String对象和String常量池
1. String的基本特性
- String:字符串,使用一对 “” 引起来表示
String s1 = "mogublog" ; // 字面量的定义方式
String s2 = new String("moxi"); // new 对象的方式
- String声明为final的,不可被继承 String实现了Serializable接口:表示字符串是支持序列化的。实现了Comparable接口:表示String可以比较大小
- string在jdk8及以前内部定义了final char[] value用于存储字符串数据。JDK9时改为byte[]
1.1 为什么String在jdk9 之后改变了其底层结构
官方解释: http://openjdk.java.net/jeps/254
String类的jdk8之前的实现将字符存储在char数组中,每个字符使用两个字节(16位)。
但是从许多不同的应用程序收集的数据表明,字符串是堆使用的主要组成部分,而且大多数字符串对象只包含拉丁字符。这些字符只需要一个字节的存储空间,因此这些字符串对象的内部char数组中有一半的空间将不会使用。 例如 存
ab这个字符,如果使用char 数组,就要分配两个字符的空间,即 四个字节, 但是ab 作为英文,本身只需占用两个字节即可之前 String 类使用 UTF-16 的 char[] 数组存储,现在改为 byte[] 数组 外加一个编码标志位存储,该编码标志将指定 String 类中 byte[] 数组的编码方式
结论:String再也不用char[] 来存储了,改成了byte [] 加上编码标记,节约了一些空间 ,
同时基于String的数据结构,例如StringBuffer和StringBuilder也同样做了修改
1.2 String 的不可变性
- 当对字符串变量重新赋值时,会直接新建一个字符串(或池中本来就有的),不会影响本来的字符串
- 当对现有的字符串进行连接拼接操作时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
- 当调用String的replace()方法修改指定字符或字符串时,也需要重新指定内存区域赋值,不能使用原有的value进行赋值。
2. String的内存分配位置
在Java语言中有8种基本数据类型和一种比较特殊的非常常用的类型String。这些类型为了使它们在运行过程中速度更快、更节省内存,都提供了一种常量池的概念。
常量池就类似一个Java系统级别提供的缓存。8种基本数据类型的常量池都是系统协调的,String类型的常量池比较特殊。它的主要使用方法有两种。
- 直接使用双引号声明出来的String对象会直接存储在常量池中。比如:
String info="atguigu.com"; - 如果不是用双引号声明的String对象(new出来的,或者其他方法返回的),可以使用String提供的intern()方法。
代码演示:
class Memory {
public static void main(String[] args) {//line 1
int i = 1;//line 2
Object obj = new Object();//line 3
Memory mem = new Memory();//line 4
mem.foo(obj);//line 5
}//line 9
private void foo(Object param) {//line 6
String str = param.toString();//line 7
System.out.println(str);
}//line 8
}
示意图: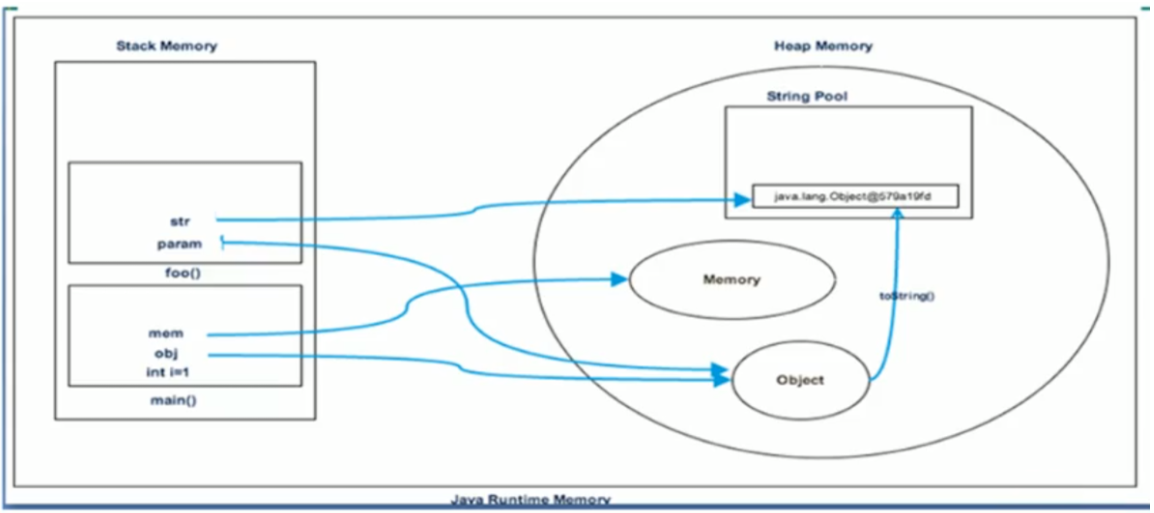
如上图所示,, 堆中的Object 对象在调用toString 方法后,将在String pool 中生成一个字符串对象,并返回给 顶层栈帧foo方法中的局部变量 str
String 内存分配的演进过程
- Java 6及以前,字符串常量池存放在永久代
- Java 7中 Oracle的工程师对字符串池的逻辑做了很大的改变,即将字符串常量池的位置调整到Java堆内
- 所有的字符串都保存在堆(Heap)中,和其他普通对象一样,这样可以让你在进行调优应用时仅需要调整堆大小就可以了。
- 字符串常量池概念原本使用得比较多,但是这个改动使得我们有足够的理由让我们重新考虑在Java 7中使用String.intern()
JDK6 : 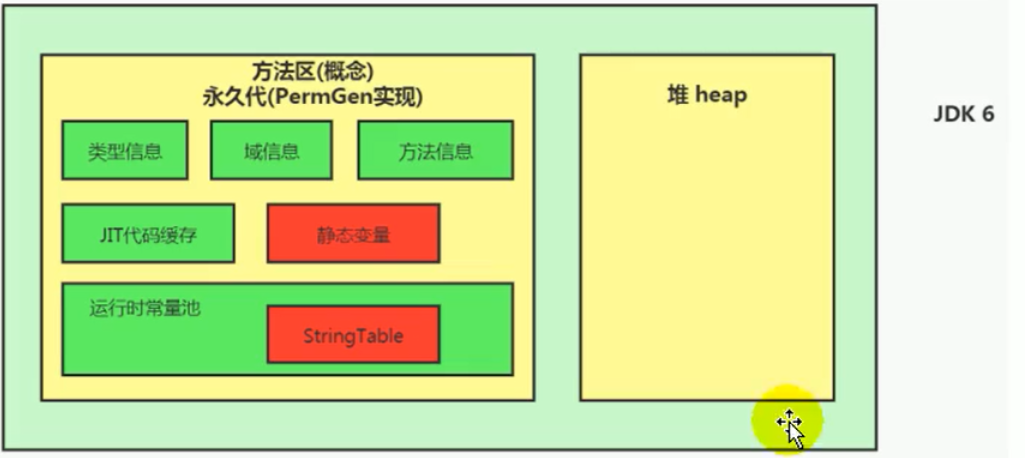
JDK7:
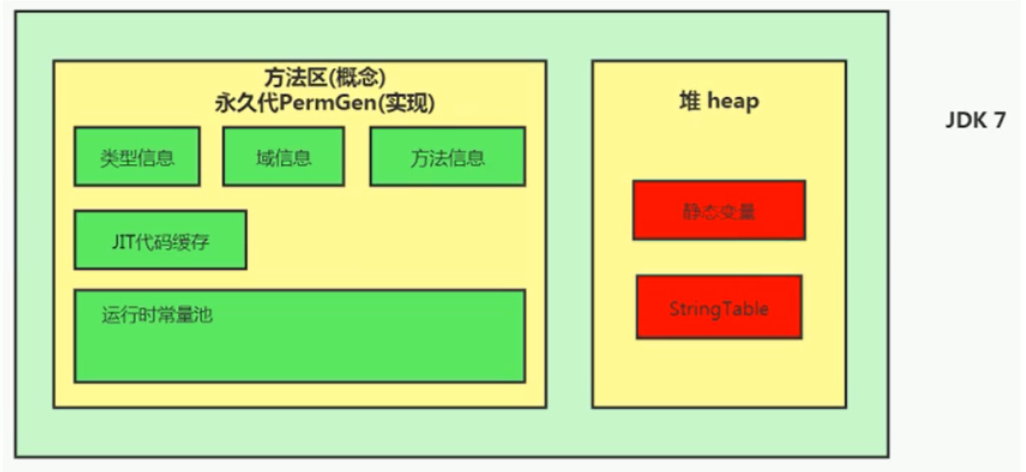
为什么要调整String 常量池的位置呢
- 永久代的默认比较小
- 永久代垃圾回收频率低
- 堆中空间足够大,字符串可被及时回收
3 String 常量池的底层结构
字符串常量池是不会存储相同内容的字符串的
- String的String Pool是一个固定大小的Hashtable,默认值大小长度是1009。如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern()方法时性能会大幅下降。
- 使用
-XX:StringTablesize可设置StringTable的长度 - 在JDK6中StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快,StringTablesize设置没有要求
- 在JDK7中,StringTable的长度默认值是60013,StringTablesize设置没有要求
- 在JDK8中,StringTable的长度默认值也是60013,但是限定了StringTable可以设置的最小值为1009
字符串常量池中同一个字符串只存在一份
Java语言规范里要求完全相同的字符串字面量,应该包含同样的Unicode字符序列(包含同一份码点序列的常量),并且必须是指向同一个String类实例。
代码示例:
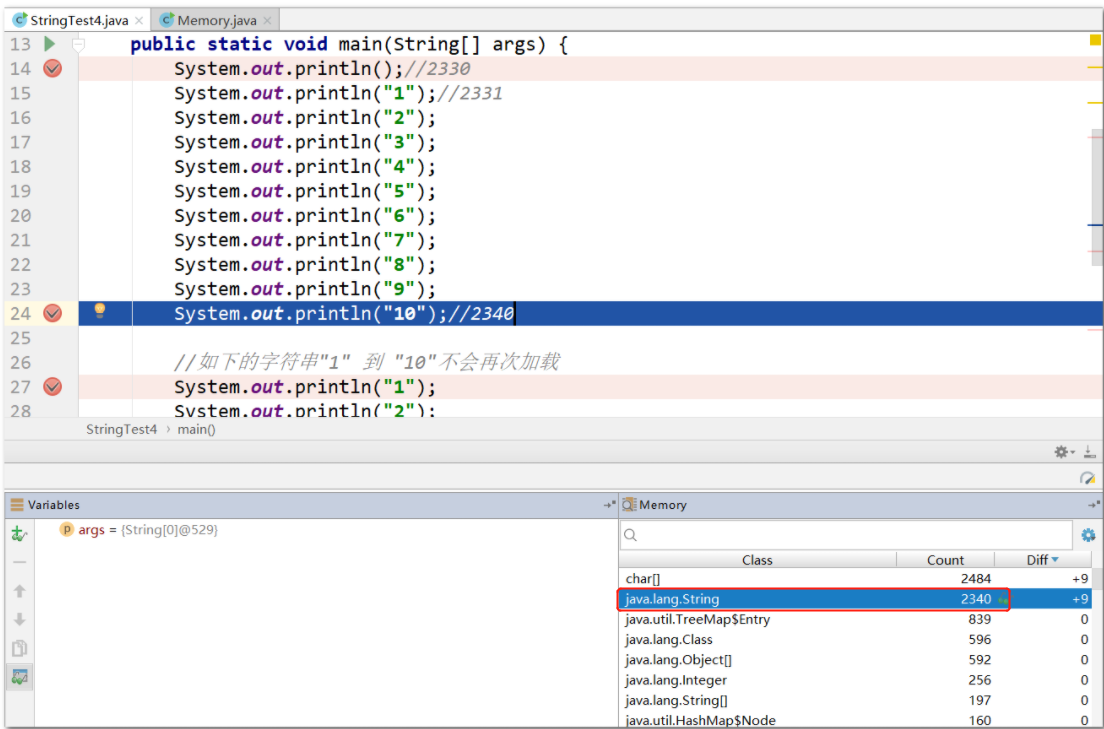
public class StringTest4 {
public static void main(String[] args) {
System.out.println();//2330
System.out.println("1");//2331 个字符串
System.out.println("2");
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");//2340 个字符串
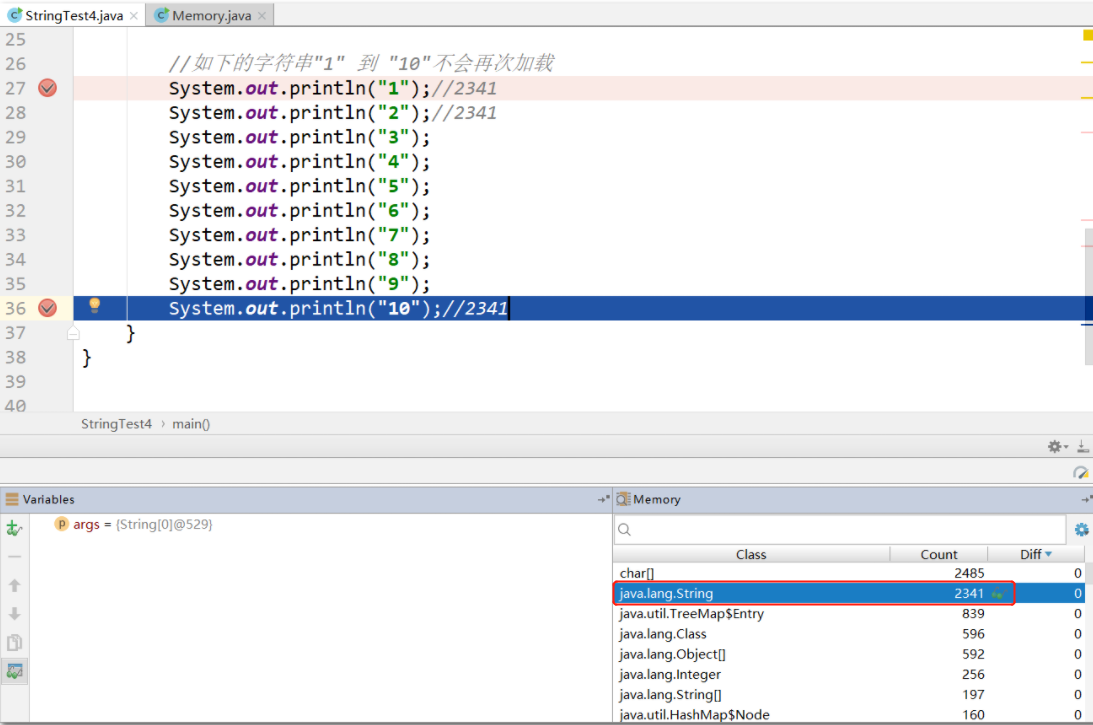
//如下的字符串"1" 到 "10"不会再次加载
System.out.println("1");//2341
System.out.println("2");//2341
System.out.println("3");
System.out.println("4");
System.out.println("5");
System.out.println("6");
System.out.println("7");
System.out.println("8");
System.out.println("9");
System.out.println("10");//2341
}
}
在第一波开始,堆中的String 个数:
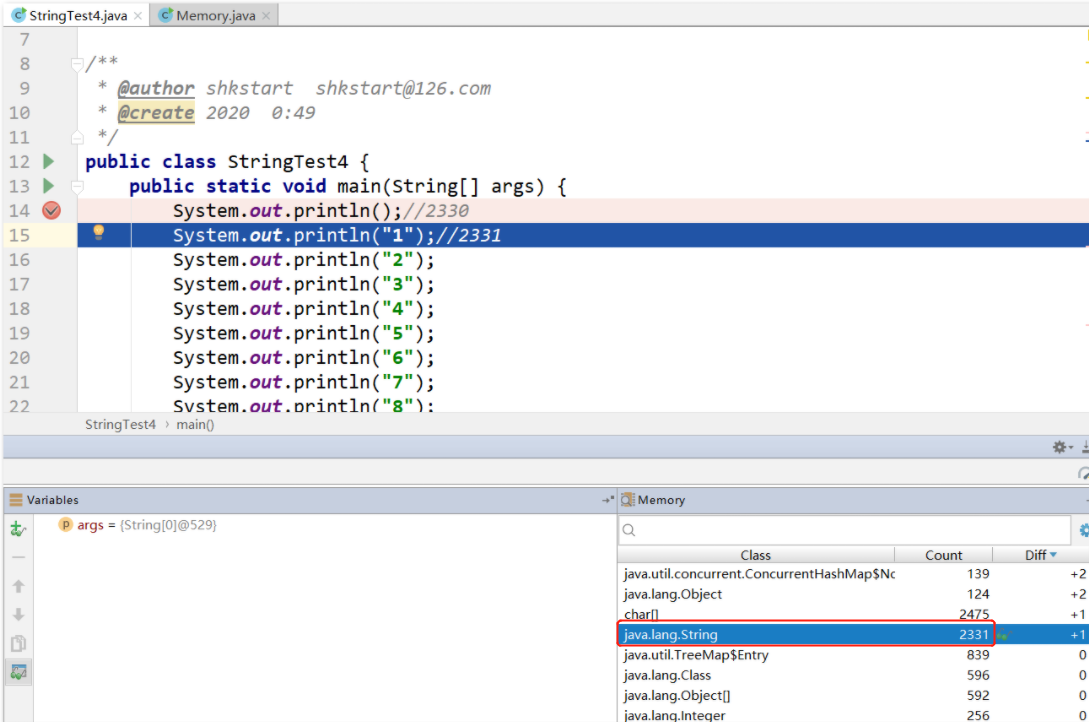
第一波结束时, 字符串个数,加了十个:
之后就再没增加过了:
测试不同的 StringTable长度下,程序的性能
首先先创建一个拥有10W行不同字符的文件,程序自行编写,这里就不演示了
/**
* -XX:StringTableSize=1009
*/
public class StringTest2 {
public static void main(String[] args) {
BufferedReader br = null;
try {
br = new BufferedReader(new FileReader("words.txt"));
long start = System.currentTimeMillis();
String data;
while ((data = br.readLine()) != null) {
//如果字符串常量池中没有对应data的字符串的话,则在常量池中生成
data.intern();
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));//1009:143ms 100009:47ms
} catch (IOException e) {
e.printStackTrace();
} finally {
if (br != null) {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
-XX:StringTableSize=1009:程序耗时 143ms-XX:StringTableSize=100009:程序耗时 47ms
4. 字符串的拼接操作
- 常量与常量的拼接结果在常量池,在编译期就进行运算了
- 常量池中不会存在相同内容的变量
- 拼接前后,只要其中有一个是变量,就会就在堆中
new一个。不在常量池中,变量拼接的原理是StringBuilder - 如果是
new出来的String调用intern()方法,则会判断常量池中有没有这个字符- 如果存在,则返回字符串在常量池中的地址
- 如果字符串常量池中不存在该字符串,则在常量池中创建一份,并返回此对象的地址
4.1 两个代码演示
代码一:
public void test1() {
String s1 = "a" + "b" + "c";//编译期优化:等同于"abc"
String s2 = "abc"; //"abc"一定是放在字符串常量池中,将此地址赋给s2
/*
* 最终.java编译成.class,再执行.class
* String s1 = "abc";
* String s2 = "abc"
*/
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
}
结果打印的都是 true,不管是 地址值还是 内容 都一样,看下面解析出的字节码指令,在指令0的位置从常量池中直接加载"abc"
0 ldc #2 <abc>
2 astore_1
3 ldc #2 <abc>
5 astore_2
6 getstatic #3 <java/lang/System.out>
9 aload_1
10 aload_2
11 if_acmpne 18 (+7)
14 iconst_1
15 goto 19 (+4)
18 iconst_0
19 invokevirtual #4 <java/io/PrintStream.println>
22 getstatic #3 <java/lang/System.out>
25 aload_1
26 aload_2
27 invokevirtual #5 <java/lang/String.equals>
30 invokevirtual #4 <java/io/PrintStream.println>
33 return
代码二:
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";//编译期优化
//如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果:javaEEhadoop
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);//true
//后面都是false 的原因是,只要拼接时 有变量参与,都是相当于new 一个 不从常量池中共享
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//false
System.out.println(s5 == s6);//false
System.out.println(s5 == s7);//false
System.out.println(s6 == s7);//false
//intern():判断字符串常量池中是否存在javaEEhadoop值,如果存在,则返回常量池中javaEEhadoop的地址;
//如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回此对象的地址。
String s8 = s6.intern();
//s6 虽然是堆中new出来的,但是调用intern方法返回出的是 常量池中的,所以和 s3 地址一样
System.out.println(s3 == s8);//true
}
4.2 字符串变量拼接的底层实现
前面说到, 一旦拼接操作有变量引用的参与,而不是全部都是字面量的形式, 就会 在堆中 新new一个对象,这是为什么呢?,下面用一个简单的代码解释
代码:
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;//"ab"
System.out.println(s3 == s4);//false
}
字节码指令:
0 ldc #14 <a> //将字符a 从字符串常量池中获取
2 astore_1 //放入 局部变量索引为 1 的位置 (0为this)
3 ldc #15 <b> //将字符b从字符串常量池中获取
5 astore_2 //放入 局部变量索引为 2 的位置
6 ldc #16 <ab> //将字符ab 从字符串常量池中获取
8 astore_3 //放入 局部变量索引为 3 的位置
9 new #9 <java/lang/StringBuilder> // new 一个 StringBuilder对象,开辟空间
12 dup
13 invokespecial #10 <java/lang/StringBuilder.<init>> //初始化该StringBuilder对象
16 aload_1 // 加载 局部变量表中索引为1的值 ,也就是 a
17 invokevirtual #11 <java/lang/StringBuilder.append> //调用 StringBuilder对象 的 append 方法
20 aload_2 //加载 b
21 invokevirtual #11 <java/lang/StringBuilder.append> //同样append
24 invokevirtual #12 <java/lang/StringBuilder.toString> //最后调用StringBuilder对象的toString方法
27 astore 4 //放入 局部变量表 索引为 4的位置
29 getstatic #3 <java/lang/System.out>
32 aload_3
33 aload 4
35 if_acmpne 42 (+7)
38 iconst_1
39 goto 43 (+4)
42 iconst_0
43 invokevirtual #4 <java/io/PrintStream.println>
46 return
从上面的 字节码 逐行解释中看, 带有 变量的字符串拼接,其底层是使用 StringBuilder 对象
相当于如下代码:
StringBuilder s = new StringBuilder();
s.append("a")
s.append("b")
s.toString() // 约等于 new String("ab"),方法内就是 new String ,但是有些不同 后面说
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer
是不是所有字符串变量的拼接操作都是使用的是StringBuilder
那肯定是不是的,看下面这种情况:
public void test4(){
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);//true
}
字节码: 看 指令9的位置,为 s1+s2 的操作,并没有使用 拼接的方式,而是在编译器就已经处理好了
0 ldc #14 <a>
2 astore_1
3 ldc #15 <b>
5 astore_2
6 ldc #16 <ab>
8 astore_3
9 ldc #16 <ab>
11 astore 4
13 getstatic #3 <java/lang/System.out>
16 aload_3
17 aload 4
19 if_acmpne 26 (+7)
22 iconst_1
23 goto 27 (+4)
26 iconst_0
27 invokevirtual #4 <java/io/PrintStream.println>
30 return
结论: 和直接使用字面量相同, 如果拼接字符变量都为 final ,都是可以在编译器就可以确定结果的, 所以也被编译器优化了(在写代码时,可以写final的都可以写上,优化代码)
4.3 拼接操作和使用StringBuilder拼接的性能差距
代码
public void test6(){
long start = System.currentTimeMillis();
//method1(100000);//4014
method2(100000);//7
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
}
public void method1(int highLevel){
String src = "";
for(int i = 0;i < highLevel;i++){
src = src + "a";//每次循环都会创建一个StringBuilder、String
}
}
public void method2(int highLevel){
//只需要创建一个StringBuilder
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
}
我们发现, 使用method1方法,拼接字符串10w次, 使用时间为 4014ms,
而使用method2方法,append 方式,仅仅只需7ms, 差距如此之大
为什么?
- StringBuilder的append()的方式:自始至终中只创建过一个StringBuilder的对象,并在操作结束后返回一个字符串,操作过程中不会产生
- 而 使用String的字符串拼接方式:每一次拼接操作都会创建一个StringBuilder和String的对象,也就是20w个对象, 期间触发GC的可能也很大, 进一步变慢
对于上面的StringBuilder方式,还有更一步的改进方式
查看 StringBuilder 类底层的实现时,发现初始定义一个 char 型数组(JDK8),用于append操作, 在数组长度不够时,会创建一个更长的,并进行拷贝, 这也有点浪费时间,所以在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值highLevel的情况下,建议使用构造器实例化:
StringBuilder s = new StringBuilder(highLevel); //new char[highLevel]
5. String的intern方法
5.1 intern()方法的基本说明
前面已经有使用过,并且大概解释过,现在具体说明一下
public native String intern();
intern是一个native方法,调用的是底层C的方法
字符串池最初是空的。在调用intern方法时,如果池中已经包含了由equals(object)方法确定的与该字符串对象相等的字符串(也就是值相等),则返回池中的字符串。否则,该字符串对象值放一个到池中,并返回对该字符串对象的引用。
也就是说,如果在任意字符串上调用String.intern方法,那么其返回结果所指向的那个类实例,必须和直接以字面量形式出现的字符串实例完全相同。因此,下列表达式的值必定是true
("a"+"b"+"c").intern()=="abc"通俗点讲,String就是确保字符串在常量池里有一份拷贝,这样可以节约内存空间,加快字符串操作任务的执行速度。
如何保证 变量s 指向的是字符串常量池中的数据呢?
方式一 : String s = "Hello"; //直接使用字面量
方式二: 使用 intern方法
- String s = new String("Hello").intern()'
- String s = new StringBuilder("123").toString().intern();
5.2 new String("ab") 创建几个对象
这个面试题应该很多人都是知道的,答案是一个或者两个, 下面用字节码指令证明这个事
public class StringNewTest {
public static void main(String[] args) {
String str = new String("ab");
}
}
字节码指令:
0 new #2 <java/lang/String> //堆中创建 String对象
3 dup
4 ldc #3 <ab> //从 常量池中获取 ab 字符串对象,如果没有 则会创建
6 invokespecial #4 <java/lang/String.<init>> //使用 ab 字面量去初始化 堆中的 String 对象
9 astore_1
10 return
所以有上面的结论 ,一个或两个, 如果常量池中没有这个字面量的情况是是会创建两个的
看看 String类的带参构造函数
private final char[] value;
private int hash;
//...
public String(String var1) {
this.value = var1.value;
this.hash = var1.hash;
}
可以看到,将常量池String对象中的value 属性,也就是维护的char[] 和字符的hash值赋给了 new String 对象的 value属性和 hash属性,所以 new 出的String 对象的内容为参数中的值, 这也说明了,虽然 常量池中的String对象 和new 出的 String 对象本身地址值不同,但是他们所维护的char[]却是同一个
那么new String(“a”) + new String(“b”) 会创建几个对象?
public class StringNewTest {
public static void main(String[] args) {
String str = new String("a") + new String("b");
}
}
字节码指令:
0 new #2 <java/lang/StringBuilder> // 1. StringBuilder 对象
3 dup
4 invokespecial #3 <java/lang/StringBuilder.<init>>
7 new #4 <java/lang/String> // 2. new String("a") 对象
10 dup
11 ldc #5 <a> //3. 常量池中 a 字符串对象
13 invokespecial #6 <java/lang/String.<init>>
16 invokevirtual #7 <java/lang/StringBuilder.append>
19 new #4 <java/lang/String> // 4. new String 对象
22 dup
23 ldc #8 <b> //5. 常量池中 b 字符串对象
25 invokespecial #6 <java/lang/String.<init>>
28 invokevirtual #7 <java/lang/StringBuilder.append>
31 invokevirtual #9 <java/lang/StringBuilder.toString> //toString 返回的
34 astore_1
35 return
所有上面的代码 最多创建 6个对象
- 对象1:new StringBuilder()
- 对象2: new String("a")
- 对象3: 常量池中的"a"
- 对象4: new String("b")
- 对象5: 常量池中的"b"
- 对象6: toString方法创建的对象
深入剖析: StringBuilder的toString():
代码:
public String toString() {
// Create a copy, don't share the array
return new String(value, 0, count);
}
这是StringBuilder 对象的toString 方法, 将 StringBuilder 类中append 处理的char[] 连接为一个字符串,
和普通的 new String("ab")不一样, 并没有使用字面量的形式创建,所以没有在 常量池中创建"ab" 字符串
所以这里就创建了一个
5.3 JDK7 前后 intern() 方法的变化
在前面说到, intern() 方法是将判断调用者字符串对象的值 是否在常量池中存在,如果存在 则返回常量池中的那个对象引用,如果不存在则 造一个, 但是这个造一个 ,在随着JDK7 将字符串常量池移到堆空间时,发生了变化
代码示例:
public class StringIntern {
public static void main(String[] args) {
String s = new String("1");
s.intern();//此方法调用前常量池中就已经有 字符串 "1"了
String s2 = "1";
System.out.println(s == s2); //jdk6:false jdk7/8:false
// 执行完下一行代码以后,字符串常量池中,是否存在"11"呢?答案:不存在!!
String s3 = new String("1") + new String("1");//s3变量记录的地址为:new String("11")
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);// jdk6:false jdk7/8:true
}
}
上面的代码中
第一个输出语句 无论如何都是打印false,那是因为在创建
new String("1")时已经在堆中创建了 字符串 "1",所以intern() 方法没有再创建,而S2则引用了常量池中的对象,所以和new String()的s一直都是false第二个输出语句 在jdk6 中打印了 false, 是因为 代码
new String("1") + new String("1")相当于 创建了一个new String("11")赋予了s3,但是根据上一节说到的,并没有在常量池中生成 "11",所以 当调用intern() 方法时, 创建了一个新的字符串 "11" 放到了常量池中,注意 此时的环境为JDK6, 字符串常量池在 方法区中,和new的对象不在一起,所以是创建一个新的方式但是在JDK7 及以后的版本,却是打印 true,是因为 字符串常量挪到了 堆中,和 new的对象在一起,所以杜绝空间浪费, 调用intern() 方法创建对象时,没有拷贝新的,而是存了
new String()对象的引用到字符串常量池中,所以打印为 true
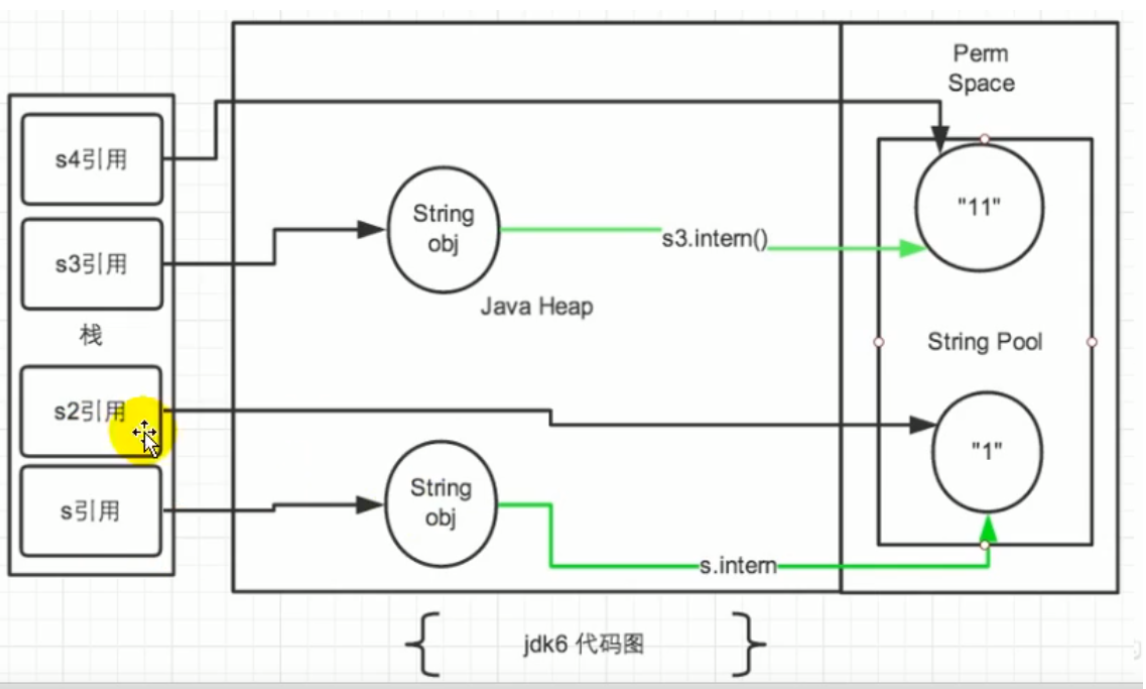
内存示意图:
JDK6:
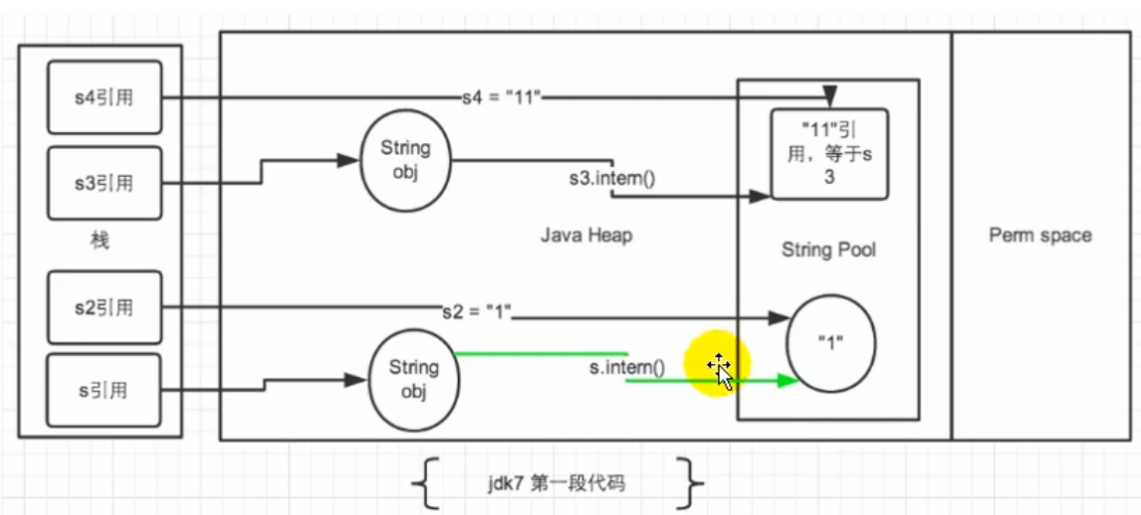
JDK7
扩展
public class StringIntern1 {
public static void main(String[] args) {
String s3 = new String("1") + new String("1");//new String("11")
//在字符串常量池中生成对象"11"
String s4 = "11";
String s5 = s3.intern();
System.out.println(s3 == s4);//false
System.out.println(s5 == s4);//true
}
}
将上面的代码中 声明字面量提到调用intern() 方法前后,打印结果就固定了,那是因为在声明"11" 时已经创建一个新的字符串到常量池中. 所以必定是false;
5.4 intern方法的总结
当调用 intern 方法时:
JDK1.6中,将这个字符串对象尝试放入串池。
- 如果串池中有,则并不会放入。返回已有的串池中的对象的地址
- 如果没有,会把此对象复制一份,放入串池,并返回串池中的对象地址
JDK1.7起,将这个字符串对象尝试放入串池。
- 如果串池中有,则并不会放入。返回已有的串池中的对象的地址
- 如果没有,则会把对象的引用地址复制一份,放入串池,并返回串池中的引用地址
5.5 intern() 方法效率测试
看下面的一段代码:
public class StringIntern2 {
static final int MAX_COUNT = 1000 * 10000;
static final String[] arr = new String[MAX_COUNT];
public static void main(String[] args) {
Integer[] data = new Integer[]{1,2,3,4,5,6,7,8,9,10};
long start = System.currentTimeMillis();
for (int i = 0; i < MAX_COUNT; i++) {
// arr[i] = new String(String.valueOf(data[i % data.length]));
arr[i] = new String(String.valueOf(data[i % data.length])).intern();
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
上面的代码中,将 1-10 每次使用 String.valueOf 的方式转换为 字符串 存入数组中,循环1000W次, 下面看 使用intern方法和不使用的区别
不使用: valueOf 方法中每次都在堆中new 了一个新的字符串对象, 所以共创建了 1000w个对象

使用intern: 虽然每次也都创建了 String 对象, 但是最后返回的 却是intern 方法返回的 字符串常量池中的,会被重用, 而因为数组中并没有指向在堆中创建的String 对象,将在垃圾回收时 被销毁,减少内存,查看内存数据也是如此

结论:
- 对于程序中大量使用存在的字符串时,尤其存在很多已经重复的字符串时,使用intern()方法能够节省内存空间。
- 大的网站平台,需要内存中存储大量的字符串。比如社交网站,很多人都存储:北京市、海淀区等信息。这时候如果字符串都调用intern() 方法,就会很明显降低内存的大小。
6 String 的垃圾回收
代码演示: 创建10w个字符串
public class StringGCTest {
public static void main(String[] args) {
for (int j = 0; j < 100000; j++) {
String.valueOf(j).intern();
}
}
}
jvm 参数: -Xms15m -Xmx15m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails 打印 字符串常量池中的信息和垃圾回收的信息
打印信息如下, 很明显在新生代PSYoungGen发生了垃圾回收的行为, 并且看出 字符串常量池中也不足10w个对象

打印内容:
Heap
PSYoungGen total 4608K, used 3883K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000)
eden space 4096K, 82% used [0x00000000ffb00000,0x00000000ffe50fb0,0x00000000fff00000)
from space 512K, 95% used [0x00000000fff00000,0x00000000fff7a020,0x00000000fff80000)
to space 512K, 0% used [0x00000000fff80000,0x00000000fff80000,0x0000000100000000)
ParOldGen total 11264K, used 228K [0x00000000ff000000, 0x00000000ffb00000, 0x00000000ffb00000)
object space 11264K, 2% used [0x00000000ff000000,0x00000000ff039010,0x00000000ffb00000)
Metaspace used 3472K, capacity 4496K, committed 4864K, reserved 1056768K
class space used 381K, capacity 388K, committed 512K, reserved 1048576K
SymbolTable statistics:
Number of buckets : 20011 = 160088 bytes, avg 8.000
Number of entries : 14158 = 339792 bytes, avg 24.000
Number of literals : 14158 = 603200 bytes, avg 42.605
Total footprint : = 1103080 bytes
Average bucket size : 0.708
Variance of bucket size : 0.711
Std. dev. of bucket size: 0.843
Maximum bucket size : 6
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 62943 = 1510632 bytes, avg 24.000
Number of literals : 62943 = 3584040 bytes, avg 56.941
Total footprint : = 5574776 bytes
Average bucket size : 1.049
Variance of bucket size : 0.824
Std. dev. of bucket size: 0.908
Maximum bucket size : 5
补充: G1中 String 去重操作
这个去重操作针对的不是 String本身,因为 String 常量池中 本身就不是重复的,而是针对 new String() 中维护的char[]
String 去重操作的背景
对许多Java应用(有大的也有小的)做的测试得出以下结果:
- 堆存活数据集合里面String对象占了25%
- 堆存活数据集合里面重复的String对象有13.5%
- String对象的平均长度是45
许多大规模的Java应用的瓶颈在于内存,测试表明,在这些类型的应用里面,Java堆中存活的数据集合差不多25%是String对象。更进一步,这里面差不多一半String对象是重复的,重复的意思是说:
str1.equals(str2)= true。堆上存在重复的String对象必然是一种内存的浪费。这个项目将在G1垃圾收集器中实现自动持续对重复的String对象进行去重,这样就能避免浪费内存。
String 去重的的具体实现
- 当垃圾收集器工作的时候,会访问堆上存活的对象。对每一个访问的对象都会检查是否是候选的要去重的String对象。
- 如果是,把这个对象的一个引用插入到队列中等待后续的处理。一个去重的线程在后台运行,处理这个队列。处理队列的一个元素意味着从队列删除这个元素,然后尝试去重它引用的String对象。
- 使用一个Hashtable来记录所有的被String对象(堆中创建的 和 常量池中的)使用的不重复的char数组。当去重的时候,会查这个Hashtable,来看堆上是否已经存在一个一模一样的char数组。
- 如果存在,String对象会被调整内部维护的数组去,引用那个数组,释放对原来的数组的引用,最终会被垃圾收集器回收掉。
- 如果查找失败,char数组会被插入到Hashtable,这样以后的时候就可以共享这个数组了。
命令行选项:
- UseStringDeduplication(bool) :开启String去重,默认是不开启的,需要手动开启。
- PrintStringDeduplicationStatistics(bool) :打印详细的去重统计信息
- stringDeduplicationAgeThreshold(uintx) :达到这个年龄的String对象被认为是去重的候选对象
String对象和String常量池的更多相关文章
- JAVA String对象和字符串常量的关系解析
JAVA String对象和字符串常量的关系解析 1 字符串内部列表 JAVA中所有的对象都存放在堆里面,包括String对象.字符串常量保存在JAVA的.class文件的常量池中,在编译期就确定好了 ...
- java基础进阶一:String源码和String常量池
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/8046564.html 邮箱:moyi@moyib ...
- String放入运行时常量池的时机与String.intern()方法解惑
运行时常量池概述 Java运行时常量池中主要存放两大类常量:字面量和符号引用.字面量比较接近于Java语言层面的常量概念,如文本字符串.声明为final的常量值等. 而符号引用则属于编译原理方面的概念 ...
- Knowledge Point 20180309 字符串常量池与String,intern()
引言 什么都先不说,先看下面这个引入的例子: public static void test4(){ String str1 = new String("SEU") + new S ...
- Java中,那些关于String和字符串常量池你不得不知道的东西
老套的笔试题 在一些老套的笔试题中,会要你判断s1==s2为false还是true,s1.equals(s2)为false还是true. String s1 = new String("xy ...
- String s = new String("xyz");创建了几个对象?
两个或一个都有可能 . ”xyz”对应一个对象,这个对象放在字符串常量池,常量”xyz”不管出现多少遍,都是常量池中的那一个. new String每写一遍,就创建一个新的对象,它使用常量”xyz”对 ...
- java中的string对象深入了解
这里来对Java中的String对象做一个稍微深入的了解. Java对象实现的演进 String对象是Java中使用最频繁的对象之一,所以Java开发者们也在不断地对String对象的实现进行优化,以 ...
- java常量池詳解
一.相关概念 什么是常量用final修饰的成员变量表示常量,值一旦给定就无法改变!final修饰的变量有三种:静态变量.实例变量和局部变量,分别表示三种类型的常量. Class文件中的常量池在Clas ...
- java字符串常量池——字符串==比较的一个误区
转自:https://blog.csdn.net/wxz980927155/article/details/81712342 起因 再一次js的json对象的比较中,发现相同内容的json对象使用 ...
- java虚拟机学习-Java常量池理解与总结(13-2)
一.相关概念 什么是常量用final修饰的成员变量表示常量,值一旦给定就无法改变!final修饰的变量有三种:静态变量.实例变量和局部变量,分别表示三种类型的常量. Class文件中的常量池在Clas ...
随机推荐
- 解决Chrome翻译无法使用
截止2022年11月3日自己ping出的ip不可用了 可以用以下ip 172.217.215.90 172.253.115.90 142.250.126.90 142.250.10.90 142.25 ...
- 分布式ID介绍&实现方案总结
分布式 ID 介绍 什么是 ID? 日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单. ...
- Golang中make和new的区别
1. 相同点 都是内建函数,都是在堆上分配内存,都需要传递类型参数 2. 不同点 传递的参数不一样,new函数只接收一个参数,make函数可以接收一个以上的参数 package main import ...
- 深入研究Delimiter,发现Delimiter 是自动合并重复的。
即使加上: MyList.StrictDelimiter := True; 也自动合并相邻的重复的.这点有好处也有坏处,坏处 暂时 还没有想到. -------------- 浙江省 绍兴市 越城区 ...
- Loading进度条
- ASP.NET Core分布式项目实战(运行Consent Page)--学习笔记
任务21:运行Consent Page 修改 Config.cs 中的 RequireConsent 为 true,这样登录的时候就会跳转到 Consent 页面 修改 ConsentControll ...
- Teams基础功能与会议介绍
目录 Teams基本功能介绍 活动 聊天 如何查找联系人 如何开启语音或视频通话 如何共享自己的屏幕 如何新建群聊 发送文件的多种方式 快速安排一个会议 重要与紧急的消息 文件 分享的文件 OneDr ...
- 【Unity3D】刚体组件Rigidbody
1 前言 刚体(Rigidbody)是运动学(Kinematic)中的一个概念,指在运动中和受力作用后,形状和大小不变,而且内部各点的相对位置不变的物体.在 Unity3D 中,刚体组件赋予了游戏 ...
- scrcpy-Android投屏神器
介绍 scrcpy 是免费开源的投屏软件,支持将安卓手机屏幕投放在 Windows.macOS.GNU/Linux 上,并可直接借助鼠标在投屏窗口中进行交互和录制. 下载scrcpy 解压. http ...
- C++ 多线程的错误和如何避免(2)
试图 join 一个已经 detach 的线程 如果你已经在某个地方分离了线程,那你不可以在主线程再次 join,这是一个明显的错误 比如: #include <iostream> #in ...