NLP技术如何为搜索引擎赋能
在全球化时代,搜索引擎不仅需要为用户提供准确的信息,还需理解多种语言和方言。本文详细探讨了搜索引擎如何通过NLP技术处理多语言和方言,确保为不同地区和文化的用户提供高质量的搜索结果,同时提供了基于PyTorch的实现示例,帮助您更深入地理解背后的技术细节。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. NLP关键词提取与匹配在搜索引擎中的应用
在自然语言处理(NLP)的领域中,搜索引擎的优化是一个长期研究的主题。其中,关键词提取与匹配是搜索引擎核心技术之一,它涉及从用户的查询中提取关键信息并与数据库中的文档进行匹配,以提供最相关的搜索结果。
1. 关键词提取
关键词提取是从文本中提取出最具代表性或重要性的词汇或短语的过程。
例子:
对于文本 "苹果公司是全球领先的技术公司,专注于设计和制造消费电子产品",可能的关键词包括 "苹果公司"、"技术" 和 "消费电子产品"。
2. 关键词匹配
关键词匹配涉及到将用户的查询中的关键词与数据库中的文档进行对比,找到最符合的匹配项。
例子:
当用户在搜索引擎中输入 "苹果公司的新产品" 时,搜索引擎会提取 "苹果公司" 和 "新产品" 作为关键词,并与数据库中的文档进行匹配,以找到相关的结果。
Python实现
以下是一个简单的Python实现,展示如何使用jieba库进行中文关键词提取,以及使用基于TF-IDF的方法进行关键词匹配。
import jieba
import jieba.analyse
# 关键词提取
def extract_keywords(text, topK=5):
keywords = jieba.analyse.extract_tags(text, topK=topK)
return keywords
# 例子
text = "苹果公司是全球领先的技术公司,专注于设计和制造消费电子产品"
print(extract_keywords(text))
# 关键词匹配(基于TF-IDF)
from sklearn.feature_extraction.text import TfidfVectorizer
# 假设有以下文档集合
docs = [
"苹果公司发布了新的iPhone",
"技术公司都在竞相开发新产品",
"消费电子产品市场日新月异"
]
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(docs)
# 对用户的查询进行匹配
query = "苹果公司的新产品"
response = vectorizer.transform([query])
# 计算匹配度
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarities = cosine_similarity(response, tfidf_matrix)
print(cosine_similarities)
这段代码首先使用jieba进行关键词提取,然后使用TF-IDF方法对用户的查询进行匹配,最后使用余弦相似度计算匹配度。
2. NLP语义搜索在搜索引擎中的应用
传统的关键词搜索主要基于文本的直接匹配,而没有考虑查询的深层含义。随着技术的发展,语义搜索已经成为现代搜索引擎的关键部分,它致力于理解用户查询的实际意图和上下文,以提供更为相关的搜索结果。
1. 语义搜索的定义
语义搜索是一种理解查询的语义或意图的搜索方法,而不仅仅是匹配关键词。它考虑了单词的同义词、近义词、上下文和其他相关性因素。
例子:
用户可能搜索 "苹果" 这个词,他们可能是想要找关于“苹果公司”的信息,也可能是想了解“苹果水果”的知识。基于语义的搜索引擎可以根据上下文或用户的历史数据来判断用户的真实意图。
2. 语义搜索的重要性
随着互联网信息的爆炸性增长,用户期望搜索引擎能够理解其复杂的查询意图,并提供最相关的结果。语义搜索不仅可以提高搜索结果的准确性,还可以增强用户体验,因为它能够提供与查询更为匹配的内容。
例子:
当用户查询 "如何烤一个苹果派" 时,他们期望得到的是烹饪方法或食谱,而不是关于“苹果”或“派”这两个词的定义。
Python/PyTorch实现
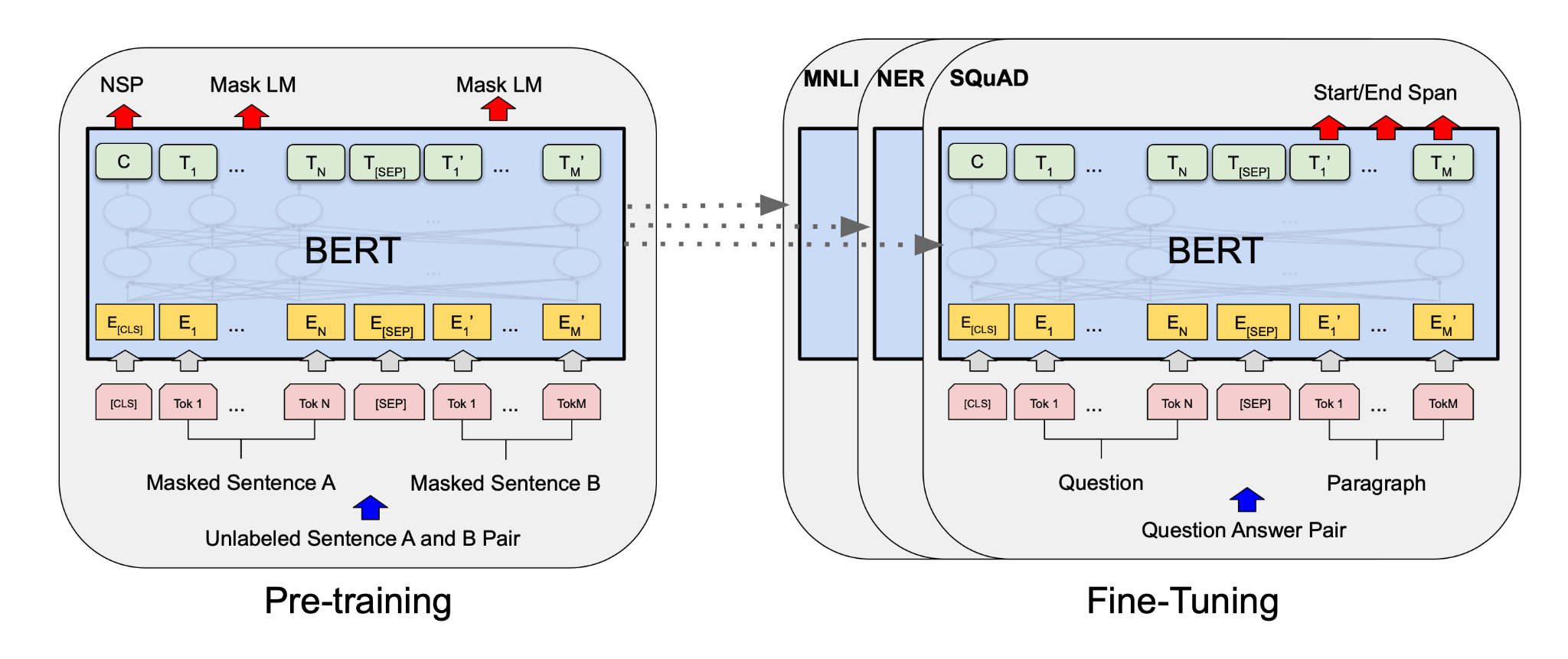
以下是一个基于PyTorch的简单语义搜索实现,我们将使用预训练的BERT模型来计算查询和文档之间的语义相似性。
import torch
from transformers import BertTokenizer, BertModel
from sklearn.metrics.pairwise import cosine_similarity
# 加载预训练的BERT模型和分词器
model_name = "bert-base-chinese"
model = BertModel.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
model.eval()
# 计算文本的BERT嵌入
def get_embedding(text):
tokens = tokenizer(text, return_tensors='pt', truncation=True, padding=True, max_length=512)
with torch.no_grad():
outputs = model(**tokens)
return outputs.last_hidden_state.mean(dim=1).squeeze().numpy()
# 假设有以下文档集合
docs = [
"苹果公司发布了新的iPhone",
"苹果是一种非常受欢迎的水果",
"很多人喜欢吃苹果派"
]
doc_embeddings = [get_embedding(doc) for doc in docs]
# 对用户的查询进行匹配
query = "告诉我一些关于苹果的信息"
query_embedding = get_embedding(query)
# 计算匹配度
cosine_similarities = cosine_similarity([query_embedding], doc_embeddings)
print(cosine_similarities)
在这段代码中,我们首先使用预训练的BERT模型来为文档和查询计算嵌入。然后,我们使用余弦相似度来比较查询和每个文档嵌入之间的相似性,从而得到最相关的文档。
3. NLP个性化搜索建议在搜索引擎中的应用
随着技术的进步和大数据的发展,搜索引擎不再满足于为所有用户提供相同的搜索建议。相反,它们开始提供个性化的搜索建议,以更好地满足每个用户的需求。
1. 个性化搜索建议的定义
个性化搜索建议是基于用户的历史行为、偏好和其他上下文信息为其提供的搜索建议,目的是为用户提供更为相关的搜索体验。
例子:
如果一个用户经常搜索“篮球比赛”的相关信息,那么当他下次输入“篮”时,搜索引擎可能会推荐“篮球比赛”、“篮球队”或“篮球新闻”等相关的搜索建议。
2. 个性化搜索建议的重要性
为用户提供个性化的搜索建议可以减少他们查找信息的时间,并提供更为准确的搜索结果。此外,个性化的建议也可以提高用户对搜索引擎的满意度和忠诚度。
例子:
当用户计划外出旅游并在搜索引擎中输入“旅”时,搜索引擎可能会根据该用户之前的旅游历史和偏好,推荐“海滩旅游”、“山区露营”或“城市观光”等相关建议。
Python实现
以下是一个简单的基于用户历史查询的个性化搜索建议的Python实现:
from collections import defaultdict
# 假设有以下用户的搜索历史
history = {
'user1': ['篮球比赛', '篮球新闻', 'NBA赛程'],
'user2': ['旅游景点', '山区旅游', '海滩度假'],
}
# 构建一个查询建议的库
suggestion_pool = {
'篮': ['篮球比赛', '篮球新闻', '篮球鞋', '篮球队'],
'旅': ['旅游景点', '山区旅游', '海滩度假', '旅游攻略'],
}
def personalized_suggestions(user, query_prefix):
common_suggestions = suggestion_pool.get(query_prefix, [])
user_history = history.get(user, [])
# 优先推荐用户的历史查询
personalized = [s for s in common_suggestions if s in user_history]
for s in common_suggestions:
if s not in personalized:
personalized.append(s)
return personalized
# 示例
user = 'user1'
query_prefix = '篮'
print(personalized_suggestions(user, query_prefix))
此代码首先定义了一个用户的历史查询和一个基于查询前缀的建议池。然后,当用户开始查询时,该函数将优先推荐与该用户历史查询相关的建议,然后再推荐其他普通建议。
4. NLP多语言和方言处理在搜索引擎中的应用
随着全球化的进程,搜索引擎需要处理各种语言和方言的查询。为了提供跨语言和方言的准确搜索结果,搜索引擎必须理解并适应多种语言的特点和差异。
1. 多语言处理的定义
多语言处理是指计算机程序或系统能够理解、解释和生成多种语言的能力。
例子:
当用户在英国搜索“手机”时,他们可能会使用“mobile phone”这个词;而在美国,用户可能会使用“cell phone”。
2. 方言处理的定义
方言处理是指对同一种语言中不同的方言或变种进行处理的能力。
例子:
在普通话中,“你好”是问候;而在广东话中,相同的问候是“你好吗”。
3. 多语言和方言处理的重要性
- 多样性: 世界上有数千种语言和方言,搜索引擎需要满足不同用户的需求。
- 文化差异: 语言和方言往往与文化紧密相关,正确的处理可以增强用户体验。
- 信息获取: 为了获取更广泛的信息,搜索引擎需要跨越语言和方言的障碍。
Python/PyTorch实现
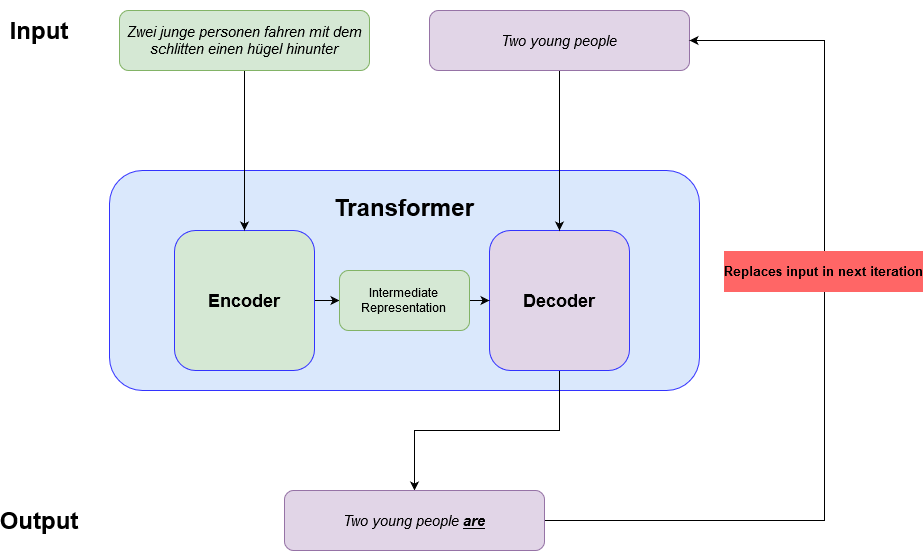
以下是一个基于PyTorch和transformers库的简单多语言翻译实现:
from transformers import MarianMTModel, MarianTokenizer
# 选择一个翻译模型,这里我们选择从英语到中文的模型
model_name = 'Helsinki-NLP/opus-mt-en-zh'
model = MarianMTModel.from_pretrained(model_name)
tokenizer = MarianTokenizer.from_pretrained(model_name)
def translate_text(text, target_language='zh'):
"""
翻译文本到目标语言
"""
# 对文本进行编码
encoded = tokenizer.encode(text, return_tensors="pt", max_length=512)
# 使用模型进行翻译
translated = model.generate(encoded)
# 将翻译结果转换为文本
return tokenizer.decode(translated[0], skip_special_tokens=True)
# 示例
english_text = "Hello, how are you?"
chinese_translation = translate_text(english_text)
print(chinese_translation)
这段代码使用了一个预训练的多语言翻译模型,可以将英文文本翻译为中文。通过使用不同的预训练模型,我们可以实现多种语言间的翻译。
5. 总结
随着信息时代的到来,搜索引擎已经成为我们日常生活中不可或缺的工具。但是,背后支持这一切的技术进步,特别是自然语言处理(NLP),往往被大多数用户所忽视。在我们深入探讨搜索引擎如何处理多语言和方言的过程中,可以看到这其中涉及的技术深度与广度。
语言,作为人类文明的基石,有着其独特的复杂性。不同的文化、历史和地理因素导致了语言和方言的多样性。因此,使得计算机理解和解释这种多样性成为了一项极具挑战性的任务。而搜索引擎正是在这样的挑战中,借助NLP技术,成功地为全球数亿用户提供了跨语言的搜索体验。
而其中最值得关注的,是这样的技术创新不仅仅满足了功能需求,更在无形中拉近了不同文化和地区之间的距离。当我们可以轻松地搜索和理解其他文化的信息时,人与人之间的理解和交流将更加流畅,这正是技术为社会带来的深远影响。
最后,我们不应该仅仅停留在技术的应用层面,更应该思考如何将这些技术与人文、社会和文化更紧密地结合起来,创造出真正有价值、有意义的解决方案。在未来的技术探索中,NLP将持续地为我们展示其无尽的可能性和魅力。

关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
NLP技术如何为搜索引擎赋能的更多相关文章
- 阿里NLP总监分享-NLP技术的应用与思考
https://yq.aliyun.com/articles/78031 NLP技术的应用及思考
- 解密优酷智能生产技术,看 AI 赋能内容数字化
2021 年,随着社会节奏的加快,用户碎片化消费时间不断增加,当前短视频的消费用户规模已超 7.73 亿人,短视频的市场规模超过 2000 亿元.短视频行业发展迅速,但也存在低质内容泛滥,精品内容稀缺 ...
- nlp底层技术列举
其实目前除了之前博客写到的一些关于自然语言处理用到的知识点之外,很多其他nlp技术只是会用但是不了解原理,先整体分个类,之后再仔细分析吧. 上图是https://www.sohu.com/a/1386 ...
- Flair:一款简单但技术先进的NLP库
过去的几年里,在NLP(自然语言处理)领域,我们已经见证了多项令人难以置信的突破,如ULMFiT.ELMo.Facebook的PyText以及谷歌的BERT等等. 这些技术大大推进了NLP的前沿性研究 ...
- NLP初步
[NLP初步] NLP是Natural Lanuage Process的缩写.搜索引擎可以通过关词匹配和完成很多的任务, 比如话题搜索(搜索包含律师, 法院, 控告等词的文档), 但是搜索引擎无法理解 ...
- NLP是什么
NLP是什么 而在计算机领域, NLP(Natural Language Processing),也就是人们常说的「自然语言处理」,就是研究如何让计算机读懂人类语言. 这包括,既要能让计算机理解自然语 ...
- nlp总结
中科院nlpir和海量分词(http://www.hylanda.com/)是收费的. hanlp:推荐基于CRF的模型的实现~~要看语料,很多常用词会被分错,所以需要词库支撑.目前最友好的开源工具包 ...
- SEO站长必备的十大常用搜索引擎高级指令
作为一个seo人员,不懂得必要的搜索引擎高级指令,不是一个合格的seo.网站优化技术配合一些搜索引擎高级指令将使得优化工作变得简单.今日就和大家聊聊SEO站长必备的十大常用搜索引擎高级指令的那些事儿. ...
- NoSQL 数据建模技术(转)
本文转载自:http://coolshell.cn/articles/7270.html ================================================ 全文译自墙外 ...
- 百度和 Google 的搜索技术是一个量级吗?
著作权归作者所有. 商业转载请联系作者获得授权,非商业转载请注明出处. 作者:Kenny Chao 链接:http://www.zhihu.com/question/22447908/answer/2 ...
随机推荐
- 【WebGL系列-01】获取WebGL上下文
获取WebGL上下文 获取上下文 WebGL上下文是从<canvas>标签中获取到的,通过canvas对象的getContext()函数可以获取WebGLRenderingContext. ...
- 宝塔面板配合tomcat部署静态资源网站
在宝塔中安装下图所示软件 第一步:上传代码到服务器 第二步,点击JAVA项目一键部署 点击添加项目 第一次使用时项目版本是为空的,点击下方的版本管理进行安装 需要填写的选项 至此配置完成 访问方式 i ...
- 【pandas小技巧】--反转行列顺序
反转pandas DataFrame的行列顺序是一种非常实用的操作.在实际应用中,当我们需要对数据进行排列或者排序时,通常会使用到Pandas的行列反转功能.这个过程可以帮助我们更好地理解数据集,发现 ...
- C# 使用openxml解析PPTX中的文本内容
前言 本文讨论的仅针对微软Office 2007以后的(OOXML定义)PowerPoint文档,Office 2007以前的用二进制格式定义的(ppt格式)文档不在本文讨论范围. 一.依赖类库 本文 ...
- arrch架构部署redis,报错: ignore-warnings ARM64-COW-BUG
arrch架构服务器redis部署完成后,启动报错.做个记录. arrch架构的redis安装包 下载链接:https://pan.baidu.com/s/1TMXNpMvMDWRFD1f5km7Mw ...
- 从零开始实现放置游戏(十七)——完结篇(附DEMO地址)
大家好,时隔2年多,我来填坑啦! 之前用的技术.设计思路都不成熟,所以直接干掉重做了. 由于从头教学实在太啰嗦,精力也有限,咱们还是直接上源码吧. DEMO地址: http://212.129.154 ...
- C++欧几里得算法求最大公约数和最小公倍数
定义 最大公约数即为 Greatest Common Divisor,常缩写为 gcd. 一组整数的公约数,是指同时是这组数中每一个数的约数的数. 一组整数的最大公约数,是指所有公约数里面最大的一个. ...
- Matlab机器人工具箱安装教程
参考以下博客 https://blog.csdn.net/AprilsHell/article/details/90722892
- Python 潮流周刊#16:优雅重要么?如何写出 Pythonic 的代码?
你好,我是猫哥.这里每周分享优质的 Python.AI 及通用技术内容,大部分为英文.标题取自其中两则分享,不代表全部内容都是该主题,特此声明. 本周刊由 Python猫 出品,精心筛选国内外的 25 ...
- API接口获取的商品详情该如何使用
获取到商品API接口返回的商品详情数据后,我们可以将其用于以下方面: 商品展示:通过获取到的商品详情数据,我们可以展示商品信息,包括商品名称.价格.商品图片.描述等信息.我们可以将这些信息显示在商品详 ...