.length; ++var2) {
if (var1[var2] == null) {
throw new NullPointerException("element of 'definitions' is null in redefineClasses");
}
}
if (var1.length != 0) {
this.redefineClasses0(this.mNativeAgent, var1);
}
}
}
private native void redefineClasses0(long var1, ClassDefinition[] var3) throws ClassNotFoundException;
这是InstrumentationImpl中的redefineClasses实现,该方法的具体实现依赖一个Native方法redefineClasses(),我们可以在libinstrument中找到这个Native方法的实现:
JNIEXPORT void JNICALL Java_sun_instrument_InstrumentationImpl_redefineClasses0
(JNIEnv * jnienv, jobject implThis, jlong agent, jobjectArray ClassDefinitions) {
redefineClasses(jnienv, (JPLISAgent*)(intptr_t)agent, ClassDefinitions);
}
redefineClasses这个函数的实现比较复杂,代码很长下面是一段关键的代码片段:
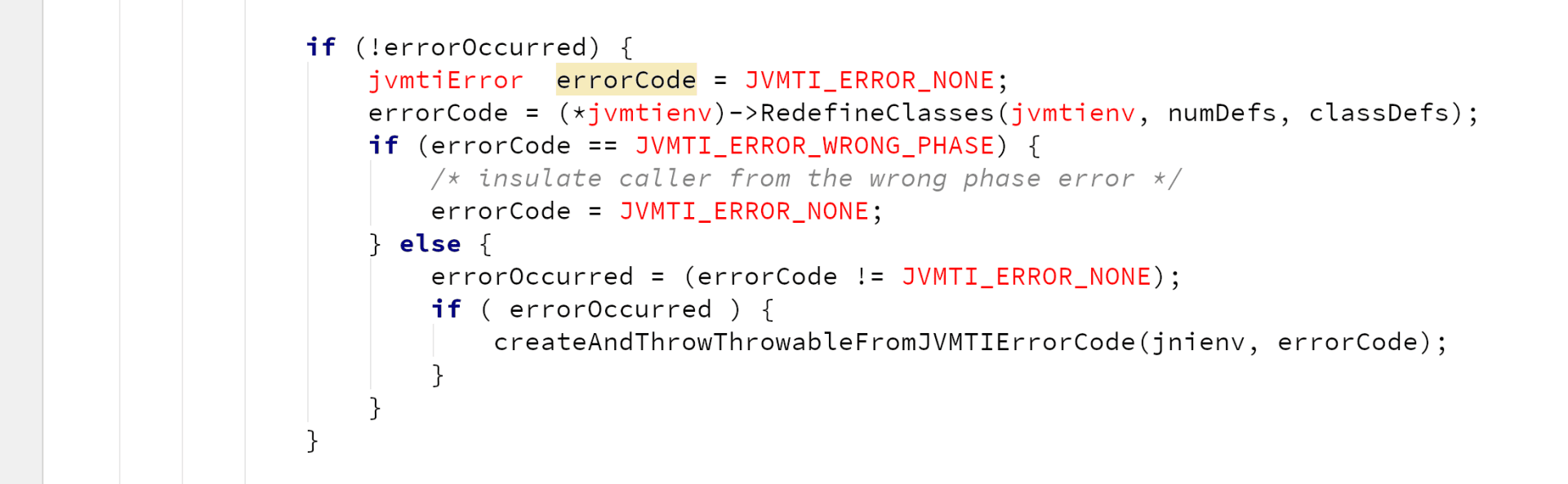
可以看到,其实是调用了JVMTI的RetransformClasses函数来完成类的重定义细节
// Class_count - pre-checked to be greater than or equal to 0
// Class_definitions - pre-checked for NULL
JVMtiError JVMtiEnv::RedefineClasses(jint Class_count, const JVMtiClassDefinition* Class_definitions) {
//TODO: add locking
VM_RedefineClasses op(Class_count, Class_definitions, JVMti_Class_load_kind_redefine);
VMThread::execute(&op);
return (op.check_error());
} /* end RedefineClasses */
重定义类的请求会被JVM包装成一个VM_RedefineClasses类型的VM_Operation,VM_Operation是JVM内部的一些操作的基类,包括GC操作等。VM_Operation由VMThread来执行,新的VM_Operation操作会被添加到VMThread的运行队列中去,VMThread会不断从队列里面拉取VM_Operation并调用其doit等函数执行具体的操作。VM_RedefineClasses函数的流程较为复杂,下面是VM_RedefineClasses的大致流程:
- 加载新的字节码,合并常量池,并且对新的字节码进行校验工作
// Load the caller's new Class definition(s) into _scratch_Classes.
// Constant pool merging work is done here as needed. Also calls
// compare_and_normalize_Class_versions() to verify the Class
// definition(s).
JVMtiError load_new_Class_versions(TRAPS);
- 清除方法上的断点
// Remove all breakpoints in methods of this Class
JVMtiBreakpoints& JVMti_breakpoints = JVMtiCurrentBreakpoints::get_JVMti_breakpoints();
JVMti_breakpoints.clearall_in_Class_at_safepoint(the_Class());
- JIT逆优化
// Deoptimize all compiled code that depends on this Class
flush_dependent_code(the_Class, THREAD);
- 进行字节码替换工作,需要进行更新类itable/vtable等操作
- 进行类重定义通知
SystemDictionary::notice_modification();
VM_RedefineClasses实现比较复杂的,详细实现可以参考 RedefineClasses的实现
Java-debug-tool
Java-debug-tool是一个使用Java Instrument API来实现的动态调试工具,它通过在目标JVM上启动一个TcpServer来和调试客户端通信。调试客户端通过命令行来发送调试命令给TcpServer,TcpServer中有专门用来处理命令的handler,handler处理完命令之后会将结果发送回客户端,客户端通过处理将调试结果展示出来。下面将详细介绍Java-debug-tool的整体设计和实现
Java-debug-tool整体架构
Java-debug-tool包括一个Java Agent和一个用于处理调试命令的核心API,核心API通过一个自定义的类加载器加载进来,以保证目标JVM的类不会被污染。整体上Java-debug-tool的设计是一个Client-Server的架构,命令客户端需要完整的完成一个命令之后才能继续执行下一个调试命令。Java-debug-tool支持多人同时进行调试,下面是整体架构图:
下面对每一层做简单介绍:
- 交互层:负责将程序员的输入转换成调试交互协议,并且将调试信息呈现出来
- 连接管理层:负责管理客户端连接,从连接中读调试协议数据并解码,对调试结果编码并将其写到连接中去;同时将那些超时未活动的连接关闭
- 业务逻辑层:实现调试命令处理,包括命令分发、数据收集、数据处理等过程
- 基础实现层:Java-debug-tool实现的底层依赖,通过Java Instrumentation提供的API进行类查找、类重定义等能力,Java Instrumentation底层依赖JVMTI来完成具体的功能
在Agent被挂载到目标JVM上之后,Java-debug-tool会安排一个Spy在目标JVM内活动,这个Spy负责将目标JVM内部的相关调试数据转移到命令处理模块,命令处理模块会处理这些数据,然后给客户端返回调试结果。命令处理模块会增强目标类的字节码来达到数据获取的目的,多个客户端可以共享一份增强过的字节码,无需重复增强下面从Java-debug-tool的字节码增强方案、命令设计与实现等角度详细说明
Java-debug-tool的字节码增强方案
Java-debug-tool使用字节码增强来获取到方法运行时的信息,比如方法入参、出参等,可以在不同的字节码位置进行增强,这种行为可以称为“插桩”,每个“桩”用于获取数据并将他转储出去。Java-debug-tool具备强大的插桩能力,不同的桩负责获取不同类别的数据,下面是Java-debug-tool目前所支持的“桩”:
- 方法进入点:用于获取方法入参信息
- Fields获取点1:在方法执行前获取到对象的字段信息
- 变量存储点:获取局部变量信息
- Fields获取点2:在方法退出前获取到对象的字段信息
- 方法退出点:用于获取方法返回值
- 抛出异常点:用于获取方法抛出的异常信息
- 通过上面这些代码桩,Java-debug-tool可以收集到丰富的方法执行信息,经过处理可以返回更加可视化的调试结果
字节码增强
Java-debug-tool在实现上使用了ASM工具来进行字节码增强,并且每个插桩点都可以进行配置,如果不想要什么信息,则没必要进行对应的插桩操作这种可配置的设计是非常有必要的,因为有时候我们仅仅是想要知道方法的入参和出参,但Java-debug-tool却给我们返回了所有的调试信息,这样我们就得在众多的输出中找到我们所关注的内容。如果可以进行配置,则除了入参点和出参点外其他的桩都不插,那么就可以快速看到我们想要的调试数据,这种设计的本质是为了让调试者更加专注。下面是Java-debug-tool的字节码增强工作方式:
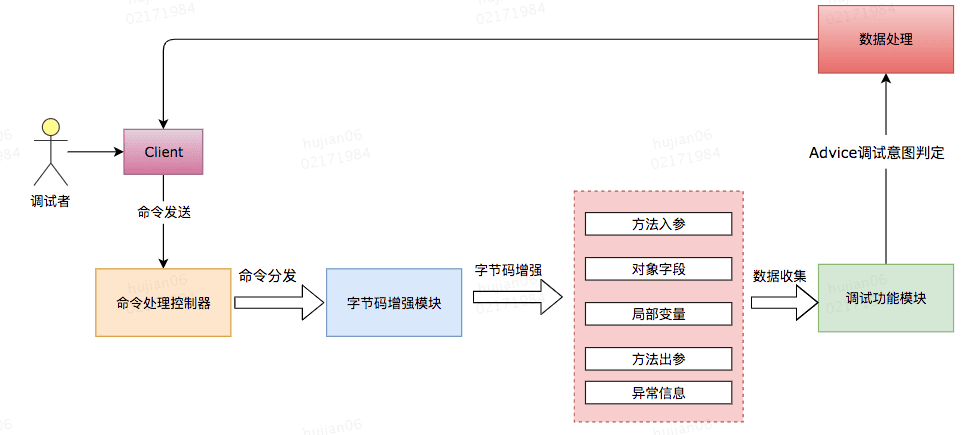
如图所示,当调试者发出调试命令之后,Java-debug-tool会识别命令并判断是否需要进行字节码增强,如果命令需要增强字节码,则判断当前类+当前方法是否已经被增强过。上文已经提到,字节码替换是有一定损耗的,这种具有损耗的操作发生的次数越少越好,所以字节码替换操作会被记录起来,后续命令直接使用即可,不需要重复进行字节码增强,字节码增强还涉及多个调试客户端的协同工作问题,当一个客户端增强了一个类的字节码之后,这个客户端就锁定了该字节码,其他客户端变成只读,无法对该类进行字节码增强,只有当持有锁的客户端主动释放锁或者断开连接之后,其他客户端才能继续增强该类的字节码
字节码增强模块收到字节码增强请求之后,会判断每个增强点是否需要插桩,这个判断的根据就是上文提到的插桩配置,之后字节码增强模块会生成新的字节码,Java-debug-tool将执行字节码替换操作,之后就可以进行调试数据收集了
经过字节码增强之后,原来的方法中会插入收集运行时数据的代码,这些代码在方法被调用的时候执行,获取到诸如方法入参、局部变量等信息,这些信息将传递给数据收集装置进行处理。数据收集的工作通过Advice完成,每个客户端同一时间只能注册一个Advice到Java-debug-tool调试模块上,多个客户端可以同时注册自己的Advice到调试模块上。Advice负责收集数据并进行判断,如果当前数据符合调试命令的要求,Java-debug-tool就会卸载这个Advice,Advice的数据就会被转移到Java-debug-tool的命令结果处理模块进行处理,并将结果发送到客户端
Advice的工作方式
Advice是调试数据收集器,不同的调试策略会对应不同的Advice。Advice是工作在目标JVM的线程内部的,它需要轻量级和高效,意味着Advice不能做太过于复杂的事情,它的核心接口“match”用来判断本次收集到的调试数据是否满足调试需求。如果满足,那么Java-debug-tool就会将其卸载,否则会继续让他收集调试数据,这种“加载Advice” -> “卸载Advice”的工作模式具备很好的灵活性
关于Advice,需要说明的另外一点就是线程安全,因为它加载之后会运行在目标JVM的线程中,目标JVM的方法极有可能是多线程访问的,这也就是说,Advice需要有能力处理多个线程同时访问方法的能力,如果Advice处理不当,则可能会收集到杂乱无章的调试数据。下面的图片展示了Advice和Java-debug-tool调试分析模块、目标方法执行以及调试客户端等模块的关系
Advice的首次挂载由Java-debug-tool的命令处理器完成,当一次调试数据收集完成之后,调试数据处理模块会自动卸载Advice,然后进行判断,如果调试数据符合Advice的策略,则直接将数据交由数据处理模块进行处理,否则会清空调试数据,并再次将Advice挂载到目标方法上去,等待下一次调试数据。非首次挂载由调试数据处理模块进行,它借助Advice按需取数据,如果不符合需求,则继续挂载Advice来获取数据,否则对调试数据进行处理并返回给客户端
Java-debug-tool的命令设计与实现
命令执行
上文已经完整的描述了Java-debug-tool的设计以及核心技术方案,本小节将详细介绍Java-debug-tool的命令设计与实现。首先需要将一个调试命令的执行流程描述清楚,下面是一张用来表示命令请求处理流程的图片:
上图简单的描述了Java-debug-tool的命令处理方式,客户端连接到服务端之后,会进行一些协议解析、协议认证、协议填充等工作,之后将进行命令分发。服务端如果发现客户端的命令不合法,则会立即返回错误信息,否则再进行命令处理命令。处理属于典型的三段式处理,前置命令处理、命令处理以及后置命令处理,同时会对命令处理过程中的异常信息进行捕获处理,三段式处理的好处是命令处理被拆成了多个阶段,多个阶段负责不同的职责。前置命令处理用来做一些命令权限控制的工作,并填充一些类似命令处理开始时间戳等信息,命令处理就是通过字节码增强,挂载Advice进行数据收集,再经过数据处理来产生命令结果的过程,后置处理则用来处理一些连接关闭、字节码解锁等事项
Java-debug-tool允许客户端设置一个命令执行超时时间,超过这个时间则认为命令没有结果,如果客户端没有设置自己的超时时间,就使用默认的超时时间进行超时控制。Java-debug-tool通过设计了两阶段的超时检测机制来实现命令执行超时功能:首先,第一阶段超时触发,则Java-debug-tool会友好的警告命令处理模块处理时间已经超时,需要立即停止命令执行,这允许命令自己做一些现场清理工作,当然需要命令执行线程自己感知到这种超时警告;当第二阶段超时触发,则Java-debug-tool认为命令必须结束执行,会强行打断命令执行线程。超时机制的目的是为了不让命令执行太长时间,命令如果长时间没有收集到调试数据,则应该停止执行,并思考是否调试了一个错误的方法当然,超时机制还可以定期清理那些因为未知原因断开连接的客户端持有的调试资源,比如字节码锁
获取方法执行视图
Java-debug-tool通过下面的信息来向调试者呈现出一次方法执行的视图:
- 正在调试的方法信息
- 方法调用堆栈
- 调试耗时,包括对目标JVM造成的STW时间
- 方法入参,包括入参的类型及参数值
- 方法的执行路径
- 代码执行耗时
- 局部变量信息
- 方法返回结果
- 方法抛出的异常
- 对象字段值快照
下图展示了Java-debug-tool获取到正在运行的方法的执行视图的信息
Java-debug-tool与同类产品对比分析
Java-debug-tool的同类产品主要是greys,其他类似的工具大部分都是基于greys进行的二次开发,所以直接选择greys来和Java-debug-tool进行对比
本文详细剖析了Java动态调试关键技术的实现细节,并介绍了我们基于Java动态调试技术结合实际故障排查场景进行的一点探索实践;动态调试技术为研发人员进行线上问题排查提供了一种新的思路,我们基于动态调试技术解决了传统断点调试存在的问题,使得可以将断点调试这种技术应用在线上,以线下调试的思维来进行线上调试,提高问题排查效率
GC调优
GC调优:指的是对垃圾回收(Garbage Collection)进行调优。GC调优的主要目标是避免由垃圾回收引起程序性能下降。
GC调优无唯一的标准答案,如何调优与硬件、程序本身、使用情况均有关系。本章节主要说明的是需要的工具和基本方法。
GC调优的核心分成三部分:
- 通用JVM参数的设置。
- 特定垃圾回收器的JVM参数的设置。
- 解决由频繁的Full GC引起的程序性能问题。
GC调优的核心指标:
- 吞吐量(Throughput):吞吐量分为业务吞吐量和垃圾回收吞吐量。
- 业务吞吐量:指的在一段时间内,程序需要完成的业务数量。保证高吞吐量的常规手段有两条:
一是:优化业务执行性能,减少单次业务的执行时间。
二是:优化垃圾回收吞吐量。
- 垃圾回收吞吐量:指的是 CPU 用于执行用户代码的时间与 CPU 总执行时间的比值,即吞吐量 = 执行用户代码时间 /(执行用户代码时间 + GC时间)。吞吐量数值越高,垃圾回收的效率就越高,允许更多的CPU时间去处理用户的业务,相应的业务吞吐量也就越高。
延迟:指的是从用户发起一个请求到收到响应这其中经历的时间。延迟 = GC延迟 + 业务执行时间。
内存使用量:指的是Java应用占用系统内存的最大值。一般通过JVM参数调整,在满足上述两个指标的前提下,这个值越小越好。
企业中所要追求的便是:高吞吐量、低延迟、低内存使用量。
GC调优的一般步骤:和前面玩的排错思路是一套的
- 发现问题:通过监控工具尽可能早地发现GC时间过长、频率过高的现象。
相关工具:
- JDK自带的jstat(垃圾回收统计)。此工具在前面 jstat:总结垃圾回收统计 已见过。主要命令如下:
缺点:无法精确到GC产生的时间,只能用于判断GC是否存在问题。
# jstat -gcutil pid interval(间隔,单位ms) [统计次数]
jstat -gcutil 2815 1000
C 代表Capacity容量,U代表Used使用量
S – 幸存者区 E – 伊甸园区 O – 老年代 M – 元空间
YGC、YGT:年轻代GC次数和GC耗时(单位:秒)
FGC、FGCT:Full GC次数和Full GC耗时
GCT:GC总耗时
- visualvm的插件:visualGC。可以通过visualvm -> tools -> plugin安装,也可以在IDEA中搜索该插件安装。
适合开发时使用,缺点:对程序运行性能有一定影响,且生产环境我们一般没有相应权限进行操作。
- 生成GC日志:可以更好的看到垃圾回收细节上的数据,同时也可以根据每款垃圾回收器的不同特点更好地发现存在的问题。
使用方法(JDK 8及以下):-XX:+PrintGCDetails -Xloggc:文件名
使用方法(JDK 9+):-Xlog:gc*:file=文件名
- GC Viewer :是一个将GC日志转换成可视化图表的小工具。使用方式如下:
java -jar gcviewer_1.3.4.jar 日志文件.log
GCeasy:业界首款使用AI机器学习技术在线进行GC分析和诊断的工具。可定位内存泄漏、GC延迟高的问题,提供JVM参数优化建议,支持在线的可视化工具图表展示。此工具进入网址选择日志文件(支持tar、zip),之后点击分析,最后就会生成分析报告。
Prometheus + Grafana:这个玩意儿可以作为GC调优的工具,也可以用来做内存分析,大厂中这个搭配是肯定会见到的,搭建一般是运维人员弄好,开发人员要学会怎么去看这个玩意儿。但是,要整知识内容的话又很麻烦和费笔墨,因此,自行去网上找相关资料学习(现在简单了解一下可以直接去这里:https://www.cnblogs.com/chanshuyi/category/1862951.html)。
- 诊断问题:通过分析工具,诊断问题产生的原因。
- 修复问题:调整JVM参数 或 修复源代码中的问题。
- 测试验证:在测试环境运行之后获得GC数据,验证问题是否解决。
常见的GC模式:可通过该情况大致判定自己的GC情况是属于哪一种,从而更快知道是什么类型原因导致的。
- 正常情况
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,存留的对象较少
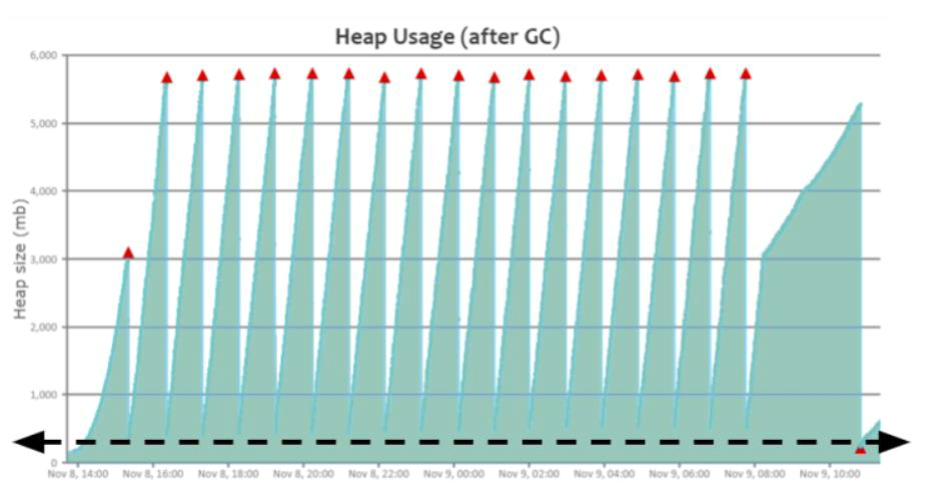
- 缓存对象过多
特点:呈现锯齿状,对象创建之后内存上升,一旦发生垃圾回收之后下降到底部,并且每次下降之后的内存大小接近,处于比较高的位置。
问题产生原因: 程序中保存了大量的缓存对象,导致GC之后无法释放,可以使用MAT或者HeapHero等工具进行分析内存占用的原因。
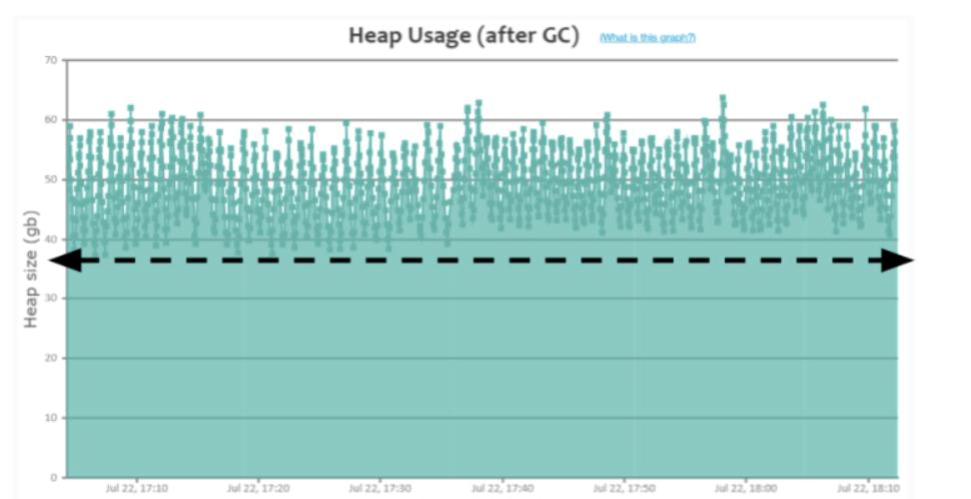
- 内存泄漏
特点:呈现锯齿状,每次垃圾回收之后下降到的内存位置越来越高,最后由于垃圾回收无法释放空间导致对象无法分配产生OutOfMemory的错误。
问题产生原因: 程序中保存了大量的内存泄漏对象,导致GC之后无法释放,可以使用MAT或者HeapHero等工具进行分析是哪些对象产生了内存泄漏。
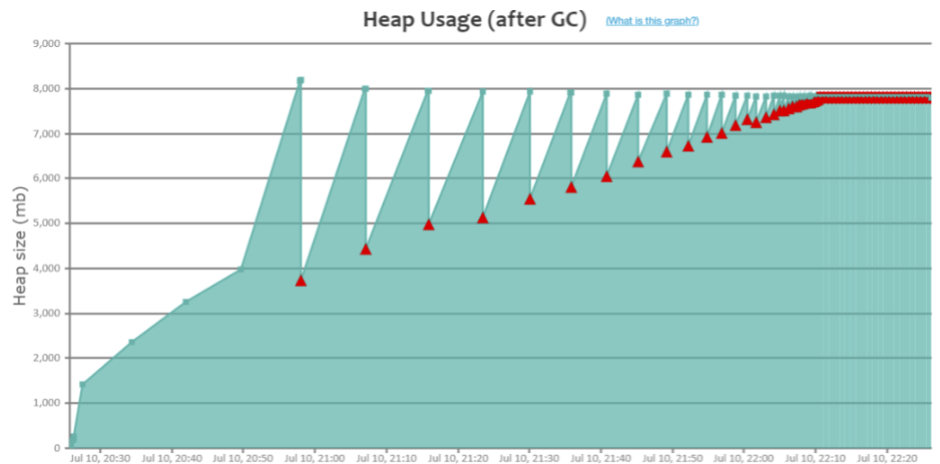
- 持续的Full GC
特点:在某个时间点产生多次Full GC,CPU使用率同时飙高,用户请求基本无法处理。一段时间之后恢复正常。
问题产生原因: 在该时间范围请求量激增,程序开始生成更多对象,同时垃圾收集无法跟上对象创建速率,导致持续地在进行Full GC。GC分析报告。
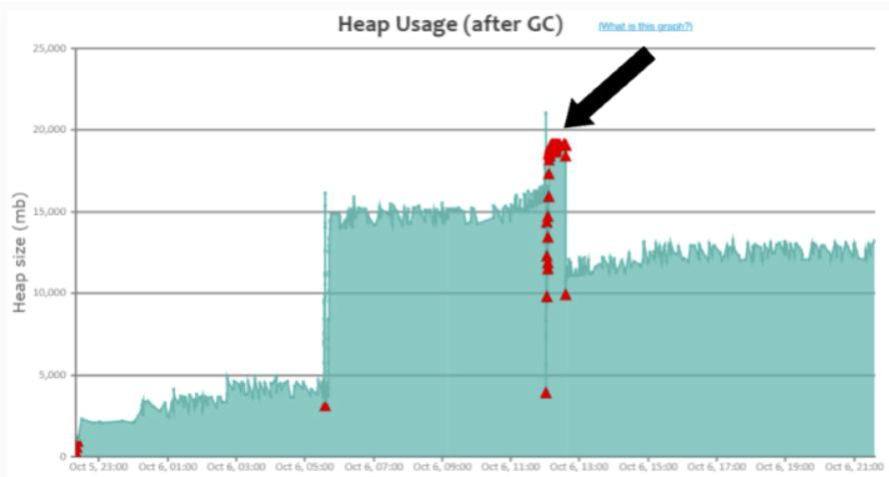
- 元空间不足导致的Full GC
特点:堆内存的大小并不是特别大,但是持续发生Full GC。
问题产生原因: 元空间大小不足(对象创建的速度比垃圾回收的速度快),导致持续FULLGC回收元空间的数据。GC分析报告。
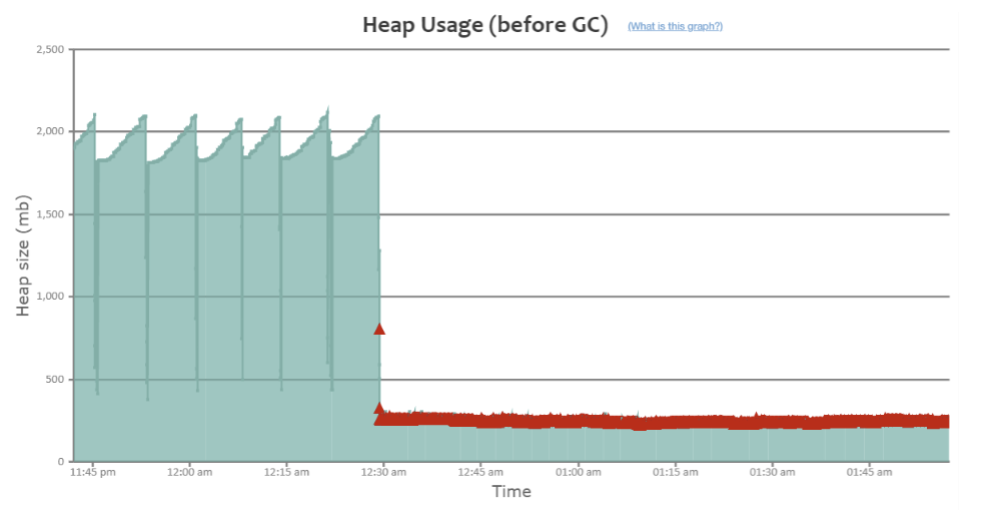
解决GC问题的手段
下面前三种是比较推荐的手段,第四种仅在前三种无法解决时选用:
- 优化基础JVM参数:基础JVM参数的设置不当,会导致频繁 FULL GC的产生。
- 减少对象产生:大多数场景下的FULL GC是由于对象产生速度过快导致的, 减少对象产生可以有效的缓解FULL GC的发生。这个解决方式去看前面:Java内存问题排查。
- 更换垃圾回收器:选择适合当前业务场景的垃圾回收器,减少延迟、提高吞吐量。这个解决方式去看前面的:垃圾回收器。
- 优化垃圾回收器参数:优化垃圾回收器的参数, 能在一定程度上提升GC 效率。
优化基础JVM参数
JVM参数
怎么找JDK对应版本所支持的所有JVM参数?
- 进入网址选择自己要的JDK版本:https://docs.oracle.com/en/java/javase/index.html
- 找到JavaSE Tools Reference:版本不同名字有区别,基本都是这个名字 或者 Tools -> [JDK] Tools Reference / Specifications。
- 找到 java选项 点进去即可。
下列是JDK8的常见JVM参数说。
- -Xmx 和 –Xms
-Xmx参数:设置的是最大堆内存,但是由于程序是运行在服务器或者容器上,计算可用内存时,要将元空间、操作系统、其它软件占用的内存排除掉。

如: 服务器内存4G,操作系统+元空间最大值+其它软件占用1.5G,所以4G - 1.5G = 2.5G,因此该值设置为 -Xmx2g 即可。
注:最合理的设置方式应该是根据最大并发量估算服务器的配置,然后再根据服务器配置计算最大堆内存的值。
-Xms参数:用来设置初始堆大小,建议将-Xms设置的和-Xmx一样大,有以下几点好处:
- 运行时性能更好:堆的扩容是需要向操作系统申请内存的,这样会导致程序性能短期下降。
- 可用性问题:如果在扩容时其他程序正在使用大量内存,很容易因为操作系统内存不足分配失败。
- 启动速度更快:Oracle官方文档 的原话:如果初始堆太小,Java 应用程序启动会变得很慢,因为 JVM 被迫频繁执行垃圾收集,直到堆增长到更合理的大小。为了获得最佳启动性能,请将初始堆大小设置为与最大堆大小相同。
- -Xss:虚拟机栈大小
# 示例
-Xss256k
如果我们不指定栈的大小,JVM 将创建一个具有默认大小的栈。大小取决于操作系统和计算机的体系结构。比如Linux x86 64位:1MB,如果不需要用到这么大的栈内存,完全可以将此值调小节省内存空间,合理值为 256k – 1m之间。
由于JVM底层设计极为复杂,一个参数的调整也许让某个接口得益,但同样有可能影响其他更多接口。因此接下来的参数不建议手动调整。
- -Xmn:年轻代的大小,默认值为整个堆的1/3
调整此参数的目的:可以根据峰值流量计算最大的年轻代大小,尽量让对象只存放在年轻代,不进入老年代。
但是实际的场景中,接口的响应时间、创建对象的大小、程序内部还会有一些定时任务等不确定因素都会导致这个值的大小。并不能仅凭计算得出,如果设置该值则要进行大量的测试。G1垃圾回收器尽量不要设置该值,G1会动态调整年轻代的大小。

- -XX:NewRatio:设置新生代与老年代比值。默认值为2
-XX:NewRatio=4 表示新生代与老年代所占比例为1:4 ,新生代占比整个堆的五分之一。如果设置了-Xmn的情况下,该参数是不需要在设置的。
- -XX:MaxMetaspaceSize 和 –XX:MetaspaceSize
-XX:MaxMetaspaceSize=值 参数:指的是最大元空间大小,默认值比较大,如果出现元空间内存泄漏会让操作系统可用内存不可控,建议根据测试情况设置最大值,一般设置为256m。
-XX:MetaspaceSize=值 参数:指的是到达这个值之后会触发Full GC(不是元空间初始大小), 后续什么时候再触发JVM会自行计算。如果设置为和MaxMetaspaceSize一样大,就不会Full GC,但是元空间中能回收的对象也无法回收。
- -XX:MaxTenuringThreshold:最大晋升阈值。年龄大于此值之后,会进入老年代。另外JVM有动态年龄判断机制:将年龄从小到大的对象占据的空间加起来,如果大于survivor区域的50%,然后把等于或大于该年龄的对象, 放入到老年代。
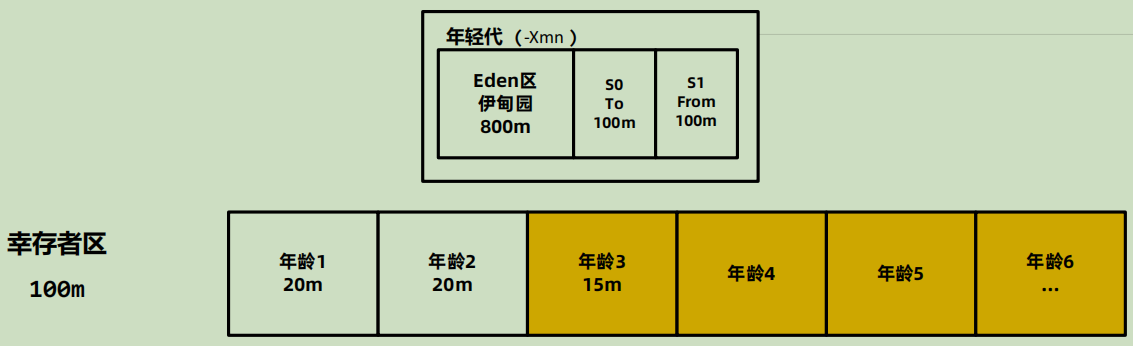
- -XX:SurvivorRatio:伊甸园区和幸存者区的大小比例,默认值为8。
两个Subrvivor区与一个Eden区的比值为2:8,一个Survivor区占整个新生代的十分之一。
- -XX:+AggressiveOpts:编译速度加快
Oracle官网 原话:允许使用积极的性能优化功能,预计这些功能将在即将发布的版本中成为默认功能。默认情况下,此选项处于禁用状态,并且不使用实验性性能功能。
垃圾回收参数
-XX:+UseSerialGC:新生代、老年代都使用串行回收器。现在基本很少使用。
-XX:+UseParNewGC:新生代使用ParNew(多线程 / 并行)回收器, 老年代使用串行回收器(即Serial Old)。
默认开启的线程数量与 CPU 数量相同,可以使用 -XX:ParallelGCThreads 参数来设置线程数。
- -XX:+UseConcMarkSweepGC:新生代使用并行(ParNew),老年代使用CMS。
- -XX:+UseCmsInitiatingOccupancyOnly:使用手动触发或者自定义触发cms 收集,同时也会禁止hostspot 自行触发CMS GC。默认情况下,此选项被禁用。
- -XX:CMSInitiatingOccupancyFraction:老年代大小达到了百分之几的阈值后自动进行CMS回收老年代。在JDK8中,此参数默认值是-1。
注意:该参数设置完是不会生效的,必须开启
-XX:+UseCmsInitiatingOccupancyOnly参数。同时:该参数是通过另外几个参数计算出的阈值
- ((100 - MinHeapFreeRatio)+(double)(CMSTriggerRatio * MinHeapFreeRatio)/ 100.0)
# 示例:老年代占用率使用了 20%:则使用CMS回收老年代
-XX:CMSInitiatingOccupancyFraction=20
- -XX:MinHeapFreeRatio:GC后允许的最小可用堆空间百分比。如果可用堆空间低于该值,则堆将被扩展。JDK8中默认值为 40%。
-XX:+PrintFlagsInitial参数:显示在处理参数之前所有可设置的参数及它们的值,然后直接退出程序。
# 示例:将最小空闲堆比率设置为 25%:
-XX:MinHeapFreeRatio=25
- -XX:CMSTriggerRatio:设置在 CMS 收集周期开始之前分配的
-XX:MinHeapFreeRatio指定值的百分比。JDK8中此值默认值为80%。
-XX:CMSTriggerRatio=75
- -XX:+DisableExplicitGC:禁止在代码中使用System.gc()
System.gc()可能会引起Full GC,在代码中尽量不要使用。使用 DisableExplicitGC参数可以禁止使用System.gc()方法调用。
-XX:+HeapDumpOnOutOfMemoryError:发生OutOfMemoryError错误时,自动生成hprof内存快照文件。
-XX:HeapDumpPath=:指定hprof文件的输出路径。打印GC日志
JDK8及之前 : -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:文件路径
JDK9及之后 : -Xlog:gc*:file=文件路径
-XX:+PrintGCDateStamps:将时间和日期也加入到GC日志中。默认是禁用的
参数模板:
-Xms1g # 初始堆内存1g
-Xmx1g # 最大堆内存1g
-Xss256k # 每个线程的栈内存最大256k
-XX:MaxMetaspaceSize=512m # 最大元空间大小512m
-XX:+DisableExplicitGC # 代码中System.gc()无效
-XX:+HeapDumpOnOutOfMemoryError # OutOfMemory错误时生成堆内存快照
-XX:HeapDumpPath=/opt/dumps/my-service.hprof # 堆内存快照生成位置
-XX:+PrintGCDetails # 打印详细垃圾回收日志
-XX:+PrintGCDateStamps # 打印垃圾回收时间
-Xloggc:文件路径 # 日志文件输出位置
注意:
- JDK9及之后gc日志输出修改为
-Xlog:gc*:file=文件名。 - 堆内存大小和栈内存大小根据实际情况灵活调整。
性能调优
这里面的内容其实在前面知识体系中已经概括进去了,这里单独弄出来方便初学者理清思路。
性能调优的思路
和内存排查、GC调优思路差不多。因为修复问题和测试验证需要具体开发场景演示,因此这里主要说明发现问题和诊断问题。
- 发现问题:通过监控、测试工具发现性能问题。
- 诊断问题:通过分析工具定位到某一部分代码存在的性能问题。
- 修复问题:内存调优、GC调优、业务代码优化、SQL优化、架构优化等等。
- 测试验证:在测试环境运行之后验证问题是否解决。
较常见的性能问题现象
- CPU占有率高:通过top命令查看CPU占用率高,接近100甚至多核CPU下超过100都是有可能的。
- 服务处理时间特别长:请求单个服务处理时间特别长,多服务(微服务)可以直接使用 Apache SkyWalking 等监控系统来判断是哪一个环节性能低下。这个问题可以直接去前面的Arthas的实践内容:重要:找到最耗时的方法调用?
- 线程被耗尽问题:程序启动之后运行正常,但是在运行一段时间之后无法处理任何的请求(内存和GC正常)。
线程转储(Thread Dump):对所有运行中的线程当前状态的快照。
线程转储可以通过jstack、visualvm等工具获取。其中包含了线程名、优先级、线程ID、线程状态、线程栈信息等等内容,可以用来解决CPU占用率高、死锁等问题。

线程转储(Thread Dump)中的几个核心内容:
- 名称: 线程名称,通过给线程设置合适的名称更容易“见名知意”。
- 优先级(prio):线程的优先级。
- Java ID(tid):JVM中线程的唯一ID。
- 本地 ID (nid):操作系统分配给线程的唯一ID。
- 状态:线程的状态,分为
- NEW – 新创建的线程,尚未开始执行。
- RUNNABLE –正在运行或准备执行。
- BLOCKED – 等待获取监视器锁以进入或重新进入同步块/方法。
- WAITING – 等待其他线程执行特定操作,没有时间限制。
- TIMED_WAITING – 等待其他线程在指定时间内执行特定操作。
- TERMINATED – 已完成执行
- 栈追踪: 显示整个方法的栈帧信息
线程转储的可视化在线分析平台:
CPU占有率高问题的大致思路
这里说明的是最基础的一种,也很麻烦的方式,只起引导思路的作用。
- 通过
top –c命令找到CPU占用率高的进程,获取它的进程ID。

- 使用
top -p 进程ID单独监控某个进程,按H查看所有的线程以及线程对应的CPU使用率,找到CPU使用率特别高的线程,获取此线程的线程ID(即下图PID,上一步获取的是进程ID,这里查看的是某进程的所有线程)。
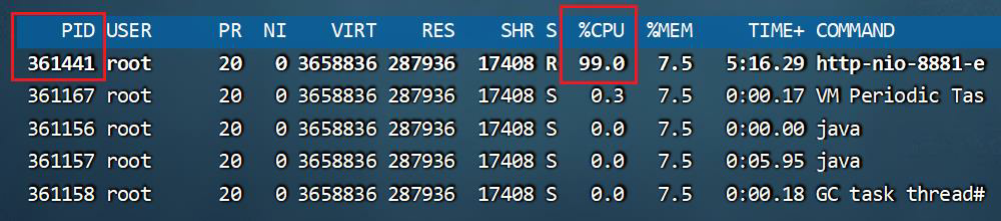
- 使用
jstack 进程ID命令查看所有线程正在执行的栈信息。使用jstack 进 程ID > 文件名保存到文件中方便查看。

- 找到nid与线程ID相同的栈信息,从而就可以找到栈信息对应的源代码位置了。
注意:需要将之前记录下的十进制线程ID号(第2步获取的)转换成16进制。
可以通过计算器,也可以通过
printf ‘%x\n’ 线程ID命令直接获得16进制下的线程ID。
另外什么更简单、方法嵌套排查、性能问题等等直接去前面的Arthas的内容:Arthas场景实战。
线程被耗尽问题
线程耗尽问题:程序在启动运行一段时间之后,就无法接受任何请求了。将程序重启之后继续运行,依然会出现相同的情况。
线程耗尽问题,一般是由于执行时间过长:
- 检测是否有死锁产生,无法自动解除的死锁会将线程永远阻塞。
- 若无死锁,再使用前面“CPU占有率高的问题”中的打印线程栈的方法检测线程正在执行哪个方法,一般这些大量出现的方法就是慢方法。
线程死锁问题的定位方式
- 第一种方式(适合线上环境):
jstack -l 进程ID > 文件名将线程栈保存到本地。在文件中搜索"deadlock"即可找到死锁位置。 - 第二种方式(适合开发与测试环境使用):使用visual vm或者Jconsole工具。可以自动检测出死锁问题。生产环境这种方式一般没相应权限。
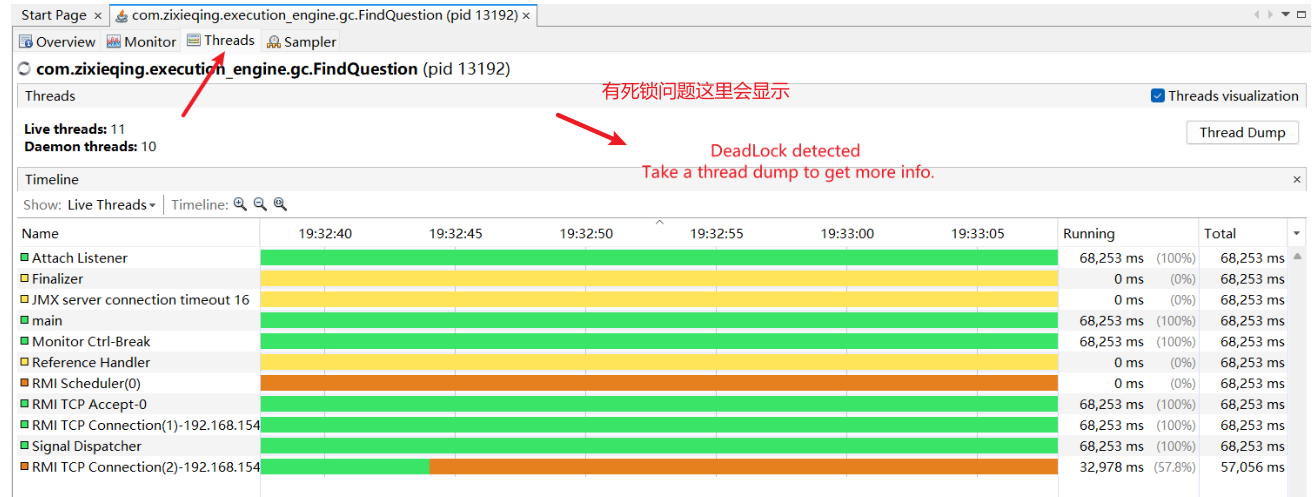
- 第三种方式(适合开发与测试环境):生成线程转储文件(Thread Dump),然后使用 fastthread 自动检测线程问题
如何准确判断一个方法耗时多久
这个问题会想到什么方式?
- 方法上打印开始时间和结束时间,他们的差值就是方法的执行耗时。
- 通过postman或者jmeter发起一笔请求,在控制台上看输出的时间。或者使用前面Arthas的 重要:找到最耗时的方法调用?trace。
这样做是不准确的。
第一:测试时有些对象创建是懒加载的,所以会影响第一次的请求时间;
第二:因为虚拟机中JIT(即时编译器)会优化你的代码,所以上面的测试方式得出的时间并不一定是最终用户处理的时间。
OpenJDK中提供了一款叫 JMH(Java Microbenchmark Harness)的工具,可以准确地对Java代码进行基准测试,量化方法的执行性能。
JMH会首先执行预热过程,确保JIT对代码进行优化之后再进行真正的迭代测试,最后输出测试的结果。
简单搭建JMH环境
- 依赖:版本看GitHub官网 JMH
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
<scope>test</scope>
</dependency>
- 编写测试代码
import org.openjdk.jmh.annotations.*;
import java.util.concurrent.TimeUnit;
// 会将测试方法(@Benchmark标识的方法)执行5轮预热,每次持续1秒
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
// 启动多少个进程 jvmArgsAppend追加JVM参数
@Fork(value = 1, jvmArgsAppend = {"-Xms1g", "-Xmx1g"})
// 指定显示结果 可选:平均时间(Mode.AverageTime 单位纳秒)、吞吐量(Mode.Throughput)、所有内容(Mode.All)等
@BenchmarkMode(Mode.AverageTime)
// 指定显示结果的单位 方法执行时间快就纳秒、慢就毫秒.........
@OutputTimeUnit(TimeUnit.NANOSECONDS)
// 变量共享范围 整个测试环境中共享(Scope.Benchmark)、单个线程中共享(Scope.Thread)
@State(Scope.Benchmark)
public class HelloWorldBench {
@Benchmark // 标志是一个测试方法
public int test1() {
int i = 0;
i++;
/*
* 需要将变量返回。因为上面的i没用(即:死代码),所以JIT就会将其去掉,从而造成实际测试时间的出入
*
* 要是有多个变量怎么做?
* 使用黑洞方法:new Blackhole().consume(...variable);
* */
return i;
}
}
- 开始测试
测试结果可以通过 https://jmh.morethan.io/ 转为可视化。格式是JSON格式(
new OptionsBuilder().resultFormat(ResultFormatType.JSON)可以构建为JSON格式)
方式一(推荐):通过maven的verify命令,检测代码问题并打包成jar包。然后通过 java -jar 打成的jar包 命令执行基准测试。
方式二:使用Java代码。但是,这种方式测试出来的时间会有出入。
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
// 要测试的类
.include(HelloWorldBench.class.getSimpleName())
// 结果的格式
.resultFormat(ResultFormatType.JSON)
// 启用多少进程(当前main方法使用) jar就是用类上的@Fork(value = 1, jvmArgsAppend = {"-Xms1g", "-Xmx1g"})
.forks(1)
.build();
new Runner(opt).run();
}
更多openjdk jmh专业场景示例去官网:jmh-samples
综合案例:Java层面性能调优思路
- 假设从数据库获取的数据如下
package com.zixieqing.jvmoptimize.performance.practice.dao.impl;
import com.zixieqing.jvmoptimize.performance.practice.dao.UserDao;
import com.zixieqing.jvmoptimize.performance.practice.entity.UserDetails;
import org.springframework.stereotype.Repository;
import javax.annotation.PostConstruct;
import java.time.LocalDateTime;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
@Repository
public class UserDaoImpl implements UserDao {
// 提前准备好数据
private List<UserDetails> users = new ArrayList<>();
@PostConstruct
public void init(){
// 初始化时生成数据 这里模拟获取的数据很多
for (int i = 1; i <= 10000; i++) {
users.add(new UserDetails((long) i, LocalDateTime.now(),new Date()));
}
}
/*
模拟下数据库查询接口,主要目的是只优化Java代码,屏蔽SQL相关的内容
*/
@Override
public List<UserDetails> findUsers() {
return users;
}
}
package com.zixieqing.jvmoptimize.performance.practice.service.impl;
import com.zixieqing.jvmoptimize.performance.practice.dao.UserDao;
import com.zixieqing.jvmoptimize.performance.practice.entity.User;
import com.zixieqing.jvmoptimize.performance.practice.entity.UserDetails;
import com.zixieqing.jvmoptimize.performance.practice.service.UserService;
import org.apache.commons.lang3.RandomStringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
@Service
public class UserServiceImpl implements UserService {
private List<User> users = new ArrayList<>();
@PostConstruct
public void init(){
// 初始化时生成数据
for (int i = 1; i <= 10000; i++) {
users.add(new User((long) i, RandomStringUtils.randomAlphabetic(10)));
}
}
@Autowired
private UserDao userDao;
@Override
public List<UserDetails> getUserDetails() {
return userDao.findUsers();
}
@Override
public List<User> getUsers() {
return users;
}
}
- 假设服务器中程序员写的代码如下,还未优化
package com.zixieqing.jvmoptimize.performance.practice.controller;
import com.zixieqing.jvmoptimize.performance.practice.entity.User;
import com.zixieqing.jvmoptimize.performance.practice.entity.UserDetails;
import com.zixieqing.jvmoptimize.performance.practice.service.UserService;
import com.zixieqing.jvmoptimize.performance.practice.vo.UserVO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.text.SimpleDateFormat;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/puser")
public class UserController {
@Autowired
private UserService userService;
private final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 初始代码
public List<UserVO> user1(){
// 1.从数据库获取前端需要的详情数据
List<UserDetails> userDetails = userService.getUserDetails();
// 2.获取缓存中的用户数据
List<User> users = userService.getUsers();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 3.遍历详情集合,从缓存中获取用户名,生成VO进行填充
ArrayList<UserVO> userVOS = new ArrayList<>();
// 嵌套循环
for (UserDetails userDetail : userDetails) {
UserVO userVO = new UserVO();
// 可以使用BeanUtils对象拷贝
userVO.setId(userDetail.getId());
userVO.setRegister(simpleDateFormat.format(userDetail.getRegister2()));
// 填充name
for (User user : users) {
if(user.getId().equals(userDetail.getId())){
userVO.setName(user.getName());
}
}
// 加入集合
userVOS.add(userVO);
}
return userVOS;
}
}
- 使用Arthas的trace定位性能
# trace 类名 方法名 --skipJDKMethod false
trace com.zixieqing.jvmoptimize.performance.practice.controller.UserController user1 --skipJDKMethod false

发现问题就出在上面的循环嵌套里面(第2步user1()方法),共循环了(count)100 0000次。
通过多次对2中代码的优化、多次3的测试,发现的问题如下:
- 两次循环,则减少循环次数:去掉内层循环,使用map
// 2.获取缓存中的用户数据
List<User> users = userService.getUsers();
// 将list转换成hashmap
HashMap<Long, User> map = new HashMap<>();
for (User user : users) {
map.put(user.getId(), user);
}
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 3.遍历详情集合,从缓存中获取用户名,生成VO进行填充
ArrayList<UserVO> userVOS = new ArrayList<>();
for (UserDetails userDetail : userDetails) {
UserVO userVO = new UserVO();
// 可以使用BeanUtils对象拷贝
userVO.setId(userDetail.getId());
userVO.setRegister(simpleDateFormat.format(userDetail.getRegister2()));
// 填充name
userVO.setName(map.get(userDetail.getId()).getName());
// 加入集合
userVOS.add(userVO);
}
- 优化日期格式化:
Date对象(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());):的SimpleDateFormatter是线程不安全的,所以每次需要重新创建对象。优化的方式:将对象放入ThreadLocal中进行保存。
LocalDateTime对象(LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));):DateTimeFormatter线程安全,并且性能较好。
测试代码:
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.text.SimpleDateFormat;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Date;
import java.util.concurrent.TimeUnit;
// 执行5轮预热,每次持续1秒
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
// 执行一次测试
@Fork(value = 1, jvmArgsAppend = {"-Xms1g", "-Xmx1g"})
// 显示平均时间,单位纳秒
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.NANOSECONDS)
@State(Scope.Thread)
public class DateBench {
private static String sDateFormatString = "yyyy-MM-dd HH:mm:ss";
private Date date = new Date();
private LocalDateTime localDateTime = LocalDateTime.now();
private static ThreadLocal<SimpleDateFormat> simpleDateFormatThreadLocal = new ThreadLocal();
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Setup
public void setUp() {
SimpleDateFormat sdf = new SimpleDateFormat(sDateFormatString);
simpleDateFormatThreadLocal.set(sdf);
}
@Benchmark
public String date() {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat(sDateFormatString);
return simpleDateFormat.format(date);
}
@Benchmark
public String localDateTime() {
return localDateTime.format(formatter);
}
@Benchmark
public String localDateTimeNotSave() {
return localDateTime.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
}
@Benchmark
public String dateThreadLocal() {
return simpleDateFormatThreadLocal.get().format(date);
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(DateBench.class.getSimpleName())
.resultFormat(ResultFormatType.JSON)
.forks(1)
.build();
new Runner(opt).run();
}
}
将JSON结果用 https://jmh.morethan.io/ 转为可视化的对比结果如下:
可见如下方式的LocalDateTime胜出:
private LocalDateTime localDateTime = LocalDateTime.now();
private static final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
@Benchmark
public String localDateTime() {
return localDateTime.format(formatter);
}
- 使用并发流(
xxxx.parallelStream(),xxxxx.Stream()的方式性能低)优化外层循环
所以经过上面的优化之后,源代码就被优化为如下的形式:
package com.zixieqing.jvmoptimize.performance.practice.controller;
import com.zixieqing.jvmoptimize.performance.practice.entity.User;
import com.zixieqing.jvmoptimize.performance.practice.entity.UserDetails;
import com.zixieqing.jvmoptimize.performance.practice.service.UserService;
import com.zixieqing.jvmoptimize.performance.practice.vo.UserVO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.text.SimpleDateFormat;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/puser")
public class UserController {
@Autowired
private UserService userService;
private final DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// 初始代码
// public List<UserVO> user1() {
// // 1.从数据库获取前端需要的详情数据
// List<UserDetails> userDetails = userService.getUserDetails();
//
// // 2.获取缓存中的用户数据
// List<User> users = userService.getUsers();
//
// SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// // 3.遍历详情集合,从缓存中获取用户名,生成VO进行填充
// ArrayList<UserVO> userVOS = new ArrayList<>();
// for (UserDetails userDetail : userDetails) {
// UserVO userVO = new UserVO();
// // 可以使用BeanUtils对象拷贝
// userVO.setId(userDetail.getId());
// userVO.setRegister(simpleDateFormat.format(userDetail.getRegister2()));
// // 填充name
// for (User user : users) {
// if (user.getId().equals(userDetail.getId())) {
// userVO.setName(user.getName());
// }
// }
// // 加入集合
// userVOS.add(userVO);
// }
//
// return userVOS;
//
// }
// 使用并行流优化性能
public List<UserVO> user5() {
// 1.从数据库获取前端需要的详情数据
List<UserDetails> userDetails = userService.getUserDetails();
// 2.获取缓存中的用户数据
List<User> users = userService.getUsers();
// 将list转换成hashmap
Map<Long, User> map = users.parallelStream().collect(Collectors.toMap(User::getId, o -> o));
// 3.遍历详情集合,从缓存中获取用户名,生成VO进行填充
return userDetails.parallelStream().map(userDetail -> {
UserVO userVO = new UserVO();
// 可以使用BeanUtils对象拷贝
userVO.setId(userDetail.getId());
userVO.setRegister(userDetail.getRegister().format(formatter));
// 填充name
userVO.setName(map.get(userDetail.getId()).getName());
return userVO;
}).collect(Collectors.toList());
}
}
- JMH再次测试
package com.zixieqing.jvmoptimize;
import com.zixieqing.jvmoptimize.performance.practice.controller.UserController;
import org.junit.jupiter.api.Test;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import org.springframework.boot.SpringApplication;
import org.springframework.context.ApplicationContext;
import java.io.IOException;
import java.util.concurrent.TimeUnit;
// 执行5轮预热,每次持续1秒
@Warmup(iterations = 5, time = 1, timeUnit = TimeUnit.SECONDS)
// 执行一次测试
@Fork(value = 1, jvmArgsAppend = {"-Xms1g", "-Xmx1g"})
// 显示平均时间,单位纳秒
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Benchmark)
public class PracticeBenchmarkTest {
private UserController userController;
private ApplicationContext context;
// 初始化将springboot容器启动 端口号随机
@Setup
public void setup() {
this.context = new SpringApplication(JvmOptimizeApplication.class).run();
userController = this.context.getBean(UserController.class);
}
// 启动这个测试用例进行测试
@Test
public void executeJmhRunner() throws RunnerException, IOException {
new Runner(new OptionsBuilder()
.shouldDoGC(true)
.forks(0)
.resultFormat(ResultFormatType.JSON)
.shouldFailOnError(true)
.build()).run();
}
// 用黑洞消费数据,避免JIT消除代码
@Benchmark
public void test1(final Blackhole bh) {
bh.consume(userController.user1());
}
@Benchmark
public void test2(final Blackhole bh) {
bh.consume(userController.user2());
}
@Benchmark
public void test3(final Blackhole bh) {
bh.consume(userController.user3());
}
@Benchmark
public void test4(final Blackhole bh) {
bh.consume(userController.user4());
}
@Benchmark
public void test5(final Blackhole bh) {
bh.consume(userController.user5());
}
}
JMH测试对比结果如下:
若是需要再提升,追求更高的性能、更小的CPU和内存开销,则可以使用Oracle提供的另一款高性能JDK:GraalVM 。这玩意儿有两种模式:
JIT(Just-In-Time)模式:可跨平台,就是“一次编写,到处运行”。预热之后,通过内置的Graal即时编译器优化热点代码,生成比Hotspot JIT更高性能的机器码。这种模式提高性能,社区版对CPU占有率和内存提高不明显(企业版有显著提高)。
AOP(Ahead-Of-Time)模式:不可跨平台,而是为特定平台创建可执行文件,本质是本地镜像(Native Image)。这种模式对启动速度、CPU、内存开销都有了显著提高。但是此模式也有另外问题:
- 跨平台问题:在不同平台下运行需要编译多次。编译平台的依赖库等环境要与运行平台保持一致。
- 消耗大量的CPU和内存:使用框架之后,编译本地镜像的时间比较长,同时也需要消耗大量的CPU和内存。
- AOT 编译器在编译时,需要知道运行时所有可访问的所有类。但是Java中有一些技术可以在运行时创建类,例如反射、动态代理等。这些技术在很多框架比如Spring中大量使用,所以框架需要对AOT编译器进行适配解决类似的问题。
GraalVM的使用场景:传统的系统架构有人力、机房开销大;流量激增需要大量服务器,流量过后很多服务器就闲置造成资源浪费,而因为虚拟化技术、云原生技术,所以GraalVM+云服务商提供的Serverless无服务器化架构就是其使用场景了。
对应MD文档
JVM(Java虚拟机)整理(二):排错调优的更多相关文章
- 如何利用JConsole观察分析Java程序的运行并进行排错调优_java
如何利用JConsole观察分析Java程序的运行并进行排错调优_java 官方指导 use jconsole use jmx technology
- Java虚拟机性能监控与调优实战
From: https://c.m.163.com/news/a/D7B0C6Q40511PFUO.html?spss=newsapp&fromhistory=1 Java虚拟机性能监控与调 ...
- 实战Java虚拟机之二“虚拟机的工作模式”
今天开始实战Java虚拟机之二:“虚拟机的工作模式”. 总计有5个系列 实战Java虚拟机之一“堆溢出处理” 实战Java虚拟机之二“虚拟机的工作模式” 实战Java虚拟机之三“G1的新生代GC” 实 ...
- Java虚拟机(二):JVM内存模型
所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?其实如果你经常解决服务器性能问题,那么这些问 ...
- Java 虚拟机系列二:垃圾收集机制详解,动图帮你理解
前言 上篇文章已经给大家介绍了 JVM 的架构和运行时数据区 (内存区域),本篇文章将给大家介绍 JVM 的重点内容--垃圾收集.众所周知,相比 C / C++ 等语言,Java 可以省去手动管理内存 ...
- 从头捋捋jvm(-java虚拟机)
jvm 是Java Virtual Machine(Java虚拟机)的缩写,java 虚拟机作为一种跨平台的软件是作用于操作系统之上的,那么认识并了解它的底层运行逻辑对于java开发人员来说很有必要! ...
- JVM,Java虚拟机基础知识新手入门教程(超级通熟易懂)
作者:请叫我红领巾,转载请注明出处http://www.cnblogs.com/xxzhuang/p/7453746.html,简书地址:http://www.jianshu.com/p/b963b3 ...
- 深入学习重点分析java基础---第一章:深入理解jvm(java虚拟机) 第一节 java内存模型及gc策略
身为一个java程序员如果只会使用而不知原理称其为初级java程序员,知晓原理而升中级.融会贯通则为高级 作为有一个有技术追求的人,应当利用业余时间及零碎时间了解原理 近期在看深入理解java虚拟机 ...
- (转)JVM——Java虚拟机架构
背景:最近开始忙着找工作了,把需要储备的知识再整理总结一遍!关于JVM的总结,是转自下面的连接.结合<深入理解java虚拟机>,看起来有更清晰的认识. 转载自:http://blog.cs ...
- Java虚拟机(二):Java GC算法 垃圾收集器
概述 垃圾收集 Garbage Collection 通常被称为“GC”,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了. jvm 中,程序计数器.虚拟机栈.本地方 ...
随机推荐
- kali 的 vim 中不能粘贴复制
kali 的 vim 中不能粘贴复制 进入 vim 命令行模式,输入 :set mouse=c 之后可以正常粘贴复制
- Mac Docker 挂载数据卷失败
问题描述: docker: Error response from daemon: Mounts denied: The path /srv/docker/bind is not shared fro ...
- homebrew的安装和使用
目录 背景 安装xcode 安装homebrew 有关报错解决 卸载脚本 homebrew软件搜索 brew 常用命令 brew redis安装 PhpWebStudy安装 安装php 背景 最近用b ...
- 08. C语言函数
[函数基础] 函数用于将程序代码分类管理,实现不同功能的代码放在不同函数内,一个函数等于一种功能,其它函数可以调用本函数执行. C语言规定所有的指令数据必须定义在函数内部,比如之前介绍的程序执行流程控 ...
- ts小知识
在引入enum枚举的时候不需要加type import type {a} from 'b'
- 数据驱动ddt安装3种方式_unittest_Python
命令行安装 pip install ddt -i 管理员运行命令提示符 pycharm设置里安装 pycharm Python Packages里安装
- 8.5考试总结(NOIP模拟31)[Game·Time·Cover]
我们总是在注意错过太多,却不注意自己拥有多少. 前言 考场上疯狂搞第一题,终于把人给搞没了.. T1 Game 解题思路 线段树+二分 总体来讲就是用线段树维护三个值: 没有产生贡献的 a(小 B 的 ...
- MySQL学习笔记-存储引擎
存储引擎 一. MySQL体系结构 MySQL Server 连接层:连接的处理.认证授权.安全方案.检查是否超过最大连接数等. 服务层:SQL接口.解析器.查询优化器.缓存 引擎层:引擎是数据存储和 ...
- css 跑马灯
html: <view class="in_scro"> <view class="in_scrview">恭喜139******1用户 ...
- IMX6ULL基本环境搭建
基本环境搭建 1 交叉编译工具 在虚拟机中安装交叉编译工具,为后续开发做准备. 1.1 工具版本 工具版本:Linaro Releases 当前虚拟机为64位系统,因此下载64位系统的工具: $ un ...